Keil C51程序设计
转载地址:http://www.dwenzhao.cn/profession/mcu/mcu51keilc.html
Keil C51是一种专为8051系列单片机设计的C编译器,支持符合ANSI标准的C语言进行程序设计,同时针对8051系列单片机自身特点做了一些特殊扩展。
1. Keil C51程序设计基本语法:
1)Keil C51程序的一般结构:
C51程序由一个或多个函数构成,其中至少应包含一个主函数main()。程序执行时,一定是从main()函数开始,调用其他函数后又返回main()函数,被调用函数如果位于主调函数前面则可直接调用,否则要先说明后调用,函数之间可以互相调用。C51程序的一般结构如下:
预处理命令 //用于包含头文件等
全局变量说明; //全局变量可被本程序的所有函数引用
函数1说明;
... ...
函数n说明;
/*主函数*/
main(){
局部变量说明; //局部变量只能在所定义的函数内部引用
执行语句;
函数调用(形式参数表);
}
/*其他函数定义*/
函数1(形式参数定义){
局部变量说明; //局部变量只能在所定义的函数内部引用
执行语句;
函数调用(形式参数表);
}
... ...
函数n(形式参数定义){
局部变量说明; //局部变量只能在所定义的函数内部引用
执行语句;
函数调用(形式参数表);
}
由此可见,C51是由函数组成的,函数之间可以相互调用,但main()函数只能调用其他功能函数,不能被其他函数调用。其他功能函数,可以是C51编译器提供的库函数,也可以是用户按需要自行编写的。不管main()函数处于程序中什么位置,程序总是从main()开始执行。
编写C51程序的注意点:
①函数以“{”开始,以“}”结束,二者必须成对出现,它们之间的部分为函数体。
②C51程序没有行号,一行内可以书写多条语句,一条语句也可以分写在多行上。
③每条语句最后必须以一个分号“;”结尾,分号是C51程序的必要组成部分。
④每个变量必须先定义后引用。函数内部定义的变量为局部变量,又称内部变量,只有在定义它的那个函数之内才能够使用。在函数外部定义的变量为全局变量,又称外部变量,在定义它的那个程序文件中的函数都可以使用它。
⑤对程序语句的注释必须放在双斜杠“//”之后,或者放在“/*......*/”之内。
2)数据类型:
C51数据类型可分为基本数据类型和复杂数据类型,复杂数据类型由基本数据类型构造而成。基本数据类型有char(字符型)、int(整型)、long(长整型)、float(浮点型)和*(指针型)。下表列出了Keil C51编译器能够识别的数据类型:
|
数据类型 |
长度 |
值域 |
|
unsigned char |
单字节 |
0~255 |
|
signed char |
单字节 |
-128~+127 |
|
unsigned int |
双字节 |
0~65536 |
|
signed int |
双字节 |
-32768~+32767 |
|
unsigned long |
四字节 |
0~4294967295 |
|
signed long |
四字节 |
-2147483648~+2147483647 |
|
float |
四字节 |
±1.175494E-38~±3.402823E+38 |
|
* |
1~3字节 |
对象的地址 |
|
bit |
位 |
0或1 |
|
sfr |
单字节 |
0~255 |
|
sfr16 |
双字节 |
0~65536 |
|
sbit |
位 |
0或1 |
Keil C51编译器除了支持基本数据类型之外,还支持扩充数据类型:
①bit:位类型,可以定义一个位变量,但不能定义位指针,也不能定义位数组。
②sfr:特殊功能寄存器,可以定义8051单片机的所有内部8位特殊功能寄存器。sfr型数据占用一个内存单元,其取值范围是0~255。
③sfr16:16位特殊功能寄存器,它占用两个内存单元,取值范围0~65535,可以定义8051单片机内部的16位特殊功能寄存器。
④sbit:可寻址位,可以定义8051单片机内部RAM中的可寻址位或特殊功能寄存器中的可寻址位。
示例:采用如下语句可以将8051单片机P0口地址定义为80H,将P0.1位定义为FLAG1。
sfr P0=80H;
sbit FLAG1=P0^1;
3)常量、变量及其存储模式:
常量包括整型变量、浮点型变量、字符型常量及字符串常量等。
变量,是一种在程序执行过程中其值能不断变化的量。在使用一个变量之前,必须先进行定义,用一个标识符作为变量名并指出它的数据类型和存储类型,以便编译系统为它分配相应的存储单元。在C51中对变量进行定义的格式如下:
[存储种类] 数据类型 [存储器类型] 变量名表;
其中,“存储种类”和“存储器类型”是可选项。变量的存储种类有4种:auto自动、extern外部、static静态和register寄存器。定义变量时如果省略存储种类选项,则该变量将为自动变量。
Keil C51编译器还允许说明变量的存储器类型,使之能够在8051单片机系统内准确地定位。下表列出了Keil C51编译器所能识别的存储器类型:
|
存储器类型 |
说明 |
|
DATA |
直接寻址的片内数据存储器(128B),访问速度最快 |
|
BDATA |
可位寻址的片内数据存储器(16B),允许位与字节混合访问 |
|
IDATA |
间接访问的片内数据存储器(256B),允许访问全部片内地址 |
|
PDATA |
分页寻址的片外数据存储器(256B),用MOVX @Ri指令访问 |
|
XDATA |
片外数据存储器(64KB),用MOVX @DPTR指令访问 |
|
CODE |
程序存储器(64KB),用MOVC @A+DPTR指令访问 |
下面是一些变量定义的示例:
char data var1; //在DATA区定义字符型变量var1
int idata var2; //在IDATA区定义整型变量var2
char code text[]=”ENTER PARAMETER”; //在CODE区定义字符串数组text[]
long xdata array[100]; //在XDATA区定义长整数数组变量array[100]
extern float idata x,y,z; //在IDATA区定义外部浮点型变量x, y, z
char bdata flags; //在BDATA区定义字符型变量flags
sbit flag0=flags^0; //在BDATA区定义可位寻址变量flag0
sfr P0=ox80; //定义特殊功能寄存器P0
定义变量时如果省略“存储器类型”选项,则按编译时使用的存储器模式SMALL、COMPACT或LARGE来规定默认存储器类型,确定变量的存储器空间。函数中不能采用寄存器传递的参数变量的过程变量也保存在默认的存储器空间中。Keil C51编译器的3种存储器模式对变量的影响如下:
①SMALL:变量被定义在8051单片机片内数据存储器中,对这种变量的访问速度最快。另外,所有的对象,包括堆栈,都位于片内数据存储器中,实际的堆栈长度取决于不同函数的嵌套深度。
②COMPACT:变量被定义在分页寻址的片外数据存储器中,每一页片外数据存储器的长度为256B。这时对变量的访问是通过寄存器间接寻址(MOVX @Ri)进行的,堆栈位于8051单片机片内数据存储器中。采用这种模式的同时,必须适当改变启动配置文件STARTUP.A51中的参数PDATASTART和PDATALEN;在用BL51进行连接时,还必须采用连接控制命令“PDATA”对P2口地址进行定位,这样才能确保P2口为所需要的高8位地址。
③LARGE:变量被定义在片外数据存储器中(最大可达64KB),通常使用数据指针(DPTR)来间接访问变量(MOVX @DPTR)。这种访问数据的方法效率不高,尤其是对于2个以上字节的变量。
Keil C51编译器在不同编译模式下的存储器类型:
|
编译模式 |
存储器类型 |
|
SMALL |
DATA |
|
COMPACT |
PDATA |
|
LARGE |
XDATA |
4)运算符与表达式:
Keil C51对数据有很强的表达能力,具有十分丰富的运算符。运算符就是完成某种特定运算的符号,表达式则是由运算符及运算对象所组成的具有特定含义的算式。
运算符,按其在表达式中所起的作用,可分为赋值运算符、算术运算符、增量与减量运算符、关系运算符、逻辑运算符、位运算符、复合赋值运算符、逗号运算符、条件运算符、指针和地址运算符、强制类型转换运算符等。
⑴赋值运算符:
在C51程序中,符号“=”称为赋值运算符,作用是将一个数据的值赋给一个变量。
⑵算术运算符:
C语言中的算术运算符有+、-、*、/(除)和%(取余)运算符。其中加、减和乘法都符合一般的算术运算规则,但除法和取余有所不同。如果两个整数相除,其结果为整数,舍去小数部分;如果是两个浮点数相除,其结果为浮点数。取余运算要求两个运算对象均为整形数据。
⑶增量和减量运算符:
C51还提供有一种特殊的运算符,即++(增量)和--(减量)运算符,作用分别是对运算对象作加1和减1运算。增量和减量运算符只能用于变量,不能用于常数或表达式,在使用中还要注意运算符的位置。例如,++i与i++的意义不同,前者为在使用i前先使i加1,而后者则是在使用i之后再使i的值加1。
⑷关系运算符:
C语言中有以下6种关系运算符:>、<、>=、<=、= =、!=。用关系运算符将两个表达式连接起来即称为关系表达式。
⑸逻辑表达式:
C51中有以下3种逻辑运算符:||(逻辑或)、&&(逻辑与)、!(逻辑非)。用逻辑运算符将关系表达式或逻辑量连接起来即称为逻辑表达式。
关系运算符和逻辑运算符通常用来判别某个条件是否满足,关系运算和逻辑运算的结果只有0和1两种值。当所指定的条件满足时结果为1,条件不满足时结果为0。
⑹位运算符:
C51中共有以下6种位运算符:~(按位取反)、<<(左移)、>>(右移)、&(按位与)、^(按位异或)、|(按位或)。为运算符的作用是按位对变量进行运算。位运算符不能用来对浮点型数据进行操作。
⑺复合赋值运算符:
在赋值运算符“=”的前面加上其他运算符,就构成了复合赋值运算符。C51中共有以下10种复合赋值运算符:+=(加法赋值)、-=(减法赋值)、*=(乘法赋值)、/=(除法赋值)、%=(取模赋值)、<<=(左移位赋值)、>>=(右移位赋值)、&=(逻辑与赋值)、|=(逻辑或赋值)、^=(逻辑异或赋值)、~=(逻辑非赋值)。
复合赋值运算,首先对变量进行某种操作,然后将运算的结果再赋给该变量。采用复合赋值运算符,可以使程序简化,同时还可以提高程序的编译效率。
⑻逗号运算符:
在C51程序中,逗号“,”是一种特殊的运算符,用逗号运算符连接起来的两个(或多个)表达式,称为逗号表达式。在程序运行时,对逗号表达式的处理是从左至右依次计算出各个表达式的值,而整个逗号表达式的值是最右边表达式(即表达式n)的值。
⑼条件运算符:
条件运算符“?:”是C51中唯一的三目运算符,它要求有3个运算对象,用它可以将3个表达式连接构成一个条件表达式。条件表达式的一般形式如下:
逻辑表达式 ? 表达式1 : 表达式2
其功能是:首先计算逻辑表达式,当值为真(非0值)时,将表达式1的值作为整个条件表达式的值;当逻辑表达式的值为假(0值)时,将表达式2的值作为整个条件表达式的值。
例如,条件表达式max=(a>b)?a:b的执行结果是将a和b中的较大者赋值给变量max。另外,条件表达式中逻辑表达式的类型可以与表达式1和表达式2的类型不一样。
⑽指针和地址运算符:
C51中专门规定了一种指针类型的数据,变量的指针就是该变量的地址,还可以定义一个指向某个变量的指针变量。C51提供了以下两个专门的运算符:*(取内容)、&(取地址)。
取内容和取地址运算的一般形式如下:
变量=*指针变量
指针变量=&目标变量
取内容运算的含义是将指针变量所指向的目标变量的值赋给左边的变量;取地址运算的含义是将目标变量的地址赋给左边的变量。需要注意,指针变量中只能存放地址(即指针型数据),不要将一个非指针类型的数据赋值给一个指针变量。示例:
char data *p //定义指针变量
p=30H //给指针变量赋值,30H为8051片内RAM地址
⑾C51对存储器和特殊功能寄存器的访问:
由于8051单片机存储器结构自身的特点,C51提供了利用库函数中的绝对地址访问头文件“absacc.h”来访问不同区域的存储器以及片外扩展I/O端口的方法。
在“absacc.h”头文件中进行了如下宏定义:
CBYTE[地址] (访问CODE区char型)
DBYTE[地址] (访问DATA区char型)
PBYTE[地址] (访问PDATA区或I/O端口char型)
XBYTE[地址] (访问XDATA区或I/O端口char型)
CWORD[地址] (访问CODE区int型)
DWORD[地址] (访问DATA区int型)
PWORD[地址] (访问PDATA区或I/O端口int型)
XWORD[地址] (访问XDATA区或I/O端口int型)
下面的语句是向片外扩展端口地址7FFFH写入一个字符型数据:
XBYTE[0x7FFF]=0x80;
下面的语句是将int型数据0x9988送入外部RAM单元0000H和0001H:
XWORD[0]=0x9988;
如果采用如下语句定义一个D/A转换器端口地址:
#define DAC0832 XBYTE[0x7FFF]
那么程序文件中所有出现DAC0832的地方,就是对地址为0x7FFFH的外部RAM单元或I/O端口进行访问。
8051单片机具有100多个品种,为了方便访问不同品种单片机内部特殊功能寄存器,C51提供了多个相关头文件,如reg51.h、reg52.h等。在头文件中,对单片机内部特殊功能寄存器及其可寻址位进行了定义,编程时只要根据所采用的单片机,在程序文件的开始处用文件包含处理命令“#include”将相关头文件包含进来,然后就可以直接引用特殊功能寄存器了。例如,下面语句完成的8051定时方式寄存器TMOD的赋值:
#include <reg51.h>
TMOD=0x20;
⑿强制类型转换运算符:
C语言中的圆括号“()”也可作为一种运算符使用,这就是强制类型转换运算符,它的作用是将表达式或变量的类型强制转换成为所指定的类型。
数据类型转换分为隐式转换和显式转换。隐式转换是在对程序编译时由编译器自动处理的,并且只有基本数据类型(即char、int、long和float)可以进行隐式转换,其他数据类型不能进行隐式转换,这种情况下就必须利用强制类型转换运算符来进行显式转换。强制类型转换运算符的一般使用形式如下:
(类型)=表达式
显式强制类型转换在给指针变量赋值时特别有用。例如,预先在8051单片机的片外数据存储器(XDATA)中定义了一个字符型指针变量px,如果想给这个指针变量赋一初值0xB000,可以写成px=(char xdata *)0xB00
2. C51程序的基本语句:
C51提供了十分丰富的程序控制语句。
1)表达式语句:
表达式语句是最基本的一种语句。在表达式的后面加一个分号“;”,就构成了表达式语句。表达式语句也可以仅由一个分号“;”组成,这种语句称为空语句。当程序在语法上需要有一个语句,但在语义上并不要求有具体的动作时,便可以采用空语句。
2)复合语句:
复合语句,是由若干条语句组合而成的一种语句,是用“{}”将若干条语句组合在一起而形成的功能块,内部的各条单语句需以“;”结束。复合语句的一般形式如下:
{
局部变量定义;
语句1;
语句2;
... ...
语句n;
}
复合语句在执行时,其中各条语句依次顺序执行。整个复合语句在语法上等价于一条单语句。复合语句允许嵌套,即在复合语句内部还可以包含其他的复合语句。实际上,函数的执行部分(函数体)就是一个复合语句。复合语句中的单语句一般是可执行语句,也可以是变量定义语句。在复合语句内所定义的变量,称为该复合语句中的局部变量,仅在当前复合语句中有效。
3)条件语句:
条件语句,又称为分支语句,是用关键字“if”构成的。C51提供了3种形式的条件语句:
①if (表达式) 语句
含义是:若条件表达式的结果为真(非0值),执行后面的语句;反之,若条件表达式的结果为假(0值),不执行后面的语句。其中的语句也可以是复合语句。
②if (表达式) 语句1
else 语句2
含义是:若条件表达式的结果为真(非0值),执行语句1;反之,若条件表达式的结果为假(0值),执行语句2。其中的语句都可以是复合语句。
③if (条件表达式1) 语句1
else if (条件表达式2) 语句2
else if (条件表达式3) 语句3
... ...
else if (条件表达式m) 语句m
else 语句n
这种条件语句常用来实现多方向条件分支。当分支较多时,会使条件语句的嵌套层次太多,程序冗长,可读性降低。
4)开关语句:
开关语句也是一种用来实现多方向条件分支的语句。开关语句直接处理多分支选择,使程序结构清晰,使用方便。开关语句是用关键字switch构成的,一般形式如下:
switch (表达式)
{
case 常量表达式1:语句1;
break;
case 常量表达式2:语句2;
break;
... ...
case 常量表达式n:语句n;
break;
default:语句d;
}
开关语句的执行过程是:将switch后面的表达式的值与case后面各个常量表达式的值逐个进行比较,若遇到匹配时,就执行相应case后面的语句,然后执行break语句。若无匹配的情况,则只执行default后面的语句d。break语句又称间断语句,功能是中止当前语句的执行,使程序跳出switch语句。
5)循环语句:
实际应用中,很多地方要用到循环控制,如对于某种操作需要反复进行多次等。在C51程序中,用来构成循环控制的语句有while、do-while、for以及goto等形式的语句。
①采用while构成的循环结构:
while (表达式) 语句;
含义是:当条件表达式的结果为真(非0值)时,程序就重复执行后面的语句,一直执行到条件表达式的结果变为假(0值)为止。这种循环结构是先检查条件表达式所给出的条件,再根据检查结果决定是否执行后面的语句。如果条件表达式的结果一开始就为假,则后面的语句一次也不会被执行。这里的语句可以是复合语句。
②采用do-while构成的循环结构:
do 语句 while (表达式);
含义是:当条件表达式的值为真(非0值)时,则重复执行循环体语句,直到条件表达式的值变为假(0值)为止。这种循环结构是先执行给定的循环语句,然后再检查条件表达式的结果,任何条件下循环体语句至少会被执行一次。
③采用for构成的循环结构:
for ([初值设定表达式];[循环条件表达式];[更新表达式]) 语句;
for语句的执行过程是:先计算初值表达式的值作为循环控制变量的初值,再检查循环条件表达式的结果,当满足条件时就执行循环体语句并计算更新表达式,然后再根据更新表达式的计算结果来判断循环条件是否满足... ...一直进行到循环条件表达式的结果为假(0值)时退出循环体。
6)goto、break、continue语句:
①goto语句:
是一个无条件转向语句,它的一般形式如下:
goto 语句标号;
其中,语句标号是一个带冒号“:”的标识符。将goto语句与if语句一起使用,可以构成一个循环语句,但更常见的是采用goto语句来跳出多重循环。需要注意,只能用goto语句从内层循环跳到外层循环,而不允许从外层循环跳到内层循环。
②break语句:
break语句也用于跳出循环语句,只能用于开关语句和循环语句中,是一种具有特殊功能的无条件转移语句。对于多重循环的情况,break语句只能跳出它所处的那一层循环。
③continue语句:
continue语句是一种中断语句,功能是中断本次循环,通常和条件语句一起用在由while、do-while和for语句构成的循环结构中,也是一种具有特殊功能的无条件转移语句。但与break语句不同,continue语句并不跳出循环体,而只是根据循环控制条件确定是否继续执行循环语句。
7)返回语句:
返回语句用于终止函数的执行,并控制程序返回到调用该函数时所处的位置。返回语句有两种形式:
return (表达式);
return;
如果return语句后面带有表达式,则要计算表达式的值,并将表达式的值作为该函数的返回值。若使用不带表达式的形式,则被调用函数返回主函数时函数值不确定。一个函数的内部,可以含有多个return语句,但程序仅执行其中的一个return语句而返回主调用函数。一个函数的内部也可以没有return语句,在这种情况下,当程序执行到最后一个界限符“}”处时,就自动返回主调函数。
3. 函数:
从用户的角度看,有两种函数,即标准库函数和用户自定义函数。标准库函数是Keil C51编译器提供的,可以直接调用;用户自定义函数是用户根据自己的需要编写的,必须先进行定义之后才能调用。
1)函数的定义:
函数定义的一般形式如下:
函数类型 函数名(形式参数表)
{
局部变量定义;
函数体语句;
}
其中,函数类型说明了自定义函数返回值的类型;函数名是用标识符表示的自定义函数的名字;形式参数表中则列出了主调用函数与被调用函数之间传递的数据,形式参数的类型必须加以说明。局部变量是对在函数内部使用的局部变量进行定义;函数体语句是为完成该函数的特定功能而设置的各种语句。
ANSI C标准,允许在形式参数表中对形式参数的类型进行说明。如果定义的是无参函数,可以没有形式参数表,但圆括号“()”不能省略。
2)函数的调用:
所谓函数调用,就是在一个函数体中引用另外一个已经定义了的函数,前者称为主调函数,后者称为被调用函数。C51程序中,函数是可以互相调用的。函数调用的一般形式为:
函数名 (实际参数表)
其中,函数名指出被调用的函数;实际参数表中可以包括多个实际参数,各个参数之间用逗号“,”分开。实际参数的作用是将它的值传递给被调用函数中的形式参数。需要注意,函数调用中的实际参数与函数定义中的形式参数必须在个数、类型及顺序上严格保持一致,以便将实际参数的值正确地传递给形式参数,否则在函数调用时会产生意想不到的结果。如果调用的是无参函数,则可以没有形式参数表,但圆括号“()”不能省略。
C51中可以采用3种方式完成函数的调用:
①函数语句:
在主调函数中,将函数调用作为一条语句。这是无参调用,不要求被调用函数返回一个确定的值,只要求它完成一定的操作。
②函数表达式:
在主调函数中,将函数调用作为一个运算对象直接出现在表达式中,这种表达式称为函数表达式。这种函数调用方式通常要求被调用函数返回一个确定的值。
③函数参数:
在主调函数中,将函数调用作为另一个函数调用的实际参数。这种在调用一个函数的过程中又调用了另外一个函数的方式,称为嵌套函数调用。
3)函数的说明:
与使用变量一样,在调用一个函数之前(包括标准库函数),必须对该函数的类型进行说明,即“先说明,后调用”。如果调用的是库函数,一般应在程序的开始处用预处理命令#include将有关函数说明的头文件包含进来。
如果调用的是用户自定义函数,而且函数与调用它的主调函数在同一个文件中,一般应该在主调用函数中对被调用函数的类型进行说明。函数说明的一般形式如下:
类型标识符 被调用的函数名(形式参数表);
其中,类型标识符说明了函数的返回值的类型;形式参数表说明了各个形式参数的类型。
需要注意,函数定义与函数说明是完全不同的,书写方式上也有差别。函数定义时,被定义函数名的圆括号后面没有分号“;”,函数定义还未结束,后面应接着写被定义的函数体部分;而函数说明结束时,在圆括号的后面需要有一个分号“;”作为结束标志。
4)中断服务函数:
C51支持在C语言源程序中直接编写8051单片机的中断服务函数程序,一般形式为:
函数类型 函数名(形式参数表) [interrupt n] [using n]
关键字interrupt后面的n是中断号,n的取值范围为0~31.编译器从8n+3处产生中断向量,具体的中断号n和中断向量取决于8051系列单片机芯片的型号。常用的中断源与中断向量表如下表:
|
中断号n |
中断源 |
中断向量8n+3 |
|
0 |
外部中断0 |
0003H |
|
1 |
定时器0 |
000BH |
|
2 |
外部中断1 |
0013H |
|
3 |
定时器1 |
001BH |
|
4 |
串行口 |
0023H |
8051系列单片机可以在片内PAM中使用4个不同的工作寄存器组,每个寄存器组中包含8个工作寄存器(R0~R7)。C51编译器扩展了一个关键字using,专门用来选择8051单片机中不同的工作寄存器组。using后面的n是一个0~3的常整数,分别选中4个不同的工作寄存器组。在定义一个函数时,using是一个选项,如果不用该选项,则由编译器自动选择一个寄存器组做绝对寄存器组访问。
编写8051单片机中断函数时应遵循以下规则:
①中断函数不能进行参数传递,也没有返回值,因此一般定义为void型。
②在任何情况下都不能直接调用中断函数,否则会产生编译错误。
③如果中断函数中调用了其他函数,则被调用函数所使用的寄存器组必须与中断函数相同。
④C51编译器从绝对地址8n+3处产生一个中断向量,其中n为中断号,该向量包含一个到中断函数入口地址的绝对跳转。
5. Keil C51编译器对ANSI C的扩展:
1)存储器类型:
8051单片机的存储器空间可分为片内外统一编址的程序寄存器ROM、片内数据存储器RAM和片外数据存储器RAM。
①C51编译器对ROM存储器提供了存储器类型标识符code,用户的应用程序代码以及各种表格常数被定为在code空间。
②数据存储器RAM用于存放各种变量,通常应尽可能将变量放在片内RAM中以加快操作速度。C51编译器对片内RAM提供了3种存储器类型标识符,即data、idata、bdata。data地址范围为0x00~0x7f,位于data空间的变量以直接寻址方式操作,速度很快;idata地址范围为0x00~0xff,位于idata空间的变量以寄存器间接寻址方式操作,速度略慢于data空间;bdata地址范围为0x20~0x2f,位于bdata空间的变量,除了可以进行直接寻址或间接寻址之外,还可以进行位寻址操作。
③片外数据RAM简称XRAM,C51提供了xdata和pdata两个存储器类型标识符。xdata空间地址范围为0x0000~0xffff,位于xdata空间的变量以MOVX @DPTR方式寻址,可以操作整个64KB地址范围内的变量,但这种方式速度最慢;pdata空间又称为片外分页XRAM空间,它将地址0x0000~0xffff均匀地分成256页,每页地址都为0x00~0xff,位于pdata空间的变量以MOVX @R0、MOVX @R1方式寻址。实际上,XRAM空间并非全部用于存放变量,用户扩展的I/O接口也位于XRAM地址范围之内。有些新型的80C51单片机还提供有片内XRAM,其操作方式与传统的XRAM相同,但一般要先对相应的特殊功能寄存器(SFR)进行配置之后才能使用。
一些新型的8051单片机能够进行大容量存储器扩展,如到8MB甚至16MB的code和xdata存储器空间。C51编译器针对这种大容量扩展存储器定义了far和const far两种存储器类型,分别用以操作这种扩展的片外RAM和片外ROM空间。
对于传统的8051单片机,如果具有可以映射到xdata的附加存储器空间,或者提供了一种地址扩展特殊功能寄存器,则可以根据具体硬件电路通过修改配置文件XBANKING.A51来使用far和const far类型的变量。需要注意,在使用far和const far存储器类型时,必须采用LX51扩展连接定位器,同时还必须采用OMF2格式的目标文件。
下表列出了Keil C51编译器能够识别的存储器类型:
|
存储器类型 |
说明 |
|
code |
程序存储器(64KB),用MOVC @A+DPTR指令访问 |
|
data |
直接寻址的片内数据存储器(128B),访问速度最快 |
|
idata |
间接访问的片内数据存储器(256B),允许访问全部片内地址 |
|
bdata |
可位寻址的片内数据存储器(16B),允许位与字节混合访问 |
|
xdata |
片外数据存储器(64KB),用MOVX @DPTR指令访问 |
|
pdata |
分页寻址的片外数据存储器(256B),用MOVX @R0、MOVX @R1指令访问 |
|
far |
高达16MB的扩展RAM和ROM,专用芯片扩展访问或用户自定义子程序进行访问 |
2)编译模式:
如果定义变量时没有明确指出具体的存储器类型,则按C51编译器采用的编译模式来确定变量的默认存储器空间。Keil C51编译器控制命令SMALL、COMPACT、LARGE对变量存储空间的影响如下:
①SMALL:所有变量都被定义在8051单片机的片内RAM中,对这种变量的访问速度最快。另外,堆栈也必须位于片内RAM中,实际的堆栈长度取决于不同函数的嵌套深度。采用SMALL编译模式,与定义变量时指定data存储器类型具有相同的效果。
②COMPACT:所有变量被定义在分页寻址的片外XRAM中,每一页片外XRAM的长度都为256B。这时对变量的访问是通过寄存器间接寻址(MOVX @R0、MOVX @R1)进行的,变量的低8位地址由R0或R1确定,变量的高8位地址由P2口确定。采用这种模式时,必须适当改变配置文件STARTUP.A51中参数PDATASTART和PDATALEN;同时还必须在编译器菜单“option选项/BL51 Locator标签栏/Pdata”打开的对话框中键入合适的地址参数,以确保P2口能输出所需要的高8位地址。而堆栈则位于8051单片机片内数据存储器中。采用COMPACT编译模式,与定义变量时指定pdata存储器类型具有相同的效果。
③LARGE:所有变量被定义在片外XRAM中(最大可达64KB),通常使用数据指针(DPTR)来间接访问变量(MOVX @DPTR)。这种编译模式对数据访问的效率最低,而且将增加程序的代码长度。采用LARGE编译模式与定义变量时指定xdata存储器类型具有相同的效果。
3)数据类型bit、sbit、sfr、sfr16:
Keil C51编译器支持标准C语言的数据类型,另外还根据8051单片机的特点扩展了数据类型,如bit、sbit、sfr、sfr16。
①bit:所有bit类型的变量都被定位在8051片内RAM的可位寻址区。由于8051单片机的可位寻址区只有16个字节长,所以在某个范围内最多只能声明128个bit类型变量。声明bit类型变量时,可以带有存储器类型data、idata或bdata。对于bit类型变量有如下限制:如果在函数中采用预处理命令“#pragma disable”禁止了中断,或者在函数声明时采用关键字“using n”明确进行了寄存器组切换,则该函数不能返回bit类型的值,否则C51在进行编译时会产生编译错误;另外,不能定义bit类型指针,也不能定义bit类型数组。
②sbit:sbit用于定义可独立寻址访问的位变量。C51编译器提供了一个存储器类型bdata,带有bdata存储器类型的变量被定为在8051单片机片内RAM的可位寻址区。带有bdata存储器类型的变量可以进行字节寻址,也可以进行位寻址,因此对bdata变量可用sbit指定其中任一位为可位寻址变量。需要注意,采用bdata及sbit所定义的变量都必须是全局变量,并且采用sbit定义可位寻址变量时要求基址对象的存储器类型为bdata。
例如,可先定义变量的数据类型和存储器类型:
int bdata ibase; //定义ibase为bdata整型变量
char bdata bary[4]; //定义bary[4]为bdata字符型数组
然后使用sbit定义可位寻址变量:
sbit mybit0= ibase^0; //定义mybit0为ibase的第0位
sbit mybit15= ibase^15; //定义mybit15为ibase的第15位
sbit Ary07= bary[0]^7; //定义Ary07为 bary[0]的第7位
sbit Ary37= bary[3]^7; //定义Ary37为 bary[3]的第7位
操作符“^”后面的数值范围取决于基址变量的数据类型,对于char型是0~7,对于int型是0~15,对于long型是0~31。bdata变量ibase和bdata数组bary[4]可以进行字或字节寻址,sbit变量可以直接操作可寻址位。例如:
ibase=-1; //字寻址,对ibase赋值为-1
bary[3]=’a’; //字节寻址,对bary[3]赋值为’a’
Ary37=0; //清0 bary[3]的第7位
mybit15=1; //置1 ibase的第15位
对bdata变量可以向对data变量一样处理,所不同的是,bdata变量必须位于8051单片机的片内RAM的可位寻址区,其长度不能超过16个字节。
sbit还可以用于定义结构与联合,利用这一特点可以实现对float型数据指定bit变量。例如:
union lft {
float mf;
long ml;
};
bdata struct bad {
char mc;
union lft u;
}tcp;
sbir tcpf31=tcp.u.ml^31; //float数据的第31位
sbir tcpm10=tcp.mc^0;
sbir tcpm17=tcp.mc^7;
采用sbit类型时,需要指定一个变量作为基地址,再通过指定该基地址变量的bit位来获得实际的物理bit地址。并不是所有类型变量的物理bit地址都与其逻辑bit地址相一致。物理上的bit0对应第一个字节的bit0,物理上的bit8对应第二个字节的bit0.对于int类型的数据,由于它是按高字节在前的方式存储的,int类型数据的bit0应位于第二个字节的bit0,因此采用sbit指定int类型数据bit0时应使用物理上的bit8。
③sfr:8051单片机片内RAM中与idata空间相重叠的高128字节(地址范围为80~FFH)称为特殊功能寄存器SFR区。单片机对片内集成的定时器、串行口、I/O等操作都是通过SFR来实现的。为了能够直接访问8051系列单片机内部的SFR,C51编译器扩充了关键字sfr和sfr16,利用这种扩充关键字可以在C51源程序中直接定义8051单片机的SFR,定义方法如下:
sfr 特殊功能寄存器名=地址常数;
例如:
sfr P0=0x80; //定义P0寄存器地址为0x80
sfr SCON=0x90; //定义串行口控制寄存器地址为0x90
需要注意,关键字sfr后面必须跟一个标识符作为特殊功能寄存器名,名字可任意选取,但应符合一般习惯。等号后面必须是常数,不允许有带运算符的表达式。传统8051单片机地址常数的范围是0x80~0xff。
④sfr16:在一些新型8051单片机中,特殊功能寄存器经常组合成16位来使用,采用关键字sfr16可以定义这种16位的SFR。例如,8052单片机的定时器T2,可定义为:
sfr16 T2=0xCC; //定义TIMER2地址为T2L=0xCC,T2H=0xCD
这里的T2为SFR名,等号后面使它的低字节地址,其高字节地址必须在物理上直接位于低字节之后。
4)SFR特定位的定义:
在8051单片机应用系统中经常需要访问特殊功能寄存器SFR中的一些特定位,可以利用C51编译器提供的扩充关键字sbit来定义特殊功能寄存器SFR中的可位寻址对象,定义方法有如下三种:
①sbit 位变量名=位地址;
这种方法将位的绝对地址赋给位变量,位地址位于0x80~0xFF之间。例如:
sbit OV= 0xD2; //定义溢出标志位地址
sbit CY= 0xD7; //定义进位标志位地址
②sbit 位变量名=特殊功能寄存器名^位;
当可寻址位位于特殊功能寄存器SFR中时可采用这种方法,位是一个0~7之间的常数。例如:
sfr PSW=0xD0; //定义PSW寄存器地址为0xD0
sbit OV= PSW^2; //定义溢出标志位
sbit CY= PSW^7; //定义进位标志位
③sbit 位变量名=字节地址^位;
这种方法以一个常数(字节地址)作为基地址,该常数必须在0x80~0xFF之间。位是一个0~7之间的常数。例如:
sbit OV= 0xD0^2; //定义溢出标志位地址
sbit CY= 0xD0^7; //定义进位标志位地址
需要注意,用sbit定义的特殊功能寄存器中的可寻址位是一个独立的定义类(class),不能与其他位定义和位域互换。
5)一般指针与基于存储器的指针及其转换:
Keil C51编译器支持两种指针类型,即一般指针和基于存储器的指针。一般指针需要占用3个字节,基于存储器的指针只需要占用1~2个字节。一般指针具有较好的兼容性,但运行速度缓慢,基于存储器的指针是C51编译器专门针对8051单片机存储器的特点进行的扩展,只适用于8051单片机,但具有较高的运行速度。
①一般指针:
定义一般指针的方法与ANSI C相同,例如:
char * sptr; //定义char型指针
int * numptr; //定义int型指针
一般指针在内存中占用3字节,第一字节存放该指针的存储器类型编码(由编译模式确定),第二和第三字节分别存放该指针的高位和低位地址偏移量。一般指针的存储器类型编码见表:
|
存储器类型 |
idata/data/bdata |
xdata |
pdata |
code |
|
编码值 |
0x00 |
0x01 |
0xFE |
0xFF |
一般指针可用于存取任何变量,而不用考虑变量在8051单片机存储器空间的位置,许多C51库函数都采用一般指针。函数可以利用一般指针来存取位于任何存储器空间的数据。
定义一般指针时,可以在“*”后带一个存储器类型选项,用于指定一般指针本身的存储器空间位置。例如:
char * xdata sptr; //定义位于xdata空间的一般指针,char型数据
int * data numptr; //定义位于data空间的一般指针,int型数据
long * idata varptr; //定义位于idata空间的一般指针,long型数据
由于一般指针所指对象的存储器空间位置,只有在运行期间才能确定,编译器在编译期间无法优化存储方式,必须生成一般代码以保证能对任意空间的对象进行存取,因此一般指针所产生的代码运行速度较慢。
②基于存储器的指针:
基于存储器的指针具有明确的存储器空间,长度可为1字节(存储器类型为idata、data、pdata)或2字节(存储器类型为code、xdata)。定义指针时,如果在“*”前面增加一个存储器类型选项,该指针就被定义为基于存储器的指针。例如:
char data * str; //定义指向data空间char型数据的指针
int xdata * num; //定义指向xdata空间int型数据的指针
long code * pow; //定义指向code空间long型数据的指针
与一般指针类型类似,定义基于存储器的指针时还可以指定指针本身的存储器空间位置,即在“*”后面带一个存储器类型选项。例如:
char data * xdata str; //定义指向data空间char型数据的指针,指针在xdata空间
int xdata * data num; //定义指向xdata空间int型数据的指针,指针在data空间
long code * idata pow; //定义指向code空间long型数据的指针,指针在idata空间
基于存储器的指针长度比一般指针短,可以节省存储器空间,运行速度快,但它所指对象具有确定的存储器空间,缺乏兼容性。
③一般指针与基于存储器的指针之间的转换:
一般指针与基于存储器的指针可以相互转换。在某些函数调用中进行参数传递时需要采用一般指针,例如C51的库函数printf()、sprintf()、gets()等便是如此。当传递的参数是基于存储器的指针时,若不特别指明,C51编译器会自动将其转换为一般指针。
需要注意,如果采用基于存储器的指针作为自定义函数的参数,而程序中又没有给出该函数原型,则基于存储器的指针就自动转换为一般指针,有时会导致错误发生。为了避免这类错误,应该在程序的开始处用预处理命令“#include”将函数原型说明文件包含进来,或者直接给出函数原型声明。
6)C51编译器对ANSI C函数定义的扩展:
C51编译器提供了几种对于ANSI C函数定义的扩展,可用于选择函数的编译模式、规定函数所使用的工作寄存器组、定义中断服务函数、指定再入方式等。
C51程序中进行函数定义的一般格式如下:
函数类型 函数名(形式参数表) [编译模式] [reentrant] [interrupt n] [using n]
{
局部变量定义
函数体语句
}
其中,函数类型说明了自定义函数返回值的类型,函数名是用标识符表示的自定义函数名字,形式参数表中列出了在主调用函数与被调用函数之间传递数据的形式参数,形式参数的类型必须加以说明。
编译模式选项是C51对ANSI C的扩展,可以是SMALL、COMPACT或LARGE,用于指定函数中局部变量和参数的存储器空间;reentrant选项是C51对ANSI C的扩展,用于定义再入函数;interrupt n选项是C51对ANSI C的扩展,用于定义中断服务函数,n为中断号,可为0~31;using n选项是C51对ANSI C的扩展,用于确定中断服务程序所使用的工作寄存器组,n可以是0~3。
①堆栈及函数的参数传递:
函数在运行过程中需要使用堆栈,8051单片机的堆栈必须位于片内RAM空间,其最大范围只有256B。(对于一些新型8051单片机,C51编译器可以使用扩展堆栈区,最大可达几千字节)。为了节省堆栈空间,C51 编译器采用一个固定的存储器区域来进行函数参数的传递。发生函数调用时,主调函数先将实际参数复制到该固定的存储器区域,然后再将程序流程控制交给被调函数,被调函数则从该固定的存储器区域取得所需要的参数进行操作。这样,就需要将函数的返回地址保存到堆栈区。由于中断服务函数可能要进行工作寄存器组切换,因此需要采用较多的堆栈空间。
C51编译器可以采用控制命令“REGPARMS”和“NOREGPARMS”来决定是否通过工作寄存器传递函数参数。默认状态下,C51编译器通过工作寄存器最多传递3个函数参数,这种方式可以提高程序执行效率。如果没有寄存器可用,则通过固定的存储器区域来传递函数的参数。
②函数的编译模式:
不同类项的8051单片机片内RAM空间大小不同,有些衍生产品只有64个字节的片内RAM,因此在定义函数时要根据具体情况来决定应采用的编译模式。函数参数和局部变量都存放在由编译模式决定的默认存储器空间中,可以根据需要对不同函数采用不同的编译模式。在SMALL编译模式下,函数参数和局部变量被存放在8051的片内RAM空间,这种方式对数据的处理效率最高。但片内RAM空间有限,对于较大的程序若采用SMALL编译模式可能不能满足要求,这时就需要采用其他编译模式。下面的函数分别采用了不同的编译模式:
#pragma small //默认编译模式为small
extern int calc(char i, int b) large reentrant; //采用LARGE编译模式
extern int func(int i, float f) large; //采用LARGE编译模式
extern void *tcp(char xdata *xp, int ndx) small; //采用SMALL编译模式
int mtest(int i, int y) {
return(i*y+y*i+func(-1, 4.75)); //采用默认编译模式
}
int large_func(int i, int k) { large
return(mtest(i, k)+2); //采用LARGE编译模式
}
③寄存器组切换:
8051单片机片内RAM中最低32个字节平均分为4组,每组8个字节都命名为R0~R7,统称为工作寄存器组。利用扩展关键字“using”可以在定义函数时规定所使用的工作寄存器组,只要在后面跟一个数字0~3,即可规定所使用的工作寄存器组。
需要注意,关键字using不能用在以寄存器返回一个值的函数中,并且要保证任何寄存器组的切换都只在仔细控制的区域内发生,否则将产生不正确的结果。带using属性的函数原则上不能返回bit类型的值。
8051单片机复位时PSW的值为0x00,因此在默认状态下所有非中断函数都将使用工作寄存器0区。C51编译器可以通过控制命令“REGISTERBAN”为源程序中的所有函数指定一个默认的工作寄存器组,为此用户需要修改启动代码选择不同的寄存器组,然后采用控制命令“REGISTERBAN”来指定新的工作寄存器组。
在默认状态下,C51编译器生成的代码将使用绝对寻址方式来访问工作寄存器R0~R7,从而提高操作性能。绝对寄存器寻址方式可以通过编译控制命令“AREGS”或“NOAREGS”来激活或禁止。采用了绝对寄存器的函数不能被另一个使用了不同工作寄存器组的函数所调用,否则会导致不可预知的结果。为了使函数对当前工作寄存器组不敏感,该函数必须采用控制命令“NOAREGS”进行编译。
需要注意,C51编译器对函数之间使用的工作寄存器组是否匹配不做检查,因此使用了交替寄存器组的函数只能调用没有设定默认寄存器组的函数。
④中断函数:
利用控制关键字“interrupt”可以直接在C51程序中定义中断服务函数。在“interrupt”后跟一个0~31的数字,用于规定中断源和中断入口。关键字“interrupt”对中断函数目标代码的影响如下:
·在进入中断函数时,特殊功能寄存器ACC、B、DPH、DPL、PSW将被保存入栈
·如果不使用关键字using进行工作寄存器切换,则将中断函数中所有用到的工作寄存器入栈
·函数退出之前所有的寄存器内容出栈恢复
·中断函数由8051单片机指令RETI结束
·C51编译器根据中断号自动生成中断函数入口向量地址
⑤再入函数:
利用C51编译器的扩展控制字“reentrant”可以定义一个再入函数。再入函数可以进行递归调用,或者同时被两个以上的其他函数同时调用。通常,在实时系统应用中或在中断函数与非中断函数需要共享一个函数时,应将该函数定义为再入函数。
再入函数可被递归调用,无论何时,包括中断服务函数在内的任何函数都可调用再入函数。与非再入函数的参数传递和局部变量的存储分配方法不同,C51编译器为再入函数生成一个模拟栈,通过这个模拟栈来完成参数传递和存放局部变量。根据再入函数所采用的编译模式,模拟栈可以位于片内或片外存储器空间,SMALL模式下的再入栈位于data空间,COMPACT模式下的再入栈位于pdata空间,LARGE模式下的再入栈位于xdata空间。当程序中包含有多种存储器模式的再入函数时,C51编译器为每种模式单独建立一个模拟栈并独立管理各自的栈指针。再入函数的局部变量及参数都被放在再入栈中,从而使再入函数可以进行递归调用。而非再入函数的局部变量被放在再入栈之外的暂存区内,如果对非再入函数进行递归调用,则上次调用时使用的局部变量数据将被覆盖。
Keil C51编译器对于再入函数有如下规定:
·再入函数不能彻底传递bit类型的参数,也不能定义局部位变量。再入函数不能操作可位寻址变量。
·与PL/M51兼容的alien函数不能具有reentrant属性,也不能调用再入函数。
·再入函数可以同时具有其他属性,如interrupt、using等,还可以声明存储器模式SMALL、COMPACT、LARGE。
·在同一个程序中可以定义和使用不同存储器模式的再入函数,每个再入函数都必须具有合适的函数原型,原型中还应包含该函数的存储器模式。
·如果函数的返回地址保存在8051单片机的硬件堆栈内,任意其他的PUSH和POP指令都会影响8051硬件堆栈。
·不同存储器模式下的再入函数具有其自己的模拟再入栈以及再入栈指针。例如,若在同一模块内定义了SMALL和LARGE模式的再入函数,则C51编译器会同时生成对应的两种再入栈及其再入栈指针。
8051单片机的常规栈总是位于内部数据RAM中,而且是“向上生长”型的,而模拟再入栈是“向下生长”型的。如果编译时采用SMALL模式,常规栈和再入函数的模拟栈将被放在内部RAM中,从而使有限的内部数据存储器得到充分利用。模拟再入栈及其再入栈指针可以通过配置文件“STARTUP.A51”进行调整。使用再入函数时,应根据需要对该配置文件进行适当修改。
5. C51编译器的数据调用协议:
1)bit类型的数据:只有一位长度,不允许定义位指针和位数组。Bit对象始终位于8051单片机内部可位寻址的数据存储器空间(20H~2FH),只要有可能,BL51连接定位器将对位对象进行覆盖操作。
2)char类型的数据:长度为一个字节(8位),可存放于8051单片机内部或外部数据存储器中。
3)int和short类型的数据:长度为两个字节(16位),可存放于8051单片机内部或外部数据存储器中。数据在内存中按高字节地址在前、低字节地址在后的顺序存放。例如,int类型数据0x1234,在内存中的存储格式如下:
|
地址 |
+0 |
+1 |
|
内容 |
0x12 |
0x34 |
4)long类型的数据:长度为4个字节(32位),可存放于8051单片机内部或外部数据存储器中。数据在内存中按高字节地址在前、低字节地址在后的顺序存放。例如,long类型数据0x12345678,在内存中的存储格式如下:
|
地址 |
+0 |
+1 |
+2 |
+3 |
|
内容 |
0x12 |
0x34 |
0x56 |
0x78 |
5)float类型的数据:长度为4个字节(32位),存放于8051单片机内部或外部数据存储器中。一个float类型数据的数值范围是:
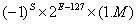
在内存中按IEEE-754标准单精度32位浮点数的格式存储:
|
地址 |
+0 |
+1 |
+2 |
+3 |
|
内容 |
SEEEEEEE |
EMMMMMMM |
MMMMMMMM |
MMMMMMMM |
其中,S为符号位,0表示正,1表示负。E为用原码表示的阶码,占用8位二进制数,存放在两个字节中,E的取值范围是1~254。(实际上,以2为底的指数要用E的值减去偏移量127,从而实际幂指数的取值范围为-126~+127)。M为尾数的小数部分,用23位二进制表示,存放在3个字节中。尾数的整数部分永远为1,因此不予保存,但是隐含存在的。小数点位于隐含的整数位1的后面。
例如,一个值为-12.5的float类型数据,在内存中的存储格式如下:
|
地址 |
+0 |
+1 |
+2 |
+3 |
|
二进制内容 |
11000001 |
01001000 |
00000000 |
00000000 |
|
十六进制内容 |
0xC1 |
0x48 |
0x00 |
0x00 |
如果阶码E为全1(即255),小数部分M为全0,则根据符号位,分别表示正负无穷大:
正无穷:+INF=7F800000H 负无穷:-INF=FF800000H
阶码E为全0,小数部分M也全0的浮点数,认为是0。绝对值最小的正常浮点数为阶码E为1,小数部分M为全0的数:
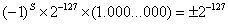
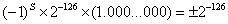
除了正常浮点数,在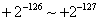 以及
以及 之间的数为非正常数。按IEEE754标准,浮点数的数值如果在正常数值之外,即为溢出错误,二进制表示为:
之间的数为非正常数。按IEEE754标准,浮点数的数值如果在正常数值之外,即为溢出错误,二进制表示为:
非正常数: NaN=0FFFFFFFFH
6)指针:C51编译器支持一般指针和基于存储器的指针。基于存储器类型data、idata和pdata的指针具有1个字节的长度,基于存储器类型xdata和code的指针具有两字节的长度,一般指针具有3字节的长度。
在一般指针的3个字节中,第一个字节表示存储器类型,第二、第三字节表示指针的地址偏移量。一般指针在内存中的存储格式如下:
|
地址 |
+0 |
+1 |
+2 |
|
内容 |
存储器类型 |
高字节地址偏移量 |
低字节地址偏移量 |
在第一个字节中,存储器类型的编码如下:
|
存储器类型 |
idata/data/bdata |
xdata |
pdata |
code |
|
编码值(8051) |
0x00 |
0x01 |
0xFE |
0xFF |
|
编码值(8051Mx) |
0x7F |
0x00 |
0x00 |
0x80 |
采用一般指针时,必须使用规定的存储器类型编码值。如果使用其他类型的值,将导致不可预测的后果。
例如,将xdata类型的地址0x1234作为一般指针表示如下:
|
地址 |
+0 |
+1 |
+2 |
|
内容 |
0x01 |
0x12 |
0x34 |
6. 绝对地址访问:
在进行8051 单片机应用系统程序设计时,用户会关心如何直接操作各个存储器的地址空间。C51程序经过编译后,产生的目标代码具有浮动地址,其绝对地址必须经过BL51连接定位后才能确定。为了能够在C51程序中直接对任意指定的存储器地址进行操作,可以采用扩展关键字“_at_”、指针、预定义宏以及连接定位控制命令。
1)采用扩展关键字“_at_”或指针定义变量的绝对地址:
在C51源程序中定义变量时,可以利用C51编译器提供的扩展关键字“_at_”来指定变量的存储器空间绝对地址。一般格式如下:
[存储器类型] 数据类型 标识符 _at_ 地址常数
其中,存储器类型为idata、data、xdata等C51编译器能够识别的所有类型,如果省略该选项,则按编译模式SMALL、COMPACT和LARGE规定的默认存储器类型确定变量的存储器空间;数据类型除了可用int、long、float等基本类型外,还可以采用数组、结构等复杂数据类型;标识符为要定义的变量名;地址常数规定了变量的绝对地址,它必须位于有效存储器空间之内。下面是采用关键字“_at_”进行变量的绝对地址定位的示例:
struct link {
struct link idata * next;
char code * test;
};
idata struct link list _at_ 0x40; //结构变量list定位于idata空间地址0x40
xdata char text[256] _at_ 0xE000; //数组array定位于xdata空间地址0xE000
xdata int il _at_ 0x8000; //int变量il定位于xdata空间地址0x8000
利用扩展关键字“_at_”定义的变量称为绝对变量,对该变量的操作就是对指定存储器空间绝对地址的直接操作,因此不能对绝对变量进行初始化。对于函数和位bit类型变量不能采用这种方法进行绝对地址定位。采用关键字“_at_”所定义的绝对变量必须是全局变量,在函数内部不能采用“_at_”关键字指定局部变量的绝对地址。另外,在XDATA空间定义全局变量的绝对地址时,还可以在变量前面加一个关键字“volatile”,这样对该变量的访问就不会被C51编译器优化掉。
利用基于存储器的指针也可以指定变量的存储器绝对地址,其方法是先定义一个基于存储器的指针变量,然后对该变量赋以存储器绝对地址。下面是一个利用基于存储器的指针进行变量的绝对地址定位的示例:
char xdata temp _at_ 0x4000; //定义全局变量temp,地址为XDATA空间0x4000
void main() {
char xdata *xdp; //定义一个指向XDATA存储器空间的指针
char data *dp; //定义一个指向DATA存储器空间的指针
xdp=0x2000; //XDATA指针赋值,指向XDATA存储器地址2000H
temp=*xdp; //读取XDATA空间地址0x2000的内容送往0x4000单元
*xdp=0xAA; //将数据0xAA送往XDATA空间0x2000地址单元
dp=0x30; //XDATA指针赋值,指向DATA存储器地址30H
*dp=0xBB; //将数据0xBB送往指定的DATA空间地址
2)采用预定义宏指定变量的绝对地址:
C51编译器的运行库中提供了如下一套预定义宏:
CBYTE CWORD FARRAY
DBYTE DWORD FCARRAY
PBYTE PWORD FCVAR
XBYTE XWORD FVAR
这些宏定义包含在头文件“ABSACC.H”中。在C51源程序中可以利用这些宏来指定变量的绝对地址。例如:
#include <ABSACC.H>
char c_var;
int i_var;
XBYTE[0X12]=c_var; //向XDATA存储器地址0012H写入数据C_var
i_var=XWORD[0x100]; //从XDATA存储器地址0100H中读取数据并赋值给i_var
上面语句中的XWORD[0x100]是对地址“2*0x100”进行操作,将字节地址0x100和0x101的内容取出来并赋值给int型变量i_var。
用户可以充分利用C51运行库中提供的预定义宏来进行绝对地址的直接操作。例如,可以采用如下方法定义一个D/A转换接口地址,每向该地址写入一个数据,即可完成一次D/A转换。
#include <ABSACC.H>
#define DAC0832 XBYTE[0x7FFF] //定义DAC0832端口地址
DAC0832=0x80; //启动一次D/A转换
Keil C51程序设计相关推荐
- keil c语言 延迟程序,Keil C51程序设计中几种精确延时方法
前几天时间在做一个基于51单片机开发板的等精度频率计,用LCD1602液晶显示的,晶振是22.1184MHZ,用得是测频率法,目的是想做到能够测试0--900KHZ的信号. 液晶显示部分花了我好几天才 ...
- keil延时c语言程序设计,Keil C51程序设计中几种精确延时方法
引言 单片机因具有体积小.功能强.成本低以及便于实现分布式控制而有非常广泛的应用领域[1].单片机开发者在编制各种应用程序时经常会遇到实现精确延时的问题,比如按键去抖.数据传输等操作都要在程序中插入一 ...
- Keil C51教程
第三课 C51数据类型 作者: 来源:本站原创 点击数: <script src="http://www.51hei.com/Article/GetHits.asp?ID= ...
- 根据c51程序改写汇编语言,Keil C51编译及连接技术
主要介绍Keil C51的预处理方法如宏定义.常用的预处理指令及文件包含指令,C51编译库的选择及代码优化原理,C51与汇编混合编程的方法与实现以及超过64KB空间的地址分页方法的C51实现. 教学目 ...
- Keil C51编译/链接/优化
Keil C51编译/链接/优化 一.C51编译库及代码优化技术 如下图所示:可以根据优化等级的需要选择相应的库文件. 通过Keil ->Target 下 Memory Model / code ...
- 配置Keil C51配置开发 STC51单片机过程
内容 1. Keil C51 下载 2. 配置开发STC51单片机 配置 Keil IDE与TEASOFT编辑 1. 配置Keil编辑器 2. 设置Keil自动开打文件 参考博文 1. Keil C5 ...
- 如何让Keil MDK兼容Keil C51?
原来用51单片机,使用的是Keil C51 uVision V4.02:最近搞STM32,装了keilMDK uVision V4.23. 原来我是先装keilC51,后装keilMDK的,装在不同的 ...
- keil c51的内部RAM(idata)动态内存管理程序(转)
源:keil c51的内部RAM(idata)动态内存管理程序 程序比较简单,但感觉比较有意思,个人认为有一定应用价值,希望大家有更好的思路和方法,互相促进. 程序的基本思路是:在CPU堆栈指针SP以 ...
- 【Keil C51】使用 watch1 来查看变量的值
在使用Keil C51,进行软件调试时,对变量观察的办法如下: 在变量处单击右键,选择添加至watch1窗口,即可看到R6变量在代码调试运行时,具体的数值变化.
最新文章
- find name 模糊匹配_Linux的文件搜索命令(locate ,find,grep,find命令和)
- 如何自定义Tableau 调色板
- boost::hana::less_equal用法的测试程序
- Run service in specified proxyPort via jettyrun
- FastJson 中 jsonArray 转换成 list 集合的方法
- 《Netkiller Spring Cloud 手札》Spring boot 2.0 mongoTemplate 操作范例
- java leader 选举_简述ZK的fastleaderelection选举leader的算法
- Mifare l卡特性简介
- [转载]安全设置 IIS 中的权限
- 在RHEL5下构建LAMP网站服务平台之MySQL、PHP的安装与配置
- c语言开发环境win10,老司机解决win10系统搭建C语言开发环境的操作技巧
- 1338: 不及格率
- 【冷冻电镜入门】加州理工公开课课程笔记 Part 3: Image Formation
- 'javac'不是内部或外部命令,也不是可运行的程序或批处理文件.
- 微信小程序中显示HTML格式内容的实例
- 渗透测试实战指南笔记
- BFC是什么?BFC可以做什么?
- 知识变现海哥|知识变现需要使用哪些工具
- Relax中的量化管理
- Windows系统部分软件显示乱码