python实现数据爬取-清洗-持久化存储-数据平台可视化
基于python对淘宝模特个人信息进行筛选爬取,数据清洗,持久化写入mysql数据库.使用django对数据库中的数据信息筛选并生成可视化报表进行分析。
数据爬取,筛选,存库:
# -*- coding:utf-8 -*-import requests
from bs4 import BeautifulSoup
import sys
import re
reload(sys)
sys.setdefaultencoding('utf-8')
import MySQLdb
import chardetconn= MySQLdb.connect(host='localhost',port = 数据库端口,user='root',passwd='数据库密码db ='xxnlove',charset='utf8')
cur = conn.cursor()
cur.execute("create table model(name text(225),age varchar(10),blood varchar(10),school text(225),height varchar(10),weight varchar(10),Measurements text(225),cup varchar(20),location text(225))ENGINE=InnoDB DEFAULT CHARSET=utf8;")#CREATE DATABASE gmtdb DEFAULT CHARACTER SET utf8mb4;
for num in range(521,1314):try:URL = 'http://mm.taobao.com/json/request_top_list.htm?page=%d' % num#print "现在爬取的网站url是:" + URLresponse = requests.get(URL) response.encoding = 'gb2312'text = response.text soup = BeautifulSoup(text, 'lxml') for model in soup.select(".list-item"):try:model_id = model.find('span', {'class': 'friend-follow J_FriendFollow'})['data-userid']json_url = "http://mm.taobao.com/self/info/model_info_show.htm?user_id=%d" % int(model_id)response_json = requests.get(json_url)response_json.encoding = 'gb2312'text_response_json = response_json.textsoup_json = BeautifulSoup(text_response_json, 'lxml')#print "***********************************" + model.find('a', {'class': 'lady-name'}).string + "*********************************"#print "模特的名字:" + model.find('a', {'class': 'lady-name'}).stringname = model.find('a', {'class': 'lady-name'}).string#print "模特的年龄:"+ model.find('p', {'class': 'top'}).em.strong.stringage = model.find('p', {'class': 'top'}).em.strong.stringblood = soup_json.find_all('li', {'class': 'mm-p-cell-right'})[1].span.string # if blood is None:# blood = "None"school = soup_json.find_all('li')[5].span.stringheight = soup_json.find('li', {'class': 'mm-p-small-cell mm-p-height'}).p.stringweight = soup_json.find('li', {'class': 'mm-p-small-cell mm-p-weight'}).p.stringMeasurements = soup_json.find('li', {'class': 'mm-p-small-cell mm-p-size'}).p.stringlocation = model.find('p', {'class': 'top'}).span.stringcup = soup_json.find('li', {'class': 'mm-p-small-cell mm-p-bar'}).p.stringsqli="insert into model values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"cur.execute(sqli,(name,age,blood,school,height,weight,Measurements,cup,location))#print "罩杯:" + soup_json.find('li', {'class': 'mm-p-small-cell mm-p-bar'}).p.string'''print "生日:" + soup_json.find('li', {'class': 'mm-p-cell-left'}).span.stringblood = soup_json.find_all('li', {'class': 'mm-p-cell-right'})[1].span.stringif blood is None:blood = "无"print "血型:" + bloodprint "学校/专业:" + soup_json.find_all('li')[5].span.stringprint "身高:" + soup_json.find('li', {'class': 'mm-p-small-cell mm-p-height'}).p.stringprint "体重:" + soup_json.find('li', {'class': 'mm-p-small-cell mm-p-weight'}).p.stringprint "三围:" + soup_json.find('li', {'class': 'mm-p-small-cell mm-p-size'}).p.stringprint "罩杯:" + soup_json.find('li', {'class': 'mm-p-small-cell mm-p-bar'}).p.stringprint "鞋码:" + soup_json.find('li', {'class': 'mm-p-small-cell mm-p-shose'}).p.stringprint "模特所在地:"+ model.find('p', {'class': 'top'}).span.stringprint "模特的id:"+ model.find('span', {'class': 'friend-follow J_FriendFollow'})['data-userid']print "模特的标签:"+ model.find_all('p')[1].em.stringprint "模特的粉丝数:"+ model.find_all('p')[1].strong.stringprint "模特的排名:"+ [text for text in model.find('div', {'class': 'popularity'}).dl.dt.stripped_strings][0]print model.find('ul', {'class': 'info-detail'}).get_text(" ",strip=True)print "模特的个人资料页面:" +"http:"+ model.find('a', {'class': 'lady-name'})['href'] print "模特的个人作品页面:" +"http:"+ model.find('a', {'class': 'lady-avatar'})['href']print "模特的个人头像:" + "http:" + model.find('img')['src']print "***********************************" + model.find('a', {'class': 'lady-name'}).string + "*********************************"print "\n"'''except:print "error"except:print num + "page is error"
cur.close()
conn.commit()
conn.close()数据库结构:
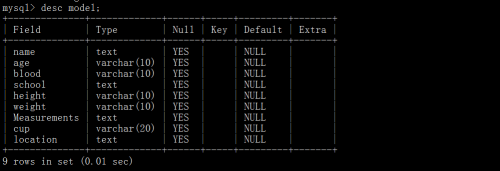
写入数据库中的模特记录数量:

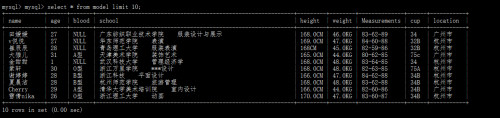
写入数据库中模特信息部分图:
django 实现图表展示:
#coding:utf-8
# Create your views here.
from django.shortcuts import render,render_to_response
from django.http import HttpResponse,HttpResponseRedirect
import MySQLdb
import sys
import re
import json
import jieba
from operator import itemgetter
from pytagcloud import create_tag_image, make_tags
import random
import time
import smtplib
from email.mime.text import MIMEText
reload(sys)
sys.setdefaultencoding('utf-8')
conn= MySQLdb.connect(host='localhost',port = 端口,user='root',passwd='密码',db ='xxnlove',charset='utf8')
def receive_message(request):if request.method == 'POST':name = request.POST['name']email = request.POST['email']subject = request.POST['subject']message = request.POST['message']cur = conn.cursor()sql = "insert into message values(%s,%s,%s,%s)"cur.execute(sql,(name,email,subject,message))cur.close()conn.commit()conn.close() return render_to_response('index.html') def send_email(request):_user = "961769710@qq.com"_pwd = "**************"_to = "961769710@qq.com"msg = MIMEText("Test")msg["Subject"] = "don't panic"msg["From"] = _usermsg["To"] = _totry:s = smtplib.SMTP_SSL("smtp.qq.com", 465)s.login(_user, _pwd)s.sendmail(_user, _to, msg.as_string())s.quit()return HttpResponse("邮件发送成功")except smtplib.SMTPException,e:return HttpResponse("Falied,%s"%e )def create_pictures(request):cur = conn.cursor()sql = "select school from model "cur.execute(sql)rows = cur.fetchall()cur.close()conn.commit()conn.close()fclist = []for row in rows:fclist.append(row[0].encode("utf-8"))fcstr = " ".join(fclist)wg = jieba.cut_for_search(fcstr)wd = {}nonsense = [u"我的", u"什么", u"你好"]for w in wg:if len(w) < 2:continueelif w in nonsense:continuetry:str(w)continuefinally:if w not in wd:wd[w] = 1else:wd[w] += 1swd = sorted(wd.iteritems(), key=itemgetter(1), reverse=True)swd = swd[1:100]tags = make_tags(swd,maxsize = 100)create_tag_image(tags,'./modles/static/1.jpg',#background=(0, 0, 0, 255),size=(500, 300),fontname="STKAITI")
# cur.close()
# conn.commit()
# conn.close()return render(request,'index.html')def cloud(request):return render(request,'cloud.html')def index(request):return render(request,'index.html')def search(request):if request.method == 'POST':modelname = request.POST['name'] sql = "select * from model where name='%s'" % modelnamecur = conn.cursor()try:search = cur.execute(sql)info = cur.fetchmany(search)name = info[0][0]age = info[0][1]school = info[0][3]school = ''.join(school.split())height = info[0][4]weight = info[0][5]Measurements = info[0][6]return render(request, 'index.html', {'name': name,'age': age,'school':school,'height':height,'weight':weight,'Measurements':Measurements})except:prompt = "sorry: 数据库中没有 "+modelname+" 这个模特的信息"return render(request, 'index.html', {'prompt': prompt})cur.close()conn.commit()conn.close()else:return HttpResponse('提交的方式不是post')def show(request):cur = conn.cursor()agedata = []category = []for i in range(10,40):category.append(i)age = isql = "select count(*) from model where age='%s'" % ageage = cur.execute(sql)i = int(cur.fetchmany(age)[0][0])agedata.append(i)return render(request,'show.html',{'category':category,'agedata':agedata})cur.close()conn.commit()conn.close()
def area(request):cur = conn.cursor()citydict = {'jianxi':'南昌市|赣州市|上饶市|吉安市|九江市|新余市|抚>州市|宜春市|景德镇市|萍乡市|鹰潭市|江西','beijin':'北京','guangdong':'东莞市|广州市|中山市|深圳市|惠州市|江门市|珠海市|汕头市|佛山市|湛江市|河源市|肇庆市|清远市|潮州市|韶关市|揭阳市|阳江市|梅州市|云浮市|茂名市|汕尾市|广东','shandong':'济南市|青岛市|临沂市|济宁市|菏泽市|烟台市|淄博市|泰安市|潍坊市|日照市|威海市|滨州市|东营市|聊城市|德州市|莱芜市|枣庄市|山东','jiangsu':'苏州市|徐州市|盐城市|无锡市|南京市|南通市|连云港市|常州市|镇江市|扬州市|淮安市|泰州市|宿迁市', 'henan':'郑州市|南阳市|新乡市|安阳市|洛阳市|信阳市|平顶山市|周口市|商丘市|开封市|焦作市|驻马店市|濮阳市|三门峡市|漯河市|许昌市|鹤壁市|济源市|河南','shanghai':'松江区|宝山区|金山区|嘉定区|南汇区|青浦区|>浦东新区|奉贤区|徐汇区|静安区|闵行区|黄浦区|杨浦区|虹口区|普陀区|闸北区|长宁区|崇明县|卢湾区|上海','hebei': '石家庄市|唐山市|保定市|邯郸市|邢台市|河北区|沧州市|秦皇岛市|张家口市|衡水市|廊坊市|承德市|河北','zhejiang':'温州市|宁波市|杭州市|台州市|嘉兴市|金华市|>湖州市|绍兴市|舟山市|丽水市|衢州市|浙江','shanxi':'西安市|咸阳市|宝鸡市|汉中市|渭南市|安康市|榆>林市|商洛市|延安市|铜川市|陕西','hunan':'长沙市|邵阳市|常德市|衡阳市|株洲市|湘潭市|永州市|岳阳市|怀化市|郴州市|娄底市|益阳市|张家界市|湘西州|湖南', 'chongqing':'江北区|渝北区|沙坪坝区|九龙坡区|万州区|永川市|南岸区|酉阳县|北碚区|涪陵区|秀山县|巴南区|渝中区|石柱县|忠县|合川市|大渡口区|开县|长寿区|荣昌县|云阳县|梁平县|潼南县|江津市|彭水县|綦江县|璧山县|黔江区|大足县|巫山县|巫溪县|垫江县|丰都县|武隆县|万盛区|铜梁县|南川市|奉节县|双桥区|城口县|重庆','fujian':'漳州市|厦门市|泉州市|福州市|莆田市|宁德市|三明市|南平市|龙岩市|福建','tianjin':'和平区|北辰区|河北区|河西区|西青区|津南区|东丽区|武清区|宝坻区|红桥区|大港区|汉沽区|静海县|塘沽区|宁河县|蓟县|南开区|河东区|天津','yunnan':'昆明市|红河州|大理州|文山州|德宏州|曲靖市|昭通市|楚雄州|保山市|玉溪市|丽江地区|临沧地区|思茅地区|西双版纳州|怒江州|迪庆州|云南','sichuan':'成都市|绵阳市|广元市|达州市|南充市|德阳市|广安市|阿坝州|巴中市|遂宁市|内江市|凉山州|攀枝花市|乐山市|自贡市|泸州市|雅安市|宜宾市|资阳市|眉山市|甘孜州|四川','guangxi':'贵港市|玉林市|北海市|南宁市|柳州市|桂林市|梧州市|钦州市|来宾市|河池市|百色市|贺州市|崇左市|防城港市|广西','anhui':'安徽|芜湖市|合肥市|六安市|宿州市|阜阳市|安庆市|马鞍山市|蚌埠市|淮北市|淮南市|宣城市|黄山市|铜陵市|亳州市|池州市|巢湖市|滁州市','hainan':'三亚市|海口市|琼海市|文昌市|东方市|昌江县|陵水县|乐东县|保亭县|五指山市|澄迈县|万宁市|儋州市|临高县|白沙县|定安县|琼中县|屯昌县|海南','jiangxi':'南昌市|赣州市|上饶市|吉安市|九江市|新余市|抚州市|宜春市|景德镇市|萍乡市|鹰潭市|江西','hubei':'武汉市|宜昌市|襄樊市|荆州市|恩施州|黄冈市|孝感市|十堰市|咸宁市|黄石市|仙桃市|天门市|随州市|荆门市|潜江市|鄂州市|神农架林区|湖北','shanxi2':'太原市|大同市|运城市|长治市|晋城市|忻州市|临汾市|吕梁市|晋中市|阳泉市|朔州市|山西','liaoning':'大连市|沈阳市|丹东市|辽阳市|葫芦岛市|锦州市|朝阳市|营口市|鞍山市|抚顺市|阜新市|盘锦市|本溪市|铁岭市|辽宁','taiwan':'台北市|高雄市|台中市|新竹市|基隆市|台南市|嘉义市|台湾','heilongjiang':'齐齐哈尔市|哈尔滨市|大庆市|佳木斯市|双鸭山市|牡丹江市|鸡西市|黑河市|绥化市|鹤岗市|伊春市|大兴安岭地区|七台河市|黑龙江','neimenggu':'赤峰市|包头市|通辽市|呼和浩特市|鄂尔多斯市|乌海市|呼伦贝尔市|兴安盟|巴彦淖尔盟|乌兰察布盟|锡林郭勒盟|阿拉善盟|内蒙古','guizhou':'贵阳市|黔东南州|黔南州|遵义市|黔西南州|毕节地区|铜仁地区|安顺市|六盘水市','gansu':'兰州市|天水市|庆阳市|武威市|酒泉市|张掖市|陇南地区|白银市|定西地区|平凉市|嘉峪关市|临夏回族自治州|金昌市|甘南州|甘肃','qinghai':'西宁市|海西州|海东地区|海北州|果洛州|玉树州|黄南藏族自治州|青海','xinjiang':'乌鲁木齐市|伊犁州|昌吉州|石河子市|哈密地区|阿克苏地区|巴音郭楞州|喀什地区|塔城地区|克拉玛依市|和田地区|阿勒泰州|吐鲁番地区|阿拉尔市|博尔塔拉州|五家渠市|克孜勒苏州|图木舒克市|新疆','xizang':'拉萨市|山南地区|林芝地区|日喀则地区|阿里地区|昌都地区|那曲地区|西藏','jiling':'吉林市|长春市|白山市|延边州|白城市|松原市|辽源市|通化市|四平市|吉林','ningxia':'银川市|吴忠市|中卫市|石嘴山市|固原市|宁夏'}numdict = {}for key in citydict :sql = "select count(*) from model where location REGEXP '%s'" % citydict[key]city = cur.execute(sql)num = int(cur.fetchmany(city)[0][0])numdict[key] = numreturn render(request, 'area.html',{'jianxi':numdict['jianxi'],'beijin':numdict['beijin'],'guangdong':numdict['guangdong'],'shandong':numdict['shandong'],'jiangsu':numdict['jiangsu'],'henan':numdict['henan'],'shanghai':numdict['shanghai'],'hebei':numdict['hebei'],'zhejiang':numdict['zhejiang'],'shanxi':numdict['shanxi'],'hunan':numdict['hunan'],'chongqing':numdict['chongqing'],'fujian':numdict['fujian'],'tianjin':numdict['tianjin'],'yunnan':numdict['yunnan'],'sichuan':numdict['sichuan'],'guangxi':numdict['guangxi'],'anhui':numdict['anhui'],'hainan':numdict['hainan'],'jiangxi':numdict['jiangxi'],'hubei':numdict['hubei'],'shanxi2':numdict['shanxi2'],'liaoning':numdict['liaoning'],'taiwan':numdict['taiwan'],'heilongjiang':numdict['heilongjiang'],'neimenggu':numdict['neimenggu'],'guizhou':numdict['guizhou'],'gansu':numdict['gansu'],'qinghai':numdict['qinghai'],'xinjiang':numdict['xinjiang'],'xizang':numdict['xizang'],'jiling':numdict['jiling'],'ningxia':numdict['ningxia']}){% load staticfiles %}
<!DOCTYPE html>
<html>
<head> <meta charset="utf-8"> <title>Charts demo</title> <script src="{% static "js/echarts.js" %}"></script><script src="{% static "js/china.js" %}"></script><script src="https://code.jquery.com/jquery-3.1.1.min.js"></script></head>
<body> <div id="main" style="height:600px;"></div> <script type="text/javascript"> var myChart = echarts.init(document.getElementById('main')); option = {title : {text: '淘宝模特所在省份分部情况',subtext: '',x:'center'},tooltip : {trigger: 'item'},legend: {orient: 'vertical',x:'left',data:['']},dataRange: {min: 0,max: 2500,x: 'left',y: 'bottom',text:['高','低'], // 文本,默认为数值文本calculable : true},toolbox: {show: true,orient : 'vertical',x: 'right',y: 'center',feature : {mark : {show: true},dataView : {show: true, readOnly: false},restore : {show: true},saveAsImage : {show: true}}},roamController: {show: true,x: 'right',mapTypeControl: {'china': true}},series : [{name: '人数',type: 'map',mapType: 'china',roam: false,itemStyle:{normal:{label:{show:true}},emphasis:{label:{show:true}}},data:[{name: '北京',value: {{ beijin }}},{name: '江西',value: {{ jianxi }}},{name: '广东',value: {{ guangdong }}},{name: '山东',value: {{ shandong }}},{name: '江苏',value: {{ jiangsu }}},{name: '河南',value: {{ henan }}},{name: '上海',value: {{ shanghai }}},{name: '河北',value: {{ hebei }}},{name: '浙江',value: {{ zhejiang }}},{name: '陕西',value: {{ shanxi }}},{name: '湖南',value: {{ hunan }}},{name: '重庆',value: {{ chongqing }}},{name: '福建',value: {{ fujian }}},{name: '天津',value: {{ tianjin }}},{name: '云南',value: {{ yunnan }}},{name: '四川',value: {{ sichuan }}},{name: '广西',value: {{ guangxi }}},{name: '安徽',value: {{ anhui }}},{name: '海南',value: {{ hainan }}},{name: '江西',value: {{ jiangxi }}},{name: '湖北',value: {{ hubei }}},{name: '山西',value: {{ shanxi2 }}},{name: '辽宁',value: {{ liaoning }}},{name: '台湾',value: {{ taiwan }}},{name: '黑龙江',value: {{ heilongjiang }}},{name: '贵州',value: {{ guizhou }}},{name: '甘肃',value: {{ gansu }}},{name: '青海',value: {{ qinghai }}},{name: '新疆',value: {{ xinjiang }}},{name: '西藏',value: {{ xizang }}},{name: '吉林',value: {{ jiling }}},{name: '宁夏',value: {{ ningxia }}},{name: '内蒙古',value: {{ neimenggu }}},]}]};myChart.setOption(option); </script> </body>
</html>{% load staticfiles %}
<!DOCTYPE html>
<head><meta charset="utf-8"><title>动态数据展示</title>
</head>
<body><!-- 为ECharts准备一个具备大小(宽高)的Dom --><div id="main" style="height:400px"></div><!-- ECharts单文件引入 --><script src="http://echarts.baidu.com/build/dist/echarts.js"></script><script type="text/javascript">// 路径配置require.config({paths: {echarts: 'http://echarts.baidu.com/build/dist'}});// 使用require(['echarts','echarts/chart/bar' // 使用柱状图就加载bar模块,按需加载],function (ec) {// 基于准备好的dom,初始化echarts图表var myChart = ec.init(document.getElementById('main')); var option = {tooltip: {show: true},legend: {color:'#0000FF',data:['模特年龄']},xAxis : [{type : 'category',data : {{ category }}}],yAxis : [{type : 'value'}],series : [{"name":"模特年龄","type":"bar","data":{{ agedata }}}]};// 为echarts对象加载数据 myChart.setOption(option); });</script>
</body>网站首页:
提交的信息会写入数据库中:

模特年龄正态分布情况:
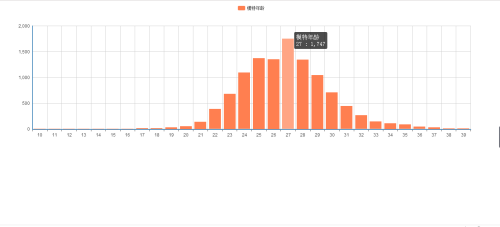
首先对信息进行分词处理,然后排序,选取出现频率最高的前100个词。

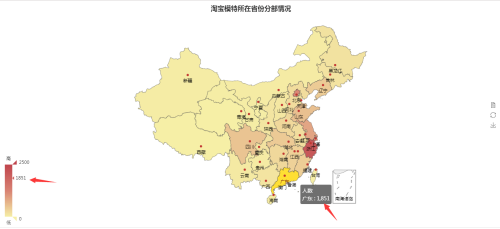
这个花了我很多时间,要解决echarts地图只精确到省或者直辖市,而我爬取到的数据可能是具体的某一个地方市名,针对这个问题:我首先找了一下各省下面的市都有哪些,sql语句使用正则匹配想要获取的信息。我创建了个字典存放省名和下属的市名。另外创建个字典存放省名和匹配到的人数。
简单小结:这里面涉及到的知识点还挺多的:
爬虫:我使用的requests和beautiful这俩库。
数据库:使用的是mysql,涉及到数据库编码,sql查询,模糊匹配,python对数据库的操作,中文显示乱码的问题。
词云:jieba进行分词,pytagcloud用来生成词云。
django:views、templates、static 、url,因为我用的MySQLdb,所以没有使用django自身的ORM(models),这样我觉得更灵活。
前端展示:bootstrap(主要用来做网站的布局)和echarts(进行图表展示和数据分析用)。
python实现数据爬取-清洗-持久化存储-数据平台可视化相关推荐
- python小记(3) | 爬取微博页面存储为html到本地提取关键词存入excel
目录 一.基本思路 二.代码详解 1. requests 2. urllib.parse urlencode() 3. re 4. 数据爬取存入文件夹 5. 关键词内容存入excel 三.问题记录 四 ...
- Python爬虫实战爬取租房网站2w+数据-链家上海区域信息(超详细)
Python爬虫实战爬取租房网站-链家上海区域信息(过程超详细) 内容可能有点啰嗦 大佬们请见谅 后面会贴代码 带火们有需求的话就用吧 正好这几天做的实验报告就直接拿过来了,我想后面应该会有人用的到吧 ...
- 【Python】批量爬取OSM建筑瓦片数据并整合为shp格式数据
目录 1 简介 2 效果展示 3 思路及代码 3 完整代码 4 一些说明 1 简介 最近在做一项课题,涉及到建筑足迹(Building footprints)数据.所以想看看现在比较常用的都有什么产品 ...
- 爬虫实战入门级教学(数据爬取->数据分析->数据存储)
爬虫实战入门级教学(数据爬取->数据分析->数据存储) 天天刷题好累哦,来一期简单舒适的爬虫学习,小试牛刀(仅供学习交流,不足之处还请指正) 文章讲的比较细比较啰嗦,适合未接触过爬虫的新手 ...
- Python爬虫04-xpath爬取豆瓣韩剧数据
xpath爬取豆瓣韩剧数据 需求:爬取豆瓣韩剧的标题.评分.评论以及详情页地址. 1.导入模块 import requests from lxml import etree import csv 2. ...
- 【Python爬虫】爬取公共交通站点数据
首先,先介绍一下爬取公交站点时代码中引入的库. requests:使用HTTP协议向网页发送请求并获得响应的库. BeautifulSoup:用于解析HTML和XML网页文档的库,简化了页面解析和信息 ...
- 大数据 爬取网站并分析数据
大数据+爬取前程无忧校园招聘+flume+hive+mysql+数据可视化 自己搭建的hadoop博客 1.爬取前程无忧网页和校园招聘 1.1用scrapy爬取前途无忧网站,我爬了10w多条数据,在存 ...
- 十年电影票房数据爬取与分析 | 免费数据教程
3月8日妇女节,我很期待的超级英雄电影<惊奇队长>上映了,票房表现很快过亿,但大众口碑却让人失望. 一个有趣且常见的现象是,隔壁获奖无数,口碑爆炸的<绿皮书>,票房却远远不如& ...
- 爬虫案例—京东数据爬取、数据处理及数据可视化(效果+代码)
一.数据获取 使用PyCharm(引用requests库.lxml库.json库.time库.openpyxl库和pymysql库)爬取京东网页相关数据(品牌.标题.价格.店铺等) 数据展示(片段): ...
最新文章
- CNN 究竟“看”到了什么?曲线检测器是否为可解释性带来了出路?
- P1801 黑匣子_NOI导刊2010提高(06)
- 虚函数和纯虚函数的区别
- Mysql带返回值与不带返回值的2种存储过程
- 了解如何使用Yii2 PHP框架创建YouTube克隆
- python求众数代码_python-LeetCode-求众数
- 第二届构建之法论坛预告(草案)
- 【安装教程】windows8.1 下安装ubuntu14.04 双系统
- Servlet 编写过滤器
- tempdb页面分配争用问题
- html5提供类似“JQuery”中操作类名的方法
- 自学c语言要下载什么软件下载,你学c语言用的什么app?
- vue组件 组件的继承extend
- 7-4 行为模式解析-摆脱被动和畏缩的行为模式,掌握职场主动权
- 计算机应用基础名词解释动画,《计算机应用基础》期末考试复习题库-名词解释题题库...
- 电路仿真软件详谈(九),proteus电路仿真软件及版本问题
- php使用qq登录api接口,QQ的账号登录及PHP api操作
- python提取发票信息发票识别_python 发票识别
- js截取某个字符串前面的内容
- 灰色模型代码GM(1,1),从excel导入数据,亦可导出数据到excel中。