【转】通过CountDownLatch提升请求处理速度
countdownlatch是java多线程包concurrent里的一个常见工具类,通过使用它可以借助线程能力极大提升处理响应速度,且实现方式非常优雅。今天我们用一个实际案例和大家来讲解一下如何使用以及需要特别注意的点。
由于线程类的东西都比较抽象,我们换一种讲解思路,先讲解决问题的案例,然后再解释下原理。
假设在微服务架构中,A服务会调用B服务处理一些事情,且每处理一次业务,A可能要调用B多次处理逻辑相同但数据不同的事情。为了提升整个链路的处理速度,我们自然会想到是否可以把A调用B的各个请求组成一个批次,这样A服务只需要调用B服务一次,等B服务处理完一起返回即可,省了多次网络传输的时间。代码如下:
/*** 批次请求处理服务* @param batchRequests 批次请求对象列表* @return*/
public List<DealResult> deal(List<DealRequest> batchRequests){ List<DealResult> resultList = new ArrayList<>(); if(batchRequests != null){ for(DealRequest request : batchRequests){ //遍历顺序处理单个请求 resultList.add(process(request)); } } return resultList; }但是B服务顺序处理批次里每一个请求的时间并没有节省,假设批次里有3个请求,一个请求平均耗时100MS,则B服务还是要花费300MS来处理完。有什么办法能立刻简单提升3倍处理速度,令总花费时间只需要100MS?到我们的大将countdownlatch出场了!代码如下:
/*** 使用countdownlatch的批次请求处理服务* @param batchRequests 批次请求对象列表* @return*/
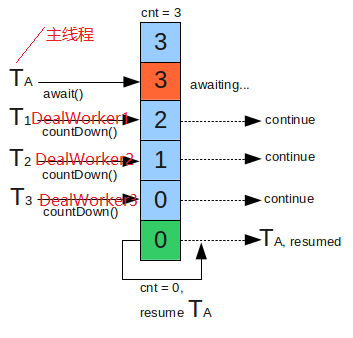
public List<DealResult> countDownDeal(List<DealRequest> batchRequests){ //定义线程安全的处理结果列表 List<DealResult> countDownResultList = Collections.synchronizedList(new ArrayList<DealResult>()); if(batchRequests != null){ //定义countdownlatch线程数,有多少个请求,我们就定义多少个 CountDownLatch runningThreadNum = new CountDownLatch(batchRequests.size()); for(DealRequest request : batchRequests){ //循环遍历请求,并实例化线程(构造函数传入CountDownLatch类型的runningThreadNum),立刻启动 DealWorker dealWorker = new DealWorker(request, runningThreadNum, countDownResultList); new Thread(dealWorker).start(); } try { //调用CountDownLatch的await方法则当前主线程会等待,直到CountDownLatch类型的runningThreadNum清0 //每个DealWorker处理完成会对runningThreadNum减1 //如果等待1分钟后当前主线程都等不到runningThreadNum清0,则认为超时,直接中断,抛出中断异常InterruptedException runningThreadNum.await(1, TimeUnit.MINUTES); } catch (InterruptedException e) { //此处简化处理,非正常中断应该抛出异常或返回错误结果 return null; } } return countDownResultList; } /** * 线程请求处理类 * */ private class DealWorker implements Runnable { /** 正在运行的线程数 */ private CountDownLatch runningThreadNum; /**待处理请求*/ private DealRequest request; /**待返回结果列表*/ private List<DealResult> countDownResultList; /** * 构造函数 * @param request 待处理请求 * @param runningThreadNum 正在运行的线程数 * @param countDownResultList 待返回结果列表 */ private DealWorker(DealRequest request, CountDownLatch runningThreadNum, List<DealResult> countDownResultList) { this.request = request; this.runningThreadNum = runningThreadNum; this.countDownResultList = countDownResultList; } @Override public void run() { try{ this.countDownResultList.add(process(this.request)); }finally{ //当前线程处理完成,runningThreadNum线程数减1,此操作必须在finally中完成,避免处理异常后造成runningThreadNum线程数无法清0 this.runningThreadNum.countDown(); } } }是不是很简单?下图和上面的代码又做了一个对应,假设有3个请求,则启动3个子线程DealWorker,并实例化值数等于3的CountDownLatch。每当一个子线程处理完成后,则调用countDown操作减1。主线程处于awaiting状态,直到CountDownLatch的值数减到0,则主线程继续resume执行。
在API中是这样描述的:
用给定的计数 初始化 CountDownLatch。由于调用了 countDown() 方法,所以在当前计数到达零之前,await 方法会一直受阻塞。之后,会释放所有等待的线程,await 的所有后续调用都将立即返回。这种现象只出现一次——计数无法被重置。如果需要重置计数,请考虑使用 CyclicBarrier。
经典的java并发编程实战一书中做了更深入的定义:CountDownLatch属于闭锁的范畴,闭锁是一种同步工具类,可以延迟线程的进度直到其到达终止状态。闭锁的作用相当于一扇门:在闭锁到达结束状态之前(上面代码中的runningThreadNumq清0),这扇门一直是关闭的,并且没有任何线程能通过(上面代码中的主线程一直await),当到达结束状态时,这扇门会打开并允许所有线程通过(上面代码中的主线程可以继续执行)。当闭锁到达结束状态后,将不会再改变状态,因此这扇门将永远保持打开状态。
像FutureTask,Semaphore这类在concurrent包里的类也属于闭锁,不过它们和CountDownLatch的应用场景还是有差别的,这个我们在后面的文章里再细说。
使用CountDownLatch有哪些需要注意的点
- 批次请求之间不能有执行顺序要求,否则多个线程并发处理无法保证请求执行顺序
- 各线程都要操作的结果列表必须是线程安全的,比如上面代码范例的countDownResultList
- 各子线程的countDown操作要在finally中执行,确保一定可以执行
- 主线程的await操作需要设置超时时间,避免因子线程处理异常而长时间一直等待,如果中断需要抛出异常或返回错误结果
使用CountDownLatch提高批次处理速度的问题
- 如果一个批次请求数很多,会瞬间占用服务器大量线程。此时必须使用线程池,并限定最大可处理线程数量,否则服务器不稳定性会大福提升。
- 主线程和子线程间的数据传输变得困难,稍不注意会造成线程不安全的问题,且代码可读性有一定下降
地址:https://segmentfault.com/a/1190000011443338
转载于:https://www.cnblogs.com/zdd-java/p/8876607.html
【转】通过CountDownLatch提升请求处理速度相关推荐
- 微软office服务器连接很慢,解决 RPC 请求处理速度慢的问题
解决 RPC 请求处理速度慢的问题 07/04/2014 本文内容 上一次修改主题: 2008-11-12 如果您在 MAPI 模式下使用 Microsoft Office,Outlook 会将客户端 ...
- Gox语言中使用内存虚拟文件系统提升IO处理速度-GX43.1
Gox语言中,1.06a版本以上,可以利用内置的github.com/topxeq/afero包来将内存中虚拟出一个文件系统.这样,如果内存足够大,完全可以利用它来提升一些文件IO处理的效率. 该包实 ...
- 服务器性能优化的8种常用方法
1.使用内存数据库 内存数据库,其实就是将数据放在内存中直接操作的数据库.相对于磁盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁盘上访问能够极大地提高应用的性能.内存数据库抛弃了磁 ...
- getallheaders函数在服务器报500错误_「干货」服务器性能优化的8种常用方法
1.使用内存数据库 内存数据库,其实就是将数据放在内存中直接操作的数据库.相对于磁盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁盘上访问能够极大地提高应用的性能.内存数据库抛弃了磁 ...
- Kafka入门篇学习笔记整理
Kafka入门篇学习笔记整理 Kafka是什么 Kafka的特性 应用场景 Kafka的安装 单机版部署 集群部署环境准备 Kafka 2.x集群部署 Kafka 3.x集群部署 监听器和内外网络 K ...
- SNG mini项目总结
Mini项目总结 一.项目介绍 一款懂你的陌生人社交APP 项目代码:https://github.com/fwdhz998/getyou 二. 项目内容 1.产品使用流程: 图一 产品使用流程 2. ...
- 服务器性能测试方式、方法
本文转载于: http://wetest.qq.com/lab/view/102.html?from=adsout_qqtips_part2_102&sessionUserType=BFT.P ...
- Web服务端性能提升实践
随着互联网的不断发展,日常生活中越来越多的需求通过网络来实现,从衣食住行到金融教育,从口袋到身份,人们无时无刻不依赖着网络,而且越来越多的人通过网络来完成自己的需求. 作为直接面对来自客户请求的Web ...
- http请求限制和http连接限制
1.http连接限制 ngx_http_limit_conn_module模块用于限制每个定义的键的连接数,特别是来自单个IP地址的连接数.并非所有连接都被计数.仅当连接具有服务器正在处理的请求并且已 ...
最新文章
- 在k8s中使用gradle构建java web项目镜像Dockerfile
- Red Hat Linux 安装教程
- Qt中使用的工程文件(.pro文件)
- 系统管理模块_部门管理_设计(映射)本模块中的所有实体并总结设计实体的技巧_懒加载异常问题_树状结构...
- python编程基础是什么-一 python编程基础
- Spring-AOP 通过配置文件实现 异常抛出增强
- Redis+Nginx+JVM+设计模式+Spring全家桶+Dubbo万字总结
- JavaScript中的Boolean 方法与Number方法
- 微信小程序 official-account组件 关注公众号
- [DB2]Linux下安装db2 v9.7
- ajax传递字符,Ajax怎么传递特殊字符的数据
- c# forbidden.html,c# - google+ api error forbidden 403 - Stack Overflow
- DirectUI的初步分析-转
- raw转bmp程序c语言,求指导,如何用c语言实现读取*.raw格式图像
- C/C++程序设计题
- 什么是有监督学习?看这里。
- 痞子衡嵌入式:ARM Cortex-M文件那些事(5)- 映射文件(.map)
- SAP中记账汇率和预算汇率的应用配置分析
- WPS office文档 为何输入文字不显示
- Git修改用户名和邮箱
热门文章
- php方便,两个方便测试PHP特性的小程序
- 定时刷新网页脚本python_在特定时间后自动刷新Python脚本
- python换行输出三个数中最大数_关于Python 3中print函数的换行详解
- leetcode组队学习——查找(一)
- PSENet PANNet DBNet 三个文本检测算法异同
- 互联网运营数据分析(5): 流失分析
- python 画蝴蝶_python画蝴蝶曲线图的实例
- linux中sed和find,Linux运维知识之Linux 之 sed 与 find 命令结合使用
- linux下目标文件的类型6,Linux下文件类型
- vs2017修改服务器地址大全,vs2017更改默认pip安装服务器地址