『行远见大』 LCQMC 信息检索文本相似度 Baseline
『行远见大』 LCQMC 信息检索文本相似度 Baseline
项目简介
LCQMC 中文问题匹配相似度计算,根据两段信息检索文本在语义上是否相似进行二分类,相似判断为1,不相似判断为0。本项目为各位同学提供一个 Baseline:acc = 0.89751,各位同学可参考本项目并在此基础上调优。
数据集介绍
LCQMC(A Large-scale Chinese Question Matching Corpus), 百度知道领域的中文问题匹配数据集,目的是为了解决在中文领域大规模问题匹配数据集的缺失。该数据集从百度知道不同领域的用户问题中抽取构建数据。
| 数据集名称 | 训练集大小 | 验证集大小 | 测试集大小 |
|---|---|---|---|
| LCQMC | 238,766 | 8,802 | 12,500 |
数据集链接:https://aistudio.baidu.com/aistudio/datasetdetail/78992
比赛报名

报名链接:https://aistudio.baidu.com/aistudio/competition/detail/45
致敬开源
大家好,我是行远见大。欢迎你与我一同建设飞桨开源社区,知识分享是一种美德,让我们向开源致敬!
前置基础知识
文本语义匹配
文本语义匹配是自然语言处理中一个重要的基础问题,NLP 领域的很多任务都可以抽象为文本匹配任务。例如,信息检索可以归结为查询项和文档的匹配,问答系统可以归结为问题和候选答案的匹配,对话系统可以归结为对话和回复的匹配。语义匹配在搜索优化、推荐系统、快速检索排序、智能客服上都有广泛的应用。如何提升文本匹配的准确度,是自然语言处理领域的一个重要挑战。
- 信息检索:在信息检索领域的很多应用中,都需要根据原文本来检索与其相似的其他文本,使用场景非常普遍。
- 新闻推荐:通过用户刚刚浏览过的新闻标题,自动检索出其他的相似新闻,个性化地为用户做推荐,从而增强用户粘性,提升产品体验。
- 智能客服:用户输入一个问题后,自动为用户检索出相似的问题和答案,节约人工客服的成本,提高效率。
让我们来看一个简单的例子,比较各候选句子哪句和原句语义更相近:
原句:“车头如何放置车牌”
- 比较句1:“前牌照怎么装”
- 比较句2:“如何办理北京车牌”
- 比较句3:“后牌照怎么装”
(1)比较句1与原句,虽然句式和语序等存在较大差异,但是所表述的含义几乎相同
(2)比较句2与原句,虽然存在“如何” 、“车牌”等共现词,但是所表述的含义完全不同
(3)比较句3与原句,二者讨论的都是如何放置车牌的问题,只不过一个是前牌照,另一个是后牌照。二者间存在一定的语义相关性
所以语义相关性,句1大于句3,句3大于句2,这就是语义匹配。
短文本语义匹配网络
短文本语义匹配(SimilarityNet, SimNet)是一个计算短文本相似度的框架,可以根据用户输入的两个文本,计算出相似度得分。主要包括 BOW、CNN、RNN、MMDNN 等核心网络结构形式,提供语义相似度计算训练和预测框架,适用于信息检索、新闻推荐、智能客服等多个应用场景,帮助企业解决语义匹配问题。
SimNet 模型结构如图所示,包括输入层、表示层以及匹配层。
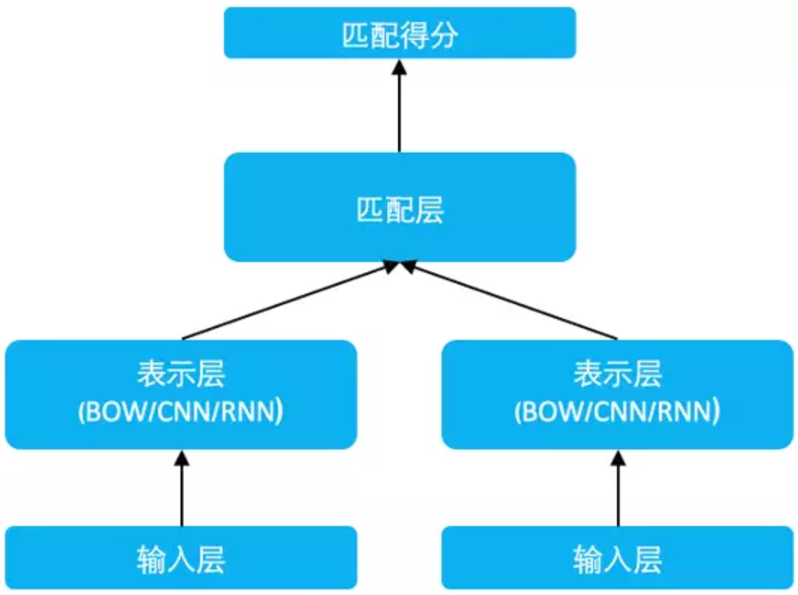
SimilarityNet模型框架结构图
模型框架结构图如下图所示,其中 query 和 title 是数据集经过处理后的待匹配的文本,然后经过分词处理,编码成 id,经过 SimilarityNet 处理,得到输出,训练的损失函数使用的是交叉熵损失。
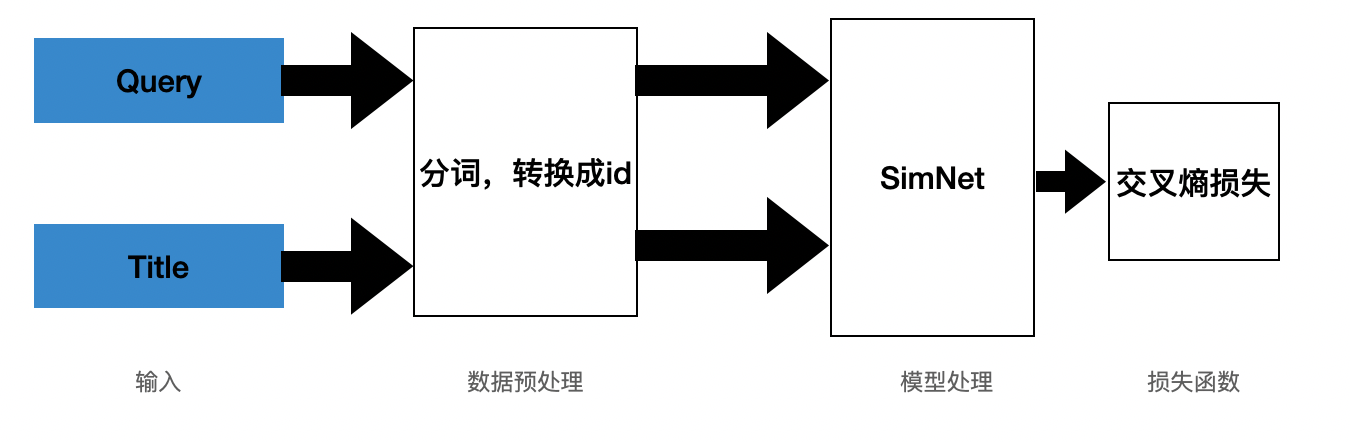
LCQMC 信息检索文本相似度计算
环境配置
# 导入必要的库
import math
import numpy as np
import os
import collections
from functools import partial
import random
import time
import inspect
import importlib
from tqdm import tqdmimport paddle
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.io import IterableDataset
from paddle.utils.download import get_path_from_urlprint("本项目基于Paddle的版本号为:"+ paddle.__version__)
本项目基于Paddle的版本号为:2.1.0
# AI Studio上的PaddleNLP版本过低,所以需要首先升级PaddleNLP
!pip install paddlenlp --upgrade
# 导入PaddleNLP相关的包
import paddlenlp as ppnlp
from paddlenlp.data import JiebaTokenizer, Pad, Stack, Tuple, Vocab
# from utils import convert_example
from paddlenlp.datasets import MapDataset
from paddle.dataset.common import md5file
from paddlenlp.datasets import DatasetBuilderprint("本项目基于PaddleNLP的版本号为:"+ ppnlp.__version__)
本项目基于PaddleNLP的版本号为:2.0.2
加载预训练模型 ERNIE
# 若运行失败,请重启项目
MODEL_NAME = "ernie-1.0"
ernie_model = ppnlp.transformers.ErnieModel.from_pretrained(MODEL_NAME)
model = ppnlp.transformers.ErnieForSequenceClassification.from_pretrained(MODEL_NAME, num_classes=2)
# 定义ERNIE模型对应的 tokenizer,并查看效果
tokenizer = ppnlp.transformers.ErnieTokenizer.from_pretrained(MODEL_NAME)
[2021-06-08 23:52:00,862] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie/vocab.txt
100%|██████████| 90/90 [00:00<00:00, 20643.52it/s]
tokens = tokenizer._tokenize("行远见大荣誉出品")
print("Tokens: {}".format(tokens))# token映射为对应token id
tokens_ids = tokenizer.convert_tokens_to_ids(tokens)
print("Tokens id: {}".format(tokens_ids))# 拼接上预训练模型对应的特殊token ,如[CLS]、[SEP]
tokens_ids = tokenizer.build_inputs_with_special_tokens(tokens_ids)
print("Tokens id: {}".format(tokens_ids))
# 转化成paddle框架数据格式
tokens_pd = paddle.to_tensor([tokens_ids])
print("Tokens : {}".format(tokens_pd))# 此时即可输入ERNIE模型中得到相应输出
sequence_output, pooled_output = ernie_model(tokens_pd)
print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
Tokens: ['行', '远', '见', '大', '荣', '誉', '出', '品']
Tokens id: [40, 629, 373, 19, 838, 1054, 39, 100]
Tokens id: [1, 40, 629, 373, 19, 838, 1054, 39, 100, 2]
Tokens : Tensor(shape=[1, 10], dtype=int64, place=CUDAPlace(0), stop_gradient=True,[[1 , 40 , 629, 373, 19 , 838, 1054, 39 , 100, 2 ]])
Token wise output: [1, 10, 768], Pooled output: [1, 768]/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/tensor/creation.py:125: DeprecationWarning: `np.object` is a deprecated alias for the builtin `object`. To silence this warning, use `object` by itself. Doing this will not modify any behavior and is safe.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecationsif data.dtype == np.object:
encoded_text = tokenizer(text="行远见大荣誉出品", max_seq_len=20)
for key, value in encoded_text.items():print("{}:\n\t{}".format(key, value))# 转化成paddle框架数据格式
input_ids = paddle.to_tensor([encoded_text['input_ids']])
print("input_ids : {}".format(input_ids))
segment_ids = paddle.to_tensor([encoded_text['token_type_ids']])
print("token_type_ids : {}".format(segment_ids))# 此时即可输入 ERNIE 模型中得到相应输出
sequence_output, pooled_output = ernie_model(input_ids, segment_ids)
print("Token wise output: {}, Pooled output: {}".format(sequence_output.shape, pooled_output.shape))
input_ids:[1, 40, 629, 373, 19, 838, 1054, 39, 100, 2]
token_type_ids:[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
input_ids : Tensor(shape=[1, 10], dtype=int64, place=CUDAPlace(0), stop_gradient=True,[[1 , 40 , 629, 373, 19 , 838, 1054, 39 , 100, 2 ]])
token_type_ids : Tensor(shape=[1, 10], dtype=int64, place=CUDAPlace(0), stop_gradient=True,[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
Token wise output: [1, 10, 768], Pooled output: [1, 768]
加载数据集
# 首次运行需要把注释(#)去掉
# !unzip -oq /home/aistudio/data/data78992/lcqmc.zip
# 删除解压后的无用文件
!rm -r __MACOSX
查看数据
import pandas as pdtrain_data = "./lcqmc/train.tsv"
train_data = pd.read_csv(train_data, header=None, sep='\t')
p='\t')
train_data.head(10)
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 喜欢打篮球的男生喜欢什么样的女生 | 爱打篮球的男生喜欢什么样的女生 | 1 |
| 1 | 我手机丢了,我想换个手机 | 我想买个新手机,求推荐 | 1 |
| 2 | 大家觉得她好看吗 | 大家觉得跑男好看吗? | 0 |
| 3 | 求秋色之空漫画全集 | 求秋色之空全集漫画 | 1 |
| 4 | 晚上睡觉带着耳机听音乐有什么害处吗? | 孕妇可以戴耳机听音乐吗? | 0 |
| 5 | 学日语软件手机上的 | 手机学日语的软件 | 1 |
| 6 | 打印机和电脑怎样连接,该如何设置 | 如何把带无线的电脑连接到打印机上 | 0 |
| 7 | 侠盗飞车罪恶都市怎样改车 | 侠盗飞车罪恶都市怎么改车 | 1 |
| 8 | 什么花一年四季都开 | 什么花一年四季都是开的 | 1 |
| 9 | 看图猜一电影名 | 看图猜电影! | 1 |
读取数据
class lcqmcfile(DatasetBuilder):SPLITS = {'train': 'lcqmc/train.tsv','dev': 'lcqmc/dev.tsv',}def _get_data(self, mode, **kwargs):filename = self.SPLITS[mode]return filenamedef _read(self, filename):with open(filename, 'r', encoding='utf-8') as f:head = Nonefor line in f:data = line.strip().split("\t")if not head:head = dataelse:query, title, label = datayield {"query": query, "title": title, "label": label}def get_labels(self):return ["0", "1"]
def load_dataset(name=None,data_files=None,splits=None,lazy=None,**kwargs):reader_cls = lcqmcfileprint(reader_cls)if not name:reader_instance = reader_cls(lazy=lazy, **kwargs)else:reader_instance = reader_cls(lazy=lazy, name=name, **kwargs)datasets = reader_instance.read_datasets(data_files=data_files, splits=splits)return datasets
train_ds, dev_ds = load_dataset(splits=["train", "dev"])
<class '__main__.lcqmcfile'>
模型构建
from functools import partial
from paddlenlp.data import Stack, Tuple, Pad
from utils import convert_example, create_dataloaderbatch_size = 64
max_seq_length = 128trans_func = partial(convert_example,tokenizer=tokenizer,max_seq_length=max_seq_length)
batchify_fn = lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id), # inputPad(axis=0, pad_val=tokenizer.pad_token_type_id), # segmentStack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(train_ds,mode='train',batch_size=batch_size,batchify_fn=batchify_fn,trans_fn=trans_func)
dev_data_loader = create_dataloader(dev_ds,mode='dev',batch_size=batch_size,batchify_fn=batchify_fn,trans_fn=trans_func)
训练配置
from paddlenlp.transformers import LinearDecayWithWarmup# 训练过程中的最大学习率
learning_rate = 5e-5
# 训练轮次
epochs = 3
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01num_training_steps = len(train_data_loader) * epochs
lr_scheduler = LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler,parameters=model.parameters(),weight_decay=weight_decay,apply_decay_param_fun=lambda x: x in [p.name for n, p in model.named_parameters()if not any(nd in n for nd in ["bias", "norm"])])criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
模型训练
import paddle.nn.functional as F
from utils import evaluateglobal_step = 0
for epoch in range(1, epochs + 1):for step, batch in enumerate(train_data_loader, start=1):input_ids, segment_ids, labels = batchlogits = model(input_ids, segment_ids)loss = criterion(logits, labels)probs = F.softmax(logits, axis=1)correct = metric.compute(probs, labels)metric.update(correct)acc = metric.accumulate()global_step += 1if global_step % 10 == 0 :print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))loss.backward()optimizer.step()lr_scheduler.step()optimizer.clear_grad()evaluate(model, criterion, metric, dev_data_loader)
global step 11130, epoch: 3, batch: 3668, loss: 0.03892, acc: 0.95436
global step 11140, epoch: 3, batch: 3678, loss: 0.10784, acc: 0.95436
global step 11150, epoch: 3, batch: 3688, loss: 0.13684, acc: 0.95438
global step 11160, epoch: 3, batch: 3698, loss: 0.10246, acc: 0.95437
global step 11170, epoch: 3, batch: 3708, loss: 0.10320, acc: 0.95436
global step 11180, epoch: 3, batch: 3718, loss: 0.05931, acc: 0.95435
global step 11190, epoch: 3, batch: 3728, loss: 0.01982, acc: 0.95436
eval loss: 0.31526, accu: 0.89751
Baseline 运行了3个 epoch,用时约45分钟。
- epoch1:eval loss: 0.32242, accu: 0.86558
- epoch2:eval loss: 0.30539, accu: 0.88910
- epoch3:eval loss: 0.31526, accu: 0.89751
保存模型
model.save_pretrained('xyjd')
tokenizer.save_pretrained('xyjd')
预测模型
测试结果
from utils import predict
import pandas as pdlabel_map = {0:'0', 1:'1'}def preprocess_prediction_data(data):examples = []for query, title in data:examples.append({"query": query, "title": title})# print(len(examples),': ',query,"---", title)return examples
test_file = 'lcqmc/test.tsv'
data = pd.read_csv(test_file, sep='\t')
# print(data.shape)
data1 = list(data.values)
examples = preprocess_prediction_data(data1)
输出 tsv 文件
results = predict(model, examples, tokenizer, label_map, batch_size=batch_size)for idx, text in enumerate(examples):print('Data: {} \t Label: {}'.format(text, results[idx]))data2 = []
for i in range(len(data1)):data2.extend(results[i])data['label'] = data2
print(data.shape)
data.to_csv('lcqmc.tsv',sep='\t')
在测试集上的部分预测结果展示:
![]()
作者简介
- 飞桨主页:行远见大
- 个人经历:上海开源信息技术协会成员
- 我的口号:向开源致敬,一同建设飞桨开源社区
- 常住地址:常年混迹在 AI Studio 平台和各类 PaddlePaddle 群
- QQ:1206313185 添加时请备注添加原因和 AI Studio 的 ID
- 感谢小伙伴们一键三连(喜欢♡、fork〧、关注+)支持,点 ♡ 数越多,更新越快~
『行远见大』 LCQMC 信息检索文本相似度 Baseline相关推荐
- 『行远见大』 BQ Corpus 信贷文本匹配相似度计算
『行远见大』 BQ Corpus 信贷文本匹配相似度计算 项目简介 BQ Corpus 信贷文本匹配相似度计算,根据两段银行信贷业务的文本在语义上是否相似进行二分类,相似判断为1,不相似判断为0.本项 ...
- 【BABY夜谈大数据】计算文本相似度
简单讲解 上一章有提到过[基于关键词的空间向量模型]的算法,将用户的喜好以文档描述并转换成向量模型,对商品也是这么处理,然后再通过计算商品文档和用户偏好文档的余弦相似度. 文本相似度计算在信息检索.数 ...
- 七夕特辑|ShardingSphere 官方『真爱指南』大公开!
ShardingSphere Lovers' Day 浪漫钟声响起 七夕佳节来袭 特此隆重推出 ShardingSphere 粉丝专属 『真爱指南』 自测下你中了几条 来解锁甜蜜超能力! 一起感受来自 ...
- 太干了!大俠『云飞杨』带你走进GFX!
我是『云飞扬』 Cocos论坛昵称『大风起兮云飞扬』 Cocos引擎忠实用户 Cocos2d-x.Cocos Creator.Cocos Creator 3D系列 都在项目中使用过 有Cocos论坛强 ...
- 『论文复现系列』3.Glove
★★★ 本文源自AlStudio社区精品项目,[点击此处]查看更多精品内容 >>> 『论文复现系列』3.Glove Glove 论文 | Global Vectors for Wor ...
- 『HTML5挑战经典』是英雄就下100层-开源讲座(二)危险!英雄
本篇为<『HTML5挑战经典』是英雄就下100层-开源讲座>第二篇,需要用到开源引擎lufylegend,可以到这里下载: 下载地址:http://lufylegend.googlecod ...
- iOS多线程:『NSOperation、NSOperationQueue』详尽总结
2019独角兽企业重金招聘Python工程师标准>>> iOS多线程:『NSOperation.NSOperationQueue』详尽总结 转载: 原地址https://www.ji ...
- 2017-2018-2 20155303『网络对抗技术』Final:Web渗透获取WebShell权限
2017-2018-2 『网络对抗技术』Final:Web渗透获取WebShell权限 --------CONTENTS-------- 一.Webshell原理 1.什么是WebShell 2.We ...
- 『力荐汇总』这些 VS Code 快捷键太好用,忍不住录了这34张gif动图
之前写过三篇文章,收获了极其不错的阅读量与转发量: 你真的会用 VS Code 的 Ctrl.Shift和Alt吗?高效易用的快捷键:多光标.跳转引用等轻松搞定 VS Code 中的 Vim 操作 | ...
最新文章
- android标题栏添加按钮_改善Android布局性能
- GitHub与PyCharm配置最新简单教程
- mysql dump gtid_mysqldump导出数据备份 --set-gtid-purged=OFF
- 【CentOS Linux 7】实验7【FTP服务器配置管理】
- 邮件伪造_伪造品背后的数学
- 【2018.4.14】模拟赛之四-ssl2394 剪草【dp】
- Linux 普通用户拿到root权限及使用szrz命令上传下载文件
- OO第一单元总结__多项式求导问题
- 时间日期大小比较判断,时间戳/时间 - 转换
- 周围剃光头顶留长发型_?22岁亿万富翁凯莉登杂志,顶着5斤“鸟窝头”凹造型,绝代艳后...
- 在python中、关于全局变量和局部变量、以下_关于全局变量和局部变量-Python
- Mysql用户管理(远程连接、授权)
- 电子或者自动化同学以后做什么
- 大陆身份证号码格式校验
- 信息系统项目管理师考试核心考点汇总
- python实例013--定义一个矩形类
- 学生成绩管理系统(一)
- Unity 渲染顺序
- 在录音等情况下保持屏幕长亮
- redhat 7 中NFS服务器配置与管理