python爬取小说代码_Python scrapy爬取小说代码案例详解
scrapy是目前python使用的最广泛的爬虫框架
架构图如下
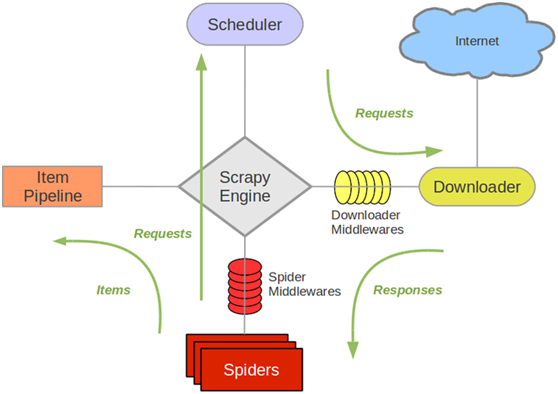
解释:
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
DownloaderMiddlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests
一。安装
pip install Twisted.whl
pip install Scrapy
Twisted的版本要与安装的python对应,https://jingyan.baidu.com/article/1709ad8027be404634c4f0e8.html
二。代码
本实例采用xpaths解析页面数据
按住shift-右键-在此处打开命令窗口
输入scrapy startproject qiushibaike 创建项目
输入scrapy genspiderqiushibaike 创建爬虫
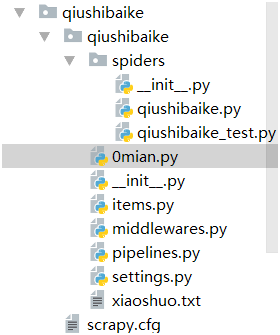
1>结构
2>qiushibaike.py爬虫文件
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders.crawl import Rule, CrawlSpider
class BaiduSpider(CrawlSpider):
name = 'qiushibaike'
allowed_domains = ['qiushibaike.com']
start_urls = ['https://www.qiushibaike.com/text/']#启始页面
#
rules= (
Rule(LinkExtractor(restrict_xpaths=r'//a[@class="contentHerf"]'),callback='parse_item',follow=True),
Rule(LinkExtractor(restrict_xpaths=r'//ul[@class="pagination"]/li/a'),follow=True)
)
def parse_item(self, response):
title=response.xpath('//h1[@class="article-title"]/text()').extract_first().strip() #标题
time=response.xpath(' //span[@class="stats-time"]/text()').extract_first().strip() #发布时间
content=response.xpath('//div[@class="content"]/text()').extract_first().replace(' ','\n') #内容
score=response.xpath('//i[@class="number"]/text()').extract_first().strip() #好笑数
yield({"title":title,"content":content,"time":time,"score":score});
3>pipelines.py 数据管道[code]class QiushibaikePipeline:
class QiushibaikePipeline:
def open_spider(self,spider):#启动爬虫中调用
self.f=open("xiaoshuo.txt","w",encoding='utf-8')
def process_item(self, item, spider):
info=item.get("title")+"\n"+ item.get("time")+" 好笑数"+item.get("score")+"\n"+ item.get("content")+'\n'
self.f.write(info+"\n")
self.f.flush()
def close_spider(self,spider):#关闭爬虫中调用
self.f.close()
4>settings.py
开启ZhonghengPipeline
ITEM_PIPELINES = {
'qiushibaike.pipelines.QiushibaikePipeline': 300,
}
5>0main.py运行
from scrapy.cmdline import execute
execute('scrapy crawl qiushibaike'.split())
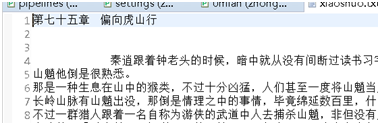
6>结果:
生成xiaohua.txt,里面有下载的笑话文字
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
python爬取小说代码_Python scrapy爬取小说代码案例详解相关推荐
- java同步方法完成案例_Java同步代码块和同步方法原理与应用案例详解
本文实例讲述了java同步代码块和同步方法.分享给大家供大家参考,具体如下: 一 点睛 所谓原子性WOmoad:一段代码要么执行,要么不执行,不存在执行一部分被中断的情况.言外之意是这段代码就像原子一 ...
- java 同步块原理_Java同步代码块和同步方法原理与应用案例详解
Java同步代码块和同步方法原理与应用案例详解 发布于 2020-8-7| 复制链接 摘记: 本文实例讲述了Java同步代码块和同步方法.分享给大家供大家参考,具体如下:一 点睛所谓原子性:一段代码要 ...
- python 实时数据推送_python scrapy 爬取金十数据并自动推送到微信
一.背景 因业务需要获取风险经济事件并采取应对措施,但因为种种原因又疏忽于每天去查看财经日历,于是通过爬取金十数据网站并自动推送到微信查看. 二.目标实现 image 三.环境与工具 1.pychar ...
- 粒子群优化算法和python代码_Python编程实现粒子群算法(PSO)详解
1 原理 粒子群算法是群智能一种,是基于对鸟群觅食行为的研究和模拟而来的.假设在鸟群觅食范围,只在一个地方有食物,所有鸟儿看不到食物(不知道食物的具体位置),但是能闻到食物的味道(能知道食物距离自己位 ...
- python多线程读取数据库数据_Python基于多线程操作数据库相关知识点详解
Python基于多线程操作数据库相关问题分析 本文实例分析了Python多线程操作数据库相关问题.分享给大家供大家参考,具体如下: python多线程并发操作数据库,会存在链接数据库超时.数据库连接丢 ...
- python爬虫常见报错_Python爬虫常见HTTP响应状态码详解
在使用Python进行网页数据抓取时,经常会遇到无数据返还或错误等异常,这个时候可以通过status_code命令来查看获得http请求返回的状态码,以便查找原因并制定相应的解决方案.import r ...
- python生成二维码_python生成二维码的实例详解
python生成二维码的实例详解 版本相关 操作系统:Mac OS X EI Caption Python版本:2.7 IDE:Sublime Text 3 依赖库 Python生成二维码需要的依赖库 ...
- python代码覆盖率怎么统计的_Python代码覆盖率统计工具coverage.py用法详解
1.安装coverage pip install coverage 安装完成后,会在Python环境下的\Scripts下看到coverage.exe: 2.Coverage 命令行 coverage ...
- python在统计专业的应用_Python统计学一数据的概括性度量详解
一.数据的概括性度量 1.统计学概括: 统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观察系统的数据,进行量化的分析.总结,并进而进行推断和预测,为相关决策提供依据和参考.统计学主 ...
- python的xpath用法介绍_python爬虫之xpath的基本使用详解
本篇文章主要介绍了python爬虫之xpath的基本使用详解,现在分享给大家,也给大家做个参考.一起过来看看吧 一.简介 XPath 是一门在 XML 文档中查找信息的语言.XPath 可用来在 XM ...
最新文章
- Python库安装相关问题
- android:contentDescription
- 蒙特利尔大学助理教授唐建《图表示学习:算法与应用》研究进展
- SuperMap iServer安装过程详解
- 更高效地利用 Jupyter+pandas 进行数据分析,6 种常用数据格式效率对比!
- perl多进程实战之一
- ArrayList排序Sort()方法(转)
- php 获取域名,域名端口,路径 $_SERVER变量
- 无限容量还不限速的网盘,了解一下~
- 开源社区人们总说的LGTM是什么意思?
- 管理员登录页面html代码,自己做的一个后台管理员登陆界面 .cshtml
- css —— 写炫酷动画
- 弹性伸缩系统的技术演进与落地实践
- 微信官方发红包DEMO
- 移动直播技术秒开优化经验(含PPT)
- Vue中的vm和VueComponent的实例对象
- oracle 二表做差,oracle 两表数据对比---minus
- Java计算机毕业设计腾讯网游辅助小助手源码+系统+数据库+lw文档
- 调用谷歌翻译实现英文转中文
- std::thread介绍