《R语言数据挖掘:实用项目解析》——第2章,第2.8节假设检验
本节书摘来自华章出版社《R语言数据挖掘:实用项目解析》一书中的第2章,第2.8节假设检验,作者[印度]普拉迪帕塔·米什拉(Pradeepta Mishra),更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.8 假设检验
零假设意味着什么都没有发生、平均值是恒定的,等等。对立假设则意味着有什么发生了,且平均值与总体有所不同。进行假设检验的步骤如下:
1)提出零假设:提出关于总体的假设。例如,平均市内行车英里数为40。
2)提出对立假设:如果证明零假设是错的,那么其他情况的概率有多大?例如,如果市内行车英里数不是40,那是大于40,还是小于40?如果不等于40,则这是一个非定向对立假设。
3)计算样本检验统计:检验统计可以是t-检验、f-检验、z-检验等。根据数据适用性和先前提出的假设选择恰当的检验统计。
4)确定置信区间:有90%、95%和99%三个置信区间,根据相关的特定业务问题的准确率而定。置信区间的水平由研究人员或分析师来确定。
5)确定显著性水平:如果置信区间是95%,则显著性水平将为5%。由此可见显著性水平的确定将有益于计算检验的p值。
6)结论:如果选择的p值小于显著水平值,则有理由否定零假设;否则,我们将认可零假设。
2.8.1 总体均值检验
根据前面的检验假设步骤,以Cars93为例来检验总体平均值。
已知方差情况下的单尾均值检验
假设某研究人员声明样本采集的所有汽车平均行车里程数超过35。在有93辆汽车的样本中,观察到所有汽车平均行车里程数为29。你应该认可,还是否定该研究人员的声明?
接下来的代码将解释你应该怎样对此下结论:

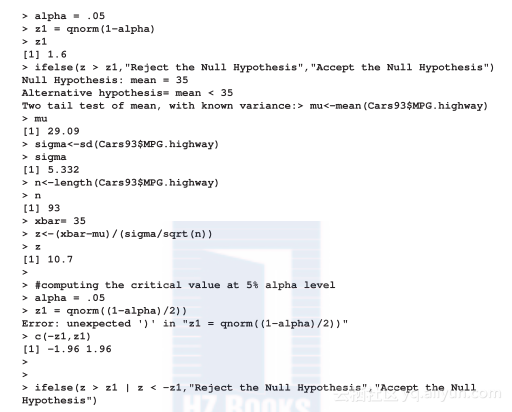
下面介绍在已知方差情况下对样本数据的总体均值进行单尾和双尾比例检验分析。
单尾和双尾比例检验
利用数据集Cars93,假设40%的美国产汽车的RPM(最大马力时的每分钟转速)超过5000。从样本数据得知,57辆汽车中有17辆的RPM超过5000。从上文你可得到什么解释?


如果对立假设是非定向假设,那么这就是双尾比例检验的例子。之前的计算不会有改变,除了临界值的计算。详细代码如下:

对连续型数据的双样本成对检验:用于双样本成对检验的零假设是指假设一个过程对研究对象没有影响、试验对试验对象没有影响,等等。对立假设声明存在过程的显著统计影响、试验的有效性或在对象上的作用。
虽然在Cars93中没有这样的变量,我们仍然假设在不同汽车品牌的最小价格和最大价格之间有成对关系。
双样本t检验的零假设:平均价格无差异。
对立假设:平均价格有差异。

由于p值小于0.05,因此最大价格和最小价格之差在95%置信区间内有显著差异。
对连续型数据的双样本不成对检验:假设在Cars93数据集中高速路的里程数和市内里程数是有差别的。如果两者有显著差异,可以通过独立的样本t检验来比较各自的平均值。
零假设:高速路的MPG和市内的MPG没有差别。
对立假设:高速路的MPG和市内的MPG有差别。

由双样本t检验可知,当两个样本相互独立时,p值小于0.05,所以我们可以否定假设高速路和市内的平均里程数无差别的零假设,即高速路和市内的平均里程数有显著差异。这可用略微不同的方法展现出来,即零假设手动挡与自动挡汽车各自的市内平均行车里程数不同:

从以上的检验可知,结论自动挡与手动挡汽车的市内平均行车里程数有显著差异,因为p值小于0.05。
在进行t检验之前,检查数据的正态性非常重要。一个变量的正态性可用Shapiro检验函数检测:
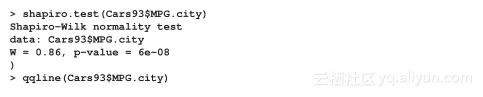
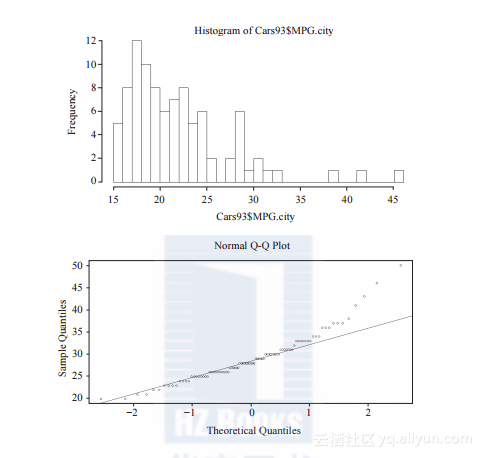
由市内每加仑行车里程数的正态分位图和直方图可知,里程数变量没有呈正态分布。因为该变量不是正态分布的,所以需要采取非参数方法比如Wilcoxon符号秩检验或Kolmogorov-Smirnov检验。
2.8.2 双样本方差检验
比较双样本的方差,采用F检验作为统计量:

因为p值小于0.05,我们可以否定手动挡与自动挡汽车在高速路的里程数的方差无差异的零假设。这表明两个样本的方差有95%置信水平的统计显著差异。
这两组样本的方差还可以用Bartlett检验测出:

由以上检验也可以得出这样的结论,即关于方差相同的零假设可在0.05的显著性水平拒绝,可证明这两组样本有显著差异。
单因子方差分析:可使用单因子方差分析。分析的变量是RPM,分组变量是Cylinders(汽缸个数)。
零假设:不同缸数的平均RPM值无差异。
对立假设:至少一种缸数的平均RPM有差异。
代码如下:
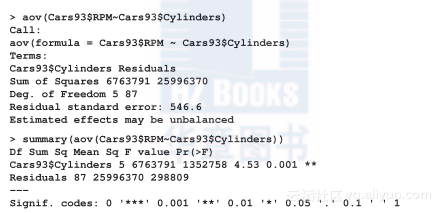
由上面的方差分析可知,p值小于0.05,因此否定零假设。这意味着至少有一种缸数的平均RPM存在显著差异。为了识别哪一种缸数是不同的,可在方差分析模型的结果上执行事后检验:


只要调整后的p值小于0.05,RPM的平均差异将显著有别于其他分组。
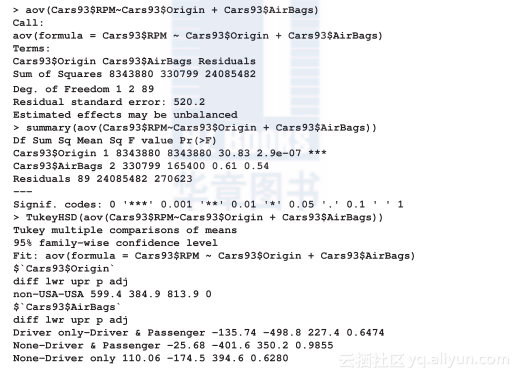
双因子方差分析及其事后检验:这里研究的因子是origin(是否美国产)和airbags(安全气囊规格)。需要检验的假设是:这两个分类变量对RPM变量是否有影响?
《R语言数据挖掘:实用项目解析》——第2章,第2.8节假设检验相关推荐
- 《R语言数据挖掘:实用项目解析》——第2章,第2.9节无参数方法
本节书摘来自华章出版社<R语言数据挖掘:实用项目解析>一书中的第2章,第2.9节无参数方法,作者[印度]普拉迪帕塔·米什拉(Pradeepta Mishra),更多章节内容可以访问云栖社区 ...
- 《R语言数据挖掘:实用项目解析》——1.11 apply原理
本节书摘来自华章计算机<R语言数据挖掘:实用项目解析>一书中的第1章,第1.11节,作者[印度]普拉迪帕塔·米什拉(Pradeepta Mishra),译 黄芸,更多章节内容可以访问云栖社 ...
- 《R语言数据挖掘:实用项目解析》——1.9 循环原理——repeat循环
本节书摘来自华章计算机<R语言数据挖掘:实用项目解析>一书中的第1章,第1.9节,作者[印度]普拉迪帕塔·米什拉(Pradeepta Mishra),译 黄芸,更多章节内容可以访问云栖社区 ...
- 《R语言数据挖掘:实用项目解析》——2.6 变量分段
本节书摘来自华章计算机<R语言数据挖掘:实用项目解析>一书中的第2章,第2.6节,作者[印度]普拉迪帕塔·米什拉(Pradeepta Mishra),译 黄芸,更多章节内容可以访问云栖社区 ...
- R语言--数据挖掘3---关联规则分析
文章目录 关联规则分析 数据介绍 基本原理介绍 基本概念: Apriori算法 有意义的关联规则 案例分析 总结反思 学习其他同学的代码 参考 代码 关联规则分析 本次报告主要包括以下内容: 数据介绍 ...
- 【R语言】常用的R语言数据挖掘包
常用的R语言数据挖掘包 与Python相比,R语言的很多算法分别会有不同的作者实现,而每个人有不同的实现方式,所以会产生大量的package.因此,学习R语言需要广泛了解与所研究问题相关的包,这样就比 ...
- 《R语言数据挖掘》读书笔记:一、预备知识
写在前面:此系列文章以<R语言数据挖掘>为主线,记录自己学习数据挖掘和算法的过程. 还引用了大量前辈的博客总结,先谢过. 第一章.预备知识 1.大数据 2.数据源 3.数据 ...
- R语言数据挖掘(关联规则、聚类算法等)——美国黑色星期五
R语言数据挖掘(关联规则.聚类算法等) 实验内容和步骤: 数据概览 产品分析 性别统计 畅销品 年龄统计 城市居住时间分析 查找顶级消费者 关联规则分析 聚类 实验内容和步骤: 一. 实验内容: 对原 ...
- 《R语言数据挖掘》----1.12 数据集成
本节书摘来自华章出版社<R语言数据挖掘>一书中的第1章,第1.12节,作者[哈萨克斯坦]贝特·麦克哈贝尔(Bater Makhabel),李洪成 许金炜 段力辉 译,更多章节内容可以访问云 ...
最新文章
- 教程是php手工注入
- linux wget 下载文件 报错 To connect to xxxx, use ‘--no-check-certificate’ 解决方法
- 小鸭脖大生意——绝味鸭脖背后的故事
- 常用计算机文章搜索方法总结
- Ribbon自带负载均衡策略比较
- 排球计分程序重构(四)
- matlab 下采样_Lattice规划与Matlab实现(1)
- python 合并word文件_python自动化办公(1)—— 批量合并word文档
- atom配置python环境_Python编程:用VScode配置Python开发环境
- 长春java开发能开多少钱,从理论到实践!
- 欧姆龙rxd指令讲解_欧姆龙PLC指令的列表
- aforge java_C#调用AForge实现摄像头录像的示例代码
- 2021年最完善的谷歌SEO关键词调研技巧
- [C0] 人工智能大师访谈 by 吴恩达
- CSS中绝对定位导致页面混乱的原因以及解决办法
- macOS Big Sur 11.3.1 (20E241) 虚拟机 ISO 镜像
- 优麒麟系统安装MySQL_优麒麟Linux(Ubuntu Kylin)简易安装手册
- 【思考题】新客老客定义
- 怎么在alert里加图片_鹅蛋怎么挑选?教你2招,一看一摇听声音
- python实现用伏羲八卦对ASCII码进行加密
热门文章
- 《安全智库》:48H急速夺旗大战通关writeup(通关策略)
- Simulink和Carsim联合仿真车辆状态估计 卡尔曼滤波的EKF,UKF,CKF等
- OSChina 周二乱弹 —— 约会奇才
- TSI: Temporal Scale Invariant Network forAction Proposal Generation
- 全志AXP209电源管理芯片介绍
- 犀牛书第2章 JavaScript词法结构
- 服务器文件同步软件有哪些东西吗,远程服务器文件同步软件
- 暴力破解Zip 文件
- 天赋 VS 勤奋,“一万小时定律” 没你想得那么简单
- CocosCreator3D插件教程(1):hello-world