某专利检索分析系统设计回顾
ES版本选择:1.6.0(当时的最新版本)
系统部署:
- 该引擎以webservice的形式对外提供服务,与web系统隔离
- 如何限制访问数量
- 引擎线程池限制同时查询数量,拒绝超量(抛异常,捕获到返回查询等待)
系统限制:
- 服务真正使用系统的用户(客户要求),
- 查询条件大于6个字
- 系统限制检索结果大于1000的结果进行缓存<!!!不要缓存>
- 历史页面再次查询时,大于1000的必须优化查询条件
系统分为三部分:
- 数据预处理
- 检索系统
- 历史缓存
- 分析系统
数据预处理:
首先数据是从国家知识产权局购买的原始数据,根据申请号分成若干级的文件夹,申请号文件夹下数据内容由xml文件、pdf、图片等文件组成
- 检索数据预处理
- 检索数据包括:
- 专利名称、摘要、权利要求、说明书、法律状态
- 申请日期、公开日期、授权日期
- 申请号、公开号、授权号
- 分类号(外观分类、国际分类)
- 申请人、当前专利人、发明人、代理人、代理机构
- 申请人地址
- 将上述字段预存入ES中,建立索引
- 注意:
- 文本类分词建索引(jieba分词)
- 编号类完整建索引
- 人名称按照逗号分隔建索引
- 注意:
- 检索数据包括:
- 分析数据预处理
- 分析数据包括:
- 申请日期、公开日期、授权日期
- 法律状态
- 分类号(外观分类、国际分类)
- 申请人、当前专利人、发明人、代理人、代理机构
- 申请人省市编号
- 将上述数据预存入Redis中(检索结果大于1000的不予分析)
- 申请号为key,hash类型存储
- 分析数据包括:
检索系统:
检索系统分为索引建立和搜索两部分
- 索引建立
- 建立索引需要注意:有的字段需要分词、有的不需要、有的需要特定字符串分词(比如:多个发明人是逗号隔开的)
- "index":"not_analyzed", //analyzed:编入索引供搜索、no:不编入索引、not_analyzed(string专有):不经分析编入索引
- 比如每个字段选择一个分词器
- 自带分词器包括:
- https://blog.csdn.net/xiaomin1991222/article/details/50981874
- keyword(不分词,内容整体作为一个token(not_analyzed))
- whitespace(以空格为分隔符拆分)
- pattern(定义分隔符的正则表达式)
- https://blog.csdn.net/xiaomin1991222/article/details/50981874
- 自带分词器包括:
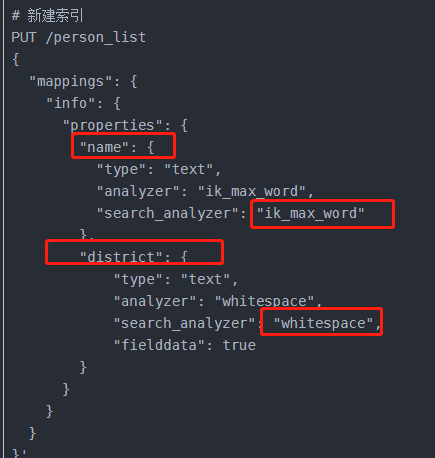
- 比如每个字段选择一个分词器
- "boost":"1", //文档中该字段的重要性,值越大表示越重要,默认1
- "index":"not_analyzed", //analyzed:编入索引供搜索、no:不编入索引、not_analyzed(string专有):不经分析编入索引
- 建立索引需要注意:有的字段需要分词、有的不需要、有的需要特定字符串分词(比如:多个发明人是逗号隔开的)
快速查询和高级查询(二次检索,就是将第二次检索条件拼接第一次检索条件)
- 快速查询:所有字段全匹配
- 高级查询:部分字段匹配
- https://www.cnblogs.com/ljhdo/p/4486978.html
- ES的搜索功能强大:
- 倒排索引的缘故(跟数据库最大的区别);
- 支持前模糊、后模糊,通配符查询、正则表达式查询、聚合查询、排序、范围查询等功能;
- 支持词条查询和全文查询:
- 全文查询首先分析(Analyze)查询字符串,使用默认的分析器分解成一系列的分词
- 可以指定最少匹配数量
- 词条查询是字符的完全匹配
- 全文查询首先分析(Analyze)查询字符串,使用默认的分析器分解成一系列的分词
- match查询常用的参数
- operator:用来控制match查询匹配词条的逻辑条件,默认值是or,如果设置为and,表示查询满足所有条件;
- minimum_should_match:当operator参数设置为or时,
- 该参数用来控制应该匹配的分词的最少数量;
- 短语匹配查询
- 必须匹配短语中的所有分词
- 并且保证各个分词的相对位置不变
- 布尔查询
- must子句:文档必须匹配must查询条件;
- should子句:文档应该匹配should子句查询的一个或多个;
- must_not子句:文档不能匹配该查询条件;
- filter子句:过滤器,文档必须匹配该过滤条件,跟must子句的唯一区别是,filter不影响查询的score;
- 过滤上下文
- 时间(范围过滤)、状态字段使用

分析系统:
- 生成20+张报表,多线程实现
- 尽管ES 也有聚合查询,排序等功能,这里考虑Es核心功能,以及处理效率,以及报表复杂度和数量较多,采用Redis,多线程自己计算
转载于:https://my.oschina.net/u/3847203/blog/3063262
某专利检索分析系统设计回顾相关推荐
- 数值分析 pdf_国内专利检索分析网站优劣势
1.专利汇-patenthub(综合检索最好) 专利汇 - 用户登录 - PatentHub专利检索|专利汇|专利查询网|发明专利查询分析 优点:含语义检索.高级检索(标题,摘要,权利要求).批量检索 ...
- 计算机检索的优点,专利检索与分析系统拥有哪些优势?
专利检索与分析系统拥有哪些优势?现在很多朋友都在了解专利检索与分析系统又有哪些优势,因为他们需要使用这些系统,不少朋友都会利用业余时间搞各种发明专利,并申请发明专利,在申请之前,人们就需要对专利进行检 ...
- 专利检索及分析模拟登陆(python)
登陆程序:#!/usr/bin/env python # -*- coding: UTF-8 -*-import requests import time import base64codeurl = ...
- python微博文本分析_基于Python的微博情感分析系统设计
基于 Python 的微博情感分析系统设计 王欣 ; 周文龙 [期刊名称] < <信息与电脑> > [年 ( 卷 ), 期] 2019(000)006 [摘要] 微博是当今公众 ...
- sessionstorage ie8下跨页面_厉害了!这款覆盖3个国家8个机翻引擎的“跨语言专利检索系统”...
#本文仅代表作者观点,不代表IPRdaily立场# 来源:IPRdaily中文网(IPRdaily.cn) 原标题:AIpatent推出跨语言专利检索系统 图1 AIpatent新版首页 IPRdai ...
- 用计算机专利检索化工,(完整版)《计算机在化学化工中的应用》教学大纲.pdf
<计算机在化学化工中的应用>课程教学大纲 英 文 名 称 : Application of Computer in Chemistry and Chemical Engineering 授 ...
- 知识产权(零)——专利检索概论
目录 1.检索概念 (0)专利检索的作用: 2.为什么检索 3.检索的类型 (0)审批流程 (1)审查工作内容 (2)检索能力 (3)内容特点 (4)方式 4.检索的时间界限 (0)质量影响因素 (1 ...
- python爬虫学习(10) —— 专利检索DEMO
这是一个稍微复杂的demo,它的功能如下: 输入专利号,下载对应的专利文档 输入关键词,下载所有相关的专利文档 0. 模块准备 首先是requests,这个就不说了,爬虫利器 其次是安装tessera ...
- Hermes实时检索分析平台
一.序言 随着TDW的发展,公司在大数据离线分析方面已经具备了行业领先的能力.但是,很多应用场景往往要求在数秒内完成对几亿.几十亿甚至几百上千亿的数据分析,从而达到不影响用户体验的目的.如何能够及时有 ...
最新文章
- LoadRunner12使用教程(三)——Action迭代
- python keyerror_python 日常笔记 - namedtuple
- 第一次马拉松_成为数据科学家是一场马拉松而不是短跑
- matlab r2014a错误,MATLAB中的潜在错误使R2014a回归
- uiautomatorviewer 查看元素新思路
- springboot整个缓存_springboot整合ehcache缓存
- [Canvas]空战游戏进阶 增加己方子弹管理类
- android报警声音
- 【智能无线小车系列二】车体的组装
- 带农历和法定节假日的 日历控件_带节日和农历的js日历
- 2014-07-23 .NET实现微信公众号接入
- 华为27asph是什么型号_华为官宣新增P40 Pro+等27款机型支持换原装电池,有你的手机吗?...
- Esac代表什么意义?
- 密码学累加器cryptographic accumulator
- 塞班 s60v5 开发
- diskgenius分区教程(diskgenius分区教程)
- 即食花胶的功效与作用有哪些?
- 剥开ios 系统sandbox神秘面纱
- 简单的进制转换器(基于数据结构)
- 记一次Linux服务器被黑