语音合成经典模型结构介绍
(以下内容搬运自 PaddleSpeech)
Models introduction
TTS system mainly includes three modules: Text Frontend, Acoustic model and Vocoder. We introduce a rule-based Chinese text frontend in cn_text_frontend.md. Here, we will introduce acoustic models and vocoders, which are trainable.
The main processes of TTS include:
- Convert the original text into characters/phonemes, through the
text frontendmodule. - Convert characters/phonemes into acoustic features, such as linear spectrogram, mel spectrogram, LPC features, etc. through
Acoustic models. - Convert acoustic features into waveforms through
Vocoders.
A simple text frontend module can be implemented by rules. Acoustic models and vocoders need to be trained. The models provided by PaddleSpeech TTS are acoustic models and vocoders.
Acoustic Models
Modeling Objectives of Acoustic Models
Modeling the mapping relationship between text sequences and speech features:
text X = {x1,...,xM}
specch Y = {y1,...yN}
Modeling Objectives:
Ω = argmax p(Y|X,Ω)
Modeling process of Acoustic Models
At present, there are two mainstream acoustic model structures.
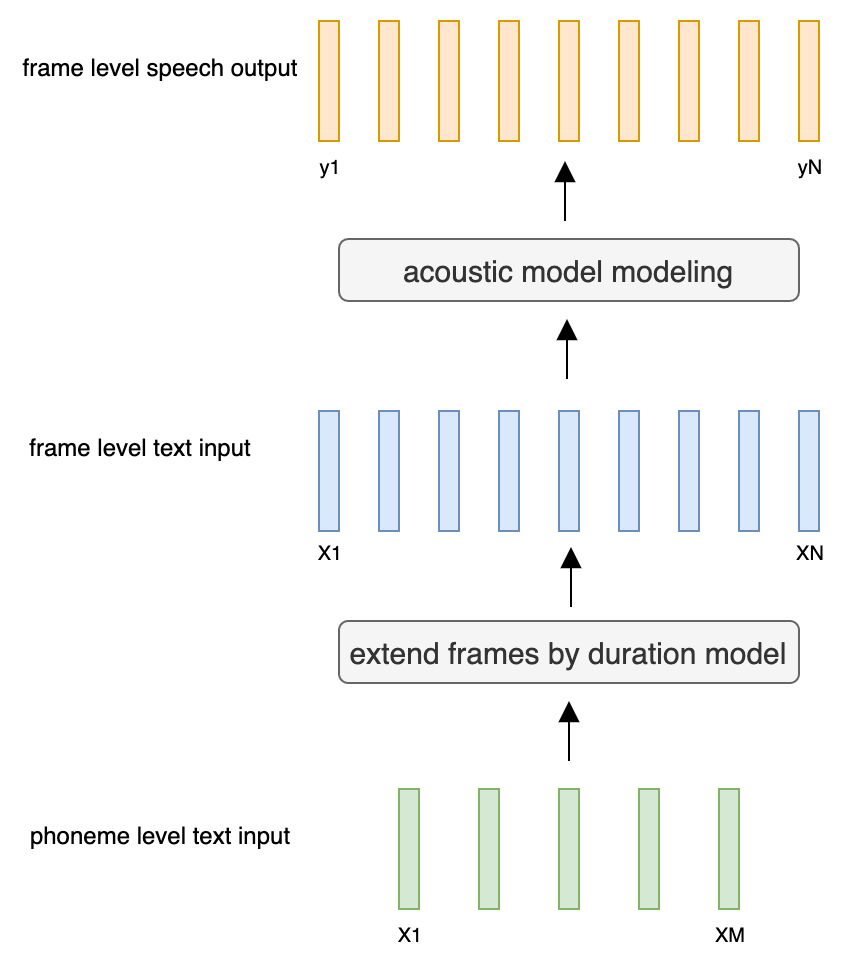
- Frame level acoustic model:
- Duration model (M Tokens - > N Frames).
- Acoustic decoder (N Frames - > N Frames).
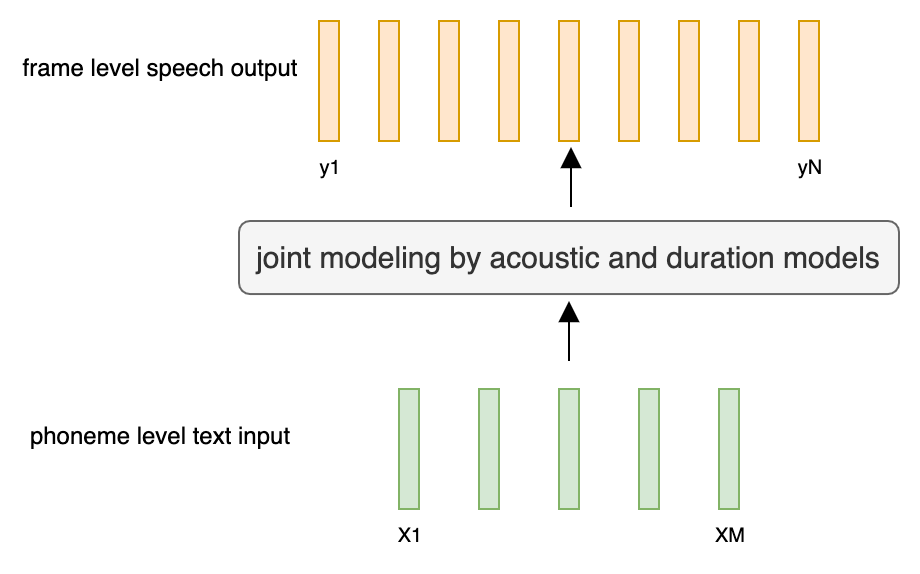
- Sequence to sequence acoustic model:
- M Tokens - > N Frames.
Tacotron2
Tacotron is the first end-to-end acoustic model based on deep learning, and it is also the most widely used acoustic model.
Tacotron2 is the Improvement of Tacotron.
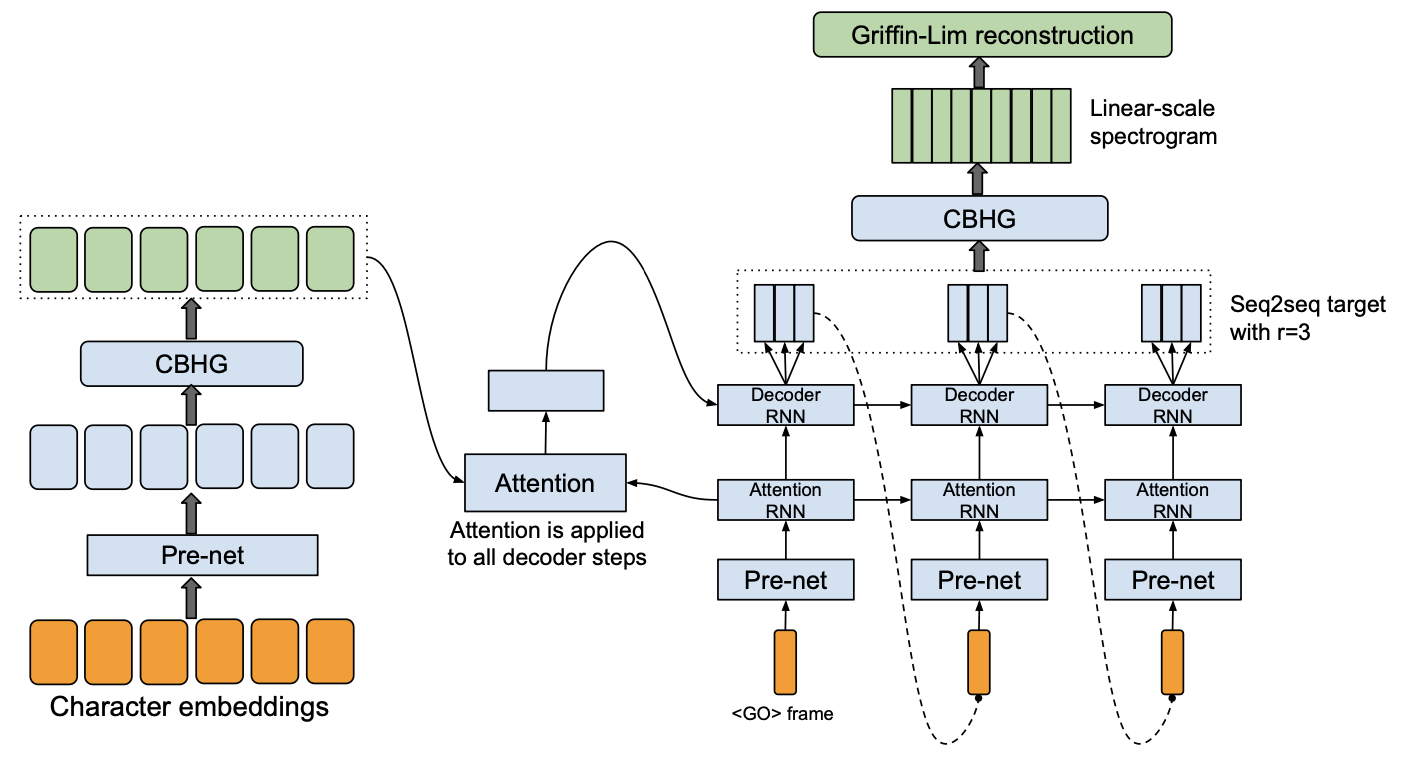
Tacotron
Features of Tacotron:
- Encoder.
- CBHG.
- Input: character sequence.
- Decoder.
- Global soft attention.
- unidirectional RNN.
- Autoregressive teacher force training (input real speech feature).
- Multi frame prediction.
- CBHG postprocess.
- Vocoder: Griffin-Lim.
Advantage of Tacotron:
- No need for complex text frontend analysis modules.
- No need for an additional duration model.
- Greatly simplifies the acoustic model construction process and reduces the dependence of speech synthesis tasks on domain knowledge.
Disadvantages of Tacotron:
- The CBHG is complex and the amount of parameters is relatively large.
- Global soft attention.
- Poor stability for speech synthesis tasks.
- In training, the less the number of speech frames predicted at each moment, the more difficult it is to train.
- Phase problem in Griffin-Lim causes speech distortion during wave reconstruction.
- The autoregressive decoder cannot be stopped during the generation process.
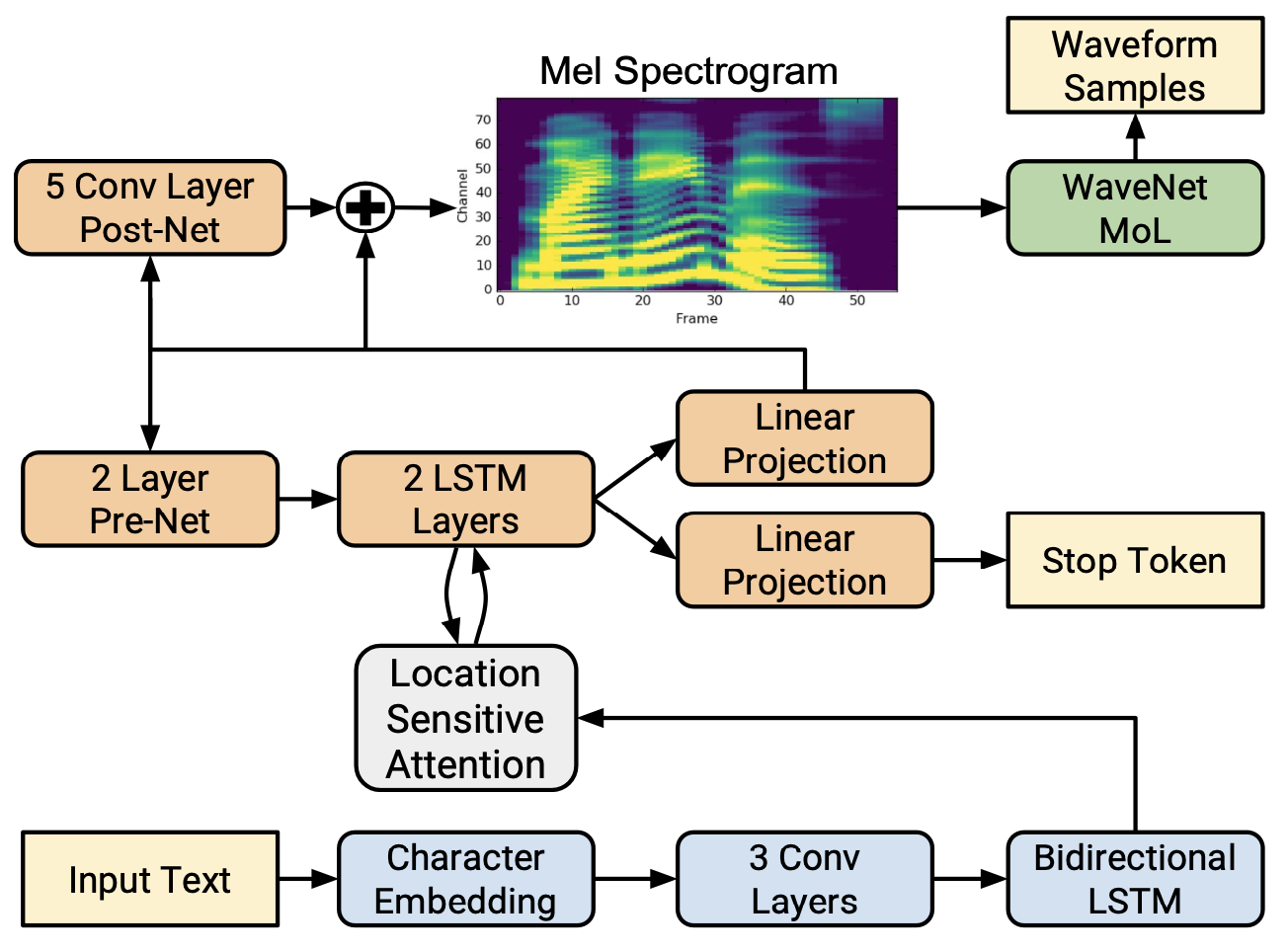
Tacotron2
Features of Tacotron2:
- Reduction of parameters.
- CBHG -> PostNet (3 Conv layers + BLSTM or 5 Conv layers).
- remove Attention RNN.
- Speech distortion caused by Griffin-Lim.
- WaveNet.
- Improvements of PostNet.
- CBHG -> 5 Conv layers.
- The input and output of the PostNet calculate
L2loss with real Mel spectrogram. - Residual connection.
- Bad stop in an autoregressive decoder.
- Predict whether it should stop at each moment of decoding (stop token).
- Set a threshold to determine whether to stop generating when decoding.
- Stability of attention.
- Location-aware attention.
- The alignment matrix of the previous time is considered at step
tof the decoder.
You can find PaddleSpeech TTS’s tacotron2 with LJSpeech dataset example at examples/ljspeech/tts0.
TransformerTTS
Disadvantages of the Tacotrons:
- Encoder and decoder are relatively weak at global information modeling
- Vanishing gradient of RNN.
- Fixed-length context modeling problem in CNN kernel.
- Training is relatively inefficient.
- The attention is not robust enough and the stability is poor.
Transformer TTS is a combination of Tacotron2 and Transformer.
Transformer
Transformer is a seq2seq model based entirely on an attention mechanism.
Features of Transformer:
- Encoder.
Nblocks based on self-attention mechanism.- Positional Encoding.
- Decoder.
Nblocks based on self-attention mechanism.- Add Mask to the self-attention in blocks to cover up the information after the
tstep. - Attentions between encoder and decoder.
- Positional Encoding.
Transformer TTS
Transformer TTS is a seq2seq acoustic model based on Transformer and Tacotron2.
Motivations:
- RNNs in Tacotron2 make the inefficiency of training.
- Vanishing gradient of RNN makes the model’s ability to model long-term contexts weak.
- Self-attention doesn’t contain any recursive structure which can be trained in parallel.
- Self-attention can model global context information well.
Features of Transformer TTS:
- Add conv based PreNet in encoder and decoder.
- Stop Token in decoder controls when to stop autoregressive generation.
- Add PostNet after decoder to improve the quality of synthetic speech.
- Scaled position encoding.
- Uniform scale position encoding may have a negative impact on input or output sequences.
Disadvantages of Transformer TTS:
- The ability of position encoding for timing information is still relatively weak.
- The ability to perceive local information is weak, and local information is more related to pronunciation.
- Stability is worse than Tacotron2.
You can find PaddleSpeech TTS’s Transformer TTS with LJSpeech dataset example at examples/ljspeech/tts1.
FastSpeech2
Disadvantage of seq2seq models:
- In the seq2seq model based on attention, no matter how to improve the attention mechanism, it’s difficult to avoid generation errors in the decoding stage.
Frame-level acoustic models use duration models to determine the pronunciation duration of phonemes, and the frame-level mapping does not have the uncertainty of sequence generation.
In seq2saq models, the concept of duration models is used as the alignment module of two sequences to replace attention, which can avoid the uncertainty in attention, and significantly improve the stability of the seq2saq models.
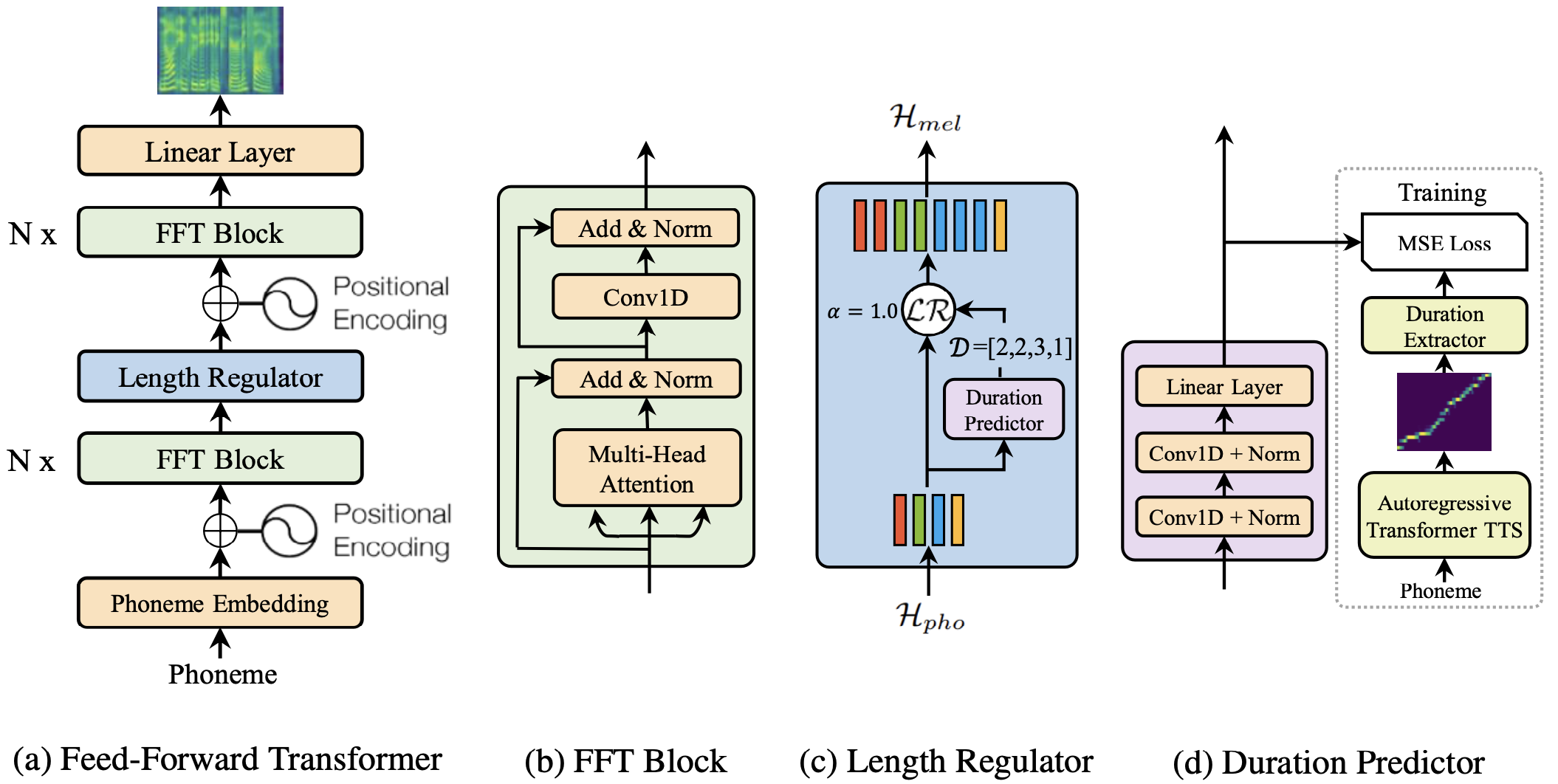
FastSpeech
Instead of using the encoder-attention-decoder based architecture as adopted by most seq2seq based autoregressive and non-autoregressive generation, FastSpeech is a novel feed-forward structure, which can generate a target mel spectrogram sequence in parallel.
Features of FastSpeech:
- Encoder: based on Transformer.
- Change
FFNtoCNNin self-attention.- Model local dependency.
- Length regulator.
- Use real phoneme durations to expand the output frame of the encoder during training.
- Non-autoregressive decode.
- Improve generation efficiency.
Length predictor:
- Pretrain a TransformerTTS model.
- Get alignment matrix of train data.
- Calculate the phoneme durations according to the probability of the alignment matrix.
- Use the output of the encoder to predict the phoneme durations and calculate the MSE loss.
- Use real phoneme durations to expand the output frame of the encoder during training.
- Use phoneme durations predicted by the duration model to expand the frame during prediction.
- Attentrion can not control phoneme durations. The explicit duration modeling can control durations through duration coefficient (duration coefficient is
1during training).
- Attentrion can not control phoneme durations. The explicit duration modeling can control durations through duration coefficient (duration coefficient is
Advantages of non-autoregressive decoder:
- The built-in duration model of the seq2seq model has converted the input length
Mto the output lengthN. - The length of the output is known,
stop tokenis no longer used, avoiding the problem of being unable to stop.
• Can be generated in parallel (decoding time is less affected by sequence length)
FastPitch
FastPitch follows FastSpeech. A single pitch value is predicted for every temporal location, which improves the overall quality of synthesized speech.
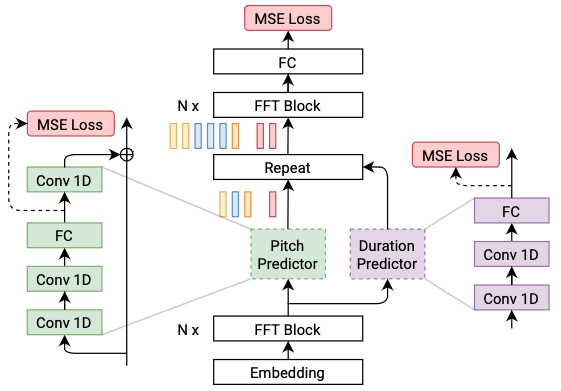
FastSpeech2
Disadvantages of FastSpeech:
- The teacher-student distillation pipeline is complicated and time-consuming.
- The duration extracted from the teacher model is not accurate enough.
- The target mel spectrograms distilled from the teacher model suffer from information loss due to data simplification.
FastSpeech2 addresses the issues in FastSpeech and better solves the one-to-many mapping problem in TTS.
Features of FastSpeech2:
- Directly train the model with the ground-truth target instead of the simplified output from the teacher.
- Introducing more variation information of speech as conditional inputs, extract
duration,pitch, andenergyfrom speech waveform and directly take them as conditional inputs in training and use predicted values in inference.
FastSpeech2 is similar to FastPitch but introduces more variation information of the speech.
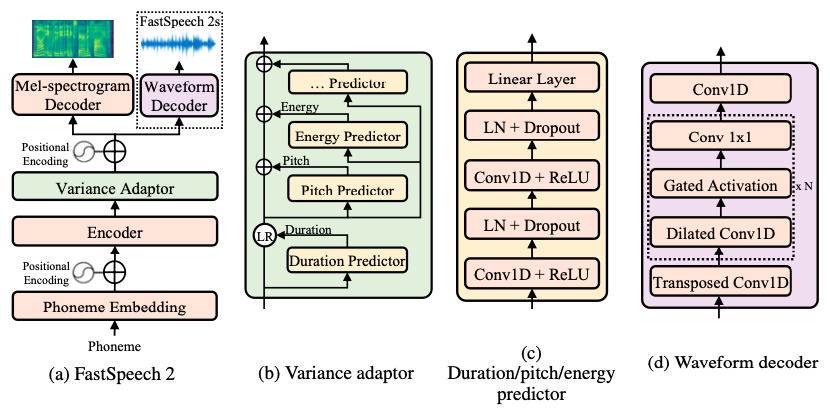
You can find PaddleSpeech TTS’s FastSpeech2/FastPitch with CSMSC dataset example at examples/csmsc/tts3, We use token-averaged pitch and energy values introduced in FastPitch rather than frame-level ones in FastSpeech2.
SpeedySpeech
SpeedySpeech simplify the teacher-student architecture of FastSpeech and provide a fast and stable training procedure.
Features of SpeedySpeech:
- Use a simpler, smaller, and faster-to-train convolutional teacher model (Deepvoice3 and DCTTS) with a single attention layer instead of Transformer used in FastSpeech.
- Show that self-attention layers in the student network are not needed for high-quality speech synthesis.
- Describe a simple data augmentation technique that can be used early in the training to make the teacher network robust to sequential error propagation.
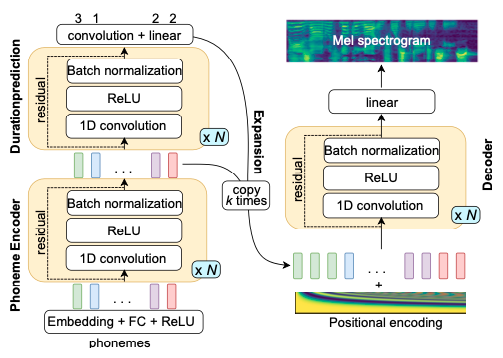
You can find PaddleSpeech TTS’s SpeedySpeech with CSMSC dataset example at examples/csmsc/tts2.
Vocoders
In speech synthesis, the main task of the vocoder is to convert the spectral parameters predicted by the acoustic model into the final speech waveform.
Taking into account the short-term change frequency of the waveform, the acoustic model usually avoids direct modeling of the speech waveform, but firstly models the spectral features extracted from the speech waveform, and then reconstructs the waveform by the decoding part of the vocoder.
A vocoder usually consists of a pair of encoders and decoders for speech analysis and synthesis. The encoder estimates the parameters, and then the decoder restores the speech.
Vocoders based on neural networks usually is speech synthesis, which learns the mapping relationship from spectral features to waveforms through training data.
Categories of neural vocodes
Autoregression
- WaveNet
- WaveRNN
- LPCNet
Flow
- WaveFlow
- WaveGlow
- FloWaveNet
- Parallel WaveNet
GAN
- WaveGAN
- Parallel WaveGAN
- MelGAN
- Style MelGAN
- Multi Band MelGAN
- HiFi GAN
VAE
- Wave-VAE
Diffusion
- WaveGrad
- DiffWave
Motivations of GAN-based vocoders:
- Modeling speech signals by estimating probability distribution usually has high requirements for the expression ability of the model itself. In addition, specific assumptions need to be made about the distribution of waveforms.
- Although autoregressive neural vocoders can obtain high-quality synthetic speech, such models usually have a slow generation speed.
- The training of inverse autoregressive flow vocoders is complex, and they also require the modeling capability of long-term context information.
- Vocoders based on Bipartite Transformation converge slowly and are complex.
- GAN-based vocoders don’t need to make assumptions about the speech distribution and train through adversarial learning.
Here, we introduce a Flow-based vocoder WaveFlow and a GAN-based vocoder Parallel WaveGAN.
WaveFlow
WaveFlow is proposed by Baidu Research.
Features of WaveFlow:
- It can synthesize 22.05 kHz high-fidelity speech around 40x faster than real-time on an Nvidia V100 GPU without engineered inference kernels, which is faster than WaveGlow and several orders of magnitude faster than WaveNet.
- It is a small-footprint flow-based model for raw audio. It has only 5.9M parameters, which is 15x smaller than WaveGlow (87.9M).
- It is directly trained with maximum likelihood without probability density distillation and auxiliary losses as used in Parallel WaveNet and ClariNet, which simplifies the training pipeline and reduces the cost of development.
You can find PaddleSpeech TTS’s WaveFlow with LJSpeech dataset example at examples/ljspeech/voc0.
Parallel WaveGAN
Parallel WaveGAN trains a non-autoregressive WaveNet variant as a generator in a GAN-based training method.
Features of Parallel WaveGAN:
- Use non-causal convolution instead of causal convolution.
- The input is random Gaussian white noise.
- The model is non-autoregressive both in training and prediction, which is fast
- Multi-resolution STFT loss.
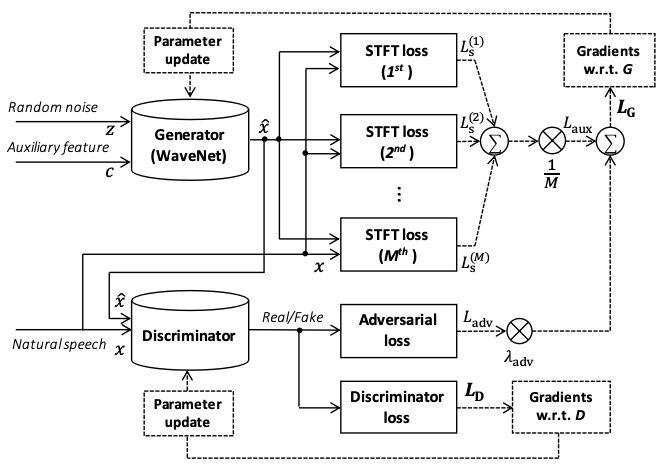
You can find PaddleSpeech TTS’s Parallel WaveGAN with CSMSC example at examples/csmsc/voc1.
P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。
语音合成经典模型结构介绍相关推荐
- 【自然语言处理】ELMo, GPT等经典模型的介绍与对比
接上一篇:BERT,Transformer的模型架构与详解 文章目录 2. ELMo, GPT等经典模型的介绍与对比 2.1 认识ELMo 学习目标 什么是ELMo ELMo的架构 ELMo的预训练任 ...
- 常用模型结构(FNN、CNN、RNN、TDNN、FSMN、Attention)
关注.点赞.收藏是对我最大的支持,谢谢^v^ 经典模型结构总结,大道至简,探寻最本质之处. 目录 1. 前馈神经网络(FNN, Feedforword Neural Network) 2. 卷积神经网 ...
- 深度神经网络经典模型介绍
经典模型的特点介绍 VGG,GoogleNet,ResNet,Inception-ResNet-v2 1. VGG模型 VGG又分为VGG16和VGG19, 分别在AlexNet的基础上将层数增加到1 ...
- 深度学习(四):卷积神经网络(CNN)模型结构,前向传播算法和反向传播算法介绍。
在前面我们讲述了DNN的模型与前向反向传播算法.而在DNN大类中,卷积神经网络(Convolutional Neural Networks,以下简称CNN)是最为成功的DNN特例之一.CNN广泛的应用 ...
- 【知识星球】分组卷积最新进展,全自动学习的分组有哪些经典模型?
欢迎大家来到<知识星球>专栏,这里是网络结构1000变小专题,今天介绍最新的分组卷积模型的进展. 作者&编辑 | 言有三 1 CondenseNet 有三AI知识星球-网络结构10 ...
- 【NLP-词向量】从模型结构到损失函数详解word2vec
上周我们讲到,在进行NNLM训练时,能够得到副产品,词向量.本文介绍一种专门用于词向量制备的方法:word2vec,利用它能够高效的训练出词向量. 作者&编辑 | 小Dream哥 1 word ...
- 计算机视觉:基于眼疾分类数据集iChallenge-PM图像分类经典模型剖析(LeNet,AlexNet,VGG,GoogLeNet,ResNet)
计算机视觉:图像分类经典模型 LeNet AlexNet VGG GoogLeNet ResNet 图像分类是根据图像的语义信息对不同类别图像进行区分,是计算机视觉的核心,是物体检测.图像分割.物体跟 ...
- 深度学习方法(五):卷积神经网络CNN经典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 关于卷积神经网络CNN,网络和文献 ...
- CNN的几种经典模型
本文主要介绍一下CNN的几种经典模型比较.之前自己也用过AlexNet和GoogleNet,网络上关于各种模型的介绍更是形形色色,自己就想着整理一下,以备自己以后查阅方便 LeNet5 先放一张图,我 ...
- 中文巨量模型“源1.0”:模型结构与生成效果解析
浪潮人工智能研究院 "源 1.0"自 2021 年 9 月底发布以来收获了广泛的关注.其参数量达 2457 亿,超越美国 OpenAI 组织研发的 GPT-3."源 1. ...
最新文章
- sencha touch Model validations 自定义验证 二选一输入验证、重复验证、时间验证、比较验证、条件验证(2015-1-14)...
- 图解计算机图形学三维变换算法
- OAuth2.0在项目中认证流程介绍
- 分布式系统原理 之5 日志技术
- python自动化开发_python自动化开发-2
- Dart 7-Day
- 11.4. String 字符串处理
- WTA (winner-take-all) 与 自组织映射 SOM (self organizing map)的理解
- Jquery 1.4.2 animate的BUG
- django连接mysql
- 微信小程序傻瓜制作_从15款工具中精选出4款,最靠谱的微信小程序制作软件!...
- RHEL7CentOS7 精简操作指令
- Win10怎么提高显卡游戏性能
- 拦截图片代码 精易web浏览器_精易Web浏览器 UChk验证源码
- iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 3306 -j DNAT --to-destinatio
- 两码一号(四):蚂蚁产品大盘
- php 微信模拟登陆给用户发送消息(文字,图片,图文)
- MacBook Pro 15寸 Late 2013 更换2TB NVME硬盘利用Big Sur完美修复睡眠唤醒及开机时长问题
- CTR --- NFM论文阅读笔记,及tf2复现
- VScode seting.json 配置 自用