【转载】深入理解L1、L2范数
原文链接:取个名字最难了 :https://blog.csdn.net/wj5637606/article/details/84582966
前言
说起L1、L2范数,大家会立马想到这是机器学习中常用的正则化方法,一般添加在损失函数后面,可以看作是损失函数的惩罚项。那添加L1和L2正则化后到底有什么具体作用呢?为什么会产生这样的作用?本篇博文将和大家一起去探讨L1范数、L2范数背后的原理。
先说结论
L1和L2的作用如下
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择;一定程度上可以防止过拟合
- L2正则化可以防止模型过拟合
理解L1范数
理解L1,主要需要理解两个问题。第一是L1产生稀疏矩阵的作用,第二是为什么L1可以产生稀疏模型。
稀疏模型与特征选择
稀疏矩阵指的是很多元素为0、只有少数元素是非零值的矩阵。以线性回归为例,即得到的线性回归模型的大部分系数都是0,这表示只有少数特征对这个模型有贡献,从而实现了特征选择。总而言之,稀疏模型有助于进行特征选择。
为什么L1正则化能产生稀疏模型?
这部分重点讨论为什么L1可以产生稀疏模型,即L1是怎么让系数等于0的。首先要从目标函数讲起,假设带有L1正则化的损失函数如下:
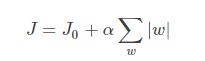
其中J0J_0J0是损失函数,后边是L1正则化项,α\alphaα是正则化系数,www是模型的参数。现在我们的目标是求解argmaxw(J)\arg\max_{w}(J)argmaxw(J),换句话说,我们的任务是在L1的约束下求出J0取最小值的解。假设只考虑二维的情况,即只有两个权值w1w^1w1 和 w2w^2w2,此时的L1正则化公式即为:L1=∣w1∣+∣w2∣L1=|w^1| + |w^2|L1=∣w1∣+∣w2∣。对J使用梯度下降法求解,则求解J0J_0J0的过程可以画出等值线,同时L1正则化的函数也可以在二维平面上画出来。如下图:
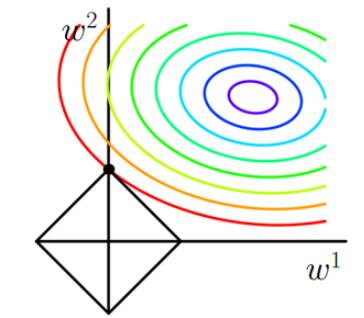
图1 L1正则化
图中等值线是J0J_0J0的等值线,黑色方形是L1L_1L1函数的图形,J0J_0J0等值线与L1L_1L1图形首次相交的地方就是最优解,我们很容易发现黑色方形必然首先与等值线相交于方形顶点处。可以直观想象,因为L1L_1L1函数有很多"突出的角"(二维情况下有四个,多维情况下更多),J0J_0J0与这些角接触的概率远大于与其它部分接触的概率。而这些点某些维度为0(以上图为例,交点处w1w^1w1为0),从而会使部分特征等于0,产生稀疏模型,进而可以用于特征选择。
理解L2范数
为什么L2范数可以防止过拟合呢?
要想知道L2范数为什么可以防止过拟合,首先就要知道什么是过拟合。通俗讲,过拟合是指模型参数较大,模型过于复杂,模型抗扰动能力弱。只要测试数据偏移一点点,就会对结果造成很大的影响。因此,要防止过拟合,其中一种方法就是让参数尽可能的小一些。同L1范数分析一样,我们做出图像,如下图所示:
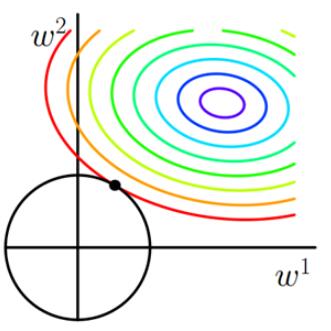
图2 L2正则化
二维平面下L2正则化的函数图形是个圆,与方形相比,没有突出的棱角。因此交点在坐标轴的概率很低,即使得w1w^1w1或W2W^2W2等于零的概率小了许多。由上图可知,L2中得到的两个权值倾向于均为非零的较小数。 这也就是L1稀疏、L2平滑的原因。
下面我从公式的角度解释一下,为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θ\thetaθ, h(x)h(x)h(x)是我们的model,那么LR的损失函数如下:
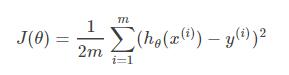
那么在梯度下降法中,最终用于迭代计算参数θ\thetaθ的迭代式为:
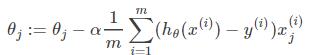
当对损失函数加上L2正则化以后,迭代公式会变成下面的样子:
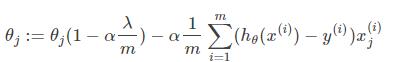
从上式可以看出,与未添加L2正则化的迭代公式相比,每一次迭代,θj\theta_jθj都要乘以一个小于1的因子,从而使得θj\theta_jθj不断减小,因此总的来看,θ\thetaθ是不断减小的。
总结
L1会趋向于产生少量的特征,而其它特征都是0。L2会选择更多的特征,这些特征都会趋近于0。L1在特征选择时非常有用,而L2只是一种防止过拟合的方法。在所有特征中只有少数特征起重要作用的情况下,选择L1范数比较合适,因为它能自动选择特征。而如果所有特征中,大部分特征都能起作用,而且起的作用很平均,那么使用L2范数也许更合适。
【转载】深入理解L1、L2范数相关推荐
- 浅谈L0,L1,L2范数及其应用
原文传送门:浅谈L0,L1,L2范数及其应用 浅谈L0,L1,L2范数及其应用 在线性代数,函数分析等数学分支中,范数(Norm)是一个函数,其赋予某个向量空间(或矩阵)中的每个向量以长度或大小.对于 ...
- 机器学习基础-23:矩阵理论(L0/L1/L2范数等)
机器学习基础-23:矩阵理论(L0/L1/L2范数等) 机器学习原理与实践(开源图书)-总目录,建议收藏,告别碎片阅读! 线性代数是数学的一个分支,广泛应用于科学和工程领域.线性代数和矩阵理论是机器学 ...
- 手推公式带你轻松理解L1/L2正则化
文章目录 前言 L1/L2正则化原理 从数学的角度理解L1/L2正则化 从几何的角度理解L1/L2正则化 L1/L2正则化使用情形 前言 L1/L2正则化的目的是为了解决过拟合,因此我们先要明白什么是 ...
- [转] L1 L2范数
作者:Andy Yang 链接:https://www.zhihu.com/question/26485586/answer/616029832 来源:知乎 著作权归作者所有.商业转载请联系作者获得授 ...
- 什么是范数(norm)?以及L1,L2范数的简单介绍
什么是范数? 范数,是具有"距离"概念的函数.我们知道距离的定义是一个宽泛的概念,只要满足非负.自反.三角不等式就可以称之为距离.范数是一种强化了的距离概念,它在定义上比距离多了一 ...
- 正则化与L0,L1,L2范数简介
参考:机器学习中的范数规则化之(一)L0.L1与L2范数 1. 常见的范数 1.1 L0 范数 向量中非零元素的个数,即稀疏度,适合稀疏编码,特征选择. 1.2 L1 范数 又叫曼哈顿距离或最小绝对误 ...
- L0,L1,L2范数
http://blog.csdn.net/zouxy09/article/details/24971995
- 超简单理解L0、L1、L2范数原理及作用
L0,L1,L2范数在机器学习中的应用个人理解 博文针对L0.L1.L2范数原理及在机器学习中作用进行了非常通俗易懂的解释,为博主了解相关概念后自我理解,相信对于看完本篇分析的读者来说对理解这几个范数 ...
- 机器学习中的范数规则化之L0、L1、L2范数
我的博客中参考了大量的文章或者别的作者的博客,有时候疏忽了并未一一标注,本着分享交流知识的目的,如果侵犯您的权利,这并非我的本意,如果您提出来,我会及时改正. 本篇博客主要是为了解决机器学习中的过拟合 ...
- 范数规则化(一):L0、L1与L2范数
目录 0 范数 1 L0 范数 2 L1 范数 2.1 L1 2.2 L1正则化和特征选择 2.3 拉普拉斯先验与L1正则化 2.3.1 拉普拉斯分布 2.3.2 拉普拉斯先验 3 L2 范数 3 ...
最新文章
- tcp断开连接,4次握手,为什么wireshark 只能抓到3个包?
- 爬虫进阶教程:极验(GEETEST)验证码破解教程
- proftpd的安装配置实例
- 万字长文带你一文读完Effective C++
- .jar中没有主清单属性_IDEA中spring boot helloword打包运行-0228-2020
- X264电影压缩率画质
- SparkSQL性能优化
- Linux 查看盘结构命令
- python面试如何以相反顺序展示一个文件的内容?
- Android之Adobe AIR本地扩展
- iPad横竖屏代码适配
- eclipse背景设置绿豆色
- 线性可变位移传感器行业调研报告 - 市场现状分析与发展前景预测
- 苹果官方揭秘:这个强大的相册功能是如何实现的?
- HNUST OJ 2293 贪吃蛇吃苹果
- 日本华人IT派遣那点事儿(2)
- 基于51单片机的火灾预警系统设计
- MarkDown-如何插入上划线,下划线,中划线汇总
- 中位数应用-货仓选址-纸牌均分-糖果传递-七夕祭
- 干货!Python操作PDF的神器——PyMuPDF