[Python]profile优化实践(基于A*算法) 1
本文由恋花蝶发表于http://blog.csdn.net/lanphaday
欢迎转载,但敬请保留全文完整,并包含本声明.
[Python]profile优化实践(基于A*算法)
在《用profile协助程序性能优化》一文中,我们学习了python用以协助性能优化的模块——profile/hotshot/timeit等,但缺少一个实例来让我们动手尝试,今天我拿以前写的A*算法的python实现来开刀,临床实验。
实验用的代码可以从我以前发在blog上的文章《基本A*算法python实现》(http://blog.csdn.net/lanphaday/archive/2006/10/11/1329956.aspx)里找到,你可以从那里了解或者重温一下A*算法;不过为了使用profile,我做了一些小小的改动,所以建议你从这里(暂未能提供)下载本文相关的所有示例代码(已将每一次改进保存到独立的.py文件)以及profile的输出文档。
下面,让我们开始吧!
得来全不费功夫
定位热点
拿到代码后,可以看到代码的入口如下:
|
if __name__ == "__main__": import profile, pstats profile.run("main()", "astar_prof.txt") p = pstats.Stats("astar_prof.txt") p.strip_dirs().sort_stats("time").print_stats(10) |
代码段1
profile.run执行main()函数,并把输出保存到astar_prof.txt,pstats.Stats的实例p把统计结果以”time”为key排序后打印出前10条。执行一下,输出结果如下:
|
62468 function calls in 1.258 CPU seconds Ordered by: internal time List reduced from 27 to 10 due to restriction <10> ncalls tottime percall cumtime percall filename:lineno(function) 5713 0.581 0.000 0.581 0.000 origine.py:156(node_in_close) 33818 0.208 0.000 0.208 0.000 origine.py:111(get_dist) 778 0.178 0.000 0.387 0.000 origine.py:99(get_best) 778 0.150 0.000 0.851 0.001 origine.py:119(extend_round) 2933 0.048 0.000 0.048 0.000 origine.py:162(node_in_open) 6224 0.028 0.000 0.028 0.000 origine.py:168(is_valid_coord) 5714 0.022 0.000 0.022 0.000 origine.py:46(__init__) 5713 0.021 0.000 0.021 0.000 origine.py:148(get_cost) 1 0.016 0.016 1.256 1.256 origine.py:71(find_path) 778 0.003 0.000 0.003 0.000 origine.py:96(is_target) |
输出1
其中node_in_close()函数用以检测可扩展的节点是否在close表中,这个简单的函数占用了46%的运行时间,差不多是排第二的get_dist()函数的三倍,我们的优化显然应该从node_in_colse()入手。优化一个函数,第一个方法应该是减少它的调用次数,然后才是优化这个函数本身,所以我们先在“代码段1”后面加入一条语句,用以查看哪个函数调用了node_in_close():
p.print_callers("node_in_close")
输出结果如下:
|
Ordered by: internal time List reduced from 27 to 1 due to restriction <'node_in_close'> Function was called by... origine.py:156(node_in_close) origine.py:119(extend_round)(5713) 0.851 |
输出2
我们看到只有extend_round函数调用了node_in_close(),看起来情况相当简明,extend_round()函数用以扩展搜索空间,有关node_in_close的代码段如下:
|
#构造新的节点 node = Node_Elem(p, new_x, new_y, p.dist+self.get_cost( p.x, p.y, new_x, new_y)) #新节点在关闭列表,则忽略 if self.node_in_close(node): continue |
代码段2
从“代码段2”可以看到根据A*算法我们必然要检测node是否在close表中,所以无法在extend_round()中减少对node_in_close()函数的调用了。那我们只好在node_in_close()函数里找突破口:
|
def node_in_close(self, node): for i in self.close: if node.x == i.x and node.y == i.y: return True return False |
代码段3
马上可以看出这是一个对list的线性查找,在close表变得很大的时候,这种复杂度为O(N)的线性算法是相当耗时的,如果能转化为O(logN)的算法那就能节省不少时间了。O(logN)的查找算法基于两个数据结构,一个是有序表,另一个是二叉查找树。显然,对于频繁插入而不删除元素的list保持有序的代价非常大,使用查找树是我们更好的选择。
修改代码
在程序里加入二叉查找树支持非常简单,python2.3开始增加了sets模块,提供了以RB_tree为底层数据结构的Set类:
from sets import Set as set
然后在把close表初始化为一个空set
self.close = set()
把self.close.append(p)语句替换为:
self.close.add(p)
最关键的是重写node_in_close()函数为:
|
def node_in_close(self, node): return node in self.close |
代码段4
简简单单就可以了,但这时候程序还不能运行,因为原来的Node_Elem类并不支持__hash__和__eq__函数,这样set就无法构造也无法查找元素了,所以最后一步是为Node_Elem增加这两个函数:
|
class Node_Elem: def __init__(self, parent, x, y, dist): # …略 self.hv = (x << 16) ^ y def __eq__(self, other): return self.hv == other.hv def __hash__(self): return self.hv |
代码段5
在构造函数中,我们加了一句self.hv=(x<<8)^y来计算一个Node_Elem元素的hash值,因为坐标相同的两个节点我们认为是相等的且坐标数值不会很大,所以这个hash函数可以保证不会产生冲突。大功告成之后我们运行一下看看:
|
78230 function calls in 0.845 CPU seconds Ordered by: internal time List reduced from 33 to 10 due to restriction <10> ncalls tottime percall cumtime percall filename:lineno(function) 33818 0.205 0.000 0.205 0.000 astar.py:120(get_dist) 778 0.179 0.000 0.383 0.000 astar.py:108(get_best) 778 0.150 0.000 0.426 0.001 astar.py:128(extend_round) 5713 0.068 0.000 0.097 0.000 sets.py:292(__contains__) 5713 0.052 0.000 0.149 0.000 astar.py:165(node_in_close) 2933 0.050 0.000 0.050 0.000 astar.py:172(node_in_open) 6224 0.028 0.000 0.028 0.000 astar.py:178(is_valid_coord) 5714 0.028 0.000 0.028 0.000 astar.py:48(__init__) 6490 0.021 0.000 0.021 0.000 astar.py:58(__hash__) 5713 0.021 0.000 0.021 0.000 astar.py:157(get_cost) |
输出3
我们可以看到,总的运行时间已经从1.258s下降到0.845s,而且node_in_close函数占用的时间已经相当少,不过因为node_in_close只在一个地方被调用,而且函数体本身就非常简单,那么我们可以去掉这个函数,直接在extend_round里进行判断,可以省下几千次函数调用的时间。
在这一步优化里,我们可以看到使用合适的数据结构可以增进数十倍的性能(使用list用时0.581s,使用set用时0.052s),随着地图的增大,这个比例将会更大。而profile也在这一个小节里初显身手,下一步又该怎么样去优化呢?
柳暗花明又一村
定位热点
从上节的“输出3”我们可以看到现在占用时间最多的就是get_dist()函数了,get_dist()函数用以估算从起点到终点经过节点i的路径的距离,使用的公式是:
F = G + H
其中G为从起始点到节点i已经走过的距离,这是已经计算好的数值,对应于i.dist;H是从节点i到终点的距离的预计值,即A*算法的启发值,在这里简单地通过两点间的距离公式(距离乘以放大系数1.2)来估计,代码如下:
|
def get_dist(self, i): return i.dist + math.sqrt( (self.e_x-i.x)*(self.e_x-i.x) + (self.e_y-i.y)*(self.e_y-i.y))*1.2 |
代码6
很短的代码,我们根据经验一眼就看出math.sqrt()函数调用肯定占用了大部分时间,但到底有多少,我们就很难说得上来了,这时候我就可以借助小巧的timeit模块来计算一下math.sqrt()函数的代价。在Python脚释器中执行下面的语句:
|
>>> import timeit >>> t = timeit.Timer("math.sqrt(0.99)","import math") >>> t.timeit(33818) 0.016204852851409886 |
执行33818次math.sqrt()不过用时0.016s,仅仅占get_dist()总用时0.205s的不到10%,事实证明经验并不可靠,我们要的是小心求证的精神和熟练地使用工具。像外行一样思考,像专家一样实践——堪称我们程序员的行动纲领。
如果get_dist()最耗时的部分并不是math.sqrt()的调用,那什么会是什么呢?乘法?”.”操作符?这些我们很难确定,那么试图从get_dist()函数内部进行优化就显得没有根据了。这时可以猜测能否减少get_dist()的调用呢?看看谁调用了get_dist():
|
Ordered by: internal time List reduced from 32 to 1 due to restriction <'get_dist'> Function was called by... astar.py:120(get_dist) astar.py:108(get_best)(33818) 0.400 |
输出4
看看唯一的调用了get_dist()的函数get_best(),我们心里不由地涌起似曾相识的感觉:
|
def get_best(self): best = None bv = 1000000 #如果你修改的地图很大,可能需要修改这个值 bi = -1 for idx, i in enumerate(self.open): value = self.get_dist(i)#获取F值 if value < bv:#比以前的更好,即F值更小 best = i bv = value bi = idx return bi, best |
代码段7
又是一个O(N)的线性遍历!真是柳暗花明又一村,我们完全可以故伎重演嘛!事不宜迟,马上动手!
修改代码
还是把open表从list改为set吗?别被习惯套住了思路!在A*算法中,对open表最多的操作是从open表中取一个F值最小的节点,即get_best()函数的功用。set并没有提供快速获取最小值的接口,从set取得最小值仍然需要进行O(N)复杂度的线性遍历,这表明set并不是最好的存储open表的数据结构。还记得什么数据结构具有O(1)复杂度获取最小/最大值吗?对,就是堆!python对通过heapq模块对堆这种数据结构提供了良好的支持,heapq实现的是小顶堆,这就更适合A*算法了。
首先导入heapq模块的API
from heapq import heappop,heappush
不再调用get_best()函数,直接使用heappop() API取得最小值
#获取F值最小的节点
#bi, bn = self.get_best()
p = heappop(self.open)
把extend_round函数里的self.open.append(node)替换为heappush(self.open, node)
这时候因为不再调用get_best()函数,所以我们可以把get_best()和get_dist()函数删除,同时为了使Node_Elem类型的节点能够计算F值和比较大小,我们需要对Node_Elem的实现作一些改变:
|
class Node_Elem: def __init__(self, parent, x, y, ex, ey, dist): # …略 self.dist2end = math.sqrt((ex-x)*(ex-x)+(ey-y)*(ey-y))*1.2 def __le__(self, other): return self.dist+self.dist2end <= other.dist+other.dist2end |
代码段8
1、构造函数增加了两个参数ex,ey用以在构造实例时即计算从x,y到终点的估计距离,这可以减少math.sqrt()的调用;2、重载__le__()函数,用以实现Node_Elem实例间的大小比较。运行程序,可以发现找到的路径变得比较曲折,不过实事上路径的长度与原来是一样的而且搜索过的节点数目/位置都是一样的;路径不同的原因在于heap存储/替换节点的策略与直接用list有所不同罢了。profile输出的结果是:
|
47823 function calls in 0.561 CPU seconds Ordered by: internal time List reduced from 35 to 10 due to restriction <10> ncalls tottime percall cumtime percall filename:lineno(function) 778 0.178 0.000 0.459 0.001 astar.py:120(extend_round) 5713 0.071 0.000 0.101 0.000 sets.py:292(__contains__) 5714 0.053 0.000 0.053 0.000 astar.py:48(__init__) 2933 0.047 0.000 0.047 0.000 astar.py:157(node_in_open) 778 0.031 0.000 0.059 0.000 heapq.py:226(_siftup) 6224 0.029 0.000 0.029 0.000 astar.py:163(is_valid_coord) 1624 0.025 0.000 0.035 0.000 heapq.py:174(_siftdown) 5876 0.024 0.000 0.024 0.000 astar.py:64(__le__) 6490 0.021 0.000 0.021 0.000 astar.py:60(__hash__) 5713 0.021 0.000 0.021 0.000 astar.py:149(get_cost) |
输出5
我们可以看到总的运行时间已经下降到0.561s,仅为之前的运行时间(0.845s)的三分之二,这真是鼓舞人心的结果。
常恨春归无觅处
从“输出5”可以看出现在的热点是extend_round(),我们马上可以动手吗?不,extend_round比刚才优化掉的node_in_close()/get_best()之类的函数复杂太多了:循环中又分支,分支中还有分支,调用了近十个函数,而且从“输出5”可以得出extend_round()运行的时间大部分被它调用的外部函数占用了,真是错踪复杂。要想从一个这么复杂的函数中找出真正的热点,我们可以借助pstats.Stats.print_callees()函数输出extend_round()函数调用,在代码中增加:
p.print_callees("extend_round")
运行可以得到如下输出:
|
Ordered by: internal time List reduced from 35 to 1 due to restriction <'extend_round'> Function called... astar.py:120(extend_round) astar.py:48(__init__)(5713) 0.053 astar.py:149(get_cost)(5713) 0.021 astar.py:157(node_in_open)(2933) 0.047 astar.py:163(is_valid_coord)(6224) 0.029 heapq.py:131(heappush)(846) 0.030 sets.py:292(__contains__)(5713) 0.101 |
输出6
这样看起来仍然不够明朗,我们可以借助MS Excel构造一个图表,如下:
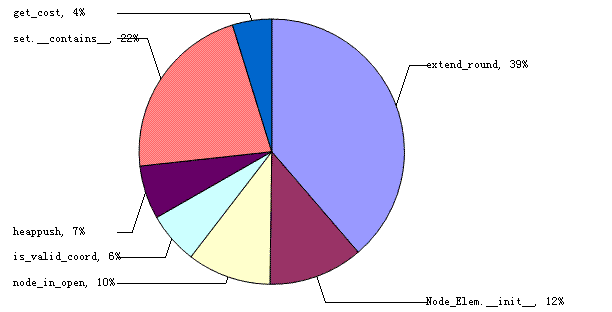
图1
一图胜过千言,我们从图1可以看出extend_round调用的函数占总时间的三分之二左右,所以减少函数调用是我们的重点,但extend_round本身也占用了38%的运行时间,更合理地重新组织extend_round的代码是有必要的。下面我们就随着extend_round的源码来分析修正:
|
def extend_round(self, p): #可以从8个方向走 xs = (-1, 0, 1, -1, 1, -1, 0, 1) ys = (-1,-1,-1, 0, 0, 1, 1, 1) for x, y in zip(xs, ys): new_x, new_y = x + p.x, y + p.y #无效或者不可行走区域,则勿略 if not self.is_valid_coord(new_x, new_y): continue #构造新的节点 node = Node_Elem(p, new_x, new_y, self.e_x, self.e_y, / p.dist+self.get_cost(p.x, p.y, new_x, new_y)) #新节点在关闭列表,则忽略 if node in self.close: continue i = self.node_in_open(node) if i != -1: #新节点在开放列表 if self.open[i].dist > node.dist: #现在的路径到比以前到这个节点的路径更好~ #则使用现在的路径 self.open[i].parent = p self.open[i].dist = node.dist continue heappush(self.open, node) |
代码段8
一进入函数,我们可看到三行劣化代码:
xs = (-1, 0, 1, -1, 1, -1, 0, 1)
ys = (-1,-1,-1, 0, 0, 1, 1, 1)
for x, y in zip(xs, ys):
这里的xs,ys,zip()都是恒不变的,但写在函数里需要每一次调用extend_round()的时候生成三个序列对象,这需要花费一点时间,我们可以把它们提出函数外,作为class A_Star的静态成员变量,如下:
class A_Star:
xs = (-1, 0, 1, -1, 1, -1, 0, 1)
ys = (-1,-1,-1, 0, 0, 1, 1, 1)
co = zip(xs, ys)
把for循环改为:
for x, y in A_Star.co:
这样就可以了。
再看下去就到了is_valid_coord()函数,它是用以判断坐标是否已经超出边界的:
|
def is_valid_coord(self, x, y): if x < 0 or x >= self.width or y < 0 or y >= self.height: return False return test_map[y][x] != '#' |
代码段9
仔细看看,可以发现if段是多余的,因为地图本身就以’#’围了起来,所以我们可以把这个函数手动内联到extend_round()里:
#if not self.is_valid_coord(new_x, new_y):
if test_map[new_y][new_x] == ‘#’:
continue
好,接着往下是Node_Elem的构造函数,调用了get_cost(),我们也可以把简单的get_cost()手动内联如下:
#构造新的节点
# node = Node_Elem(p, new_x, new_y, self.e_x, self.e_y, /
# p.dist+self.get_cost(p.x, p.y, new_x, new_y))
node = Node_Elem(p, new_x, new_y, self.e_x, self.e_y, /
p.dist+(1.4,1.0)[p.x == new_x or p.y == new_y])
再往是就是我们在前面优化过的检测新节点是否在close表中的代码:
#新节点在关闭列表,则忽略
if node in self.close:
continue
这一段代码看似已经没有什么好优化的,其实不然,我们结合上下文来看可以知道Node_Elem的构造函数是比较耗时间的,如果构造出来的对象已经在close表中,那么构造的Node_Elem对象马上就被销毁了,实在太浪费。我们可以想办法先判断是否在close表中,如果不在则构造新的Node_Elem对象,肯定可以节省一点时间。要达成这个意愿,我们必须先要修改一下在set中查找元素需要用到的Node_Elem.__eq__()函数:
def __eq__(self, other):
#return self.hv == other.hv
return self.hv == other
因为Node_Elem的hash值由坐标计算,所以可以直接把hash值作为other参数传进来,这样就可以省去构造Node_Elem实例。在extend_round中做出这样的改动:
#新节点在关闭列表,则忽略
if (new_x << 16) ^ new_y in self.close:
continue
并把这段代码移到Node_Elem对象构造之前,可以省下大约一半的Node_Elem.__init__调用呢~
接下来的代码调用了node_in_open(),又一个线性查找!当文章写到这里的时候,我已经不再想写下去了,因为我突然觉悟到我没有必要完全优化完成这次优化,我需要讲的关于profile及相关模块的应用都已经讲清楚了,我需要给大家一点作业,不是吗?所以我决定在这里完结。如果你喜欢优化下去,我可以再给一些提示,我们可以尝试用set来实现open表,但肯定会遇到取最小值的速度问题,怎么解决?
能坚持读到这里的人不多,我感谢你。
———— end ————
[Python]profile优化实践(基于A*算法) 1相关推荐
- [Python]profile优化实践(基于A*算法)
本文由恋花蝶发表于http://blog.csdn.net/lanphaday 欢迎转载,但敬请保留全文完整,并包含本声明. [Python]profile优化实践(基于A*算法) 在<用pro ...
- Python数据分析之双色球基于线性回归算法预测
@本文来源于公众号:csdn2299,喜欢可以关注公众号 程序员学府 本文实例讲述了Python数据分析之双色球基于线性回归算法预测下期中奖结果.分享给大家供大家参考,具体如下: 前面讲述了关于双色球 ...
- Python实现一条基于POS算法的区块链
最新内容会更新在主站深入浅出区块链社区 原文链接:用Python从零开始创建区块链 区块链中的共识算法 在比特币公链架构解析中,就曾提到过为了实现去中介化的设计,比特币设计了一套共识协议,并通过此协议 ...
- 【PID优化】基于蝗虫算法PID控制器优化设计含Matlab源码
1 内容介绍 该文针对广泛应用的PID控制器,在MATLAB仿真软件环境下,开发出一个过程控制系统的仿真软件包,能够实现模型辨识和PID参数调节,为过程控制系统仿真研究提供了方便. 该软件界面友好,操 ...
- 【布局优化】基于Memetic算法求解集群无线传感器网络中节能覆盖控制优化问题含Matlab源码
1 简介 Memetic 算法是一种结合遗传算法和局部搜索策略的新型智能算法.通过与局部优化策略的结合,局部调整进化后产生的新个体,强化了算法的局部搜索能力.Memetic 算法区别于遗传算法的关键是 ...
- 【布局优化】基于鲸鱼算法实现3D无线传感器网(WSN)覆盖优化 Matlab源码
一.WSN模型 二.鲸鱼算法 2.1. 鲸鱼优化算法的生物机制 图1 座头鲸的泡泡捕食示意图 据研究,鲸鱼大脑的某些区域有与人类相似的梭形细胞,而这些细胞负责人类的判断.情感和社会行为.鲸 ...
- 【路径优化】基于帝企鹅算法求解TSP问题(Matlab代码实现)
目录 1 帝企鹅算法 2 旅行商问题(TSP) 3 运行结果 4 参考文献 5 Matlab代码实现 1 帝企鹅算法 帝企鹅优化算法(emperor penguin optimizer,EPO)是Ga ...
- 【布局优化】基于布谷鸟算法实现无线传感器网(WSN)覆盖优化 Matlab源码
一.WSN模型 1.1 动机 近年来,随着对等网络.云计算和网格计算等分布式环境的发展,无线传感器网络(WSN)得到了广泛的应用.无线传感器网络(WSN)是一种新兴的计算和网络模式,它可以被定义为一个 ...
- 【布局优化】基于蚁狮算法的无线传感器网(WSN)覆盖优化matlab源码
一.WSN模型 1.1 动机 近年来,随着对等网络.云计算和网格计算等分布式环境的发展,无线传感器网络(WSN)得到了广泛的应用.无线传感器网络(WSN)是一种新兴的计算和网络模式,它可以被定义为一个 ...
最新文章
- 研究生第一篇科研论文常犯问题总结
- idea怎么配置spring
- Arrays.asList方法总结
- 【NOI2015】荷马史诗
- python coroutine_笔记-python-coroutine
- vue组件的基本使用:入门示例
- 体制内工作了十几年,跳出来学嵌入式合适吗?
- LUN/PV/VG/LV
- 微信停止服务印度用户;阿里回应“马云遭印度法院传唤”;fastjson 1.2.73 发布 | 极客头条...
- word计算机排版怎么选,Word选择题选项对齐排版方法 查找替换工具搞定
- 转载:ie6,ie7兼容性总结
- PSARDumper DA发布PSP3000解密工具
- 微信小程序实例练习——《排班查询》
- 产品经理必修课之互联网产品设计流程
- 解决 uni-app编译报错 Error: No matching use for foo.js
- android竖屏固定,安卓教程:设置竖屏固定壁纸
- MFC超市商品管理系统学生成绩管理系统学生信息管理系统通讯录管理系统图书管理系统
- Kubernetes 安全专家(CKS)必过心得
- 国产操作系统能不能完全替代windows,普及大众?
- Mysql数据库的单表查询