生成式对抗网络(GANs)综述
GAN
GAN简介
生成式对抗网络(Generative adversarial networks,GANs)的核心思想源自于零和博弈,包括生成器和判别器两个部分。生成器接收随机变量并生成“假”样本,判别器则用于判断输入的样本是真实的还是合成的。两者通过相互对抗来获得彼此性能的提升。判别器所作的其实就是一个二分类任务,我们可以计算他的损失并进行反向传播求出梯度,从而进行参数更新。

GAN的优化目标可以写作:
minGmaxDV(D,G)=Ex∼pdata[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]\large {\min_G\max_DV(D,G)= \mathbb{E}_{x\sim p_{data}}[\log D(x)]+\mathbb{E}_{z\sim p_z(z)}[log(1-D(G(z)))]} GminDmaxV(D,G)=Ex∼pdata[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
其中logD(x)\log D(x)logD(x)代表了判别器鉴别真实样本的能力,而D(G(z))D(G(z))D(G(z))则代表了生成器欺骗判别器的能力。在实际的训练中,生成器和判别器采取交替训练,即先训练D,然后训练G,不断往复。
WGAN
DCGAN

用DCGAN生成图像
为了更方便准确的说明DCGAN的关键环节,这里用一个简化版的模型实例来说明。代码基于pytorch深度学习框架,数据集采用MNIST
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms
from torchvision.utils import save_image
import os
#定义一些超参数
nc = 1 #输入图像的通道数
nz = 100 #输入噪声的维度
num_epochs = 200 #迭代次数
batch_size = 64 #批量大小
sample_dir = 'gan_samples'
# 结果的保存目录
if not os.path.exists(sample_dir):os.makedirs(sample_dir)
# 加载MNIST数据集
trans = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5], [0.5])])
mnist = torchvision.datasets.MNIST(root=r'G:\VsCode\ml\mnist',train=True,transform=trans,download=False)
data_loader = torch.utils.data.DataLoader(dataset=mnist,batch_size=batch_size, shuffle=True)
判别器&生成器
判别器使用LeakyReLU作为激活函数,最后经过Sigmoid输出,用于真假二分类
生成器使用ReLU作为激活函数,最后经过tanh将输出映射在[−1,1][-1,1][−1,1]之间
# 构建判别器
class Discriminator(nn.Module):def __init__(self, in_channel=1, num_classes=1):super(Discriminator, self).__init__()self.conv = nn.Sequential(# 28 -> 14nn.Conv2d(nc, 512, 3, stride=2, padding=1, bias=False),nn.BatchNorm2d(512),nn.LeakyReLU(0.2),# 14 -> 7nn.Conv2d(512, 256, 3, stride=2, padding=1, bias=False),nn.BatchNorm2d(256),nn.LeakyReLU(0.2),# 7 -> 4nn.Conv2d(256, 128, 3, stride=2, padding=1, bias=False),nn.BatchNorm2d(128),nn.LeakyReLU(0.2),nn.AvgPool2d(4),)self.fc = nn.Sequential(# reshape input, 128 -> 1nn.Linear(128, 1),nn.Sigmoid(),)def forward(self, x, label=None):y_ = self.conv(x)y_ = y_.view(y_.size(0), -1)y_ = self.fc(y_)return y_# 构建生成器
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.fc = nn.Sequential(nn.Linear(nz, 4*4*512),nn.ReLU(),)self.conv = nn.Sequential(# input: 4 by 4, output: 7 by 7nn.ConvTranspose2d(512, 256, 3, stride=2, padding=1, bias=False),nn.BatchNorm2d(256),nn.ReLU(),# input: 7 by 7, output: 14 by 14nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1, bias=False),nn.BatchNorm2d(128),nn.ReLU(),# input: 14 by 14, output: 28 by 28nn.ConvTranspose2d(128, 1, 4, stride=2, padding=1, bias=False),nn.Tanh(),)def forward(self, x, label=None):x = x.view(x.size(0), -1)y_ = self.fc(x)y_ = y_.view(y_.size(0), 512, 4, 4)y_ = self.conv(y_)return y_
训练模型
# 使用GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
D = Discriminator().to(device)
G = Generator().to(device)
# 损失函数及优化器
criterion = nn.BCELoss()
D_opt = torch.optim.Adam(D.parameters(), lr=0.001, betas=(0.5, 0.999))
G_opt = torch.optim.Adam(G.parameters(), lr=0.001, betas=(0.5, 0.999))def denorm(x):out = (x + 1) / 2return out.clamp(0, 1)def reset_grad():d_optimizer.zero_grad()g_optimizer.zero_grad()for epoch in range(num_epochs):for i, (images, labels) in enumerate(data_loader):images = images.to(device)real_labels = torch.ones(batch_size, 1).to(device)fake_labels = torch.zeros(batch_size, 1).to(device)#————————————————————训练判别器——————————————————————#鉴别真实样本outputs = D(images)d_loss_real = criterion(outputs, real_labels)real_score = outputs#鉴别生成样本z = torch.randn(batch_size, nz).to(device)fake_images = G(z)outputs = D(fake_images)d_loss_fake = criterion(outputs, fake_labels)fake_score = outputs #计算梯度及更新d_loss = d_loss_real + d_loss_fake reset_grad()d_loss.backward()d_optimizer.step()#————————————————————训练生成器——————————————————————z = torch.randn(batch_size, nz).to(device)fake_images = G(z)outputs = D(fake_images)g_loss = criterion(outputs, real_labels)#计算梯度及更新reset_grad()g_loss.backward()g_optimizer.step()if (i+1) % 200 == 0:print('Epoch [{}/{}], Step [{}/{}], d_loss: {:.4f}, g_loss: {:.4f}, D(x): {:.2f}, D(G(z)): {:.2f}' .format(epoch, num_epochs, i+1, total_step, d_loss.item(), g_loss.item(), real_score.mean().item(), fake_score.mean().item()))# 保存生成图片fake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28)save_image(denorm(fake_images), os.path.join(sample_dir, 'fake_images-{}.png'.format(epoch+1)))
# 保存模型
torch.save(G.state_dict(), 'G.ckpt')
torch.save(D.state_dict(), 'D.ckpt')
可视化结果
reconsPath = './gan_samples/fake_images-200.png'
Image = mpimg.imread(reconsPath)
plt.imshow(Image)
plt.axis('off')
plt.show()
cGAN

判别器&生成器
只需要在前向传播的过程中加入限制变量y,我们很容易就能得到cGAN的生成器和判别器模型
class Discriminator(nn.Module):...def forward(self, x, label):label = label.unsqueeze(2).unsqueeze(3)label = label.repeat(1, 1, x.size(2), x.size(3))x = torch.cat(tensors=(x, label), dim=1)y_ = self.conv(x)...
class Generator(nn.Module):...def forward(self, x, label):x = x.unsqueeze(2).unsqueeze(3)label = label.unsqueeze(2).unsqueeze(3)x = torch.cat(tensors=(x, label), dim=1)y_ = self.fc(x)...
Pix2Pix

CycleGAN
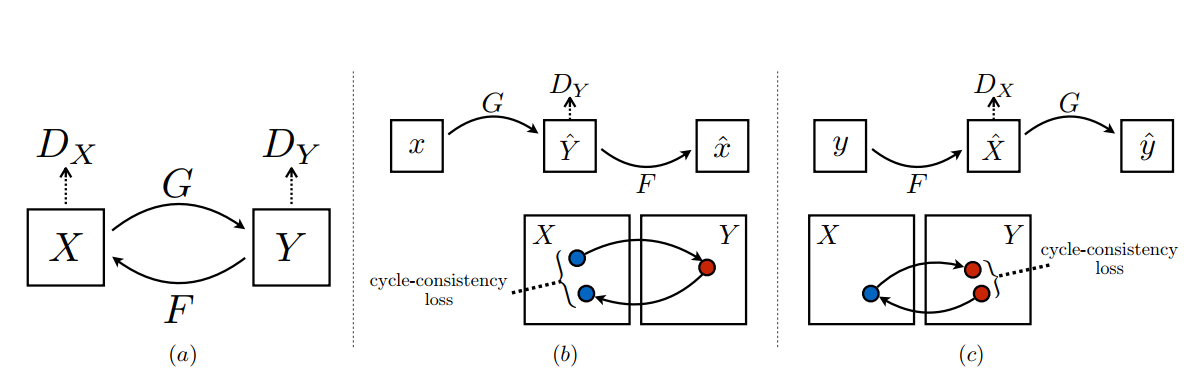
CycleGAN其实就是一个X->Y的单向GAN上再加一个Y->X的单向GAN,构成一个“循环”。网络的结构和单次训练过程如下(图片来自于量子位):


Pix2Pix以及CycleGAN的官方复现入口:https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
StarGAN
- 将原始图片ccc和目标生成域ccc进行拼接后丢入生成器得到生成图像G(x,c)G(x,c)G(x,c)
- 将生成图像G(x,c)G(x,c)G(x,c)和真实图像yyy分别丢入判别器D,判别器除了需要判断输入图像的真伪之外,还需要判断它来自哪个域
- 将生成图像G(x,c)G(x,c)G(x,c)和原始生成域c′c'c′丢入生成器生成重构图片(为了对生成器生成的图像做进一步的限制,与CycleGAN的重构损失类似)

此外,为了更具备通用性,作者还加入了mask vector来适应不同的数据集之间的训练。
总结
| 名称 | 创新点 |
|---|---|
| DCGAN | 首次将卷积神经网络引入GAN中 |
| cGAN | 通过拼接标签信息来控制生成器的输出 |
| Pix2Pix | 提出了一种图像到图像翻译的通用方法 |
| CycleGAN | 解决了Pix2Pix需要图像配对的问题 |
| StarGAN | 提出了一种一对多的图像到图像的翻译方法 |
| InfoGAN | 基于cGAN改进,提出一种无监督的生成方法,适用于不知道图像标签的情况 |
| LSGAN | 用最小二乘损失函数代替原始GAN的损失函数,缓解了训练不稳定、生成图像缺乏多样性的问题 |
| ProGAN | 在训练期间逐步添加新的高分辨率层,可以生成高分辨率的图像 |
| SAGAN | 将注意力机制引入GAN当中,简约高效利用了全局信息 |
本文列举了生成式对抗网络在发展过程中一些具有代表性的网络结构。GANs如今已广泛应用于图像生成、图像去噪、超分辨、文本到图像的翻译等各个领域,且在近几年的研究中涌现了很多优秀的论文。感兴趣的同学可以从下面的链接中pick自己想要了解的GAN~
- THE-GAN-ZOO:汇总了各种GAN的论文及代码地址。
- GAN Timeline:按照时间线对不同的GAN进行了排序。
- Browse state-of-the-art:将ArXiv上的最新论文与GitHub代码相关联,并做了比较排序,涉及了深度学习的各个方面。
参考文献
- Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
- Arjovsky M, Chintala S, Bottou L. Wasserstein gan[J]. arXiv preprint arXiv:1701.07875, 2017.
- Radford A, Metz L, Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv preprint arXiv:1511.06434, 2015.
- Mirza M, Osindero S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
- Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
- Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
- Choi Y, Choi M, Kim M, et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8789-8797.
- Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2794-2802.
- Karras T, Aila T, Laine S, et al. Progressive growing of gans for improved quality, stability, and variation[J]. arXiv preprint arXiv:1710.10196, 2017.
- Chen X, Duan Y, Houthooft R, et al. Infogan: Interpretable representation learning by information maximizing generative adversarial nets[C]//Advances in neural information processing systems. 2016: 2172-2180.
- Zhang H, Goodfellow I, Metaxas D, et al. Self-attention generative adversarial networks[C]//International Conference on Machine Learning. 2019: 7354-7363.
生成式对抗网络(GANs)综述相关推荐
- 生成式对抗网络(GANs)及变体
生成式对抗网络GANs及变体 1.基础GAN 2.条件生成对抗网络(cGAN) 3.Wasserstein GAN (WGAN) WAN-GP (improved WGAN) 3.Unsupervis ...
- 生成式对抗网络(GAN)综述——粗浅入门
2017年十月份时做了关于GAN综述的PPT汇报(http://download.csdn.net/download/sir_chai/10104778),并上传了PPT及相关参考资料,这篇博文主要是 ...
- 生成式对抗网络(Generative Adversarial Networks, GANs)
1 原始的 GANs 1.1 GANs 的结构 GANs 的结果图如下所示: 生成式对抗网络 GANs 最重要的两个部分为: 生成器(Generator) :用于生成"假"样本.生 ...
- 密歇根大学28页最新《GANs生成式对抗网络综述:算法、理论与应用》最新论文,带你全面了解GAN技术趋势...
来源:专知 [导读]生成式对抗网络(Generative Adversarial Networks,GANs)作为近年来的研究热点之一,受到了广泛关注,每年在机器学习.计算机视觉.自然语言处理.语音识 ...
- GANs系列:GAN生成式对抗网络原理以及数学表达式解剖
一.GAN介绍 生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一.模型通过框架中(至少)两 ...
- 生成式对抗网络(Generative Adversarial Networks,GANs)
1. 简介 首先简要介绍一下生成模型(Generative model)与判别模型(Discriminative mode)的概念: 生成模型:对联合概率进行建模,从统计的角度表示数据的分布情况,刻画 ...
- 《生成式对抗网络GAN的研究进展与展望》论文笔记
本文主要是对论文:王坤峰, 苟超, 段艳杰, 林懿伦, 郑心湖, 王飞跃. 生成式对抗网络GAN的研究进展与展望. 自动化学报, 2017, 43(3): 321-332. 进行总结. 相关博客地址: ...
- 到底什么是生成式对抗网络GAN?
男:哎,你看我给你拍的好不好? 女:这是什么鬼,你不能学学XXX的构图吗? 男:哦 -- 男:这次你看我拍的行不行? 女:你看看你的后期,再看看YYY的后期吧,呵呵 男:哦 -- 男:这次好点了吧? ...
- 简述生成式对抗网络 GAN
本文主要阐述了对生成式对抗网络的理解,首先谈到了什么是对抗样本,以及它与对抗网络的关系,然后解释了对抗网络的每个组成部分,再结合算法流程和代码实现来解释具体是如何实现并执行这个算法的,最后通过给出一个 ...
最新文章
- 进制转换converse
- JavaScript内置函数及API
- 将一个Excel文件分隔成多个
- 可以看到对方是否打开_打开手机实景地图,连你家门口都可以清晰看到,方便又好用...
- 快速配置MPLS ×××
- OpenCV参考手册之Mat类详解1
- Reflector7及破解
- enumerate_Java Thread类的static int enumerate(Thread [] th)方法与示例
- eclipse 的project explorer问题,这个怎样把localFileSystem去掉,
- kops_使用KOPS的Kubernetes群集中SQL Server
- C++内置数组和array的比较
- Microsoft Access 2002中文版标准培训教程pdf
- 用python进行人脸识别
- 知识表示-马尔科夫链(MC)
- 得到APP之订阅专栏《硅谷来信》和《精英日课》目录
- 在WinXP上编译Doom3源码提示
- 百度之星2017 HDU 6114 Chess 组合数学
- MOS管和三级管基础知识总结
- 【TS】1552- 浅谈TS运行时类型检查
- python中的filter(),map(),reduc…