定位匹配 模板匹配 地图_什么是地图匹配?
定位匹配 模板匹配 地图
By Marie Douriez, James Murphy, Kerrick Staley
玛丽·杜里兹(Marie Douriez),詹姆斯·墨菲(James Murphy),凯里克·史塔利(Kerrick Staley)
When you request a ride, Lyft tries to match you with the driver most suited for your route. To make a dispatch decision, we first need to ask: where are the drivers? Lyft uses GPS data from the drivers’ phones to answer this question. However, the GPS data that we get is often noisy and does not match the road.
当您请求乘车时,Lyft会尝试将您与最适合您的路线的驾驶员进行匹配。 要做出调度决定,我们首先需要问: 驾驶员在哪里? Lyft使用驾驶员电话中的GPS数据来回答此问题。 但是,我们获取的GPS数据通常比较嘈杂,与道路不匹配。
To get a clearer picture from this raw data, we run it through an algorithm that takes raw locations and returns more accurate locations that are on the road network. This process is called map-matching. We recently developed and launched a completely new map-matching algorithm and found that it improved driver location accuracy and made Lyft’s marketplace more efficient. In this post, we’ll discuss the details of this new model.
为了从原始数据中获得更清晰的图像,我们通过一种算法来运行它,该算法将获取原始位置并返回道路网络上的更精确位置。 这个过程称为map-matching 。 我们最近开发并推出了一种全新的地图匹配算法,发现它提高了驾驶员的定位准确性,并使Lyft的市场更加高效。 在这篇文章中,我们将讨论这个新模型的细节。
什么是地图匹配? (What is map-matching?)
Map-matching is a process that maps raw GPS locations to road segments on a road network in order to create an estimate of the route taken by a vehicle.
地图匹配是一种将原始GPS位置映射到路网上的路段的过程,以创建对车辆所走路线的估算。
为什么需要地图匹配? (Why do we need map-matching?)
At Lyft, we have two main use cases for map-matching:
在Lyft,我们有两个主要的地图匹配用例:
- At the end of a ride, to compute the distance travelled by a driver to calculate the fare.乘车结束时,计算驾驶员行进的距离,以计算票价。
In real-time, to provide accurate locations to the ETA team and make dispatch decisions as well as to display the drivers’ cars on the rider app.
实时 ,为ETA团队提供准确的位置并做出调度决策,并在rider应用程序上显示驾驶员的汽车。
These two use cases differ by their constraints: in real-time, we need to be able to perform map-matching quickly (low latency) and with the locations available up to the current time only. At the end of a ride however, the latency requirements are less stringent and the whole history of the ride is available to us (allowing us to work “backwards” from future locations). As a result, End-Of-Ride Map-Matching (EORMM) and Real-Time Map-Matching (RTMM) are solved using slightly different approaches. In this post, we will focus on algorithms used for Real-Time Map-Matching.
这两个用例的约束条件不同:实时,我们需要能够快速执行地图匹配(低延迟),并且仅在当前时间可用位置。 但是,在乘车结束时,对等待时间的要求不那么严格,并且可以使用乘车的全部历史记录(允许我们从将来的位置“向后”工作)。 结果,使用略有不同的方法解决了行进路线图匹配(EORMM)和实时地图匹配(RTMM)。 在本文中,我们将重点介绍用于实时地图匹配的算法。
为什么地图匹配具有挑战性? (Why is map-matching challenging?)
A bad map-matched location leads to inaccurate ETAs, then to bad dispatch decisions and upset drivers and riders. Map-matching thus directly impacts Lyft’s marketplace and has important consequences on our users’ experience. There are several main challenges to map-matching.
与地图匹配的位置不正确会导致ETA信息不准确,进而导致调度决策不正确,并使驾驶员和乘客感到不适。 因此,地图匹配会直接影响Lyft的市场 ,并对我们的用户体验产生重要影响。 地图匹配存在几个主要挑战。
First, as Yunjie noted in his blog post, the location data collected from the phones can get very noisy in urban canyons (where streets are surrounded by tall buildings), around stacked roads, or under tunnels. Those areas are particularly challenging for map-matching algorithms and are all the more important to do correctly since many Lyft rides happen there.
首先,正如Yunjie在他的博客文章中指出的那样,从手机中收集的位置数据在城市峡谷(街道被高楼大厦包围),堆积道路周围或隧道下会变得非常嘈杂 。 对于地图匹配算法而言,这些区域特别具有挑战性,而正确进行操作则更加重要,因为在那里发生了许多Lyft骑行。
Beyond noise and road geometry, another challenge is the lack of ground truth: we don’t actually know the true locations of the drivers when they are driving and we have to find proxies to evaluate the accuracy of our models.
除了噪音和道路几何形状外,另一个挑战是缺乏地面真实性 :我们实际上不知道驾驶员在开车时的真实位置,我们必须找到代理来评估模型的准确性。
Finally, the performance of the map-matching algorithms relies on the quality of the road network data. This problem is being solved by another team within Mapping at Lyft; see Albert’s blog post to learn how we make our internal map more accurate.
最后,地图匹配算法的性能取决于道路网络数据的质量 。 Lyft的Mapping内部的另一个小组正在解决此问题; 请参阅Albert的博客文章,以了解我们如何使内部地图更加准确。
那么我们如何解决地图匹配问题呢? (So how do we solve map-matching?)
We won’t go into all of the techniques for solving map-matching, but for a review of common approaches, please refer to this study by Quddus et al. [1].
我们不会介绍解决地图匹配的所有技术,但是要回顾常见方法,请参考Quddus等人的这项研究。 [1]。
A nice way to frame the problem is to use state space models. State space models are time series models where the system has “hidden” states that cannot be directly observed but give rise to visible observations. Here, our hidden states are the actual positions of the car on the road network that we are trying to estimate. We only observe a modified version of the hidden states: the observations (raw location data). We assume that the state of the system evolves in a way that only depends on the current state (Markov assumption) and further define a hidden-state-to-hidden-state transition density and a hidden-state-to-observation density.
解决问题的一种好的方法是使用状态空间模型 。 状态空间模型是时间序列模型,其中系统具有“隐藏”状态,这些状态无法直接观察到,但会引起可见的观察。 在这里,我们的隐藏状态是我们要估算的汽车在道路网络上的实际位置。 我们仅观察到隐藏状态的修改版本:观察值(原始位置数据)。 我们假设系统的状态以仅取决于当前状态的方式演化(马尔可夫假设),并进一步定义了从隐藏状态到隐藏状态的转移密度和从隐藏状态到观察的密度。
A commonly used state space model for map-matching is the discrete-state Hidden Markov Model (Newson & Krumm [2], DiDi’s IJCAI-19 Tutorial [3], Map Matching @ Uber [4]). In this system, we generate candidates by looking at the closest points on the road segment and use the Viterbi algorithm to find the most likely sequence of hidden states.
常用的地图匹配状态空间模型是离散状态隐马尔可夫模型 (Newson&Krumm [2],DiDi的IJCAI-19教程[3],Uber的Map Matching [4])。 在该系统中,我们通过查看路段上的最近点来生成候选对象,并使用维特比算法查找最可能的隐藏状态序列。
However, the Hidden Markov Model (HMM) has several limitations:
但是,隐马尔可夫模型(HMM)有几个限制:
- It is relatively inflexible to different modeling choices and input data对于不同的建模选择和输入数据而言,它相对不灵活
- It scales badly (O(N²), where N is the number of possible candidates at each state)它缩放严重(O(N²),其中N是每个状态下可能的候选数)
- It can’t cope well with high(ish) frequency observations (see Newson & Krumm [2])它不能很好地应对高频观测(请参阅Newson&Krumm [2])。
For these reasons, we developed a new real-time map-matching algorithm that is more accurate and more flexible to incorporate additional sensor data.
由于这些原因,我们开发了一种新的实时地图匹配算法,该算法更准确,更灵活,可以合并其他传感器数据。
基于(无味)卡尔曼滤波器的新模型 (A new model based on the (unscented) Kalman filter)
卡尔曼滤波器基础 (Kalman filter basics)
Let’s first review the basics of the Kalman filter. (Read how Marguerite and her team used Kalman filters to estimate the seasonality of a market in this blog post.)
让我们首先回顾一下卡尔曼滤波器的基础。 (在此博客文章中,了解Marguerite和她的团队如何使用Kalman滤波器来估计市场的季节性。)
Unlike the discrete-state HMM, the Kalman filter allows for the hidden state to be a continuous distribution. At its core, the Kalman filter is simply a linear Gaussian model and models the system using the following equations:
与离散状态HMM不同,卡尔曼滤波器允许隐藏状态为连续分布。 卡尔曼滤波器的核心是线性高斯模型 , 使用以下公式对系统进行建模:
Using these equations, the Kalman filter iteratively updates its representation of the system’s state using a closed form predict-correct step to go from step t-1 posterior to step t posterior.
使用这些方程式,卡尔曼滤波器使用封闭形式的预测正确步骤从后继的步骤t-1到后继的步骤t,迭代地更新其对系统状态的表示。
One limitation of the Kalman filter, however, is that it can only handle linear problems. To deal with non-linearities, generalizations of the Kalman filter have been developed such as the Extended Kalman Filter (EKF) and the Unscented Kalman Filter (UKF) [5]. As we’ll see in the next section, our new RTMM algorithm uses the UKF technique. For the rest of the post, the technical differences between the Kalman filter and the UKF don’t really matter: we can simply assume that the UKF works like a standard linear Kalman filter.
但是,卡尔曼滤波器的局限性在于它只能处理线性问题。 为了处理非线性,已经开发了卡尔曼滤波器的通用性,例如扩展卡尔曼滤波器(EKF)和无味卡尔曼滤波器(UKF)[5]。 正如我们将在下一节中看到的那样,我们新的RTMM算法使用UKF技术。 在剩下的文章中,卡尔曼滤波器和UKF之间的技术差异并不重要:我们可以简单地假设UKF的工作方式类似于标准线性卡尔曼滤波器。
边缘化粒子过滤器 (The Marginalized Particle Filter)
Let’s now describe how our new RTMM algorithm works. We will refer to it as a Marginalized Particle Filter (MPF).
现在让我们描述新的RTMM算法如何工作。 我们将其称为边际化粒子过滤器 (MPF)。
At a high level, our MPF algorithm keeps track of multiple “particles”, each representing a position on a trajectory on the road network, and runs an unscented Kalman filter conditioned on each of these trajectories. To be more precise, let us define the following objects:
在较高的层次上,我们的MPF算法会跟踪多个“粒子”,每个“粒子”代表道路网络上某个轨迹上的位置,并运行一个以这些轨迹为条件的无味卡尔曼滤波器。 更准确地说,让我们定义以下对象:
An MPF state is a list of particles.
MPF状态是粒子列表。
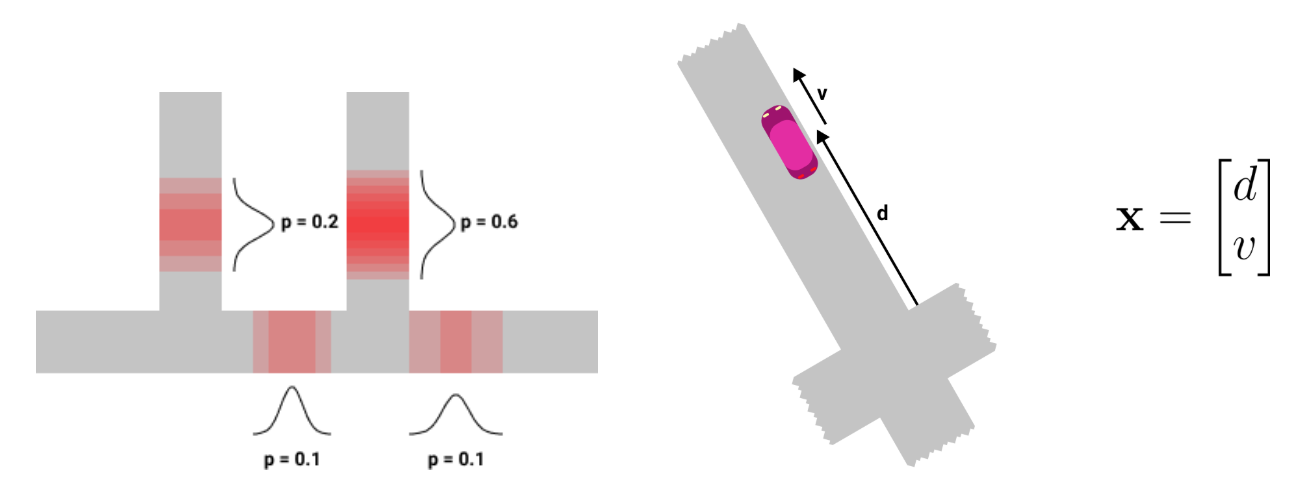
A particle represents one possible road position of the car on the map, associated with some probability. Each particle has 4 attributes:
粒子表示汽车在地图上的一种可能的道路位置,并具有一定的概率。 每个粒子具有4个属性:
- A probability p ∈ [0,1]概率p∈[0,1]
- A trajectory (i.e. a list of intersections from the map)轨迹(即地图上的交点列表)
A mean vector x = [d v]’ where d is the position of the car on the trajectory (in meters) and v is the car’s velocity (in meters/second)
平均矢量x = [dv]',其中d是汽车在轨迹上的位置(以米为单位),v是汽车的速度(以米/秒为单位)
A 2x2 covariance matrix P representing the uncertainty around the car’s position and velocity
2x2协方差矩阵P,表示汽车位置和速度周围的不确定性
We update the MPF state each time we receive a new observation from the driver’s phone in the following way:
每次从驾驶员的手机收到新的观察结果时,我们都会以以下方式更新MPF状态 :
If the previous MPF state has no particle (for example, if the driver just logged in to the app), we need to initialize a new one. The initialization step simply “snaps” the GPS observation onto the map and returns the closest road positions. Each particle’s probability is computed as a function of its distance to the observation.
如果以前的MPF状态没有粒子(例如,如果驱动程序刚刚登录到应用程序),则需要初始化一个新的粒子。 初始化步骤只是将GPS观测值“捕捉”到地图上,然后返回最接近的道路位置。 每个粒子的概率根据其到观测值的距离来计算。
At the next update (new observation), we iterate through our state’s (non-empty) list of particles and perform two steps for each particle. First, the trajectory extension step finds all the possible trajectories from the particle’s current position on the road network. Second, we loop through these new trajectories and on each of these, we run our UKF and update the newly created particle’s probability. After these two nested loops, we end up with a new list of particles. To avoid keeping track of too many of them in our MPF state, we simply discard the most unlikely ones (pruning).
在下一次更新(新观察)时,我们遍历状态的(非空)粒子列表,并对每个粒子执行两个步骤。 首先, 轨迹扩展步骤从道路网络上粒子的当前位置找到所有可能的轨迹。 其次,我们遍历这些新轨迹,并在每条轨迹上运行UKF并更新新创建的粒子的概率。 在这两个嵌套循环之后,我们最终得到一个新的粒子列表。 为了避免在MPF状态下跟踪过多的事件,我们只丢弃最不可能的事件( 修剪 )。
The downstream teams can then decide to use the most probable particle from the MPF state as the map-matched location or can directly exploit our probabilistic output (e.g. to create a distribution of possible ETAs).
然后,下游团队可以决定使用MPF状态中最可能的粒子作为地图匹配的位置,或者可以直接利用我们的概率输出(例如,创建可能的ETA的分布)。
To recap, the Marginalized Particle Filter maintains a set of particles representing possible positions of the car on trajectories and each particle is updated using the Kalman filter algorithm. The new algorithm provides not only location but also speed estimates and uncertainty. In practice, we have observed that it yields more accurate map-matched locations than the HMM, in particular in downtown areas and around intersections where errors would lead to very inaccurate ETAs.
概括地说,边缘化粒子过滤器会维护一组代表汽车在轨迹上可能位置的粒子,并且使用卡尔曼过滤器算法更新每个粒子。 新算法不仅提供位置,还提供速度估计和不确定性。 在实践中,我们已经观察到,与HMM相比,它产生的地图匹配位置更加准确,尤其是在市区和交叉路口附近,在这些交叉路口,错误会导致非常不准确的ETA。
结论 (Conclusion)
After experimenting with this new real-time map-matching algorithm, we found positive effects on Lyft’s marketplace. The new model reduced ETA errors, meaning that we could more accurately match passengers to the most suited driver. It also reduced passenger cancels, showing that it increased passengers’ confidence that their drivers would arrive on-time for pickup.
在尝试了这种新的实时地图匹配算法之后,我们发现了对Lyft市场的积极影响 。 新模型减少了ETA错误,这意味着我们可以更准确地将乘客与最适合的驾驶员匹配。 它还减少了乘客的取消,这表明它增强了乘客对他们的驾驶员将准时到达接机的信心。
We’re not done yet, though: there are many ways that we plan to improve this model in the coming months. We’re going to incorporate data from other phone sensors, such as the gyroscope, which will allow us to detect when drivers turn. We also plan to take into account the driver’s destination (if they have one, e.g. when en route to a pickup) as a prior. Indeed, another strength of the Marginalized Particle Filter is that it allows us to easily add these new types of information to the model in a principled way, and it is a good foundation on which we can continue to make the Lyft experience a little more seamless for our passengers and drivers.
不过,我们尚未完成:我们计划在未来几个月中改进此模型的方法有很多。 我们将合并来自其他电话传感器(例如陀螺仪)的数据,这将使我们能够检测到驾驶员何时转向。 我们还计划事先考虑驾驶员的目的地(如果他们有目的地,例如在去接送人的途中)。 确实,边缘化粒子过滤器的另一个优势在于,它使我们能够以有原则的方式轻松地将这些新类型的信息添加到模型中,并且这是我们可以继续使Lyft体验更加无缝的良好基础。为我们的乘客和司机。
Special thanks to the entire Locations team for helping us put this model into production!
特别感谢整个Locations团队帮助我们将此模型投入生产!
As always, Lyft is hiring! If you’re passionate about developing state-of-the-art quantitative models or building the infrastructure that powers them, read more about our Science and Engineering roles and reach out to us.
与往常一样,Lyft正在招聘! 如果您热衷于开发最新的定量模型或构建支持它们的基础架构,请详细了解我们的科学和工程角色并 与我们联系 。
翻译自: https://eng.lyft.com/a-new-real-time-map-matching-algorithm-at-lyft-da593ab7b006
定位匹配 模板匹配 地图
http://www.taodudu.cc/news/show-5062994.html
相关文章:
- matlab maxfunevals,matlab优化工具箱概述
- Matlab编写二叉树定价公式,美式期权二叉树定价及MATLAB程序
- 数学建模 MATLAB基础
- matlab代码用python替换_用python替换Matlab
- matlab对服务器性能要求,服务器运行matlab
- 存储论matlab,基于MATLAB的GUI设计应用软件
- Matlab断供哈工大,国产替代软件挺身而出,霸气
- 网络仿真软件性能比较
- 古代野兽 Ancient Beast:优质开源游戏项目
- 如何运行开源游戏?八分音符酱python版踩坑记录
- C# 开源游戏服务器框架
- 总结:那些热门的开源游戏服务器框架,还不看你就out了
- 开源游戏服务器框架NoahGameFrame(NF)客户端环境搭建(三)
- 开源游戏服务器框架NoahGameFrame(NF)简介(一)
- android 开源_适用于Android的12个开源游戏
- 开源游戏源码
- 全景播放器,免安装支持全景视频
- UE4 插件 简单全景播放器
- 全景视频播放器中OpenGL的相关记录
- VR+全景播放器+头控讲解-05
- VR+全景播放器+头控讲解-01
- VR+全景播放器+头控讲解-03
- VR+全景播放器+头控讲解-02
- iOS 全景播放器最简单的解决方案
- VR+全景播放器+头控讲解-06
- 全景播放器-js+flash
- html做全景视频播放器,一种全景视频播放方法及播放器的制造方法
- VR+全景播放器+头控讲解-04
- 劲爆全景之全景播放器
- android 全景播放器,Android VR Player(全景視頻播放器) [5]:簡單的歡迎界面
定位匹配 模板匹配 地图_什么是地图匹配?相关推荐
- ac自动机 匹配最长前缀_别再暴力匹配字符串了,高效的KMP,才是真的香
如果你想了解KMP算法,请静下心读完这篇文章,一定不会辜负你的时间 暴力匹配(BF) 字符串匹配是我们在编程中常见的问题,其中从一个字符串(主串)中检测出另一个字符串(模式串)是一个非常经典的问题,当 ...
- arcgis直方图导出地图_利用Arcgis地图工具自动输出报告地图图纸
大家在日常工作中经常会用到arcgis进行矢量的绘制,以完成规划,设计,以及测绘,监测一类的工作.这些工作的需要往往也伴随着需要完成项目报告,项目报告中会涉及到各种利用arcgis绘制的矢量图纸,这个 ...
- 地图上分成一块一块区域 高德地图_在谷歌地图上绘制行政区域轮廓【结合高德地图的API】...
实现思路: 1.利用高德地图行政区域API获得坐标列表 2.将坐标列表绘制在谷歌地图上[因为高德地图和国内的谷歌地图都是采用GCJ02坐标系,所有误差很小,可以不进行坐标误差转换] 注意点: 1.用百 ...
- wince搜狗地图_安卓百度地图winCE版 V10.9.2 安卓版下载 - 加速吧 - win10系统之家
百度地图winCE版是一款非常好用的车载地图导航app.这款百度导航车载wince版基于wince技术开发,为每一位即将出行的用户提供最适合的路线规划,少走烂路.歪路,更快更精准的找到目的地. [功能 ...
- 中国地图_铜板画地图铜地球仪高档办公室装饰用品定制铜版画地图中国地图世界地图定制惠风堂铜雕艺术...
惠风堂铜雕艺术 惠风堂911期 春华秋实,惠风堂与你同在!惠风堂感谢过去一年,新老顾客的支持和厚爱!新的一年我们会更加努力的,为您做出令您满意的艺术作品.感恩! 客户定制彩色地图,可以免费写赠言!15 ...
- mapbox中文地图_使用 Mapbox 地图
如果您可以访问 Mapbox 地图,则可以将其添加至您的工作簿,或者使用它们在 Tableau Desktop 中创建地图视图.有关特定于国家/地区的可用数据的列表,请参见支持的地图数据. 将使用 M ...
- 怎么下载没水印的谷歌卫星地图_谷歌卫星地图有水印怎么办
我们在下载谷歌卫星地图时,发现卫星地图上有水印,那怎么办呢?虽然没有办法去掉卫星地图上的水印,但是可以换一种谷歌卫星地图呀,下面小编就给大家介绍下,如何下载无水印的谷歌卫星地图. 我们先来看下几个卫星 ...
- python 匹配字符串多个_在Python中匹配多个数据集的字符串
这里有一小段你可以启发的代码.主要思想是使用递归函数. 为简单起见,我承认我已经在列表中加载了数据,但是你可以在之前从文件中获取它们: data_files = [ 'data_a.dat', 'da ...
- rust刷卡点地图_新版rust地图物资 | 手游网游页游攻略大全
发布时间:2016-04-26 中加拿大地图哪里物资比较多?接下来为大家带来玩家"诺艾尔中士"总结分享的加拿大地图物资刷新点一览,以供参考. 没框的就是没做完的地方,物资极少或者根 ...
最新文章
- 002:用Python设计第一个游戏
- C#中Split函数的使用
- Google BigTable到底解决什么问题?
- 给缺少Python项目实战经验的人
- sidecar_Spring Cloud Sidecar –节点初始化
- Spring和JSF集成:导航
- Sping(一)——IOC/DI
- (转)Cesium教程系列汇总
- C++设置不定参数方法 简单示例
- 中国农用喷雾机市场趋势报告、技术动态创新及市场预测
- SQLite 指南之FAQ(中文)
- 【java笔记】Iterator迭代器 增强for
- 《移动App测试的22条军规》—App测试综合案例分析23.11节测试微信App对多语言和地区的支持...
- 判断多边形边界曲线顺/逆时针 两种方法
- 计算机专业学arm芯片吗,手把手教你学单片机ARM-STM32(完结)
- 有限元计算计算机配置,关于有限元分析的电脑配置问题
- 泛微oa明细表添加按钮_关于E8,这些快捷方式你必须知道
- Verge3D 2.12 for 3ds Max发布
- PowerShell路转粉之造轮子(01)------B站离线缓存简单合并blvm4s
- 浙江省高考数学python_数学高考与python