26-爬取链家二手房成交的房产信息【简单】
目的:爬取链家二手房成交的信息,包括:['cjxiaoqu','cjdanjia','cjhuxing','cjmianji','cjshijian','cjlouceng','cjchaoxiang','cjzhouqi'],即为['成交小区','成交单价','成交户型','成交面积','成交时间','成交楼层','成交朝向','成交周期']
结果呈现:(1)数据保存到lianjia.csv 【然后在文章分类“数据分析”中加上一篇数据分析:https://my.oschina.net/pansy0425/blog/3031736】
【!!!这个数据分析值得一看!!!】
(2)数据存放到数据库中【不难,只是平常多使用下数据库,可以增加记忆】
注:这个爬取比较简单,没有遇到反爬,而且网页信息都可以在相应的html文件中找到,所以就直接放代码啦~~~
#下面为本实例的爬虫代码,若有问题可以给我留言,或者有更好的解决方法也可以私信我~
前期mysql中的操作:【都是这个套路,是最基本的】
""" #在数据库中进行的操作 首先打开数据库管理权限:net start mysql56C:\WINDOWS\system32>mysql -u root -pEnter password: ********进入MySQL 新建数据库LianJiaInfo 新建表chengjiao 字段:id INT; cjxiaoqu VARCHAR(225); cjdanjia FLOAT; cjhuxing VARCHAR(225); cjmianji VARCHAR(225); cjshijian VARCHAR(225);cjlouceng VARCHAR(225); cjchaoxiang VARCHAR(225), cjzhouqi INT;mysql> CREATE DATABASE IF NOT EXISTS LianJiaInfo DEFAULT CHARSET utf8 COLLATE utf8_general_ci; #创建数据库 mysql> USE LianJiaInfo; mysql> CREATE TABLE chengjiao(-> id INT PRIMARY KEY AUTO_INCREMENT,-> cjxiaoqu VARCHAR(225),-> cjdanjia FLOAT,-> cjhuxing VARCHAR(225),-> cjmianji VARCHAR(225),-> cjshijian VARCHAR(225),-> cjlouceng VARCHAR(225),-> cjchaoxiang VARCHAR(225),-> cjzhouqi INT); mysql> DESCRIBE chengjiao; +-------------+--------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | cjxiaoqu | varchar(225) | YES | | NULL | | | cjdanjia | float | YES | | NULL | | | cjhuxing | varchar(225) | YES | | NULL | | | cjmianji | varchar(225) | YES | | NULL | | | cjshijian | varchar(225) | YES | | NULL | | | cjlouceng | varchar(225) | YES | | NULL | | | cjchaoxiang | varchar(225) | YES | | NULL | | | cjzhouqi | int(11) | YES | | NULL | | +-------------+--------------+------+-----+---------+----------------+ """
爬虫代码:【简单】
import json
import re
import csv
import requests
from bs4 import BeautifulSoup
import os
import pymysqlclass SJK():def __init__(self,db_name,table_name):self.db_name=db_name #数据库名称self.table_name=table_name #表名def save_to_database(self,info):db=pymysql.connect(host='localhost',port=3306,user='root',passwd='12345678',db=self.db_name,charset='utf8')cursor=db.cursor()sql="""INSERT INTO {} (cjxiaoqu,cjdanjia,cjhuxing,cjmianji,cjshijian,cjlouceng,cjchaoxiang,cjzhouqi) VALUES('{}','{}','{}','{}','{}','{}','{}','{}')""".format(self.table_name,info[0],info[1],info[2],info[3],info[4],info[5],info[6],info[7])try:cursor.execute(sql)db.commit()print('{}------存入数据库成功'.format(info[0]))except Exception as e:print(e)db.rollback()print('{}------存入数据库失败'.format(info[0]))class LJ():def __init__(self):self.headers={'user-agent':'Mozilla/5.0'}self.start_url='https://nj.lianjia.com/chengjiao/'self.sjk=SJK('LianJiaInfo','chengjiao') #这边传入的数据库以及表名,我自己固定死self.path_name='lianjia.csv'def get_page(self,url):try:r = requests.get(url, headers=self.headers)r.raise_for_status()r.encoding = r.apparent_encodingreturn r.textexcept Exception as e:print(e)def get_num(self,url):html=self.get_page(url)soup=BeautifulSoup(html,'html.parser')page=soup.find('div',{'class':{'house-lst-page-box'}})page_info=json.loads(page['page-data'])page_num=page_info["totalPage"] #int类型return page_numdef get_info(self,url):html=self.get_page(url)soup=BeautifulSoup(html,'html.parser')ul=soup.find('ul',{'class':'listContent'})for li in ul('li'):href=li('a')[0]['href'] #每个的成交记录的链接html=self.get_page(href)soup=BeautifulSoup(html,'html.parser')info1=soup.find('div',{'class':{'deal-bread'}})cjxiaoqu=info1('a')[2].text.strip()[0:-7] #成交小区 str 【从后往前取,小区名称的个数不相同】info2=soup.find('div',{'class':{'price'}})cjdanjia=float(info2('b')[0].text.strip()) #成交单价 floatinfo3=soup.find('div',{'class':{'wrapper'}})h1=info3('h1')[0].text.strip().split(' ')cjhuxing=h1[1] #成交户型 strcjmianji=h1[-1] #成交面积 strcjshijian=info3('span')[0].text.strip().split(' ')[0] #成交时间 strinfo4=soup.find('div',{'class':{'content'}})cjlouceng=info4('ul')[0]('li')[1].text.strip()[4:] #成交楼层 strcjchaoxiang = info4('ul')[0]('li')[6].text.strip()[4:] #成交朝向 strinfo5=soup.find('div',{'class':{'msg'}})cjzhouqi=info5('span')[1].text.strip()cjzhouqi=int(re.findall('(\d+)',cjzhouqi)[0]) #成交周期 intinfo=[cjxiaoqu,cjdanjia,cjhuxing,cjmianji,cjshijian,cjlouceng,cjchaoxiang,cjzhouqi]self.save_to_csv(info) #保存到csv文件,做后续的数据分析self.sjk.save_to_database(info) #保存到数据库,之后方便存取def save_to_csv(self,info):with open(self.path_name,'a',encoding='utf-8',newline="")as csv_f:csv_write=csv.writer(csv_f)if os.path.getsize(self.path_name)==0:csv_write.writerow(['cjxiaoqu','cjdanjia','cjhuxing','cjmianji','cjshijian','cjlouceng','cjchaoxiang','cjzhouqi'])else:csv_write.writerow(info)print('{}-----存入csv成功'.format(info[0]))csv_f.close()def main(self):page_num=self.get_num(self.start_url)for i in range(1,page_num+1): #page_num+1try:print('开始爬取第{}页'.format(i))page_url=self.start_url+'pg{}/'.format(i)self.get_info(page_url)except:continuelianjiao=LJ()
lianjiao.main()
屏幕显示: 【部分显示】
【部分显示】
lianjia.csv文件中显示: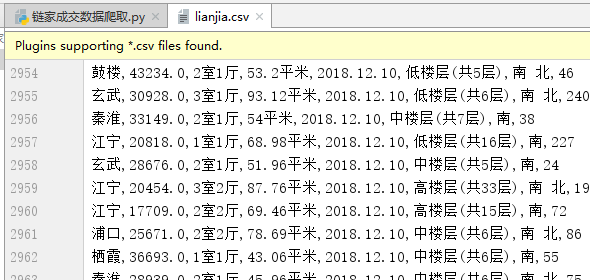 【部分显示】
【部分显示】
数据库中显示: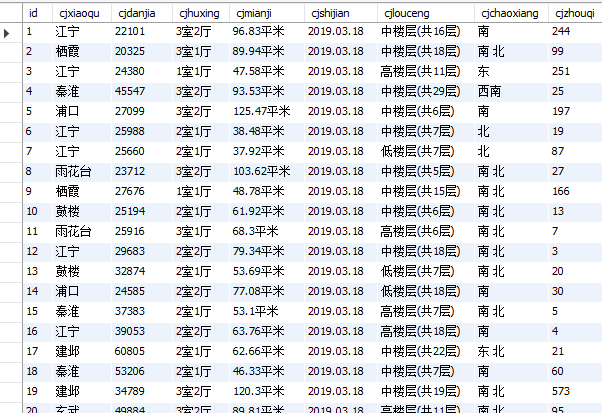 【部分显示】
【部分显示】
---------(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)(。・ω・。)----------
今日爬虫完成!
今日鸡汤:眼光放长远,格局拓宽点,见识独到些,千万不要人云亦云,随波逐流,自己的风格自己负责,自己的境界自己造就。
加油ヾ(◍°∇°◍)ノ゙
转载于:https://my.oschina.net/pansy0425/blog/3031621
26-爬取链家二手房成交的房产信息【简单】相关推荐
- python关于二手房的课程论文_基于python爬取链家二手房信息代码示例
基本环境配置 python 3.6 pycharm requests parsel time 相关模块pip安装即可 确定目标网页数据 哦豁,这个价格..................看到都觉得脑阔 ...
- python-scrapy-MongoDB 爬取链家二手房
python-scrapy-MongoDB 爬取链家二手房 链家二手房房源数据抓取 目标网址为http://bj.lianjia.com/ershoufang/ 分析网址 创建项目 scrapy st ...
- 租房不入坑不进坑,Python爬取链家二手房的数据,提前了解租房信息
目录 前言 一.查找数据所在位置: 二.确定数据存放位置: 三.获取html数据: 四.解析html,提取有用数据: 前言 贫穷限制了我的想象,从大学进入到社会这么久,从刚开始的兴致勃勃,觉得钱有什么 ...
- 掌财社:python怎么爬取链家二手房的数据?爬虫实战!
我们知道爬虫的比较常见的应用都是应用在数据分析上,爬虫作为数据分析的前驱,它负责数据的收集.今天我们以python爬取链家二手房数据为例来进行一个python爬虫实战.(内附python爬虫源代码) ...
- 爬取链家网站中的租房信息
爬取链家网站中的租房信息 信息爬取代码 信息爬取代码 import requests from lxml import etree import pandas as pdwith open('zufa ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- 爬取链家北京租房数据并做简单分析
在一个来北京不久的学生眼中,北京是一个神秘又充满魅力的大城市.它无比美好,但又无时无刻不再觊觎这你薄弱的钱包. 租房是很多人都离不开的硬性需求,这里就对从链家爬取的北京地区房屋出租数据进行一个简单分析 ...
- 爬取链家网站的北京租房信息
本来准备这个暑假好好复习,但学校安排暑期实践,既然学校安排这个,而且我自己也觉得需要提高一下自己的能力,所以静下心来做点事吧.我们要做到项目是分析北京地区的租房的信息分析. 我们需要做的是爬取链家网站 ...
- Python 爬取链家二手房,我在北京买房的经历
本节所讲内容: 链家网站前期分析 利用requests爬取数据 爬取数据存储MongoDB(代码请看最后) 链家网站前期分析 今天我们主要对链家二手房数据爬取,看下我们目前的资金能买那一套.链家二手房 ...
最新文章
- shell expect的简单用法
- numpy rollaxis理解
- OpenGL窗口属性
- 《统计学》学习笔记之数据的收集
- 虚拟服务器 cms安装,轻量化云服务器怎么安装cms
- 电子商务时代企业统计的发展方向
- android 使用AIDL实现进程间通讯
- sqlite3的backup和restore函数的使用
- linux 录屏软件 按键,linux下常用的截图、录屏工具
- 基于SVM的python简单实现验证码识别
- 特斯拉将美国政府告了:要求停止对华关税并退款!
- mysql 浮点类型和定点_mysql 中的浮点和定点类型
- python中如何下载安装库
- ssh 免密配置、修改hadoop配置文件
- php生成手写字,钢笔手写体生成工具(PHP)V1.0[原创]
- 计算机技术与软件专业技术资格(水平)考试指南
- WAF防火墙是什么呢
- 编译器与Debug的传奇:Grace Murray Hopper小传
- android国际化语言编码对照表
- Java中日志的使用