python爬新闻并保存csv_Python简单爬虫导出CSV文件的实例讲解
流程:模拟登录→获取Html页面→正则解析所有符合条件的行→逐一将符合条件的行的所有列存入到CSVData[]临时变量中→写入到CSV文件中
核心代码:
####写入Csv文件中
with open(self.CsvFileName, 'wb') as csvfile:
spamwriter = csv.writer(csvfile, dialect='excel')
#设置标题
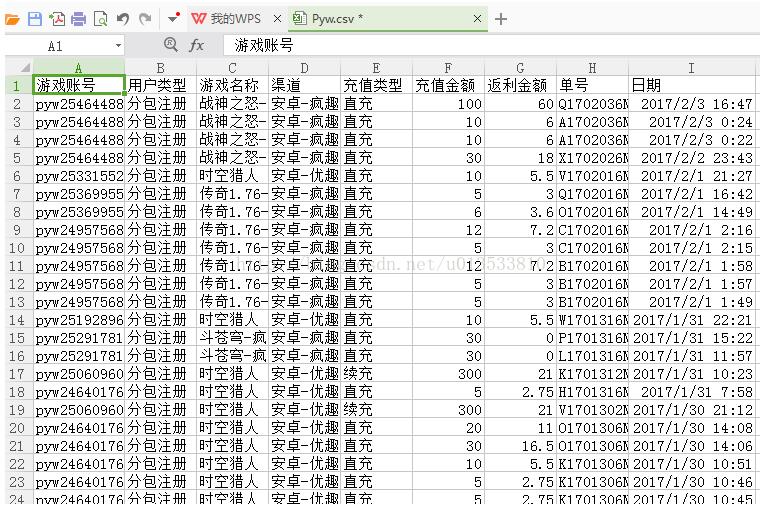
spamwriter.writerow(["游戏账号","用户类型","游戏名称","渠道","充值类型","充值金额","返利金额","单号","日期"])
#将CsvData中的数据循环写入到CsvFileName文件中
for item in self.CsvData:
spamwriter.writerow(item)
完整代码:
# coding=utf-8
import urllib
import urllib2
import cookielib
import re
import csv
import sys
class Pyw():
#初始化数据
def __init__(self):
#登录的Url地址
self.LoginUrl="http://v.pyw.cn/login/check"
#所要获取的Url地址
self.PageUrl="http://v.pyw.cn/Data/accountdetail/%s"
# 传输的数据:用户名、密码、是否记住用户名
self.PostData = urllib.urlencode({
"username": "15880xxxxxx",
"password": "a123456",
"remember": "1"
})
#第几笔记录
self.PageIndex=0;
#循环获取共4页内容
self.PageTotal=1
#正则解析出tr
self.TrExp=re.compile("(?isu)
")
#正则解析出td
self.TdExp = re.compile("(?isu)
]*>(.*?)")
#创建cookie
self.cookie = cookielib.CookieJar()
#构建opener
self.opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookie))
#解析页面总页数
self.Total=4
#####设置csv文件
self.CsvFileName="Pyw.csv"
#####存储Csv数据
self.CsvData=[]
#解析网页中的内容
def GetPageItem(self,PageHtml):
#循环取出Table中的所有行
for row in self.TrExp.findall(PageHtml):
#取出当前行的所有列
coloumn=self.TdExp.findall(row)
#判断符合的记录
if len(coloumn) == 9:
# print "游戏账号:%s" % coloumn[0].strip()
# print "用户类型:%s" % coloumn[1].strip()
# print "游戏名称:%s" % coloumn[2].strip()
# print "渠道:%s" % coloumn[3].strip()
# print "充值类型:%s" % coloumn[4].strip()
# print "充值金额:%s" % coloumn[5].strip().replace("¥", "")
# print "返利金额:%s" % coloumn[6].strip().replace("¥", "")
# print "单号:%s" % coloumn[7].strip()
# print "日期:%s" % coloumn[8].strip()
#拼凑行数据
d=[coloumn[0].strip(),
coloumn[1].strip(),
coloumn[2].strip(),
coloumn[3].strip(),
coloumn[4].strip(),
coloumn[5].strip().replace("¥", ""),
coloumn[6].strip().replace("¥", ""),
coloumn[7].strip(),
coloumn[8].strip()]
self.CsvData.append(d)
#模拟登录并获取页面数据
def GetPageHtml(self):
try:
#模拟登录
request=urllib2.Request(url=self.LoginUrl,data=self.PostData)
ResultHtml=self.opener.open(request)
#开始执行获取页面数据
while self.PageTotal<=self.Total:
#动态拼凑所要解析的Url
m_PageUrl = self.PageUrl % self.PageTotal
#计算当期第几页
self.PageTotal = self.PageTotal + 1
#获取当前解析页面的所有内容
ResultHtml=self.opener.open(m_PageUrl)
#解析网页中的内容
self.GetPageItem(ResultHtml.read())
####写入Csv文件中
with open(self.CsvFileName, 'wb') as csvfile:
spamwriter = csv.writer(csvfile, dialect='excel')
#设置标题
spamwriter.writerow(["游戏账号","用户类型","游戏名称","渠道","充值类型","充值金额","返利金额","单号","日期"])
#将CsvData中的数据循环写入到CsvFileName文件中
for item in self.CsvData:
spamwriter.writerow(item)
print "成功导出CSV文件!"
except Exception,e:
print "404 error!%s" % e
#实例化类
p=Pyw()
#执行方法
p.GetPageHtml()
导出结果
以上这篇Python简单爬虫导出CSV文件的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持脚本之家。
python爬新闻并保存csv_Python简单爬虫导出CSV文件的实例讲解相关推荐
- python pandas 处理相同标题的csv文件_Python使用pandas处理CSV文件的实例讲解
Python中有许多方便的库可以用来进行数据处理,尤其是Numpy和Pandas,再搭配matplot画图专用模块,功能十分强大. CSV(Comma-Separated Values)格式的文件是指 ...
- 使用python爬取中国电影票房数据并写入csv文件
环境 PyCharm 2021.1.2 x64 爬取的目标网页 一.代码 import requests from bs4 import BeautifulSoup url = "http: ...
- python将输出结果写入csv_python - 将输出写入CSV文件[处于保留状态] - 堆栈内存溢出...
我已经建立了一个对象检测模型来检测视频帧中的一些对象.它可以正常工作,但是我无法将输出数据写入到csv文件中 我已经编写了用于对象检测的代码,并将检测的一些输出参数写入csv文件. from __fu ...
- python爬新闻并保存_利用python的scrapy爬取新浪新闻保存至txt
1.mac本机terminal:scrapy startproject newsSpider 2.pycharm中打开项目,进行爬虫. 2.1在spider文件夹下,建立Spider.py文件,具体如 ...
- python爬新闻并保存csv_用python爬取内容怎么存入 csv 文件中
小白一个,爬取豆瓣电影250作为练习,想把爬取的内容用csv存储,想存但是不知道怎么自己原来代码拼接在一起. ps:非伸手党,查阅了官方文档,也做了csv读写的练习,就是拼不到一起,不知道该怎么改.求 ...
- python爬虫源码下载 视频_Python爬虫下载视频文件部分源码
importrequestsimporttime headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebK ...
- python股票回测源码_Python爬虫回测股票的实例讲解
股票和基金一直是热门的话题,很多周围的人都选择不同种类的理财方式.就股票而言,肯定是短时间内收益最大化,这里我们需要用python爬虫的方法,来帮助我们获取一些股票的数据,这样才能更好的买到相应的股票 ...
- python爬取图片然后保存在文件夹中
python爬取图片然后保存在文件夹中 直接上代码: import os import requests import redef getimg(soup,i):print('http:'+ soup ...
- python回测工具_Python爬虫回测股票的实例讲解
股票和基金一直是热门的话题,很多周围的人都选择不同种类的理财方式.就股票而言,肯定是短时间内收益最大化,这里我们需要用python爬虫的方法,来帮助我们获取一些股票的数据,这样才能更好的买到相应的股票 ...
- python识别手写文字_Python3实现简单可学习的手写体识别(实例讲解)
1.前言 版本:Python3.6.1 + PyQt5 + SQL Server 2012 以前一直觉得,机器学习.手写体识别这种程序都是很高大上很难的,直到偶然看到了这个视频,听了老师讲的思路后,瞬 ...
最新文章
- 第八周项目一-数组作数据成员(2)
- (解决)can't connect to redis-server
- tomcat登录账户配置
- 最近学习安卓中总结的一些知识点
- docker端口映射但外网无法访问解决方案
- Android Studio更新后导入项目报错问题解决(Minimum supported Gradle version is ×.×.×. Current version is ×.×.× )
- 车载网络测试 - UDS诊断篇 - 故障码(DTC)
- 动态规划——多重背包问题
- 一份黑椒牛肉饭引发的瞎想
- 技术背景的创业者由于其秉性容易犯三种错误
- Xgboost如何处理缺失值
- 桌游“德国心脏病”的python代码实现
- 基于Bootstrap简洁的后台UI框架
- CFA一级学习笔记--固定收益(三)--估值
- NIPTeR包分析 NIPT
- 怎样获取微信收款码免费提现(非邀请用户也可以)
- PS cs5切片工具的使用
- 使用Git提交代码到Gitee,上传、修改文件后没有绿色、红色图标提示
- 运筹说 第25期 | 对偶理论经典例题讲解
- Linux中常用的虚拟网卡
热门文章
- 花在照顾子女上的时间对父亲自己的大脑具有可塑性?
- 【arXiv 2021】Cluster Contrast for Unsupervised Person Re-Identification(CCU)
- [Maven]讲讲它的构建生命周期和拉取 jar 包流程
- 国内提供paas平台的有_国内十大paas平台
- 香橙派借助语音模块实现语音刷抖音
- 1050Ti 安装CUDA、cuDNN
- JAVA 生成二维码 并设置 +失效机制
- lae界面开发工具入门之介绍四--秘籍篇-拷贝粘贴
- ML之SHAP:机器学习可解释性之SHAP值的高级使用之聚合SHAP值以获得更详细的模型见解
- mysql sending data 耗时_mysql sending data状态时间花费太大