数据结构C语言描述———快速排序算法详解
在学习快速排序的过程中有幸看到了一位大神的博文,觉得对于快速排序的理解与讲解都非常不错:
快速排序萌萌哒详解
坐在马桶上看算法:快速排序
算法的精髓在于,跟它一比高数也显得那么生动活泼…。本文由啊哈磊吐槽而成,话说我还是头一次见到这么萌的变量,简直颠覆我对变量这个兵种、对算法这个种族的传统观念。正在被算法欺负吗?快进来看看:
高快省的排序算法
有没有既不浪费空间又可以快一点的排序算法呢?那就是“快速排序”啦!光听这个名字是不是就觉得很高端呢。
假设我们现在对“6 1 2 7 9 3 4 5 10 8”这个10个数进行排序。首先在这个序列中随便找一个数作为基准数(不要被这个名词吓到了,就是一个用来参照的数,待会你就知道它用来做啥的了)。为了方便,就让第一个数6作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在6的右边,比基准数小的数放在6的左边,类似下面这种排列:
3 1 2 5 4 6 9 7 10 8
在初始状态下,数字6在序列的第1位。我们的目标是将6挪到序列中间的某个位置,假设这个位置是k。现在就需要寻找这个k,并且以第k位为分界点,左边的数都小于等于6,右边的数都大于等于6。想一想,你有办法可以做到这点吗?
排序算法显神威
方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于6的数,再从左往右找一个大于6的数,然后交换他们。这里可以用两个变量i和j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵i”和“哨兵j”。刚开始的时候让哨兵i指向序列的最左边(即i=1),指向数字6。让哨兵j指向序列的最右边(即=10),指向数字。

首先哨兵j开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵j先出动,这一点非常重要(请自己想一想为什么)。哨兵j一步一步地向左挪动(即j--),直到找到一个小于6的数停下来。接下来哨兵i再一步一步向右挪动(即i++),直到找到一个数大于6的数停下来。最后哨兵j停在了数字5面前,哨兵i停在了数字7面前。
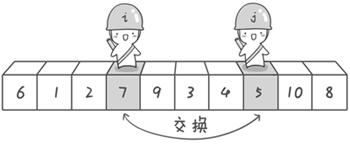
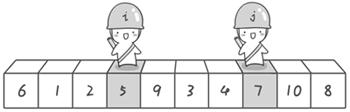
现在交换哨兵i和哨兵j所指向的元素的值。交换之后的序列如下:
6 1 2 5 9 3 4 7 10 8
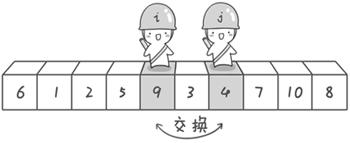
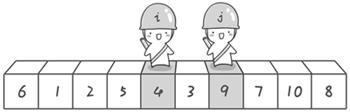
到此,第一次交换结束。接下来开始哨兵j继续向左挪动(再友情提醒,每次必须是哨兵j先出发)。他发现了4(比基准数6要小,满足要求)之后停了下来。哨兵i也继续向右挪动的,他发现了9(比基准数6要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下:
6 1 2 5 4 3 9 7 10 8
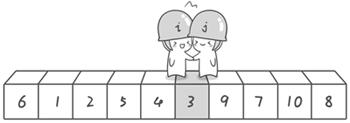
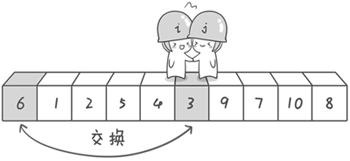
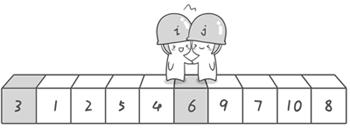
第二次交换结束,“探测”继续。哨兵j继续向左挪动,他发现了3(比基准数6要小,满足要求)之后又停了下来。哨兵i继续向右移动,糟啦!此时哨兵i和哨兵j相遇了,哨兵i和哨兵j都走到3面前。说明此时“探测”结束。我们将基准数6和3进行交换。交换之后的序列如下:
3 1 2 5 4 6 9 7 10 8
到此第一轮“探测”真正结束。此时以基准数6为分界点,6左边的数都小于等于6,6右边的数都大于等于6。回顾一下刚才的过程,其实哨兵j的使命就是要找小于基准数的数,而哨兵i的使命就是要找大于基准数的数,直到i和j碰头为止。
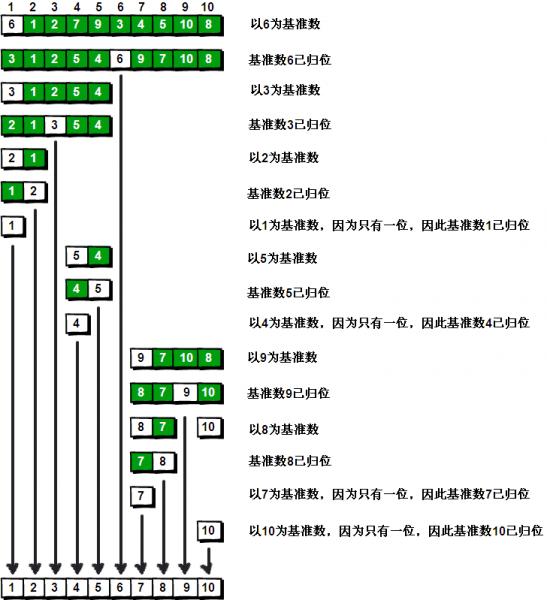
OK,解释完毕。现在基准数6已经归位,它正好处在序列的第6位。此时我们已经将原来的序列,以6为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列。因为6左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理6左边和右边的序列即可。现在先来处理6左边的序列现吧。
左边的序列是“3 1 2 5 4”。请将这个序列以3为基准数进行调整,使得3左边的数都小于等于3,3右边的数都大于等于3。好了开始动笔吧
如果你模拟的没有错,调整完毕之后的序列的顺序应该是:
2 1 3 5 4
OK,现在3已经归位。接下来需要处理3左边的序列“2 1”和右边的序列“5 4”。对序列“2 1”以2为基准数进行调整,处理完毕之后的序列为“1 2”,到此2已经归位。序列“1”只有一个数,也不需要进行任何处理。至此我们对序列“2 1”已全部处理完毕,得到序列是“1 2”。序列“5 4”的处理也仿照此方法,最后得到的序列如下:
1 2 3 4 5 6 9 7 10 8
对于序列“9 7 10 8”也模拟刚才的过程,直到不可拆分出新的子序列为止。最终将会得到这样的序列,如下
1 2 3 4 5 6 7 8 9 10
到此,排序完全结束。细心的同学可能已经发现,快速排序的每一轮处理其实就是将这一轮的基准数归位,直到所有的数都归位为止,排序就结束了。下面上个霸气的图来描述下整个算法的处理过程。
这是为什么呢?
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是O(N2),它的平均时间复杂度为O(NlogN)。其实快速排序是基于一种叫做“二分”的思想。我们后面还会遇到“二分”思想,到时候再聊。先上代码,如下
- #include <stdio.h>
- int a[101],n;//定义全局变量,这两个变量需要在子函数中使用
- void quicksort(int left,int right)
- {
- int i,j,t,temp;
- if(left>right)
- return;
- temp=a[left]; //temp中存的就是基准数
- i=left;
- j=right;
- while(i!=j)
- {
- //顺序很重要,要先从右边开始找
- while(a[j]>=temp && i<j)
- j--;
- //再找右边的
- while(a[i]<=temp && i<j)
- i++;
- //交换两个数在数组中的位置
- if(i<j)
- {
- t=a[i];
- a[i]=a[j];
- a[j]=t;
- }
- }
- //最终将基准数归位
- a[left]=a[i];
- a[i]=temp;
- quicksort(left,i-1);//继续处理左边的,这里是一个递归的过程
- quicksort(i+1,right);//继续处理右边的 ,这里是一个递归的过程
- }
- int main()
- {
- int i,j,t;
- //读入数据
- scanf("%d",&n);
- for(i=1;i<=n;i++)
- scanf("%d",&a[i]);
- quicksort(1,n); //快速排序调用
- //输出排序后的结果
- for(i=1;i<=n;i++)
- printf("%d ",a[i]);
- getchar();getchar();
- return 0;
- }
可以输入以下数据进行验证
1061279345108
运行结果是
12345678910
涨姿势环节
快速排序由 C. A. R. Hoare(东尼霍尔,Charles Antony Richard Hoare)在1960年提出,之后又有许多人做了进一步的优化。如果你对快速排序感兴趣可以去看看东尼霍尔1962年在Computer Journal发表的论文“Quicksort”以及《算法导论》的第七章。快速排序算法仅仅是东尼霍尔在计算机领域才能的第一次显露,后来他受到了老板的赏识和重用,公司希望他为新机器设计一个新的高级语言。你要知道当时还没有PASCAL或者C语言这些高级的东东。后来东尼霍尔参加了由Edsger Wybe Dijkstra(1972年图灵奖得主,这个大神我们后面还会遇到的到时候再细聊)举办的“ALGOL 60”培训班,他觉得自己与其没有把握去设计一个新的语言,还不如对现有的“ALGOL 60”进行改进,使之能在公司的新机器上使用。于是他便设计了“ALGOL 60”的一个子集版本。这个版本在执行效率和可靠性上都在当时“ALGOL 60”的各种版本中首屈一指,因此东尼霍尔受到了国际学术界的重视。后来他在“ALGOL X”的设计中还发明了大家熟知的“case”语句,后来也被各种高级语言广泛采用,比如PASCAL、C、Java语言等等。当然,东尼霍尔在计算机领域的贡献还有很多很多,他在1980年获得了图灵奖。
以上内容均转自一位大神的博文,博文原链接在此:点击打开链接
以下是在看了大神的博文后写的快排完整代码:
#include <stdio.h>
#include <stdlib.h>void quickSort1(int data[],int left,int righ){int i,j,basis,temp;if (left>righ)return;i=left,j=righ;basis=data[left];//以数组中的第一个数作为基数进行比较while (i!=j){while(data[j]>basis&&i<j)j--;while(data[i]<=basis&&i<j)i++;//当data[i]>基数&&data[j]<基数时,交换data[i]跟data[j]的值if (i<j){temp=data[j];data[j]=data[i];data[i]=temp;}}//当i和j相遇时,交换值data[left]=data[i];data[i]=basis;quickSort1(data,left,i-1);quickSort1(data,i+1,righ);
}
void quickSort2(int data[],int left,int righ){int i,j,basis,temp;if (left>righ)return;i=left,j=righ;basis=data[left];//以数组中的第一个数作为基数进行比较while (i!=j){while(data[j]<basis&&i<j)j--;while(data[i]>=basis&&i<j)i++;if (i<j){temp=data[i];data[i]=data[j];data[j]=temp;}}//当i和j相遇时,交换值data[left]=data[i];data[i]=basis;quickSort2(data,left,i-1);quickSort2(data,i+1,righ);
}void main(){FILE *p=NULL;int i=0,j=0;int arr[100];p=fopen("文件的路径.txt","r");//实现的从文件读取数组,并用快排进行排序。当然也可以直接初始化数组。while (fscanf(p,"%d",&arr[i]) != -1){j++;i++;}printf("\n从文件读取数组排序后:\n");quickSort1(arr,0,j-1);for (i=0;i<j;i++){printf("%d ",arr[i]);}printf("\n");printf("随机产生的数组排序前:\n");for (i=0;i<10;i++){arr[i]=rand()%101;//随机产生10个0到100的数字存入数组中printf("%d ",arr[i]);}printf("\n升序排序后:\n");quickSort1(arr,0,9);for (i=0;i<10;i++){printf("%d ",arr[i]);}printf("\n降序排序后:\n");quickSort2(arr,0,9);for (i=0;i<10;i++){printf("%d ",arr[i]);}
}
数据结构C语言描述———快速排序算法详解相关推荐
- SIFT特征点提取及描述论文算法详解
SIFT特征点提取及描述论文算法详解 1. 尺度空间极值检测(Scale-space extrema detection) 1.1 尺度空间和极值 1.2 DoG和LoG的关系 1.3 构建高斯尺度差 ...
- 快速排序算法详解(原理,时间复杂度,实现代码)
快速排序算法详解(原理.实现和时间复杂度) 快速排序是对冒泡排序的一种改进,由 C.A.R.Hoare(Charles Antony Richard Hoare,东尼·霍尔)在 1962 年提出. 快 ...
- 十大经典排序算法-快速排序算法详解
十大经典排序算法 十大经典排序算法-冒泡排序算法详解 十大经典排序算法-选择排序算法详解 十大经典排序算法-插入排序算法详解 十大经典排序算法-希尔排序算法详解 十大经典排序算法-快速排序算法详解 十 ...
- C语言qsort快速排序函数详解
直接进入主题,在c语言中qsort函数是用来快速排序的,qsort有4个参数,分别是数组地址,数组元素个数,数组元素字节大小和一个比较数组元素的函数指针.让我来看一下官方给出的使用标准,上图: 让我们 ...
- 经典排序算法(2)——快速排序算法详解
快速排序(Quick Sort)也是一种典型的交换排序算法,通过交换数据元素的位置进行排序. 一.算法基本思想 (1)基本思想 快速排序的基本思想就是:通过一趟排序将要排序的数据分割成独立的两部分,其 ...
- 快速排序 算法 详解 及 深度优化
下面简介经典算法 快速排序算法 实现及优化. (欢迎大家指点,继续提出优化的方法,共同提高) 基本思想:(以按从小到大排序为例说明)通过多次的排序,每次的排序均将要排序的数组分为两部分,前一部分均比 ...
- 《数据结构C语言版》——二叉树详解(图文并茂)
哈喽!这里是一只派大鑫,不是派大星.本着基础不牢,地动山摇的学习态度,从基础的C语言语法讲到算法再到更高级的语法及框架的学习.更好地让同样热爱编程(或是应付期末考试 狗头.jpg)的大家能够在学习阶段 ...
- matlab稀疏矩阵三元法,数据结构——稀疏矩阵三元组表示法+算法详解
(1).目的:对于在实际问题中出现的大型的稀疏矩阵,若用常规分配方法在计算机中储存,将会产生大量的内存浪费,而且在访问和操作的时候也会造成大量时间上的浪费,为了解决这一问题,从而善生了多种解决方案. ...
- Java的快速排序算法详解
在进入这个话题之前大家可以想想,如果给你一个无序数组,要你处理成一个有序数组,你会怎么做? 可能是双循环的冒泡排序,可能拆开成多个子集合的再合并的希尔排序,排序算法很多,而现在要介绍的是另一种排序方法 ...
- C++数据结构——旅游规划(Floyd算法详解)
旅游规划 作者 陈越 单位 浙江大学 有了一张自驾旅游路线图,你会知道城市间的高速公路长度.以及该公路要收取的过路费.现在需要你写一个程序,帮助前来咨询的游客找一条出发地和目的地之间的最短路径.如果有 ...
最新文章
- 如何用bat文件快速计算项目代码行数
- redis系列(一)-----日常使用详解
- 经典机器学习算法系列3-k近邻算法
- scholar communication
- java jpa 规范_Java:在JPA中使用规范模式
- 第八节: EF的性能篇(一) 之 EF自有方法的性能测试
- python连接不上数据库_绕不过去的Python连接MySQL数据库
- 深度推荐模型(EDRMs):面向Web级应用的基于二进制码的Hash Embedding
- java 前端通过浏览器下载服务器上的文件
- jQuery源码分析(一)
- hadoop put命令的格式_Hadoop Shell命令(基于linux操作系统上传下载文件到hdfs文件系统基本命令学习)...
- 绝对差值和 —— 二分
- 如何将已购kindle电子书转换成pdf格式阅读
- 第527篇-Prism学习系列3_Modularity
- 数据库系统概论-005: 数据库完整性(正确性和相容性)
- bzoj 4765 普通计算姬
- HTML5的基础知识整理
- 关于App置灰黑白化的探索
- python搭建_简单_交易系统【转载】
- Excel如何批量添加图片批注?
热门文章
- 用深度神经网络写一段股市预测代码
- 生成对抗网络 图像生成_用生成对抗网络在10分钟内生成图像
- 最强自动化测试框架Playwright(13)- headed模式运行
- Java线程总结(二):线程的同步方式synchronized
- 用Python分析北上广深的春节返乡趋势
- java 运行executable jar 运行可执行文件的方法
- layui多功能上传文件(视频,图片,pdf)
- 那年伞搁西楼,雨初停情难收,撩青丝微回首,人约黄昏后
- FOXBORO FBM232 P0926GW 以太网通讯模块
- fatal: open /dev/null or dup failed: No such file or directory