医疗问答机器人项目部署
医疗问答机器人项目部署
文章目录
- 医疗问答机器人项目部署
- 1. 拉取TensorFlow镜像
- 2. 配置系统环境
- 2.1 更换软件源
- 2.2 下载vim
- 2.3 解决vim中文乱码问题
- 2.4 安装Neo4J图数据库
- 2.5 安装网络工具包
- 3. 运行项目
- 3.1 拷贝项目到容器中
- 3.2 安装项目所需的工具包
- 3.3 导入数据
- 3.4 打开实体抽取服务
- 3.5 打开意图识别服务
- 3.6 打开问答助手服务
- 3.7 效果展示
- 4. 搭建项目镜像
- 4.1 Docker commit搭建
- 4.2 Dockerfile搭建
- 5. 发布项目镜像
这是去年8月份做的项目,当时我参加了南航16院卓工班的实训,是做了一个智能医疗系统,其中包含了这个医疗问答助手功能。由于当时受限于时间和知识水平,当时的问答助手的功能较为简单,可以理解为是基于规则的问答系统,不能算真正意义上的智能。故在今年年初的时候再完善一下这个项目,使用NLP领域的一些算法使其更符合实际使用。
1. 拉取TensorFlow镜像
从Docker Hub拉取TensorFlow的镜像,在该镜像上进行下面的操作。
# 拉取镜像
$ docker pull tensorflow/tensorflow:1.14.0-py3
# 生成容器
$ docker run -dit --name diagnosis -p 5002:5002 -p 7474:7474 -p 7473:7473 -p 7687:7687 -p 60061:60061 -p 60062:60062 tensorflow/tensorflow:1.14.0-py3
# 进入容器
$ docker exec -it diagnosis bash
5002端口是项目端口;7473、7474和7687三个端口是neo4j的端口;60061和60062是另外两个服务的端口。
查看容器tensorflow的版本和gpu是否可用,进入python终端输入下面的指令,可以看到使用的tensorflow版本是1.14.0。
>>> import tensorflow as tf
>>> tf.__version__
'1.14.0'
>>>tf.test.is_gpu_available()
False
2. 配置系统环境
查看Ubuntu版本,即18.04.2版本。
root@322e47635519:/workspace/Diagnosis-Chatbot# cat /etc/issue
Ubuntu 18.04.2 LTS \n \l
2.1 更换软件源
先备份原有的软件源,命令如下。
cp /etc/apt/sources.list /etc/apt/sources.list.bak
因为镜像没有安装vim,故只能通过echo指令更改/etc/apt/sources.list文件内容。
阿里源
echo "">/etc/apt/sources.list
echo "deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse">>/etc/apt/sources.list
echo "deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse">>/etc/apt/sources.list
echo "deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse">>/etc/apt/sources.list
echo "deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse">>/etc/apt/sources.list
echo "deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse">>/etc/apt/sources.list
echo "deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse">>/etc/apt/sources.list
echo "deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse">>/etc/apt/sources.list
echo "deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse">>/etc/apt/sources.list
echo "deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse">>/etc/apt/sources.list
echo "deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse">>/etc/apt/sources.list
更新软件源。
apt-get update
apt-get upgrade
在更换软件源时,我首先使用的是清华源,但是在下载vim时提示说不能下载vim相关的一些依赖。在网上搜索后应该是源的问题,后来我就更换为阿里源了。
2.2 下载vim
修改文件内容需要使用vim,所以要下载。
apt-get install vim -y
下载完成后可以通过下面的指令查看vim的版本。
vim --version
2.3 解决vim中文乱码问题
修改/etc/vim/vimrc内容,在最后面添加下面的内容:
set fileencodings=utf-8,ucs-bom,gb18030,gbk,gb2312,cp936
set termencoding=utf-8
set encoding=utf-8
设置后文件内的中文就可以正常显示了。
2.4 安装Neo4J图数据库
详细步骤可以看我的另外一篇博客—在Linux系统下安装Neo4j图数据库。
2.5 安装网络工具包
apt-get install inetutils-ping
apt-get install net-tools
3. 运行项目
3.1 拷贝项目到容器中
首先在容器中创建workspace目录,将项目代码放入到该目录下。
root@322e47635519:/# mkdir workspace
将本机上的项目代码文件拷贝到容器的工作目录下。
$ docker cp "本机上项目的路径" diagnosis:/workspace/
上面的指令实现的功能是,将项目拷贝到diagnosis容器中的/workspace/目录下。
3.2 安装项目所需的工具包
首先要升级pip,升级指令如下。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
使用pip指令下载工具包,-i后面使用的清华源,最后是工具包的名称。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple packageName
在该容器中,我需要安装的包如下:
# 导入Neo4j数据库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple py2neo==2021.2.3
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas==1.1.5
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tqdm==4.62.3
# 启动问答助手服务
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy==1.19.5
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple flask==1.1.4
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple flask_cors==3.0.10
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn==0.24.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests==2.26.0
# bilstm算法
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyahocorasick==1.4.2
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gevent==1.5.0
# 意图识别
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bert4keras==0.10.8
# 语音识别
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple huggingface_hub==0.0.6
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple hyperpyyaml==0.0.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple joblib==0.14.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pre-commit==2.3.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple sentencepiece==0.1.91
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple SoundFile==0.10.2
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torch==1.8.0
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple torchaudio==0.8.0
在启动服务的时候报错了:OSError: sndfile library not found。报错原因是因为缺少libsndfile,需要安装,安装指令如下。
$ apt-get install libsndfile1
3.3 导入数据
首先打开容器中的Neo4j服务。
neo4j start
在项目中有个build_kg文件夹,进入到该文件夹中,执行build_kg_utils.py程序即可将数据导入Neo4j数据库中。
$ python build_kg_utils.py
这个过程要等上几个小时。
![]()
3.4 打开实体抽取服务
在项目根目录中的knowledge_extraction\bilstm下存放着BiLSTM算法的代码,需要启动该服务。
$ python app.py
因为是使用别人写好的算法代码,在启动时提示版本不兼容的问题,原作者使用的是tensorflow1.0版本,在很多地方上写法不一致,故在此记录。
首先在app.py中需要修改以下代码:
| 旧代码 | 新代码 |
|---|---|
| config = tf.ConfigProto() | config = tf.compat.v1.ConfigProto() |
| sess = tf.Session(config=config) | sess = tf.compat.v1.Session(config=config) |
| graph = tf.get_default_graph() | graph = tf.compat.v1.get_default_graph() |
config = tf.ConfigProto() => config = tf.compat.v1.ConfigProto()
sess = tf.Session(config=config) => sess = tf.compat.v1.Session(config=config)
graph = tf.get_default_graph() => graph = tf.compat.v1.get_default_graph()
3.5 打开意图识别服务
在项目根目录中的nlu\intent_recg_bert下存放着使用Bert模型的意图识别算法的代码,需要启动该服务。
$ python app.py
因为是使用别人写好的算法代码,在启动时提示版本不兼容的问题,原作者使用的是tensorflow1.0版本,在很多地方上写法不一致,故在此记录。
首先在app.py中需要修改以下代码:
| 旧代码 | 新代码 |
|---|---|
| config = tf.ConfigProto() | config = tf.compat.v1.ConfigProto() |
| sess = tf.Session(config=config) | sess = tf.compat.v1.Session(config=config) |
| graph = tf.get_default_graph() | graph = tf.compat.v1.get_default_graph() |
config = tf.ConfigProto() => config = tf.compat.v1.ConfigProto()
sess = tf.Session(config=config) => sess = tf.compat.v1.Session(config=config)
graph = tf.get_default_graph() => graph = tf.compat.v1.get_default_graph()
3.6 打开问答助手服务
在app.py中需要检查主机号和端口号,主机号要写成0.0.0.0不然本机打不开项目,如果端口号要和创建容器时映射的端口一致(这里我设置了5002)。而且要关闭调试模式。
app.run(host='0.0.0.0', port=5002, debug=False, threaded=True)
在完成以上的操作后,在终端中输入如下指令启动项目:
$ python app.py
3.7 效果展示
netstat可以列出正在侦听的所有TCP或UDP端口,包括使用端口和套接字状态的服务。
$ netstat -tunlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:7687 0.0.0.0:* LISTEN 1241/java
tcp 0 0 0.0.0.0:5002 0.0.0.0:* LISTEN 1727/python
tcp 0 0 0.0.0.0:7474 0.0.0.0:* LISTEN 1241/java
tcp 0 0 127.0.0.1:60061 0.0.0.0:* LISTEN 1753/python
tcp 0 0 127.0.0.1:60062 0.0.0.0:* LISTEN 1779/python
- -t:显示 TCP 端口
- -u:显示 UDP 端口
- -n:显示数字地址而不是主机名
- -l:仅显示侦听端口
- -p:显示进程的 PID 和名称
这时在本机的浏览器上输入localhost:5002即可成功打开项目页面了!
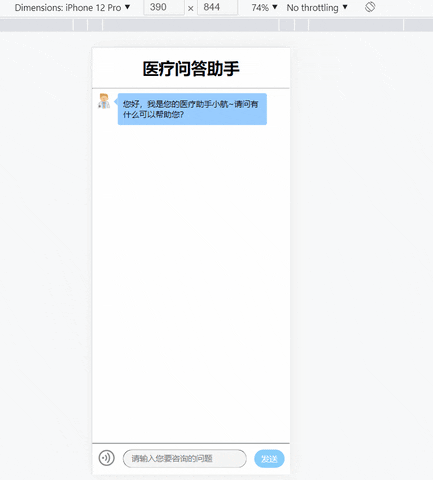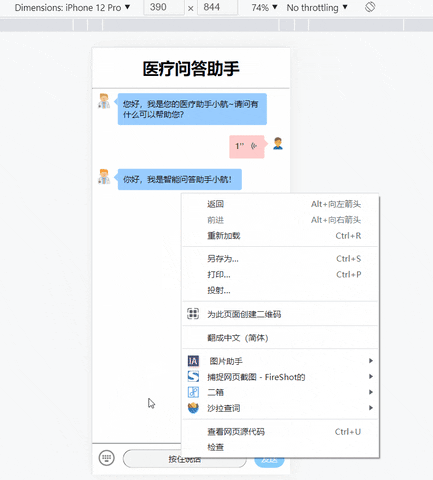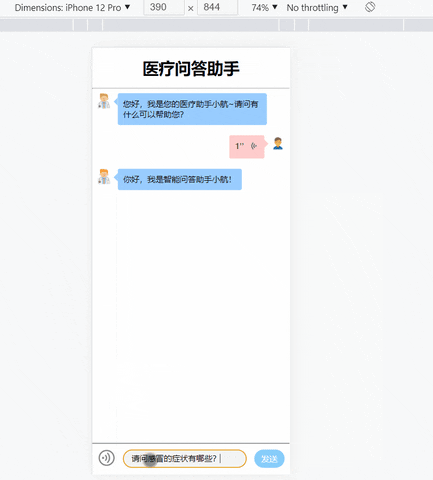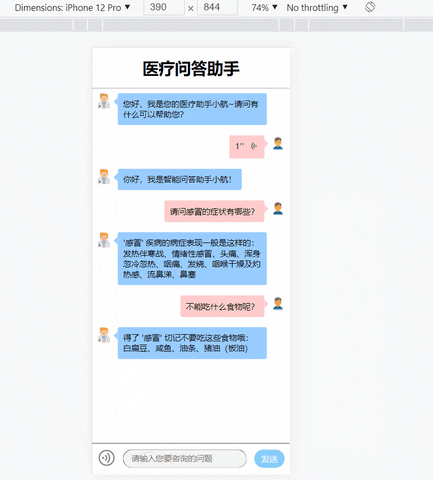
4. 搭建项目镜像
现在把项目所在的容器封装成镜像,方便不同系统上的部署。这里我采用两种方法搭建,分别是Docker commit和Dockerfile搭建项目镜像。
4.1 Docker commit搭建
在Docker中,镜像是多层存储,每一层是在前一层的基础上进行的修改;而容器同样也是多层存储,是在以镜像为基础层,在其基础上加一层作为容器运行时的存储层。
在该项目中,我们是在tensorflow镜像的基础上创建了diagnosis这个容器,并在该容器中进行了修改操作。可以通过 docker diff 命令看到具体的改动。
$ docker diff CONTAINER
docker commit 命令可以将容器的存储层保存下来成为镜像。换句话说,就是在原有镜像的基础上,再叠加上容器的存储层,并构成新的镜像。docker commit 的语法格式为:
$ docker commit [选项] <容器ID或容器名> [<仓库名>[:<标签>]]
在该项目中,我使用如下的指令构建项目镜像:
$ docker commit --author "xxxx" --message "Diagnosis Chatbot Project" diagnosis username/image:tag
其中 --author 是指定作者,而 --message 则是记录本次修改的内容。这点和 git 版本控制相似,不过这里这些信息也可以省略不写。需要注意的是仓库名必须是小写。
用docker image ls指令可以查看我们新创建的镜像。
使用docker run指令可以根据项目镜像生成项目容器,该容器已经配置好环境了,在容器中直接启动服务即可。
4.2 Dockerfile搭建
后续会计划打算用Dockerfile构建这个项目的镜像。
5. 发布项目镜像
将有Docker commit搭建好的项目镜像推送到远端仓库中,指令如下:
$ docker push username/image:tag
医疗问答机器人项目部署相关推荐
- 从开发到部署:一站式指南创建个性化 Slack App 问答机器人
从开发到部署:一站式指南创建个性化 Slack App 问答机器人 01 简介 做这个教程是因为看别人拿免费的割韭菜很不爽,所以准备做个教程来教大家如何搭建一个问答机器人 内核其实就是利用了slack ...
- 问答机器人2.0!文档问答产品科普
在之前的文章里,我们测试过百度UNIT的图形化多轮对话编辑功能TaskFlow,今天我们将带大家体验UNIT和小i机器人最新的文档问答(document-based question answerin ...
- 问答机器人接口python_设计用于机器学习工程的Python接口
问答机器人接口python In order to do machine learning engineering, a model must first be deployed, in most c ...
- AI实战:垂直领域问答机器人QA Bot常见技术架构
垂直领域问答机器人QA Bot常见技术架构 对话系统示意图 基于知识图谱的智能问答:点击查看 人机对话体系结构 问答产品知识结构 基于知识图谱的问答系统关键技术研究: 点击查看 研究架构图 对话机器人 ...
- 开发一个智能问答机器人
近期开发了一套基于自然语言处理的问答机器人,之前没有做过python,主要做asp.net,写这篇目的是给想要开发这类智能客服系统的朋友提供一个思路,项目已经上线,但在开发和设计过程中仍然有很多问题没 ...
- 剖析腾讯知文,智能问答机器人路在何方
近年来,智能机器人客服已经在各行各业发挥作用,替代人类更有效率地处理繁杂的事务. 但是,不可否认的是,目前市面上大多数智能客服并不能完美满足用户的需求,如难以处理未经过训练的场景问题,无法理解复杂的人 ...
- 毕业设计第一次总结(基于知识图谱的医疗问答)
毕业设计第一次总结(基于知识图谱的医疗问答) 写在文章前面:之所以做总结是因为本人也是一个刚入门知识图谱的本科萌新,也不是什么大佬,在整个过程中遇到了不少困难,然后也有一些自己的心得,想分享给后来人. ...
- 【码云周刊第 7 期】拥抱 HTTPS,首个完整版开源机器人项目亮相
摘要 每周为您推送最有价值的开源技术内参! 一周热门资讯回顾 1.2017 年高薪编程语言排行榜,你的语言上榜没? 选择正确的编程语言进行学习无疑成为左右个人发展投资成功与否的关键.在今天的编程语言推 ...
- 开源任务式问答机器人系列之rasa篇
开源任务式问答机器人框架系列--Rasa Rasa data/nlu.md data/stories.md domain.yml config.yml 总结 Rasa rasa是一个开源的问答机器人框 ...
最新文章
- BZOJ 1014 [JSOI2008]火星人prefix
- html5 规定input域,html5中关于input用法
- oracle expdp 39002,expdp 导入数据时ORA-39002、ORA-39070错误排查
- [备忘]Visual Studio常用小技巧
- 注册表只改一个值 马上加快宽带上网速度
- ILI9486 和 stm32F407 cortex-M4
- 【Android】Listview返回顶部,快速返回顶部的功能实现,详解代码。
- Reactive Extensions入门(4):Rx实战
- 博格和他的先锋集团创业史(3): 共同基金的先驱者
- 智能问答机器人python_帮帮智能问答机器人中TaskBot任务对话算法实践
- 读取npy格式的文件
- 关于Tacotron2看这一篇就够了
- Appium----基于Ubuntu系统安装个人版免费的Android模拟器Genymotion模拟器
- 运行时错误1004 应用程序定义或对象定义错误
- 改变中国软件教育,我们正在行动
- 函数对象,嵌套,空间与作用域
- SEO整站优化方案制作
- ipxe(可选):winboot:网络引导(启动)wim格式的windows PE系统:配置文件写法
- (转)25款实用的桌面版博客编辑器
- 科普文——拉卡拉支付是什么?