1.3.5 手写数字识别之资源配置
文章目录
- 概述
- 前提条件
- 一、单GPU训练
- 二、分布式训练
- 模型并行
- 数据并行
- PRC通信方式
- NCCL2通信方式(Collective)
- 1. 基于launch方式启动
- 单机单卡启动,默认使用第0号卡。
- 单机多卡启动,默认使用当前可见的所有卡。
- 单机多卡启动,设置当前使用的第0号和第1号卡。
- 2. 基于spawn方式启动
概述
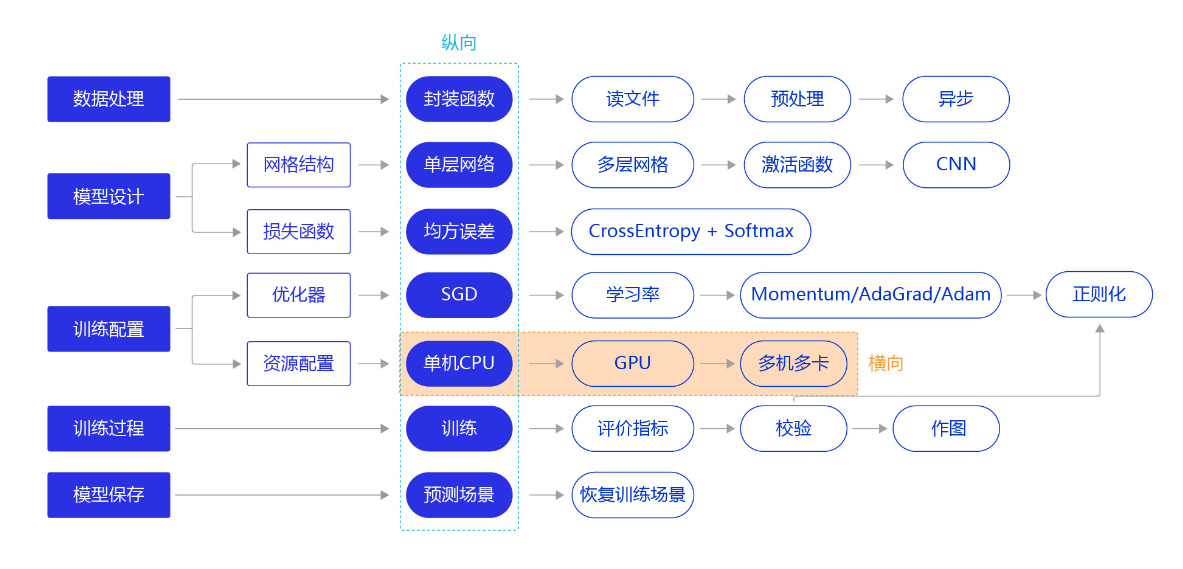
从前几节的训练看,**无论是房价预测任务还是MNIST手写字数字识别任务,训练好一个模型不会超过10分钟,主要原因是我们所使用的神经网络比较简单。**但实际应用时,常会遇到更加复杂的机器学习或深度学习任务,需要运算速度更高的硬件(如GPU、NPU),甚至同时使用多个机器共同训练一个任务(多卡训练和多机训练)。本节我们依旧横向展开"横纵式"教学方法,如 图1 所示,探讨在手写数字识别任务中,通过资源配置的优化,提升模型训练效率的方法。
前提条件
需要先进行数据处理、设计神经网络结构,代码与上一节保持一致,如下所示。如果读者已经掌握了这部分内容,可以直接阅读正文部分。
# 加载相关库
import os
import random
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear
import numpy as np
from PIL import Image
import gzip
import json# 定义数据集读取器
def load_data(mode='train'):# 读取数据文件datafile = './work/mnist.json.gz'print('loading mnist dataset from {} ......'.format(datafile))data = json.load(gzip.open(datafile))# 读取数据集中的训练集,验证集和测试集train_set, val_set, eval_set = data# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLSIMG_ROWS = 28IMG_COLS = 28# 根据输入mode参数决定使用训练集,验证集还是测试if mode == 'train':imgs = train_set[0]labels = train_set[1]elif mode == 'valid':imgs = val_set[0]labels = val_set[1]elif mode == 'eval':imgs = eval_set[0]labels = eval_set[1]# 获得所有图像的数量imgs_length = len(imgs)# 验证图像数量和标签数量是否一致assert len(imgs) == len(labels), \"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(labels))index_list = list(range(imgs_length))# 读入数据时用到的batchsizeBATCHSIZE = 100# 定义数据生成器def data_generator():# 训练模式下,打乱训练数据if mode == 'train':random.shuffle(index_list)imgs_list = []labels_list = []# 按照索引读取数据for i in index_list:# 读取图像和标签,转换其尺寸和类型img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')label = np.reshape(labels[i], [1]).astype('int64')imgs_list.append(img) labels_list.append(label)# 如果当前数据缓存达到了batch size,就返回一个批次数据if len(imgs_list) == BATCHSIZE:yield np.array(imgs_list), np.array(labels_list)# 清空数据缓存列表imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator# 定义模型结构
import paddle.nn.functional as F
# 多层卷积神经网络实现
class MNIST(paddle.nn.Layer):def __init__(self):super(MNIST, self).__init__()# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2self.conv1 = Conv2D(in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)# 定义池化层,池化核的大小kernel_size为2,池化步长为2self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2self.conv2 = Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)# 定义池化层,池化核的大小kernel_size为2,池化步长为2self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)# 定义一层全连接层,输出维度是10self.fc = Linear(in_features=980, out_features=10)# 定义网络前向计算过程,卷积后紧接着使用池化层,最后使用全连接层计算最终输出# 卷积层激活函数使用Relu,全连接层激活函数使用softmaxdef forward(self, inputs):x = self.conv1(inputs)x = F.relu(x)x = self.max_pool1(x)x = self.conv2(x)x = F.relu(x)x = self.max_pool2(x)x = paddle.reshape(x, [x.shape[0], 980])x = self.fc(x)return x
一、单GPU训练
通过paddle.device.set_device API,设置在GPU上训练还是CPU上训练。
paddle.device.set_device (device)
参数
device (str):此参数确定特定的运行设备,可以是cpu、 gpu:x或者是xpu:x。其中,x是GPU或XPU的编号。当device是cpu时, 程序在CPU上运行;当device是gpu:x时,程序在GPU上运行。
#仅优化算法的设置有所差别
def train(model):#开启GPUuse_gpu = Truepaddle.device.set_device('gpu:0') if use_gpu else paddle.device.set_device('cpu')model.train()#调用加载数据的函数train_loader = load_data('train')#设置不同初始学习率opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())EPOCH_NUM = 5for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,变得更加简洁images, labels = dataimages = paddle.to_tensor(images)labels = paddle.to_tensor(labels)#前向计算的过程predicts = model(images)#计算损失,取一个批次样本损失的平均值loss = F.cross_entropy(predicts, labels)avg_loss = paddle.mean(loss)#每训练了100批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))#后向传播,更新参数的过程avg_loss.backward()opt.step()opt.clear_grad()#保存模型参数paddle.save(model.state_dict(), 'mnist.pdparams')
#创建模型
model = MNIST()
#启动训练过程
train(model)
W0615 13:50:33.741969 103 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0615 13:50:33.745787 103 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.loading mnist dataset from ./work/mnist.json.gz ......
epoch: 0, batch: 0, loss is: [2.410855]
epoch: 0, batch: 200, loss is: [0.0368525]
epoch: 0, batch: 400, loss is: [0.06597616]
epoch: 1, batch: 0, loss is: [0.05192101]
epoch: 1, batch: 200, loss is: [0.01990369]
epoch: 1, batch: 400, loss is: [0.01839648]
epoch: 2, batch: 0, loss is: [0.00373071]
epoch: 2, batch: 200, loss is: [0.04803684]
epoch: 2, batch: 400, loss is: [0.06256894]
epoch: 3, batch: 0, loss is: [0.06984695]
epoch: 3, batch: 200, loss is: [0.01895934]
epoch: 3, batch: 400, loss is: [0.0678551]
epoch: 4, batch: 0, loss is: [0.00520308]
epoch: 4, batch: 200, loss is: [0.02010738]
epoch: 4, batch: 400, loss is: [0.03121328]
二、分布式训练
在工业实践中,很多较复杂的任务需要使用更强大的模型。强大模型加上海量的训练数据,经常导致模型训练耗时严重。比如在计算机视觉分类任务中,**训练一个在ImageNet数据集上精度表现良好的模型,大概需要一周的时间,因为过程中我们需要不断尝试各种优化的思路和方案。**如果每次训练均要耗时1周,这会大大降低模型迭代的速度。在机器资源充沛的情况下,建议采用分布式训练,大部分模型的训练时间可压缩到小时级别。
分布式训练有两种实现模式:模型并行和数据并行。
模型并行
模型并行是将一个网络模型拆分为多份,拆分后的模型分到多个设备上(GPU)训练,每个设备的训练数据是相同的。模型并行的实现模式可以节省内存,但是应用较为受限。
模型并行的方式一般适用于如下两个场景:
模型架构过大: 完整的模型无法放入单个GPU。如2012年ImageNet大赛的冠军模型AlexNet是模型并行的典型案例,由于当时GPU内存较小,单个GPU不足以承担AlexNet,因此研究者将AlexNet拆分为两部分放到两个GPU上并行训练。
网络模型的结构设计相对独立: 当网络模型的设计结构可以并行化时,采用模型并行的方式。如在计算机视觉目标检测任务中,一些模型(如YOLO9000)的边界框回归和类别预测是独立的,可以将独立的部分放到不同的设备节点上完成分布式训练。
数据并行
数据并行与模型并行不同,数据并行每次读取多份数据,读取到的数据输入给多个设备(GPU)上的模型,每个设备上的模型是完全相同的,飞桨采用的就是这种方式。
说明:
当前GPU硬件技术快速发展,深度学习使用的主流GPU的内存已经足以满足大多数的网络模型需求,所以大多数情况下使用数据并行的方式。
数据并行的方式与众人拾柴火焰高的道理类似,如果把训练数据比喻为砖头,把一个设备(GPU)比喻为一个人,那单GPU训练就是一个人在搬砖,多GPU训练就是多个人同时搬砖,每次搬砖的数量倍数增加,效率呈倍数提升。值得注意的是,每个设备的模型是完全相同的,但是输入数据不同,因此每个设备的模型计算出的梯度是不同的。如果每个设备的梯度只更新当前设备的模型,就会导致下次训练时,每个模型的参数都不相同。因此我们还需要一个梯度同步机制,保证每个设备的梯度是完全相同的。
梯度同步有两种方式:PRC通信方式和NCCL2通信方式(Nvidia Collective multi-GPU Communication Library)。
PRC通信方式
PRC通信方式通常用于CPU分布式训练,它有两个节点:参数服务器Parameter server和训练节点Trainer,结构如 图2 所示。
图2:Pserver通信方式的结构
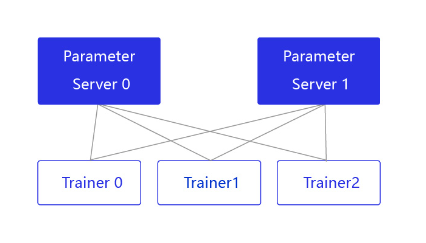
parameter server收集来自每个设备的梯度更新信息,并计算出一个全局的梯度更新。Trainer用于训练,每个Trainer上的程序相同,但数据不同。当Parameter server收到来自Trainer的梯度更新请求时,统一更新模型的梯度。
NCCL2通信方式(Collective)
当前飞桨的GPU分布式训练使用的是基于NCCL2的通信方式,结构如 图3 所示。
图3:NCCL2通信方式的结构
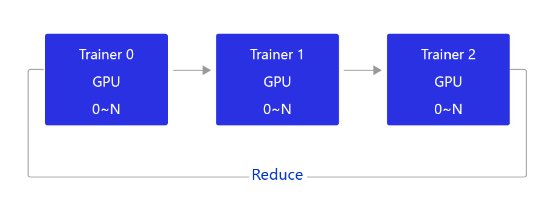
相比PRC通信方式,使用NCCL2(Collective通信方式)进行分布式训练,不需要启动Parameter server进程,每个Trainer进程保存一份完整的模型参数,在完成梯度计算之后通过Trainer之间的相互通信,Reduce梯度数据到所有节点的所有设备,然后每个节点在各自完成参数更新。
飞桨提供了便利的数据并行训练方式,用户只需要对程序进行简单修改,即可实现在多GPU上并行训练。接下来将讲述如何将一个单机程序通过简单的改造,变成单机多卡程序。
单机多卡程序通过如下两步改动即可完成:
- 初始化并行环境。
- 使用paddle.DataParallel封装模型。
注意:由于我们的数据是通过手动构造批次的方式输入给模型的,没有针对多卡情况进行划分,因此每个卡上会基于全量数据迭代训练。可通过继承paddle.io.Dataset的方式准备自己的数据,再通过DistributedBatchSampler实现分布式批采样器加载数据的一个子集。这样,每个进程可以传递给DataLoader一个DistributedBatchSampler的实例,每个进程加载原始数据的一个子集。
import paddle
import paddle.distributed as distdef train_multi_gpu(model):# 修改1- 初始化并行环境dist.init_parallel_env()# 修改2- 增加paddle.DataParallel封装model = paddle.DataParallel(model)model.train()#调用加载数据的函数train_loader = load_data('train')opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())EPOCH_NUM = 5for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,变得更加简洁images, labels = dataimages = paddle.to_tensor(images)labels = paddle.to_tensor(labels)#前向计算的过程predicts = model(images)#计算损失,取一个批次样本损失的平均值loss = F.cross_entropy(predicts, labels)avg_loss = paddle.mean(loss)#每训练了100批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))#后向传播,更新参数的过程avg_loss.backward()opt.step()opt.clear_grad()#保存模型参数paddle.save(model.state_dict(), 'mnist.pdparams')paddle.set_device('gpu')
#创建模型
model = MNIST()
#启动训练过程
train_multi_gpu(model)/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/distributed/parallel.py:158: UserWarning: Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything."Currently not a parallel execution environment, `paddle.distributed.init_parallel_env` will not do anything."
/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/dygraph/parallel.py:631: UserWarning: The program will return to single-card operation. Please check 1, whether you use spawn or fleetrun to start the program. 2, Whether it is a multi-card program. 3, Is the current environment multi-card.warnings.warn("The program will return to single-card operation. "loading mnist dataset from ./work/mnist.json.gz ......
epoch: 0, batch: 0, loss is: [2.60024]
epoch: 0, batch: 200, loss is: [0.07817128]
epoch: 0, batch: 400, loss is: [0.07151236]
epoch: 1, batch: 0, loss is: [0.06610017]
epoch: 1, batch: 200, loss is: [0.08385283]
epoch: 1, batch: 400, loss is: [0.11474587]
epoch: 2, batch: 0, loss is: [0.0622436]
epoch: 2, batch: 200, loss is: [0.05884153]
epoch: 2, batch: 400, loss is: [0.16888449]
epoch: 3, batch: 0, loss is: [0.00911527]
epoch: 3, batch: 200, loss is: [0.00979588]
epoch: 3, batch: 400, loss is: [0.1098608]
epoch: 4, batch: 0, loss is: [0.00384958]
epoch: 4, batch: 200, loss is: [0.01216829]
epoch: 4, batch: 400, loss is: [0.01615573]
启动多GPU的训练,有两种方式:
- 基于launch启动;
- 基于spawn方式启动。
说明:
AI Studio当前仅支持单卡GPU,因此本案例需要在本地GPU上执行,无法在AI Studio上演示。
1. 基于launch方式启动
需要在命令行中设置参数变量。打开终端,运行如下命令:
单机单卡启动,默认使用第0号卡。
$ python train.py
单机多卡启动,默认使用当前可见的所有卡。
$ python -m paddle.distributed.launch train.py
单机多卡启动,设置当前使用的第0号和第1号卡。
$ python -m paddle.distributed.launch --gpus '0,1' --log_dir ./mylog train.py
$ export CUDA_VISIABLE_DEVICES='0,1'
$ python -m paddle.distributed.launch train.py
相关参数含义如下:
- paddle.distributed.launch:启动分布式运行。
- gpus:设置使用的GPU的序号(需要是多GPU卡的机器,通过命令watch nvidia-smi查看GPU的序号)。
- log_dir:存放训练的log,若不设置,每个GPU上的训练信息都会打印到屏幕。
- train.py:多GPU训练的程序,包含修改过的train_multi_gpu()函数。
训练完成后,在指定的./mylog文件夹下会产生四个日志文件,其中worklog.0的内容如下:
grep: warning: GREP_OPTIONS is deprecated; please use an alias or script
dev_id 0
I1104 06:25:04.377323 31961 nccl_context.cc:88] worker: 127.0.0.1:6171 is not ready, will retry after 3 seconds...
I1104 06:25:07.377645 31961 nccl_context.cc:127] init nccl context nranks: 3 local rank: 0 gpu id: 1↩
W1104 06:25:09.097079 31961 device_context.cc:235] Please NOTE: device: 1, CUDA Capability: 61, Driver API Version: 10.1, Runtime API Version: 9.0
W1104 06:25:09.104460 31961 device_context.cc:243] device: 1, cuDNN Version: 7.5.
start data reader (trainers_num: 3, trainer_id: 0)
epoch: 0, batch_id: 10, loss is: [0.47507238]
epoch: 0, batch_id: 20, loss is: [0.25089613]
epoch: 0, batch_id: 30, loss is: [0.13120805]
epoch: 0, batch_id: 40, loss is: [0.12122715]
epoch: 0, batch_id: 50, loss is: [0.07328521]
epoch: 0, batch_id: 60, loss is: [0.11860339]
epoch: 0, batch_id: 70, loss is: [0.08205047]
epoch: 0, batch_id: 80, loss is: [0.08192863]
epoch: 0, batch_id: 90, loss is: [0.0736289]
epoch: 0, batch_id: 100, loss is: [0.08607423]
start data reader (trainers_num: 3, trainer_id: 0)
epoch: 1, batch_id: 10, loss is: [0.07032011]
epoch: 1, batch_id: 20, loss is: [0.09687119]
epoch: 1, batch_id: 30, loss is: [0.0307216]
epoch: 1, batch_id: 40, loss is: [0.03884467]
epoch: 1, batch_id: 50, loss is: [0.02801813]
epoch: 1, batch_id: 60, loss is: [0.05751991]
epoch: 1, batch_id: 70, loss is: [0.03721186]
.....
2. 基于spawn方式启动
**launch方式启动训练,是以文件为单位启动多进程,需要用户在启动时调用paddle.distributed.launch,对于进程的管理要求较高;**飞桨最新版本中,增加了spawn启动方式,可以更好地控制进程,在日志打印、训练和退出时更加友好。spawn方式和launch方式仅在启动上有所区别。
# 启动train多进程训练,默认使用所有可见的GPU卡。
if __name__ == '__main__':dist.spawn(train)# 启动train函数2个进程训练,默认使用当前可见的前2张卡。
if __name__ == '__main__':dist.spawn(train, nprocs=2)# 启动train函数2个进程训练,默认使用第4号和第5号卡。
if __name__ == '__main__':dist.spawn(train, nprocs=2, selelcted_gpus='4,5')1.3.5 手写数字识别之资源配置相关推荐
- 手写数字识别之资源配置
单GPU训练 飞桨动态图通过fluid.dygraph.guard(place=None)里的place参数,设置在GPU上训练还是CPU上训练. with fluid.dygraph.guard(p ...
- 深蓝学院第三章:基于卷积神经网络(CNN)的手写数字识别实践
参看之前篇章的用全连接神经网络去做手写识别:https://blog.csdn.net/m0_37957160/article/details/114105389?spm=1001.2014.3001 ...
- 深蓝学院第二章:基于全连接神经网络(FCNN)的手写数字识别
如何用全连接神经网络去做手写识别??? 使用的是jupyter notebook这个插件进行代码演示.(首先先装一个Anaconda的虚拟环境,然后自己构建一个自己的虚拟环境,然后在虚拟环境中安装ju ...
- 深度学习--TensorFlow(项目)Keras手写数字识别
目录 效果展示 基础理论 1.softmax激活函数 2.神经网络 3.隐藏层及神经元最佳数量 一.数据准备 1.载入数据集 2.数据处理 2-1.归一化 2-2.独热编码 二.神经网络拟合 1.搭建 ...
- 使用Caffe进行手写数字识别执行流程解析
之前在 http://blog.csdn.net/fengbingchun/article/details/50987185 中仿照Caffe中的examples实现对手写数字进行识别,这里详细介绍下 ...
- 使用Pytorch实现手写数字识别
使用Pytorch实现手写数字识别 1. 思路和流程分析 流程: 准备数据,这些需要准备DataLoader 构建模型,这里可以使用torch构造一个深层的神经网络 模型的训练 模型的保存,保存模型, ...
- 教程 | 基于LSTM实现手写数字识别
点击上方"小白学视觉",选择加"星标"或"置顶" 重磅干货,第一时间送达 基于tensorflow,如何实现一个简单的循环神经网络,完成手写 ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec...
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- MNIST数据集实现手写数字识别(基于tensorflow)
------------先看看别人的博客--------------------- Tensorflow 实现 MNIST 手写数字识别 用这个的代码跑通了 使用Tensorflow和 ...
最新文章
- 智能车技术创新与实践(01510422-90)课程简介
- 基于zbus的MySQL透明代理(100行)
- C++对字符串每个字母按照字典顺序排序
- RK 3399 切换以太网卡
- aspose.words读取html,Aspose.Words for .NET HTML代码直接生成WORD | 学步园
- static用法报错解决:cannot declare member function to have static linkage [-fpermissive]
- linux进程加载和运行,linux进程管理之可执行文件的加载和运行
- MySQL 字符串拼接 - 多种字符串拼接实战案例
- 怎样启动本地mysql服务_启动本地mysql服务
- 四川大学计算机组成原理实验报告_计算机组成原理基础解释
- FILD FLD FSTP
- 干货|Python基础入门 课程笔记(三)
- 联想IdeapadU410重装系统win10
- 2022 CCF形式化方法工业应用前沿分论坛暨中科国创高可信联合上海控安新品发布会顺利召开!...
- 【AV1 编码器研究一】aomenc.exe命令行参数简析
- 协方差矩阵和矩阵相关系数的理解
- SSM在线车队货车管理系统
- 海老师的技术博客: OCA 考试 准备笔记 前言
- linux发邮件失败,Linux SendMail发送邮件失败诊断案例,sendmail发送邮件
- 响应式布局必懂知识_五分钟教会你响应式布局