如何实现单服务器300万个长连接的?
引自:http://www.zhihu.com/question/20831000
很疑惑,这是吹牛还是真的做到了?
什么是“多消息循环、异步非阻塞”?有什么特点?
用单台服务器实现高连接数,和使用多台服务器实现高连接数,哪种成本更高?
12 个回答
 彭哲夫,一个默默无闻的系统工程师
彭哲夫,一个默默无闻的系统工程师
1. 事件驱动,这个只是为了IO和CPU异步,让CPU从IO等待中解放出来,这样就能在CPU循环中往死里accept连接了,nginx就靠这个把apache玩死的,nodejs的快不仅仅因为这个,语言层的magic就扯远了。
2. 利用双核,2个核就2个进程,一个进程一个事件驱动核(epoll,select啥的),增加链接吞吐。
3. 参数调优,这才是最重要的一步,一个Socket连接默认是有内存消耗的,我不记得Python的Socket占用是4M还是多少来着了,当然这个也可以调优,eurasia的作者沈大侠说过可以搞到2M来着?当然这对于一个24G的服务器来说300w还是搞不定的,但是就送TCP本身来分析的话,tcp_rmem/tcp_wmem,这2个系统tcp读写缓存默认都很高,拉低到4k,然后把tcp_mem也得改下,这个说起来太麻烦,man一下就有了,总的来说就是得拉高High值
4. 网卡要给力,端口给足,句柄加高。
参考文献:100万并发连接服务器笔记之1M并发连接目标达成
从我的测试和此文的结论来看,他在7.5G左右实现了1M并发,24G到3M差不多,我那么挫的水平2G 18W,24G怎么说也能上2M啊,而且如果仅仅是推送,业务层逻辑复杂度不强,等于就是个Proxy所以恩。
至于单台和多台之间的选择,追求技术的,单台你屌你牛逼,追求稳妥Crash也不会造成太大影响还想在推送一层玩点花样用点动态语言的,多台不二选择。
以上。
 徐大白,二半调子码农一只
徐大白,二半调子码农一只
(以下参考值皆是Linux平台上)
1,Linux单个进程可以维持的连接数(fd)理论值是通过ulimit -a设置,或在server内使用setrlimit()设置,具体最大是多少?我看我的64机上是64bits的一个数值,所以,权且认为理论上是2^64-1。 anyway,几百万不是问题。
2,TCP连接数。因为是Server端,不用向系统申请临时端口,只占fd资源。所以tcp连接数不受限制。
3,维持连接当然需要内存消耗,假如每个连接(fd),我们为其分配5k字节(应该足够了,就存放一些用户信息之类的)。这样是5k*3000000=15G。 文中有24G内存,应该也足够了。
================================
下面我们说下文中提及的 多消息循环、异步非阻塞。
先说异步和非阻塞吧。权且认为这俩是一个概念。都是指的IO的异步和非阻塞。
1,异步+非阻塞的话,Linux上必然是epoll了。
原理上简而言之吧,异步就是基于事件的读写,epoll同时监听所有的tcp连接(fd),当有哪些连接上有了事件(读、写、错误),就返回有事件的连接集合,然后处理这个集合里的需要处理的连接事件。这儿就是基于事件的异步IO。
非阻塞。 在得到有事件的tcp连接集合之后,逐一进行读(写)。分开来说,需要读的fd,其实数据已经到OS的tcp buffer里了,读完直接返回,CPU不等待。(返回EAGAIN,其实就进行了几次memcpy); 需要写的连接,同样,其实是把数据写到了OS的tcp buffer里,写满为止。。不会等待对方发来ACK再返回。这样,其实这里CPU基本上只进行了一些memcpy的操作。。即便同时几十万连接有事件,也是瞬间处理完的事。。。然后,CPU再进行异步io等待(epoll_wait())。
当然这儿要充分利用多核,最好将io线程和work线程分开。
2,多消息循环。。这个应该是他们内部的概念。我个人猜测是异步的消息协议。
举例子,传统的TCP连接是一问一答,如HTTP。
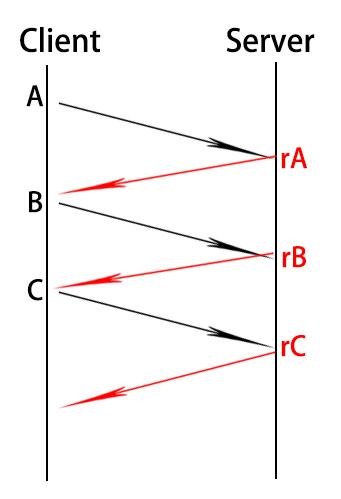
如图,客户端在发送A和发送B之间,CPU就纯等待。服务器在回复A之后,也是纯等待B包的到来。。这样的话。TCP吞吐量很低。
异步协议就是读写完全分开,无需等待(当然,在包内需要自行对应包的ID来识别对应请求包和回复包)。如图
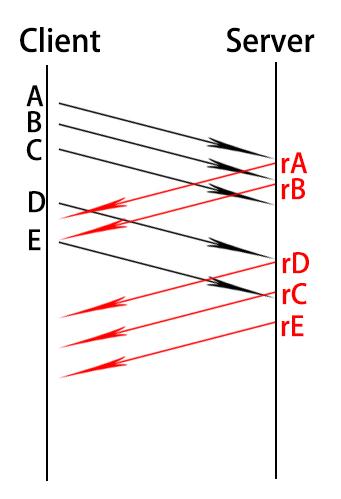
这样的话,双方在任一时刻,都尽最大努力的发包。充分利用tcp连接。使单条TCP连接吞量直线上升。而且,如果其中有一个包处理的极慢,丝豪不影响其他包的回包。
大体推算一下流量,因为300万的客户端均是手机客户端,,假如每个人每天平均收到500条push信息。300万*500=1500000000, 1500000000 /一天86400=17361。一个封装的不错的server每秒进行2W次IO是很轻松的事。
最后说单台Hold大量和多台Hold小量的区别。
成本上肯定是多台的硬件本高了。。但是,这个量级,从架构上,绝对是多台更加合理。我们假如,每个连接有一个用户认证的过程 ,用户认证时要去数据库(或其他类似db)查询用户信息,当你升级服务重启时,300万用户瞬间断开,客户端会重连;再次启动之后,300万用户同时连接,同时请求库。。然后,杯具了。。。
 张博,江湖人,程序员
张博,江湖人,程序员
刚好搜索长连接的时候看到这个问题,就来回答一下,算做是知乎的处女答。
首先理解多消息循环、异步非阻塞从程序设计角度来说是两个层次的东西。
1.多消息循环指的就是利用到epoll或者select来做的IO多路复用机制
2.异步非阻塞是指利用到下层的IO多路复用做的基于事件触发方式的一种设计方式
其实现在的异步模型大同小异,大致过程如下(分三层,一二层就是上面所说的两个层次):
1.(最重要的)维护一个事件反应堆,用epoll或者select或者kqueue来做,反应堆的作用就是用同步的方式处理异步问题,在反应堆上注册好事件后如果相应的事件发生,就调用其回调函数,一般情况下反应堆是一个进程内全局唯一的。
2.上层的buffer,维护一系列的buffer用于管理每一个连接的数据,可以把buffer看做是一个对象。一般在一个连接到达的时候分配一个buffer对象,然后上层的连接注册事件的时候是注册到buffer上,buffer再注册到反应堆中。
3.就是一个个的连接对象,把每一个来自外部的连接都抽象为一个具体的对象,用于管理每一个连接,其中这个对象就包含了上面所说的buffer对象和其他一些状态。
处理并发的过程就是这样的:
1.为监听套接口在反应堆注册一个事件,此事件发生调用对应的回调,一般情况是accept这个连接,然后为这个连接创建连接对象,统一管理。
2.为此连接创建buffer对象,并注册对应的读写错误事件的回调(上层对于buffer的读写事件回调都是业务层来控制的了).
3.在加入监听队列后是离散的,准确来说epoll中是由一颗红黑树维护的,每一个事件的先后顺序跟它达到的顺序有关。
4.维护了众多的连接对象,也就是这里的并发情况了,如果有事件发生会调用回调来处理,理论上无阻塞情况减少了很多CPU的wait,这部分时间用于处理真正的业务,所以异步模型能够带来很高的CPU处理能力,减少等待,单位时间处理的事件越多,从外部来看并发就很高,实际上也是一个串行的工作状态,但是串行过程没有等待。
 达达,程序员
达达,程序员
 张虎,http://yunba.io CEO,原 JPush CTO
张虎,http://yunba.io CEO,原 JPush CTO
单机高连接数好与不好跟业务有一定的相关性,当然跟“钱”也有关系。
如果内存可以更多,还可以维持更多的连接数,无需吹牛。
2013年11月4日更新:
这两天发现还有不少朋友对这个话题有兴趣,再细说一点。
- 消息循环。前面提到过 nginx/node.js 都是采用的 IO 事件触发的消息循环,如果不了解可以直接看代码。
- 多消息循环。在多核 CPU 的服务器,是一个 IO 口上的事件用多个进程处理,充分利用多核的运算能力。每个进程运行一下独立的消息循环,一般来说,进程数据与 CPU 核数相同。
- 异步非阻塞 就更容易理解了。CPU 不同步读写 IO,减少 CPU 等待时间。在业务层面的通讯也全部采用异步模型。
正如我前面提到的,这些模型,在 nginx 上几乎都能找到代码。最近比较流行的 node.js 也有大量异步模型。
2014/06/19 更新:
最近我们用 Erlang 实现了了一个版本,维持长连接的效果也很好,开发时间成本低。
 pig pig,网管
pig pig,网管
2.所谓的“多消息循环、异步非阻塞"只是很简单的东西,很多书上直接有这些东西。就像别的回答一样,不了解具体业务细节,一味夸大某个参数,是有误导推销嫌疑。
3.辩证看待,这家公司可能在开发体验、用户体验以及细节优化方面做的不错。
 罗然,是在下输了
罗然,是在下输了
 知乎用户,运维
知乎用户,运维
main dark,技术宅
 侯廷文
侯廷文
 wang vvic
wang vvic
 VrWorking,Do what U think!
VrWorking,Do what U think!
仅仅凭几个名词无法判断,需要较为详细的架构模型才能分析。
汉字博大精深,会遣词造句的人太多。
如何实现单服务器300万个长连接的?相关推荐
- Netty 通过 WebSocket 编程实现服务器和客户端全双工长连接<2021SC@SDUSC>
2021SC@SDUSC Netty 通过 WebSocket 编程实现服务器和客户端全双工长连接 实例要求: Http 协议是无状态的, 浏览器和服务器间的请求响应一次,下一次会重新创建连接. 要求 ...
- 实现单台测试机6万websocket长连接
本文由作者郑银燕授权网易云社区发布. 本文是我在测试过程中的记录,实现了单台测试机发起最大的websocket长连接数.在一台测试机上,连接到一个远程服务时的本地端口是有限的.根据TCP/IP协议,由 ...
- mysql5.7单表最大容量_mysql 5.7单表300万数据,性能严重下降,如何破?
环境: DB: mysql 5.7.xx OS: windows server 2012 r2 CPU: E3 1220-V5 内存: 4G. 数据库配置(基本上是默认配置): join_buffer ...
- 如何实现android和服务器长连接呢?推送消息的原理
前言:现在的大多数移动端应用都有实时得到消息的能力,简单来说,有发送消息的主动权和接受消息的被动权.例如:微信,QQ,天气预报等等,相信好处和用户体验相信大家都知道吧. 提出问题:这种功能必须涉及cl ...
- 极光推送技术原理:移动无线网络长连接(转自eoe移动开发门户)
看了看极光推送的原理,还不是太明白,现在记录下来,供以后深究.原文如下: 移动互联网应用现状 因为手机平台本身.电量.网络流量的限制,移动互联网应用在设计上跟传统 PC 上的应用很大不一样,需要根据手 ...
- 安卓 休眠 长连接和推送的可选实现
http://www.cnblogs.com/kobe8/p/3819305.html 从上面的连接里面找到了一些资料: 如果一开始就对Android手机的硬件架构有一定的了解,设计出的应用程序 ...
- [NewLife.Net]单机400万长连接压力测试
目标 对网络库NewLife.Net进行单机百万级长连接测试,并持续收发数据,检测网络库稳定性. [2020年8月1日晚上22点] 先上源码:https://github.com/NewLifeX/N ...
- Comet:基于 HTTP 长连接的“服务器推”技术 (实例)
"服务器推"技术的应用 传统模式的 Web 系统以客户端发出请求.服务器端响应的方式工作.这种方式并不能满足很多现实应用的需求,譬如: 1. 监控系统:后台硬件热插拔.LED.温度 ...
- Comet:基于HTTP长连接的“服务器推”技术
作者:周 婷 (zhouting@cn.ibm.com), 软件工程师, IBM 中国软件开发技术实验室 来源:http://www.ibm.com/developerworks/cn/web/wa- ...
最新文章
- BZOJ 3669 魔法森林
- 学Excel函数公式,怎能不会这个组合套路?
- python类似微信未读信息图片脚本
- Servlet中的转发
- 生活质量衡量系统_16个你需要了解的DevOps指标,助你提升软件质量
- 中国 IT 行业平均工资再次碾压金融业,意味着什么?
- 线性代数【八】二次型
- DGIOT国内首家轻量级物联网开源平台——真实电表接入实战教程
- 南阳计算机职称考试报名时间2015,2015河南公务员考试14日起开始报名 南阳市计划招录590人...
- RK3399 opencv rtsp流报错drm prime is not supported as input pixel format
- python爬取网易云音乐飙升榜音乐_Python爬虫实战,30行代码轻松爬取网易云音乐热歌榜...
- response.setHeader()方法设置http文件头的值
- Python3正则表达式(慢慢更新中~)
- mysql中的locate_mysql中LOCATE和CASE WHEN...THEN...ELSE...END结合用法
- pandas数据合并:concat、join、append
- uni-app下使用vant组件
- C语言——结构体(入门详解)
- 知网查重提交论文显示服务器错误,知网查重怎么会提交失败
- 信号与系统2023第三次作业辅导视频:差分方程求解
- 免费内网穿透 对外一键发布网站 穿透80端口