数据不平衡问题——SMOTE算法赏析
春节前后好久没有总结问题了,这一段时间一直在做NLP的文本分类(二分类)问题,遇到了各种问题 。分别如下:
1、数据打标问题。运营人手不够可把兄弟们累坏了,是我给兄弟们分的任务,别打我嘿嘿。
打标问题主要是业务不熟悉,主观上分类很容易分错,在分类的时候一定要让运营方来确定分类标准。
2、数据不平衡问题。T:F为1:10,重新筛选样本以后达到了T:F为1:17。
实在是数据很脏,没得办法。
之前的blog关于样本不平衡的参考:https://blog.csdn.net/qq_33472765/article/details/86561557
3、过拟合问题。
这个问题不管是什么任务都是无法避免的会遇到。
我们采用的方法是添加dropout层。
4、precision和recall问题。
这俩真是冤家路窄,此消彼长。
5、loss跑飞,这个很尴尬!
造成原因是数据的问题,划分数据集的时候没有打乱数据导致的。
提醒我以后要注意划分数据集要及时打乱数据在开始划分。(eg:我们有10条业务线的数据,在不打乱数据的时候划分数据集就会造成训练集有前6个业务线的样本,验证集有2个业务线的样本,测试集也有2个业务线的样本,每条业务线都是独立的。)
**********************************************************************************************************
这篇blog主要是对smote算法的介绍和参考,当然是站在别人的肩膀上的。
不平衡问题其实常用的就是过采样和欠采样。smote就是针对少类样本进行过采样(从已有正样本生成正样本:增强正样本)
原文地址:http://m.elecfans.com/article/620100.html
本次分享的主题是关于数据挖掘中常见的非平衡数据的处理,内容涉及到非平衡数据的解决方案和原理,以及如何使用Python这个强大的工具实现平衡的转换。
SMOTE算法的介绍
在实际应用中,读者可能会碰到一种比较头疼的问题,那就是分类问题中类别型的因变量可能存在严重的偏倚,即类别之间的比例严重失调。如欺诈问题中,欺诈类观测在样本集中毕竟占少数;客户流失问题中,非忠实的客户往往也是占很少一部分;在某营销活动的响应问题中,真正参与活动的客户也同样只是少部分。
如果数据存在严重的不平衡,预测得出的结论往往也是有偏的,即分类结果会偏向于较多观测的类。对于这种问题该如何处理呢?最简单粗暴的办法就是构造1:1的数据,要么将多的那一类砍掉一部分(即欠采样),要么将少的那一类进行Bootstrap抽样(即过采样)。但这样做会存在问题,对于第一种方法,砍掉的数据会导致某些隐含信息的丢失;而第二种方法中,有放回的抽样形成的简单复制,又会使模型产生过拟合。
为了解决数据的非平衡问题,2002年Chawla提出了SMOTE算法,即合成少数过采样技术,它是基于随机过采样算法的一种改进方案。该技术是目前处理非平衡数据的常用手段,并受到学术界和工业界的一致认同,接下来简单描述一下该算法的理论思想。
SMOTE算法的基本思想就是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。该算法的模拟过程采用了KNN技术,模拟生成新样本的步骤如下:
采样最邻近算法,计算出每个少数类样本的K个近邻;
从K个近邻中随机挑选N个样本进行随机线性插值;
构造新的少数类样本;
将新样本与原数据合成,产生新的训练集;
为了使读者理解SMOTE算法实现新样本的模拟过程,可以参考下图和人工新样本的生成过程:
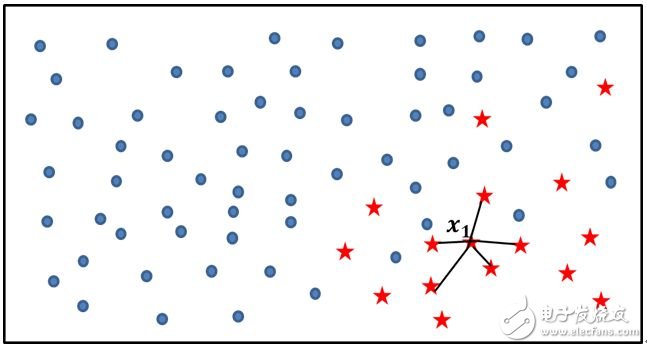
如上图所示,实心圆点代表的样本数量要明显多于五角星代表的样本点,如果使用SMOTE算法模拟增加少类别的样本点,则需要经过如下几个步骤:
利用KNN算法,选择离样本点x1最近的K个同类样本点(不妨最近邻为5);
从最近的K个同类样本点中,随机挑选M个样本点(不妨M为2),M的选择依赖于最终所希望的平衡率;
对于每一个随机选中的样本点,构造新的样本点;新样本点的构造需要使用下方的公式:

其中,xi表示少数类别中的一个样本点(如图中五角星所代表的x1样本);xj表示从K近邻中随机挑选的样本点j;rand(0,1)表示生成0~1之间的随机数。
假设图中样本点x1的观测值为(2,3,10,7),从图中的5个近邻中随机挑选2个样本点,它们的观测值分别为(1,1,5,8)和(2,1,7,6),所以,由此得到的两个新样本点为:

重复步骤1)、2)和3),通过迭代少数类别中的每一个样本xi,最终将原始的少数类别样本量扩大为理想的比例;
通过SMOTE算法实现过采样的技术并不是太难,读者可以根据上面的步骤自定义一个抽样函数。当然,读者也可以借助于imblearn模块,并利用其子模块over_sampling中的SMOTE“类”实现新样本的生成。有关该“类”的语法和参数含义如下:

ratio:用于指定重抽样的比例,如果指定字符型的值,可以是’minority’,表示对少数类别的样本进行抽样、’majority’,表示对多数类别的样本进行抽样、’not minority’表示采用欠采样方法、’all’表示采用过采样方法,默认为’auto’,等同于’all’和’not minority’;如果指定字典型的值,其中键为各个类别标签,值为类别下的样本量;
random_state:用于指定随机数生成器的种子,默认为None,表示使用默认的随机数生成器;
k_neighbors:指定近邻个数,默认为5个;
m_neighbors:指定从近邻样本中随机挑选的样本个数,默认为10个;
kind:用于指定SMOTE算法在生成新样本时所使用的选项,默认为’regular’,表示对少数类别的样本进行随机采样,也可以是’borderline1’、’borderline2’和’svm’;
svm_estimator:用于指定SVM分类器,默认为sklearn.svm.SVC,该参数的目的是利用支持向量机分类器生成支持向量,然后再生成新的少数类别的样本;
n_jobs:用于指定SMOTE算法在过采样时所需的CPU数量,默认为1表示仅使用1个CPU运行算法,即不使用并行运算功能;
分类算法的应用实战
本次分享的数据集来源于德国某电信行业的客户历史交易数据,该数据集一共包含条4,681记录,19个变量,其中因变量churn为二元变量,yes表示客户流失,no表示客户未流失;剩余的自变量包含客户的是否订购国际长途套餐、语音套餐、短信条数、话费、通话次数等。接下来就利用该数据集,探究非平衡数据转平衡后的效果。



如上图所示,流失用户仅占到8.3%,相比于未流失用户,还是存在比较大的差异的。可以认为两种类别的客户是失衡的,如果直接对这样的数据建模,可能会导致模型的结果不够准确。不妨先对该数据构建随机森林模型,看看是否存在偏倚的现象。
原始数据表中的state变量和Area_code变量表示用户所属的“州”和地区编码,直观上可能不是影响用户是否流失的重要原因,故将这两个变量从表中删除。除此,用户是否订购国际长途业务international_plan和语音业务voice_mail_plan,属于字符型的二元值,它们是不能直接代入模型的,故需要转换为0-1二元值。


如上表所示,即为清洗后的干净数据,接下来对该数据集进行拆分,分别构建训练数据集和测试数据集,并利用训练数据集构建分类器,测试数据集检验分类器:

如上结果所示,决策树的预测准确率超过93%,其中预测为no的覆盖率recall为97%,但是预测为yes的覆盖率recall却为62%,两者相差甚远,说明分类器确实偏向了样本量多的类别(no)。

如上图所示,ROC曲线下的面积为0.795,AUC的值小于0.8,故认为模型不太合理。(通常拿AUC与0.8比较,如果大于0.8,则认为模型合理)。接下来,利用SMOTE算法对数据进行处理:

如上结果所示,对于训练数据集本身,它的类别比例还是存在较大差异的,但经过SMOTE算法处理后,两个类别就可以达到1:1的平衡状态。下面就可以利用这个平衡数据,重新构建决策树分类器了:

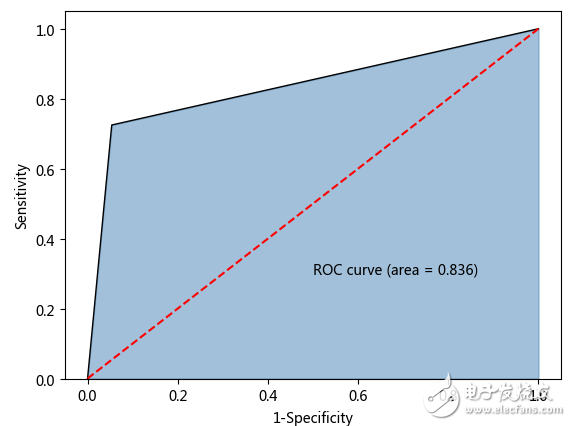
如上结果所示,利用平衡数据重新建模后,模型的准确率同样很高,为92.6%(相比于原始非平衡数据构建的模型,准确率仅下降1%),但是预测为yes的覆盖率提高了10%,达到72%,这就是平衡带来的好处。

最终得到的AUC值为0.836,此时就可以认为模型相对比较合理了。
数据不平衡问题——SMOTE算法赏析相关推荐
- 数据预处理与特征工程—1.不均衡样本集采样—SMOTE算法与ADASYN算法
文章目录 一.第一种思路:平衡采样 1.SMOTE算法 2.SMOTE与RandomUnderSampler进行结合 3.Borderline-SMOTE与SVMSMOTE 4.ADASYN 5.平衡 ...
- SMOTE算法代码实现-机器学习
类别不平衡问题 类别不平衡问题,顾名思义,即数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题.例如逻辑回归即不适合处理类别不平衡问题,例如逻辑回归在欺诈检测问 ...
- 数据挖掘:数据清洗——数据不平衡处理
数据挖掘:数据清洗--数据不平衡处理 一.什么是数据不平衡? 不平衡数据集指的是数据集各个类别的样本数目相差巨大,也叫数据倾斜.以二分类问题为例,即正类的样本数量远大于负类的样本数量.严格地讲,任何数 ...
- 机器学习数据不平衡不均衡处理之SMOTE算法实现
20201125 当多数类和少数类数量相差太大的时候,少数类不一定要补充到和多数类数量一致 最好的办法就是全部过采样到最大记录数的类别 调参 SMOTE:只是过采样 SMOTEENN:过采样的同时欠采 ...
- 数据不平衡imblearn算法汇总
转载自:kizgel的博客 Imblearn package study 准备知识 1 Compressed Sparse RowsCSR 压缩稀疏的行 过采样Over-sampling 1 实用性的 ...
- python使用imbalanced-learn的SMOTE方法进行上采样处理数据不平衡问题
python使用imbalanced-learn的SMOTE方法进行上采样处理数据不平衡问题 机器学习中常常会遇到数据的类别不平衡(class imbalance),也叫数据偏斜(class skew ...
- 数据不平衡、不平衡采样、调整分类阈值、过采样、欠采样、SMOTE、EasyEnsemble、加入数据平衡的流程、代价敏感学习BalanceCascade、
数据不平衡.不平衡采样.调整分类阈值.过采样.欠采样.SMOTE.EasyEnsemble.加入数据平衡的流程.BalanceCascade.代价敏感学习 目录
- 影像组学视频学习笔记(30)-SMOTE解决数据不平衡的问题、Li‘s have a solution and plan.
本笔记来源于B站Up主: 有Li 的影像组学系列教学视频 本节(30)主要介绍: SMOTE解决数据不平衡的问题 SMOTE基本介绍 SMOTE (Synthetic Minority Over-sa ...
- 数据不平衡的解决办法
转载自:https://www.leiphone.com/news/201706/dTRE5ow9qBVLkZSY.html 数据不平衡问题主要存在于有监督机器学习任务中.当遇到不平衡数据时,以总体分 ...
- python过采样代码实现_过采样中用到的SMOTE算法
平时很多分类问题都会面对样本不均衡的问题,很多算法在这种情况下分类效果都不够理想.类不平衡(class-imbalance)是指在训练分类器中所使用的训练集的类别分布不均.比如说一个二分类问题,100 ...
最新文章
- 线上比赛投诉:同一赛点两支队伍比赛车模是否相同?
- 使用Zookeeper实现leader选举-LeaderSelector
- 我们注意到您的计算机目前处于离线状态_你为什么会选择用反渗透设备离线清洗设备?...
- 高效能程序员的七个习惯
- 简述tcp协议三报文握手过程_TCP协议的3次握手与4次挥手过程详解
- 架构篇:大型网站技术架构
- Android webView嵌套h5页面 软键盘遮盖页面问题 解决方案 java kotlin
- 使用idea导入远程git版本库项目
- obj类型的3d人体模型解读
- 深入解密比Guava Cache更优秀的缓存-Caffeine
- 美创解读|《数据安全法》实施,企业数据安全合规技术能力建设
- 软负载均衡和F5负载均衡(硬负载均衡)区别
- Python 助你填写高考志愿
- Opencv入门(播放AVI视频)
- python的selenium的带https安全隐私问题解决方案
- 我的世界网易绘梦师国服 物品材料介绍
- java发送图片_Java发送邮件(图片、附件、HTML)
- AI作画的业界天花板被我找到了,AIGC模型揭秘 | 昆仑万维
- 宝塔开启ngx_pagespeed加速网站
- 升级sp3后出现:一个问题阻止windows正确检测此机器许可证--解决方案