数据分析学习之路——(三)从泰坦尼克号撞击冰山后开始说起
1912年4月14日,Titanic号在其处女航程中,不幸撞击冰山沉没在大西洋,超过1500名船员和乘客遇难,成为人类灾难史上沉痛的一幕,而与之相关的一系列谣言猜测也为后人津津乐道。那么我们不禁会问,船上这么多人,到底有多少人活下来了,这些活下来的又是什么人呢?下面我们从一份泰坦尼克号乘客的数据集来获取信息吧。
数据获取
本数据集是kaggle网站上面提供的,是一份包含891名船上乘客(本文将船员和乘客统称乘客)的样本数据;是一份csv格式,包含近十种乘客信息的数据集。
数据探索
用excel打开文件可以看到包含的乘客信息如下图,再通过表格形式对每个字段说明一下。
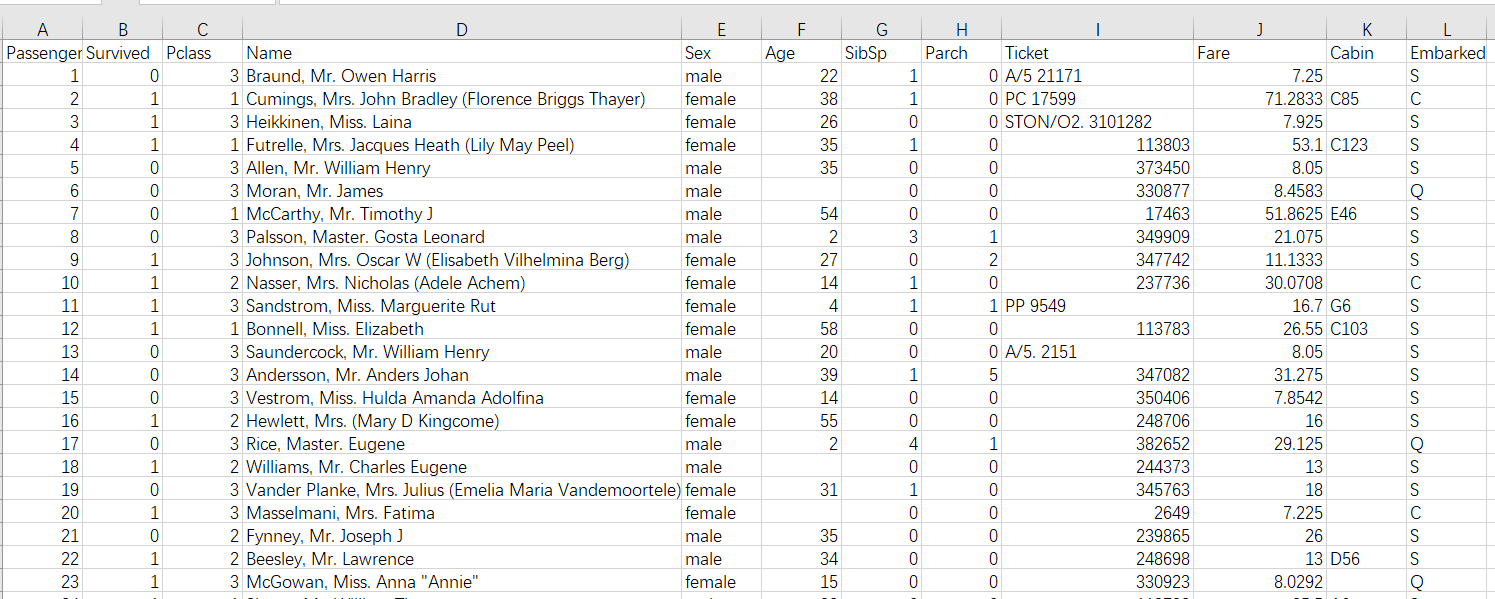
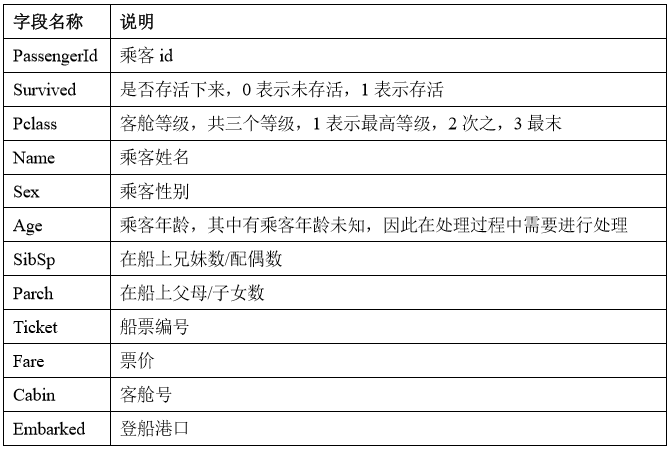
我们从给出的信息来分析乘客的存活情况,像Ticket、Name这样的字段并无太大意义,因此主要选择Pclass、Sex、Age等字段信息来分析。例如我们印象深刻的救生圈优先给女人和小孩,那么我们可以看看是否女人和小孩的存活率更高;再有,乘坐船舱的等级表示一个人的身份,那么我们可以这样猜想:是否身份越高,生存下来的机会就越大呢?
因此我们主要选取客舱等级、性别和年龄作为自变量,是否存活下来作为因变量,来对整个数据集做分析。同时,使用python这一工具来对数据进行清理分析,pandas库的read_csv方法读取数据集文件,得到DataFrame格式的数据进行操作,非常便捷。
数据处理
根据观察,以及用代码检测,发现数据集比较规整,不存在完全重复的数据项。此外,年龄是分析中的一个重要维度,但是数据集中该信息却有很多缺失值,因此我将缺失的年龄默认赋值为整个数据集年龄的平均值,这样就做到每一个乘客都有一个年龄值。
# 乘客年龄存在空值,使用整体年龄的平均值代替 titanic_data['Age']=titanic_data['Age'].fillna(titanic_data['Age'].mean())
年龄空值填充后的数据集信息:
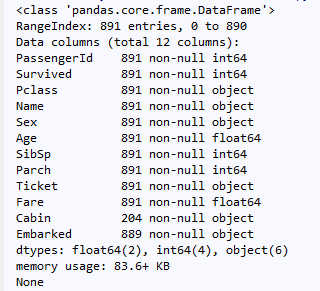
可以知道,整个数据集有891条数据,也就是有891名乘客的信息,其中有2名乘客登船港口未知。此外我们只知道204名乘客所在的客舱号,比例不到25%,但是我们不需要从这个维度去分析,因此影响不大。
数据分析过程
1. 选取存活下来的乘客作为分析对象。
# 选取存活下来的乘客数据 survived_titanic_data = titanic_data[titanic_data['Survived']==1]
给出的数据集一共有342名乘客活下来占比38.38%。我们从以下几个维度来分析。
def surviveddata_groupby_feature(feature,list):if feature == 'Sex':_feature='乘客性别'elif feature == 'Pclass':_feature = '客舱等级'# 按feature分组计算乘客人数print survived_titanic_data.groupby([feature])['PassengerId'].count()survived_titanic_groupby_feature = survived_titanic_data.groupby([feature])['PassengerId'].count() # 将分组得到的人数组成一个数组fig = plt.figure(figsize=(10, 5)) # 设置绘图区域大小及子图 ax_1 = fig.add_subplot(121)survived_titanic_data.groupby([feature])['PassengerId'].count().plot(kind='bar') # 根据feature分组,计算人数并绘制柱状图for index, feature_num in enumerate(survived_titanic_groupby_feature):ax_1.text(index, feature_num, feature_num, ha='center', va='bottom', rotation=0) # 柱状图增加对应的数据显示,前面三个参数分别为横、纵坐标和数据ax_1.set_xticklabels(['male', 'famale'], rotation=0) # 重新命名柱状图横坐标刻度ax_1.set_xlabel(_feature)ax_1.set_ylabel('乘客人数')ax_1.set_title('按'+_feature+'存活人数')ax_2 = fig.add_subplot(122)ax_2.set_title('按'+_feature+'乘客存活占比(%)')plt.pie(survived_titanic_groupby_feature, labels=list, autopct='%1.1f%%') # 饼图plt.show()
1)乘客性别
surviveddata_groupby_feature('Sex',['male', 'famale']) # 根据乘客性别分析存活下来的乘客
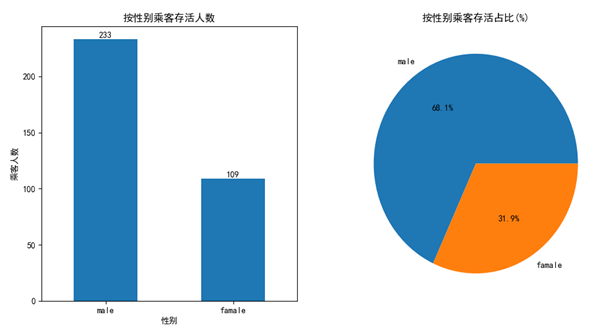
活下来的乘客中男性233名,女性109名。通过饼图可以直观看到,存活下来的乘客中男性明显多于女性乘客。
2)乘客所在客舱等级
surviveddata_groupby_feature('Pclass',['P1','P2','P3']) # 根据客舱等级分析存活下来的乘客
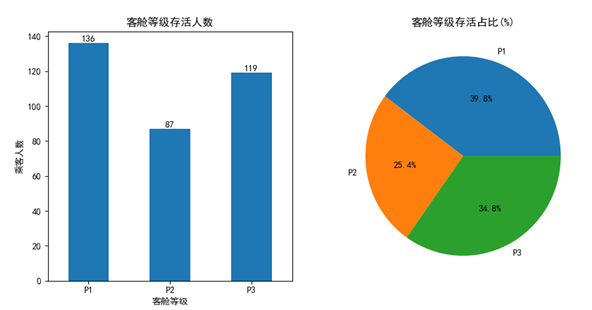
活下来的乘客中在最高级船舱的乘客136名,占比大约40%;次等船舱87名,占比约25%,最末等级船舱119名,占比约35%。同样通过饼图可以很直观看到,存活下来的乘客中在最高级船舱所占比例最大。
3)乘客年龄
def surviveddata_groupby_age():survived_titanic_data['Age'].hist(bins=12) # 根据乘客年龄绘制直方图plt.xlabel('年龄')plt.ylabel('乘客人数')plt.title('乘客存活人数年龄分布')plt.show()
surviveddata_groupby_age() # 根据乘客年龄分析存活下来的乘客
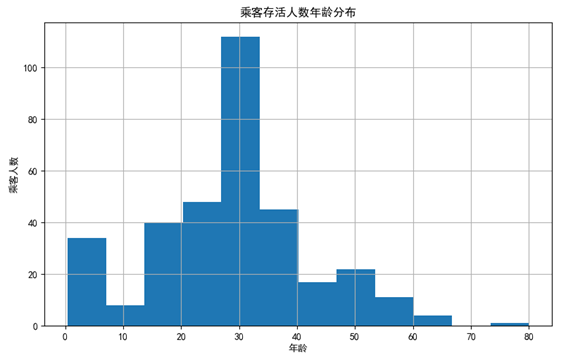
通过直方图,可以看到在活下来的乘客当中,青壮年(30岁左右的乘客)占到了绝对比例,相对来讲,上了年纪的乘客不多,可能是由于本身岁数较大的乘客就不多,乘客以中青年为主。
2. 将全部乘客作为分析对象。
同样按照下面的维度对比分析。
def data_groupby_feature(feature,dic):
if feature == 'Sex':_feature='乘客性别'elif feature == 'Pclass':_feature = '客舱等级'titanic_data_feature = titanic_data.groupby([feature, 'Survived'])['PassengerId'].count().unstack()feature_percent = titanic_data_feature.apply(lambda x: x / x.sum() * 100, axis=1) # 计算百分比feature_percent.rename(columns={1: 'yes', 0: 'no'}, index=dic, inplace=True) # 坐标刻度、图例修改#print titanic_data_feature, feature_percentfeature_percent.plot(kind='bar', stacked=True) # 累计百分比柱状图plt.xticks(rotation=0)plt.xlabel(_feature)plt.ylabel('百分比(%)')plt.title(_feature+'存活率对比')plt.show()
1)乘客所在客舱等级
data_groupby_feature('Pclass',{1:'P1', 2:'P2', 3:'P3'}) # 根据客舱等级分析乘客生存情况
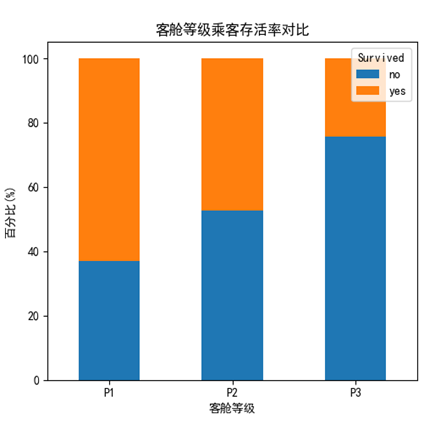
不难发现,通过将整体数据进行对比,在P1船舱的乘客明显活下来的机率大得多,概率超过了60%;而P3船舱的乘客活下来的机率只有大概25%。也印证了上面提出的猜想:身份越高贵,活下来的机会就越大。
2)乘客性别
data_groupby_feature('Sex',{}) # 根据乘客性别分析乘客生存情况
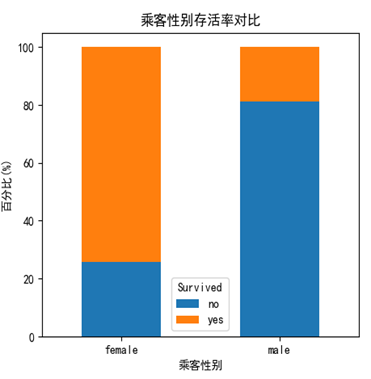
同样,我们会发现,性别也是一个非常有影响因子,女性乘客活下来的概率高达75%+,而男性乘客只有区区20%。
3)乘客年龄
# 将年龄分成几组,计算各组人数和比例。新增一列,不改变原数据 bins = [0, 9, 18, 27, 36, 45, 54, 63, 72, 81, 90] level = ['0~9', '9~18', '18~27', '27~36', '36~45', '45~54', '54~63', '63~72', '72~81', '81+'] titanic_data['Age_Group'] = pd.cut(titanic_data['Age'], bins=bins, labels=level)
def data_groupby_age():
titanic_data_bucket = titanic_data.groupby(['Age_Group', 'Survived'])['PassengerId'].count().unstack().fillna(0)titanic_data_bucket.rename(columns={1:'yes', 0:'no'}, inplace=True)fig = plt.figure(figsize=(10, 5))ax_1 = fig.add_subplot(121)titanic_data_bucket['yes'].plot(kind='bar',alpha=0.5) # 各年龄段乘客存活/未存活数分布,通过柱状图展示titanic_data_bucket['no'].plot(kind='bar',alpha=0.5)ax_1.set_xlabel('年龄')ax_1.set_ylabel('乘客存活数/总乘客数')ax_1.set_title('乘客存活人数年龄分布')plt.xticks(rotation=0)ax_2 = fig.add_subplot(122)titanic_data_bucket[['no_percent','yes_percent']] \= titanic_data_bucket.apply(lambda x: x / x.sum()*100, axis=1)print titanic_data_buckettitanic_data_bucket['yes_percent'].plot(kind='bar', stacked=True) # 各年龄段乘客存活百分比ax_2.set_xlabel('年龄')ax_2.set_ylabel('存活人数百分比(%)')ax_2.set_title('乘客存活百分比分布')plt.xticks(rotation=0)plt.show()
data_groupby_age() # 根据乘客年龄分析乘客生存情况
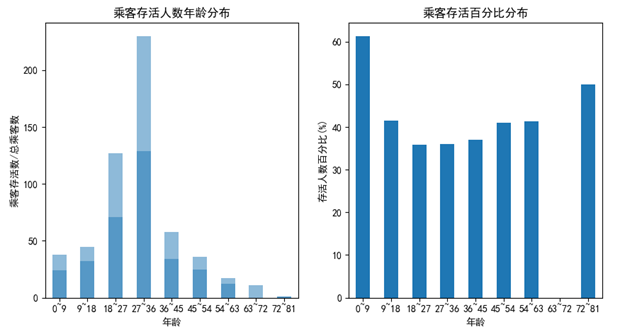
通过左边累积图我们可以看到,船上确实是中青年人最多,活下来的人当中也是中青年人占了大多数,很容易就会让人得出中青年人存活率较高的结论。但是右边的存活比率分布却告诉我们并不是这样,小孩才是存活率最高的一批人,18岁以下的人活下来的概率超过了50%。此外,72~81岁这个区间存活概率50%,是因为样本数据中2人当中活了一个,并不具有代表性不多做讨论;63~72岁大概10多个人居然一个也没活下来,很异常的数据,可能是由于数据集的不全,也可能本身就是因为老人抵抗力差,在海水和恐惧中不能坚持太长时间,即使个别人有救生设备,最终也没能够抵御死亡。
到这里,我们就比较明晰了,上面两个维度的分析给了我们很深刻的印象,女人和小孩,对!就是这两个群体存活下来的机率远远高于其他群体,那么,传言了近一个世纪的言论我们就有理由相信了:在泰坦尼克撞击冰山快要沉没时,大多数船上的人自发的将救生圈留给了女人和小孩。
4)乘客性别&乘客所在船舱
我们同时从乘客的性别和所在船舱,也许更能接近一些真相。
def data_groupby_pclass_and_sex(): titanic_data_sex_and_pclass = titanic_data.groupby(['Sex', 'Survived', 'Pclass'])['PassengerId'].count().unstack('Survived') # 根据性别和乘客所在船舱等级分组,分析对存活的影响titanic_data_sex_and_pclass.rename(columns={0:'no', 1:'yes'}, inplace=True)titanic_data_sex_and_pclass['yes_percent(%)'] = titanic_data_sex_and_pclass['yes']/\(titanic_data_sex_and_pclass['no']+titanic_data_sex_and_pclass['yes'])*100 # 计算活下来的人占各自群体的百分比print titanic_data_sex_and_pclasstitanic_data.groupby(['Pclass', 'Sex'])['Survived'].mean().unstack().plot(kind='bar')plt.xticks(rotation=0)plt.xlabel('船舱等级')plt.ylabel('比例')plt.title('存活比例对比')plt.show()
data_groupby_pclass_and_sex() # 根据乘客性别和乘客所在船舱等级分析乘客生存情况
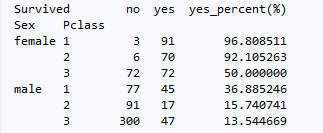
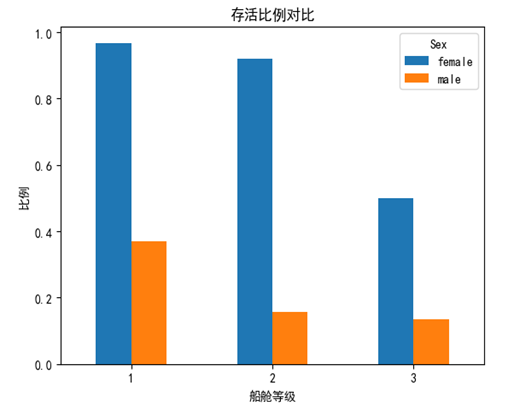
不出所料,活下来机会最大的是在高等船舱的女性(超过了90%),而留在大洋深处的就是那些在低等船舱的男性乘客(最高还不到20%)。更印证了身份越高贵越有机会活下来的结论。
3. 最后来看下船票票价的情况。
def fare():
print titanic_data['Fare'].describe() # 船票价格描述性统计titanic_data['Fare'].hist(bins=60, normed=True, alpha=0.8)titanic_data['Fare'].plot(kind='kde')plt.show()
fare() # 查看船票价格
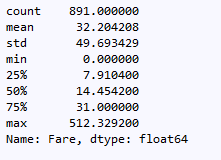
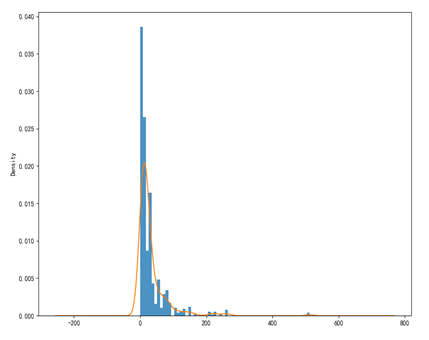
根据第一四分位数,中位数和平均数可以看到,绝大部分票价是很低的只有极个别票价很高,最高的价格超过了500。通过直方图更直观,除了一少部分,船票价格都在200以下,而绝大多数没有超过100。
总结
根据上面的分析,可以得出:泰坦尼克撞击冰山即将沉没时,女人和小孩被安排优先使用救生圈,活下来的机会更大;并且,身份地位比较高的人更在意自己的生死,会想尽方法使自己找机会活下来,一般人在这种绝境下更可能牺牲自己,优先帮助救助弱小的人。
思考
但是,这样分析有没有什么问题呢?有,只要是基于不完全的数据进行分析都有局限性。本次分析是建立在这891个筛选出来的乘客数据基础上的,只是样本数据,而且例如像年龄这样的还有很多缺失信息,尽管我们用均值代替了空值,终究是有误差的,假如那几个年龄缺失值大部分是大于60并且都活了下来,那么我们可能得出另外相反的结论,即老人的存活率也比较高。因此只有我们得到的数据越接近总体数据,我们得到的结论才越可靠。从本次分析来看,乘客所在的船舱、年龄以及性别是乘客存活的最大影响因素,那还有那些其他因素会产生一定的影响呢,我们可以再探索一下:1、船上乘客类别,是普通乘客还是船上的工作人员,猜想船上工作人员要组织营救和自救,活下来的概率小一些;2、乘客是否有亲人在船上,这应该可以通过其中SibSp和Parch两个字段来挖掘分析,也许在面对困难时,一个家庭或者亲人间互相帮扶互相鼓励,活下来的机会也大;3、乘客所在的楼层,应该是楼层越高,自救时间越长,乘客活下来机会越大,这个因素应该与船舱等级有相关性的,从这个维度分析也许会佐证船舱等级对乘客存活率的影响。
题外话:在kaggle上面,这其实是一个入门比赛的数据集之一,目标是基于机器学习,通过测试数据集构建特征,预测乘客的生存概率,不再是单纯的简单相关性分析。所以这里先挖个坑,在之后的学习过程中学习了机器学习相关知识,一定要回来填坑!
转载于:https://my.oschina.net/nekyo/blog/1545133
数据分析学习之路——(三)从泰坦尼克号撞击冰山后开始说起相关推荐
- 数据分析学习记录(三)--主成分分析及在origin中的实现
数据分析学习记录(三)–主成分分析及在origin中的实现 注:本文仅作为自己的学习记录以备以后复习查阅 一 概念 主成分分析是一种数据分析的方法,尤其应用在光谱降维领域,降维是一种对高纬度特征数据的 ...
- 佩奇的数据分析学习之excel(三)
佩奇的数据分析学习之excel(三) 文章目录 佩奇的数据分析学习之excel(三) 前言 一.excel是什么? 二.什么是周报 三.周报的制作 前言 文章内容来源于博主对B站UP主:"戴 ...
- 数据分析学习之路——(五)用数据告诉你电影的市场趋势
随着社会的多元化,越来越多的影视作品走入人们的生活中.但是近年来鲜有几部新制作的电影能俘获观众的心,到底是观众越来越挑剔,还是电影作品本身不够吸引力?如果你是有一个电影公司,你想制作一部电影作品,你有 ...
- 数据分析学习笔记(三)
心电图Task03 特征工程 比赛地址:https://tianchi.aliyun.com/competition/entrance/531883/introduction 学习目标 学习时间序列数 ...
- CYQ.Data 轻量数据层之路 使用篇三曲 MAction 取值赋值(十四)
上一篇:CYQ.Data 轻量数据层之路 使用篇二曲 MAction 数据查询(十三) 内容概要 本篇继续上一篇内容,本节介绍所有取值与赋值的相关操作. 1:原生:像操作Row一样 2:扩展:对UI操 ...
- CYQ.Data 轻量数据层之路 V3.0版本发布-Xml绝对杀手(三十二)
前言: 继正式发布V2.0到现在,已30来天了,一直静悄悄的都没发布什么版本 中间仅有插播了一下:CYQ.Data 轻量数据层之路 V2.5 抢先体验版本功能说明演示 (二十九) 只因最近花了很多时间 ...
- 数据分析学习笔记(二)数据分析三思维七技巧
数据分析学习笔记(二) What 三种核心思维 结构化 公式化 业务化 Why 数据分析的思维技巧 象限法 多维法 假设法 指数法 二八法 对比法 漏斗法 总结 How 如何在业余时间锻炼分析能力 好 ...
- (秦路)七周成为数据分析师(第三周)—— Excel
文章目录 1 文本清洗函数 2 关联匹配类 2.1 LOOKUP和VLOOKUP 2.2 INDEX和MATCH 2.3 ROW和COLUMN 2.4 OFFSET 2.5 HYPERLINK 3 逻 ...
- 网易组建Python数据分析学习群,3场直播课+6G学习资料免费领
学会Python之后的你会有什么不同? 写几十行代码便能实现表情包爬取: 用几行代码就能快速整理数据并出图: 甚至可以编写合成多个Excel表格的Python脚本,一键跳过复制粘贴: 今天给大家送个福 ...
- CYQ.Data 轻量数据层之路 使用篇五曲 MProc 存储过程与SQL(十六)
上一篇:CYQ.Data 轻量数据层之路 使用篇四曲 MAction 增删改(十五) 本篇内容概要 本篇继续上一篇内容,本节介绍MProc 类的相关操作. 1:MProc 存储过程操作 2:MProc ...
最新文章
- 利用IPSec实现网络安全之三(身份验证和加密数据)
- 【Android 应用开发】Android中使用ViewPager制作广告栏效果 - 解决ViewPager占满全屏页面适配问题
- 图像处理(四)图像分割(2)测地距离Geodesic图割
- Python编程从入门到实践~JSON
- bios升级工具_雨林木风U盘启动盘装系统制作工具再次升级。。。
- 续易crm源码客户资源管理系统crm源码(源代码c#)
- html2canvas 像素,html2canvas 如何生成高清图片?
- decode 大于比较 小于_「oracle decode」【ORACLE】Oracle提高篇之DECODE - seo实验室
- 可能促使您决定创建自定义数据绑定控件的一些原因:
- mac pdf去水印_Inpaint For Mac :超强去水印工具
- springboot jpa 实体类继承
- mysql 3个表左连接查询_MySQL数据库三个表的左连接查询(LEFT JOIN)
- 无法上网的N种解决方法
- Cubieboard安装系统
- 根据身高体重计算BMI指数
- Xshell如何连接虚拟机
- 矩阵相关知识回顾--协方差的意义
- Excel TEXT函数怎么把数值转换成文本
- 跨界教授林宙辰:从北大来,回北大去
- TA进阶实例34(Unreal制作水晶星光效果)