CNN:卷积神经网络
CNN基本结构
主要针对DNN存在的参数数量膨胀问题,对于CNN,并不是所有的上下层神经元都能直接相连,而是通过“卷积核”作为中介(部分连接)。同一个卷积核在多有图像内是共享的,图像通过卷积操作仍能保留原先的位置关系。CNN之所以适合图像识别,正是因为CNN模型限制参数个数并挖掘局部结构的这个特点。
卷积神经网络的基本结构大致包括:卷积层、激活函数、池化层、全连接层、输出层等。
![]()
![]()
卷积层
- 二维卷积
给定二维的图像I作为输入,二维卷积核K,卷积运算可以表示为:
S ( i , j ) = ( I ∗ K ) ( i , j ) = ∑ m ∑ n I ( i − m , j − n ) ⋅ K ( m , n ) S(i,j)=(I*K)(i,j)=\sum_m \sum_n I(i-m,j-n)·K(m,n) S(i,j)=(I∗K)(i,j)=m∑n∑I(i−m,j−n)⋅K(m,n)
卷积运算中的卷积核需要进行上下翻转和左右翻转:
S ( i , j ) = [ I ( i − 2 , j − 2 ) I ( i − 2 , j − 1 ) I ( i − 2 , j ) I ( i − 1 , j − 2 ) I ( i − 1 , j − 1 ) I ( i − 1 , j ) I ( i , j − 2 ) I ( i , j − 1 ) I ( i , j ) ] . ∗ [ K ( 2 , 2 ) K ( 2 , 1 ) K ( 2 , 0 ) K ( 1 , 2 ) K ( 1 , 1 ) K ( 1 , 0 ) K ( 0 , 2 ) K ( 0 , 1 ) K ( 0 , 0 ) ] S(i,j)= \begin{bmatrix} I(i-2,j-2) & I(i-2,j-1) & I(i-2,j)\\ I(i-1,j-2) & I(i-1,j-1) & I(i-1,j)\\ I(i,j-2) & I(i,j-1) & I(i,j)\\ \end{bmatrix} .* \begin{bmatrix} K(2,2) & K(2,1) & K(2,0)\\ K(1,2) & K(1,1) & K(1,0)\\ K(0,2) & K(0,1) & K(0,0)\\ \end{bmatrix} S(i,j)= I(i−2,j−2)I(i−1,j−2)I(i,j−2)I(i−2,j−1)I(i−1,j−1)I(i,j−1)I(i−2,j)I(i−1,j)I(i,j) .∗ K(2,2)K(1,2)K(0,2)K(2,1)K(1,1)K(0,1)K(2,0)K(1,0)K(0,0)
如果忽略卷积核的左右翻转,对于实数卷积实际上与互相换运算是一致的:
![]()
- 卷积步长
卷积步长,也就是每次卷积核移动的步长。下图显示了卷积步长分别为1,2两种情况下的输出结果。从中可以看到,当步长大于1之后,相当于从原来的的步长为1的情况下结果进行降采样。
![]()
卷积模式
根据结果是否要求卷积核与原始图像完全重合,部分重合以及结果尺寸的要求,卷积模式包括有三种:
Full:允许卷积核部分与原始图像重合;所获得结果的尺寸等于原始图像尺寸加上卷积核的尺寸减1;
Same:允许卷积核部分与原始图像重合;但最终截取Full卷积结果中中心部分与原始图像尺寸相同的结果;
Validate:所有卷积核与原始图像完全重合下的卷积结果;结果的尺寸等于原始图像的尺寸减去卷积核尺寸加1;
下面显示了三种卷积模式对应的情况。实际上可以通过对于原始图像补零(Padding)然后通过Validate模式获得前面的Full,Same两种模式的卷积结果。
![]()
数据填充
- 边缘填充
数据填充,也称为Padding。如果有一个尺寸为n × n的图像,使用尺寸为m × m卷积核进行卷积操作,在进行卷积之前对于原图像周围填充p层数据,可以影响卷积输出结果尺寸。
下面就是对于原始的图像周围进行1层的填充,可以将Validate模式卷积结果尺寸增加1。

- 膨胀填充
对于数据的填充也可以使用数据上采样填充的方式。这种方式主要应用在转置卷积(反卷积中)。
感受野
感受野:卷积神经网络每一层输出的特征图(featuremap)上的像素点在输 入图片上映射的区域大小,即特征图上的一个点对应输入图上的区域。
下图反映了经过几层卷积之后,卷积结果所对应前几层的图像数据范围。
![]()
计算感受野的大小,可以从后往前逐层计算:
第i层的感受野大小和第i − 1层的卷积核大小、卷积步长有关系,同时也与i − 1层的感受野大小有关系;
假设最后一层(卷积层或者池化层)输出的特征图感受也都大于(相对于其直接输入而言)等于卷积核的大小;
假设最后一层(卷积层或者池化层)输出的特征图感受也都大于(相对于其直接输入而言)等于卷积核的大小;
R F i = R F i − 1 + ( K i − 1 ) × ∏ i = 1 i s i RF_{i}=RF_{i-1} + (K_i-1)\times \prod_{i=1}^i s_i RFi=RFi−1+(Ki−1)×i=1∏isi
公式中:
s i s_i si:第 i i i层步长,Stride
K i K_i Ki:第i层卷积核大小,Kernel Size
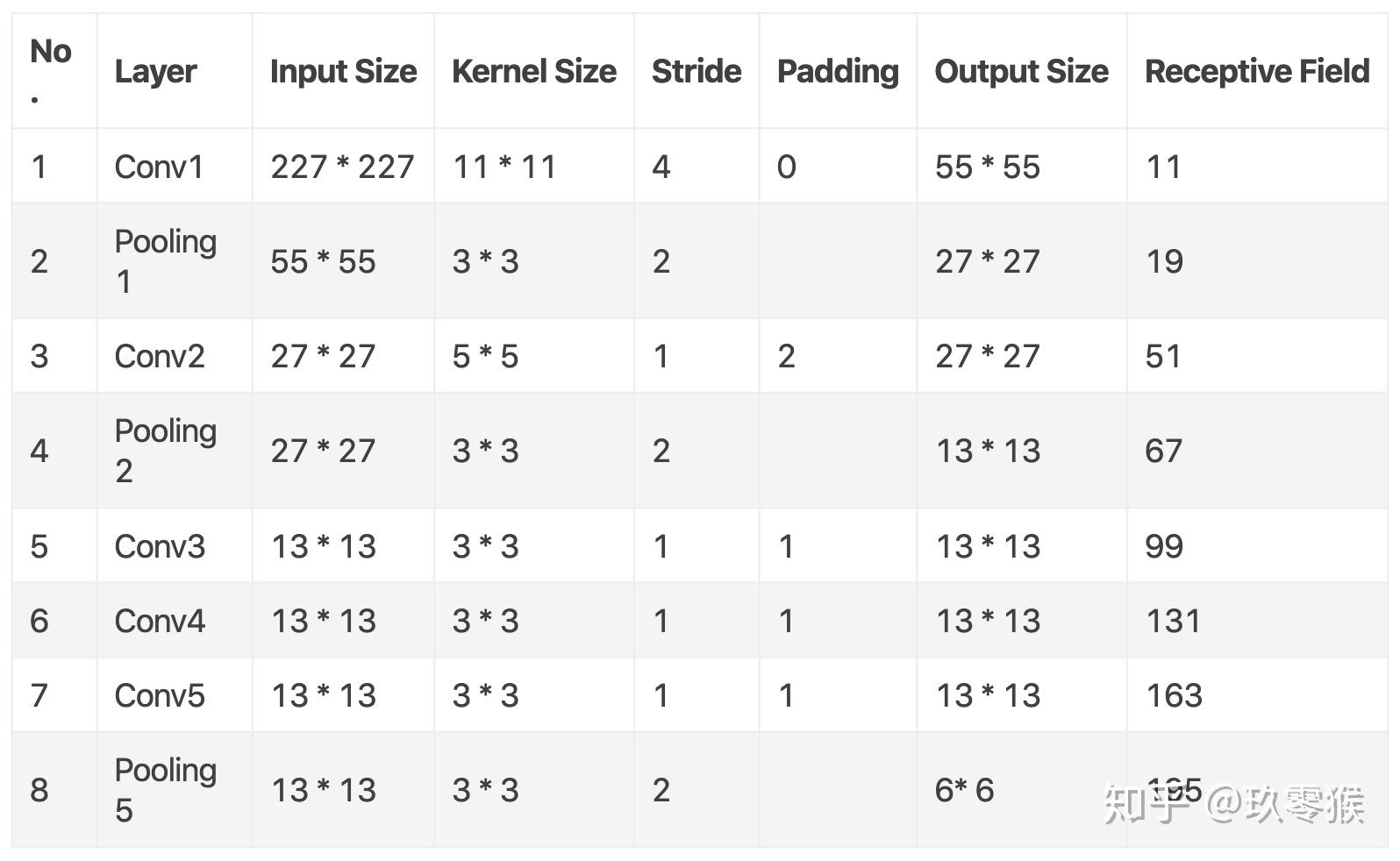
部分计算过程如下:
R a w = 1 C o n v 1 = 1 + ( 11 − 1 ) × 1 = 11 P o o l 1 = 11 + ( 3 − 1 ) × 4 = 19 C o n v 2 = 19 + ( 5 − 1 ) × 4 × 2 = 51 Raw=1 \\ Conv1=1+(11-1) \times1=11 \\ Pool1=11+(3-1) \times 4=19 \\ Conv2=19+(5-1) \times 4 \times 2=51 Raw=1Conv1=1+(11−1)×1=11Pool1=11+(3−1)×4=19Conv2=19+(5−1)×4×2=51
感受野的大小除了与卷积核的尺寸、卷积层数,还取决与卷积是否采用空洞卷积(Dilated Convolve)有关系:
![]()
- 卷积深度
卷积层的深度(卷积核个数):一个卷积层通常包含多个尺寸一致的卷积核。如果在CNN网络结构中,一层的卷积核的个数决定了后面结果的层数,也是结果的厚度。
![]()
- 卷积核尺寸
卷积核的大小一般为奇数奇数 1×1,3×3,5×5,7×7都是最常见的。这是为什么呢?为什么没有偶数偶数?
(1)更容易padding
在卷积时,我们有时候需要卷积前后的尺寸不变。这时候我们就需要用到padding。假设图像的大小,也就是被卷积对象的大小为n × n,卷积核大小为k × k,padding的幅度设为( k − 1 ) / 2 时,卷积后的输出就为n − k + 2 × k − 1/2 + 1 = n,即卷积输出为n × n,保证了卷积前后尺寸不变。但是如果k是偶数的话,( k − 1 ) / 2就不是整数了。
(2)更容易找到卷积锚点
在CNN中,进行卷积操作时一般会以卷积核模块的一个位置为基准进行滑动,这个基准通常就是卷积核模块的中心。若卷积核为奇数,卷积锚点很好找,自然就是卷积模块中心,但如果卷积核是偶数,这时候就没有办法确定了,让谁是锚点似乎都不怎么好。
![]()
激活函数
激活函数是用来加入非线性因素,提高网络表达能力,卷积神经网络中最常用的是ReLU(修正线性单元,Rectified Lineat Unit),Sigmoid使用较少。
![]()
![]()
1、ReLU函数
f ( x ) = { 0 , x < 0 x , x ≥ 0 f(x)=\left\{ \begin{aligned} 0,x<0 \\ x,x \geq 0 \end{aligned} \right. f(x)={0,x<0x,x≥0
ReLU函数的优点:
- 计算速度快,ReLU函数只有线性关系,比Sigmoid和Tanh要快很多
- 输入为正数的时候,不存在梯度消失问题
ReLU函数的缺点:
- 强制性把负值置为0,可能丢掉一些特征
- 当输入为负数时,权重无法更新,导致“神经元死亡”(学习率不 要太大)
2、Parametric ReLU
f ( x ) = { α x , x < 0 x , x ≥ 0 f(x)=\left\{ \begin{aligned} \alpha x,x<0 \\ x,x \geq 0 \end{aligned} \right. f(x)={αx,x<0x,x≥0
- 当 α = 0.01 \alpha = 0.01 α=0.01的时候,称为 Leaky ReLU;
- 当 α α α从高斯分布随机产生的时候,称为 Randomized ReLU(RReLU)
PReLU函数的优点:
- 比sigmoid/tanh收敛快;
- 解决了ReLU的“神经元死亡”问题;
PReLU函数的缺点:
- 需要再学习一个参数,工作量变大
3、ELU函数
f ( x ) = { α ( e x − 1 ) , x < 0 x , x ≥ 0 f(x)=\left\{ \begin{aligned} \alpha (e^x-1),x<0 \\ x,x \geq 0 \end{aligned} \right. f(x)={α(ex−1),x<0x,x≥0
ELU函数的优点:
- 处理含有噪声的数据有优势
- 更容易收敛
ELU函数的缺点:
- 计算量较大,收敛速度较慢
CNN在卷积层尽量不要使用Sigmoid和Tanh,将导致梯度消失。首先选用ReLU,使用较小的学习率,以免造成神经元死亡的情况。
如果ReLU失效,考虑使用Leaky ReLU、PReLU、ELU或者Maxout,此时一般情况都可以解决
4、特征图
- 浅层卷积层:提取的是图像基本特征,如边缘、方向和纹理等特征
- 深层卷积层:提取的是图像高阶特征,出现了高层语义模式,如“车轮”、“人脸”等特征
池化层
池化操作使用某位置相邻输出的总体统计特征作为该位置的输出,常用最大池化 (max-pooling)和均值池化(average- pooling) 。池化层不包含需要训练学习的参数,仅需指定池化操作的核大小、操作步幅以及池化类型。
![]()
池化的作用:
- 减少网络中的参数计算量,从而遏制过拟合;
- 增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微 小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/ 平均值)
- 帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为 这样我们就可以探测到图片里的物体,不管它在哪个位置
全连接与输出层
对卷积层和池化层输出的特征图(二维)进行降维
将学到的特征表示映射到样本标记空间的作用
输出层:
- 对于分类问题采用Softmax函数:
y i = e z i ∑ i = 1 n e z i y_i=\frac{e^{z_i}}{\sum_{i=1}^n e^{z_i}} yi=∑i=1neziezi
- 对于回归问题,使用线性函数:
y i = ∑ m = 1 M w i m x m y_i=\sum_{m=1}^{M}w_{im}x_m yi=m=1∑Mwimxm
CNN训练过程
1、网络训练基本步骤
CNN的训练,也称神经网络的学习算法与经典BP网络是一样的,都属于随机梯度下降(SGD:Stochastic Gradient Descent),也称增量梯度下降,实验中用于优化可微分目标函数的迭代算法。
- Step 1:用随机数初始化所有的卷积核和参数/权重
- Step 2:将训练图片作为输入,执行前向步骤(卷积, ReLU,池化以及全连接层的前向传播)并计算每个类别的对应输出概率。
- Step 3:计算输出层的总误差
- Step 4:反向传播算法计算误差相对于所有权重的梯度,并用梯度下降法更新所有的卷积核和参数/权重的值,以使输出误差最小化
注:卷积核个数、卷积核尺寸、网络架构这些参数,是在 Step 1 之前就已经固定的,且不会在训练过程中改变——只有卷 积核矩阵和神经元权重会更新。
2、网络等效为BP网络
和多层神经网络一样,卷积神经网络中的参数训练也是使用误差反向传播算法,关于池化层的训练,需要再提一下,是将池化层改为多层神经网络的形式:
![]()
![]()
![]()
3、每层特征图尺寸
- 输入图片的尺寸:一般用n×n表示输入的image大小。
- 卷积核的大小:一般用 f*f 表示卷积核的大小。
- 填充(Padding):一般用 p 来表示填充大小。
- 步长(Stride):一般用 s 来表示步长大小。
- 输出图片的尺寸:一般用 o来表示。
- 如果已知n 、 f 、 p、 s 可以求得 o ,计算公式如下:
O = [ n + 2 p − f s ] + 1 O=[\frac{n+2p-f}{s}]+1 O=[sn+2p−f]+1
其中:[]:是向下取整符号,用于结果不是整数时向下取整。
CNN优缺点
①CNN优点
1)共享卷积核,处理高维数据无压力;
2)可以自动进行特征提取,卷积层可以提取特征, 卷积层中的卷积核(滤波器)真正发挥作用,通过卷积提取需要的特征 (详细解释参考牛人博文 https://blog.csdn.net/bobo_jiang/article/details/79080561)
②CNN缺点
1)当网络层次太深时,采用BP传播修改参数会使靠近输入层的参数改动较慢;
2)采用梯度下降算法很容易使训练结果收敛于局部最小值而非全局最小值;
3)池化层会丢失大量有价值信息,忽略局部与整体之间关联性;
4)由于特征提取的封装,为网络性能的改进罩了一层黑盒
CNN代码实现(手写字母识别)
(原文链接:https://blog.csdn.net/weixin_38468077/article/details/106592690)
下面我将会以一个手写字母识别的例子来入门CNN吧。MNIST 数据集来自美国国家标准与技术研究所。 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.其图片形式如下所示:
![]()
# @Time : 2020/6/6 13:23
# @Author : kingback
# @File : cnn_test.py
# @Software: PyCharmimport torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt#Hyper prameters
EPOCH=1
BATCH_SIZE=50
LR=0.001
DOWNLOAD_MNIST=Falsetrain_data=torchvision.datasets.MNIST(root='./mnist',train=True,transform=torchvision.transforms.ToTensor(), #将下载的文件转换成pytorch认识的tensor类型,且将图片的数值大小从(0-255)归一化到(0-1)download=DOWNLOAD_MNIST
)#画一个图片显示出来
# print(train_data.data.size())
# print(train_data.targets.size())
# plt.imshow(train_data.data[0].numpy(),cmap='gray')
# plt.title('%i'%train_data.targets[0])
# plt.show()train_loader=Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)test_data=torchvision.datasets.MNIST(root='./mnist',train=False,
)
with torch.no_grad():test_x=Variable(torch.unsqueeze(test_data.data, dim=1)).type(torch.FloatTensor)[:2000]/255 #只取前两千个数据吧,差不多已经够用了,然后将其归一化。test_y=test_data.targets[:2000]'''开始建立CNN网络'''
class CNN(nn.Module):def __init__(self):super(CNN,self).__init__()'''一般来说,卷积网络包括以下内容:1.卷积层2.神经网络3.池化层'''self.conv1=nn.Sequential(nn.Conv2d( #--> (1,28,28)in_channels=1, #传入的图片是几层的,灰色为1层,RGB为三层out_channels=16, #输出的图片是几层kernel_size=5, #代表扫描的区域点为5*5stride=1, #就是每隔多少步跳一下padding=2, #边框补全,其计算公式=(kernel_size-1)/2=(5-1)/2=2), # 2d代表二维卷积 --> (16,28,28)nn.ReLU(), #非线性激活层nn.MaxPool2d(kernel_size=2), #设定这里的扫描区域为2*2,且取出该2*2中的最大值 --> (16,14,14))self.conv2=nn.Sequential(nn.Conv2d( # --> (16,14,14)in_channels=16, #这里的输入是上层的输出为16层out_channels=32, #在这里我们需要将其输出为32层kernel_size=5, #代表扫描的区域点为5*5stride=1, #就是每隔多少步跳一下padding=2, #边框补全,其计算公式=(kernel_size-1)/2=(5-1)/2=), # --> (32,14,14)nn.ReLU(),nn.MaxPool2d(kernel_size=2), #设定这里的扫描区域为2*2,且取出该2*2中的最大值 --> (32,7,7),这里是三维数据)self.out=nn.Linear(32*7*7,10) #注意一下这里的数据是二维的数据def forward(self,x):x=self.conv1(x)x=self.conv2(x) #(batch,32,7,7)#然后接下来进行一下扩展展平的操作,将三维数据转为二维的数据x=x.view(x.size(0),-1) #(batch ,32 * 7 * 7)output=self.out(x)return outputcnn=CNN()
# print(cnn)# 添加优化方法
optimizer=torch.optim.Adam(cnn.parameters(),lr=LR)
# 指定损失函数使用交叉信息熵
loss_fn=nn.CrossEntropyLoss()'''
开始训练我们的模型哦
'''
step=0
for epoch in range(EPOCH):#加载训练数据for step,data in enumerate(train_loader):x,y=data#分别得到训练数据的x和y的取值b_x=Variable(x)b_y=Variable(y)output=cnn(b_x) #调用模型预测loss=loss_fn(output,b_y)#计算损失值optimizer.zero_grad() #每一次循环之前,将梯度清零loss.backward() #反向传播optimizer.step() #梯度下降#每执行50次,输出一下当前epoch、loss、accuracyif (step%50==0):#计算一下模型预测正确率test_output=cnn(test_x)y_pred=torch.max(test_output,1)[1].data.squeeze()accuracy=sum(y_pred==test_y).item()/test_y.size(0)print('now epoch : ', epoch, ' | loss : %.4f ' % loss.item(), ' | accuracy : ' , accuracy)'''
打印十个测试集的结果
'''
test_output=cnn(test_x[:10])
y_pred=torch.max(test_output,1)[1].data.squeeze() #选取最大可能的数值所在的位置
print(y_pred.tolist(),'predecton Result')
print(test_y[:10].tolist(),'Real Result')
经典CNN
(我理解就是基于CNN,构建的更大的网络,经典的CNN网络)
CNN发展脉络:
![]()
LeNet-5
1、简介
LeNet-5由LeCun等人提出于1998年提出,主要进行手写数字识别和英文字母识别。经典的卷积神经网络,LeNet虽小,各模块齐全,是学习 CNN的基础。
参考:http://yann.lecun.com/exdb/lenet/
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, November 1998.
2、网络结构
![]()
- 输入层:32 × 32 的图片,也就是相当于1024个神经元;
- C1层(卷积层):选择6个 5 × 5 的卷积核,得到6个大小为32-5+1=28的特征图,也就是神经元的个数为 6 × 28 × 28 = 4704;
- S2层(下采样层):每个下抽样节点的4个输入节点求和后取平均(平均池化),均值 乘上一个权重参数加上一个偏置参数作为激活函数的输入,激活函数的输出即是下一层节点的值。池化核大小选择 2 ∗ 2 得到6个 14 ×14大小特征图
- C3层(卷积层):用 5 × 5 的卷积核对S2层输出的特征图进行卷积后,得到6张10 × 10新 图片,然后将这6张图片相加在一起,然后加一个偏置项b,然后用 激活函数进行映射,就可以得到1张 10 × 10 的特征图。我们希望得到 16 张 10 × 10 的 特 征 图 , 因 此 我 们 就 需 要 参 数 个 数 为 16 × ( 6 × ( 5 × 5 ) ) 个参数
- S4层(下采样层):对C3的16张 10 × 10 特征图进行最大池化,池化核大小为2 × 2,得到16张大小为 5 × 5的特征图。神经元个数已经减少为:16 × 5 × 5 =400
- C5层(卷积层):用 5 × 5 的卷积核进行卷积,然后我们希望得到120个特征图,特征图 大小为5-5+1=1。神经元个数为120(这里实际上是全连接,但是原文还是称之为了卷积层)
- F6层(全连接层):有84个节点,该层的训练参数和连接数都( 120 + 1 ) × 84 = 10164
- Output层:共有10个节点,分别代表数字0到9,如果节点i的输出值为0,则网络识别的结果是数字i。采用的是径向基函数(RBF)的网络连接方式:
y i = ∑ j ( x − j − w i j ) 2 y_i = \sum_ j ( x − j − w_{i j} ) ^2 yi=j∑(x−j−wij)2
- 总结:卷积核大小、卷积核个数(特征图需要多少个)、池化核大小(采样率多少)这些参数都是变化的,这就是所谓的CNN调参,需要学会根据需要进行不同的选择。
AlexNet
1、简介
AlexNet由Hinton的学生Alex Krizhevsky于2012年提出,获得ImageNet LSVRC-2012(物体识别挑战赛)的冠军,1000个类别120万幅高清图像(Error: 26.2%(2011) →15.3%(2012)),通过AlexNet确定了CNN在计算机视觉领域的王者地位。
参考:A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
- 首次成功应用ReLU作为CNN的激活函数
- 使用Dropout丢弃部分神元,避免了过拟合
- 使用重叠MaxPooling(让池化层的步长小于池化核的大小), 一定程度上提升了特征的丰富性
- 使用CUDA加速训练过程
- 进行数据增强,原始图像大小为256×256的原始图像中重 复截取224×224大小的区域,大幅增加了数据量,大大减 轻了过拟合,提升了模型的泛化能力
2、网络结构
AlexNet可分为8层(池化层未单独算作一层),包括5个卷 积层以及3个全连接层:
![]()
- 输入层:AlexNet首先使用大小为224×224×3图像作为输入(后改为227×227×3) (227-11+2*0)/4+1=55
- 第一层(卷积层):包含96个大小为11×11的卷积核,卷积步长为4,因此第一层输出大小为55×55×96;然后构建一个核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为27×27×96
- 第二层(卷积层):包含256个大小为5×5卷积核,卷积步长为1,同时利用padding保证 输出尺寸不变,因此该层输出大小为27×27×256;然后再次通过 核大小为3×3、步长为2的最大池化层进行数据降采样,进而输出大小为13×13×256
- 第三层与第四层(卷积层):均为卷积核大小为3×3、步长为1的same卷积,共包含384个卷积核,因此两层的输出大小为13×13×384
- 第五层(卷积层):同样为卷积核大小为3×3、步长为1的same卷积,但包含256个卷积 核,进而输出大小为13×13×256;在数据进入全连接层之前再次 通过一个核大小为3×3、步长为2的最大池化层进行数据降采样, 数据大小降为6×6×256,并将数据扁平化处理展开为9216个单元
- 第六层、第七层和第八层(全连接层):全连接加上Softmax分类器输出1000类的分类结果,有将近6千万个参数
VGGNet
1、简介
VGGNet由牛津大学和DeepMind公司提出:
- Visual Geometry Group:https://www.robots.ox.ac.uk/~vgg/
- DeepMind:https://deepmind.com/
参考:K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
比较常用的是VGG-16,结构规整,具有很强的拓展性。相较于AlexNet,VGG-16网络模型中的卷积层均使用 3 ∗ 3 333∗3 的 卷积核,且均为步长为1的same卷积,池化层均使用 2 ∗ 2 222∗2 的 池化核,步长为2。
2、网络结构
![]()
- 两个卷积核大小为 3 ∗ 3 333∗3 的卷积层串联后的感受野尺寸为 5 ∗ 5 555∗5, 相当于单个卷积核大小为 5 ∗ 5 5*55∗5 的卷积层
- 两者参数数量比值为( 2 ∗ 3 ∗ 3 ) / ( 5 ∗ 5 ) = 72 % (233)/(5*5)=72%(2∗3∗3)/(5∗5)=72% ,前者参数量更少
- 此外,两个的卷积层串联可使用两次ReLU激活函数,而一个卷积层只使用一次
Inception Net
1、简介
Inception Net 是Google公司2014年提出,获得ImageNet LSVRC-2014冠军。文章提出获得高质量模型最保险的做法就是增加模型的深度(层数)或者是其宽度(层核或者神经元数),采用了22层网络。
Inception四个版本所对应的论文及ILSVRC中的Top-5错误率:
- Going Deeper with Convolutions: 6.67%
- Batch Normalization: Accelerating Deep Network Training by
- Reducing Internal Covariate Shift: 4.8%
- RethinkingtheInceptionArchitectureforComputerVision:3.5%
- Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning: 3.08%
2、网络结构
Inception Module
深度:层数更深,采用了22层,在不同深度处增加了两个 loss来避免上述提到的梯度消失问题
宽度
:Inception Module包含4个分支,在卷积核3x3、5x5 之前、max pooling之后分别加上了1x1的卷积核,起到了降低特征图厚度的作用
- 1×1的卷积的作用:可以跨通道组织信息,来提高网络的表达能力;可以对输出通道进行升维和降维。
![]()
ResNet
1、简介
ResNet(Residual Neural Network),又叫做残差神经网络,是由微软研究院的何凯明等人2015年提出,获得ImageNet ILSVRC 2015比赛冠军,获得CVPR2016最佳论文奖。
随着卷积网络层数的增加,误差的逆传播过程中存在的梯 度消失和梯度爆炸问题同样也会导致模型的训练难以进行,甚至会出现随着网络深度的加深,模型在训练集上的训练误差会出现先降低再升高的现象。残差网络的引入则有助于解决梯度消失和梯度爆炸问题。
残差块:
ResNet的核心是叫做残差块(Residual block)的小单元, 残差块可以视作在标准神经网络基础上加入了跳跃连接(Skip connection)。
原连接:
跳跃连接:
![]()
- Skip connection作用:
记:
![]()
我们有:
![]()
Densenet
1、简介
DenseNet中,两个层之间都有直接的连接,因此该网络的直接连接个数为L(L+1)/2。
对于每一层,使用前面所有层的特征映射作为输入,并且使用其自身的特征映射作为所有后续层的输入:
![]()
参考:Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700- 4708).
2、网络结构
5层的稠密块示意图:
![]()
DenseNets可以自然地扩展到数百个层,而没有表现出优化困难。在实验中,DenseNets随着参数数量的增加,在精度上产生一致的提高,而没有任何性能下降或过拟合的迹象。
优点:
- 缓解了消失梯度问题
- 加强了特征传播,鼓励特征重用
- 一定程度上减少了参数的数量
CNN:卷积神经网络相关推荐
- 3层-CNN卷积神经网络预测MNIST数字
3层-CNN卷积神经网络预测MNIST数字 本文创建一个简单的三层卷积网络来预测 MNIST 数字.这个深层网络由两个带有 ReLU 和 maxpool 的卷积层以及两个全连接层组成. MNIST 由 ...
- 深度学习--TensorFlow(项目)识别自己的手写数字(基于CNN卷积神经网络)
目录 基础理论 一.训练CNN卷积神经网络 1.载入数据 2.改变数据维度 3.归一化 4.独热编码 5.搭建CNN卷积神经网络 5-1.第一层:第一个卷积层 5-2.第二层:第二个卷积层 5-3.扁 ...
- plt保存图片_人工智能Keras CNN卷积神经网络的图片识别模型训练
CNN卷积神经网络是人工智能的开端,CNN卷积神经网络让计算机能够认识图片,文字,甚至音频与视频.CNN卷积神经网络的基础知识,可以参考:CNN卷积神经网络 LetNet体系结构是卷积神经网络的&qu ...
- DeepLearning tutorial(4)CNN卷积神经网络原理简介+代码详解
FROM: http://blog.csdn.net/u012162613/article/details/43225445 DeepLearning tutorial(4)CNN卷积神经网络原理简介 ...
- Deep Learning论文笔记之(五)CNN卷积神经网络代码理解
Deep Learning论文笔记之(五)CNN卷积神经网络代码理解 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- DL之CNN:关于CNN(卷积神经网络)经典论文原文(1950~2018)简介总结框架结构图(非常有价值)之持续更新(吐血整理)
DL之CNN:关于CNN(卷积神经网络)经典论文原文(1950~2018)简介总结框架结构图(非常有价值)之持续更新(吐血整理) 导读 关于CNN,迄今为止已经提出了各种网络结构.其中特别 ...
- CNN卷积神经网络:权值更新公式推导
版权声明:本文为博主原创文章,转载请注明出处. https://blog.csdn.net/happyer88/article/details/46772347 在上篇<CNN卷积神经网络学习笔 ...
- cnn卷积神经网络_5分钟内卷积神经网络(CNN)
cnn卷积神经网络 Convolutional neural networks (CNNs) are the most popular machine leaning models for image ...
- cnn图像二分类 python_人工智能Keras图像分类器(CNN卷积神经网络的图片识别篇)...
上期文章我们分享了人工智能Keras图像分类器(CNN卷积神经网络的图片识别的训练模型),本期我们使用预训练模型对图片进行识别:Keras CNN卷积神经网络模型训练 导入第三方库 from kera ...
最新文章
- poj1068解题报告(模拟类)
- 关于汇编跟C/C++已经java的内存理解
- c语言斐波那契数列_视频丨神奇的斐波那契数列科学性与艺术性
- 网络 IPC 套接字socket
- 2020知道python语言应用答案_2020知到Python语言应用答案章节期末答案
- 适合 Python 入门的 8 款强大工具,赶紧收藏一波!
- GBDT(梯度提升决策树)总结笔记
- java 基础知识面试题(持续更新),java基础面试笔试题
- HAproxy + keepalived 实现双机热备
- 【干货】房地产基础知识及开发流程.pdf(附下载链接)
- RSA加密算法【手把手解释】
- 人工智能如何改变农业?这是五大类创业公司全图
- word20161210
- JVM监控及诊断工具GUI篇之Arthas(五):其他指令
- erp系统用MySQL吗_如何给ERP系统选择合适的数据库?
- 数据结构-树-愿天下有情人都是失散多年的兄妹
- 嵌入式系统开发笔记19:CJ/T-188 冷热量表协议解析8
- POI设置excel格式为文本格式
- 从文本生成场景图(1)——SPICE:Semantic Propositional Image Caption Evaluation
- 跟着小马哥学习Spring(1)