python 直方图的绘制方法全解_5种方法教你用Python玩转histogram直方图
原标题:5种方法教你用Python玩转histogram直方图
作者 | xiaoyu
知乎 | https://zhuanlan.zhihu.com/pypcfx
介绍 | 一个半路转行的数据挖掘工程师
直方图是一个可以快速展示数据概率分布的工具,直观易于理解,并深受数据爱好者的喜爱。大家平时可能见到最多就是matplotlib,seaborn等高级封装的库包,类似以下这样的绘图。
本篇博主将要总结一下使用Python绘制直方图的所有方法,大致可分为三大类(详细划分是五类,参照文末总结):
纯Python实现直方图,不使用任何第三方库
使用Numpy来创建直方图总结数据
使用matplotlib,pandas,seaborn绘制直方图
下面,我们来逐一介绍每种方法的来龙去脉。
纯Python实现histogram
当准备用纯Python来绘制直方图的时候,最简单的想法就是将每个值出现的次数以报告形式展示。这种情况下,使用字典来完成这个任务是非常合适的,我们看看下面代码是如何实现的。
>>> a = ( 0, 1, 1, 1, 2, 3, 7, 7, 23)
>>> defcount_elements(seq)-> dict:
... """Tally elements from `seq`."""
... hist = {}
... fori inseq:
... hist[i] = hist.get(i, 0) + 1
... returnhist
>>> counted = count_elements(a)
>>> counted
{ 0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}
我们看到,count_elements()返回了一个字典,字典里出现的键为目标列表里面的所有唯一数值,而值为所有数值出现的频率次数。hist[i] = hist.get(i, 0) + 1实现了每个数值次数的累积,每次加一。
实际上,这个功能可以用一个Python的标准库collection.Counter类来完成,它兼容Pyhont 字典并覆盖了字典的.update()方法。
>>> from collections import Counter
>>> recounted = Counter(a)
>>> recounted
Counter({ 0: 1, 1: 3, 3: 1, 2: 1, 7: 2, 23: 1})
可以看到这个方法和前面我们自己实现的方法结果是一样的,我们也可以通过collection.Counter来检验两种方法得到的结果是否相等。
>>> recounted.items() == counted.items()
True
我们利用上面的函数重新再造一个轮子ASCII_histogram,并最终通过Python的输出格式format来实现直方图的展示,代码如下:
defascii_histogram(seq)-> None:
"""A horizontal frequency-table/histogram plot."""
counted = count_elements(seq)
fork insorted(counted):
print( '{0:5d} {1}'.format(k, '+'* counted[k]))
这个函数按照数值大小顺序进行绘图,数值出现次数用(+)符号表示。在字典上调用sorted()将会返回一个按键顺序排列的列表,然后就可以获取相应的次数counted[k]。
>>> import random
>>> random.seed( 1)
>>> vals = [ 1, 3, 4, 6, 8, 9, 10]
>>> # `vals` 里面的数字将会出现5到15次
>>> freq = (random.randint( 5, 15) for _in vals)
>>> data = []
>>> for f, v in zip(freq, vals):
... data.extend([v] * f)
>>> ascii_histogram(data)
1+++++++
3++++++++++++++
4++++++
6+++++++++
8++++++
9++++++++++++
10++++++++++++
这个代码中,vals内的数值是不重复的,并且每个数值出现的频数是由我们自己定义的,在5和15之间随机选择。然后运用我们上面封装的函数,就得到了纯Python版本的直方图展示。
总结:纯python实现频数表(非标准直方图),可直接使用collection.Counter方法实现。
使用Numpy实现histogram
以上是使用纯Python来完成的简单直方图,但是从数学意义上来看,直方图是分箱到频数的一种映射,它可以用来估计变量的概率密度函数的。而上面纯Python实现版本只是单纯的频数统计,不是真正意义上的直方图。
因此,我们从上面实现的简单直方图继续往下进行升级。一个真正的直方图首先应该是将变量分区域(箱)的,也就是分成不同的区间范围,然后对每个区间内的观测值数量进行计数。恰巧,Numpy的直方图方法就可以做到这点,不仅仅如此,它也是后面将要提到的matplotlib和pandas使用的基础。
举个例子,来看一组从拉普拉斯分布上提取出来的浮点型样本数据。这个分布比标准正态分布拥有更宽的尾部,并有两个描述参数(location和scale):
>>> import numpy as np
>>> np.random.seed( 444)
>>> np.set_printoptions(precision= 3)
>>> d = np.random.laplace(loc= 15, scale= 3, size= 500)
>>> d[ :5]
array([ 18.406, 18.087, 16.004, 16.221, 7.358])
由于这是一个连续型的分布,对于每个单独的浮点值(即所有的无数个小数位置)并不能做很好的标签(因为点实在太多了)。但是,你可以将数据做分箱处理,然后统计每个箱内观察值的数量,这就是真正的直方图所要做的工作。
下面我们看看是如何用Numpy来实现直方图频数统计的。
>>> hist, bin_edges = np.histogram(d)
>>> hist
array([ 1, 0, 3, 4, 4, 10, 13, 9, 2, 4])
>>> bin_edges
array([ 3.217, 5.199, 7.181, 9.163, 11.145, 13.127, 15.109, 17.091,
19.073, 21.055, 23.037])
这个结果可能不是很直观。来说一下,np.histogram()默认地使用10个相同大小的区间(箱),然后返回一个元组(频数,分箱的边界),如上所示。要注意的是:这个边界的数量是要比分箱数多一个的,可以简单通过下面代码证实。
>>> hist.size, bin_edges.size
(10, 11)
那问题来了,Numpy到底是如何进行分箱的呢?只是通过简单的 np.histogram()就可以完成了,但具体是如何实现的我们仍然全然不知。下面让我们来将 np.histogram()的内部进行解剖,看看到底是如何实现的(以最前面提到的a列表为例)。
>>> # 取a的最小值和最大值
>>> first_edge, last_edge = a.min(), a.max()
>>> n_equal_bins = 10# NumPy得默认设置,10个分箱
>>> bin_edges = np.linspace(start=first_edge, stop=last_edge,
... num=n_equal_bins + 1, endpoint=True)
...
>>> bin_edges
array([ 0. , 2.3, 4.6, 6.9, 9.2, 11.5, 13.8, 16.1, 18.4, 20.7, 23. ])
解释一下:首先获取a列表的最小值和最大值,然后设置默认的分箱数量,最后使用Numpy的linspace方法进行数据段分割。分箱区间的结果也正好与实际吻合,0到23均等分为10份,23/10,那么每份宽度为2.3。
除了np.histogram之外,还存在其它两种可以达到同样功能的方法:np.bincount()和np.searchsorted(),下面看看代码以及比较结果。
>>> bcounts = np.bincount(a)
>>> hist, _= np.histogram(a, range=( 0, a.max()), bins=a.max() + 1)
>>> np.array_equal(hist, bcounts)
True
>>> # Reproducing `collections.Counter`
>>> dict(zip(np.unique(a), bcounts[bcounts.nonzero()]))
{ 0: 1, 1: 3, 2: 1, 3: 1, 7: 2, 23: 1}
总结:通过Numpy实现直方图,可直接使用np.histogram()或者np.bincount()。
使用Matplotlib和Pandas可视化Histogram
从上面的学习,我们看到了如何使用Python的基础工具搭建一个直方图,下面我们来看看如何使用更为强大的Python库包来完成直方图。Matplotlib基于Numpy的histogram进行了多样化的封装并提供了更加完善的可视化功能。
importmatplotlib.pyplot asplt
# matplotlib.axes.Axes.hist() 方法的接口
n, bins, patches = plt.hist(x=d, bins= 'auto', color= '#0504aa',
alpha= 0.7, rwidth= 0.85)
plt.grid(axis= 'y', alpha= 0.75)
plt.xlabel( 'Value')
plt.ylabel( 'Frequency')
plt.title( 'My Very Own Histogram')
plt.text( 23, 45, r'$mu=15, b=3$')
maxfreq = n.max()
# 设置y轴的上限
plt.ylim(ymax=np.ceil(maxfreq / 10) * 10ifmaxfreq % 10elsemaxfreq + 10)
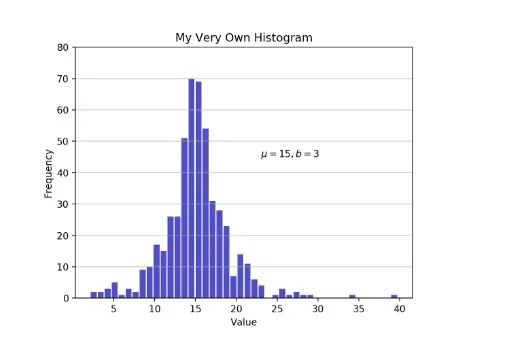
之前我们的做法是,在x轴上定义了分箱边界,y轴是相对应的频数,不难发现我们都是手动定义了分箱的数目。但是在以上的高级方法中,我们可以通过设置bins='auto'自动在写好的两个算法中择优选择并最终算出最适合的分箱数。这里,算法的目的就是选择出一个合适的区间(箱)宽度,并生成一个最能代表数据的直方图来。
如果使用Python的科学计算工具实现,那么可以使用Pandas的Series.histogram(),并通过matplotlib.pyplot.hist()来绘制输入Series的直方图,如下代码所示。
importpandas aspd
size, scale = 1000, 10
commutes = pd.Series(np.random.gamma(scale, size=size) ** 1.5)
commutes.plot.hist(grid= True, bins= 20, rwidth= 0.9,
color= '#607c8e')
plt.title( 'Commute Times for 1,000 Commuters')
plt.xlabel( 'Counts')
plt.ylabel( 'Commute Time')
plt.grid(axis= 'y', alpha= 0.75)
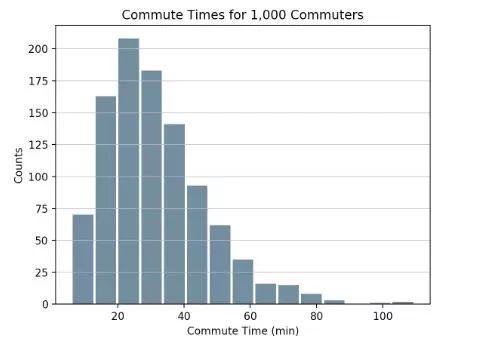
pandas.DataFrame.histogram()的用法与Series是一样的,但生成的是对DataFrame数据中的每一列的直方图。
总结:通过pandas实现直方图,可使用Seris.plot.hist(),DataFrame.plot.hist(),matplotlib实现直方图可以用matplotlib.pyplot.hist()。
绘制核密度估计(KDE)
KDE(Kernel density estimation)是核密度估计的意思,它用来估计随机变量的概率密度函数,可以将数据变得更平缓。
使用Pandas库的话,你可以使用plot.kde()创建一个核密度的绘图,plot.kde() 对于 Series和DataFrame数据结构都适用。但是首先,我们先生成两个不同的数据样本作为比较(两个正太分布的样本):
>>> # 两个正太分布的样本
>>> means = 10, 20
>>> stdevs = 4, 2
>>> dist = pd.DataFrame(
... np.random.normal(loc=means, scale=stdevs, size=( 1000, 2)),
... columns=[ 'a', 'b'])
>>> dist.agg([ 'min', 'max', 'mean', 'std']).round(decimals= 2)
a b
min - 1.5712.46
max 25.3226.44
mean 10.1219.94
std 3.941.94
以上看到,我们生成了两组正态分布样本,并且通过一些描述性统计参数对两组数据进行了简单的对比。现在,我们可以在同一个Matplotlib轴上绘制每个直方图以及对应的kde,使用pandas的plot.kde()的好处就是:它会自动的将所有列的直方图和kde都显示出来,用起来非常方便,具体代码如下:
fig, ax = plt.subplots()
dist.plot.kde(ax=ax, legend= False, title= 'Histogram: A vs. B')
dist.plot.hist(density= True, ax=ax)
ax.set_ylabel( 'Probability')
ax.grid(axis= 'y')
ax.set_facecolor( '#d8dcd6')
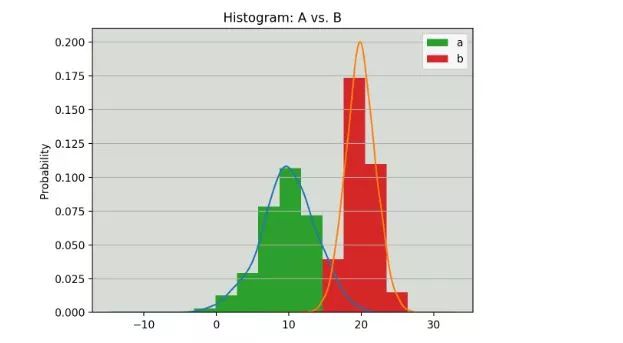
总结:通过pandas实现kde图,可使用Seris.plot.kde(),DataFrame.plot.kde()。
使用Seaborn的完美替代
一个更高级可视化工具就是Seaborn,它是在matplotlib的基础上进一步封装的强大工具。对于直方图而言,Seaborn有 distplot() 方法,可以将单变量分布的直方图和kde同时绘制出来,而且使用及其方便,下面是实现代码(以上面生成的d为例):
importseaborn assns
sns.set_style( 'darkgrid')
sns.distplot(d)
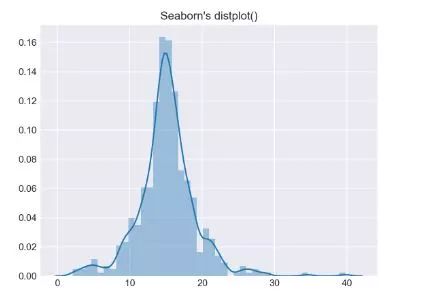
distplot方法默认的会绘制kde,并且该方法提供了fit参数,可以根据数据的实际情况自行选择一个特殊的分布来对应。
sns.distplot(d, fit=stats.laplace, kde= False)
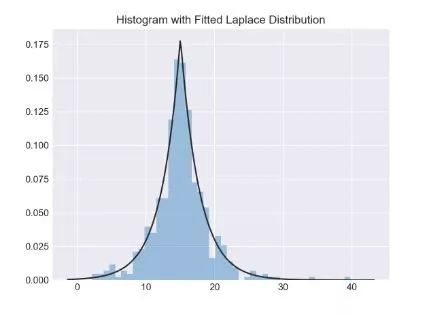
注意这两个图微小的区别。第一种情况你是在估计一个未知的概率密度函数(PDF),而第二种情况是你是知道分布的,并想知道哪些参数可以更好的描述数据。
总结:通过seaborn实现直方图,可使用seaborn.distplot(),seaborn也有单独的kde绘图seaborn.kde()。
在Pandas中的其它工具
除了绘图工具外,pandas也提供了一个方便的.value_counts()方法,用来计算一个非空值的直方图,并将之转变成一个pandas的series结构,示例如下:
>>> import pandas as pd
>>> data = np.random.choice(np.arange( 10), size= 10000,
... p=np.linspace( 1, 11, 10) / 60)
>>> s = pd.Series(data)
>>> s.value_counts()
91831
81624
71423
61323
51089
4888
3770
2535
1347
0170
dtype:int64
>>> s.value_counts(normalize=True).head()
90. 1831
80. 1624
70. 1423
60. 1323
50. 1089
dtype:float64
此外,pandas.cut()也同样是一个方便的方法,用来将数据进行强制的分箱。比如说,我们有一些人的年龄数据,并想把这些数据按年龄段进行分类,示例如下:
>>> ages = pd.Series(
... [ 1, 1, 3, 5, 8, 10, 12, 15, 18, 18, 19, 20, 25, 30, 40, 51, 52])
>>> bins = ( 0, 10, 13, 18, 21, np.inf) # 边界
>>> labels = ( 'child', 'preteen', 'teen', 'military_age', 'adult')
>>> groups = pd.cut(ages, bins=bins, labels=labels)
>>> groups.value_counts()
child 6
adult 5
teen 3
military_age 2
preteen 1
dtype:int64
>>> pd.concat((ages, groups), axis= 1).rename(columns={ 0: 'age', 1: 'group'})
age group
01child
11child
23child
35child
48child
510child
612preteen
715teen
818teen
918teen
1019military_age
1120military_age
1225adult
1330adult
1440adult
1551adult
1652adult
除了使用方便外,更加好的是这些操作最后都会使用Cython代码来完成,在运行速度的效果上也是非常快的。
总结:其它实现直方图的方法,可使用.value_counts()和pandas.cut()。
该使用哪个方法?
至此,我们了解了很多种方法来实现一个直方图。但是它们各自有什么有缺点呢?该如何对它们进行选择呢?当然,一个方法解决所有问题是不存在的,我们也需要根据实际情况而考虑如何选择,下面是对一些情况下使用方法的一个推荐,仅供参考。
你的情况
推荐使用
备注
有清晰的整数型数据在列表,元组,或者集合的数据结构中,并且你不想引入任何第三方那个库
标准库Collection.counter()提供了快速直接的频数实现方法
这只是频数的一个表,不存在histogram真正意义上的分箱
大的数组数据,并且你只是想要计算含有分箱的直方图(无可视化,纯数学计算)
Numpy的np.histogram()和np.bincount()对于直方图的纯数学计算时非常有帮助的
更多请查阅np.digitize()
数据存在于在Pandas的Series和DataFrame对象中
Pandas方法,比如, Series.plot.hist(),DataFrame.plot.hist(),Series.value_counts(),and cut(),Series.plot.kde()以及DataFrame.plot.kde()
参考pandas的visualization章节
从任意数据结构中,创建一个高度定制化可调节的直方图
推荐使用基于np.histogram()的Pyplot.hist()函数,被频繁使用,简单易懂。
Matplotlib可定制化
提前封装的设计和集成(而非定制的)
Seaborn的distplot(),可以方便的结合直方图和KDE绘图
高级封装
参考:https://realpython.com/python-histograms/
以上就是本篇所有内容,直方图的各种玩法你get到了吗?返回搜狐,查看更多
责任编辑:
python 直方图的绘制方法全解_5种方法教你用Python玩转histogram直方图相关推荐
- Python可视化 | Matplotlib绘制圆环图的两种方法!
人生苦短,快学Python!今天给大家介绍Python可视化之环形图的绘制. 环形图,也被称为圆环图.它在功能上与饼图相同,只是中间有一个空白,并且能够同时支持多个统计数据.与标准饼图相比,环形图提供 ...
- python数据分析——pyecharts折线图全解
折线图是排列在工作表的列或行中的数据可以绘制到折线图中.折线图可以显示随时间(根据常用比例设置)而变化的连续数据,因此非常适用于显示在相等时间间隔下数据的趋势. 下面我给大家介绍一下如何用pyecha ...
- python中的format什么意思中文-Python中format()格式输出全解
格式化输出:format() format():把传统的%替换为{}来实现格式化输出 1.使用位置参数:就是在字符串中把需要输出的变量值用{}来代替,然后用format()来修改使之成为想要的字符串, ...
- python基础教程zip密码_python基础教程Python实现加密的RAR文件解压的方法(密码已知)...
博主之前在网上找了很多资料,发现rarfile库不能直接调用,需要安装unrar模块,下面将详细介绍整个实现流程. 第一步:安装unrar模块,直接pip install unrar可能会找不到库,需 ...
- python画波浪线_PPT绘制波浪线的四种方法
在开始学习教程前,先欣赏两幅画.画面中的波浪线使用的恰到好处,给整个画面增添张力与活力.那么用PPT能绘制出柔美的波浪线吗?答案当然是肯定的!一共四种方法,本文图文详解使用PPT绘制波浪线的四种方法. ...
- Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)—命令提示符cmd的几种方法
Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)-命令提示符cmd的几种方法 目录 利用python语言实现调用内部命令-命令提示符cmd的几种方法 T1. ...
- python调用C语言函数(方法)的几种方法
1. 使用ctypes 可能是Python调用C方法中最简单的一种 2. 使用SWIG 是Python中调用C代码的另一种方法.在这个方法中,开发人员必须编写一个额外的接口文件来作为SWIG的入口. ...
- python去重复元素_Python实现去除列表中重复元素的方法总结【7种方法】
这里首先给出来我很早之前写的一篇博客,Python实现去除列表中重复元素的方法小结[4种方法],感兴趣的话可以去看看,今天是在实践过程中又积累了一些方法,这里一并总结放在这里. 由于内容很简单,就不再 ...
- python怎么清屏_python实现清屏的方法 Python Shell中清屏一般有两种方法。
Python Shell 怎样清屏? Python Shell中清屏一般有两种方法. 奈何一个人随着年龄增长,梦想便不复轻盈:他开始用双手掂量生活,更看重果实而非花朵.--叶芝<凯尔特的搏暮&g ...
- C语言中三个数比较大小详解——三种方法
C语言中三个数比较大小详解--三种方法 方法一:if-else法 方法二:函数法 方法三:三目运算符法 C语言中比较三个数的大小有很多方法,以下是我总结的三种方法: 首先我定义 int a = 1 ...
最新文章
- 【2020年BNN网络的SOTA—— ReActNet 】以简单的操作得到更高精度的二值神经网络
- Linux下的I/O
- 微信抢红包应用要哭了,让我们来给微信红包设计一个新交互
- SLAM中有关占据栅格地图的的表示方法和利用激光传感器构建占据栅格地图的方法
- .Net 分布式云平台基础服务建设说明概要
- C++ 运算符重载(二) | 类型转换运算符,二义性问题
- online游戏服务器架构--网络架构
- Sublime text 入门学习资源篇及其基本使用方法
- python 编程模型
- Python获取当前目录
- 官方 STM32F303ZE Nucleo-144开发板 点亮led
- .net实现调用本地exe等应用程序的办法总结
- Consul注册中心删除某个服务
- 【密码学基础】02 数论基础
- 如何做好DevOps Secrets管理
- 交换机和路由器的关系
- Linux的markdown笔记软件,3款免费好用的Markdown笔记应用,可以替代印象笔记
- APFS 强在哪里?
- 中国企业领导力培训行业市场供需与战略研究报告
- 【模块图】软件-系统架构-模块图
热门文章
- 如何在eclipse中配置反编译工具JadClipse
- windows版redis报错:本地计算机上的Redis服务启动后停止
- NSOJ 一个人的旅行(图论)
- Git 命令行(cygwin) + Git Extensions + Git Source Control Provider
- InnoDB Plugin 1.0.2 for MySQL 5.1.30 (GA) Released
- 转盘抽奖的案例-----
- RN Adatper_Util工具类
- pandas读取csv文件数据并使用matplotlib画折线图和饼图
- ELK logstash的grok 自带的正则匹配
- PHPStorm常用快捷方式