使用BeautifulSoup的Python Web爬网教程
When performing data science tasks, it’s common to want to use data found on the internet. You’ll usually be able to access this data in csv format, or via an Application Programming Interface(API). However, there are times when the data you want can only be accessed as part of a web page. In cases like this, you’ll want to use a technique called web scraping to get the data from the web page into a format you can work with in your analysis.
执行数据科学任务时,通常要使用Internet上的数据。 通常,您将能够以csv格式或通过应用程序编程接口 (API)访问此数据。 但是,有时您所需的数据只能作为网页的一部分进行访问。 在这种情况下,您将需要使用一种称为“网络抓取”的技术,以将网页中的数据转换为可以在分析中使用的格式。
In this tutorial, we’ll show you how to perform web scraping using Python 3 and the BeautifulSoup library. We’ll be scraping weather forecasts from the National Weather Service, and then analyzing them using the Pandas library.
在本教程中,我们将向您展示如何使用Python 3和BeautifulSoup库执行网络抓取。 我们将从国家气象局 ( National Weather Service)抓取天气预报,然后使用熊猫库进行分析。
We’ll be scraping weather forecasts from the National Weather Service site.
我们将从国家气象局(National Weather Service)网站上抓取天气预报。
Before we get started, if you’re looking for more background on APIs or the csv format, you might want to check out our Dataquest courses on APIs or data analysis.
在开始使用之前,如果您希望了解有关API或csv格式的更多背景知识,则可能需要查看有关API或数据分析的 Dataquest课程。
网页的组成部分 (The components of a web page)
When we visit a web page, our web browser makes a request to a web server. This request is called a GET request, since we’re getting files from the server. The server then sends back files that tell our browser how to render the page for us. The files fall into a few main types:
当我们访问网页时,我们的网络浏览器会向网络服务器发出请求。 该请求称为GET请求,因为我们正在从服务器获取文件。 然后,服务器发回文件,这些文件告诉我们的浏览器如何为我们呈现页面。 文件分为几种主要类型:
- HTML – contain the main content of the page.
- CSS – add styling to make the page look nicer.
- JS – Javascript files add interactivity to web pages.
- Images – image formats, such as JPG and PNG allow web pages to show pictures.
- HTML –包含页面的主要内容。
- CSS –添加样式以使页面看起来更好。
- JS – Javascript文件增加了与网页的交互性。
- 图片–图片格式(例如JPG和PNG)允许网页显示图片。
After our browser receives all the files, it renders the page and displays it to us. There’s a lot that happens behind the scenes to render a page nicely, but we don’t need to worry about most of it when we’re web scraping. When we perform web scraping, we’re interested in the main content of the web page, so we look at the HTML.
浏览器收到所有文件后,它将呈现页面并将其显示给我们。 要使页面漂亮地渲染,在幕后发生了很多事情,但是当我们进行网页抓取时,我们不需要担心其中的大多数问题。 进行网页抓取时,我们会对网页的主要内容感兴趣,因此我们看一下HTML。
HTML (HTML)
HyperText Markup Language(HTML) is a language that web pages are created in. HTML isn’t a programming language, like Python – instead, it’s a markup language that tells a browser how to layout content. HTML allows you to do similar things to what you do in a word processor like Microsoft Word – make text bold, create paragraphs, and so on. Because HTML isn’t a programming language, it isn’t nearly as complex as Python.
超文本标记语言 ( HyperText Markup Language ,HTML)是用于创建网页的语言。HTML不是像Python这样的编程语言,而是一种标记语言,它告诉浏览器如何布局内容。 HTML使您可以执行与Microsoft Word等字处理器中类似的操作–使文本加粗,创建段落等。 因为HTML不是一种编程语言,所以它几乎不像Python那样复杂。
Let’s take a quick tour through HTML so we know enough to scrape effectively. HTML consists of elements called tags. The most basic tag is the <html> tag. This tag tells the web browser that everything inside of it is HTML. We can make a simple HTML document just using this tag:
让我们快速浏览一下HTML,以便我们了解足够有效地进行抓取。 HTML由称为标签的元素组成。 最基本的标记是<html>标记。 此标记告诉Web浏览器,其中的所有内容都是HTML。 我们可以使用以下标记创建一个简单HTML文档:
<html>
<html>
</html>
</html>
We haven’t added any content to our page yet, so if we viewed our HTML document in a web browser, we wouldn’t see anything:
我们尚未在页面上添加任何内容,因此,如果我们在Web浏览器中查看HTML文档,则不会看到任何内容:
Right inside an html tag, we put two other tags, the head tag, and the body tag. The main content of the web page goes into the body tag. The head tag contains data about the title of the page, and other information that generally isn’t useful in web scraping:
在html标签内,我们放置了另外两个标签,即head标签和body标签。 网页的主要内容进入body标签。 head标记包含有关页面标题的数据,以及通常在网络抓取中无用的其他信息:
We still haven’t added any content to our page (that goes inside the body tag), so we again won’t see anything:
我们仍未在页面中添加任何内容(位于body标签内),因此我们再也看不到任何内容:
You may have noticed above that we put the head and body tags inside the html tag. In HTML, tags are nested, and can go inside other tags.
您可能在上面已经注意到,我们将head和body标签放在html标签内。 在HTML中,标签是嵌套的,可以放在其他标签内。
We’ll now add our first content to the page, in the form of the p tag. The p tag defines a paragraph, and any text inside the tag is shown as a separate paragraph:
现在,我们将以p标记的形式将第一个内容添加到页面。 p标签定义了一个段落,并且标签内的所有文本都显示为单独的段落:
<html><html><head><head></head></head><body><body><p>Here's a paragraph of text!<p>Here's a paragraph of text!</p></p><p>Here's a second paragraph of text!<p>Here's a second paragraph of text!</p></p></body>
</body>
</html>
</html>
Here’s how this will look:
外观如下:
Here’s a paragraph of text!
这是一段文字!
Here’s a second paragraph of text!
这是第二段文字!
Tags have commonly used names that depend on their position in relation to other tags:
标签的常用名称取决于它们相对于其他标签的位置:
child– a child is a tag inside another tag. So the twoptags above are both children of thebodytag.parent– a parent is the tag another tag is inside. Above, thehtmltag is the parent of thebodytag.sibiling– a sibiling is a tag that is nested inside the same parent as another tag. For example,headandbodyare siblings, since they’re both insidehtml. Bothptags are siblings, since they’re both insidebody.
child-子是另一个标签内的标签。 因此,上面的两个p标签都是body标签的子元素。parent-父是标签,另一个标签在其中。 上面的html标签是的父body标签。sibiling– sibiling是与另一个标签嵌套在同一父对象内的标签。 例如,head和body是同级,因为它们都在html。 两个p标签都是兄弟姐妹,因为它们都在body内部。
We can also add properties to HTML tags that change their behavior:
我们还可以向HTML标记添加属性以更改其行为:
Here’s how this will look:
外观如下:
In the above example, we added two a tags. a tags are links, and tell the browser to render a link to another web page. The href property of the tag determines where the link goes.
在上面的示例中,我们添加了两个a标签。 a标签是联系,并告诉浏览器呈现链接到其他网页。 标签的href属性确定链接的位置。
a and p are extremely common html tags. Here are a few others:
a和p是极为常见的html标签。 这里还有其他一些:
div– indicates a division, or area, of the page.b– bolds any text inside.i– italicizes any text inside.table– creates a table.form– creates an input form.
div–指示页面的划分或区域。b–加粗其中的任何文本。i-斜体里面的任何文字。table–创建一个表。form–创建输入表单。
For a full list of tags, look here.
有关标签的完整列表,请参见此处 。
Before we move into actual web scraping, let’s learn about the class and id properties. These special properties give HTML elements names, and make them easier to interact with when we’re scraping. One element can have multiple classes, and a class can be shared between elements. Each element can only have one id, and an id can only be used once on a page. Classes and ids are optional, and not all elements will have them.
在进行实际的Web抓取之前,让我们了解class和id属性。 这些特殊的属性为HTML元素命名,并使它们在我们抓取时更易于与之交互。 一个元素可以具有多个类,并且一个类可以在元素之间共享。 每个元素只能有一个ID,并且一个ID在页面上只能使用一次。 类和ID是可选的,并非所有元素都具有它们。
We can add classes and ids to our example:
我们可以在我们的示例中添加类和ID:
<html><html><head><head></head></head><body><body><p <p class=class= "bold-paragraph""bold-paragraph" >Here's a paragraph of text!>Here's a paragraph of text!<a <a href=href= "https://www.dataquest.io" "https://www.dataquest.io" id=id= "learn-link""learn-link" >Learn Data Science Online> Learn Data Science Online </a></a></p></p><p <p class=class= "bold-paragraph extra-large""bold-paragraph extra-large" >Here's a second paragraph of text!>Here's a second paragraph of text!<a <a href=href= "https://www.python.org" "https://www.python.org" class=class= "extra-large""extra-large" >Python> Python </a></a></p></p></body>
</body>
</html>
</html>
Here’s how this will look:
外观如下:
As you can see, adding classes and ids doesn’t change how the tags are rendered at all.
如您所见,添加类和id根本不会改变标记的呈现方式。
请求库 (The requests library)
The first thing we’ll need to do to scrape a web page is to download the page. We can download pages using the Python requests library. The requests library will make a GET request to a web server, which will download the HTML contents of a given web page for us. There are several different types of requests we can make using requests, of which GET is just one. If you want to learn more, check out our API tutorial.
我们要抓取网页的第一件事就是下载网页。 我们可以使用Python 请求库下载页面。 请求库将向Web服务器发出GET请求,该服务器将为我们下载给定网页HTML内容。 我们可以使用requests几种不同类型的请求,其中GET只是其中一种。 如果您想了解更多信息,请查看我们的API教程 。
Let’s try downloading a simple sample website, http://dataquestio.github.io/web-scraping-pages/simple.html. We’ll need to first download it using the requests.get method.
让我们尝试下载一个简单的示例网站http://dataquestio.github.io/web-scraping-pages/simple.html 。 我们需要先使用request.get方法下载它。
<Response [200]>
After running our request, we get a Response object. This object has a status_code property, which indicates if the page was downloaded successfully:
运行请求后,我们得到一个Response对象。 该对象具有status_code属性,该属性指示页面是否已成功下载:
pagepage .. status_code
status_code
A status_code of 200 means that the page downloaded successfully. We won’t fully dive into status codes here, but a status code starting with a 2 generally indicates success, and a code starting with a 4 or a 5 indicates an error.
status_code为200表示页面已成功下载。 这里我们不会完全探讨状态码,但是以2开头的状态码通常表示成功,而以4或5开头的代码表示错误。
We can print out the HTML content of the page using the content property:
我们可以使用content属性打印出页面HTML内容:
b'<!DOCTYPE html>n<html>n <head>n <title>A simple example page</title>n </head>n <body>n <p>Here is some simple content for this page.</p>n </body>n</html>'
使用BeautifulSoup解析页面 (Parsing a page with BeautifulSoup)
As you can see above, we now have downloaded an HTML document.
如您在上面看到的,我们现在已经下载了一个HTML文档。
We can use the BeautifulSoup library to parse this document, and extract the text from the p tag. We first have to import the library, and create an instance of the BeautifulSoup class to parse our document:
我们可以使用BeautifulSoup库来解析此文档,并从p标签中提取文本。 我们首先必须导入库,并创建BeautifulSoup类的实例来解析我们的文档:
from from bs4 bs4 import import BeautifulSoup
BeautifulSoup
soup soup = = BeautifulSoupBeautifulSoup (( pagepage .. contentcontent , , 'html.parser''html.parser' )
)
We can now print out the HTML content of the page, formatted nicely, using the prettify method on the BeautifulSoup object:
现在,我们可以使用BeautifulSoup对象上的prettify方法打印出格式正确HTML页面内容:
<!DOCTYPE html>
<html><head><title>A simple example page</title></head><body><p>Here is some simple content for this page.</p></body>
</html>
As all the tags are nested, we can move through the structure one level at a time. We can first select all the elements at the top level of the page using the children property of soup. Note that children returns a list generator, so we need to call the list function on it:
由于所有标签都是嵌套的,因此我们可以一次在整个结构中移动一层。 我们首先可以使用soup的children属性选择页面顶部的所有元素。 请注意, children返回一个列表生成器,因此我们需要在其上调用list函数:
listlist (( soupsoup .. childrenchildren )
)
['html', 'n', <html><head><title>A simple example page</title></head><body><p>Here is some simple content for this page.</p></body></html>]
The above tells us that there are two tags at the top level of the page – the initial <!DOCTYPE html> tag, and the <html> tag. There is a newline character (n) in the list as well. Let’s see what the type of each element in the list is:
上面告诉我们,页面的顶层有两个标签-初始<!DOCTYPE html>标签和<html>标签。 列表中也有换行符( n )。 让我们看看列表中每个元素的类型是:
[bs4.element.Doctype, bs4.element.NavigableString, bs4.element.Tag]
As you can see, all of the items are BeautifulSoup objects. The first is a Doctype object, which contains information about the type of the document. The second is a NavigableString, which represents text found in the HTML document. The final item is a Tag object, which contains other nested tags. The most important object type, and the one we’ll deal with most often, is the Tag object.
如您所见,所有项目都是BeautifulSoup对象。 第一个是Doctype对象,其中包含有关文档类型的信息。 第二个是NavigableString ,它表示在HTML文档中找到的文本。 最后一项是Tag对象,其中包含其他嵌套标签。 Tag对象是最重要的对象类型,也是我们最常处理的对象类型。
The Tag object allows us to navigate through an HTML document, and extract other tags and text. You can learn more about the various BeautifulSoup objects here.
Tag对象使我们可以浏览HTML文档,并提取其他标签和文本。 您可以在此处了解有关各种BeautifulSoup对象的更多信息。
We can now select the html tag and its children by taking the third item in the list:
现在,我们可以通过选择列表中的第三项来选择html标签及其子元素:
html html = = listlist (( soupsoup .. childrenchildren )[)[ 22 ]
]
Each item in the list returned by the children property is also a BeautifulSoup object, so we can also call the children method on html.
children属性返回的列表中的每个项目也是BeautifulSoup对象,因此我们也可以在html上调用children方法。
Now, we can find the children inside the html tag:
现在,我们可以在html标记内找到子代:
['n', <head><title>A simple example page</title></head>, 'n', <body><p>Here is some simple content for this page.</p></body>, 'n']
As you can see above, there are two tags here, head, and body. We want to extract the text inside the p tag, so we’ll dive into the body:
如上所示,这里有两个标签head和body 。 我们想要提取p标签内的文本,因此我们将深入研究正文:
body body = = listlist (( htmlhtml .. childrenchildren )[)[ 33 ]
]
Now, we can get the p tag by finding the children of the body tag:
现在,我们可以通过找到body标签的子元素来获得p标签:
['n', <p>Here is some simple content for this page.</p>, 'n']
We can now isolate the p tag:
现在我们可以隔离p标签:
p p = = listlist (( bodybody .. childrenchildren )[)[ 11 ]
]
Once we’ve isolated the tag, we can use the get_text method to extract all of the text inside the tag:
隔离标签后,可以使用get_text方法提取标签内的所有文本:
'Here is some simple content for this page.'
一次查找标签的所有实例 (Finding all instances of a tag at once)
What we did above was useful for figuring out how to navigate a page, but it took a lot of commands to do something fairly simple. If we want to extract a single tag, we can instead use the find_all method, which will find all the instances of a tag on a page.
上面我们做的事情对于弄清楚如何导航页面很有用,但是花了很多命令才能完成相当简单的事情。 如果要提取单个标签,则可以改用find_all方法,该方法将在页面上查找标签的所有实例。
soup soup = = BeautifulSoupBeautifulSoup (( pagepage .. contentcontent , , 'html.parser''html.parser' )
)
soupsoup .. find_allfind_all (( 'p''p' )
)
[<p>Here is some simple content for this page.</p>]
Note that find_all returns a list, so we’ll have to loop through, or use list indexing, it to extract text:
请注意, find_all返回一个列表,因此我们必须遍历或使用列表索引来提取文本:
'Here is some simple content for this page.'
If you instead only want to find the first instance of a tag, you can use the find method, which will return a single BeautifulSoup object:
如果只想查找标签的第一个实例,则可以使用find方法,该方法将返回一个BeautifulSoup对象:
soupsoup .. findfind (( 'p''p' )
)
<p>Here is some simple content for this page.</p>
We introduced classes and ids earlier, but it probably wasn’t clear why they were useful. Classes and ids are used by CSS to determine which HTML elements to apply certain styles to. We can also use them when scraping to specify specific elements we want to scrape. To illustrate this principle, we’ll work with the following page:
我们之前介绍了类和id,但是可能不清楚它们为什么有用。 CSS使用类和ID来确定将某些样式应用于哪些HTML元素。 在抓取时,我们也可以使用它们来指定要抓取的特定元素。 为了说明这一原理,我们将使用以下页面:
We can access the above document at the URL http://dataquestio.github.io/web-scraping-pages/ids_and_classes.html. Let’s first download the page and create a BeautifulSoup object:
我们可以通过URL http://dataquestio.github.io/web-scraping-pages/ids_and_classes.html访问上述文档。 让我们首先下载页面并创建一个BeautifulSoup对象:
page page = = requestsrequests .. getget (( "http://dataquestio.github.io/web-scraping-pages/ids_and_classes.html""http://dataquestio.github.io/web-scraping-pages/ids_and_classes.html" )
)
soup soup = = BeautifulSoupBeautifulSoup (( pagepage .. contentcontent , , 'html.parser''html.parser' )
)
soup
soup
<html>
<head>
<title>A simple example page</title>
</head>
<body>
<div>
<p class="inner-text first-item" id="first">First paragraph.</p>
<p class="inner-text">Second paragraph.</p>
</div>
<p class="outer-text first-item" id="second">
<b>First outer paragraph.</b>
</p>
<p class="outer-text">
<b>Second outer paragraph.</b>
</p>
</body>
</html>
Now, we can use the find_all method to search for items by class or by id. In the below example, we’ll search for any p tag that has the class outer-text:
现在,我们可以使用find_all方法按类或ID搜索项目。 在下面的示例中,我们将搜索所有具有outer-text类的p标签:
[<p class="outer-text first-item" id="second"><b>First outer paragraph.</b></p>, <p class="outer-text"><b>Second outer paragraph.</b></p>]
In the below example, we’ll look for any tag that has the class outer-text:
在下面的示例中,我们将查找所有具有outer-text类的标签:
soupsoup .. find_allfind_all (( class_class_ == "outer-text""outer-text" )
)
[<p class="outer-text first-item" id="second"><b>First outer paragraph.</b></p>, <p class="outer-text"><b>Second outer paragraph.</b></p>]
We can also search for elements by id:
我们还可以通过id搜索元素:
[<p class="inner-text first-item" id="first">First paragraph.</p>]
使用CSS选择器 (Using CSS Selectors)
You can also search for items using CSS selectors. These selectors are how the CSS language allows developers to specify HTML tags to style. Here are some examples:
您也可以使用CSS选择器搜索项目。 这些选择器是CSS语言允许开发人员指定样式HTML标签的方式。 这里有些例子:
p a– finds allatags inside of aptag.body p a– finds allatags inside of aptag inside of abodytag.html body– finds allbodytags inside of anhtmltag.p.outer-text– finds allptags with a class ofouter-text.p#first– finds allptags with an id offirst.body p.outer-text– finds anyptags with a class ofouter-textinside of abodytag.
pa-找到所有a一个的标签内p标签。body pa-找到所有a一个的标签内p一的标签中body标记。html body–在html标签内查找所有body标签。p.outer-text–查找所有带有一类outer-textp标签。p#first–查找所有id为firstp标签。body p.outer-text–查找在body标签内部具有一类outer-text任何p标签。
You can learn more about CSS selectors here.
您可以在此处了解有关CSS选择器的更多信息。
BeautifulSoup objects support searching a page via CSS selectors using the select method. We can use CSS selectors to find all the p tags in our page that are inside of a div like this:
BeautifulSoup对象支持使用select方法通过CSS选择器搜索页面。 我们可以使用CSS选择器来查找页面中位于div内的所有p标签,如下所示:
soupsoup .. selectselect (( "div p""div p" )
)
[<p class="inner-text first-item" id="first">First paragraph.</p>, <p class="inner-text">Second paragraph.</p>]
Note that the select method above returns a list of BeautifulSoup objects, just like find and find_all.
请注意,上面的select方法将返回BeautifulSoup对象的列表,就像find和find_all 。
下载天气数据 (Downloading weather data)
We now know enough to proceed with extracting information about the local weather from the National Weather Service website. The first step is to find the page we want to scrape. We’ll extract weather information about downtown San Francisco from this page.
现在我们已经足够了解,可以从国家气象服务网站提取有关当地天气的信息。 第一步是找到我们要抓取的页面。 我们将从此页面提取有关旧金山市区的天气信息。

We’ll extract data about the extended forecast.
我们将提取有关扩展预测的数据。
As you can see from the image, the page has information about the extended forecast for the next week, including time of day, temperature, and a brief description of the conditions.
从图像中可以看到,该页面包含有关下周的扩展天气预报的信息,包括一天中的时间,温度和条件的简要说明。
使用Chrome DevTools探索页面结构 (Exploring page structure with Chrome DevTools)
The first thing we’ll need to do is inspect the page using Chrome Devtools. If you’re using another browser, Firefox and Safari have equivalents. It’s recommended to use Chrome though.
我们需要做的第一件事是使用Chrome Devtools检查页面。 如果您使用其他浏览器,则Firefox和Safari具有等效功能。 建议还是使用Chrome。
You can start the developer tools in Chrome by clicking View -> Developer -> Developer Tools. You should end up with a panel at the bottom of the browser like what you see below. Make sure the Elements panel is highlighted:
您可以通过单击View -> Developer -> Developer Tools人员工具在Chrome中启动开发View -> Developer -> Developer Tools 。 您应该最终在浏览器底部看到一个面板,如下所示。 确保“ Elements面板突出显示:
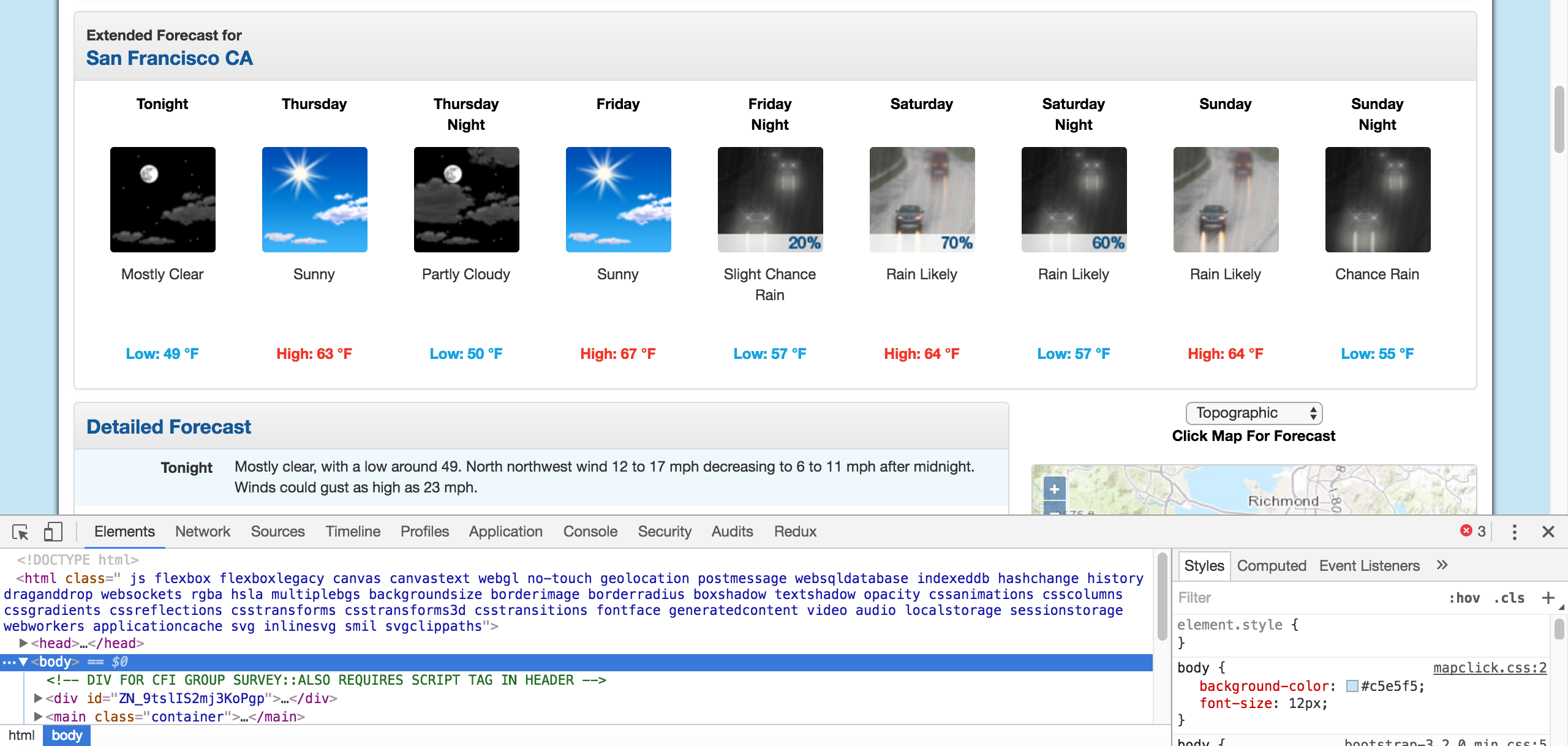
Chrome Developer Tools.
Chrome开发者工具。
The elements panel will show you all the HTML tags on the page, and let you navigate through them. It’s a really handy feature!
元素面板将在页面上显示所有HTML标记,并让您浏览它们。 这是一个非常方便的功能!
By right clicking on the page near where it says “Extended Forecast”, then clicking “Inspect”, we’ll open up the tag that contains the text “Extended Forecast” in the elements panel:
通过右键单击“扩展的预测”附近的页面,然后单击“检查”,我们将在元素面板中打开包含文本“扩展的预测”的标签:
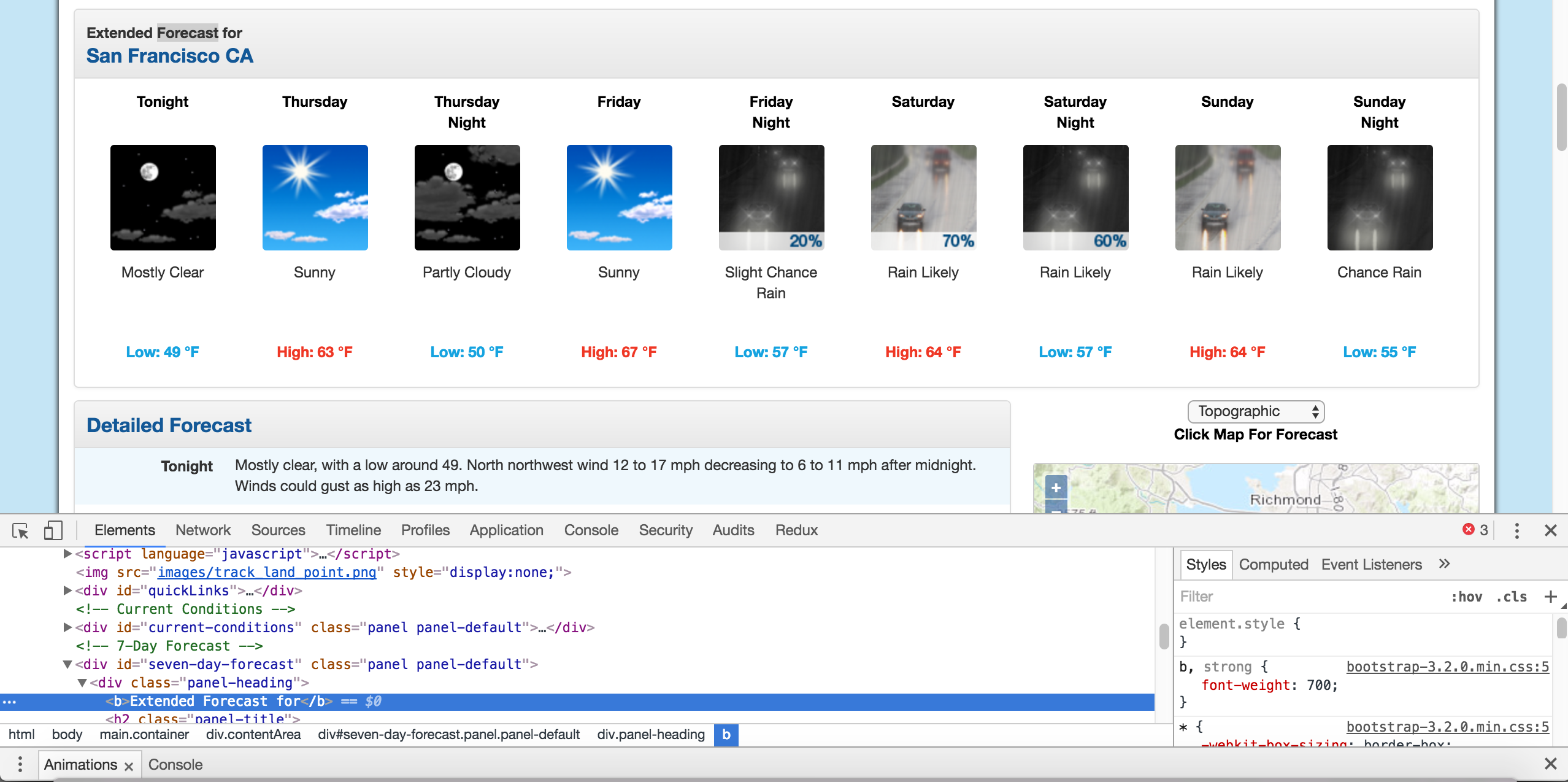
The extended forecast text.
扩展的预测文本。
We can then scroll up in the elements panel to find the “outermost” element that contains all of the text that corresponds to the extended forecasts. In this case, it’s a div tag with the id seven-day-forecast:
然后,我们可以在“元素”面板中向上滚动以找到“最外面的”元素,其中包含与扩展的预测相对应的所有文本。 在这种情况下,它是一个div标签,其ID为seven-day-forecast :
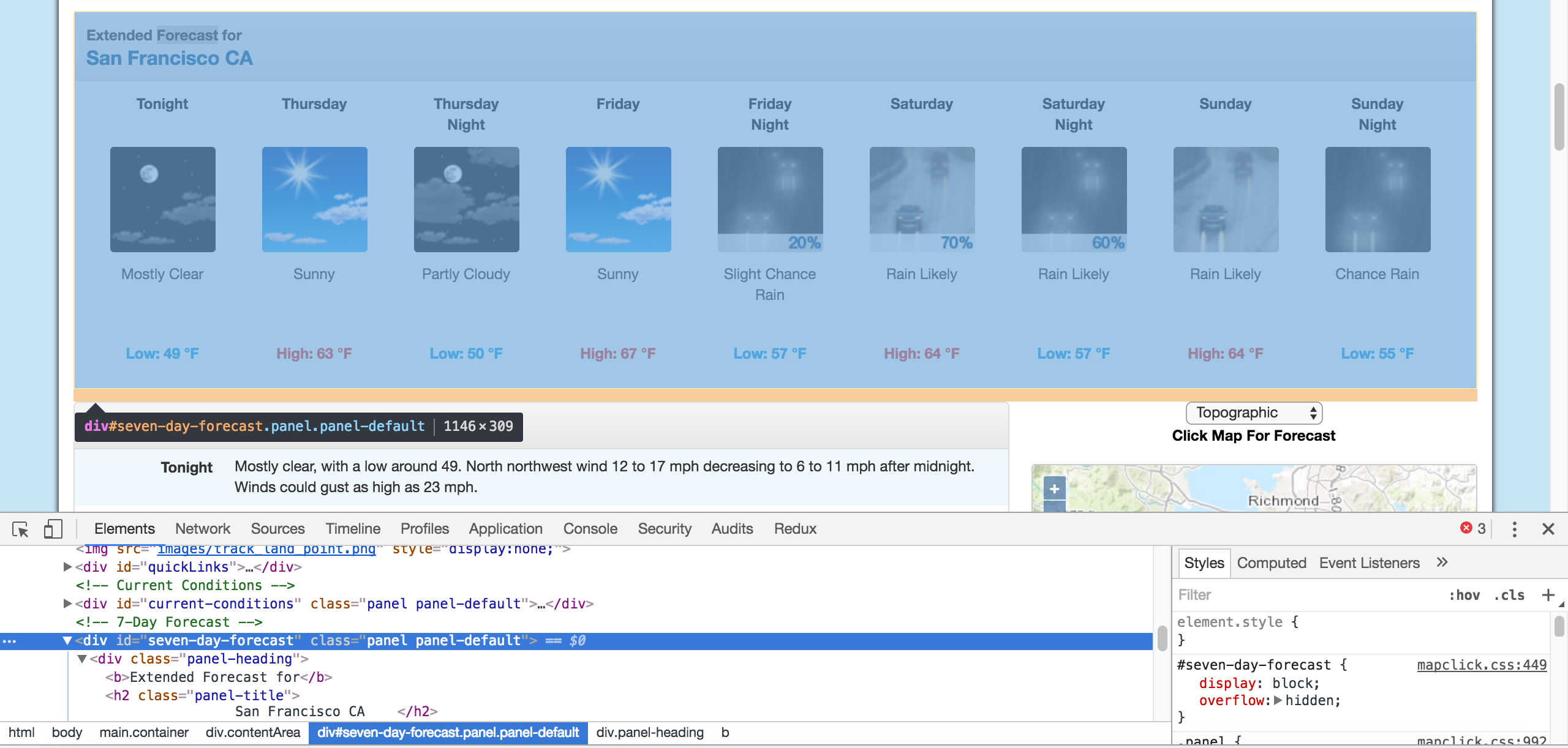
The div that contains the extended forecast items.
包含扩展预测项目的div。
If you click around on the console, and explore the div, you’ll discover that each forecast item (like “Tonight”, “Thursday”, and “Thursday Night”) is contained in a div with the class tombstone-container.
如果在控制台上单击鼠标并浏览div,您会发现每个预测项目(例如“ Tonight”,“ Thursday”和“ Thursday Night”)都包含在一个类为tombstone-container的div tombstone-container 。
We now know enough to download the page and start parsing it. In the below code, we:
现在我们知道足够的信息来下载页面并开始对其进行解析。 在下面的代码中,我们:
- Download the web page containing the forecast.
- Create a
BeautifulSoupclass to parse the page. - Find the
divwith idseven-day-forecast, and assign toseven_day - Inside
seven_day, find each individual forecast item. - Extract and print the first forecast item.
- 下载包含预测的网页。
- 创建
BeautifulSoup类以解析页面。 - 查找ID为
seven-day-forecastdiv并分配给seven_day - 在
seven_day,找到每个单独的预测项目。 - 提取并打印第一个预测项目。
<div class="tombstone-container"><p class="period-name">Tonight<br><br/></br></p><p><img alt="Tonight: Mostly clear, with a low around 49. West northwest wind 12 to 17 mph decreasing to 6 to 11 mph after midnight. Winds could gust as high as 23 mph. " class="forecast-icon" src="newimages/medium/nfew.png" title="Tonight: Mostly clear, with a low around 49. West northwest wind 12 to 17 mph decreasing to 6 to 11 mph after midnight. Winds could gust as high as 23 mph. "/></p><p class="short-desc">Mostly Clear</p><p class="temp temp-low">Low: 49 °F</p>
</div>
As you can see, inside the forecast item tonight is all the information we want. There are 4 pieces of information we can extract:
如您所见, tonight的预测项内是我们想要的所有信息。 我们可以提取4条信息:
- The name of the forecast item – in this case,
Tonight. - The description of the conditions – this is stored in the
titleproperty ofimg. - A short description of the conditions – in this case,
Mostly Clear. - The temperature low – in this case,
49degrees.
- 预测项目的名称–在本例中为
Tonight。 - 条件的描述–这存储在
img的title属性中。 - 条件的简短说明–在这种情况下,
Mostly Clear。 - 温度低–在这种情况下为
49度。
We’ll extract the name of the forecast item, the short description, and the temperature first, since they’re all similar:
我们将首先提取预测项的名称,简短描述和温度,因为它们都相似:
period period = = tonighttonight .. findfind (( class_class_ == "period-name""period-name" )) .. get_textget_text ()
()
short_desc short_desc = = tonighttonight .. findfind (( class_class_ == "short-desc""short-desc" )) .. get_textget_text ()
()
temp temp = = tonighttonight .. findfind (( class_class_ == "temp""temp" )) .. get_textget_text ()()printprint (( periodperiod )
)
printprint (( short_descshort_desc )
)
printprint (( temptemp )
)
Tonight
Mostly Clear
Low: 49 °F
Now, we can extract the title attribute from the img tag. To do this, we just treat the BeautifulSoup object like a dictionary, and pass in the attribute we want as a key:
现在,我们可以从img标签中提取title属性。 为此,我们只是将BeautifulSoup对象当作字典,然后将想要的属性作为键传递:
Tonight: Mostly clear, with a low around 49. West northwest wind 12 to 17 mph decreasing to 6 to 11 mph after midnight. Winds could gust as high as 23 mph.
Now that we know how to extract each individual piece of information, we can combine our knowledge with css selectors and list comprehensions to extract everything at once.
现在我们知道了如何提取每条信息,我们可以将我们的知识与CSS选择器和列表推导相结合,以一次提取所有信息。
In the below code, we:
在下面的代码中,我们:
- Select all items with the class
period-nameinside an item with the classtombstone-containerinseven_day. - Use a list comprehension to call the
get_textmethod on eachBeautifulSoupobject.
- 选择在
seven_day具有tombstone-container的项目中所有具有period-name类的项目。 - 使用列表
get_text对每个BeautifulSoup对象调用get_text方法。
period_tags period_tags = = seven_dayseven_day .. selectselect (( ".tombstone-container .period-name"".tombstone-container .period-name" )
)
periods periods = = [[ ptpt .. get_textget_text () () for for pt pt in in period_tagsperiod_tags ]
]
periods
periods
['Tonight','Thursday','ThursdayNight','Friday','FridayNight','Saturday','SaturdayNight','Sunday','SundayNight']
As you can see above, our technique gets us each of the period names, in order. We can apply the same technique to get the other 3 fields:
正如您在上面看到的,我们的技术按顺序为我们获取了每个期间名称。 我们可以应用相同的技术来获取其他3字段:
['Mostly Clear', 'Sunny', 'Mostly Clear', 'Sunny', 'Slight ChanceRain', 'Rain Likely', 'Rain Likely', 'Rain Likely', 'Chance Rain']
['Low: 49 °F', 'High: 63 °F', 'Low: 50 °F', 'High: 67 °F', 'Low: 57 °F', 'High: 64 °F', 'Low: 57 °F', 'High: 64 °F', 'Low: 55 °F']
['Tonight: Mostly clear, with a low around 49. West northwest wind 12 to 17 mph decreasing to 6 to 11 mph after midnight. Winds could gust as high as 23 mph. ', 'Thursday: Sunny, with a high near 63. North wind 3 to 5 mph. ', 'Thursday Night: Mostly clear, with a low around 50. Light and variable wind becoming east southeast 5 to 8 mph after midnight. ', 'Friday: Sunny, with a high near 67. Southeast wind around 9 mph. ', 'Friday Night: A 20 percent chance of rain after 11pm. Partly cloudy, with a low around 57. South southeast wind 13 to 15 mph, with gusts as high as 20 mph. New precipitation amounts of less than a tenth of an inch possible. ', 'Saturday: Rain likely. Cloudy, with a high near 64. Chance of precipitation is 70%. New precipitation amounts between a quarter and half of an inch possible. ', 'Saturday Night: Rain likely. Cloudy, with a low around 57. Chance of precipitation is 60%.', 'Sunday: Rain likely. Cloudy, with a high near 64.', 'Sunday Night: A chance of rain. Mostly cloudy, with a low around 55.']
将我们的数据合并到Pandas Dataframe中 (Combining our data into a Pandas Dataframe)
We can now combine the data into a Pandas DataFrame and analyze it. A DataFrame is an object that can store tabular data, making data analysis easy. If you want to learn more about Pandas, check out our free to start course here.
现在,我们可以将数据合并到Pandas DataFrame中并进行分析。 DataFrame是可以存储表格数据的对象,从而使数据分析变得容易。 如果您想了解有关熊猫的更多信息,请在此处免费试用我们的课程。
In order to do this, we’ll call the DataFrame class, and pass in each list of items that we have. We pass them in as part of a dictionary. Each dictionary key will become a column in the DataFrame, and each list will become the values in the column:
为了做到这一点,我们将调用DataFrame类,并传入我们拥有的每个项目列表。 我们将它们作为字典的一部分传递。 每个字典键将成为DataFrame中的一列,每个列表将成为该列中的值:
import import pandas pandas as as pd
pd
weather weather = = pdpd .. DataFrameDataFrame ({({"period""period" : : periodsperiods , , "short_desc""short_desc" : : short_descsshort_descs , , "temp""temp" : : tempstemps , , "desc""desc" :: descsdescs})
})
weather
weather
| desc | 描述 | period | 期 | short_desc | short_desc | temp | 温度 | ||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Tonight: Mostly clear, with a low around 49. W… | 今晚:大部分时间晴,最低至49。W… | Tonight | 今晚 | Mostly Clear | 大部分晴 | Low: 49 °F | 最低:49°F |
| 1 | 1个 | Thursday: Sunny, with a high near 63. North wi… | 星期四:晴,高点在63附近。 | Thursday | 星期四 | Sunny | 阳光明媚 | High: 63 °F | 最高:63°F |
| 2 | 2 | Thursday Night: Mostly clear, with a low aroun… | 星期四晚上:大部分晴朗,周围无阳光。 | ThursdayNight | 星期四晚上 | Mostly Clear | 大部分晴 | Low: 50 °F | 最低:50°F |
| 3 | 3 | Friday: Sunny, with a high near 67. Southeast … | 星期五:晴,高点接近67。东南… | Friday | 星期五 | Sunny | 阳光明媚 | High: 67 °F | 最高:67°F |
| 4 | 4 | Friday Night: A 20 percent chance of rain afte… | 星期五晚上:雨后有20%的几率发生… | FridayNight | 星期五晚上 | Slight ChanceRain | 轻微机会雨 | Low: 57 °F | 最低:57°F |
| 5 | 5 | Saturday: Rain likely. Cloudy, with a high ne… | 星期六:可能会下雨。 晴间多云 | Saturday | 星期六 | Rain Likely | 可能下雨 | High: 64 °F | 最高:64°F |
| 6 | 6 | Saturday Night: Rain likely. Cloudy, with a l… | 周六晚上:可能会下雨。 多云,有… | SaturdayNight | 周六晚上 | Rain Likely | 可能下雨 | Low: 57 °F | 最低:57°F |
| 7 | 7 | Sunday: Rain likely. Cloudy, with a high near… | 星期日:可能下雨。 多云,近在... | Sunday | 星期日 | Rain Likely | 可能下雨 | High: 64 °F | 最高:64°F |
| 8 | 8 | Sunday Night: A chance of rain. Mostly cloudy… | 周日晚上:可能会下雨。 大部分多云... | SundayNight | 星期天晚上 | Chance Rain | 机会雨 | Low: 55 °F | 最低:55°F |
We can now do some analysis on the data. For example, we can use a regular expression and the Series.str.extract method to pull out the numeric temperature values:
现在,我们可以对数据进行一些分析。 例如,我们可以使用正则表达式和Series.str.extract方法提取数字温度值:
0 49
1 63
2 50
3 67
4 57
5 64
6 57
7 64
8 55
Name: temp_num, dtype: object
We could then find the mean of all the high and low temperatures:
然后,我们可以找到所有高温和低温的平均值:
weatherweather [[ "temp_num""temp_num" ]] .. meanmean ()
()
58.444444444444443
We could also only select the rows that happen at night:
我们也只能选择夜间发生的行:
0 True
1 False
2 True
3 False
4 True
5 False
6 True
7 False
8 True
Name: temp, dtype: bool
weatherweather [[ is_nightis_night ]
]
| desc | 描述 | period | 期 | short_desc | short_desc | temp | 温度 | temp_num | temp_num | is_night | is_night | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | Tonight: Mostly clear, with a low around 49. W… | 今晚:大部分时间晴,最低至49。W… | Tonight | 今晚 | Mostly Clear | 大部分晴 | Low: 49 °F | 最低:49°F | 49 | 49 | True | 真正 |
| 2 | 2 | Thursday Night: Mostly clear, with a low aroun… | 星期四晚上:大部分晴朗,周围无阳光。 | ThursdayNight | 星期四晚上 | Mostly Clear | 大部分晴 | Low: 50 °F | 最低:50°F | 50 | 50 | True | 真正 |
| 4 | 4 | Friday Night: A 20 percent chance of rain afte… | 星期五晚上:雨后有20%的几率发生… | FridayNight | 星期五晚上 | Slight ChanceRain | 轻微机会雨 | Low: 57 °F | 最低:57°F | 57 | 57 | True | 真正 |
| 6 | 6 | Saturday Night: Rain likely. Cloudy, with a l… | 周六晚上:可能会下雨。 多云,有… | SaturdayNight | 周六晚上 | Rain Likely | 可能下雨 | Low: 57 °F | 最低:57°F | 57 | 57 | True | 真正 |
| 8 | 8 | Sunday Night: A chance of rain. Mostly cloudy… | 周日晚上:可能会下雨。 大部分多云... | SundayNight | 星期天晚上 | Chance Rain | 机会雨 | Low: 55 °F | 最低:55°F | 55 | 55 | True | 真正 |
下一步 (Next Steps)
You should now have a good understanding of how to scrape web pages and extract data. A good next step would be to pick a site and try some web scraping on your own. Some good examples of data to scrape are:
您现在应该对如何抓取网页和提取数据有了很好的了解。 下一步不错的选择是选择一个网站,然后尝试自己进行一些网络抓取。 一些要抓取的数据的好例子是:
- News articles
- Sports scores
- Weather forecasts
- Stock prices
- Online retailer prices
- 新闻文章
- 体育比分
- 天气预报
- 股票价格
- 网上零售商价格
翻译自: https://www.pybloggers.com/2016/11/python-web-scraping-tutorial-using-beautifulsoup/
使用BeautifulSoup的Python Web爬网教程相关推荐
- python web应用_为您的应用选择最佳的Python Web爬网库
python web应用 Living in today's world, we are surrounded by different data all around us. The ability ...
- vs azure web_在Azure中迁移和自动化Chrome Web爬网程序的指南。
vs azure web Webscraping as a required skill for many data-science related jobs is becoming increasi ...
- python微信爬取教程_PYTHON爬虫之旅系列教程之【利用Python开发微信公众平台一】...
感谢大家的等待,好啦,都准备好瓜子.板凳,老司机要发车啦-- 本系列课程讲述"PYTHON爬虫之旅",具体大纲可参考:[PYTHON爬虫之旅]概要目录. 本节课讲述如何利用Pyth ...
- 构建您的第一个Web爬网程序,第2部分
在本教程中,您将学习如何使用Mechanize单击链接,填写表单和上传文件. 您还将学习如何切片机械化页面对象,以及如何自动执行Google搜索并保存其结果. 主题 单页与分页 机械化 代理商 页 N ...
- pythonweb搭建教程_基于Centos搭建Python Web 环境搭建教程
CentOS 7.2 64 位操作系统 安装 setuptools 工具 安装 因为之后我们需要安装 Django ,而 Django 需要用这个工具,所以我们需要先安装 setuptools 工具. ...
- python爬虫爬图片教程_Python爬虫爬图片需要什么
Python爬虫爬图片需要什么?下面用两种方法制作批量爬取网络图片的方法: 第一种方法:基于urllib实现 要点如下: 1.url_request = request.Request(url) 2. ...
- python爬虫爬图片教程_python爬去妹子网整个图片资源教程(最详细版)
爬取妹子网的低级教程连接如下:[爬妹子网](https://blog.csdn.net/baidu_35085676/article/details/68958267) ps:只支持单个套图下载,不支 ...
- python爬虫如何运行在web_Python Web爬网-使用爬虫进行测试
本章介绍了如何在Python中使用Web抓取工具执行测试. 介绍 在大型Web项目中,会定期执行网站后端的自动化测试,但经常会跳过前端测试.这背后的主要原因是网站的编程就像各种标记和编程语言的网络一样 ...
- python微信爬取教程_python爬虫_微信公众号推送信息爬取的实例
问题描述 利用搜狗的微信搜索抓取指定公众号的最新一条推送,并保存相应的网页至本地. 注意点 搜狗微信获取的地址为临时链接,具有时效性. 公众号为动态网页(JavaScript渲染),使用request ...
最新文章
- ecs服务器配置git_基于ECS和NAS搭建个人网盘
- 如何自学python爬虫-怎样入门学习Python爬虫?
- 算法导论之多项式与快速傅里叶变换
- springer journal recommendation tool
- php stmp 授权码问题,PHPmailer 使用网易126发送邮件的问题
- 技术人看《长安十二时辰》的正确姿势是?
- matlab中关于程序运行的快捷键
- python程序弹出输入框_尝试使Kivy按钮弹出一个文本框
- TCP洪水攻击(SYN Flood)的诊断和处理
- 算法进阶之Leetcode刷题记录
- feedback vertex set problem (FVS) 反馈顶点集问题 是什么
- 计算机方向关键字,从计算机的角度理解volatile关键字
- mmap文件做成html,mmap()映射到文件的一些总结
- 老男孩python课后作业_老男孩Python全栈学习 S9 日常作业 001
- 【天池大数据竞赛】“数智教育”2019数据可视化竞赛亚军方案总结
- 【CF487E】Tourists
- FIDO android客户端认证
- PHP的strtolower()和strtoupper()函数在安装非中文系统的服务器下可能会导致将汉字转换为乱码,请写两个替代的函数实现兼容Unicode文字的字符串大小写转换
- 坐标正反算通用程序(极短篇)
- 「对话GitOps之星」张晋涛:“肝帝”时不时也会拖更