机器学习笔试、面试题五
1、Logistic回归分类器是否能对下列数据进行完美分类?
![]()
注:只可使用X1和X2变量,且只能使用两个二进制值(0,1)。
A 是
B 否
C 不确定
D 都不是
正确答案是: B
解析:逻辑回归只能形成线性决策面,而图中的例子并非线性可分的。
2、假设对给定数据应用了Logistic回归模型,并获得了训练精度X和测试精度Y。现在要在同一数据中添加一些新特征,以下哪些是错误的选项。
注:假设剩余参数相同。
A 训练精度提高
B 训练准确度提高或保持不变
C 测试精度提高或保持不变
正确答案是: B
解析:将更多的特征添加到模型中会增加训练精度,因为模型必须考虑更多的数据来适应逻辑回归。但是,如果发现特征显着,则测试精度将会增加
3、选择Logistic回归中的One-Vs-All方法中的哪个选项是真实的。
A 我们需要在n类分类问题中适合n个模型
B 我们需要适合n-1个模型来分类为n个类
C 我们需要只适合1个模型来分类为n个类
D 这些都没有
正确答案是:A
解析: 如果存在n个类,那么n个单独的逻辑回归必须与之相适应,其中每个类的概率由剩余类的概率之和确定。
4、假设有一个如下定义的神经网络:
![]()
如果我们去掉ReLU层,这个神经网络仍能够处理非线性函数,这种说法是:
A 正确的
B 错误的
正确答案是: B
5、假定特征 F1 可以取特定值:A、B、C、D、E 和 F,其代表着学生在大学所获得的评分。
在下面说法中哪一项是正确的?
A 特征 F1 是名义变量(nominal variable)的一个实例。
B 特征 F1 是有序变量(ordinal variable)的一个实例。
C 该特征并不属于以上的分类。
D 以上说法都正确。
正确答案是: B
解析:有序变量是一种在类别上有某些顺序的变量。例如,等级 A 就要比等级 B 所代表的成绩好一些。
6、下面哪个选项中哪一项属于确定性算法?
A PCA
B K-Means
C 以上都不是
正确答案是:A
解析:确定性算法表明在不同运行中,算法输出并不会改变。如果我们再一次运行算法,PCA 会得出相同的结果,而 k-means 不会。
7、两个变量的 Pearson 相关性系数为零,但这两个变量的值同样可以相关。
A 正确
B 错误
正确答案是:A
解析:答案为(A):Y=X2,请注意他们不仅仅相关联,同时一个还是另一个的函数。尽管如此,他们的相关性系数还是为 0,因为这两个变量的关联是正交的,而相关性系数就是检测这种关联。详情查看:https://en.wikipedia.org/wiki/Anscombe's_quartet
8、下面哪一项对梯度下降(GD)和随机梯度下降(SGD)的描述是正确的?
1 在 GD 和 SGD 中,每一次迭代中都是更新一组参数以最小化损失函数。
2 在 SGD 中,每一次迭代都需要遍历训练集中的所有样本以更新一次参数。
3 在 GD 中,每一次迭代需要使用整个训练集的数据更新一个参数。
A 只有 1
B 只有 2
C 只有 3
D 都正确
正确答案是:A
解析:在随机梯度下降中,每一次迭代选择的批量是由数据集中的随机样本所组成,但在梯度下降,每一次迭代需要使用整个训练数据集。
9、下面哪个/些超参数的增加可能会造成随机森林数据过拟合?
1 树的数量
2 树的深度
3 学习速率
A 只有 1
B 只有 2
C 只有 3
D 都正确
正确答案是: B
解析:通常情况下,我们增加树的深度有可能会造成模型过拟合。学习速率在随机森林中并不是超参数。增加树的数量可能会造成欠拟合。
10、假如你在「Analytics Vidhya」工作,并且想开发一个能预测文章评论次数的机器学习算法。你的分析的特征是基于如作者姓名、作者在 Analytics Vidhya 写过的总文章数量等等。那么在这样一个算法中,你会选择哪一个评价度量标准?
1 均方误差
2 精确度
3 F1 分数
A 只有 1
B 只有 2
C 只有 3
正确答案是:A
解析:你可以把文章评论数看作连续型的目标变量,因此该问题可以划分到回归问题。因此均方误差就可以作为损失函数的度量标准。
1、给定以下三个图表(从上往下依次为1,2,3). 哪一个选项对以这三个图表的描述是正确的?
![]()
![]()
A 1 是 tanh,2 是 ReLU,3 是 SIGMOID 激活函数
B 1 是 SIGMOID,2 是 ReLU,3 是 tanh 激活函数
C 1 是 ReLU,2 是 tanh,3 是 SIGMOID 激活函数
D 1 是 tanh,2 是 SIGMOID,3 是 ReLU 激活函数
正确答案是:D
解析:因为 SIGMOID 函数的取值范围是 [0,1],tanh 函数的取值范围是 [-1,1],RELU 函数的取值范围是 [0,infinity]。
2、以下是目标变量在训练集上的 8 个实际值 [0,0,0,1,1,1,1,1],目标变量的熵是所少?
A -(5/8 log(5/8) + 3/8 log(3/8))
B 5/8 log(5/8) + 3/8 log(3/8)
C 3/8 log(5/8) + 5/8 log(3/8)
D 5/8 log(3/8) – 3/8 log(5/8)
正确答案是:A
解析:信息熵的公式为: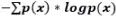
3、假定你正在处理类属特征,并且没有查看分类变量在测试集中的分布。现在你想将 one hot encoding(OHE)应用到类属特征中。
那么在训练集中将 OHE 应用到分类变量可能要面临的困难是什么?
A 分类变量所有的类别没有全部出现在测试集中
B 类别的频率分布在训练集和测试集是不同的
C 训练集和测试集通常会有一样的分布
D A 和 B 都正确
正确答案是:D
解析:A、B 项都正确,如果类别在测试集中出现,但没有在训练集中出现,OHE 将会不能进行编码类别,这将是应用 OHE 的主要困难。选项 B 同样也是正确的,在应用 OHE 时,如果训练集和测试集的频率分布不相同,我们需要多加小心。
4、Skip gram 模型是在 Word2vec 算法中为词嵌入而设计的最优模型。以下哪一项描绘了 Skip gram 模型?
![]()
A A
B B
C A和B
D 以上都不是
正确答案是: B
解析:这两个模型都是在 Word2vec 算法中所使用的。模型 A 代表着 CBOW,模型 B 代表着 Skip gram。
5、假定你在神经网络中的隐藏层中使用激活函数 X。在特定神经元给定任意输入,你会得到输出「-0.0001」。X 可能是以下哪一个激活函数?
A ReLU
B tanh
C SIGMOID
D 以上都不是
正确答案是: B
解析:该激活函数可能是 tanh,因为该函数的取值范围是 (-1,1)。
6、对数损失度量函数可以取负值。
A 对
B 错
正确答案是: B
解析:对数损失函数不可能取负值。
7、下面哪个/些对「类型 1(Type-1)」和「类型 2(Type-2)」错误的描述是正确的?
类型 1 通常称之为假正类,类型 2 通常称之为假负类。
类型 2 通常称之为假正类,类型 1 通常称之为假负类。
类型 1 错误通常在其是正确的情况下拒绝假设而出现。
A 只有 1
B 只有 2
C 只有 3
D 1和3
正确答案是:D
解析:在统计学假设测试中,I 类错误即错误地拒绝了正确的假设(即假正类错误),II 类错误通常指错误地接受了错误的假设(即假负类错误)
8、假定你想将高维数据映射到低维数据中,那么最出名的降维算法是 PCA 和 t-SNE。现在你将这两个算法分别应用到数据「X」上,并得到数据集「X_projected_PCA」,「X_projected_tSNE」。
下面哪一项对「X_projected_PCA」和「X_projected_tSNE」的描述是正确的?
A X_projected_PCA 在最近邻空间能得到解释
B X_projected_tSNE 在最近邻空间能得到解释
C 两个都在最近邻空间能得到解释
D 两个都不能在最近邻空间得到解释
正确答案是: B
解析:t-SNE 算法考虑最近邻点而减少数据维度。所以在使用 t-SNE 之后,所降的维可以在最近邻空间得到解释。但 PCA 不能。
9、给定下面两个特征的三个散点图(从左到右依次为图 1、2、3)
![]()
在上面的图像中,哪一个是多元共线(multi-collinear)特征?
A 图 1 中的特征
B 图 2 中的特征
C 图 3 中的特征
D 图 1、2 中的特征
正确答案是:D
解析:在图 1 中,特征之间有高度正相关,图 2 中特征有高度负相关。所以这两个图的特征是多元共线特征。
10、在先前问题中,假定你已经鉴别了多元共线特征。那么下一步你可能的操作是什么?
1 移除两个共线变量
2 不移除两个变量,而是移除一个
3 移除相关变量可能会导致信息损失。为了保留这些变量,我们可以使用带罚项的回归模型(如 ridge 或 lasso regression)。
A 只有 1
B 只有 2
C 只有 3
D 2 或 3
正确答案是:D
解析:因为移除两个变量会损失一切信息,所以我们只能移除一个特征,或者也可以使用正则化算法(如 L1 和 L2)。
1、给线性回归模型添加一个不重要的特征可能会造成:
1 增加 R-square
2 减少 R-square
A 只有 1 是对的
B 只有 2 是对的
C 1 或 2 是对的
D 都不对
正确答案是:A,您的选择是:C
解析:在给特征空间添加了一个特征后,不论特征是重要还是不重要,R-square 通常会增加
R-square可参考这篇博客
2、假设给定三个变量 X,Y,Z。(X, Y)、(Y, Z) 和 (X, Z) 的 Pearson 相关性系数分别为 C1、C2 和 C3。现在 X 的所有值加 2(即 X+2),Y 的全部值减 2(即 Y-2),Z 保持不变。
那么运算之后的 (X, Y)、(Y, Z) 和 (X, Z) 相关性系数分别为 D1、D2 和 D3。
现在试问 D1、D2、D3 和 C1、C2、C3 之间的关系是什么?
A D1= C1, D2 < C2, D3 > C3
B D1 = C1, D2 > C2, D3 > C3
C D1 = C1, D2 > C2, D3 < C3
D D1 = C1, D2 < C2, D3 < C3
E D1 = C1, D2 = C2, D3 = C3
正确答案是:E
解析:特征之间的相关性系数不会因为特征加或减去一个数而改变。
3、假定你现在解决一个有着非常不平衡类别的分类问题,即主要类别占据了训练数据的 99%。现在你的模型在测试集上表现为 99% 的准确度。那么下面哪一项表述是正确的?
1 准确度并不适合于衡量不平衡类别问题
2 准确度适合于衡量不平衡类别问题
3 精确率和召回率适合于衡量不平衡类别问题
3 精确率和召回率不适合于衡量不平衡类别问题
A 1 and 3
B 1 and 4
C 2 and 3
D 2 and 4
正确答案是:A
4、在集成学习中,模型集成了弱学习者的预测,所以这些模型的集成将比使用单个模型预测效果更好。下面哪个/些选项对集成学习模型中的弱学习者描述正确?
1 他们经常不会过拟合
2 他们通常带有高偏差,所以其并不能解决复杂学习问题
3 他们通常会过拟合
A 1 和 2
B 1 和 3
C 2 和 3
D 只有 1
正确答案是:A,您的选择是:C
解析:弱学习者是问题的特定部分。所以他们通常不会过拟合,这也就意味着弱学习者通常拥有低方差和高偏差。
5、下面哪个/些选项对 K 折交叉验证的描述是正确的
1 增大 K 将导致交叉验证结果时需要更多的时间
2 更大的 K 值相比于小 K 值将对交叉验证结构有更高的信心
3 如果 K=N,那么其称为留一交叉验证,其中 N 为验证集中的样本数量
A 1 和 2
B 2 和 3
C 1 和 3
D 1、2 和 3
正确答案是:D
解析:大 K 值意味着对过高估计真实预期误差(训练的折数将更接近于整个验证集样本数)拥有更小的偏差和更多的运行时间(并随着越来越接近极限情况:留一交叉验证)。我们同样在选择 K 值时需要考虑 K 折准确度和方差间的均衡。
6、为了得到和 SVD 一样的投射(projection),你需要在 PCA 中怎样做?
A 将数据转换成零均值
B 将数据转换成零中位数
C 无法做到
D 以上方法不行
正确答案是:A
解析:当数据有一个 0 均值向量时,PCA 有与 SVD 一样的投射,否则在使用 SVD 之前,你必须将数据均值归 0。
7、假设存在一个黑箱算法,其输入为有多个观察(t1, t2, t3,…….. tn)的训练数据和一个新的观察(q1)。该黑箱算法输出 q1 的最近邻 ti 及其对应的类别标签 ci。你可以将这个黑箱算法看作是一个 1-NN(1-最近邻)
能够仅基于该黑箱算法而构建一个 k-NN 分类算法?注:相对于 k 而言,n(训练观察的数量)非常大。
A 可以
B 不可以
正确答案是:A
解析:在第一步,你在这个黑箱算法中传递一个观察样本 q1,使该算法返回一个最近邻的观察样本及其类别,在第二步,你在训练数据中找出最近观察样本,然后再一次输入这个观察样本(q1)。该黑箱算法将再一次返回一个最近邻的观察样本及其类别。你需要将这个流程重复 k 次
8、假设存在一个黑箱算法,其输入为有多个观察(t1, t2, t3,…….. tn)的训练数据和一个新的观察(q1)。该黑箱算法输出 q1 的最近邻 ti 及其对应的类别标签 ci。你可以将这个黑箱算法看作是一个 1-NN(1-最近邻)
我们不使用 1-NN 黑箱,而是使用 j-NN(j>1) 算法作为黑箱。为了使用 j-NN 寻找 k-NN,下面哪个选项是正确的?
A j 必须是 k 的一个合适的因子
B j>k
C 不能办到
正确答案是:A
解析:用 1NN 实现 KNN 的话,每次找到最近邻,然后把这项从数据中取出来,重新运行 1NN 算法,这样重复 K 次,就行了。所以,少找多的话,少一定要是多的因子。
9、有以下 7 副散点图(从左到右分别编号为 1-7),你需要比较每个散点图的变量之间的皮尔逊相关系数。下面正确的比较顺序是?
![]()
1 1<2<3<4
2 1>2>3 > 4
3 7<6<5<4
4 7>6>5>4
A 1 和 3
B 2 和 3
C 1 和 4
D 2 和 4
正确答案是: B
10、你可以使用不同的标准评估二元分类问题的表现,例如准确率、log-loss、F-Score。让我们假设你使用 log-loss 函数作为评估标准。
下面这些选项,哪个/些是对作为评估标准的 log-loss 的正确解释
![]()
1如果一个分类器对不正确的分类很自信,log-loss 会严重的批评它。
2 对一个特别的观察而言,分类器为正确的类别分配非常小的概率,然后对 log-loss 的相应分布会非常大。
3 log-loss 越低,模型越好。
A 1 和 3
B 2 和 3
C 1 和 2
D 1、2、3
正确答案是:D
1、假设你被给到以下数据,你想要在给定的两个类别中使用 logistic 回归模型对它进行分类
![]()
你正在使用带有 L1 正则化的 logistic 回归,其中 C 是正则化参数,w1 和 w2 是 x1 和 x2 的系数。
![]()
当你把 C 值从 0 增加至非常大的值时,下面哪个选项是正确的?
A 第一个 w2 成了 0,接着 w1 也成了 0
B 第一个 w1 成了 0,接着 w2 也成了 0
C w1 和 w2 同时成了 0
D 即使在 C 成为大值之后,w1 和 w2 都不能成 0
正确答案是: B
解析:通过观察图像我们发现,即使只使用 x2,我们也能高效执行分类。因此一开始 w1 将成 0;当正则化参数不断增加时,w2 也会越来越接近 0。
2、假设我们有一个数据集,在一个深度为 6 的决策树的帮助下,它可以使用 100% 的精确度被训练。现在考虑一下两点,并基于这两点选择正确的选项。
注意:所有其他超参数是相同的,所有其他因子不受影响。
1 深度为 4 时将有高偏差和低方差
2 深度为 4 时将有低偏差和低方差
A 只有 1
B 只有 2
C 1 和 2
D 没有一个
正确答案是:A,您的选择是:D
解析:如果在这样的数据中你拟合深度为 4 的决策树,这意味着其更有可能与数据欠拟合。因此,在欠拟合的情况下,你将获得高偏差和低方差。
3、在 k-均值算法中,以下哪个选项可用于获得全局最小?
1 尝试为不同的质心(centroid)初始化运行算法
2 调整迭代的次数
3 找到集群的最佳数量
A 2 和 3
B 1 和 3
C 1 和 2
D 以上所有
正确答案是:D
解析:所有都可以用来调试以找到全局最小
4、假设你正在做一个项目,它是一个二元分类问题。你在数据集上训练一个模型,并在验证数据集上得到混淆矩阵。基于上述混淆矩阵,下面哪个选项会给你正确的预测。
1 精确度是~0.91
2 错误分类率是~0.91
3 假正率(False correct classification)是~0.95
4 真正率(True positive rate)是~0.95
A 1 和 3
B 2 和 4
C 1 和 4
D 2 和 3
正确答案是:C
解析:精确度(正确分类)是 (50+100)/165,约等于 0.91。真正率是你正确预测正分类的次数,因此真正率将是 100/105 = 0.95,也被称作敏感度或召回。
5、对于下面的超参数来说,更高的值对于决策树算法更好吗?
1 用于拆分的样本量
2 树深
3 树叶样本
A 1 和 2
B 2 和 3
C 1 和 3
D 1、2 和 3
E 无法分辨
正确答案是:E
解析:对于选项 A、B、C 来说,如果你增加参数的值,性能并不一定会提升。例如,如果我们有一个非常高的树深值,结果树可能会过拟合数据,并且也不会泛化。另一方面,如果我们有一个非常低的值,结果树也许与数据欠拟合。因此我们不能确定更高的值对于决策树算法就更好。
6、想象一下,你有一个 28x28 的图片,并使用输入深度为 3 和输出深度为 8 在上面运行一个 3x3 的卷积神经网络。注意,步幅padding是1,你正在使用相同的填充(padding)。当使用给定的参数时,输出特征图的尺寸是多少?
A 28 宽、28 高、8 深
B 13 宽、13 高、8 深
C 28 宽、13 高、8 深
D 13 宽、28 高、8 深
正确答案是:A
解析: 计算输出尺寸的公式是:输出尺寸=(N – F)/S + 1。其中,N 是输入尺寸,F 是过滤器尺寸,S 是步幅。
7、假设,我们正在 SVM 算法中为 C(惩罚参数)的不同值进行视觉化绘图。由于某些原因,我们忘记了使用视觉化标注 C 值。这个时候,下面的哪个选项在 rbf 内核的情况下最好地解释了下图(1、2、3 从左到右,图 1 的 C 值 是 C 1,图 2 的 C 值 是 C 2,图 3 的 C 值 是 C 3)中的 C 值。
![]()
A C1 = C2 = C3
B C1 > C2 > C3
C C1 < C2 < C3
D 没有一个
正确答案是:C
解析:错误项的惩罚参数 C。它也控制平滑决策边界和训练点正确分类之间的权衡。对于 C 的大值,优化会选择一个较小边距的超平面。
C是惩罚系数 就是说你对误差的宽容度,这个值越高,说明你越不能容忍出现误差
8、假设有如下一组输入并输出一个实数的数据,则线性回归(Y = bX+c)的留一法交叉验证均方差为?
![]()
A 10/27
B 20/27
C 50/27
D 49/27
正确答案是:D,您的选择是: B
解析:我们需要计算每个交叉验证点的残差,拟合后得到两点连线和一点用于交叉验证。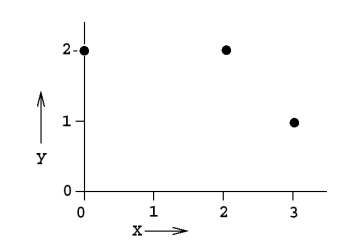
留一法交叉验证均方差为(2^2 +(2/3)^2 +1^2) /3 = 49/27
9、下列哪一项关于极大似然估计(MLE)的说法是正确的?
1.MLE并不总是存在
2.MLE一直存在
3.如果MLE存在,它可能不特异
4.如果MLE存在,它一定是特异的
A 1和4
B 2和3
C 1和3
D 2和4
正确答案是:C,您的选择是:A
解析:MLE可能不是一个转折点,即它可能不是一个似然函数的一阶导数消失的点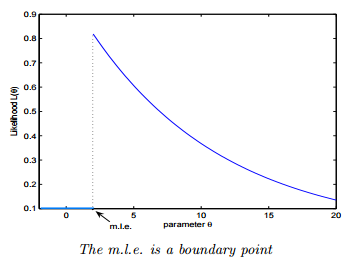 MLE可能并不特异
MLE可能并不特异
10、假设线性回归模型完美拟合训练数据(即训练误差为零),则下列哪项是正确的?
A 测试误差一定为零
B 测试误差一定不为零
C 以上都不对
正确答案是:C
解析:如果测试数据无干扰,则测试误差可能为零。换言之,如果测试数据是训练数据的典型代表,测试误差即为零,但这种情况并不总是出现。
机器学习笔试、面试题五相关推荐
- 机器学习笔试面试题——day3
选择题 1.下列方法中,不可以用于特征降维的方法包括 A 主成分分析PCA B 线性判别分析LDA C 深度学习SparseAutoEncoder D 矩阵奇异值分解SVD 特征降维方法主要有:PCA ...
- 在微型计算机中进行数据传输使用的编码方式,2013年一级windows笔试模拟试题及答案(五)...
无忧考网为大家收集整理了<2013年一级windows笔试模拟试题及答案(五)>供大家参考,希望对大家有所帮助!!! 一.选择题 1.在微机中,应用最普遍的字符编码是( ) A.BCD码 ...
- 机器学习笔试精选题精选(四)
点击上方"AI有道",选择"置顶公众号" 关键时刻,第一时间送达! 读本文需要 8 分钟 机器学习是一门理论性和实战性都比较强的技术学科.在应聘机器学习相关工作 ...
- c/c++笔试面试题(4)
c/c++笔试面试题(4) 2007-11-08 16:46 749人阅读 评论(0) 收藏 举报 Sony笔试题 1.完成下列程序 * *.*. *..*..*.. *...*...*.. ...
- 福建农商银行计算机类笔试题目,2020年福建福州农商银行免笔试面试试题
原标题:2020年福建福州农商银行免笔试面试试题 华夏启成教育整理2020年福建福州农商银行免笔试面试试题,以供大家参考学习. 农信社面试培训,华夏启成教育2009年起至今每年均有开班,老师具有十年以 ...
- 第一篇 多线程笔试面试题汇总(转)
一.概念性问答题 第一题:线程的基本概念.线程的基本状态及状态之间的关系? 线程:一个线程是进程的一个顺序执行流.同类的多个线程共享一块内存空间和一组系统资源,线程本身有一个供程序执行时的堆栈.线程在 ...
- 计算机自动化程序高 应用范围广是由于,计算机等级考试一级笔试模拟试题(三)及答案...
计算机等级考试一级笔试模拟试题(三) 第一卷必做模块 必做模块一计算机基础知识(每项1.5分,14项,共21分) 一. 计算机的自动化程度高.应用范围广是由于.目前的计算机所使用的电子元器件是. 1. ...
- 机器学习笔试精选 100 题
欢迎关注"勇敢AI"公众号,更多python学习.数据分析.机器学习.深度学习原创文章与大家分享,还有更多电子资源.教程.数据集下载.勇敢AI,一个专注于人工智能AI的公众号. = ...
- PHP 笔试 + 面试题
本章主要介绍常见的 PHP 笔试 + 面试题,包括: 基础及程序题 数据库技术题 综合技术题 项目及设计题 ** 基础及程序题 ** [1] 写一个排序算法,可以是冒泡排序或者是快速排序,假设待排序对 ...
- JAVA高级工程师笔试面试题
前段时间应聘几家公司的JAVA高级软件工程师职位遇到的几个笔试面试题: 一.tomcat有哪些性能调优方法,请举例说明? 二.Spring中bean的作用域有哪些? 三.struts2和struts1 ...
最新文章
- 下拉列表插件bootstrap-select使用实例
- unix 存储空间不足 无法处理此命令_大数据分析命令行使用教程
- 点击弹窗 input直接是待输入状态_第六课:你知道如何用两行代码做个弹窗吗?看这里...
- Hyperledger fabric1.4.0搭建环境
- cocos2dx 调用oc java_cocos2dx 调用浏览器打开网址
- C#写的windows应用程序打包
- 华为畅享9s可以升级鸿蒙吗,珍珠全面屏!华为畅享9S/9e正式发布:千元三摄加持...
- 【转】如何缩进你的代码?
- POJ-1386 Play on Words 有向图欧拉通路判定
- python db api_dbapi · PyPI
- java keytool 使用总结(转)
- 真不是开玩笑:同事因在涉及金钱交易中使用double造成无法挽回的损失,已跑路...
- 2021-09-0818. 四数之和
- 通过命令行使用bandizip压缩与解压
- 如何同时登陆2个微信
- 饱和蒸汽比容计算、 温压补偿系数计算
- 如何避开PPT演讲的几个误区(中)
- 统计专业人数 (10 分)
- 项目中涉及到的Python小技巧(3)—— 高维高斯分布
- JavaScript----BOM模块,定时器