Python做文本挖掘的情感极性分析(基于情感词典的方法)

「情感极性分析」是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
1. 基于情感词典的文本情感极性分析
笔者是通过情感打分的方式进行文本情感极性判断,score > 0判断为正向,score < 0判断为负向。
1.1 数据准备
1.1.1 情感词典及对应分数
词典来源于BosonNLP数据下载http://bosonnlp.com/dev/resource 的情感词典,来源于社交媒体文本,所以词典适用于处理社交媒体的情感分析。
词典把所有常用词都打上了唯一分数有许多不足之处。
不带情感色彩的停用词会影响文本情感打分。由于中文的博大精深,词性的多变成为了影响模型准确度的重要原因。一种情况是同一个词在不同的语境下可以是代表完全相反的情感意义,用笔者模型预测偏最大的句子为例(来源于朋友圈文本):
有车一族都用了这个宝贝,后果很严重哦[偷笑][偷笑][偷笑]1,交警工资估计会打5折,没有超速罚款了[呲牙][呲牙][呲牙]2,移动联通公司大幅度裁员,电话费少了[呲牙][呲牙][呲牙]3,中石化中石油裁员2成,路痴不再迷路,省油[悠闲][悠闲][悠闲]5,保险公司裁员2成,保费折上折2成,全国通用[憨笑][憨笑][憨笑]买不买你自己看着办吧[调皮][调皮][调皮]
里面严重等词都是表达的相反意思,甚至整句话一起表示相反意思,不知死活的笔者还没能深入研究如何用词典的方法解决这类问题,但也许可以用机器学习的方法让神经网络进行学习能够初步解决这一问题。另外,同一个词可作多种词性,那么情感分数也不应相同,例如:
这部电影真垃圾
垃圾分类
很明显在第一句中垃圾表现强烈的贬义,而在第二句中表示中性,单一评分对于这类问题的分类难免有失偏颇。
1.1.2 否定词词典
否定词的出现将直接将句子情感转向相反的方向,而且通常效用是叠加的。常见的否定词:不、没、无、非、莫、弗、勿、毋、未、否、别、無、休、难道等。
1.1.3 程度副词词典
既是通过打分的方式判断文本的情感正负,那么分数绝对值的大小则通常表示情感强弱。既涉及到程度强弱的问题,那么程度副词的引入就是势在必行的。词典可从《知网》情感分析用词语集(beta版)http://www.keenage.com/download/sentiment.rar
词典内数据格式可参考如下格式,即共两列,第一列为程度副词,第二列是程度数值,> 1表示强化情感,< 1表示弱化情感。

1.1.4 停用词词典
中科院计算所中文自然语言处理开放平台发布了有1208个停用词的中文停用词表,http://www.datatang.com/data/43894
也有其他不需要积分的下载途径。
http://www.hicode.cc/download/view-software-13784.html
1.2 数据预处理
1.2.1 分词
即将句子拆分为词语集合,结果如下:
e.g. 这样/的/酒店/配/这样/的/价格/还算/不错
Python常用的分词工具(在此笔者使用Jieba进行分词):结巴分词 Jieba
Pymmseg-cpp
Loso
smallseg
- from collections import defaultdict
- import os
- import re
- import jieba
- import codecs
- “””
- 1. 文本切割
- “””def sent2word(sentence):
- “””
- Segment a sentence to words
- Delete stopwords
- “””
- segList = jieba.cut(sentence)
- segResult = [] for w in segList:
- segResult.append(w)
- stopwords = readLines(‘stop_words.txt’)
- newSent = [] for word in segResult: if word in stopwords:
- continue
- else:
- newSent.append(word) return newSent
1.2.2 去除停用词
遍历所有语料中的所有词语,删除其中的停用词
e.g. 这样/的/酒店/配/这样/的/价格/还算/不错–> 酒店/配/价格/还算/不错
1.3 构建模型
1.3.1 将词语分类并记录其位置
将句子中各类词分别存储并标注位置。
- “””2. 情感定位”””
- def classifyWords(wordDict): # (1) 情感词
- senList = readLines(‘BosonNLP_sentiment_score.txt’) senDict = defaultdict()
- for s in senList:
- senDict[s.split(‘ ‘)[0]] = s.split(‘ ‘)[1] # (2) 否定词
- notList = readLines(‘notDict.txt’) # (3) 程度副词 degreeList = readLines(‘degreeDict.txt’)
- degreeDict = defaultdict()
- for d in degreeList:
- degreeDict[d.split(‘,’)[0]] = d.split(‘,’)[1]
- senWord = defaultdict()
- notWord = defaultdict()
- degreeWord = defaultdict()
- for word in wordDict.keys():
- if word in senDict.keys() and word not in notList and word not in degreeDict.keys():
- senWord[wordDict[word]] = senDict[word]
- elif word in notList and word not in degreeDict.keys(): notWord[wordDict[word]] = -1
- elif word in degreeDict.keys(): degreeWord[wordDict[word]] = degreeDict[word]
- return senWord, notWord, degreeWord
1.3.2 计算句子得分
在此,简化的情感分数计算逻辑:所有情感词语组的分数之和.
定义一个情感词语组:两情感词之间的所有否定词和程度副词与这两情感词中的后一情感词构成一个情感词组,即notWords + degreeWords + sentiWords,例如不是很交好,其中不是为否定词,为程度副词,交好为情感词,那么这个情感词语组的分数为:
finalSentiScore = (-1) ^ 1 * 1.25 * 0.747127733968
其中1指的是一个否定词,1.25是程度副词的数值,0.747127733968为交好的情感分数。
- “””3. 情感聚合”””
- def scoreSent(senWord, notWord, degreeWord, segResult):
- W = 1 score = 0 # 存所有情感词的位置的列表 senLoc = senWord.keys()
- notLoc = notWord.keys()
- degreeLoc = degreeWord.keys()
- senloc = -1 # notloc = -1 # degreeloc = -1
- # 遍历句中所有单词segResult,i为单词绝对位置
- for i in range(0, len(segResult)):
- # 如果该词为情感词
- if i in senLoc: # loc为情感词位置列表的序号 senloc += 1 # 直接添加该情感词分数 score += W * float(senWord[i])
- # print “score = %f” % score
- if senloc < len(senLoc) – 1:
- # 判断该情感词与下一情感词之间是否有否定词或程度副词 # j为绝对位置
- for j in range(senLoc[senloc], senLoc[senloc + 1]): # 如果有否定词
- if j in notLoc:
- W *= -1 # 如果有程度副词
- elif j in degreeLoc:
- W *= float(degreeWord[j])
- # i定位至下一个情感词
- if senloc < len(senLoc) – 1:
- i = senLoc[senloc + 1]
- return score
1.4 模型评价
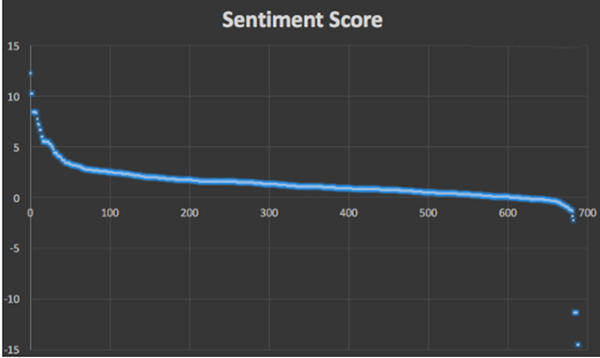
其中大多数文本被判为正向文本符合实际情况,且绝大多数文本的情感得分的绝对值在10以内,这是因为笔者在计算一个文本的情感得分时,以句号作为一句话结束的标志,在一句话内,情感词语组的分数累加,如若一个文本中含有多句话时,则取其所有句子情感得分的平均值。然而,这个模型的缺点与局限性也非常明显:
首先,段落的得分是其所有句子得分的平均值,这一方法并不符合实际情况。正如文章中先后段落有重要性大小之分,一个段落中前后句子也同样有重要性的差异。
其次,有一类文本使用贬义词来表示正向意义,这类情况常出现与宣传文本中,还是那个例子:
有车一族都用了这个宝贝,后果很严重哦[偷笑][偷笑][偷笑]1,交警工资估计会打5折,没有超速罚款了[呲牙][呲牙][呲牙]2,移动联通公司大幅度裁员,电话费少了[呲牙][呲牙][呲牙]3,中石化中石油裁员2成,路痴不再迷路,省油[悠闲][悠闲][悠闲]5,保险公司裁员2成,保费折上折2成,全国通用[憨笑][憨笑][憨笑]买不买你自己看着办吧[调皮][调皮][调皮]2980元轩辕魔镜带回家,推广还有返利[得意]
Score Distribution中得分小于-10的几个文本都是与这类情况相似,这也许需要深度学习的方法才能有效解决这类问题,普通机器学习方法也是很难的。
对于正负向文本的判断,该算法忽略了很多其他的否定词、程度副词和情感词搭配的情况;用于判断情感强弱也过于简单。
本文作者:佚名
来源:51CTO
Python做文本挖掘的情感极性分析(基于情感词典的方法)相关推荐
- 关于《流浪地球》炸裂的口碑,机器学习竟然是这样评价的————Python文本情感极性分析详解(下)
二.基于机器学习的文本情感极性分析 基于词向量Word2Vec建立机器学习模型 1.模型数学抽象 本文构建模型的目的是进行文本(影评)情感色彩识别,属于分类问题. NLP处理涉及分词(中文分词器:ji ...
- 关于《流浪地球》炸裂的口碑,机器学习竟然是这样评价的————Python文本情感极性分析详解(上)
NLP(神经语言程序学/自然语言学习)是当前机器学习领域一个重要的分支,就是用机器学习模型来理解处理人类的自然语言,并给出符合自然语言逻辑的反馈. 自然语言学习中具体的工作包括,教会程序用算法来正确地 ...
- Python做文本挖掘的情感极性分析
Python做文本挖掘的情感极性分析 数据挖掘入门与实战2017-03-23 21:25:41line阅读(27)评论(0) 声明:本文由入驻搜狐公众平台的作者撰写,除搜狐官方账号外,观点仅代表作者本 ...
- 情感极性分析:基于情感词典、k-NN、Bayes、最大熵、SVM的情感极性分析
向AI转型的程序员都关注了这个号???????????? 机器学习AI算法工程 公众号:datayx 1.预处理 (1).特征提取 对应文件:feature_extraction.py 最后结果: ...
- python情感分析语料库_利用Python实现中文情感极性分析
情感极性分析,即情感分类,对带有主观情感色彩的文本进行分析.归纳.情感极性分析主要有两种分类方法:基于情感知识的方法和基于机器学习的方法.基于情感知识的方法通过一些已有的情感词典计算文本的情感极性(正 ...
- Selenium爬取京东商品评价,并进行基于情感词典的文本情感极性分析
Selenium爬取京东商品评价,并进行基于情感词典的文本情感极性分析 1. 介绍及开发环境 2. 爬虫实现 2.1 请求构造 2.2 提取信息 2.3 数据存储 2.4 运行结果 3. 文本情感分析 ...
- 大江大河2弹幕数据之词云分析、情感极性分析、主题分析、共现网络分析
最近,自己在疯狂追<大江大河2>这部剧,作为当下最热门的电视剧之一,这部电视剧深受观众的喜爱,自从播出以后就好评不断 它主要讲述了改革开放三十年,一代人奋斗向阳的故事,看完之后深受启发,特 ...
- 百度点石情感极性分析--代码案例
情感极性分析 目前,为了增强我们学生的动手能力,老师组织我们参加了一场百度点石的练习赛,这是一场有着NLP背景的多分类问题, 搜集一些资料后,笔者拼来拼去,终于初步完成,目前f1得分为0.9066(未 ...
- 利用python做微信聊天记录词云分析——记录美好回忆
目录 1 概述 2 数据准备 2.1 安卓设备 2.1.1 Root手机,安装Root Explorer 2.1.2 用Root Explorer将聊天记录的数据文件导出并存入电脑 2.1.3 对En ...
最新文章
- 自动化测试框架cucumber_BDD测试框架之Cucumber使用入门
- ldconfig提示is not a symbolic link警告的去除方法
- [转]ActionScript 3.0入门:Hello World、文件读写、数据存储(SharedObject)、与JS互调
- python从低到高排序_使用python对matplotlib直方图中的xaxis值从最低值到最高值排序...
- Android复习14【高级编程:推荐网址、抠图片上的某一角下来、Bitmap引起的OOM问题、三个绘图工具类详解、画线条、Canvas API详解(平移、旋转、缩放、倾斜)、矩阵详解】
- web flash rtmp_基于RTMP和WebRTC开发大规模低延迟(1000毫秒内)直播系统
- [转载] Java中日期格式转换
- 【华为大咖分享】8.Focus on Value 的思考与实践精粹(后附PPT下载地址)
- 乐山市计算机学校欺骗,据说这个学校很乱。
- 局部变量AND全局变量
- jQuery 文档操作方法大全(也适用于 XML 文档和 HTML 文档)
- 三维视觉、SLAM方向全球顶尖实验室汇总
- 计算机硬盘中没有设控制器,电脑设置硬盘为兼容模式
- Mac 输入法候选词框消失的解决方法
- 第一次使用公有云需要注意啥
- vmware启动虚拟机报“内部错误”的解决方法
- SVN提交失败 can‘t open file‘\db\txn-current-lock’
- 计算机考研院校难度排行榜
- 怎么把1g的视频压缩到500m?
- CSS实现内容强制不换行、自动换行、强制换行