python3爬虫框架scrapy_带你深入浅出python爬虫框架scrapy(三)
接下来我们要讲解爬取一些较难的数据评论:
1. 在Item中定义自己要抓取的数据:
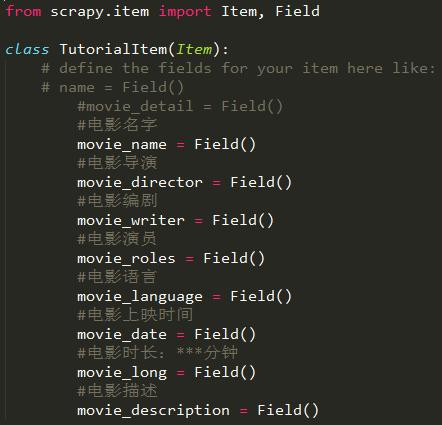
movie_name就像是字典中的“键”,爬到的数据就像似字典中的“值”。在继承了BaseSpider的类中会用到:
第一行就是上面那个图中的TutorialItem这个类,红框圈出来的就是上图中的movie_name中。
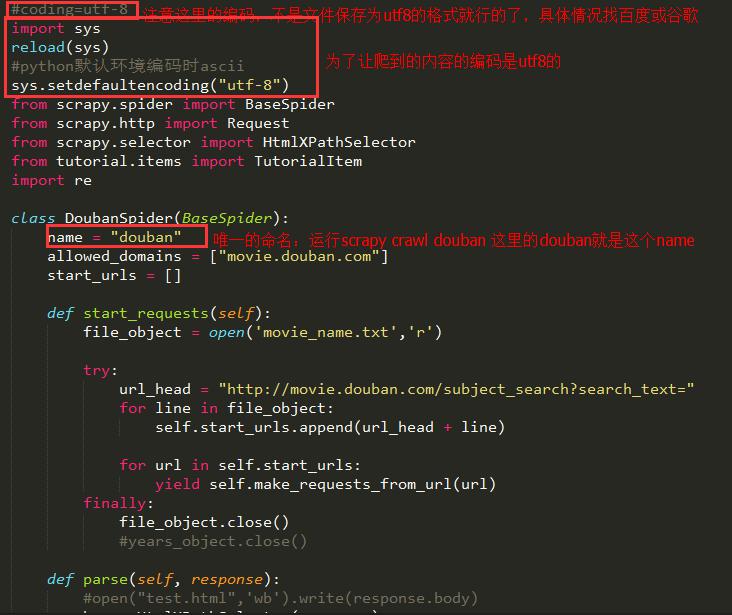
2、然后在spiders目录下编辑Spider.py那个文件
跟着上面的item是匹配的
3.编辑pipelines.py文件,可以通过它将保存在TutorialItem中的内容写入到数据库或者文件中。
对json模块的方法的注释:dump和dumps(从Python生成JSON),load和loads(解析JSON成Python的数据类型);dump和dumps的唯一区别是dump会生成一个类文件对象,dumps会生成字符串,同理load和loads分别解析类文件对象和字符串格式的JSON
4. 上述三个过程后就可以爬虫了,仅需上述三个过程哟,然后在dos中将目录切换到tutorial下输入scrapy crawl douban就可以爬啦
接下来就简单介绍下一些基本知识
5. start_requests方法:
直接在start_urls中存入我们要爬虫的网页链接,但是如果我们要爬虫的链接很多,而且是有一定规律的,我们就需要重写这个方法了,可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request。
那么这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入我们自定义的规律的链接。
6. parse方法:
生成了请求后,scrapy会帮我们处理Request请求,然后获得请求的url的网站的响应response,parse就可以用来处理response的内容。在我们继承的类中重写parse方法,parse_item是我们自定义的方法,用来处理新连接的request后获得的response。友情提示:获得更多学科学习视频+资料+源码,请加QQ:3276250747。
7. 在这个函数体中,根据 start_requests (默认为GET请求)返的 Response,得到了一个 名字为‘item_urls’ 的url集合。然后遍历并请求这些集合。再看 Request 源码

本文版权归传智播客人工智能+Python学院所有,欢迎转载,转载请注明作者出处。谢谢!
作者:传智播客人工智能+Python学院
python3爬虫框架scrapy_带你深入浅出python爬虫框架scrapy(三)相关推荐
- 视频教程-手把手带你学会python爬虫-Python
手把手带你学会python爬虫 曾在某大型公司大型互联网任职多年,在公司主要从事移动端开发.全栈开发.主要技术栈是Android.Java.Python.爬虫.Linux等等. 赵庆元 ¥99.00 ...
- 用几个最简单的例子带你入门 Python 爬虫
作者 | ZackSock 来源 | 新建文件夹X(ID:ZackSock) 头图 | CSDN下载自视觉中国 前言 爬虫一直是Python的一大应用场景,差不多每门语言都可以写爬虫,但是程序员们却独 ...
- 图解爬虫,用几个最简单的例子带你入门Python爬虫
一.前言 爬虫一直是Python的一大应用场景,差不多每门语言都可以写爬虫,但是程序员们却独爱Python.之所以偏爱Python就是因为她简洁的语法,我们使用Python可以很简单的写出一个爬虫程序 ...
- 手把手带你飞Python爬虫+数据清洗新手教程(一)
本文共有2394字,读完大约需要10分钟. 目录 简介 思考 撸起袖子开始干 1 获取网页源代码 2 在网页源代码里找出所需信息的位置 3 数据清洗 4 完整代码 5 优化后的代码 简介 本文使用An ...
- 带你入门Python爬虫
点击关注我哦 一篇文章带你了解Python爬虫 数据科学只有通过数据才能实现,而在现实世界中,数据通常不会有现成的.csv文件等你使用.你必须去自己寻找.这就是为什么爬虫对数据科学非常重要的原因. 但 ...
- python爬虫项目实战教学视频_('[Python爬虫]---Python爬虫进阶项目实战视频',)
爬虫]---Python 爬虫进阶项目实战 1- Python3+Pip环境配置 2- MongoDB环境配置 3- Redis环境配置 4- 4-MySQL的安装 5- 5-Python多版本共存配 ...
- 【浅谈爬虫】一名合格的Python爬虫工程师必须具备技能—具体了解四大Python爬虫分类以及爬虫基本原理实现
一.网络爬虫概述 网络爬虫(又被称作为网络蜘蛛.网络机器人,在某社区中经常被称为网页追逐者),可以按照指定的规则(网络爬虫的算法)自动浏览或抓取网络中的信息,通过Python可以很轻松地编写爬虫程序或 ...
- python爬虫是干嘛的?python爬虫能做什么?
python爬虫可以用于收集数据,爬虫是一个爬虫程序,一个程序的运行速度是非常快的,而且不会因为重复的事情感到疲倦,接下来我们一起学习python爬虫是干嘛用的,python爬虫究竟能做什么呢?pyt ...
- 为什么用python写爬虫_老猿为什么写Python爬虫教程
对于"爬虫", 或许你只是听说过,或许已经有所了解.无论怎样,你可能有过这样的困惑: + 学了爬虫不知道怎么挣钱? + 技术不知道如何进阶? + 遇到问题不知道找谁交流? 十多年前 ...
最新文章
- chart.Correlation绘制相关性热图
- 网络传输中的两个阶段、阻塞IO、非阻塞IO和多路复用
- Nginx学习之五:Nginx第三方模块
- Spring MVC @RequestMapping注解详解
- 多进程实现生产者消费者
- valgrind 常见错误提示信息
- SSH远程终端连接数问题
- C# 10 新特性 —— 补充篇
- 双向循环链表:维吉尼亚密码
- 003——数组(三)count()reset()end()prev()next()current()
- zabbix监控哪些东西_监控系统选型,一篇全搞定
- Linux学习12—文件服务
- CSDN 赚积分C币方法
- 程 | 深度学习 + OpenCV,Python 实现实时视频目标检测 机器之心 09-21
- 电子元器件商城与数据手册下载网站汇总
- 联想android手机驱动,Lenovo联想手机驱动
- Eclipse中英文对照表(整理笔记)
- 使用Scrapy爬取电影链接
- 软件工程本科生实习_我从n00b实习生到工程团队主管的方式
- 前端自学驿站:【建议收藏】css晦涩难懂的点都在这啦