ctc decoder
本文主要对CTC 原理及实现中的代码进行解释。
1.np.random.seed(1111)
请参见本专栏文章numpy中random.seed()的妙用
2.softmax的实现
代码是这样的:
def softmax(logits):max_value = np.max(logits, axis=1, keepdims=True)exp = np.exp(logits - max_value)exp_sum = np.sum(exp, axis=1, keepdims=True)dist = exp / exp_sumreturn dist
很多人包括我一开始对减掉max_value不知其解,觉得没有意义,毕竟
可以看出,两者其实是等价的,当初就这个问题我特意问了作者softmax和序列最大值无关,大意是这样:
因为 ,当
过大时,很容易导致
overflow,所以为了数值稳定性就需要保持输入不是那么大,一个比较不错的方法就是减掉
,很明显
至于会不会underflow则留待以后再讨论吧。
3.logSumExp()的作用
有很多代码用到了logSumExp(),其作用用数学公式可以表达为:
在CTC实现代码中的一些图形化解释中分析了beam decode中logY = np.log(y)的作用,那么在prefix beam decode中,关键的数学步骤也可以这样简化:
假设有两条路径的概率分别为 ,
,其中经过many-to-one map后
和
的路径相同,且
和
相同,那么两条路径可以化为一条路径,总概率为:
那么求对数后变为:
那么问题就变为求解 的问题,这里就使用一个技巧:
其作用大体就是这么回事,用于将不同路径合在一起.举例来说:
newProbabilityNoBlank = logSumExp(newProbabilityNoBlank, probabilityNoBlank + p)
这里newProbabilityNoBlank大致相当于 ,probabilityNoBlank 相当于
,p相当于
.
以下是三种ctc decoder的比较,实现代码在我的github里compareCTCDecoder
4.greedy search
代码为:
rawRs = np.argmax(y, axis=1)
maxNumber = y[xrange(y.shape[0]), rawRs]
score = np.multiply.accumulate(maxNumber)[-1]
rs = removeBlank(rawRs, black)
return rawRs, rs, score
基本原理就是将每个时间 内最大概率的
取出即可。
下面通过一个例子来阐述:
的分布如下:

图片1 y分布
那么greedy search的结果为:

例如当 时,在序列
中得到最大概率为0.4,依次找到各时间内的最大概率即可。
5.beam search
代码为:
T, V = y.shape
logY = np.log(y)beam = [([], 0)]
for t in range(T): # for every timestepnewBeam = []for prefix, score in beam:for i in range(V): # for every statenewPrefix = prefix + [i]# log(a * b) = log(a) + log(b)newScore = score + logY[t, i]newBeam.append((newPrefix, newScore))# sort by the scorenewBeam.sort(key=lambda x: x[1], reverse=True)beam = newBeam[:beamSize]
return beam
基本原理是通过 中
个序列,每个序列分别连接
中
个节点,得到
个新序列及对应的score,然后按照score从大到小的顺序选出前
个序列,依次推进即可。
这里先分析下代码,注意有这么一句代码:
logY = np.log(y)
为什么要先进行对数呢,这其实是一个防止underflow的技巧。
因为最终得到的概率的形式是 ,而
,所以如果非常多的小数连乘,到具体的数值计算步骤中,会导致underflow,概率直接为0了,所以使用下面的技巧
改乘为加可以完美的解决这个问题。
我调用的代码是:
print ('beam decode:')
beam = beamDecode(y, beamSize=2)
for string, score in beam:print ('\tB(%s) = %s, score is %.4f' % (string, removeBlank(string), np.exp(score)))
这里,设置 为2,这是具体的执行步骤:
5.1

只会将两个最大的节点放进路劲中去。
5.2
这里每个路径都会和下一个时间点组成新的路径,因此一共有 个新路径
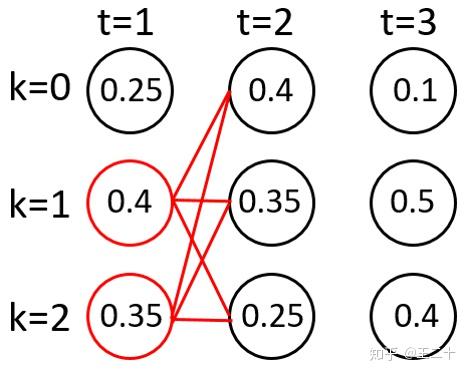
根据score取得最大的两个路径(次大的两个路径相等,这里舍弃掉一个)(感谢评论提醒,程序选的是另外一条,当初忘了看了)

5.3
新的路径也有6条
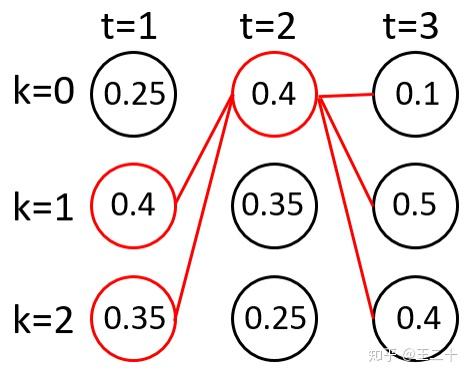
根据score取得最大的两个路径

最终会得到两条路径,在程序里打印出来的结果为:
# B([1, 0, 1]) = [1, 1], score is 0.0800
# B([1, 1, 1]) = [1], score is 0.0700
可以看出,分析和程序运行的结果是一致的。
6.prefix beam search
代码基本脉络与beam search一致,最主要的一方面是基于如下的考虑:
有许多不同的路径在many-to-one map的过程中是相同的,但beam search却会将一部分舍去,这导致了很多有用的信息被舍弃了。
比如 中,
和
经过many-to-one map后相同,虽然两者的概率都不高,但两者加起来的概率很高,如果忽略这一点而直接舍弃掉他们是很不明智的一种做法。这种朴素的想法就催生了prefix beam search。基本的思想是将记录prefix的时候不在记录raw sequence,而是记录去掉blank和duplicate(具体步骤较复杂,会同时保留duplicate的和没duplicate得序列)。
具体较复杂,不过读者弄懂beam search后再想想prefix beam search的流程不是很难,主要弄懂probabilityWithBlank和probabilityNoBlank分别代表最后一个字符是空格和最后一个字符不是空格的概率即可。
有个小伙伴表示这里看不懂,抱歉也没时间弄图了,这里解释一下吧。
令*表示任意字符串(经过many-to-one map后的),比如 ,这里
表示Blank,那么这里的*特指尾部是Blank的*,表示为
,即
。同理
。
那么任意字符串*与一个新的字符结合有多少种情况呢,一共有这样5种情况(为了简便,令*最后一个字符为 ):
弄懂了这5种情况的意思应该就明白了。
6.1 probabilityWithBlank和probabilityNoBlank
大致思想就是将每个路径的情况分为尾部为blank和尾部不为blank的情况,例如,当t=2时,many-to-one map后为[1]的序列有三种:[1,0],[0,1],[1,1],其中[1,0]是尾部待blank的情况,[0,1]和[1,1]的情况,为了说明这有什么用,那么假设t=3时label为1,那么新的序列就两者情况:
1.[1,0]+[1]=[1,0,1]->[1,0,1]
2.[0,1]+[1]=[0,1,1]->[1]
3.[1,1]+[1]=[1,1,1]->[1]
后两者是新的尾部不为blank的序列,可见尾部不为blank在新序列产生的时候是可以算作一种情况的,这就是为什么要分为blank和尾部不为blank的情况.
6.2 keep current prefix的作用
有一段代码开始也是困扰了我很久:
# keep current prefix
if i == endT:newProbabilityWithBlank, newProbabilityNoBlank = newBeam[prefix]newProbabilityNoBlank = logSumExp(newProbabilityNoBlank, probabilityNoBlank + p)newBeam[prefix] = (newProbabilityWithBlank, newProbabilityNoBlank)
后来我想明白了,这是因为beam中prefix的最后一个label并不一定是many-to-one map之前的label,换言之,many-to-one map之前,最后一个label是blank,比如下面的情况:
1.[1,0]
2.[0,1]
经过many-to-one map后都为[1],如果t=3,那么新的序列第一种情况应该是[1,1],第二种情况是[1],这就对应了一个是keep current prefix,一个加了新的label进来.
7.三种decode的比较
直接上结果吧。
将所有路径都打印出来再统计的结果为raw decode,结果显示top path为string=(2, 1) score=0.2185。
greedy decode的结果是[1, 1],score is 0.0800,与raw decode结果不符,可以看到这个算法的局限性。
beam decode的结果是[1, 1], score is 0.0800,与raw decode结果不符,可以看到这个算法的局限性。
prefix beam decode的结果是[1, 2], score is 0.1200,与raw decode的结果相符,可以已经完美考虑到路径many-to-one map后相同的情况,推荐优先使用这种算法。至于score不同的原因,即prefix beam decode的score is 0.1200,和raw decde的0.2185有些许差距,编程发现,这其实是一个小问题,因为我把beamSize设为2了,将其设为3就能得到0.2185的score了.
8.我对decode方法的理解
在计算机领域我认为大部分的算法的出发点都是在降低时间复杂度,甚至为此会提高一点空间复杂度。从时间复杂度的角度思考decode方法能带给我们不一样的思考方式。
CTC的输入是维度0大小为时间 、维度1大小为字符集大小C+1的二维矩阵,那么一个时间复杂度最高的decode方法是什么呢?对每条路径进行解码,经过many-to-one map后把相同的路径概率相加,最后取最高概率的路径即可。这种路径有
条,每条路径要计算
次乘法,即时间复杂度为
,这个时间复杂度是不能忍的。
greedy search因为只选取最高的那个路径,路径只有1条,即时间复杂度为 ,这个时间复杂度是最少的。但是因为没有考虑到many-to-one map的操作,所以一般认为这个search用处不大(虽然在项目中我发现greedy search和没有字典加持的prefix beam search的效果是一样的)。另外一个不好的地方在于这种search方法不支持字典。
而beam search因为每次都是选取条路径,所以时间复杂度为
(我是这么算的,
,一个需要考虑的点在于得到
条路径后需要使用排序法得到score排名最高的前
条路径,当然,严格来说,排序时间复杂度可以减少到
)。这个复杂度还是可以接受的。
prefix beam search的时间复杂度比较复杂,我认为时间消耗和beam search相近,不同的在于将merge beam的过程不一样,而且这个merge算法不一样消耗时间也不同,所以时间复杂度也是 。
【已完结】
参考文献:https://zhuanlan.zhihu.com/p/39266552
ctc decoder相关推荐
- 超详细讲解CTC理论和实战
CTC理论和实战 CTC简介 CTC算法详解 对齐 损失函数 预测 CTC算法的特性 条件独立 对齐 使用CTC进行变长验证码识别 问题描述和解决方法 安装WarpCTC 得到tensorflow源代 ...
- 完美解释:wenet-流式与非流式语音识别统一模型
Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition[1] ,本文以该篇论文为主线, ...
- TensorFlow实现语音识别
整体介绍: 环境python3.6+TensorFlow1.12 显卡是英伟达GTX1070(后头换个好些的显卡)训练了四天四夜 主要技术点CTC,BRNN,MFCC特征,全连接神经网络 CTC时序 ...
- 【NLP】自然语言处理学习笔记(一)语音识别
前言 本笔记参考的课程是李宏毅老师的自然语言处理 课程Link:https://aistudio.baidu.com/aistudio/education/lessonvideo/1000466 To ...
- NVIDIA NeMo学习笔记
NeMo可以做以下三个方面的事情: Automatic Speech Recognition (ASR):声纹识别 Natural Language Processing (NLP):自然语言处理 T ...
- Beam Search与Prefix Beam Search的理解与python实现
引言 Beam search是一种动态规划算法,能够极大的减少搜索空间,增加搜索效率,并且其误差在可接受范围内,常被用于Sequence to Sequence模型,CTC解码等应用中 时间复杂度 对 ...
- TensorFlow入门教程(19)语音识别(下)
# #作者:韦访 #博客:https://blog.csdn.net/rookie_wei #微信:1007895847 #添加微信的备注一下是CSDN的 #欢迎大家一起学习 # 16.Bi-RNN网 ...
- 【飞桨PaddleSpeech语音技术课程】— 语音识别-Transformer
使用 Transformer 进行语音识别 0. 视频理解与字幕 # 下载demo视频 !test -f work/source/subtitle_demo1.mp4 || wget -c https ...
- 【飞桨PaddleSpeech语音技术课程】— 语音识别-Deepspeech2
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码) 语音识别--DeepSpeech2 0. 视频理解与字幕 # 下载demo视频 !test -f work/sour ...
- 全卷积网络用于手语识别
Fully Convolutional Networks for Continuous Sign Language Recognition 年份 识别类型 输入数据类型 手动特征 非手动特征 Full ...
最新文章
- 345 所开设人工智能本科专业高校名单大全
- 从0梳理1场CV缺陷检测赛事!
- MYSQL数据库——mysql的数据类型和运算符
- 数字数据fzu 2120 数字排列
- python.集合转列表_Python基础数据类型:元组、列表、字典、集合
- android中shape的属性,android中shape的属性
- ssl初一组周六模拟赛【2018.4.7】
- 前端学习(2697):重读vue电商网站18之监听图片删除事件
- es6 filter函数的用法_Python 函数式编程指北,不只是面向对象哦!超级详细!
- 如何在XSLT中将字符串转换为大写或小写形式
- 在一个行业做,一定要打造自己的品牌IP
- python识别颜色1007python识别颜色_python读取word文档识别字段颜色,解析字段
- State Processor API:如何读取,写入和修改 Flink 应用程序的状态
- CSS半透明磨砂效果实现
- 遗传算法原理与matlab,有关路径优化遗传算法原理(结合matlab代码)
- 2016-2017 ACM-ICPC, Egyptian Collegiate Programming Contest (ECPC 16) 题解
- pimple学习(1)pimple的使用
- Sencha Touch(Extjs)
- Vmware安装MacOS系统
- 语义分割之 标签生成