Flink如何保证数据的一致性
当在分布式系统中引入状态时,自然也引入了一致性问题。一致性实际上是"正确性级别"的另一种说法,也就是说在成功处理故障并恢复之后得到的结果,与没有发生任何故障时得到的结果相比,前者到底有多正确?举例来说,假设要对最近一小时登录的用户计数。在系统经历故障之后,计数结果是多少?如果有偏差,是有漏掉的计数还是重复计数?
## 一致性级别
在流处理中,一致性可以分为3个级别:
- at-most-once: 这其实是没有正确性保障的委婉说法——故障发生之后,计数结果可能丢失。同样的还有udp。
- at-least-once: 这表示计数结果可能大于正确值,但绝不会小于正确值。也就是说,计数程序在发生故障后可能多算,但是绝不会少算。
- exactly-once: 这指的是系统保证在发生故障后得到的计数结果与正确值一致。
Flink的一个重大价值在于,**它既保证了exactly-once,也具有低延迟和高吞吐的处理能力**。
## 端到端(end-to-end)状态一致性
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在 Flink 流处理器内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。具体可以划分如下:
- 内部保证 —— 依赖checkpoint
- source 端 —— 需要外部源可重设数据的读取位置
- sink 端 —— 需要保证从故障恢复时,数据不会重复写入外部系统
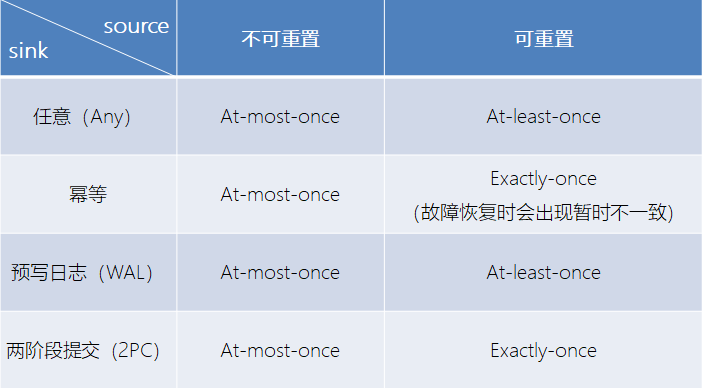
而对于sink端,又有两种具体的实现方式:幂等(Idempotent)写入和事务性(Transactional)写入。
- 幂等写入
所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
- 事务写入
需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。
不同Source和Sink的一致性保证可用下表说明:
## 检查点
检查点的代码实践
public class CheckpointApp {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 开启checkpoint/*** 不开启checkpoint: 不重启* 配置了重启策略: 使用配置的重启策略* 1. 使用默认的重启策略: Integer.MAX_VALUE* 2. 配置了重启策略, 使用配置的重启策略覆盖默认的** 重启策略的配置:* 1. code* 2. yaml*/env.enableCheckpointing(5000);// env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);// 作业完成后是否保留CheckpointConfig config = env.getCheckpointConfig();config.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);// 设置状态后端config.setCheckpointStorage("file:Users/carves/workspace/imook-flink");// 自定义设置我们需要的重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, // number of restart attempts, 正常运行之后,进入错误再运行的次数Time.of(10, TimeUnit.SECONDS) // delay));DataStreamSource<String> source = env.socketTextStream("localhost", 9527);source.map(new MapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {if (value.contains("pk")) {throw new RuntimeException("PK pk test!");} else {return value.toLowerCase();}}}).flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] splits = value.split(",");for (String split:splits) {out.collect(split);}}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return Tuple2.of(value, 1);}}).keyBy(value -> value.f0).sum(1).print();env.execute("CheckpointApp");}
}检查点算法:
Flink检查点算法的正式名称是**异步分界线快照**(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport分布式快照算法。
检查点是Flink最有价值的创新之一,因为**它使Flink可以保证exactly-once,并且不需要牺牲性能**。
## Flink + Kafka 实现exactly once 语义
我们知道,端到端的状态一致性的实现,需要每一个组件都实现,对于Flink + Kafka的数据管道系统(Kafka进、Kafka出)而言,各组件怎样保证exactly-once语义呢?利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source —— kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink —— kafka producer作为sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
内部的checkpoint机制我们已经有了了解,那source和sink具体又是怎样运行的呢?接下来我们逐步做一个分析。
我们知道Flink由JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。
### 2阶段提交
执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流;barrier会在算子间传递下去。
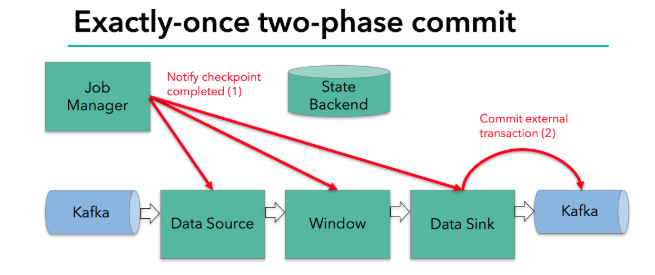
每个算子会对当前的状态做个快照,保存到状态后端。对于source任务而言,就会把当前的offset作为状态保存起来。下次从checkpoint恢复时,source任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。
具体的两阶段提交步骤总结如下:第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”。jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager。sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据。jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成。sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据。外部kafka关闭事务,提交的数据可以正常消费了。
### 2阶段提交步骤
1. 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
2. sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
3. jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
4. sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
5. 外部kafka关闭事务,提交的数据可以正常消费了。
[state](https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/fault-tolerance/state/)
[checkpointing](https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/fault-tolerance/checkpointing/)
[状态后端](https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/dev/datastream/fault-tolerance/state_backends/)
[流式数据的处理](https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/concepts/stateful-stream-processing/)
Flink如何保证数据的一致性相关推荐
- HDFS的特性以及如何保证数据的一致性
链接:https://www.nowcoder.com/questionTerminal/962225fa78e74ba7b1d7d7792407acc6?orderByHotValue=1& ...
- 高并发下如何保证数据的一致性
2019独角兽企业重金招聘Python工程师标准>>> 1.通过悲观锁实现 for update 2.通过乐观锁实现,加字段 3.针对秒杀系统,可以采取将并发请求串行化.放在一个队列 ...
- ElasticSearch 集群是如何保证数据的一致性和实时性?
1. 当我们在说一致性,我们在说什么? 在分布式环境下,一致性指的是多个数据副本是否能保持一致的特性. 在一致性的条件下,系统在执行数据更新操作之后能够从一致性状态转移到另一个一致性状态. 对系统的一 ...
- 如何保证数据最终一致性(分布式事务)
分布式事务种类 按照实现原理分主要有三类:传统事务型.事件通知型.补偿型. 传统事务型(不适用高并发场景,锁定资源较多): 两阶段提交(2PC) 三阶段提交(3PC) 事件通知型: 可靠消息实现模式 ...
- c# mysql代码中写事务_代码中添加事务控制 VS(数据库存储过程+事务) 保证数据的完整性与一致性...
[c#]代码库代码中使用事务前提:务必保证一个功能(或用例)在同一个打开的数据连接上,放到同一个事务里面操作. 首先是在D层添加一个类为了保存当前操作的这一个连接放到一个事务中执行,并事务执行打开同一 ...
- Flink原理解析50篇(四)-基于 Flink CDC 打通数据实时入湖
在构建实时数仓的过程中,如何快速.正确的同步业务数据是最先面临的问题,本文主要讨论一下如何使用实时处理引擎Flink和数据湖Apache Iceberg两种技术,来解决业务数据实时入湖相关的问题. 0 ...
- 基于Flink CDC打通数据实时入湖
作者 | 数据社 责编 | 欧阳姝黎 在构建实时数仓的过程中,如何快速.正确的同步业务数据是最先面临的问题,本文主要讨论一下如何使用实时处理引擎 Flink 和数据湖 Apache Ice ...
- ServiceComb中的数据最终一致性方案
本文由华为微服务引擎技术团队&&ServiceComb社区授权发布. 数据一致性是构建业务系统需要考虑的重要问题 , 以往我们是依靠数据库来保证数据的一致性.但是在微服务架构以及分布式 ...
- Mysql 扩展性设计之数据切分、那么数据切分后会带来哪些问题呢?比如分布式事务、数据的一致性、垂直切分和水平切分应用场景
Mysql 扩展性设计之数据切分.那么数据切分后会带来哪些问题呢?比如分布式事务.数据的一致性.垂直切分和水平切分应用场景 前言.什么是数据切分 垂直(纵向)切分.水平(横向)切分.他们各自的特点 垂 ...
最新文章
- 【IntelliJ IDEA】快捷键
- A Context-aware Attention Network for Interactive Question Answering--阅读笔记
- 浙江理工大学电信宽带校园网访问添加路由表命令(2020.10)(Windows和Liunx)
- signature=35e01da53254eb12b5fc3c020f572e6a,Signature Analyzer Use NXP MCU
- 生命银行怎么样_减脂就像是从“脂肪银行”中提款,想要成功,你要做到这两点...
- python做网络的仿真_用python自动化仿真HFSS,超简易
- SpringBoot页面出现 Whitelabel Error Page
- mybaties专题
- 网信集团:一直在正常运营 高管被带走消息不实
- 杨春立:基于数字孪生的智慧城市顶层设计探索与实践...
- 开源生态研究与实践| ChinaOSC
- 机器学习中的数学——Nesterov Momentum
- C#適應練習:幾種常見設計模式的實現
- 泡菜 亚硝酸_不要相信泡菜
- java我的世界114_我的世界114更新了什么_我的世界114更新内容_快吧单机游戏
- android11.0 Launcher3 高端定制之抽屉列表固定APP显示位置
- 统一认证:移动互联网时代的用户账号一站式管理平台
- 【计算机网络】网络分层:五层或七层因特网协议栈
- TraceView使用
- 最新C++游戏服务器开发