不理智的_如何显示大量指标并保持理智
不理智的
Large scale equals distributed. Distributed equals inevitable complexity. Complexity at runtime equals extensive monitoring. At Hazelcast, doing distributed systems well is our bread and butter. It means we have no choice but to be huge fans of collecting all kinds of metrics to stay on guard of the data our users trust us with.
大规模等于分布式。 分布式等于不可避免的复杂性。 运行时的复杂性等于广泛的监视。 在Hazelcast,出色的分布式系统是我们的生计。 这意味着我们别无选择,只能成为收集各种指标的忠实拥护者,以保护用户信任的数据。
In Management Center 4.2020.08, we drastically changed the model of how we transfer the metric data from the cluster members to the Management Center, how we store it, and how we display it. In this post, we are going to talk about the latter bit of the triad.
在管理中心4.2020.08 ,我们彻底改变了将度量标准数据从集群成员传输到管理中心,如何存储它以及如何显示它的模型。 在这篇文章中,我们将讨论三合会的后半部分。
We will discuss what to do when you want to display all the data at once, but your users have a limited number of monitors and only one pair of eyes. We will speculate about what users actually want to see when they look at a chart of a monitoring web app. We will go over different approaches to filter the data, and how an average, a median, and a definite integral play their key roles.
我们将讨论您想要一次显示所有数据但您的用户的显示器数量有限且只有一对眼睛时该怎么办。 我们将推测用户在查看监视Web应用程序的图表时实际想要看到的内容。 我们将介绍各种方法来过滤数据,以及平均值,中位数和定积分如何发挥关键作用。
Cross-posted from hazelcast.com
从hazelcast.com交叉发布
4.2020.08! 4.2020.08! 4.2020.08! 为什么我们如此兴奋? (4.2020.08! 4.2020.08! 4.2020.08! Why are we so excited?)
This release stands on 3 pillars:
此版本基于以下三个Struts:
- Enhanced UX for developers开发人员的增强用户体验
- Unification with the Jet Management Center与喷气机管理中心统一
- New metric engine新的指标引擎
Struts1.针对开发人员的增强型UX。 (Pillar 1. Enhanced UX for developers.)
We love developers and loathe unnecessarily complex UIs. As you might know, Hazelcast Management Center supports numerous security providers. Prior to 4.2020.08, the default choice was to use username/password based authentication, which we called the "Default" authentication. We are happy to present you with the "Dev Mode" security provider!
我们热爱开发人员,讨厌不必要的复杂UI。 如您所知,Hazelcast管理中心支持众多安全提供程序 。 在4.2020.08之前,默认选择是使用基于用户名/密码的身份验证,我们将其称为“默认”身份验证。 我们很高兴为您提供“开发模式”安全提供商!
Internally, we call it "Just click save" security provider. Go ahead and try it yourself. We are keen to hear back from you!
在内部,我们将其称为“仅单击保存”安全提供程序。 继续尝试一下 。 我们渴望收到您的回音!
Struts2.与喷气机管理中心统一。 (Pillar 2. Unification with the Jet Management Center.)
What the heck is Jet? It is a blazing fast distributed computing platform built on top of Hazelcast In-Memory Data Grid. Here you can read more about it. Previously, Jet had its own Management Center, but not anymore. One Hazelcast — one Management Center!
杰克到底是什么? 它是建立在Hazelcast内存数据网格之上的快速分布式计算平台。 在这里您可以有关它的信息。 以前,Jet有自己的管理中心,但现在没有了。 一本Hazelcast-一本管理中心!
Struts3.新的公制引擎。 (Pillar 3. New metric engine.)
Since the dawn of time we used the "push" model to collect the metric data from the cluster. It is not even entirely correct to use the word "collect" here. Collecting is an active process. We received the metric data from the cluster. Every node had to know the address of the management center, and it pushed its metric data to that address.
自从黎明起,我们就使用“推”模型从集群中收集度量数据。 在此处使用“收集”一词甚至不完全正确。 收集是一个活跃的过程。 我们从集群接收了指标数据。 每个节点都必须知道管理中心的地址,并将其度量标准数据推送到该地址。
With 4.2020.08 we are trilled to reverse that paradigm and start polling cluster members for metric data! It is a huge change but we have not stopped there. Here is a list with new major metric-related features:
在4.2020.08中,我们被认为可以颠覆该范式并开始轮询集群成员以获取度量数据! 这是一个巨大的变化,但我们还没有止步于此。 以下是具有新的主要指标相关功能的列表:
- The "poll" model instead of the "push" one.“投票”模型代替“推送”模型。
A new metrics storage for time-series data implemented on top of RocksDB.
在RocksDB之上实现的用于时间序列数据的新指标存储。
Prometheus exporter for the metric data.
度量数据的Prometheus导出器。
- A new customizable UI widget to display the metric data.一个新的可自定义的UI小部件,用于显示指标数据。
Having that said, let's dive deeper in the anatomy of the widget, and what problems we faced while creating it.
话虽如此,让我们更深入地了解小部件的结构,以及在创建小部件时遇到的问题。
小部件 (The widget)
用户想看什么,为什么 (What users want to see and why)
What is the purpose of monitoring? One could argue that the whole point is to provide top management with pretty charts and multi-page reports with statistics. Jokes aside. What is the real purpose of monitoring? Why do we stare at all these graphs for ours? The ultimate goal is to detect abnormalities as early as possible. Why? Because any abnormality is a predecessor to potential issues.
监视的目的是什么? 有人可能会说,关键是要为高层管理人员提供漂亮的图表和多页的统计报表。 开个玩笑。 监视的真正目的是什么? 为什么我们盯着所有这些图表? 最终目标是尽早发现异常。 为什么? 因为任何异常都是潜在问题的前兆。
Speaking of monitoring in general, we are usually speaking of time series data (a list of data points in time order, in our case they come to the front end as { time: number; value: number }[]). Speaking of monitoring of distributed systems, we are usually speaking of multiple time series. Multiple time series cause multiple problems.
一般而言,谈到监视,我们通常说的是时间序列数据(按时间顺序排列的数据点列表,在我们的情况下,它们以{ time: number; value: number }[]出现在前端)。 说到监视分布式系统,我们通常说的是多个时间序列。 多个时间序列会导致多个问题。
问题1.我们如何分析图? (Problem 1. How do we analyze graphs?)
We have several data points. We use fancy or not so fancy methods of interpolation to draw continuous lines that resemble the original continuous real-world data standing behind the discrete data. How do we detect abnormality there?
我们有几个数据点。 我们使用奇特的或非奇特的插值方法来绘制连续的线条,这些线条类似于位于离散数据后面的原始连续真实世界数据。 我们如何在那里发现异常?
We can analyze graphs:
我们可以分析图:
- Individually个别地
- As a group作为一个团队
For individual analysis, we already have the data points containing scalar values. Comparing scalars is, if not simple, at least doable.
对于单个分析,我们已经有包含标量值的数据点。 如果不是简单的话,比较标量至少是可行的。
For group analysis, we have to somehow calculate a single scalar out of a time series for each time series, and compare the resulting scalars. There are endless possibilities of how one could do the calculation, depending on the needs of the business. We will go over a small bit of them that we chose for our application down below.
对于组分析,我们必须以某种方式为每个时间序列计算出一个时间序列中的单个标量,并比较所得的标量。 根据业务需求,人们如何进行计算有无限可能。 我们将在下面逐一介绍为应用程序选择的一小部分。
As we can see, for both methods of analysis we end up with a list of scalars that we need to somehow compare.
如我们所见,对于这两种分析方法,我们最终都需要以某种方式进行比较的标量列表。
问题2。如何在标量列表中找到异常? (Problem 2. How do we find an abnormality in a list of scalars?)
Generally speaking, we have 4 ways of describing abnormality:
一般来说,我们有4种描述异常的方式:
We can define a range a values that are considered normal. If anything falls out of the range then it is abnormal. For example, we can say that
[-42,42]is our normal range. Then7would be considered normal, and43would be abnormal.我们可以定义一个范围,将其视为正常值。 如果有任何超出范围,则异常。 例如,我们可以说
[-42,42]是我们的正常范围。 那么7将被视为正常,而43将被视为异常。We can define a predicate for normality. If a value satisfies the predicate than it is considered normal. Otherwise, it is abnormal. For example, we can say that all integer odd values are normal range. Then
7would be considered normal, and7.5or42would be abnormal.我们可以定义正常性的谓词。 如果一个值满足谓词,则认为它是正常的。 否则,异常。 例如,我们可以说所有整数奇数值都是正常范围。 那么
7将被视为正常,而7.5或42将被视为异常。- We can define a range a values that are considered abnormal. If anything falls out of the range then it is normal. Basically, it is a negation of #1.我们可以定义一个范围a,该值被认为是异常的。 如果有任何超出范围的现象,那是正常的。 基本上,它是对#1的否定。
- We can define a predicate for abnormality. If a value satisfies the predicate than it is considered abnormal. Otherwise, it is normal. Basically, it is a negation of #2.我们可以定义异常的谓词。 如果一个值满足谓词,则认为该值异常。 否则,这是正常的。 基本上,它是对#2的否定。
We can also detect abnormality iteratively, using different methods (listed above) at different stages, chaining them. For example, we could consider abnormal only integer odd values that belong to [0, 42).
我们还可以在不同阶段使用不同的方法(上面列出)来迭代地检测异常,并将它们链接起来。 例如,我们可以考虑仅属于[0, 42)整数唯一奇数异常。
With a few exceptions, predicates make the most sense for analyzing potentially infinite lists, as they, usually, require limited processing power and memory.
除少数例外,谓词对于分析潜在的无限列表最有意义,因为它们通常需要有限的处理能力和内存。
Ranges are not that simple. Ranges can be:
范围不是那么简单。 范围可以是:
- Static静态的
- Dynamic动态
Static range is constant predefined range that does not change when new metrics data comes in. Say, we have a cluster of 30 machines. Every machine has 16 GB of RAM. Knowing the average expected load, we could identify the normal range for the used RAM as [1.6 GB, 14.4 GB] (from 10% and up to 90%). That would be a perfect example of a static range. It does not depend on the number of machines or the phase of the moon.
静态范围是恒定的预定义范围,当输入新指标数据时该范围不会更改。假设我们有30台计算机的集群。 每台机器都有16 GB的RAM。 知道了平均预期负载后,我们可以确定已用RAM的正常范围为[1.6 GB, 14.4 GB] (从10%到90%)。 那将是静态范围的完美示例。 它不取决于机器的数量或月相。
For some metrics and under certain conditions, we could define a range of normal values beforehand, without analyzing the metric data itself. Say, we have a cluster of 30 machines. Every machine has 16 GB of RAM. Knowing the expected load, we could identify the normal range for the used RAM as [1.6 GB, 14.4 GB] (from 10% and up to 90%).
对于某些指标和某些条件下,我们可以预先定义一个正常值范围,而无需分析指标数据本身。 假设我们有30台机器。 每台机器都有16 GB的RAM。 知道预期的负载后,我们可以将已用RAM的正常范围确定为[1.6 GB, 14.4 GB] (从10%到90%)。
However, not all metrics have a universal predefined range of possible values that make sense for any system. For those metrics, we have to evaluate them by comparison to their peers, i.e. process the whole list of scalars to define the normal range, and then process the list all over again to identify the abnormal range. We can see that the complexity here scales at least linearly with the size of the list.
但是,并非所有指标都具有适用于任何系统的通用预定义范围的可能值。 对于那些度量,我们必须通过与它们的同级进行比较来评估它们,即处理整个标量列表以定义正常范围,然后再次处理整个列表以识别异常范围。 我们可以看到,这里的复杂度至少与列表的大小呈线性比例关系。
As a result, we see that abnormality could be identified in 2 ways:
结果,我们发现可以通过两种方式识别异常:
- Absolutely绝对
- Relatively相对
The absolute abnormality detection is simpler to understand and implement. It also, usually, requires less processing power as it does not require a dynamic range calculation. It could be used on a potentially unlimited list of scalars. However, it has a restricted area of application as not all metrics have a constant predefined range of metrics.
绝对异常检测更易于理解和实现。 由于不需要动态范围计算,因此通常也需要较少的处理能力。 它可以用于可能不受限制的标量列表。 但是,由于并非所有指标都具有恒定的预定义指标范围,因此它的应用范围有限。
The relative abnormality detection is more complex. It requires a dynamic range calculation and, therefore, could be used only on the limited list of scalars. However, it could be applied to any metric in the cluster.
相对异常检测更加复杂。 它需要动态范围计算,因此只能在有限的标量列表上使用。 但是,它可以应用于集群中的任何度量。
The absolute abnormality detection requires users to have deep knowledge of the system to define the normal/abnormal range. In comparison, the relative abnormality detection allows users to easily identify if any metric on any node significantly deviates from the average cluster value without the prior knowledge of the system, or without the expert knowledge of the normal reference range for the system.
绝对异常检测要求用户深入了解系统,以定义正常/异常范围。 相比之下,相对异常检测使用户可以轻松地识别出任何节点上的任何度量标准,如果没有系统的先验知识,或者没有系统的正常参考范围的专业知识,都明显偏离了平均群集值。
问题3.如何显示异常? (Problem 3. How do we display the abnormality?)
Say, we have 100 time series. We identified 20 of them as abnormal. How do we display them?
说,我们有100个时间序列。 我们确定其中20个为异常。 我们如何显示它们?
We could display all 100 graphs, and somehow mark the 20 abnormal ones. For instance, we could color code them, but would you be comfortable browsing through 100 graphs? I certainly would not be. I seriously doubt any living human being could make any sense of that mess.
我们可以显示所有100个图形,并以某种方式标记20个异常图形。 例如,我们可以对它们进行颜色编码,但是您是否可以轻松浏览100张图表? 我当然不会。 我严重怀疑任何活着的人都无法理解这种混乱。
We could display only the 20 abnormal ones. But then we wouldn't know what is considered normal. What was the benchmark against which we identified the abnormality?
我们只能显示20个异常。 但是那时我们不知道什么被认为是正常的。 我们确定异常的基准是什么?
Should we display the 20 abnormal ones and additionally draw a graph with the calculated reference value, considered normal? Yes and no! Yes, because it is the correct principal. We should display the abnormal lines along with the reference normal one. No, because 20 graphs are still too much to comprehend. Various studies on how many items a human being can focus on simultaneously show different results on a range from 3 to 7-9. As the final number varies from study to study, it is still a single-digit number everywhere. It means that 20 is still not good enough. How do we go from 20 to a single-digit number?
我们是否应该显示这20个异常值,并另外绘制一个带有计算出的参考值(被视为正常)的图形? 是的,没有! 是的,因为它是正确的主体。 我们应该显示异常线以及参考正常线。 不可以,因为20张图仍然太多,难以理解。 关于人类可以同时关注多少个项目的各种研究表明,结果范围从3到7-9。 由于最终的数字因研究而异,所以到处都还是个位数。 这意味着20仍然不够好。 我们如何将数字从20变为一位数字?
Previously, we said we could detect abnormality iteratively. Why don't we apply that idea here? Once we detect the initial list of abnormal scalars, we could sort them in the ascending order by their deviation from the reference normal scalar, and leave only those with the biggest deviation.
之前,我们说过我们可以迭代地检测异常。 我们为什么不在这里应用这个想法? 一旦我们检测到异常标量的初始列表,就可以按照它们与参考标准标量的偏差按升序对它们进行排序,而只留下那些偏差最大的标量。
After experimenting a bit ourselves, we decided that 4 is a good number. So for a single metric we decided to display up to 3 abnormal graphs along with the reference normal one.
经过一些实验后,我们认为4是一个好数字。 因此,对于一个度量,我们决定最多显示3个异常图以及参考正常图。
筛选器 (Filters)
Hazelcast cluster could have hundreds of members. It means that for every metric we have hundreds of time series. We could not display all of them. Inevitably, we had to somehow help our users to find the abnormality and filter out the result graphs.
Hazelcast群集可能有数百个成员。 这意味着对于每个指标,我们都有数百个时间序列。 我们无法全部显示。 不可避免地,我们不得不以某种方式帮助我们的用户找到异常并过滤出结果图。
As of Management Center 4.2020.08, we provide our users with 6 different filters:
从管理中心4.2020.08 ,我们为用户提供6种不同的过滤器:
- Peak Top 3峰顶3
- Peak Bottom 3峰底3
- Average Top 3平均前三名
- Average Bottom 3平均倒数3
- Outliers离群值
- Manual Selection手动选择
手动选择 (Manual Selection)
Let's start with the most boring one — Manual Selection. It allows users to select several members out of the list of cluster members they want to see the metric data for. Our front end receives the data only for those members. Piece of cake.
让我们从最无聊的一项开始-手动选择。 它允许用户从要查看其度量标准数据的集群成员列表中选择几个成员。 我们的前端仅接收那些成员的数据。 小菜一碟。
峰顶3 /峰顶3 (Peak Top 3/Peak Bottom 3)
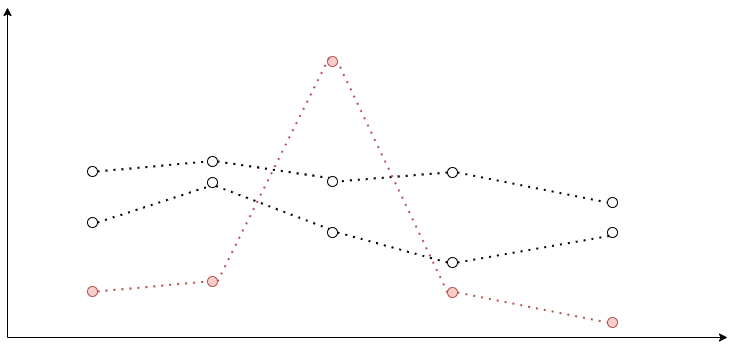
Do you remember what we have to do to analyze time series as a group? We have to calculate a scalar value for every time series. When you think of a calculation approach, one of the first things that comes to mind is just to take the absolute maximum value of the function.
您还记得我们要分析一个小组的时间序列吗? 我们必须为每个时间序列计算一个标量值。 当您想到一种计算方法时,想到的第一件事就是采取函数的绝对最大值。
Given that every data point is { time: number; value: number }, the implementation is straightforward:
假设每个数据点都是{ time: number; value: number } { time: number; value: number } ,实现非常简单:
const timeSeriesResScalar = Max.max(timeSeries.map(({ value }) => value))After that, we sort our multiple time series in the descending order by their calculated scalars, and take the first 3 time series. We call this filter Peak Top 3. For the Peak Bottom 3, we swap Math.max for Math.min, but the idea is the same.
在那之后,我们按照其计算的标量按降序对多个时间序列进行排序,并采用前三个时间序列。 我们称此过滤器为Peak Top 3 。 对于“ Peak Bottom 3 ,我们将Math.max交换为Math.min ,但是想法是相同的。
We do not calculate any average cluster value (a reference normal value) with this approach, leaving the final judgment of normality to the admin. However, we might start doing it if there is a strong demand.
我们不使用这种方法来计算任何平均聚类值(参考标准值),而将正常性的最终判断权留给管理员。 但是,如果需求旺盛,我们可能会开始这样做。
Have you noticed any problems with the Peak filter? One data point with an extraordinary value can make the whole time series range higher even though all other data points have rather small values. For some metrics with modest volatility Peak filter is exactly what we need. Those short term surges could indicate a potential abnormality. But what about highly volatile metrics? We need a way to minimize the effect of those short-term spikes on the result scalar. Here is where the story of mean and median begins.
您是否注意到Peak过滤器有任何问题? 一个具有非凡值的数据点可以使整个时间序列范围更大,即使所有其他数据点的值都很小。 对于某些波动率适中的指标,正是我们所需要的。 这些短期波动可能表明存在潜在的异常情况。 但是高度不稳定的指标呢? 我们需要一种方法来最小化那些短期峰值对结果标量的影响。 这就是平均值和中位数的故事的起点。
均值和中位数 (Mean and median)

Barry has 4 pots of gold. Amy, John and Douglas have 0. The mean value here is 1. The median, however, is 0. How do we calculate them?
巴里有4罐黄金。 艾米(Amy),约翰(John)和道格拉斯(Douglas)有0。这里的平均值是1。但是,中位数是0。我们如何计算它们?
Mean is the average you are used to. Calculate the sum of the items in the list and divide it by the number of the items.
平均值是您习惯的平均值。 计算列表中项目的总和,然后除以项目数。
Median is the middle value of the list. Sort the list in the ascending order. If the number of items is odd, the middle item of your sorted list is the median. If the number of items is even, sum two middle numbers and divide them by 2.
中位数是列表的中间值。 按升序对列表进行排序。 如果项目数为奇数,则排序列表的中间项目为中位数。 如果项目数为偶数,则将两个中间数字相加并除以2。
In terms of monitoring it means that mean accounts for extraordinary spikes. Several of them can drastically change the resulting scalar. Median, on the contrary, filters out the surges.
就监控而言,这意味着要考虑到异常的峰值。 其中几个可以极大地改变生成的标量。 相反,中位数可以滤除波动。
Should we stop at the mean and the median though?
我们应该在均值和中位数处停止吗?
平均积分 (Average by integral)
Let me rephrase it. Should we stop at the arithmetic mean and the median though? After all, we are not calculating an average of a list of simple numbers, these are data points of a time series. By extracting only values and operating only on the values we simply disregard the time factor.
让我改一下。 我们是否应该停止算术平均值和中位数? 毕竟,我们不是在计算简单数字列表的平均值,而这些是时间序列的数据点。 通过仅提取值并仅对值进行运算,我们完全可以忽略时间因素。
Consider these two graphs:
考虑以下两个图形:
The arithmetic means for their values are the same. Do you think they adequately represent the average value for both functions? What scalar value could be used to describe a function?
它们的值的算术平均值相同。 您认为它们足以代表这两个功能的平均值吗? 什么标量值可以用来描述一个函数?
It is the area under the curve. Ladies and gentlemen, please, give your warmest welcome to the definite integral!
它是曲线下的面积。 女士们,先生们,请给您最热情的欢迎!
Usually, we are speaking of a definite integral of a function, but with a time series we do not have a function. Instead, we have a list of discrete data points. Luckily, we do not have to reinvent the wheel. There is an area of study in math researching specifically this problem called numerical integration of discrete data or discrete data integration.
通常,我们说的是函数的定积分,但是对于时间序列,我们没有函数。 相反,我们有一个离散数据点列表。 幸运的是,我们不必重新发明轮子。 数学中有一个专门研究此问题的领域,即离散数据的数值积分或离散数据积分。
There are various methods of discrete data integration. We will consider only one of them. The one we used for the widget — the trapezoidal rule.
离散数据集成有多种方法。 我们将只考虑其中之一。 我们用于小部件的一个-梯形规则。
Consider the following graph:
考虑下图:
You can see how the data points of the time series form 3 trapezoids. To find the area under the interpolated curve we need to find areas of those 3 trapezoids and sum them up.
您可以看到时间序列的数据点如何形成3个梯形。 要找到插值曲线下的面积,我们需要找到这三个梯形的面积并将其求和。
For trapezoid A it is ((2+4)/2)*(2-1) and equals 3. For trapezoid B it is ((1+4)/2)*(2.5-2) and equals 1.25. For trapezoid C it is ((1+1.5)/2)*(7-2.5) and equals 5.625. So the final square is 3+1.25+5.625 and equals 9.875.
对于梯形A它是((2+4)/2)*(2-1)等于3 。 对于梯形B它是((1+4)/2)*(2.5-2)等于1.25 。 对于梯形C它是((1+1.5)/2)*(7-2.5)等于5.625 。 因此,最后一个平方是3+1.25+5.625 ,等于9.875 。
To find the average value of the function we now only need to divide its area by its projection on the x axis. Imagine it as if we are trying to find the height of a rectangle with the same length as the projection of the function and with the same area.
为了找到函数的平均值,我们现在只需要将其面积除以在x轴上的投影即可。 想象一下,就好像我们试图找到与函数的投影长度相同且面积相同的矩形的高度一样。
So the TypeScript function to find the average could look like this:
因此,用于查找平均值的TypeScript函数如下所示:
export const averageByTrapezoidalRule = (data: { value: number; time: number }[],
): number => {let totalArea = 0for (let i = 0; i < data.length - 1; i += 1) {const point1 = data[i]const point2 = data[i + 1]totalArea += ((point2.value + point1.value) / 2) * (point2.time - point1.time)}const average = totalArea / (data[data.length - 1].time - data[0].time)return average
}平均前3名/平均后3名 (Average Top 3/Average Bottom 3)
With all that knowledge, let's now build an algorithm for the Average Top 3 filter:
有了这些知识,现在让我们为“ Average Top 3过滤器构建一个算法:
- For every time series calculate its average by the trapezoidal rule.对于每个时间序列,通过梯形规则计算其平均值。
- Sort the multiple time series in the descending order.按降序对多个时间序列进行排序。
- Take the first 3 of them.拿其中的前三个。
For the Average Bottom 3 we just reverse the sorting.
对于“ Average Bottom 3我们只是将排序反向。
For both of these filters, we still do not calculate any average cluster value (a reference normal value) leaving the final judgment of normality to the admin.
对于这两个过滤器,我们仍然不计算任何平均聚类值(参考标准值),而将正常性的最终判断留给管理员。
离群值 (Outliers)
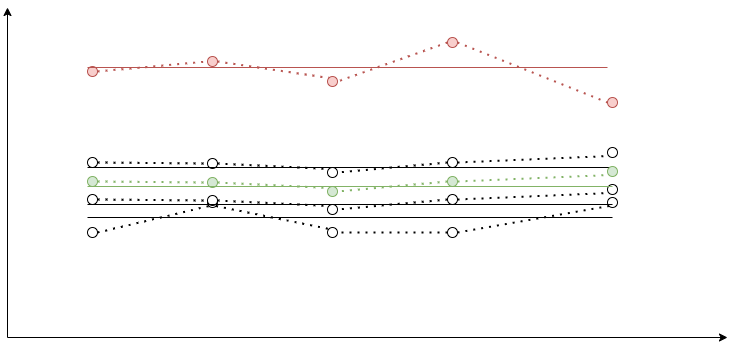
Alrighty, so all previous filters require some expert knowledge of the system to identify if the displayed values are normal or abnormal. Could we create a filter that unleashes the whole power of the relative abnormality detection, and helps us find the abnormal graphs based on the peer values?
好的,因此所有以前的过滤器都需要系统的一些专业知识,才能确定显示的值是正常还是异常。 我们是否可以创建一个过滤器来释放相对异常检测的全部功能,并帮助我们根据对等值找到异常图?
It is our default filter. We call it the Outliers or simply auto. The core idea is to calculate the reference normal value based on the multiple time series as some sort of average. Calculate averages for every time series using the trapezoidal rule. Compare their averages with the reference value. If it deviates from the reference value by more than 30%, consider it abnormal.
这是我们的默认过滤器。 我们称其为Outliers或简称为auto 。 核心思想是基于多个时间序列作为某种平均值来计算参考标准值。 使用梯形法则计算每个时间序列的平均值。 将其平均值与参考值进行比较。 如果偏离参考值超过30%,则认为异常。
The trick is with finding the reference value. Originally, we did it all on the frontend.
诀窍在于找到参考值。 最初,我们是在前端完成所有操作。
- We calculated averages for every time series.我们计算了每个时间序列的平均值。
- We calculated a median of those averages.我们计算了这些平均值的中位数。
- We used the median as the reference value.我们使用中位数作为参考值。
Why the median? Say, you have a cluster of 10 nodes. 2 of those nodes deviate from the median by some extreme value, say, 300%. They could shift the reference value, so one of the normally behaving members could start being an outlier. The median mitigates the effect of outliers on the reference value.
为什么是中位数? 假设您有一个由10个节点组成的集群。 这些节点中有2个偏离中值某个极端值,例如300%。 它们可能会偏移参考值,因此行为正常的成员之一可能会成为异常值。 中位数减轻了离群值对参考值的影响。
Later, our backend provided us with a cool aggregation API for the metric time series data. So now we:
后来,我们的后端为我们提供了一个很酷的汇总API,用于度量时间序列数据。 所以现在我们:
Request the
MEDIANaggregate for all nodes.请求所有节点的
MEDIAN聚合。MEDIANaggregate is a time series as well. For its every data point it takes values for all nodes for the timestamp, and returns a median of those values.MEDIAN聚合也是一个时间序列。 对于其每个数据点,它获取时间戳的所有节点的值,并返回这些值的中值。
- Calculate the average of the median time series.计算中间时间序列的平均值。
- Use the calculated average as the reference value.使用计算出的平均值作为参考值。
Now we disassembled our reference value calculation. Only one last question still stands. What happens when there are too many outliers?
现在,我们拆解参考值计算。 最后一个问题仍然存在。 当异常值过多时会发生什么?
If we find more than 3 outliers we sort the outliers in the ascending order by their deviation from the reference value, and take only the top 3 with the greatest deviation.
如果发现3个以上的离群值,则按离群值与参考值的偏差按升序对离群值进行排序,并且仅采用偏差最大的前3个。
The final Outliers algorithm looks like this:
最终的Outliers算法如下所示:
Request the
MEDIANaggregate.请求
MEDIAN聚合。- Display it as a dashed graph on the chart.在图表上将其显示为虚线图。
- Calculate its average by the trapezoidal rule. Consider it a reference value.通过梯形法则计算其平均值。 将其视为参考值。
- Calculate averages for every time series.计算每个时间序列的平均值。
- Leave only ones that deviate from the reference value by more than 30%.仅保留那些偏离参考值超过30%的值。
- Sort them in ascending order by the deviation. Display the top 3 time series with the greatest deviation.按偏差按升序对它们进行排序。 显示偏差最大的前3个时间序列。
As you can see, with the Outliers we have the reference graph, so it is easy to understand what is considered normal at first glance.
如您所见, Outliers具有参考图,因此乍看之下很容易理解什么是正常的。
小部件的未来计划 (Future plans for the widget)
Going further, we would like to:
更进一步,我们希望:
- Make the outliers threshold adjustable.使异常值阈值可调。
- Allow zooming and out for both X and Y axes.允许同时放大和缩小X和Y轴。
- Make the maximum number of graphs adjustable.使最大图形数可调。
We encourage you try he new Management Center yourself, and get back to us with your feedback! Stay tuned for the new posts with the lessons we learned a truly distributed enterprise-ready in-memory data grid.
我们鼓励您自己尝试使用新的管理中心 ,并通过您的反馈与我们联系! 请继续学习这些新课程,我们将学习到一个真正的分布式企业就绪内存数据网格。
翻译自: https://habr.com/en/post/517532/
不理智的
不理智的_如何显示大量指标并保持理智相关推荐
- 通达信缠论三买三卖指标公式_【新增选股指标:中枢突破】通达信版缠论自动画线选股指标今天更新1个重要新版...
本文要点 通达信版缠论自动画线选股指标,今日新增一个"中枢突破"选股指标: 指标将在后天(8月12日)涨价到1999元,大家有需要的今天/明天可以考虑入手了.现在购买的指标均终身可 ...
- 基于51单片机十字路口交通灯_只显示绿灯时间+黄灯5s
基于51单片机十字路口交通灯_只显示绿灯时间+黄灯5s (程序+仿真+参考报告) 仿真:proteus 7.8 程序编译器:keil 4/keil 5 编程语言:C语言 编号J011 目录标题 基于5 ...
- NET-A-PORTER为何难以模仿?_全文显示_生活福布斯中文网
NET-A-PORTER为何难以模仿?_全文显示_生活福布斯中文网 NET-A-PORTER为何难以模仿?
- 华为官方鸿蒙系统发布会,手机显示hd是什么意思_手机显示hd有什么影响_手机hd怎么关闭...
描述 手机显示hd是什么意思_手机显示hd有什么影响 手机屏幕顶端显示HD,说明开启了中国移动VoLTE高清语音业务.如需取消,进入设置-(更多连接设置)-移动网络-高清语音-关闭即可. 温馨提示:V ...
- 没有理智的欲望会走向毁灭,没有欲望的理智会永守清贫
欲望是人类的本性,哥伦布因为它片帆浮海.横渡大洋发现了美州.理性是人类的禀赋,哥白尼因为它仰望星空.冥想终生提出了日心说.在金融市场上没有理智的欲望会走向毁灭,没有欲望的理智会永守清贫. 转载于:ht ...
- zabbix如何添加图表显示内容_自定义 Zabbix 监控指标及图表
问题描述 有时候 Zabbix 监控系统的模版提供的监控指标并不能满足我们的需求,比如我们要监控服务器的线程数.TCP 连接数等,这些指标在 Zabbix 自带的模板中是没有的,这时候我们就需要自定义 ...
- gta5显示nat较为严格_报告显示,中国超七成企业正在使用灵活用工
(财见2020年12月4日讯)近日,上海外服联合人力资源智享会在线上共同发布<中国企业灵活用工全景路线图研究>,聚焦新冠疫情后异军突起的灵活用工模式,从灵活用工的开始与运用场景.数字化与灵 ...
- 通达信指标能用c语言编写吗_翔博精选指标看长做短,引用周线数据(通达信公式 副图 源码 测试图)...
问题:怎样才能每天都收到这类文章! 答案:只需点击上方<翔博软件工作室> 做价值的传播者,一路同行,一起成长 免费指标和实战干货持续更新中,欢迎关注 点赞 收藏视频号. 公式源码 看长,故 ...
- 九龙擒庄指标源码破译_九龙擒庄指标源码破译_破译股市密码
K线密码非原创(主图源码贴图) 您正在下载的是:破译K线密码非原创(主图源码贴图)破译K线密码其实就是趋势射线指标.本人认为是对趋势射线指标的用法作了很好的解释.3),L,3),L,0),7),H,7 ...
最新文章
- 【Ubuntu入门到精通系列讲解】常用其他命令(find ln tar apt)等速查
- Improved Alpha-Tested Magnification for Vector Textures and Special Effects
- linux 32库路径,linux – 共享库如何在64位/ 32位混合系统中工作?
- c语言cgi函数库,cgic: 为C语言编写CGI的C函数库
- python多线程操作列表_详解Python多线程下的list
- 使java代码更干净_java如何使用Lombok更优雅地编码
- Docker 容器互联 --link 和 自定义网络
- 关于caffe-ssd训练时smooth_L1到底参与运算与否的问题
- Chrome主页被篡改的一种解决方法
- 从GDPR和个保法看,为什么要做数据合规?
- simulink 菜单栏 不见了
- Lomo 照片特效 Lr 预设 Lomo Lightroom Presets
- html自定义弹窗,自定义弹窗为密文密码框(实现重新鉴别密码),一系列踩坑解决
- 量化投资 -- 技术篇(6)投资组合策略性能评价(上)
- 新疆工程学院计算机在哪个校区,2021年新疆大学有几个校区,大一新生在哪个校区...
- 阿里云服务器后台运行服务
- 查看Windows10系统版本的方法
- 基于PP-Human V2的闯入人员检测
- 华为美女小姐姐,被外派墨西哥后,发生的事...
- free_rtos系统基本配置