图数据库 TigerGraph 使用全攻略
与关系型数据库或其他类型的NoSQL数据库相比,图数据库提供了更有效的关系和网络建模方法。在1999年左右,图数据库领域还是Neo4j一家独大,但是发展至今,该领域也出现了很多新玩家和新产品。
TigerGraph是一款“实时原生并行图数据库”,既可以部署在云端也可以部署在本地,支持垂直扩展和水平扩展,可以对集群中的图数据自动分区,遵循ACID标准,并且提供了内置的数据压缩功能。它使用了一种消息传递架构,这种架构具备了可随数据增长而伸缩的并行性。
TigerGraph被设计用来执行深层链接分析以及实时在线事务处理(OLTP)和大容量数据加载。深度链接分析是指从一个顶点开始遍历图,找到三个或更多的跳转关系,并分析出结果。目前大多数图数据库都是为OLTP设计的,用于分析少量的关系跳数,其他的分析功能基本是后续添加的。
目前,有一些开源的图查询语言已经得到了广泛的采用,如Cypher、Gremlin和SPARQL,不过,TigerGraph使用了一种新的查询语言GSQL。GSQL将SQL风格的查询语法与Cypher风格的图导航语法结合在一起,并加入了过程编程和用户自定义函数。
我对TigerGraph的GSQL查询语言一直有一种说不清的感觉,不可否认的是,它是一种很好的设计,支持并行化,且可以将Cypher转换为GSQL,便于从Neo4j数据库转到TigerGraph的开发者使用。但是,面对一门全新的编程语言,我总会问自己,它是否值得我花时间和精力来学习呢?
TigerGraph的架构
从下图中可以看出,TigerGraph包含了一个ETL加载器、图数据存储和处理引擎、查询语言和可视化客户端以及REST API,并集成了很多企业数据基础设施服务。再往下的系统流程图清楚地表明,TigerGraph使用Apache Kafka与图形处理和存储引擎进行通信,使用Nginx Web服务器处理GraphStudio和来自用户的GSQL请求,并将它们传给后端服务器。
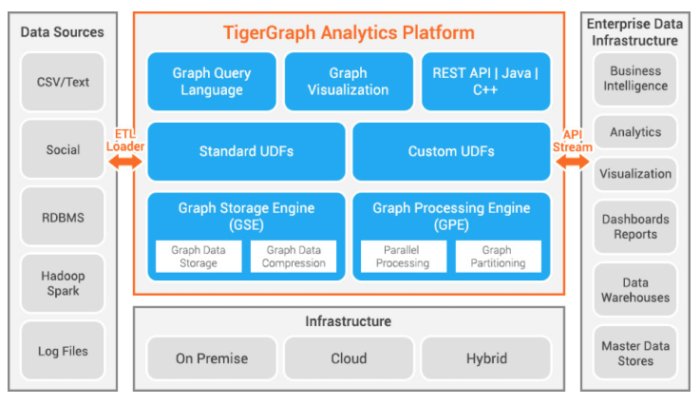
TigerGraph Analytics Platform包含了图数据存储引擎、图数据处理引擎和三种类型的API。它可以在本地、云端或混合环境中运行。
传给TigerGraph的消息可以在顶点或边级别进行并行处理。RESTPP是一种增强的REST API服务器,主要用于任务管理。
TigerGraph每小时可以加载多达150 GB的数据,每台机器每秒可以遍历数亿个顶点或边,将20亿个日常事件以流的方式实时地传输到包含1千亿个顶点和6千亿条边的图中(这些图数据处于包含20台商用机器的集群上),并将实时分析与大规模离线数据处理统一起来。
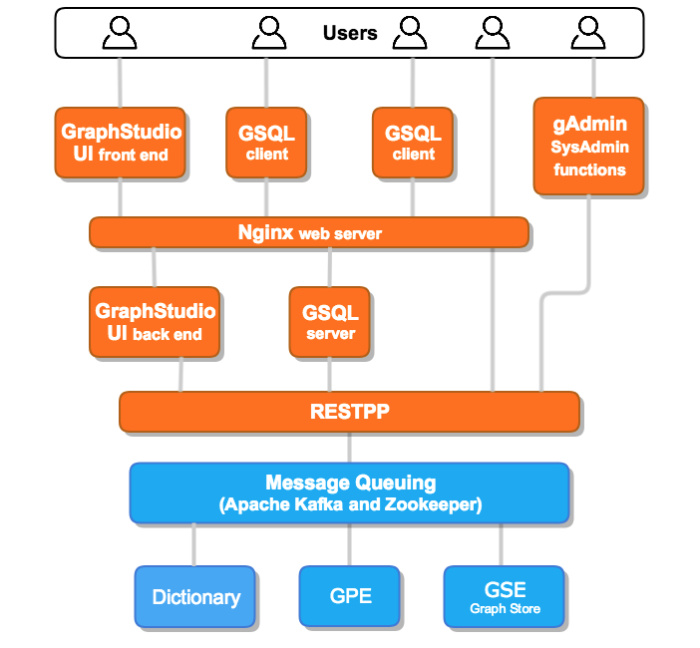
TigerGraph使用了几种流行的开源组件:用于处理Web流量的Nginx、消息队列Apache Kafka、用于管理Kafka集群的Apache Zookeeper。平台的其余部分则使用了专有代码。
在Docker中安装TigerGraph
你可以在各种流行的Linux(加上Docker和VirtualBox)上安装TigerGraph。我选择在iMac上使用Docker来安装。在开始安装之前,我更新了Docker,并将Docker可用的RAM和处理器分别增加到4 GB和4个内核。最后,我将TigerGraph镜像下载到本地。
Martins-iMac:Downloads mheller$ docker load \u0026lt; ./tigergraph-developer-2.2.3-docker-image.tar.gz8823818c4748: Loading layer 119MB/119MB19d043c86cbc: Loading layer 15.87kB/15.87kB883eafdbe580: Loading layer 14.85kB/14.85kB4775b2f378bb: Loading layer 5.632kB/5.632kB75b79e19929c: Loading layer 3.072kB/3.072kB2106b49716cb: Loading layer 7.168kB/7.168kBda572f4e0c2f: Loading layer 4.034GB/4.034GB6cd767fef659: Loading layer 338.4kB/338.4kBLoaded image: tigergraph:2.2.3Martins-iMac:Downloads mheller$ docker image lsREPOSITORY TAG IMAGE ID CREATED SIZEtigergraph 2.2.3 e1911655f9a7 3 weeks ago 4.11GBhello-world latest 4ab4c602aa5e 2 months ago 1.84kB安装过程中没有出现任何警报,启动过程也很顺利。
Martins-iMac:Downloads mheller$ docker run -i -t --name tigergraph -p 4142:14240 tigergraph:2.2.3Welcome to TigerGraph Developer Edition, for non-commercial use only.[RUN ] rm -rf /home/tigergraph/tigergraph/logs/ALL*.pid[FAB ][2018-11-30 21:56:06] check_port_of_admin_servers[RUN ] /home/tigergraph/tigergraph/.gium/GSQL_LIB/service/../scripts/admin_service.sh start/home/tigergraph/tigergraph/bin/admin_server/config.sh=== zk ===[SUMMARY][ZK] process is down[SUMMARY][ZK] /home/tigergraph/tigergraph/zk is ready=== dict ===[SUMMARY][DICT] process is down[SUMMARY][DICT] dict server has NOT been initialized=== kafka ===[SUMMARY][KAFKA] process is down[SUMMARY][KAFKA] queue has NOT been initialized=== gse ===[SUMMARY][GSE] process is down[SUMMARY][GSE] id service has NOT been initialized=== gpe ===[SUMMARY][GPE] process is down[SUMMARY][GPE] graph has NOT been initialized=== nginx ===[SUMMARY][NGINX] process is down[SUMMARY][NGINX] nginx has NOT been initialized=== restpp ===[SUMMARY][RESTPP] process is down[SUMMARY][RESTPP] restpp has NOT been initialized[FAB ][2018-11-30 21:56:47] launch_zookeepers[FAB ][2018-11-30 21:57:00] launch_gsql_subsystems:DICT[FAB ][2018-11-30 21:57:04] launch_kafkas[FAB ][2018-11-30 21:57:22] launch_ts3s[FAB ][2018-11-30 21:57:25] launch_gsql_subsystems:GSE[FAB ][2018-11-30 21:57:28] launch_gsql_subsystems:GPE[FAB ][2018-11-30 21:57:31] launch_gsql_subsystems:NGINX[FAB ][2018-11-30 21:57:34] launch_gsql_subsystems:RESTPP[FAB ][2018-11-30 21:57:38] check_port_of_vis_services[RUN ] LD_LIBRARY_PATH=\u0026quot;/home/tigergraph/tigergraph/bin\u0026quot; home/tigergraph/tigergraph/visualization/utils/start.sh[FAB ][2018-11-30 21:57:39] check_port_of_admin_servers[RUN ] home/tigergraph/tigergraph/.gium/GSQL_LIB/service/../scripts/admin_service.sh start home/tigergraph/tigergraph/bin/admin_server/config.sh[RUN ] /home/tigergraph/tigergraph/dev/gdk/gsql/gsql_server_util START || :=== zk ===[SUMMARY][ZK] process is up[SUMMARY][ZK] /home/tigergraph/tigergraph/zk is ready=== kafka ===[SUMMARY][KAFKA] process is up[SUMMARY][KAFKA] queue is ready=== gse ===[SUMMARY][GSE] process is up[SUMMARY][GSE] id service has NOT been initialized (not_ready)=== dict ===[SUMMARY][DICT] process is up[SUMMARY][DICT] dict server is ready=== ts3 ===[SUMMARY][TS3] process is up[SUMMARY][TS3] ts3 is ready=== graph ===[SUMMARY][GRAPH] graph has NOT been initialized=== nginx ===[SUMMARY][NGINX] process is up[SUMMARY][NGINX] nginx is ready=== restpp ===[SUMMARY][RESTPP] process is up[SUMMARY][RESTPP] restpp is ready=== gpe ===[SUMMARY][GPE] process is up[SUMMARY][GPE] graph has NOT been initialized (not_ready)=== gsql ===[SUMMARY][GSQL] process is up[SUMMARY][GSQL] gsql is ready=== Visualization ===[SUMMARY][VIS] process is up (VIS server PID: 1242)[SUMMARY][VIS] gui server is up[RUN ] rm -rf ~/.gsql/gstore_gs*_autostart_flagDone.tigergraph@2089c417aa54:~$执行到这一步,我已经启动了gsql客户端,并完成了一些命令行教程和演示。
tigergraph@2089c417aa54:~$ ls /home/tigergraph/friendship.csv hello2.gsql hello.gsql person.csv tigergraph tigergraph_coredumptigergraph@2089c417aa54:~$ gsqlWelcome to TigerGraph Developer Edition, for non-commercial use only.GSQL-Dev \u0026gt;GSQL教程和示例
GSQL 101教程(https://docs.tigergraph.com/intro/gsql-101)教你如何创建图模式、加载数据和运行查询。对于完成某些操作(例如安装自定义查询)所花费的时间,我感到有些惊讶,但它们确实与文档所描述的是一致的。
为了让你对GSQL有个直观的感受,以下的自定义查询演示了如何使用累加器、嵌套查询和自定义查询。
USE GRAPH socialCREATE QUERY hello2 (VERTEX\u0026lt;person\u0026gt; p) FOR GRAPH social{ OrAccum @visited = false; AvgAccum @@avgAge; Start = {p}; FirstNeighbors = SELECT tgt FROM Start:s -(friendship:e)-\u0026gt; person:tgt ACCUM tgt.@visited += true, s.@visited += true; SecondNeighbors = SELECT tgt FROM FirstNeighbors -(:e)-\u0026gt; :tgt WHERE tgt.@visited == false POST_ACCUM @@avgAge += tgt.age; PRINT SecondNeighbors; PRINT @@avgAge;}INSTALL QUERY hello2RUN QUERY hello2(\u0026quot;Tom\u0026quot;)GSQL的演示示例(https://docs.tigergraph.com/dev/gsql-examples)涵盖了其他内容,包括协作过滤、PageRank、产品推荐和最短路径算法,这些也值得研究一下。由于开发者许可只允许每个数据库使用一个图,所以你需要通过DROP ALL来删除在练习中创建的社交图数据。
GSQL图算法库(https://docs.tigergraph.com/graph-algorithm-library)实现了标准图算法,并经过测试。你可以从GitHub下载这个库(https://github.com/tigergraph/ecosys/tree/master/graph_algorithms)。除了基本算法,这个库还提供了安装脚本,可用于生成自定义算法。这些算法包括紧密度中心性、连通分量检测、社区检测、PageRank、最短路径和三角计数。
GraphStudio和TigerGraph测试驱动
除了GSQL的命令行界面外,TigerGraph还提供了一个叫作GraphStudio的GUI。你可以通过浏览localhost:4142在本地实例上访问它,如下所示。
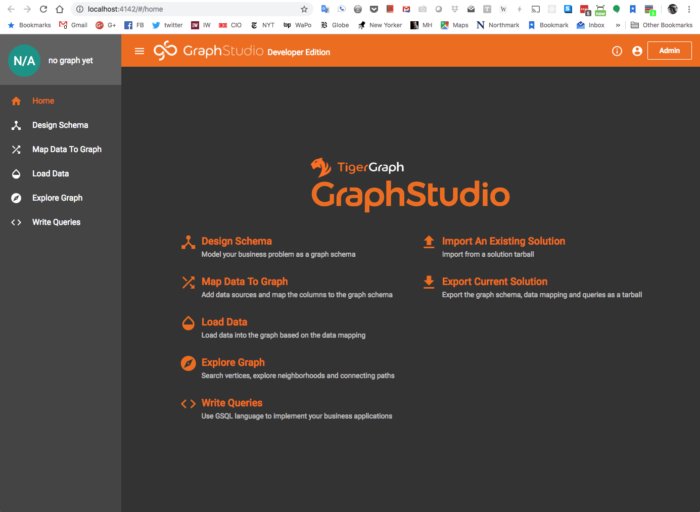
TigerGraph的GraphStudio GUI可以用于设计图模式、加载数据和探索图。查询使用GSQL编写。
出于学习的目的,你可能需要了解下TigerGraph测试驱动演示(https://testdrive.tigergraph.com/main/dashboard)。它们是只读的图数据库,包括一些预定义的参数化查询。当然,你也可以编写自己的查询。
包含了较大数据集(包含了数十亿条边)的三个测试驱动用例使用了Amazon EC2 r4.4xlarge(16个vCPU和122 GB RAM)实例,而包含小数据集的两个测试驱动用例使用了更经济的Amazon EC2 t2.xlarge(4个vCPU和16 GB RAM)实例。根据我的经验,即使对于具有44亿边缘的反欺诈演示(如下所示),它的性能也相当不错。
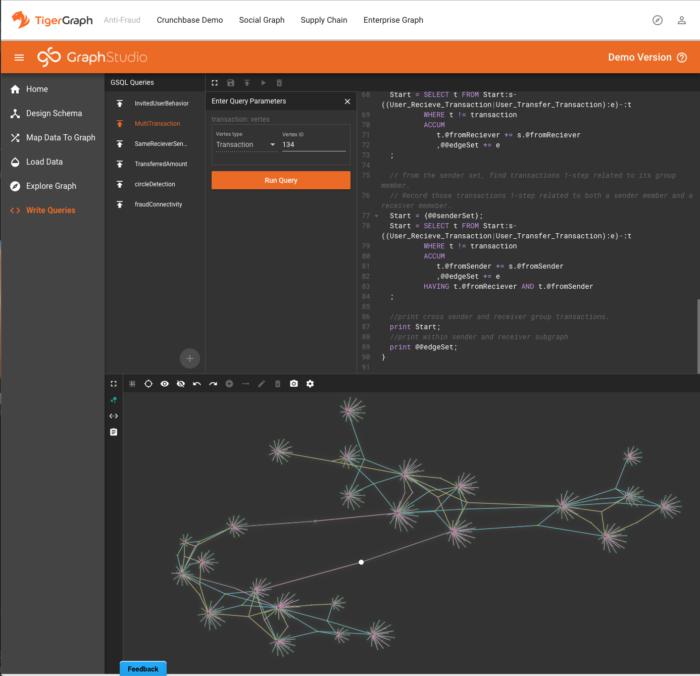
使用GraphStudio对包含用户、设备和交易数据的大型(44亿条边)图执行欺诈检测查询。GraphStudio和TigerGraph都运行在Amazon EC2 r4.4xlarge实例上。
TigerGraph基准测试
TigerGraph提供了一些基准测试(https://www.tigergraph.com/benchmark/),与其他几个图数据库(Neo4j、Amazon Neptune、JanusGraph和ArangoDB)进行了比较,测试了数据加载时间和图分析查询时间,所有这些任务在TigerGraph中都可以进行并行化操作。毫不奇怪的是,因为基准测试的设置方式偏向于TigerGraph的长处,所以TigerGraph在所有测试中均胜出,有些还胜出了一大截。其中令我印象深刻的基准测试是TigerGraph集群可扩展性测试,当使用8台机器时,它的速度提升了6.7倍。
在这种情况下,你需要问自己的问题是:“图数据库可以帮我解决哪些问题”?如果你要进行在线事务处理(OLTP),那你可能就不会关心批量加载和多跳分析查询性能。毕竟,唯一真正重要的衡量标准是数据库能为应用程序做些什么,这也是为什么在采用新技术时需要花些时间进行概念验证。
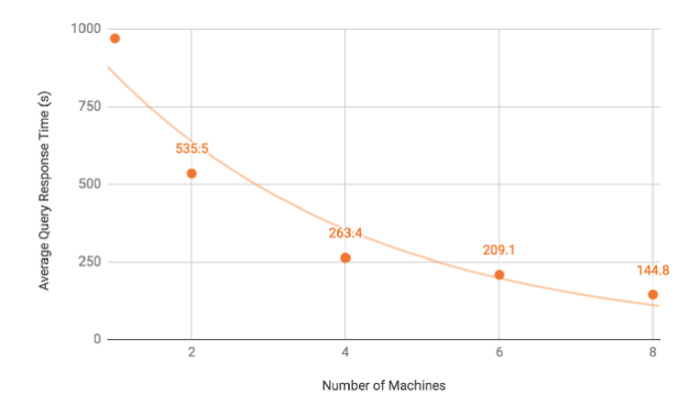
TigerGraph集群可扩展性测试,使用8台机器时速度提升6.7倍。如果可扩展性可以达到完美,那么这条线应该是直的,而且速度提升将达到8倍。
云端的TigerGraph
在我进行这次调研时,TigerGraph发布了一款云产品,将于2019年在AWS上开始试用。这是对TigerGraph目前授权版AWS和Azure镜像的一个补充。
英文原文:https://www.javaworld.com/article/3330736/application-development/tigergraph-review-a-graph-database-designed-for-deep-analytics.html?upd=1547004107229
图数据库 TigerGraph 使用全攻略相关推荐
- 传统关系型数据库性能优化全攻略
影响数据库性能的因素 业务需求层面 不合理的需求 论坛发帖数实时更新select count(*) from table 深翻页 比如查询第1万页的内容冷数据加载到内存热数据被swap出去了目前基本已 ...
- 从网页模版切图到网页生成全攻略(转)
鉴于很多朋友问到如何切图这个问题,又鉴于这个问题可大可小,一两句话是绝对讲不清楚的,所以今天有空闲在家里就举一个简单的例子来说明这个问题吧!OK,让我们开始: step1:在Photoshop中打开设 ...
- PSD的网页模版PS切图到网页生成全攻略
鉴于很多模板天下的朋友问,你们网站上有很多的psd格式的模板,这个怎么做成网页啊. 所以呢,我在这里就给大家讲一讲将PSD格式的模板进行切图,然后导出,然后再dreamweaver中编辑,最后就得到了 ...
- dw2019连接mysql数据库_Dreamweaver 8.0连接Mysql数据库全攻略
1 Dreamweaver 8.0 连接 Mysql 数据库全攻略 一.所需安装文件清单: 1 . Dreamweaver8.0 2 . SP2DBFix1.0.2.mxp ( Dreamweaver ...
- EVC4.0+AdoCe3.1访问Access数据库全攻略(附带说明及例程)
http://bbs.mscommunity.com/forums/ShowThread.aspx?PostID=26641 EVC4.0+AdoCe3.1访问Access数据库全攻略(附带说明及例程 ...
- 手动创建数据库实例全攻略7:UNDO
手动创建数据库实例全攻略7:UNDO 一.偷来的常识 网络上这个哥们写的太精彩了,直接复制阅读之! 文字来源:http://blog.csdn.net/tianlesoftware/article/d ...
- VC用ADO访问数据库全攻略 作者 相生昌
VC用ADO访问数据库全攻略 作者 相生昌 <script language=VBScript> document.title="VC用ADO访问数据库全攻略 "&am ...
- CAD图块全攻略:别羡慕我下班早,我的CAD软件会开挂!
在使用浩辰CAD软件进行工程设计的过程中,一些CAD图形元素会被多次重复使用,例如机械行业中的螺钉.螺母等标准紧固件.这些高频使用的CAD图形,如果每次都重新设计和绘制,十分麻烦费时.因此,在浩辰CA ...
- (转)工商银行U盾全攻略 (兼容Windows 7 多图)
工商银行U盾全攻略 (兼容Windows 7 多图) 本文的目标受众是初次接触网络银行的所谓"小白",请自诩高手的"老鸟"自行绕过. 1.什么是U盾? U盾是中 ...
最新文章
- AI人脸识别 生物识别 活体检测 的发展历程
- 交叉熵(cross entropy)概念整理
- oracle视图无法使用rowid,请问:无法从没有键值保存表的连接视图中选择 ROWID 这个是什么原因啊?...
- 小姐姐公开征婚高智商 IT 男:微信号竟要质数解密?
- Pytorch中的强化学习
- BP反向传播算法推导
- SVN-----CornerStone
- 手机游戏制作(开发流程)
- 昆明半程马拉松:1名选手死亡5名选手昏迷(图)
- C#为窗体控件设置透明色问题
- 游戏感:虚拟感觉的游戏设计师指南——第十五章 超级马里奥64
- android 监听系统广播
- P2242公路维修问题题解
- spwan-fcgi和fcgi 关系
- Css实现刘海,使用CSS Shapes实现滚动环绕iPhone X刘海效果
- j1900适合装哪版群晖_我的NAS入坑之旅(小米-DIY-群晖-威联通-蜗牛星际)
- python3.7.4 32位下载_Python for Windows 32位下载
- 用excel vba,将EXCEL数据追加到ACCESS数据库的某张表中的实例(学习备注)
- python发票识别代码_python 发票验证码自动生成
- MarkDown+Hbuilder学习总结