HM-SpringCloud微服务系列11.4【缓存同步】
大多数情况下,浏览器查询到的都是缓存数据,如果缓存数据与数据库数据存在较大差异,可能会产生比较严重的后果。
所以我们必须保证数据库数据、缓存数据的一致性,这就是缓存与数据库的同步。
1. 数据同步策略
1.1 缓存数据同步常见方式
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
1.2 异步通知缓存同步实现方案
而异步实现又可以基于MQ或者Canal来实现:
- 基于MQ的异步通知
![]()
解读:
- 商品服务完成对数据的修改后,只需要发送一条消息到MQ中。
- 缓存服务监听MQ消息,然后完成对缓存的更新。
- 依然有少量的代码侵入。
- 基于Canal的通知
![]()
解读:
- 商品服务完成商品修改后,业务直接结束,没有任何代码侵入
- Canal监听MySQL变化,当发现变化后,立即通知缓存服务
- 缓存服务接收到canal通知,更新缓存
- 代码零侵入
2. 安装Canal
2.1 认识Canal
Canal [kə'næl],译意为水道/管道/沟渠,canal是阿里巴巴旗下的一款开源项目,基于Java开发。
基于数据库增量日志解析,提供增量数据订阅&消费。
GitHub的地址:https://github.com/alibaba/canal
Canal是基于MySQL的主从同步来实现的
2.1.1 MySQL主从同步原理
![]()
- 1)MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做binary log events
- 2)MySQL slave 将 master 的 binary log events拷贝到它的中继日志(relay log)
- 3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
2.1.2 Canal实现原理
Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。
再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。
![]()
2.2 安装和配置Canal
Canal是基于MySQL的主从同步功能,因此必须先开启MySQL的主从功能才可以。
这里以之前用Docker运行的mysql为例进行操作:
![]()
2.2.1 开启MySQL主从
一、开启binlog
打开mysql容器挂载的日志文件,在/tmp/mysql/conf目录:
![]()
修改文件:
vi /tmp/mysql/conf/my.cnf添加内容:
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima配置解读:
log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-binbinlog-do-db=heima:指定对哪个database记录binary log events,这里记录heima这个库
最终完整my.cnf文件:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima![]()
docker重启mysql服务:
docker restart mysql![]()
重启完成后查看一下mysql的data目录:生成了binary log文件
![]()
二、设置用户权限
需要给从库设置权限
添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对heima这个库的操作权限
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;![]()
![]()
![]()
重启mysql容器
docker restart mysql![]()
测试设置是否成功:在mysql控制台,或者Navicat中,输入命令并运行:
show master status;![]()
PS:由于刚刚又重启了一次mysql,所以增加了新的binary log文件:000002
2.2.2 安装Canal
一、创建Docker网络
需要创建一个网络,将MySQL、Canal放到同一个Docker网络中:
docker network create heima让mysql加入这个网络:
docker network connect heima mysql![]()
二、安装Canal
课前资料中提供了canal的镜像压缩包,本地上传到远程虚拟机:
![]()
通过以下命令导入镜像到docker:
docker load -i canal.tar![]()
然后运行命令创建Canal容器:
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=heima\\..* \
--network heima \
-d canal/canal-server:v1.1.5说明:
-p 11111:11111:这是canal的默认监听端口,端口映射-e canal.destinations=heima:canal集群名称-e canal.instance.master.address=mysql:3306:数据库地址和端口,如果不知道mysql容器地址,可以通过docker inspect 容器id来查看-e canal.instance.dbUsername=canal:数据库用户名-e canal.instance.dbPassword=canal:数据库密码-e canal.instance.filter.regex=:要监听的表名称
表名称监听支持的语法:
mysql 数据解析关注的表,Perl正则表达式. 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\) 常见例子: 1. 所有表:.* or .*\\..* 2. canal schema下所有表: canal\\..* 3. canal下的以canal打头的表:canal\\.canal.* 4. canal schema下的一张表:canal.test1 5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2
![]()
通过以下命令动态查看一下Canal的运行日志(ctrl+c退出):
docker logs -f canal![]()
Canal启动成功后,如何知道Cancl是否已与MySql建立连接?
首先,可以通过以下命令进行Canal容器内部:
docker exec -it canal bash![]()
![]()
![]()
其次,查看一下Canal的运行日志:
tail -f canal-server/logs/canal/canal.log![]()
可以看到Canal运行正常
再次,查看一下"数据库"heima的日志:
tail -f canal-server/logs/heima/heima.log![]()
可以看到Canal先尝试连接mysql,连接成功后会去找binlog二进制文件(此处是000002),找到后开始做主从同步
证明Canal安装成功了
最后退出Canal容器:
exit![]()
3. 监听Canal
3.1 客户端
Canal提供了各种语言的客户端,当Canal监听到binlog变化时,会通知Canal的客户端。
![]()
我们可以利用Canal提供的Java客户端,监听Canal通知消息。当收到变化的消息时,完成对缓存的更新。
不过Canal默认提供的官方Java客户端是比较麻烦的
所以这里我们会使用GitHub上的第三方开源的canal-starter客户端。
地址:https://github.com/NormanGyllenhaal/canal-client
canal-starter与SpringBoot完美整合,自动装配,比官方客户端要简单好用很多
3.2 实现监听
3.2.1 引入依赖
<!--canal客户端-->
<dependency><groupId>top.javatool</groupId><artifactId>canal-spring-boot-starter</artifactId><version>1.2.1-RELEASE</version>
</dependency>![]()
3.2.2 编写配置
canal:destination: heima # canal集群名/实例名,要与安装canal时设置的名称一致(跟canal-server运行时设置的destination一致)server: 10.193.193.141:11111 # canal服务地址![]()
3.2.3 修改Item实体类
![]()
通过@Id、@Column、等注解完成Item与数据库表字段的映射:
package com.heima.item.pojo;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.annotation.Transient;import java.util.Date;@Data
@TableName("tb_item")
public class Item {@TableId(type = IdType.AUTO)@Idprivate Long id;//商品idprivate String name;//商品名称private String title;//商品标题private Long price;//价格(分)private String image;//商品图片private String category;//分类名称private String brand;//品牌名称private String spec;//规格private Integer status;//商品状态 1-正常,2-下架private Date createTime;//创建时间private Date updateTime;//更新时间@TableField(exist = false)@Transientprivate Integer stock;@TableField(exist = false)@Transientprivate Integer sold;
}![]()
3.2.4 编写监听器
![]()
通过实现EntryHandler<T>接口编写监听器,监听Canal消息。注意两点:
- 实现类通过
@CanalTable("tb_item")指定监听的表信息 - EntryHandler的泛型是与表对应的实体类
![]()
![]()
package com.heima.item.config;import com.github.benmanes.caffeine.cache.Cache;
import com.heima.item.pojo.Item;
import org.checkerframework.checker.units.qual.A;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;/*** 每当数据库发生增删改,会将对应的数据传递给以下三个方法*/
@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {@Autowiredprivate RedisHandler redisHandler;@Autowiredprivate Cache<Long, Item> itemCache;@Overridepublic void insert(Item item) {// PS:本地缓存效率更高,建议放到redis缓存前处理// 写数据到本地JVM进程缓存itemCache.put(item.getId(), item);// 写数据到redis缓存redisHandler.saveItem(item);}@Overridepublic void update(Item before, Item after) {// 更新本地JVM进程缓存数据itemCache.put(after.getId(), after);// 更新redis缓存数据redisHandler.saveItem(after);}@Overridepublic void delete(Item item) {// 删除本地JVM进程缓存数据itemCache.invalidate(item.getId());// 删除redis缓存数据redisHandler.deleteItemById(item.getId());}
}注意:上面这里对Redis的操作都封装到了RedisHandler这个对象中,用到时直接调用即可
是之前做缓存预热时编写的一个配置类,内容如下:
![]()
package com.heima.item.config;import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.util.List;/*** 实现redis缓存预热* 项目启动那一刻,就会创建RedisHandler这个Bean,并注入redisTemplate对象,然后执行afterPropertiesSet()*/
@Component
public class RedisHandler implements InitializingBean {@Autowiredprivate RedisTemplate redisTemplate;@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;/*** from jackson* spring里一个默认的json处理工具ObjectMapper* 静态常量,工具*/private static final ObjectMapper MAPPER = new ObjectMapper();/*** 初始化缓存* @throws Exception*/@Overridepublic void afterPropertiesSet() throws Exception {// 1. 查询商品信息(此处理应仅查询热点数据,实际因为此次演示数据不多,所以全查全放到缓存中)List<Item> itemList = itemService.list();// 2. 放入缓存for (Item item : itemList) {// 2.1 item序列化为jsonString json = MAPPER.writeValueAsString(item);// 2.2 存入redisredisTemplate.opsForValue().set("item:id:"+item.getId(), json); //key=前缀"item:id:"+id,value=json}// 3. 查询商品库存信息(同上)List<ItemStock> stockList = stockService.list();// 4. 放入缓存for (ItemStock stock : stockList) {// 4.1 stock序列化为jsonString json = MAPPER.writeValueAsString(stock);// 4.2 存入redisredisTemplate.opsForValue().set("item:stock:id:"+stock.getId(), json);}}public void saveItem(Item item) {try {String json = MAPPER.writeValueAsString(item);redisTemplate.opsForValue().set("item:id:" + item.getId(), json);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}public void deleteItemById(Long id) {redisTemplate.delete("item:id:" + id);}
}3.2.5 测试
重启ItemApplication和ItemApplication2这两个微服务:
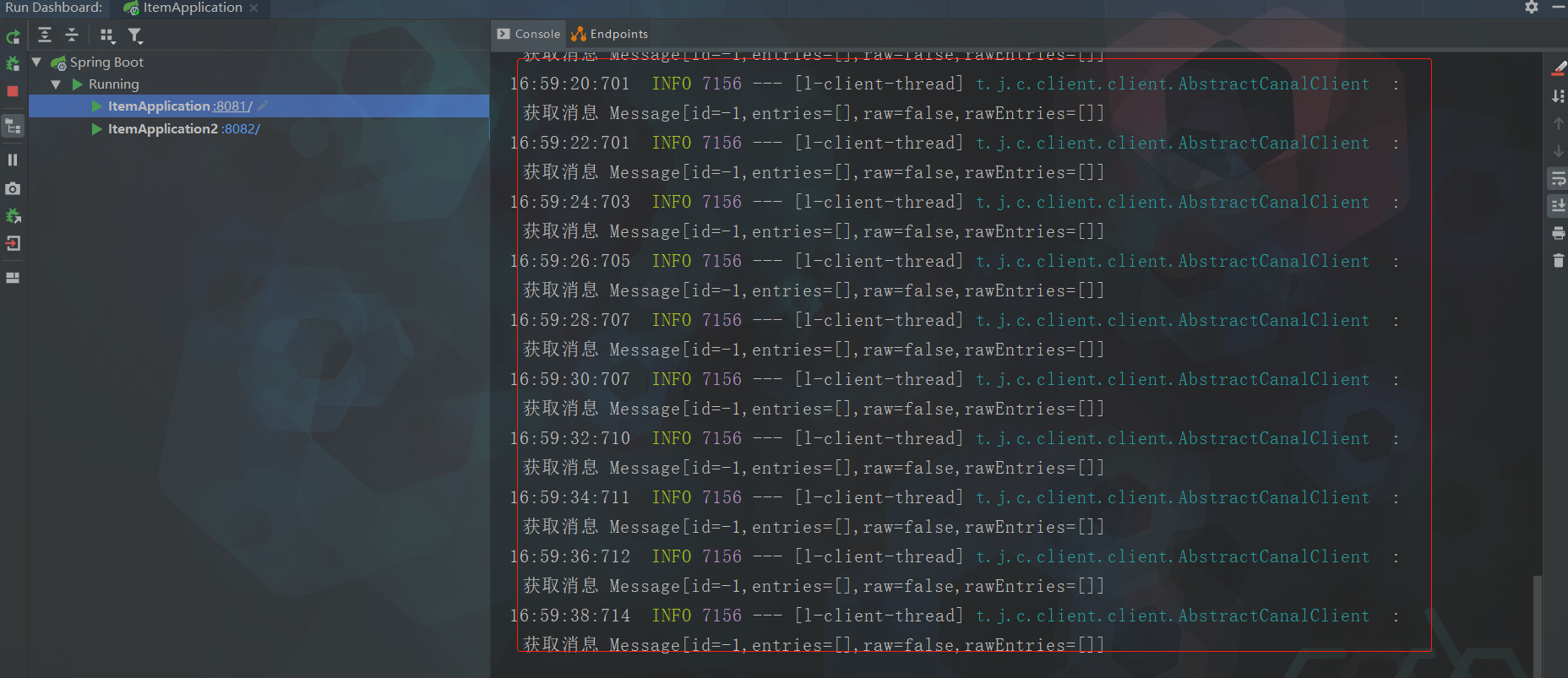
![]()
从控制台中可以看到在服务启动成功后会一直收到消息,证明java代码已经与Canal建立起连接了
访问http://localhost:8081/item/10001
![]()
初始项目中老师已经给准备好了管理数据操作界面,可以直接使用
访问http://localhost:8081
![]()
修改一下商品信息
![]()
![]()
查看一下idea控制台日志,发现刚才操作数据库时,有日志,说明数据修改了
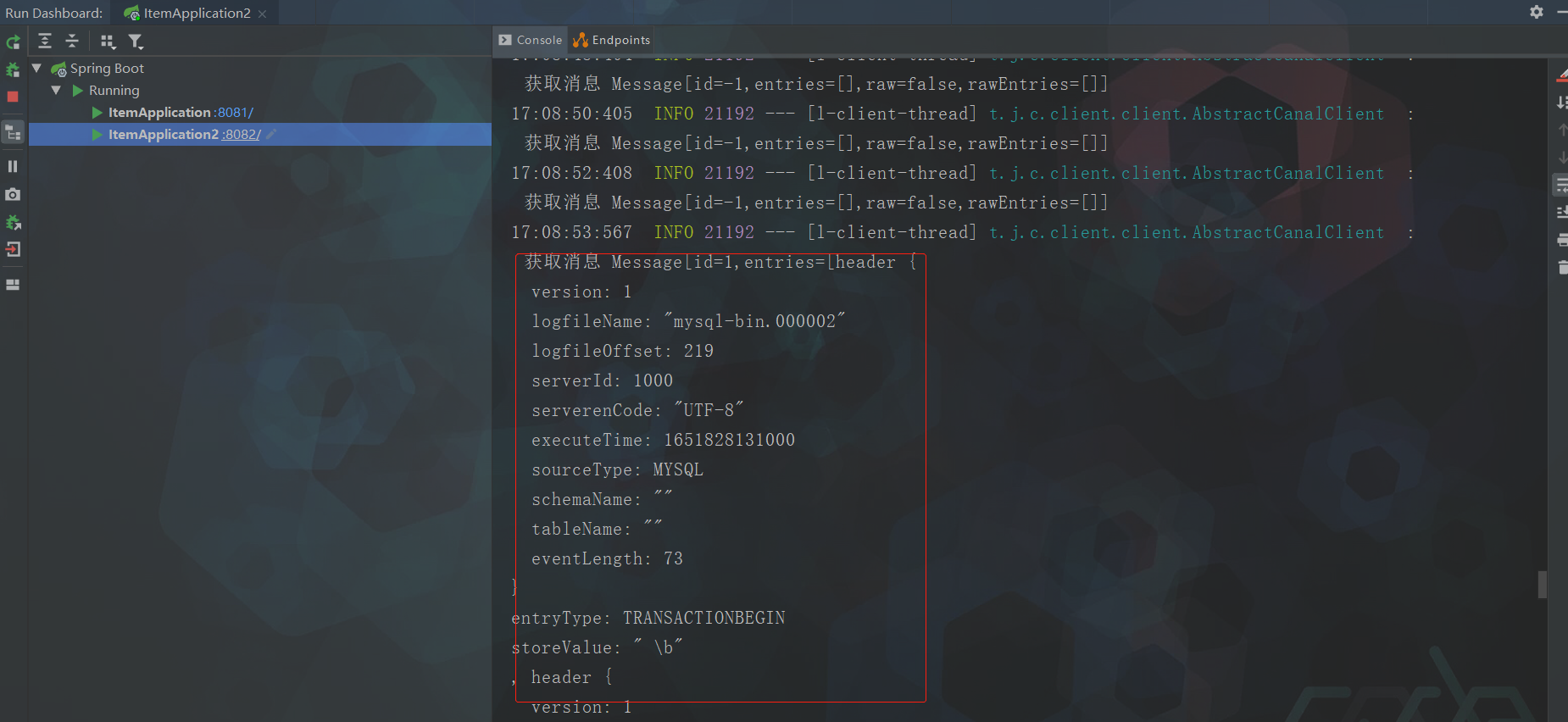
![]()
![]()
然后,再来访问http://localhost:8081/item/10001,查看数据是否已发生变化
![]()
最后,再通过RDM来看一下redis缓存数据
![]()
至此实现了:当数据库数据发生变化时,缓存都会跟着一起变
4. 多级缓存架构总结
![]()
- 红框是本节11.4实现的内容
![]()
- 蓝框时本次课程未实现的内容(可以参考绿框实现)
![]()
HM-SpringCloud微服务系列11.4【缓存同步】相关推荐
- HM-SpringCloud微服务系列11.1【多级缓存的意义JVM进程缓存】
HM-SpringCloud微服务系列11:多级缓存-高级篇 1. 什么是多级缓存 多级缓存是亿级流量的缓存方案 浏览器访问静态资源时,优先读取浏览器本地缓存 访问非静态资源(ajax查询数据)时,访 ...
- springcloud微服务系列之服务注册与发现组件Eureka
一.Eurake的简介 二.使用Eureka进行服务的注册消费 1.创建一个服务注册中心 2.创建服务的提供者 3.创建服务的消费者 总结 一.Eurake的简介 今天我们来介绍下springclou ...
- HM-SpringCloud微服务系列11.1.2【案例导入】
启动docker服务:systemctl start docker 2.1 导入商品管理案例 2.1.1 安装MySQL 后期做数据同步需要用到MySQL的主从功能,所以需要大家在虚拟机中,利用Doc ...
- 微服务系列:Dubbo与SpringCloud的Ribbon、Hystrix、Feign的优劣势比较
在微服务架构中,分布式通信.分布式事务.分布式锁等问题是亟待解决的几个重要问题. Spring Cloud是一套完整的微服务解决方案,基于 Spring Boot 框架.确切的说,Spring Clo ...
- 学习笔记:SpringCloud 微服务技术栈_实用篇①_基础知识
若文章内容或图片失效,请留言反馈.部分素材来自网络,若不小心影响到您的利益,请联系博主删除. 前言 学习视频链接 SpringCloud + RabbitMQ + Docker + Redis + 搜 ...
- springcloud 微服务 分布式 Activiti6 工作流 vue.js html 跨域 前后分离
1.代码生成器: [正反双向](单表.主表.明细表.树形表,快速开发利器) freemaker模版技术 ,0个代码不用写,生成完整的一个模块,带页面.建表sql脚本.处理类.service等完整模块 ...
- Spring Cloud微服务系列文,服务调用框架Feign
之前博文的案例中,我们是通过RestTemplate来调用服务,而Feign框架则在此基础上做了一层封装,比如,可以通过注解等方式来绑定参数,或者以声明的方式来指定请求返回类型是JSON. 这种 ...
- Java生鲜电商平台-SpringCloud微服务架构高并发参数优化实战
Java生鲜电商平台-SpringCloud微服务架构高并发参数优化实战 一.写在前面 在Java生鲜电商平台平台中相信不少朋友都在自己公司使用Spring Cloud框架来构建微服务架构,毕竟现在这 ...
- Java生鲜电商平台-SpringCloud微服务架构中分布式事务解决方案
Java生鲜电商平台-SpringCloud微服务架构中分布式事务解决方案 说明:Java生鲜电商平台中由于采用了微服务架构进行业务的处理,买家,卖家,配送,销售,供应商等进行服务化,但是不可避免存在 ...
最新文章
- 插入ts以及判断列是否存在(支持多数据库)
- 解构亚马逊Alexa的1.5万种技能
- 使用maven整合SSM框架详细步骤
- 分布式ID生成器的解决方案总结
- CAS项目部署和基础操作
- iPhone8 和 X 买哪个?听我的
- 关于兔子的一些往事~
- 笨办法学 Python · 续 第一部分:预备知识
- linux awk 脚本格式,偷偷学习shell脚本之awk编辑器
- SQL注入分类,一看你就明白了。SQL注入点/SQL注入类型/SQL注入有几种/SQL注入点分类
- python-3高级特征
- 百度之星程序设计大赛输出格式的注意
- 数据加密以及国密基础知识
- C++自动化(模板元)编程基础与应用(4)
- 解决龙芯2F使用oprofile-0.9.7无法采样应用程序函数的问题
- 人工智能终究会抢了我们程序员的饭碗
- dos界面操作mysql讲解
- Login 和 Logout
- 2019.9-电赛国赛-基于FDC2214的纸张计数显示装置
- 数据结构----各种排序方法总结