大数据Spark实战第五集 Spark股票交易实时价格分析
统一批处理与流处理:Dataflow
在本模块前面的课时中,我们已经学习了 Spark Streaming 的架构、原理、用法以及生产环境中需要考虑的问题。对于 Spark Streaming 的学习,我们已经告一段落了。在学习 Spark 最新的流处理套件 Structured Streaming 之前,你有必要来看看一种新的计算模型或者范式:Dataflow,它也是 Structured Streaming、Flink、Apex 等最新技术的理论基础,从这种新的计算模型中,我们能发现不少有趣且非常重要的内容。
本课时的主要内容有:
Google MillWheel 系统
Dataflow 模型
Google MillWheel 系统
Google MillWheel(水磨轮转)系统来源于谷歌公司在 2013 年发表的一篇论文:“MillWheel: Fault-Tolerant Stream Processing atInternet Scale”,它致力于构建一种低延迟、大规模的流处理系统,用户只需定义计算拓扑和应用代码,系统会自动管理持久化状态以及连续的数据流,所有的这一切都在框架的容错保证之下。换句话说,Google MillWheel 系统是一种高吞吐、低延迟、数据不重不丢且具有容错性保证的分布式流处理框架,并且还提供了晚到和乱序数据的解决方案,可以说是下一代流处理系统的雏形。Spark 2.2 正式发布的 Structured Streaming 和 Flink 中都可以看到 Google MillWheel 的影子。Google MillWheel 的最大特色是对乱序数据与晚到数据的处理方法。
乱序和晚到数据处理方式的提出,体现了业界对于实时数据处理结果正确性不断提升的要求。在解释晚到数据之前,需要先了解两个与时间相关的概念。
事件时间(event time),事件时间指的是事件发生的时间,在消息诞生时就被系统记录在消息中。
处理时间(processing time),处理时间指的是在数据管道中处理数据时,该消息被数据处理系统观察到的时间,是数据处理系统的时间,这里并没有假设分布式系统中时钟是同步的。
在现实情况中,由于网络存在延迟、处理本身需要时间,以及数据管道内部的性能消耗等原因,会导致同一条数据的这两个时间存在差异,如下图所示:
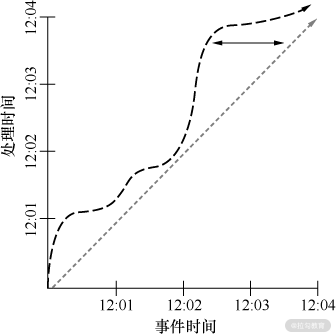
斜线表示的是理想情况,处理时间与事件时间完全相等,曲线表示的是实际情况,通常我们将其称之为时间域倾斜。曲线所代表的数据就是晚到数据和乱序数据,晚到数据和乱序数据一定是用户希望按照数据的事件时间顺序来处理数据才有的概念,如果只是按照处理时间来处理,晚到和乱序就无从说起了。
基于此,Google MillWheel 提出了一种低水位(low watermark)机制,作为一种解决方案。我们先来看看低水位的定义,如下图所示。

A 和 C 是流处理计算拓扑中的两个计算单元(可以简单理解为 Spark DAG 中的两个 Executor ),C 是 A 的上游,会将数据源源不断地发送给 A,A 会维护一个时间戳,这个时间戳就是上文提到的低水位,它本质是一个边界,代表不会有晚于这个时间的数据发送给 A,如上图所示。换句话说,低水位后到达的数据很有可能已经丢失了,也没必要参与计算,流处理系统可以略过这些数据或是由应用自行处理,据谷歌表示,这部分丢掉的数据占整体数据的 0.001% 左右,考虑到晚到和乱序已经成为数据流的常态,系统也不可能无休止地等下去,这个误差还是可以接受的。
低水位不是一成不变的,就像真实情况中的水位一样,它会随着 A 处理过的数据的事件时间变化而变化。在 Google MillWheel 模型中,对低水位是这样定义的:
对于一个 C→A 的拓扑片段:
A 的低水位 = min( A 接收到但还未被处理完毕的最老的数据的事件时间,C 的低水位);
如果没有输入流,则低水位的值与最大事件时间相等。
从下图中可以看到,横轴上方是待处理的数据,横轴下方是处理完毕的数据,低水位就是最后一条待处理数据事件后的时间戳,它会随着数据流向前推进。
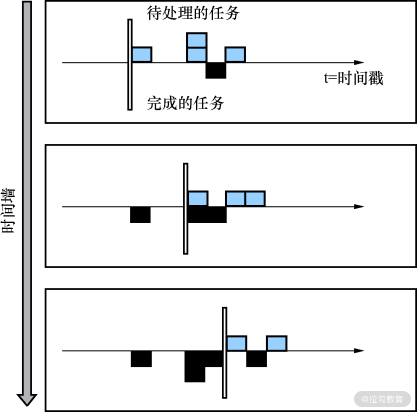
在谷歌 MillWheel 中,可以看到低水位本质上是 A 的一个可变状态。 得到了低水位的值以后,就可以根据该值来判断是否触发计算,以窗口计算为例,如下图所示。
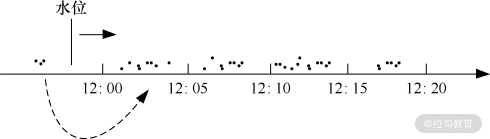
窗口是天然存在的,时长为 5 min,窗口和窗口之间没有重叠。在 A 中接收到的数据根据其事件时间分布在这 4 个窗口中,随着水位不断上涨,当低水位超过第一个窗口的结束时间(12:05)时,根据低水位的定义,有理由相信属于该窗口的数据已经全部到达,这时就可以触发该窗口进行计算,并且在窗口中,可以根据事件时间进行顺序处理,而在低水位之后的数据,虽然事件时间属于第一个窗口(12:00-12:05),但不会触发任何计算,也就不会体现在结果中。低水位可以认为是谷歌公司提出的一个基准,它给出了一个可以容忍数据晚到的最大极限,在低水位之前到达的数据(乱序数据)会参与计算,低水位后到达的数据(晚到数据)将被丢弃。
Google Dataflow 模型
谷歌公司的“MillWheel: Fault-Tolerant Stream Processing at Internet Scale”这篇论文着重介绍了 Google MillWheel 系统如何实现,讨论范围只限于流处理的范畴,可以看成是一篇解决某个具体问题的论文。又过了两年,几乎是发表 MillWheel 的原班人马又发表了一篇论文
“The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing”,这篇论文与 MillWheel 不同,抽象程度非常高,提出了 Dataflow 模型,在一个很高的层次统一了流处理和批处理的计算模型,把这两类问题变成了一个简单的选择题。Structured Streaming 和 Flink 在设计上很大程度借鉴了 Dataflow 模型的设计思想,从这个层次上来说,这两种技术没有什么不同。
作为和数据打交道的工程师,我们不能把无边界数据集切分成有边界数据集,等待一个批次完整后再做处理。相反地,我们应该假设自己永远无法知道数据流是否终结,是否有序,数据何时会变完整。 唯一应该确信的是,新的数据会源源不断,老的数据可能会被撤销或更新,能够让我们应对这个挑战唯一可行的方法是通过一个通用抽象模型,在数据处理的结果准确性、延迟程度和处理成本(这里的处理成本指的是每条数据的处理成本)之间进行取舍。这也是 Dataflow 模型的最大贡献。
这篇论文提出,对于无边界、乱序的数据,可以按照数据本身的特性、事件时间的顺序计算结果;通过以下 4 个维度对数据流进行解构,使用户可以透明地、灵活地组合它们:
计算什么(what);
根据事件时间,哪些数据会参与计算(where);
什么时候触发计算(when);
早期的计算结果如何被修正(how)。
此外,计算逻辑不再和处理的数据类型相关,也就是说,无论处理什么数据,用户只需要编写一套代码。具体来说,Dataflow 包含了:
窗口模型,可以支持非对齐窗口,提供创建并使用基于事件时间窗口的一整套 API,对于 Spark Streaming 有状态和无状态的概念都可以用窗口轻松地进行表达;
触发器模型,可以根据数据流的特征来决定何时输出计算结果的模型,并且提供了一组强有力,且足够灵活的 API 来描述触发语义,比如由低水位触发就是一种触发语义;
增量计算模型,能够将数据变化体现到上述的窗口模型和触发器模型中;
可扩展实现,基于 MillWheel 和 FlumeJava 的可扩展实现;
一系列核心原则,指导 Dataflow 设计的核心原则。
这些元素分别解答了上面四个问题:what、where、when、how。
从 Google MillWheel 系统来看,它对无边界的乱序和晚到数据处理提出了一种解决方法,下面通过几个例子来看看如何将这种解决方法泛化,并推广到不同场景中去。假设输入如下图所示。
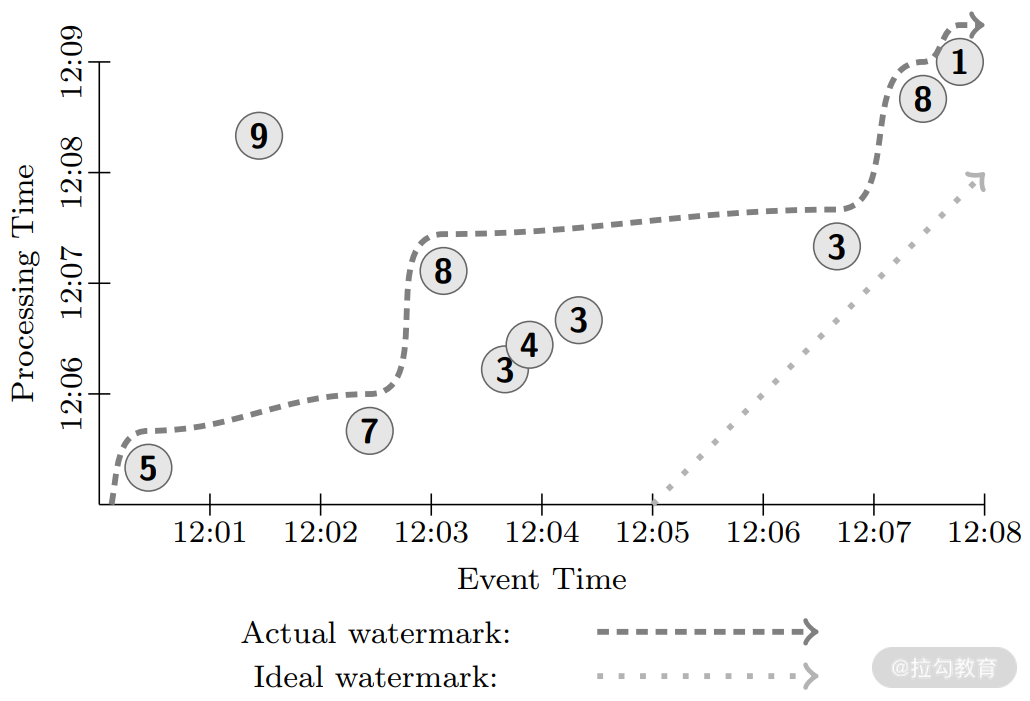
其中,竖轴是处理时间,也就是系统观察到数据的时间,横轴是事件时间,每条数据的值如圆圈数字所示,曲折的曲线是实际的低水位,而直线虚线是理想情况的低水位,可以看到值为 9 的数据落后于水位线,其他数据也存在不同程度的乱序。
下图是我们按照传统批处理来构建求和需求的数据管道。在传统的批处理中,并没有水位线的概念,但是在 Dataflow 的语义中,批处理也引入了水位线的概念。可以看到,在所有数据到来之前,水位线一直不动,直到系统收集到了所有数据,计算发生(下图长方形上沿),水位线开始以平行于事件时间的方向迅速移动,直到无穷远,得到结果 51。这也可以理解为,流处理系统等待所有数据到来后,再开始处理,这样水位线变化和批处理是完全一样的。
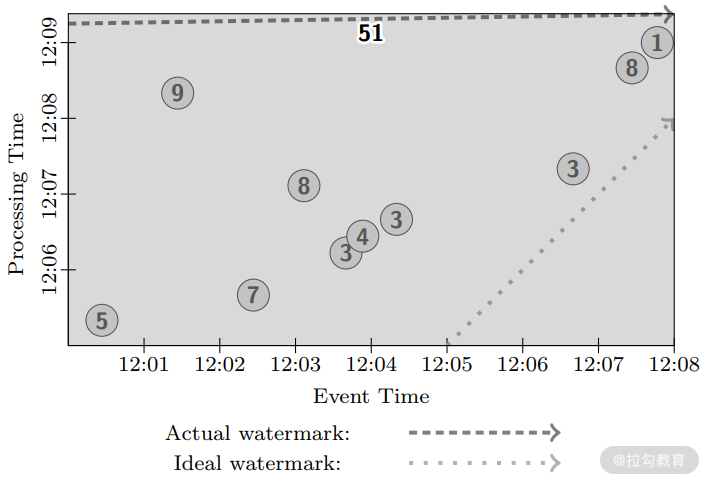
再回到无边界数据中,如果我们采用一个全局窗口,以 MillWheel 那样的方式触发,那么用户永远也等不到结果出现,因为窗口会不断变大,所以必须采用一种新的触发方式,抑或采用别的方式进行开窗操作。
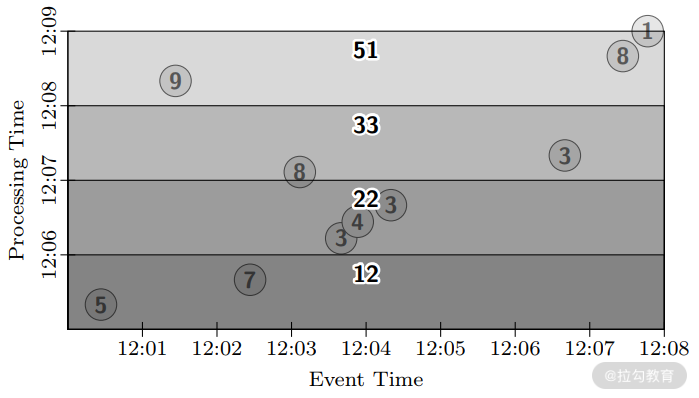
如下图所示,采取的是一种基于处理时间定期触发的方式,不断修正之前计算的结果,从触发计算的结果可以看到,每次计算包含原来窗口的计算结果并进行累计求和,这样延迟为 1 分钟,但是用户只能在最后一分钟才能得到完全正确的结果。
下面我们基于事件时间开窗,还是采用批处理的方式,如下图所示:
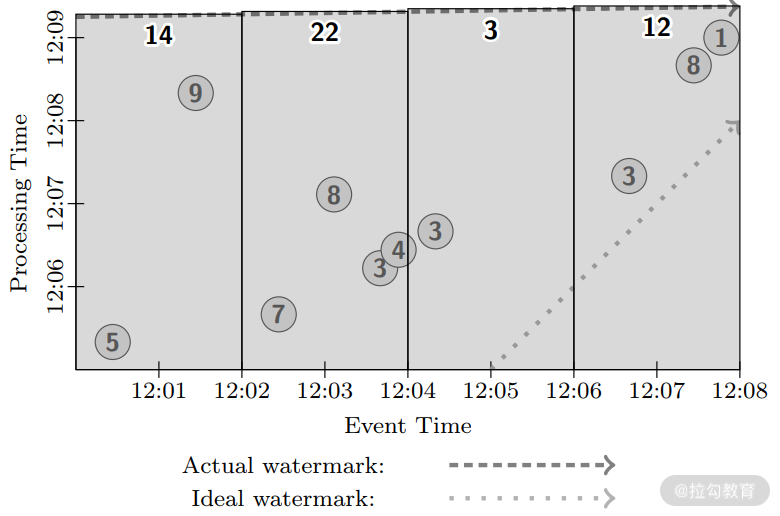
同样,传统的批处理引擎会等待所有数据到来后,再根据事件时间处理,同样也是在水位线到达窗口后触发计算产生结果。现在再来考虑下在基于事件时间的固定窗口下进行微批处理,以一分钟为一个批次。系统每分钟会对窗口中的数据进行处理,而没有像上一个例子中,等待所有数据到来后再处理。每个批次开始时,水位线会从批次开始的时间迅速上升到批次结束的时间,如下图所示。这样每个批次完成后,系统会达到一个新的水位线。我们可以看到在 12:08 的时候,微批处理方式下,3 个窗口已经分别有结果输出,而反观批处理的方式,还没有触发计算,微批处理选择了低延迟和结果的最终准确性,而批处理则选择了最高的延迟和最好的准确性。
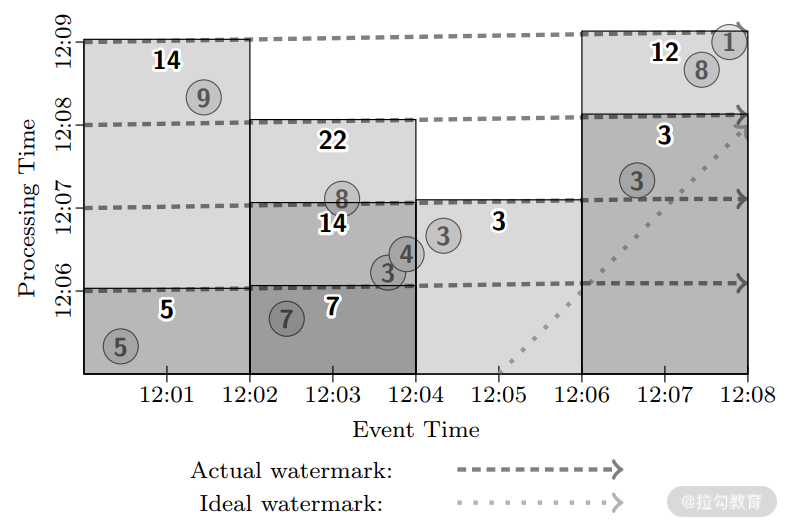
现在我们运用像 MillWheel 这样的流处理引擎来基于事件时间的固定窗口进行实验,如下图所示,该实验类似于 MillWheel 的执行机制。
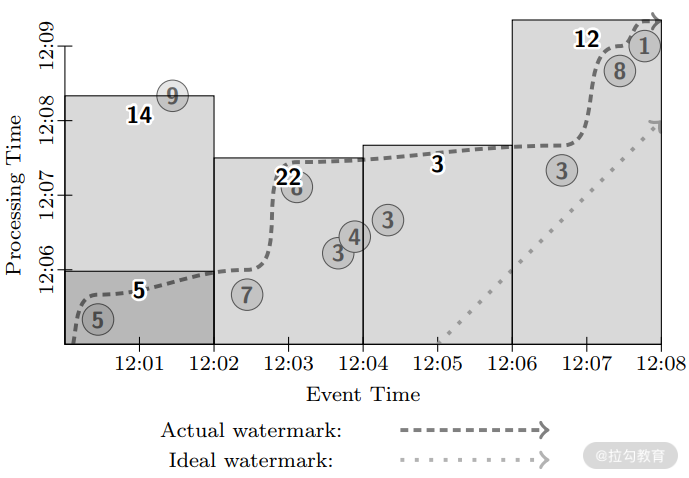
可以看到,当水位线一旦越过固定窗口的结束时间,就会触发计算,但是与 MillWheel 不同的是,虽然值为 9 的数据落后于水位线,但是在这里仍然触发了窗口的计算,这也是 Dataflow 的设计原则之一:永远不要依赖任何数据完整性标记。 从上图中可以看到,只有第一个窗口被触发了两次,其余窗口都只被触发了一次,这种计算方式需要等待水位线漫过窗口才会触发,因此整体上的延迟可能比微批处理系统还要差,这就是单纯依赖水位线可能引起的问题:水位线可能太慢。
那么很自然的,如果我们想降低整体延迟的话,可以考虑将微批的定期触发与 MillWheel 的水位线触发结合起来:系统会周期性地触发,并且在水位线漫过窗口时也会触发。这样整个系统的平均延迟会比微批处理系统更低,因为数据一旦到达就可能会被处理,周期性地触发也会不断进行,它是系统延迟的下限。如下图所示,这种混合的方式在结果准确性、延迟程度和处理成本之间做出了一个适合大部分需求的取舍。
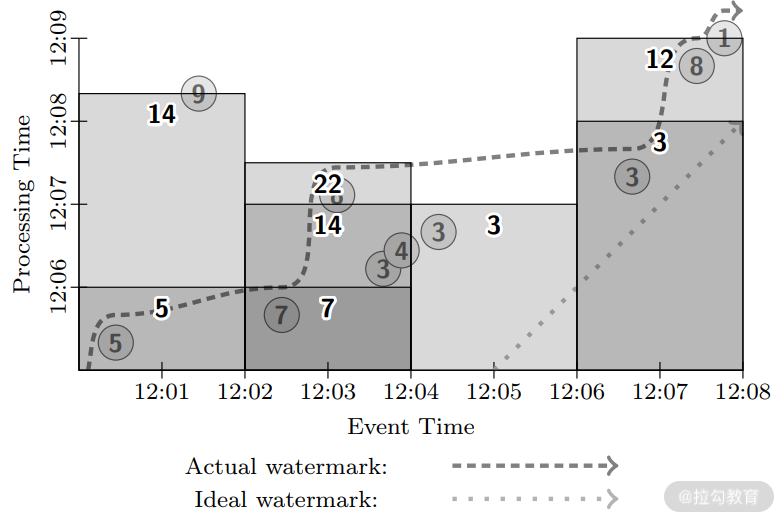
Google Dataflow 精彩的地方在于,无论我们面对的数据类型和处理方式是什么,最后都转化为对结果准确性、延迟程度和处理成本之间的取舍。 取舍也意味着三者不可兼得,像这种“不可能三角”,在实际情况中比较普遍,例如分布式系统的 CAP 原则,宏观经济学中的蒙代尔三角,或许这就是自然界中的普遍规律。但是“不可能三角”并不意味着必须取二舍一,更多情况下是在偏重两点的情况下对三者进行权衡,比如上图中混合触发的方式并没有完全放弃结果准确性、延迟程度和处理成本中的任一点。
在论文中,Dataflow 也介绍了其简洁而表现力丰富的 API,以上图为例,代码如下:
PCollection<KV<String, Integer>> output = input
.apply(Window.into(FixedWindows.of(2, MINUTES))
.trigger(SequenceOf(
RepeatUntil(
AtPeriod(1, MINUTE),
AtWatermark()),
Repeat(AtWatermark())))
.accumulating())
.apply(Sum.integersPerKey());
在这段声明式代码中,可以看到我们定义了窗口的类型(固定窗口)、长度(2 min)和触发的机制(每分钟触发一次;水位线触发;迟到数据触发),另外 accumulating 方法控制了触发的模式,触发模式有 3 种,即累加(Accumulating)、丢弃(Discarding)、累加和撤回(Accumulating & Retracting)。Accumulating 表示窗口一旦触发后,窗口中的数据会被保留,该窗口下一次的触发结果在上一次结果的基础上更新。
你还可以选择 Discarding,该选项表示窗口触发后,窗口的数据会被丢弃,这样窗口每次计算的结果是互相独立的。此外,还可以选择 Accumulating & Retracting,该选项表示窗口的下一次触发会撤回上一次计算的结果重新进行计算,Sum.integersPerKey() 定义了窗口聚合的逻辑。用这种简单的声明方式,我们可以轻易地定义上图中触发计算的逻辑。这套 API 也很好地实现了 what、where、when、how 这四个问题的答案。
我们来看看 Dataflow 在业务场景的应用,如在支付场景中,它们采用的是 Accumulating & Retracting 触发模式加定时触发;还有一些统计场景,在这种场景下,我们希望能够在一个可以接受的时间范围内得到一个相对完整的结果,所以采用了水位线触发,如图 E 所示;而在推荐场景,结果的及时性比基于完备数据的结果有意义得多,所以在这种场景我们采用了处理时间定时触发,如图 D 所示;最后一个是异常检测,异常检测比较适合由数据驱动来进行触发计算,因为一旦异常发生,系统应该马上做出回应,同时这个场景也使用了组合触发器。
小结
本课时主要介绍了 Dataflow 模型,而本课时的内容可以算是整个课程中最重要的理论,目前最新的大数据技术 Spark 和 Flink,从设计理念上都是 Dataflow 的实现,从某种程度上来说,这两种技术也没什么不同,即使目前略有差异,最后也会殊途同归。请你一定要花时间将 Dataflow 这部分的内容吃透,那么再学习 Structured Streaming 和 Flink 就会显得异常的轻松。
Spark Streaming 是基于 RDD 与算子的组合进行编程,批处理也一样,那么流处理是否也有 DataFrame + SQL 组合,它们又是如何和本课时的内容结合呢,下个课时我将为你解答这些问题。
最后给你留一个思考题:
在上一课时,我们将端到端的过程拆分为:输入- 处理 - 输出,那么在处理阶段,Dataflow 是如何实现“恰好一次”的消息送达语义呢?
新一代流式计算框架:Structured Streaming
作为 Spark Streaming 的技术继任者,Structured Streaming 出现得其实有点晚,但是得益于 Spark 庞大的用户群体和社区,Structured Streaming 仍然是实时处理领域一种非常有竞争力和前景的技术。
从前面的 Spark Streaming 可以看到,Spark Streaming 仍然采用 RDD 与算子的组合进行编程。这其实是 Spark 官方不推荐的,它的缺点也显而易见,而 Structured Streaming 的改进是由内而外的,它不仅参考了 MillWheel 系统与 Dataflow 模型,并且还引入 DataFrame 与 SQL 作为自己的编程接口。
本课时的主要内容有:
Structured Streaming 的关键抽象与架构
操作
输入与输出
Structured Streaming 抽象与架构
前面提过,Spark Streaming 的本质是将数据流抽象成流,以微批的方式进行处理,而 Structured Streaming 则不同,它采用的是 Google Dataflow 的思想,将数据流抽象成无边界表(unbounded table),如下图所示:
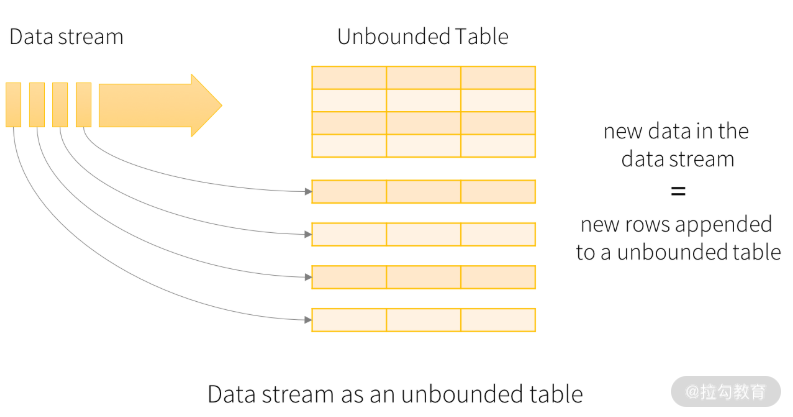
这其实是将流抽象成了批,在这种抽象中,实时的数据流会不停追加到下图这张表中。我们通过对输入表查询的方式得到流处理的结果,并生成结果表。在每个触发间隔,新的数据将追加到输入表中,最终触发计算将会更新结果表,如下图所示:
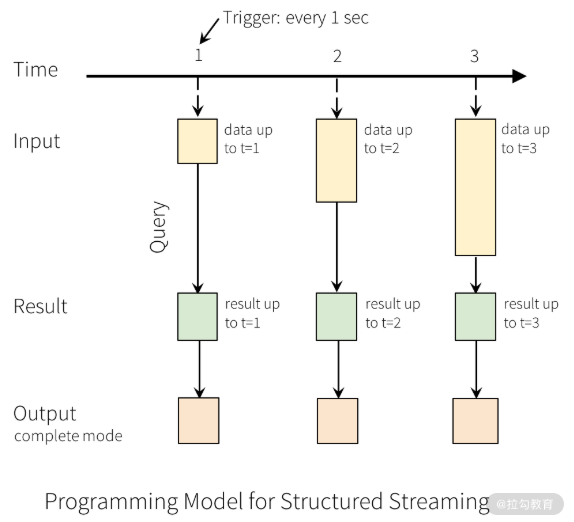
第二行的方块表示结果表(Result Table),第三行的方块表示输出的外部存储,结果表更新到外部存储的方式,也就是输出模式,有 3 种,分别是完全模式、追加模式与更新模式。
完全模式:整个更新的结果表将被写入外部存储,由存储连接器来决定如何写入整张表。上图即为完全模式下的输出结果,一般用来调试。
追加模式:只将上次触发后追加到结果表的数据写到外部存储。这种模式适用于不希望修改已经存在于结果表的数据场景。这是默认的输出模式。在这种模式下,窗口内定时触发生成的中间结果会保存到中间状态,最后一次触发生成的结果才会写到结果表。
更新模式:只将上次触发后更新到结果表的数据写到外部存储。这与完全模式不同,它只输出上次触发后变更的结果记录。如果窗口中不包含聚合逻辑,则意味着不需要修改以前结果表中的数据,其实与追加模式无异。
这些其实就是对应的Dataflow的触发模式。
作为 MillWheel 和 Dataflow 的实现者,实现端到端恰好一次的消息送达保证是必不可少的,为了实现这一目标,Structured Streaming 引入了 Source、Sink 和 StreamExecution 等组件,可以准确地追踪处理进度,以便从重启或重新处理中处理任何类型的故障。每个流式数据源(Source)都具有偏移量(类似于 Kafka 的偏移量)追踪读取进度,以便在故障发生后进行数据回放。在每次触发计算时,执行引擎(StreamExecution)使用检查点和预写日志机制记录来记录数据源偏移量。数据输出(Sink)允许自定义,如设计成幂等效果或者采取两段式提交。结合可重放的数据源与可靠的数据输出,Structured Streaming 可以在任何时候实现端到端的恰好一次消息送达保证。
Structured Streaming 不会保存整个无边界表的数据。它会从数据源读取数据,以增量处理的方式来更新结果,然后丢弃这些源数据,只会保留更新结果所需的最小化中间状态数据(如中间计数)。Structured Streaming 支持基于事件时间处理数据,对于晚到和乱序数据的处理,也同样引入了水位机制,后面会详细介绍。
Structured Streaming 也遵循 Driver 和 Executor 的主从架构,其功能与前面介绍的无异:Driver 负责调度,Executor 负责执行,如下图所示。其中 Driver 和前面介绍的 Driver 差别不大,SQLExecution 变成了 StreamExecution,Executor 多了 StateStore,但是取消了和 Receiver 相关的组件,这是一个比较大的变化,代表接收数据的方式变了。下面我将就这两个组件展开讲解。
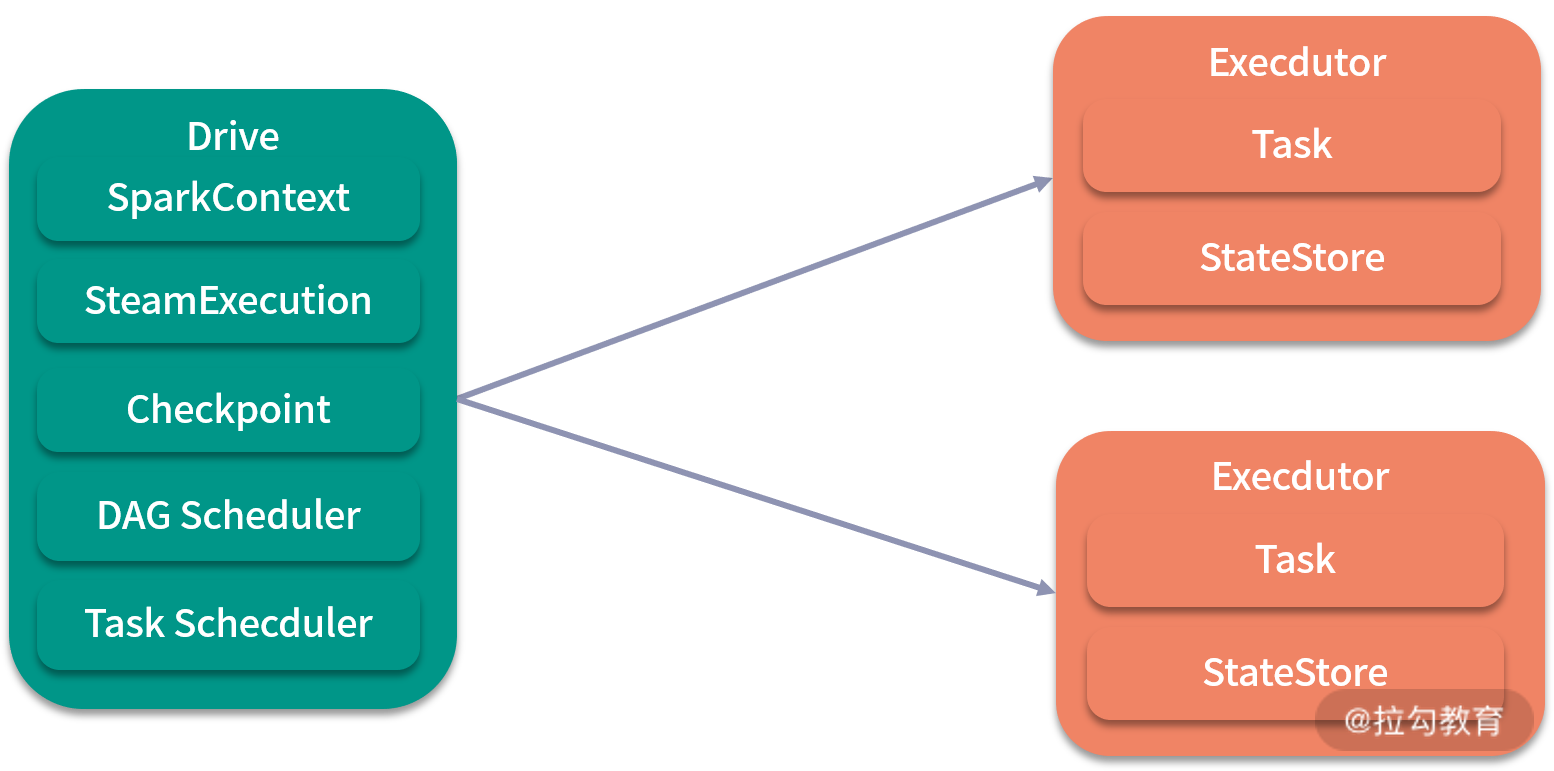
1、 StreamExecution
StreamExecution 是 Structured Streaming 的执行引擎,是 StreamingQuery 接口的实现,在用户的代码中被初始化,start() 方法是这个过程的入口,如下面的代码所示:
...
val lines = spark
.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
...
val query: QueryExecution = wordCounts.map(…).writeStream
.trigger(ProcessingTime(2.seconds))
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()
StreamExecution 有几个比较重要的成员变量:Trigger、LogicalPlan、Sink 和 Source。其中 Trigger 表示用户设定的触发间隔,它决定了一次处理的数据大小,LogicalPlan 代表执行计划,从用户代码的 start 方法开始,就进入了 StreamExecution。首先,可以看见这里设置触发器为每 2 分钟(处理时间)处理一次,用户从 Source 中取得相应的数据;接着根据用户定义的运算逻辑和 Trigger 得到优化过后的 IncrementalExecution,最后再交给 Sink 的 addBatch 方法触发整个过程执行;执行完成后,会通知 Source 修改相应的偏移量。其中 IncrementalExecution 是 Structured Streaming 独有的,它体现了 Structured Streaming 的执行方式是增量微批,主要针对前面 3 种输出模式进行优化。 Source、Sink 和 StreamExecution 抽象了整个流处理过程。从上面的这个过程可以看出,StreamExecution 存在的目的还是要将流式数据转化为 DataFrame 的执行计划并执行,其实最后还是由 SQLExecution 负责执行,也就是与批处理同样的执行引擎。这样的好处就在于无缝对接了 DataFrame 与 Tungsten 巨大的性能优化,并且统一了流处理和批处理的计算引擎。
再来看看 query 初始化的代码,与上一课时中 Dataflow 的样例代码非常相似,在这段代码中我们定义了 Trigger、输出模式、处理逻辑。在处理逻辑中,还可以定义窗口和水位,完全是一种 Dataflow 思想的体现。其中,Trigger 组件的选项有以下几个。
未指定(默认)。如果没有指定触发器,默认的触发逻辑是微批处理,一旦前一个微批完成处理,将立即生成下一个微批进行处理。
固定间隔的微批触发器。将以固定间隔进行触发,固定间隔长度由用户设置(默认的触发器实际上固定间隔长度为 0,即不固定)。如果先前的微批在当前间隔完成,则等到该间隔结束再开始下一个微批处理;如果前一个微批处理需要的时间超过了间隔长度,那么下一个微批将在前一个微批完成后立即执行,而不是等待下一个间隔边界;如果没有数据,则不会触发新的微批处理。固定间隔的微批触发器设定如下:
.trigger(Trigger.ProcessingTime(2000))
一次性微批触发器。查询只会触发一次针对所有可用数据的微批处理,然后自行停止。**这在希望定期启动集群来处理上一个时间段里累积的所有数据,然后停止集群的场景里非常有用。**在某些情况下,可以显著减少性能开销。
.trigger(Trigger.Once())
固定检查点间隔的连续触发器。固定检查点间隔的连续触发器是 Spark 新加入的流执行模式——连续处理的体现。连续处理是 Spark 2.3 中引入的实验性质的流执行模式,可以实现约 1ms 的端到端延迟,并且实现了“至少一次”消息送达保证,而默认的微批处理引擎虽然实现了“恰好一次”的消息送达保证,但是延迟最少也要 100ms 左右。对于某些类型的查询,我们可以通过只修改触发器而不修改应用逻辑来启用该特性。如下:
.trigger(Trigger.Continuous("1 second")) // 只需修改这一行
参数 1 秒指的是检查点间隔,意味着执行引擎每秒会记录一次执行进度,得到的检查点文件将采用和微批执行引擎兼容的格式,所以我们可以在不同触发器之间任意切换,例如以微批触发模式启动的查询,可以以连续触发模式重新启动。无论何时切换,用户都可以获得“至少一次”的消息传递保证。目前连续触发器只支持特定的操作、数据源和输出。
从触发器的多样性来看,Dataflow 中的触发器功能无疑更加强大,既提供了固定周期触发器(AtPeriod),也可以基于水位(AtWatermark)等,但按照 Structured Streaming 的发展速度,相信很快能够实现更多类型的触发器。
2、 StateStore
StateStore 的作用是作为数据流转的状态存储(持久化)。它本质是一个分布式、高可用、分版本的键值存储,提供 get、put、remove 等增删改查操作。它的分片逻辑是算子编号(operatorId)加分区编号(partitionId)。
操作
既然使用了 DataFrame 与 SQL,因此从使用上来说,无论是普通的转换 API 还是 Spark SQL,都是完全一样的,甚至一些封装过的批处理的代码都可以直接复用。那么按照 Dataflow的理论,这就是 what 部分,我们在本节还要解决:
根据事件时间,哪些数据会参与计算(where);
什么时候触发计算(when);
早期的计算结果如何被修正(how)。
前面其实已经介绍过相应的内容,where 由窗口来指定,when 由 Trigger 组件来指定,how 由 watermark 机制来解决。
下面这个例子包含了 what、where、when、how 的声明:
...
val windowDuration = "3000 seconds"
val slideDuration = "1000 seconds"val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.option("includeTimestamp", true)
.load()
val words = lines.as[(String, TimestampType)].flatMap(line =>
line._1.split(" ").map(word => (word, line._2))
).toDF(“word”, “timestamp”)
val windowedCounts = words.groupBy(
window($“timestamp”, windowDuration, slideDuration),
$“word”)
.count().orderBy(“window”)
…
上面这段代码的计算逻辑如下图所示:
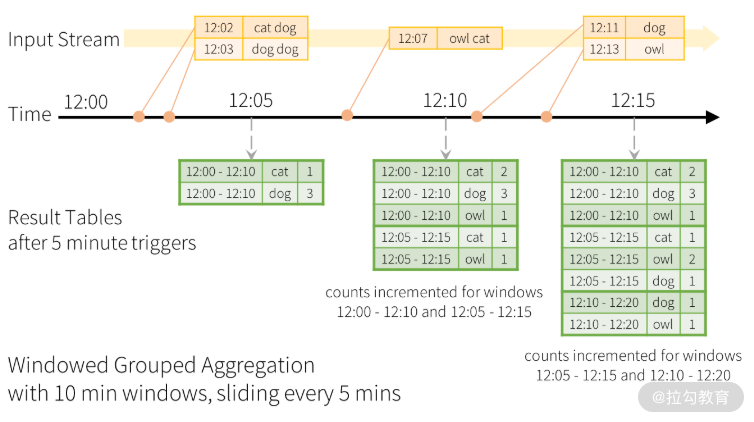
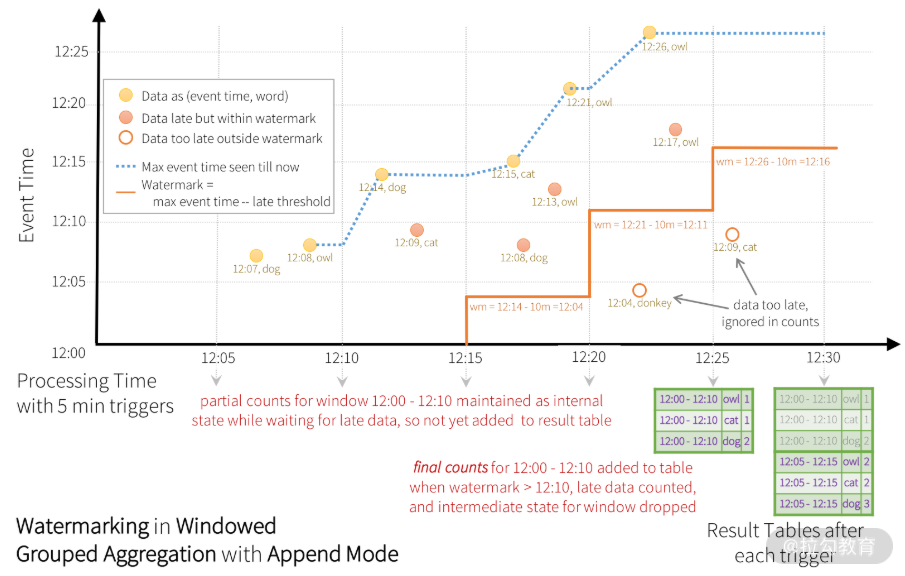
上图中,下方的结果表显示了 5 分钟滑动步长以及 10 分钟大小的窗口聚合结果。窗口跨度也是结果表的一个字段,该字段名为 window,从图中虚线箭头可以看出,触发器(Trigger)采用的是固定间隔触发,每 5 分钟触发一次。聚合的时间窗口是以数据的事件时间为准的,那么这样一定会存在晚到和乱序数据的问题。与 Google Dataflow 模型类似,Structured Streaming 也基于水位机制对晚到和乱序数据提供了相应处理机制,如下图所示:
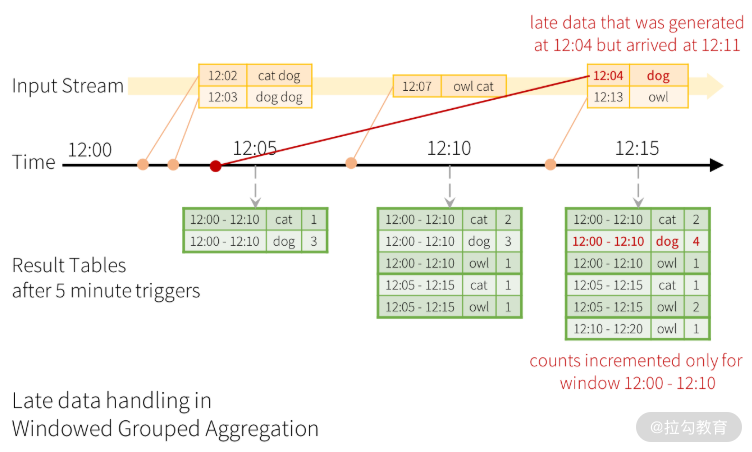
当 12:04 的晚到数据在 12:11 到达时,它实际应该落在 12:00-12:10 的窗口里。在下一次触发时间(12:15)到来时,会更新结果表中的结果。Structured Streaming 会将这种类似聚合需求长时间维护在一个中间状态以便处理晚到数据,但是,如果对于长期运行的应用,对晚到数据无限期等待的代价或许会很大,这时系统应该有一种方法知道什么时候应该丢弃那些过时的中间结果,这样应用也不用再去处理这种晚到数据了。 和 Google Dataflow 一样,Structured Streaming 也采用了水位机制,旨在让计算引擎追踪数据中当前的事件时间,并尝试清除过时的中间状态。在 Structured Streaming 中,水位定义为当前最大的事件时间减去晚到时间最大容忍值。对一个 T 时刻的特定窗口,计算单元会维护其结果状态,当计算单元接收到的晚到数据,满足观察到的最大事件时间减去晚到时间最大容忍值,大于 T 的条件时,都允许晚到数据修改结果状态。换句话说,在水位线前面的数据会被处理,后面的数据则会被丢弃,如下图所示。
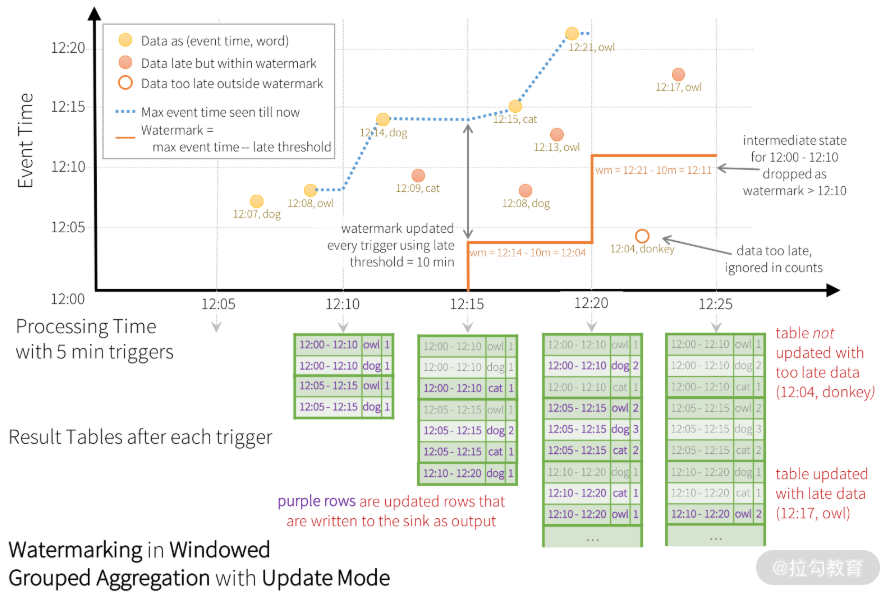
坐标轴中的虚线表示了至今为止计算单元观察到的最大事件时间;浅色实心圆点代表正常处理的数据;深色实心圆点代表了晚到数据,但是在可以容忍的晚到范围之内,而空心圆点数据表示晚到且在不能容忍的时间范围之内。判断是否可以容忍的依据是阶梯形实线(当前最大事件时间减去最大容忍晚到时间),也就是上面说的水位,在每个触发间隔前,会重新计算水位。晚到数据以这种机制被计算、被丢弃,最后更新结果表。
上图是更新输出模式,所以在每个触发点都会输出结果表,晚到数据会在后面的触发点再更新到结果表。
开启 Structured Streaming 的水位机制很简单,只需在代码中加上 withWatermark:
val windowedCounts = words
// 最大容忍时间是5分钟,指定水位基于的列名timestamp
.withWatermark("timestamp", "5 minmutes")
.groupBy(
window(
$"timestamp",
windowDuration,
slideDuration),
$"word")
.count()
想要使用水位机制需要满足一定条件,具体如下。
输出模式必须是更新模式和追加模式。在这两种模式中,会导致结果输出有所差别,在更新模式中,晚到的数据会被处理后再修改结果表,如图f所示,但是在追加模式中,由于不能修改结果表的内容,因此只有在水位超过了窗口结束时间后的下一个触发点才会触发聚合操作,也就是说,在追加模式中,是等所有晚到时间小于最大容忍时间的数据都接收到后,再进行聚合操作,并一次性输出到结果表,如下图所示,这两种模式的差别主要考虑的是接收器的差别,有些接收器不能进行修改,如文件系统。
聚合操作必须有事件时间列,或者有一个基于事件时间列的窗口。
水位机制与聚合操作中使用的时间列必须相同。
水位机制必须在聚合操作之前被调用。
输入与输出
在 Structured Streaming 中,输入被统一抽象为 Source,与 Spark Streaming 中各种不同的输入源不同,输出也被统一抽象为 Sink,这在 Spark Streaming 并没有进行抽象,这么做的好处不言而喻,有了统一的输出抽象,要实现端到端级别的“恰好一次”消息送达语义的实现就不再那么困难。也就是说,Structured Streaming 将整个流处理过程抽象为“Source + StreamExecution + Sink”,对应我们前面讲的“输入-处理-输出”过程,这样 Structured Streaming 就有能力为用户提供端到端级别“恰好一次”消息送达语义的实现。
下面分别来看看 Source 和 Sink 组件。
1. Source
Source 抽象了流式数据从接收到处理之间的过程,它是一个接口,其定义非常简单,如下面的代码所示:
trait Source {
def schema: StructTypedef getOffset: Option[Offset]def getBatch(start: Option[Offset], end: Offset): DataFramedef commit(end: Offset) : Unit = {}def stop(): Unit
}
从这个接口可以看出,无论是哪种数据源,都必须实现 getOffset 方法,这意味着在 Structured Streaming 中,所有数据源都可以向 Spark Streaming 中 Kafka Direct API 那样通过维护偏移量的方式进行容错(回放)。所有的数据源皆是如此,也就意味着,Source 完全抛弃了基于 Receiver 的数据接收方式,省事省心。
目前 Source 的实现类有 KafkaSource 和 FileStreamSource,分别代表了 Kafka 数据源和 HDFS 数据源,还提供了用于测试的控制台数据源、Socket 数据源和 Rate 数据源(Rate 数据源能以指定速率生成数据,生成的每条数据都带有时间戳和消息 ID)的实现类。KafkaSource 很好理解,它本身的数据结构中就自带 offset,可以很好地和接口中 getOffset 相匹配,而 HDFS 的 offset 概念稍微复杂一点,每当调用 getOffset 方法时,HDFS 都会扫描文件夹下的文件,将最新的一些文件进行聚合成批,再赋予一个递增数字,FileStreamSource 对象中会维护一个名为 seenFiles 的 HashMap,用来保存已经扫描过的文件,判断依据是文件年龄和文件名。不管是哪种偏移量(除了 TextSocketSource),最后都会被 StreamExecution 预写日志 WAL 以便进行回放。这与 Spark Streaming 中介绍的思路是完全一样的,只不过 Structured Streaming 已经在这个环节中做到了对用户完全透明并泛化到所有数据源。
下面来看一个从 KafkaSource 中读取数据的例子,在这个例子中,会根据Kafka地址读取消息并将其转换为结构化数据:
......
val spark = SparkSession
.builder
.master("local[2]")
.appName("StructuredNetworkWordCount")
.getOrCreate()import spark.implicits._val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topicA")
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)").as[(String, String)]
.....
2. Sink
Sink 是 Structured Streaming 对输出过程的抽象,目的也是实现对用户透明的容错处理。与Source 对应,Sink 也有 FileStreamSink、KafkaSink、ForeachSink 等,分别对应的输出为 HDFS、Kafka 和自定义 Sink,此外还提供了用于测试的控制台输出和内存输出的实现类。Sink 接口非常简单,如下面的代码所示:
trait Sink {def addBatch(batchId: Long, data: DataFrame): Unit
}
其中只定义了一个方法 addBatch,整个计算过程都是由这个方法触发执行的,现在来深入了解下这个方法,以 KafkaSink 为例:
override def addBatch(batchId: Long, data: DataFrame): Unit = {if (batchId <= latestBatchId) {logInfo(s"Skipping already committed batch $batchId")} else {KafkaWriter.write(sqlContext.sparkSession,data.queryExecution, executorKafkaParams, topic)latestBatchId = batchId}}
在这个方法中,先判断了是否是重复提交的数据,然后由 KafkaWriter 的 write() 方法进行写入,写入完成后,更新最新的 batchId。接下来我们来看看 write() 方法:
def write(sparkSession: SparkSession,queryExecution: QueryExecution,kafkaParameters: ju.Map[String, Object],topic: Option[String] = None): Unit = {val schema = queryExecution.analyzed.outputvalidateQuery(queryExecution, kafkaParameters, topic)queryExecution.toRdd.foreachPartition { iter =>val writeTask = new KafkaWriteTask(kafkaParameters, schema, topic)Utils.tryWithSafeFinally(block = writeTask.execute(iter))(finallyBlock = writeTask.close())
}
在这个方法中,由 queryExecution 的 toRDD 方法触发计算开始,在最后 foreachPartition 操作中完成写入 Kafka 的操作。最后的写入操作是在 KafkaWriteTask 的 execute 方法完成的,如下面的代码所示:
def execute(iterator: Iterator[InternalRow]): Unit = {producer = CachedKafkaProducer.getOrCreate(producerConfiguration)while (iterator.hasNext && failedWrite == null) {val currentRow = iterator.next()val projectedRow = projection(currentRow)val topic = projectedRow.getUTF8String(0)val key = projectedRow.getBinary(1)val value = projectedRow.getBinary(2)if (topic == null) {throw new NullPointerException(s"null topic present in the data. Use the " +s"${KafkaSourceProvider.TOPIC_OPTION_KEY} option for setting a default topic.")}// 由上面构建好的topic、key和value生成最后待插入的消息val record = new ProducerRecord[Array[Byte], Array[Byte]](topic.toString, key, value)val callback = new Callback() {override def onCompletion(recordMetadata: RecordMetadata, e: Exception): Unit = {if (failedWrite == null && e != null) {failedWrite = e}}}producer.send(record, callback)}
}
插入完成后,按照前面课时的思路,还要更新 Source 的偏移量,这由 StreamExecution 中的 batchCommitLog.add(currentBatchId) 完成。整个过程与 Spark Streaming 中实现的过程大同小异,不同的是这个过程更加透明,用户不用直接维护偏移量,比起 Spark Streaming 的各种 API 调用,更加优雅。但是目前的版本,Spark Streaming 中的问题仍然存在,还是无法在事务层面保证处理-输出的这个环节做到完美的“恰好一次”,只能做到“至少一次”,需要通过使输出幂等来实现,或者使用 Structured Streaming 提供的去重操作:
// 参数为去重列名
streamingDf.dropDuplicates("uniquecolumn")
目前 FileStreamSink 提供了幂等保证,用户不用自己实现幂等逻辑,而 ForeachSink 则提供了自定义的 Writer,因此是否幂等取决于用户自己是否实现,目前 ForeachWriter 只有 Scala 和 Java 接口。ForeachWriter 代码如下:
abstract class ForeachWriter[T] extends Serializable {def open(partitionId: Long,version: Long): Booleandef process(value: T): Unitdef close(errorOrNull: Throwable): Unit
}
ForeachWriter 是一个抽象类,任何继承它的类必须重写 open、process 和 close 这 3 个方法,这 3 个方法会在 Executor 上依次被调用:
open 方法的参数 partitionId 代表了输出分区ID;
version 是一个单调递增的 ID,随着每次触发而增加,我们可以通过两个参数判断这一批数据是否继续输出。如果返回值为 true,就调用 process 方法;如果返回值为 false,则不会调用 process 方法。
每当调用 open 方法时,close 方法也会被调用(除非 JVM 因为某些错误而退出),因此我们可以在 open 方法中打开外部存储连接,并在 close 方法中关闭外部存储连接。
小结
本课时介绍了 Structured Streaming 的相关内容,可以看到 Structured Streaming 忠实地复刻了 Dataflow 思路与实现,但是在声明计算逻辑环节复用了 Spark的DataFrame + Spark SQL,使得流处理编程变得十分简单,相信你也有相同的体会。另外,这样一来的话,Spark编程的批处理与流处理在形式上就得到了完美的统一,相信你在完成了本模块的实践课时后,体会会更深。
最后给你留一个思考题:
在流处理中,连接操作涉及两个数据源的操作,会相对比较复杂,其中每个数据源都有可能是静态的数据,或者是动态的数据流,那么 Structured Streaming 是如何处理连接操作的呢,它支持哪些类型的连接,又有什么限制呢?
如何对 Spark 流处理进行性能调优?
本课时会从硬件、框架的使用和配置这三个维度介绍性能调优,最后再介绍流处理中出现得最多的一个问题场景:反压。
本课时的主要内容有:
硬件优化
使用层面的优化
配置优化
硬件优化
Spark Streaming 与 Spark 离线计算相比,I/O 并没有那么密集,整体负载也低于 Spark 离线计算,数据基本存放于 Executor 的内存中。但是,它对于 CPU 的要求相对较高,例如更低的延迟(较小的批次间隔)、大量微批作业的同时提交与处理。但是对基于时间窗口的操作以及对状态进行操作的算子来说,需要在内存中将这部分数据缓存,如果时间窗口跨度较长的话,需要的内存也会比较高,像 updateStateByKey 这种算子,更需要全程追踪状态,这也需要耗费不少内存,因此 Spark Streaming 集群的硬件配置也可参照离线计算型的配置。
使用层面的优化
对于使用层面的下列优化,有些是使用技巧,有些是在某些场景下得到的经验,你可以根据自己的需求选择。
1. 批次间隔
虽然说 Spark Streaming 号称可以达到毫秒级(理论上 50ms)的延迟,但是在设置批次间隔时,一般不会低于 0.5s,否则大量的作业同时提交会引起负载过高。这个值可以通过反复实验来得到,我们可以先将该值设置为比较大的值,比如 10s,如果作业很快就完成了,我们可以减小批次间隔,直到 Spark Streaming 在这个时间段内刚好处理完上一批的数据,此时的批次间隔就是比较合适的了。
2. 窗口大小与滑动步长
这两个配置的值同样对性能有巨大影响,当性能低下时,可以考虑减小窗口大小和增加滑动步长。
3. updateStateByKey 与 mapWithState
在绝大多数情况下,使用 mapWithState 而不用 updateStateByKey,实践证明,前者的延迟表现和能够同时维护的 key 数量都远远优于后者。
4. mapPartition 与 map
在与外部数据库交互,如写操作时,使用 mapPartition 而不要使用 map 算子,mapPartition 会在处理每个分区时连接一次数据库,而不像 map 每条数据连接一次数据库,性能优势明显。
5. reduceByKey/aggregateByKey 与 groupByKey
前者的聚合性能要明显优于后者,因此尽量使用 reduceByKey/aggregateByKey。
6. 反函数
在前面的课时中,我们介绍了 reduceByKeyAndWindow 的反函数重载版本,这对于跨度很大的时间窗口,且滑动窗口与上一个时间窗口有较大重合部分的场景来说尤其有用。这里解释下反函数的由来,从滑动时间窗口的原理上来说,如果:

公式 1
则:

公式 2
如果把 S* 重叠部分的计算结果 看成自变量,S *该滑动窗口的处理结果 看成因变量,那么就可以认为公式 2 是公式 1 的反函数。反函数的主要作用是避免重复计算。
7. 序列化
采用 Kyro 进行序列化,可以改善 GC。
8. 数据处理的并行程度
可以通过增大计算的并行度来提升性能,如 reduceByKey、join 等,如果不指定,并行度为配置项 spark.default.parallelism 的值,如果遇到数据倾斜还可以使用 repartition。
9. filter 与 coalesce
与离线计算相似,在 filter 算子作用后,会产生大量零碎的分区,不利于计算,可以在后面接 coalesce 或者 repartition 算子将其进行合并或者重分。
10. 将 Checkpoint 存储到 Alluxio
使用 Alluxio 作为 Spark Streaming 的 Checkpoint 存储介质,这有助于提高读写 Checkpoint 的性能。
11. 资源调度
如果使用统一资源管理平台,那么批处理作业与流处理作业有可能会运行在同一个节点的不同容器中。如果批处理作业负载较高,就会对流处理作业造成较大影响,建议分离部署。如果从提高资源利用率的角度出发,确实需要部署在一个集群,那么建议采用 Hadoop 2.6 以后引入的新特性:基于标签的调度(Label based scheduling),使流处理计算作业得到稳定且独立的计算资源。
12. 缓存数据与清除数据
与 Spark 离线计算一样,需要重复计算的数据需要用 cache 算子进行缓存。但是,这些缓存会不断占用内存,可以设置 spark.streaming.unpersist 为 true,让 Spark 来决定哪些数据需要缓存,否则需要手动控制,这样通常性能开销还会大一点。
配置优化
配置方面的优化具体如下
1. JVM GC
在 Executor 的堆足够大(大概 30GB 以上)时,使用 G1 GC 代替 CMS GC,否则采用 Parallel GC,如下所示:
--conf "spark.executor.extraJavaOptions=-XX:+UseG1GC"
--conf "spark.executor.extraJavaOptions=-XX:+UseParallelGC"
2. spark.streaming.blockInterval
该参数设置了 Receiver 的接收块间隔时间,默认为 200ms。对于大多数 Receiver,接收的数据在存储到 Spark 的 Executor 之前,会先聚合成块的形式,每个块就是一个分区,也就是说,每个批次间隔的数据中,块的数量决定了后面类似 map 算子所处理的任务数,这也影响了数据处理的并行程度。一个批次的数据块的数量(分区数)的计算公式为:batch interval /spark.streaming.blockInterval,分子为我们设置的批次间隔,假设为 2s,那么每个批次会有 2000/200=10 个数据块。如果这个数字低于节点的 CPU 核数,说明没有充分发挥 CPU 的能力,那么可以考虑降低 spark.streaming.blockInterval 的值,但是一般也不推荐低于 50 ms。
3. 反压
反压在流处理场景里面比较常见,是每个流处理框架必须考虑的问题。反压的实质是,当每批数据处理时间大于批次间隔时间时,长久以往,数据会在 Executor 中的内存中迅速累积,内存会很快溢出,如果设定持久化存储基本为硬盘,则会出现大量磁盘 I/O,增加延迟。
防止反压的关键是做好流量控制,如果一味地限制 Receiver 接收数据的速度,会降低整个集群的资源利用率。Spark Streaming 在 1.5 之后引入了反压机制,可以通过 spark.streaming. backpressure.enabled 来开启,开启后系统会根据每一批次作业调度与完成的情况让系统按照处理数据的速率来接收数据。实际上,就是限制 Receiver 接收数据的速度,上限由 spark.streaming. receiver.maxRate 设置,如果以 Kafka Direct 方式接收的话,上限由 spark.streaming.kafka.maxRatePerPartition 来配置。开启反压机制后,资源利用率肯定会有所下降,因此 spark.streaming.backpressure.enabled 默认关闭。
Spark Streaming 是利用 PID(proportional-integral-derivative)算法来确定新的数据接收速率的,开启反压机制后的速率公式为(单位:条/秒):
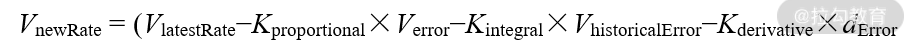
其中,VnewRate 为下一批次的接收速率;VlatestRate 为在上一批次中所确定当前批次的接收速率;Verror 为 VlatestRate 减去当前批次的实际处理速率;VhistoricalError 为当前批次等待调度的时间乘以当前批次的处理速率再除以批次间隔;dError 为Verror 减去上一批次的 Verror 的差,除以当前批次完成的时间,减去上一批次完成的时间的结果。Kproportional、Kintegral、Kderivative 为 PID 算法的 3 个重要的调适参数。
小结
与 Spark 批处理调优一样,流处理调优也是一个与业务紧密结合的问题,不光需要对原理、参数、配置非常熟悉,还需要大量的实践。
最后给你留一个思考题:
在很多场景中,为了提高资源利用率,很多时候,集群中既长驻着流处理作业也跑着批处理作业,这样做有什么不好的影响呢?
实战:如何对股票交易实时价格进行分析?
在流处理这个模块中,我们已经学习了 Spark 的两种流处理解决方案,在本课时中,我们将进行一个略微复杂的实践,也是我们本模块的实践环节。
在本模块中,我们将对实时股票价格数据进行处理。我们将在本课时中计算一个在股票分析中的比较常见的指标:CCI。
实时股票价格数据蕴含着巨大的价值,如何能在交易过程中敏锐地捕捉到机会非常重要,所以这就是一个非常典型的流处理应用场景。下面介绍一个股票交易实时分析应用:计算分钟级 CCI。
CCI(Commodity Channel Index),也被称为顺势指标。它最早用于期货市场的判断,后期才运用于股票市场的研判,并被广泛使用。与大多数单一利用股票的收盘价、开盘价、最高价或最低价而发明出的各种技术分析指标不同,CCI 指标是根据统计学原理,引进价格与固定期间的股价平均区间的偏离程度的概念,强调股价平均绝对偏差在股市技术分析中的重要性,是一种比较独特的技术指标。CCI 有事件时间区间的概念,很适合用 Structured Streaming 来完成。
CCI 有日 CCI、周 CCI、年 CCI 以及分钟 CCI 等很多种类型。本例主要实现的是 30 分钟 CCI(一个周期为 30 分钟),其计算公式为:
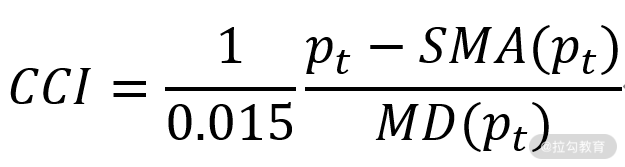
其中
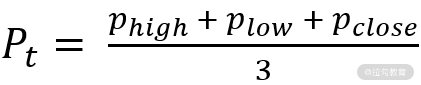
这个公式为给定 30 分钟内的最高价、最低价和收盘价的平均值,SMA 是 N 个周期的 pt 的移动平均值,MD 是 pt 的平均离差,本例中 N = 3。
再来看看数据,目前股票的实时数据来源渠道有很多,如 Wind、大智慧等,都提供了自己的接口。假定数据已经被实时拉取并灌入到消息队列中,在这个过程中,有可能会出现数据晚到和乱序的现象。为了结果的准确,在处理时需要考虑这些情况,来看一条数据样例:
000002.SZ, 1502126681, 22.71, 21.54, 22.32, 22.17
其中每个字段分别是股票代码、事件时间戳、现价、买入价、卖出价、成交均价。
下面我们来看看 CCI 的计算方式,SMA、MD 都需要 pt 序列计算得到,而从公式可以看到计算 pt 需要先得到 30 分钟内的最高价、最低价和收盘价。当 pt 序列按照时间被保存到数据库后,那么计算 CCI 就非常容易了,一个应用定期进行查询并计算即可,所以计算 CCI 的核心是计算 pt。
下面的代码采用 Structured Streaming 对数据流进行处理,得到最高价、最低价和收盘价并求其均值,从而得到 pt 序列。其中,我们需要开发一个求收盘价的 UDAF,然后还要开发一个输出到 HBase 的 Sink,正好可以把我们前面学到的知识用上。
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.functions._import org.apache.spark.sql.types.TimestampTypeimport org.apache.spark.sql.streaming.Triggerimport java.sql.Timestamp
<span class="hljs-class"><span class="hljs-keyword">object</span> <span class="hljs-title">StockCCICompute</span> </span>{
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">main</span></span>(args: <span class="hljs-type">Array</span>[<span class="hljs-type">String</span>]): <span class="hljs-type">Unit</span> = {
<span class="hljs-keyword">val</span> spark = <span class="hljs-type">SparkSession</span>
.builder
.appName(<span class="hljs-string">"StockCCICompute"</span>)
.getOrCreate()
<span class="hljs-comment">//分别设置window长度、容忍最大晚到时间和触发间隔</span>
<span class="hljs-keyword">val</span> windowDuration = <span class="hljs-string">"30 minutes"</span>
<span class="hljs-keyword">val</span> waterThreshold = <span class="hljs-string">"5 minutes"</span>
<span class="hljs-keyword">val</span> triggerTime = <span class="hljs-string">"1 minutes"</span> <span class="hljs-keyword">import</span> spark.implicits._ spark.readStream
.format(<span class="hljs-string">"kafka"</span>)
.option(<span class="hljs-string">"kafka.bootstrap.servers"</span>, <span class="hljs-string">"broker1:port1,broker2:port2"</span>)
.option(<span class="hljs-string">"subscribe"</span>, <span class="hljs-string">"stock"</span>)
.load()
.selectExpr(<span class="hljs-string">"CAST(key AS STRING)"</span>, <span class="hljs-string">"CAST(value AS STRING)"</span>)
.as[(<span class="hljs-type">String</span>, <span class="hljs-type">String</span>)]
<span class="hljs-comment">//解析数据</span>
.map(f => {
<span class="hljs-keyword">val</span> companyNo = f._1
<span class="hljs-keyword">val</span> infos = f._2.split(<span class="hljs-string">","</span>)
(f._1,infos(<span class="hljs-number">0</span>),infos(<span class="hljs-number">1</span>),infos(<span class="hljs-number">2</span>),infos(<span class="hljs-number">3</span>),infos(<span class="hljs-number">4</span>))
})
.toDF(<span class="hljs-string">"companyno"</span>,<span class="hljs-string">"timestamp"</span>,<span class="hljs-string">"price"</span>,<span class="hljs-string">"bidprice"</span>,<span class="hljs-string">"sellpirce"</span>,<span class="hljs-string">"avgprice"</span>)
.selectExpr(
<span class="hljs-string">"CAST(companyno AS STRING)"</span>,
<span class="hljs-string">"CAST(timestamp AS TIMESTAMP[DF1] )"</span>,
<span class="hljs-string">"CAST(price AS DOUBLE)"</span>,
<span class="hljs-string">"CAST(bidprice AS DOUBLE)"</span>,
<span class="hljs-string">"CAST(sellpirce AS DOUBLE)"</span>,
<span class="hljs-string">"CAST(avgprice AS DOUBLE)"</span>)
.as[(<span class="hljs-type">String</span>,<span class="hljs-type">Timestamp</span>,<span class="hljs-type">Double</span>,<span class="hljs-type">Double</span>,<span class="hljs-type">Double</span>,<span class="hljs-type">Double</span>)]
<span class="hljs-comment">//设定水位</span>
.withWatermark(<span class="hljs-string">"timestamp"</span>, waterThreshold)
.groupBy(
window($<span class="hljs-string">"timestamp"</span>,
windowDuration),
$<span class="hljs-string">"companyno"</span>)
<span class="hljs-comment">//求出最高价、最低价和收盘价,其中收盘价需要自己开发UDAF</span>
.agg(
max(col(<span class="hljs-string">"price"</span>)).as(<span class="hljs-string">"max_price"</span>),
min(col(<span class="hljs-string">"price"</span>)).as(<span class="hljs-string">"min_price"</span>),
<span class="hljs-type">ClosePriceUDAF</span>(col(<span class="hljs-string">"price"</span>).as(<span class="hljs-string">"latest_price"</span>)))
.writeStream
.outputMode(<span class="hljs-string">"append"</span>)
.trigger(<span class="hljs-type">Trigger</span>.<span class="hljs-type">ProcessingTime</span>(triggerTime))
<span class="hljs-comment">//输出到HBase中</span>
.foreach(<span class="hljs-type">HBaseWriter</span>)
.start()
.awaitTermination() }
}
代码中选取了 append 模式,所以分析应用不用处理结果发生变化的情况。另外代码风格特意采用了 Dataflow 的数据管道式,本例中的数据处理的逻辑是完全可以应用于批处理的。开发的 UDAF 目的是求出收盘价,也就是窗口内时间戳最大的那一条,代码如下:
import org.apache.spark.sql.expressions._import org.apache.spark.sql.types._import org.apache.spark.sql.Rowimport org.apache.spark.sql.functions._import java.sql.Timestamp
<span class="hljs-class"><span class="hljs-keyword">object</span> <span class="hljs-title">ClosePriceUDAF</span> <span class="hljs-keyword">extends</span> <span class="hljs-title">UserDefinedAggregateFunction</span> </span>{ <span class="hljs-comment">//指定输入的类型</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">inputSchema</span></span>: <span class="hljs-type">StructType</span>
= <span class="hljs-type">StructType</span>(<span class="hljs-type">Array</span>(<span class="hljs-type">StructField</span>[<span class="hljs-type">DF1</span>] (<span class="hljs-string">"price"</span>, <span class="hljs-type">DoubleType</span>, <span class="hljs-literal">true</span>)))
<span class="hljs-comment">//中间结果只需要两个字段:价格、时间</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">bufferSchema</span></span>: <span class="hljs-type">StructType</span>
= <span class="hljs-type">StructType</span>(
<span class="hljs-type">Array</span>(<span class="hljs-type">StructField</span>(<span class="hljs-string">"latestprice"</span>, <span class="hljs-type">DoubleType</span>, <span class="hljs-literal">true</span>),
<span class="hljs-type">StructField</span>(<span class="hljs-string">"timestamp"</span>, <span class="hljs-type">TimestampType</span>, <span class="hljs-literal">true</span>))) <span class="hljs-comment">//指定最后输出的类型</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">dataType</span></span>: <span class="hljs-type">DataType</span> = <span class="hljs-type">DoubleType</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">deterministic</span></span>: <span class="hljs-type">Boolean</span> = <span class="hljs-literal">true</span>
<span class="hljs-comment">//初始化中间结果</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">initialize</span></span>(buffer: <span class="hljs-type">MutableAggregationBuffer</span>): <span class="hljs-type">Unit</span>
= {
buffer(<span class="hljs-number">0</span>) = <span class="hljs-number">0</span>D
buffer(<span class="hljs-number">1</span>) = <span class="hljs-number">0</span>L
}
<span class="hljs-comment">//更新时间晚的价格为中间</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">update</span></span>(buffer: <span class="hljs-type">MutableAggregationBuffer</span>, input: <span class="hljs-type">Row</span>): <span class="hljs-type">Unit</span> = {
<span class="hljs-keyword">val</span> priceNow = input.getAs[<span class="hljs-type">Double</span>](<span class="hljs-string">"price"</span>)
<span class="hljs-keyword">val</span> timestampNow = input.getAs[<span class="hljs-type">Timestamp</span>](<span class="hljs-string">"timestamp"</span>)
<span class="hljs-keyword">val</span> timestampBuf = buffer.getAs[<span class="hljs-type">Timestamp</span>](<span class="hljs-string">"timestamp"</span>)
<span class="hljs-keyword">if</span>(timestampNow.after(timestampBuf)){
buffer(<span class="hljs-number">0</span>) = priceNow
buffer(<span class="hljs-number">1</span>) = timestampNow
}
}
<span class="hljs-comment">//合并中间结果</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">merge</span></span>(buffer1: <span class="hljs-type">MutableAggregationBuffer</span>, buffer2: <span class="hljs-type">Row</span>): <span class="hljs-type">Unit</span> = {
<span class="hljs-keyword">val</span> buffer1Timestamp = buffer1.getAs[<span class="hljs-type">Timestamp</span>](<span class="hljs-string">"timestamp"</span>)
<span class="hljs-keyword">val</span> buffer2Timestamp = buffer2.getAs[<span class="hljs-type">Timestamp</span>](<span class="hljs-string">"timestamp"</span>)
<span class="hljs-keyword">if</span>(buffer2Timestamp.after(buffer1Timestamp)){
buffer1(<span class="hljs-number">0</span>) = buffer2.getAs[<span class="hljs-type">Double</span>](<span class="hljs-string">"price"</span>)
buffer1(<span class="hljs-number">1</span>) = buffer2Timestamp
}
}
<span class="hljs-comment">//返回最后的结果</span>
<span class="hljs-keyword">override</span> <span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">evaluate</span></span>(buffer: <span class="hljs-type">Row</span>): <span class="hljs-type">Any</span> = buffer.getAs[<span class="hljs-type">Double</span>](<span class="hljs-string">"price"</span>)
}
最后为了保证结果的正确性,需要实现自定义 Writer。这也是选取 HBase 的原因,因为插入到 HBase 的操作天然就具有幂等性(重复 Put 会覆盖之前的值),所以可以实现端到端的恰好一次的消息送达的效果,代码如下:
import org.apache.spark.sql.ForeachWriterimport org.apache.spark.sql.Rowimport org.apache.hadoop.hbase.HBaseConfigurationimport org.apache.hadoop.hbase.client.ConnectionFactoryimport org.apache.hadoop.hbase.client.Connectionimport org.apache.hadoop.hbase.TableNameimport org.apache.hadoop.hbase.client[DF1] .Putimport org.apache.hadoop.hbase.util.Bytes
<span class="hljs-class"><span class="hljs-keyword">object</span> <span class="hljs-title">HBaseWriter</span> <span class="hljs-keyword">extends</span> <span class="hljs-title">ForeachWriter</span>[<span class="hljs-type">Row</span>] </span>{
<span class="hljs-keyword">var</span> conn: <span class="hljs-type">Connection</span> = <span class="hljs-literal">null</span>
<span class="hljs-comment">//初始化HBase连接</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">open</span></span>(partitionId: <span class="hljs-type">Long</span>, version: <span class="hljs-type">Long</span>): <span class="hljs-type">Boolean</span> = {
<span class="hljs-keyword">val</span> conf = <span class="hljs-type">HBaseConfiguration</span>.create()
conn = <span class="hljs-type">ConnectionFactory</span>.createConnection(conf) <span class="hljs-literal">true</span>
}
<span class="hljs-comment">//获取结果表中的字段,并以窗口标识为行键,插入HBase中</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">process</span></span>(row: <span class="hljs-type">Row</span>): <span class="hljs-type">Unit</span> = {
<span class="hljs-comment">//window字段作为rowkey供分析应用查询</span>
<span class="hljs-keyword">val</span> window = row.getAs[<span class="hljs-type">String</span>](<span class="hljs-string">"window"</span>)
<span class="hljs-keyword">val</span> maxPrice = row.getAs[<span class="hljs-type">Double</span>](<span class="hljs-string">"max_price"</span>)
<span class="hljs-keyword">val</span> minPrice = row.getAs[<span class="hljs-type">Double</span>](<span class="hljs-string">"min_price"</span>)
<span class="hljs-keyword">val</span> latestPrice = row.getAs[<span class="hljs-type">Double</span>](<span class="hljs-string">"latest_price"</span>)
<span class="hljs-keyword">val</span> table = conn.getTable(<span class="hljs-type">TableName</span>.valueOf(<span class="hljs-string">"CCI"</span>))
<span class="hljs-keyword">val</span> put = <span class="hljs-keyword">new</span> <span class="hljs-type">Put</span>(<span class="hljs-type">Bytes</span>.toBytes(<span class="hljs-string">"window"</span>))
<span class="hljs-comment">//列族为cf,列名分别为max_price、min_price、latest_price</span>
put.addColumn(<span class="hljs-type">Bytes</span>.toBytes(<span class="hljs-string">"cf"</span>), <span class="hljs-type">Bytes</span>.toBytes(<span class="hljs-string">"max_price"</span>), <span class="hljs-type">Bytes</span>.toBytes(maxPrice))
put.addColumn(<span class="hljs-type">Bytes</span>.toBytes(<span class="hljs-string">"cf"</span>), <span class="hljs-type">Bytes</span>.toBytes(<span class="hljs-string">"min_price"</span>), <span class="hljs-type">Bytes</span>.toBytes(minPrice))
put.addColumn(<span class="hljs-type">Bytes</span>.toBytes(<span class="hljs-string">"cf"</span>), <span class="hljs-type">Bytes</span>.toBytes(<span class="hljs-string">"latest_price"</span>), <span class="hljs-type">Bytes</span>.toBytes(latestPrice))
table.put(put)
table.close()
}
<span class="hljs-comment">//关闭连接</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">close</span></span>(errorOrNull: <span class="hljs-type">Throwable</span>): <span class="hljs-type">Unit</span> = {
conn.close()
}}
Structured Streaming 用窗口起点--窗口终点作为 window 字段的值,也就是窗口唯一标识。在入库时,该值作为行键方便应用查询。在数据入库后,分析应用可以用窗口标识进行查询,例如用 12:00-12:30、12:30-13:00、13:00-13:30 这三个值分别发起三次查询,从而得到这些窗口的最高价、最低价和收盘价,再分别计算出 pt,最后就能得到当前周期的 CCI。
如果你看到这里,就会发现这个应用的开发过程以及它所需要的组件还是比较复杂的,除了上面的开发过程,我们还需要开发一个后端查询应用才能计算出 CCI,这也是流处理通常是属于数据工程领域而非数据科学领域。
最后值得注意的是,从代码 spark.readStream 开始到最后处理过程的完成,其实是一行代码,这一行代码稍加改动也可直接用于批处理,这也是 Spark 统一编程接口的一种体现。
本课时的内容就到这里,下个课时我们将进入下一个模块的学习,我将为你讲解什么是图:图模式,图相关技术与使用场景。
大数据Spark实战第五集 Spark股票交易实时价格分析相关推荐
- docker-compose观察实时日志_大数据项目实战之在线教育(03实时需求) - 十一vs十一...
第1章Spark Streaming概念 Spark Streaming 是核心Spark API的扩展,可实现实时数据的可扩展,高吞吐量,容错处理.数据可以从许多来源(如Kafka,Flume,Ki ...
- 2018年新春报喜!热烈祝贺王家林大咖大数据经典传奇著作《SPARK大数据商业实战三部曲》 畅销书籍 清华大学出版社发行上市!
2018年新春报喜!热烈祝贺王家林大咖大数据经典传奇著作<SPARK大数据商业实战三部曲>畅销书籍 清华大学出版社发行上市! 本书基于Spark 2.2.0新版本,以Spark商业案例实战 ...
- 王家林大咖新书预发布:清华大学出版社即将出版《Spark大数据商业实战三部曲:内核解密|商业案例|性能调优》第二版 及《企业级AI技术内幕讲解》
王家林大咖新书预发布:清华大学出版社即将出版<Spark大数据商业实战三部曲:内核解密|商业案例|性能调优>第二版,新书在第一版的基础上以Spark 2.4.3版本全面更新源码,并以Ten ...
- 决胜Spark大数据时代企业级最佳实践:Spark CoreSpark SQLGraphXMachine LearningBest Practice
王家林:Spark.Docker.Android技术中国区布道师. 联系邮箱18610086859@126.com 电话:18610086859 QQ:1740415547 微信号:186100868 ...
- 大数据开发:剖析Hadoop和Spark的Shuffle过程差异
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- Spark大数据技术与应用 第一章Spark简介与运行原理
Spark大数据技术与应用 第一章Spark简介与运行原理 1.Spark是2009年由马泰·扎哈里亚在美国加州大学伯克利分校的AMPLab实验室开发的子项目,经过开源后捐赠给Aspache软件基金会 ...
- 【ADS层表-V1】前端页面所需的数据库设计——大数据开发实战项目(五)
文章目录 前言 TiTan数据运营系统--数据库 表的具体设计 前言 如果你从本文中学习到丝毫知识,那么请您点点关注.点赞.评论和收藏 大家好,我是爱做梦的鱼,我是东北大学大数据实验班大三的小菜鸡,非 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
大数据学习系列之八----- Hadoop.Spark.HBase.Hive搭建环境遇到的错误以及解决方法 参考文章: (1)大数据学习系列之八----- Hadoop.Spark.HBase.Hiv ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第五讲Hadoop图文训练课程:解决典型Hadoop分布式集群环境搭建问题
王家林的"云计算分布式大数据Hadoop实战高手之路---从零开始"的第五讲Hadoop图文训练课程:解决典型Hadoop分布式集群环境搭建问题 参考文章: (1)王家林的&quo ...
最新文章
- 跟我一起写 Makefile(七)
- Mysql Engine【innodb,myisam】
- iOS11最新隐私信息访问列表
- 给Windows 服务添加命令行参数
- mysql连接编码设置_MySQL基础 - 编码设置
- js获取当前月的第一天和最后一天
- CCF201903-3 损坏的RAID5(100分)【数学计算+文本处理】
- 23andme、gsa、wegene各染色体位点统计
- 神经网络常见问题和技巧(持续更新)
- 人民日报申论范文:“传统文化”怎么写?
- Python操控鼠标和键盘
- log4cplus的各种坑
- 【原创】数据分析报告撰写概览
- 督促自己——某客网编程题三道(Java)——字符串、集合、数组
- 深入剖析斐波拉契数列
- 智慧地铁轨道交通解决方案-最新全套文件
- hadoop 透明加密先关命令
- Mac开发之重写NSSlider(比酷狗的播放进度条好看)
- tcpdump如何抓接口包_TCPDUMP抓包方法
- Debian 安装amd驱动