分类预测回归预测_我们应该如何汇总分类预测?
分类预测回归预测
If you are reading this, then you probably tried to predict who will survive the Titanic shipwreck. This Kaggle competition is a canonical example of machine learning, and a right of passage for any aspiring data scientist. What if instead of predicting who will survive, you only had to predict how many will survive? Or, what if you had to predict the average age of survivors, or the sum of the fare that the survivors paid?
如果您正在阅读本文,那么您可能试图预测谁将在泰坦尼克号沉船中幸存。 这场Kaggle竞赛是机器学习的典范,也是任何有抱负的数据科学家的通行权。 如果不必预测谁将生存,而只需要预测多少将生存怎么办? 或者,如果您必须预测幸存者的平均年龄或幸存者支付的车费之和怎么办?
There are many applications where classification predictions need to be aggregated. For example, a customer churn model may generate probabilities that a customer will churn, but the business may be interested in how many customers are predicted to churn, or how much revenue will be lost. Similarly, a model may give a probability that a flight will be delayed, but we may want to know how many flights will be delayed, or how many passengers are affected. Hong (2013) lists a number of other examples from actuarial assessment to warranty claims.
在许多应用中,需要汇总分类预测。 例如,客户流失模型可能会产生客户流失的概率,但是企业可能会对预计有多少客户流失或将损失多少收入感兴趣。 同样,模型可能会给您一个航班延误的可能性,但我们可能想知道有多少航班会延误,或者有多少乘客受到影响。 Hong(2013)列举了从精算评估到保修索赔的许多其他示例。
Most binary classification algorithms estimate probabilities that examples belong to the positive class. If we treat these probabilities as known values (rather than estimates), then the number of positive cases is a random variable with a Poisson Binomial probability distribution. (If the probabilities were all the same, the distribution would be Binomial.) Similarly, the sum of two-value random variables where one value is zero and the other value some other number (e.g. age, revenue) is distributed as a Generalized Poisson Binomial. Under these assumptions we can report mean values as well as prediction intervals. In summary, if we had the true classification probabilities, then we could construct the probability distributions of any aggregate outcome (number of survivors, age, revenue, etc.).
大多数二进制分类算法都会估计示例属于肯定类的概率。 如果我们将这些概率视为已知值(而不是估计值),则阳性病例数是具有泊松二项式概率分布的随机变量。 (如果概率都相同,则分布将为二项式。)类似地,二值随机变量的总和(其中一个值为零,而另一个值为其他数字(例如年龄,收入))作为广义泊松分布二项式 在这些假设下,我们可以报告平均值以及预测间隔。 总而言之,如果我们拥有真正的分类概率,那么我们可以构建任何总体结果(幸存者的数量,年龄,收入等)的概率分布。
Of course, the classification probabilities we obtain from machine learning models are just estimates. Therefore, treating the probabilities as known values may not be appropriate. (Essentially, we would be ignoring the sampling error in estimating these probabilities.) However, if we are interested only in the aggregate characteristics of survivors, perhaps we should focus on estimating parameters that describe the probability distributions of these aggregate characteristics. In other words, we should recognize that we have a numerical prediction problem rather than a classification problem.
当然,我们从机器学习模型中获得的分类概率只是估计值。 因此,将概率视为已知值可能不合适。 (从本质上讲,在估计这些概率时,我们将忽略采样误差。)但是,如果我们仅对幸存者的总体特征感兴趣,那么也许我们应该专注于估算描述这些总体特征的概率分布的参数。 换句话说,我们应该认识到我们有一个数值预测问题,而不是分类问题。
I compare two approaches to getting aggregate characteristics of Titanic survivors. The first is to classify and then aggregate. I estimate three popular classification models and then aggregate the resulting probabilities. The second approach is a regression model to estimate how aggregate characteristics of a group of passengers affect the share that survives. I evaluate each approach using many random splits of test and train data. The conclusion is that many classification models do poorly when the classification probabilities are aggregated.
我比较了两种获取泰坦尼克号幸存者总体特征的方法。 首先是分类,然后汇总 。 我估计了三种流行的分类模型,然后合计了得出的概率。 第二种方法是一种回归模型,用于估计一组乘客的总体特征如何影响幸存的份额。 我使用许多随机的测试和训练数据评估每种方法。 结论是,当汇总分类概率时,许多分类模型的效果不佳。
1.分类和汇总方法 (1. Classify and Aggregate Approach)
Let’s use the Titanic data to estimate three different classifiers. The logistic model will use only age and passenger class as predictors; Random Forest and XGBoost will also use sex. I train the model on the 891 passengers in Kaggle’s training data. I evaluate the predictions on the 418 in the test data. (I obtained the labels for the test set to be able to evaluate my models.)
让我们使用Titanic数据来估计三个不同的分类器。 逻辑模型将仅使用年龄和乘客等级作为预测因子; 随机森林和XGBoost也将使用性别。 我在Kaggle的训练数据中为891名乘客训练了模型。 我在测试数据中评估418的预测。 (我获得了测试集的标签,以便能够评估我的模型。)

The logistic model with only age and passenger class as predictors has an AUC of 0.67. Random Forest and XGBoost that also use sex reach a very respectable AUC of around 0.8. Our task, however, is to predict how many passengers will survive. We can estimate this by adding up the probabilities that a passenger will survive. Interestingly, of the three classifiers, the logistic model was the closest to the actual number of survivors despite having the lowest AUC. It is also worth noting that a naive estimate based on the share of survivors in the training data did best of all.
仅以年龄和乘客等级为预测因子的逻辑模型的AUC为0.67。 同样使用性行为的Random Forest和XGBoost的AUC达到了非常可观的0.8。 但是,我们的任务是预测有多少乘客能够幸存。 我们可以通过将乘客生存的概率相加来估计这一点。 有趣的是,在三个分类器中,逻辑模型尽管AUC最低,但与实际幸存者数量最接近。 还值得注意的是,基于幸存者在训练数据中所占份额的天真估计最能说明问题。
Given the probabilities of survival for each passenger in the test set, the number of passengers that will survive is a random variable distributed Poisson Binomial. The mean of this random variable is the sum of the individual probabilities. The percentiles of this distribution can be obtained using the `poibin` R package developed by Hong (2013). A similar package for Python is under development. The percentiles can also be obtained through brute force by simulating 10,000 different sets of outcomes for the 418 passengers in the test set. The percentiles can be interpreted as prediction intervals telling us that the actual number of survivors will be within this interval with 95% probability.
给定测试集中每个乘客的生存概率,将生存的乘客数量是一个随机变量分布的Poisson Binomial。 该随机变量的平均值是各个概率的总和。 可以使用Hong(2013)开发的`poibin` R软件包来获得该分布的百分位数。 类似的Python包正在开发中。 通过为测试集中的418位乘客模拟10,000种不同的结果集,还可以通过蛮力获得百分位数。 百分位可以解释为预测间隔,告诉我们幸存者的实际数量将以95%的概率在此间隔内。
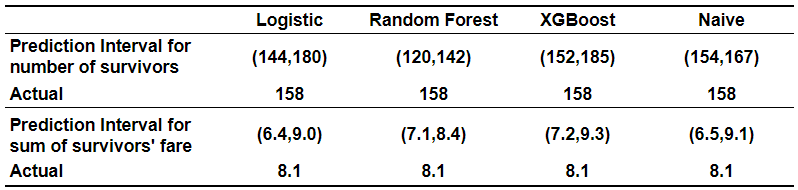
The interval based on the Random Forest probabilities widely missed the actual number of survivors. It is worth noting that the width of the interval is not necessarily based on the accuracy of the individual probabilities. Instead, it depends on how far those individual probabilities are from 0.5. Probabilities close to 0.9 or 0.1 rather than 0.5 mean that there is a lot less uncertainty as to how many passengers will survive. A good discussion of forecast reliability versus sharpness is here.
基于随机森林概率的时间间隔大大错过了幸存者的实际数量。 值得注意的是,间隔的宽度不一定基于各个概率的准确性。 取而代之的是,它取决于这些个体概率与0.5之间的差值。 概率接近0.9或0.1而不是0.5意味着,有多少乘客能够幸存,其不确定性要小得多。 这里对预测的可靠性与清晰度进行了很好的讨论。
While the number of survivors is a sum of zero/one random variables (Bernoulli trials), we may also be interested in predicting other aggregate characteristics of the survivors, e.g. total fare paid by the survivors. This measure is a sum of two-value random variables where one value is zero (passenger did not survive) and the other one is the fare that the passenger paid. Zhang, Hong and Balakrishnan (2018) call the probability distribution of this sum Generalized Poisson Binomial. As with Poisson Binomial, Hong, co-wrote an R package, GPB, that makes computing the probability distributions straightforward. Once again, simulating the distribution is an alternative to using the packages to compute percentiles.
虽然幸存者的数量是零/一个随机变量的总和(Bernoulli试验),但我们也可能对预测幸存者的其他总体特征感兴趣,例如,由幸存者支付的总票价。 此度量是两个值随机变量的总和,其中一个值为零(乘客无法幸存),另一个为乘客支付的票价。 Zhang,Hong和Balakrishnan(2018)称该和为广义泊松二项式的概率分布。 像Hong的Poisson Binomial一样,编写了R程序包GPB ,这使得计算概率分布变得简单。 再一次,模拟分布是使用软件包计算百分位数的替代方法。
2.总体回归法 (2. Aggregate Regression Approach)
If we only care about the aggregate characteristics of survivors, then we really have a numerical prediction problem. The simplest estimate of the share of survivors in the test set is the share of survivors in the training set — it is the naive estimate from the previous section. This estimate is probably unbiased and efficient if the characteristics of passengers in the test and train sets are identical. If not, then we would want an estimate of the share of survivors conditional on the characteristics of the passengers.
如果我们只关心幸存者的总体特征,那么我们确实有一个数值预测问题。 测试集中幸存者份额的最简单估计是训练集中幸存者的份额-这是上一节中的幼稚估计。 如果测试组和火车组中的乘客特征相同,则此估计可能是公正且有效的。 如果没有,那么我们将希望根据乘客的特征估算幸存者的份额。
The issue is that we don’t have the data to estimate how aggregate characteristics of a group of passengers affect the share that survived. After all, the Titanic hit the iceberg only once. Perhaps in other applications such as customer churn, we may have new data every month.
问题在于,我们没有数据来估计一组乘客的总体特征如何影响幸存的份额。 毕竟,泰坦尼克号只击中了冰山一次。 也许在其他应用程序(例如客户流失)中,我们可能每个月都有新数据。
In the Titanic case I resort to simulating many different training data sets by re-sampling the original training data set. I calculate the average characteristics of each simulated data set to estimate of how these characteristics affect the share that will survive. I then take the average characteristics of passengers in the test set and predict how many will survive in the test set. There are many different ways one could summarize the aggregate characteristics. I use the share of passengers in first class, the share of passengers under the age of 10 and the share of female passengers. Not surprisingly, the samples of passengers that have more women, children and first class passengers have a higher share of survivors.
在泰坦尼克号案例中,我通过对原始训练数据集进行重新采样来模拟许多不同的训练数据集。 我计算每个模拟数据集的平均特征,以估计这些特征如何影响将生存的份额。 然后,我将测试集中的乘客的平均特征,并预测有多少人将在测试集中幸存。 有多种不同的方式可以总结总体特征。 我使用头等舱乘客的份额,10岁以下乘客的份额和女性乘客的份额。 毫不奇怪,拥有更多妇女,儿童和头等舱乘客的乘客样本中幸存者的比例更高。

Applying the above equation to aggregate characteristics of the test data, I predict 162 survivors against the actual of 158 with a prediction interval of 151 to 173. Thus, the regression approach worked quite well.
将上述方程式应用到测试数据的总体特征中,我预测了162个幸存者,而实际值是158,而预测间隔为151到173。因此,回归方法工作得很好。
3.两种方法比较如何? (3. How Do the Two Approaches Compare?)
So far, we evaluated the two approaches using only one test set. In order to compare the two approaches more systematically, I re-sampled from the union of the original train and test data set to create five hundred new train and test data sets. I then applied the two approaches five hundred times and calculated the mean square error of each approach across these five hundred samples. The graphs below show the relative performance of each approach.
到目前为止,我们仅使用一个测试集评估了这两种方法。 为了更系统地比较这两种方法,我从原始火车和测试数据集的联合中重新采样以创建五百个新的火车和测试数据集。 然后,我对这两种方法进行了500次应用,并计算了这500种样本中每种方法的均方误差。 下图显示了每种方法的相对性能。

Among the classification models, the logistic model did best (had the lowest MSE). XGBoost is a relatively close second. Random Forest is way off. The accuracy of aggregate predictions depends crucially on the accuracy of the estimated probabilities. The logistic regression directly estimates the probability of survival. Similarly, XGBoost optimizes a logistic loss function. Therefore, both provide a decent estimate of probabilities. In contrast, Random Forest estimates probabilities as shares of trees that classified the example as success. As pointed out by Olson and Wyner (2018), the share of trees that classified the example as a success has nothing to do with the probability that the example will be a success. (For the same reason, calibration plots for Random Forest tend to be poor.) Although Random Forest can deliver a high AUC, the estimated probabilities are inappropriate for aggregation.
在分类模型中,逻辑模型表现最好(MSE最低)。 XGBoost相对来说排名第二。 随机森林渐行渐远。 聚合预测的准确性主要取决于估计概率的准确性。 逻辑回归直接估计生存的可能性。 同样,XGBoost优化了物流损失功能。 因此,两者都提供了不错的概率估计。 相反,随机森林将概率估计为将示例归类为成功的树木份额。 正如Olson和Wyner(2018)指出的那样,将示例成功分类为树木的份额与示例成功的可能性无关。 (出于同样的原因,随机森林的标定图往往很差。)尽管随机森林可以提供较高的AUC,但估计的概率不适合汇总。
The aggregate regression model had the lowest MSE of all the approaches, beating even the classification logistic model. The naive predictions are handicapped in this evaluation because the share of survivors in the test data is not independent of the share of survivors in the train data. If we happen to have many survivors in the train, we will naturally have fewer survivors in the test. Even with this handicap, naive predictions handily beat XGBoost and Random Forest.
总体回归模型具有所有方法中最低的MSE,甚至超过了分类逻辑模型。 由于测试数据中幸存者的比例与火车数据中幸存者的比例无关,因此天真的预测在此评估中受到了限制。 如果我们碰巧有很多幸存者在火车上,那么我们自然会减少测试中的幸存者。 即使有这种障碍,幼稚的预测也轻易击败了XGBoost和Random Forest。
4。结论 (4. Conclusion)
If we only need aggregate characteristics, estimating and aggregating individual classification probabilities seems like more trouble than is needed. In many cases, the share of survivors in the train set is a pretty good estimate of the share of survivors in the test set. Customer churn rate this month is probably a pretty good estimate of churn rate next month. More complicated models are worth building if we want to understand what drives survival or churn. It is also worth building more complicated models when our training data has very different characteristics than the test data, and when these characteristics affect survival or churn. Still, even in these cases, it is clear that using methods that are optimized for individual classifications could be inferior to methods optimized for a numerical prediction when a numerical prediction is needed.
如果我们只需要汇总特征,则估计和汇总单个分类概率似乎比需要的麻烦更多。 在许多情况下,训练集中幸存者的比例是对测试集中幸存者比例的一个很好的估计。 本月的客户流失率可能是下个月流失率的相当不错的估计。 如果我们想了解驱动生存或流失的因素,则更复杂的模型值得构建。 当我们的训练数据与测试数据具有非常不同的特征并且这些特征影响生存或流失时,也值得建立更复杂的模型。 尽管如此,即使在这些情况下,很明显,当需要数值预测时,使用针对单个分类优化的方法可能不如针对数值预测优化的方法。
You can find the R code behind this note here.
您可以在此处找到此注释后面的R代码。
翻译自: https://towardsdatascience.com/how-should-we-aggregate-classification-predictions-2f204e64ede9
分类预测回归预测
http://www.taodudu.cc/news/show-997436.html
相关文章:
- 神经网络推理_分析神经网络推理性能的新工具
- 27个机器学习图表翻译_使用机器学习的信息图表信息组织
- 面向Tableau开发人员的Python简要介绍(第4部分)
- 探索感染了COVID-19的动物的数据
- 已知两点坐标拾取怎么操作_已知的操作员学习-第4部分
- lime 模型_使用LIME的糖尿病预测模型解释— OneZeroBlog
- 永无止境_永无止境地死:
- 吴恩达神经网络1-2-2_图神经网络进行药物发现-第1部分
- python 数据框缺失值_Python:处理数据框中的缺失值
- 外星人图像和外星人太空船_卫星图像:来自太空的见解
- 棒棒糖 宏_棒棒糖图表
- nlp自然语言处理_不要被NLP Research淹没
- 时间序列预测 预测时间段_应用时间序列预测:美国住宅
- 经验主义 保守主义_为什么我们需要行动主义-始终如此。
- python机器学习预测_使用Python和机器学习预测未来的股市趋势
- knn 机器学习_机器学习:通过预测意大利葡萄酒的品种来观察KNN的工作方式
- python 实现分步累加_Python网页爬取分步指南
- 用于MLOps的MLflow简介第1部分:Anaconda环境
- pymc3 贝叶斯线性回归_使用PyMC3估计的贝叶斯推理能力
- 朴素贝叶斯实现分类_关于朴素贝叶斯分类及其实现的简短教程
- vray阴天室内_阴天有话:第1部分
- 机器人的动力学和动力学联系_通过机器学习了解幸福动力学(第2部分)
- 大样品随机双盲测试_训练和测试样品生成
- 从数据角度探索在新加坡的非法毒品
- python 重启内核_Python从零开始的内核回归
- 回归分析中自变量共线性_具有大特征空间的回归分析中的变量选择
- python 面试问题_值得阅读的30个Python面试问题
- 机器学习模型 非线性模型_机器学习:通过预测菲亚特500的价格来观察线性模型的工作原理...
- pytorch深度学习_深度学习和PyTorch的推荐系统实施
- 数据库课程设计结论_结论:
分类预测回归预测_我们应该如何汇总分类预测?相关推荐
- 使用机器学习预测天气_使用机器学习的二手车价格预测
使用机器学习预测天气 You can reach all Python scripts relative to this on my GitHub page. If you are intereste ...
- 时间序列预测方法_让我们使用经典方法预测您的时间序列
时间序列预测方法 时间序列预测 (Time Series Forecasting) 背景 (Background) We learned various data preparation techni ...
- 遥感分类误差矩阵_遥感卫星影像之分类精度评价
原标题:遥感卫星影像之分类精度评价 对一帧遥感影像进行专题分类后需要进行分类精度的评价,而进行评价精度的因子有混淆矩阵.总体分类精度.Kappa系数.错分误差.漏分误差.每一类的制图精度和拥护精度. ...
- python交通流预测算法_基于机器学习的交通流预测技术的研究与应用
摘要: 随着城市化进程的加快,交通系统的智能化迫在眉睫.作为智能交通系统的重要组成部分,短时交通流预测也得到了迅速的发展,而如何提升短时交通流预测的精度,保障智能交通系统的高效运行,一直是学者们研究的 ...
- python财务报表预测股票价格_建模股票价格数据并进行预测(统计信号模型):随机信号AR模型+Yule-Walker方程_Python...
1.背景: 针对股票市场中AR 模型的识别.建立和估计问题,利用AR 模型算法对股票价格进行预测. 2.模型选取: 股票的价格可视为随机信号,将此随机信号建模为:一个白噪声通过LTI系统的输出,通过原 ...
- python 二分类的实例_深入理解GBDT二分类算法
我的个人微信公众号:Microstrong 微信公众号ID:MicrostrongAI 微信公众号介绍:Microstrong(小强)同学主要研究机器学习.深度学习.计算机视觉.智能对话系统相关内容, ...
- 使用cnn预测房价_使用CNN的人和马预测
使用cnn预测房价 There are many transfer learning methods to solve classification problems with respect to ...
- #时间预测算法_基于超级学习者机器学习算法预测ICU患者急性低血压发作
点击"蓝字"关注,更多精彩内容! 背景 急性低血压发作(AHE),定义为平均动脉压下降至<65mmHg且至少持续5分钟,是重症监护病房(ICU)最严重的不良事件,往往导致重症 ...
- python 预测算法_通过机器学习的线性回归算法预测股票走势(用Python实现)
本文转自博客园,作者为hsm_computer 原文链接:https://www.cnblogs.com/JavaArchitect/p/11717998.html在笔者的新书里,将通过股票案例讲述P ...
最新文章
- java的线程管理器,QuickThread - Java线程池管理器
- Linux 下查看系统是32位 还是64 位的方法
- 【Jetson-Nano】2.Tensorflow object API和Pytorch的安装
- 训练日志 2019.3.28
- [论文翻译]Sequence to Sequence Learning with Neural Networks
- unef螺纹_统一螺纹(美制螺纹)UN,UNC,UNF,UNEF详细区别
- 【云计算学习教程】探讨私有云计算平台的搭建(附带3套解决方案)
- LOI2504 [HAOI2006]聪明的猴子
- office word安装mathtype报错,找不到mathpage.WLL文件
- FlinkX数据同步
- CMAP1000-05气象数字压力校验系统
- C语言fscanf函数的理解
- 【渝粤题库】广东开放大学 文化创意学 形成性考核
- 关于智能语音机器人使用中可能出现的问题
- chrome新版不支持旺旺 支付宝 插件的解决方法
- web容器的加载过程
- bom树形结构 表设计_K/3管理视角:树形结构下的BOM管理方式!
- 机器学习岗位面试问题汇总 之 深度学习
- 系统集成项目管理工程师答题卡样式
- 实验17:DS18B20温度传感器