大话数据结构读书笔记系列(五)串
2019独角兽企业重金招聘Python工程师标准>>> 
5.1 开场白
同学们,大家好!我们开始上新的一课。
我们古人没有电影电视,没有游戏网络,所以文人们就会想出一些文字游戏来娱乐。比如宋代的李禺写了这样一首诗:"枯眼望遥山隔水,往来曾见几心知?壶空怕酌一杯酒,笔下难成和韵诗。途路阻人离别久,迅音无雁寄回迟。孤灯夜守长寥寂,夫忆妻兮父忆儿。"显然这个老公想念老婆和儿子的诗句。曾经和妻儿在一起,尽享天伦之乐,现在一个人长久没有回家,也不见书信返回,望着油灯想念亲人,能不伤感吗?
可再仔细一读发现,这首诗竟然可以倒过来读:"儿忆父兮妻忆夫,寂寥长守夜灯孤。迟回寄雁无音讯,久别离人阻路途。诗韵和成难下笔,酒杯一酌怕空壶。知心几见曾来往,水隔山遥望眼枯。"这表达了什么意思呢?呵呵,表达了妻子对丈夫的思念。老公离开好久,路途遥远,难以相见。写信不知道写什么,独自喝酒也没什么兴致。只能和儿子夜夜守在家里一盏孤灯下,苦等老公的归来。
这种诗体叫做回文诗。它是一种可以倒读或反复回旋阅读的诗体。刚才这首就是正读是丈夫思念妻子,倒读是妻子思念丈夫的古诗。是不是感觉很奇妙呢?
在英语单词中,同样有神奇的地方。"即使是lover也有个over,即使是friend也有个end,即使是believe也有个lie"。你会发现,本来不相干,甚至对立的两个词,却有某种神奇的联系。这可能是创造这几个单词的那么智者们也没有想到的问题。
今天我们就要来谈谈这些单词或句子组成字符串的相关问题。
5.2 串的定义
早先的计算机在被发明时,主要作用是做一些科学和工程的计算工作,也就是现在我们理解的计算器,只不过它比小小计算器功能更强大、速度更快一些。后来发现,在计算机上作非数值处理的工作越来越多,使得我们不得不需要引入对字符的处理。于是就有了字符串的概念。
比如我们现在常用的搜索引擎,当我们在文本框中输入"数据"时,它已经把我们想要的"数据结构"列在下面了。显然这里网站作了一个字符串查找匹配的工作,如图5-2-1所示。 
今天我们就是来研究"串"这样的数据结构。先来看定义。
串(String)是由零个或多个字符组成的有限序列,又名叫字符串。
一般记为s="a1a2...an"(n>0),其中,s是串的名称,用双引号(有些书中也用单引号)括起来的字符序列是串的值,注意单引号不属于串的内容。ai(1<=i<=n)可以是字母、数字或其他字符,i就是该字符在串中的位置。串中的字符数目n称为串的长度,定义中谈到"有限"是指长度n是一个有限的数值。零个字符的串称为空串(null string),它的长度为零,可以直接用两双引号""""表示,也可以用希腊字母"ø"来表示。所谓的序列,说明串的相邻字符之间具有前驱和后继的关系。
还有一些概念需要解释。
- 空格串,是只包含空格的串。注意它与空串的区别,空格串是有内容有长度的,而且可以不止一个空格。
- 子串与主串,串中任意个数的连续字符组成的子序列称为该串的子串,相应地,包含子串的串称为主串。
- 子串在主串中的位置就是子串的第一个字符在主串中的序号。
- 开头我所提到的"over"、"end"、"lie"其实可以认为是"lover"、"friend"、"believe"这些单词字符串的子串。
5.3 串的比较
两个数字,很容易比较大小。2比1大,这完全正确,可是两个字符串如何比价?比如"silly"、"stupid"这样的同样表达"愚蠢的"的单词字符串,它们在计算机中的大小其实取决于它们挨个字母的前后顺序。它们的第一个字母都是"s",我们认为不存在大小差异,而第二个字母,由于"i"字母比"t"字母要靠前,所以"i"<"t",于是我们说"silly"<"stupid"。
事实上,串的比较是通过组成串的字符之间的编码来进行的,而字符的编码指的是字符在对应字符集中的序号。
计算机中的常用字符是使用标准的ASCII编码,更准确一点,由7位二进制数表示一个字符,总共可以表示256个字符,这已经足够满足以英语为主的语言的特殊符号进行输入、存储、输出等操作的字符需要了。可是,单我们国家就有除汉族外的满、回、藏、蒙古、维吾尔等多个少数民族文字,换作全世界估计要有成百上千种语言与文字,显然这256个字符是不够的,因此后来就有了Unicode编号,比较常用的是由16位的二进制表示一个字符,这样总共就可以表示216个字符,约是65万多个字符,足够表示世界上所有语言的所有字符了。当然,为了和ASCII码兼容,Unicode的前256个字符与ASCII码完全相同。
所以如果我们要在C语言中比较两个串是否相等,必须是它们串的长度以及它们各个对应位置的字符都相等时,才算是相等。即给定两个串:s="a1a2...an",t="b1b2...bm",当且仅当n=m,且a1=b1,a2=b2,...,an=bm时,我们认为s=t。
那么对于两个串不相等时,如何判定它们的大小呢。我们这样定义:
- n<m,且ai=bi(i=1,2,...,n)。 例如当s="hap",t="happy",就有s<t。因为t比s多出了两个字母。
- 存在某个k<=min(m,n),使得ai=bi(i=1,2,...,k-1),ak<bk。 例如当s="happen",t="happy",因为两串的前4个字母均相同,而两串第5个字母(k值),字母e的ASCII码是101,而字母y的ASCII码是121,显然e<y,所以s<t。(>)
有同学如果对这样的数学定义很不爽的话,那我再说一个字符串比较的应用。
我们的英语词典,通常都是上万个单词的有序排列。就大小而言,前面的单词比后面的要小。你在查找单词的过程,其实就是在比较字符串大小的过程。
5.4 串的抽象数据类型
串的逻辑结构和线性表很相似,不同之处在于串针对的是字符集,也就是串中的元素都是字符,哪怕串中的字符是"123"这样的数字组成,或者"2010-10-10"这样的日期组成,它们都只能理解为长度为3和长度为10的字符串,每个元素都是字符而已。
因此,对于串的基本操作与线性表是有很大差别的,线性表更关注的是单个元素的操作,比如查找一个元素,插入或删除一个元素,但串中更多的是查找子串位置、得到指定位置子串、替换子串等操作。 
对于不同的高级语言,其实对串的基本操作会有不同的定义方法,所以同学们在用某个语言操作字符串时,需要先查看它的参考手册关于字符串的基本操作有哪些。不过还好,不同语言除方法名称外,操作实质都是相类似的。比如C#中,字符串操作就还有ToLower转小写、ToUpper转大写、IndecOf从左查找子串位置(操作名有修改)、LastIndexOf从右查找子串位置、Trim去除两边空格等比较方便的操作,他们其实就是前面这些基本操作的扩展函数。
我们来看一个操作Index的实现算法。 

当中用到了StrLength、SubString、StrCompare等基本操作来实现。
5.5 串的存储结构
串的存储结构与线性表相同,分为两种。
5.5.1 串的顺序存储结构
串的顺序存储结构是用一组地址连续的存储单元来存储串中的字符序列的。按照预定义的大小,为每个定义的串变量分配一个固定长度的存储区。一般是用定长数组来定义。
既然是定长数组,就存在一个预定义的最大串长度,一般可以将实际的串长度值保存在数组的0下标位置,有的书中也会定义存储在数组的最后一个下标位置。但也有些编程语言不想这么干,觉得存个数字占个空间麻烦。它规定在串值后面加一个不计入串长度的结束标记字符,比如"\0"来表示串值的终结,这个时候,你要想知道此时的串长度,就需要遍历计算一下才知道了,其实这还是需要占用一个空间,何必呢。 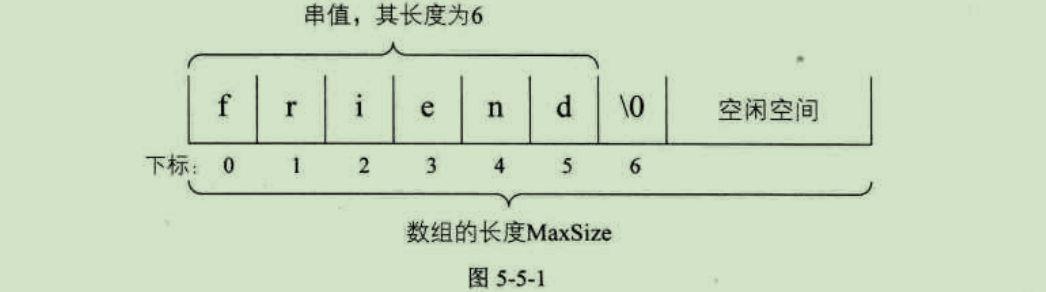
刚才讲的串的顺序存储方式其实是有问题的,因为字符串的操作,比如两串的连接Concat、新串的插入StrInsert,以及字符串的替换Replace。都有可能使得串序列的长度超过了数组的长度MaxSize。
说说我当年的一件囧事。手机发送短信时,运营商规定每条短信限制70个字。大约八年前,我的手机每当学了超过70个字后,它就提示"短信过长,请删减后重发"。后来我换了一个手机后再也没有这样见鬼的提示了,我很高兴。一次,因为一点小矛盾需要向当时的女友解释一下,我准备发一条短信,一共打了79个字。最后的部分字实际上"......只会说好听的话,像'我恨你'这种话是不可能的"。点发送。后来得知对方收到的,只有70个字,短信结尾是"......只会说好听的话,像'我恨你'"。 
有这样截断的吗?我后来知道这个情况后,恨不得把手机砸了。显然,无论是上溢提示报错,还是对多出来的字符串截尾,都不是什么好办法。但字符串操作中,这种情况比比皆是。
于是对于串的顺序存储,有一些变化,串值的存储空间可再程序执行过程中动态分配而得。比如在计算机中存在一个自由存储区,叫做"堆"。这个堆可由C语言的动态分配函数malloc()和free()来管理。
串的链式存储结构
对于串的链式存储结构,与线性表是相似的,但由于串结构的特殊性,结构中的每个元素数据是一个字符,如果也简单的应用链表存储串值,一个结点对于一个字符,就会存在很大的空间浪费。因此,一个结点可以存放一个字符,也可以考虑存放多个字符,最后一个结点若是未被占满时,可以用"#"或其他非串值字符补全,如图5-5-3所示。 
当然,这里一个结点存多少个字符才合适就变得很重要,这会直接影响着串处理的效率,需要根据实际情况作出选择。
但串的链式存储结构除了在连接串与串操作时有一定方便之外,总的来说不如顺序存储灵活,性能也不如顺序存储结构好。
5.6 朴素的模式匹配算法
记得我在刚做软件开发的时候,需要阅读一些英文的文章或帮助。此时才发现学习英语不只是为了过四六级,工作中它还是挺重要的。而我那只为应付考试的英语,早已经忘得差不多了。于是我想在短时间内突击一些,很明显,找一本词典从头开始背不是什么好的办法。要背也得背那些最常用的,至少是计算机文献中常用的,于是我就想自己写一个程序,只要输入一些英文的文档,就可以计算出这当中所用频率最高的词汇是哪些。把它们都背好了,基本上阅读也就不成问题了。
当然,说说容易,要实现这一需求,当中会有很多困难,有兴趣的同学,不妨去试试看。不过,这里面最重要其实就是去找一个单词咋一篇文章(相当于一个大字符串)中的定位问题。这种子串的定位操作通常称做串的模式匹配,应该算是串中最重要的操作之一。
假设我们要从下面的主串S="goodgoogle"中,找到T="google"这个子串的位置。我们通常需要下面的步骤。
主串S第一位开始,S与T前三个字母都匹配成功,但S第四个字母是d而T的是g。第一位匹配失败。如图5-6-1所示,其中竖直连线表示相等,闪电状弯折连线表示不等。
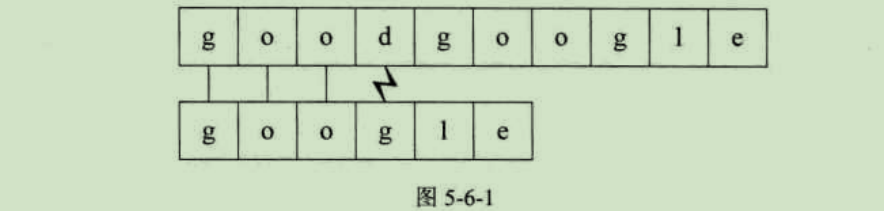
主串S第二位开始,主串S首字母是o,要匹配的T首字母是g,匹配失败,如图5-6-2所示。
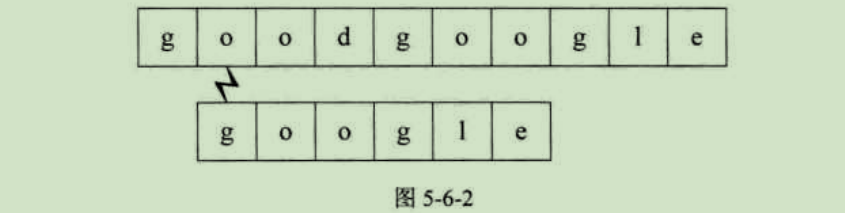
主串S第三位开始,主串S首字母是o,要匹配的T首字母是g,匹配失败,如图5-6-3所示。
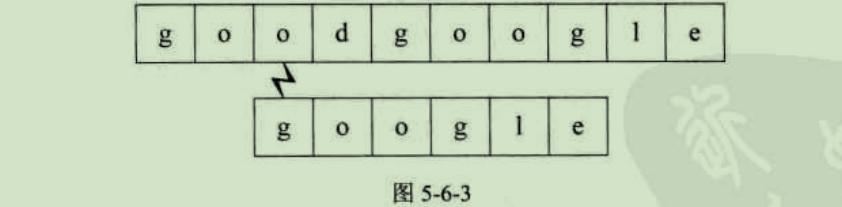
主串S第四位开始,主串S首字母是d,要匹配的T首字母是g,匹配失败,如图5-6-4所示。
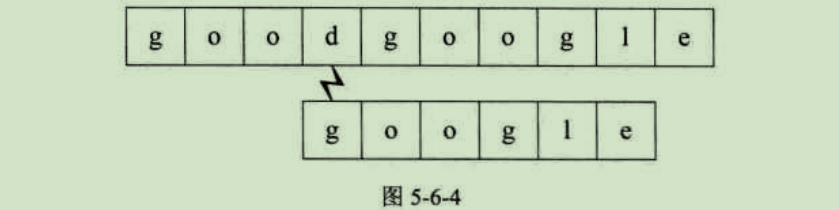
主串S第五位开始,S与T,6个字母全匹配,匹配成功,如图5-6-5所示。
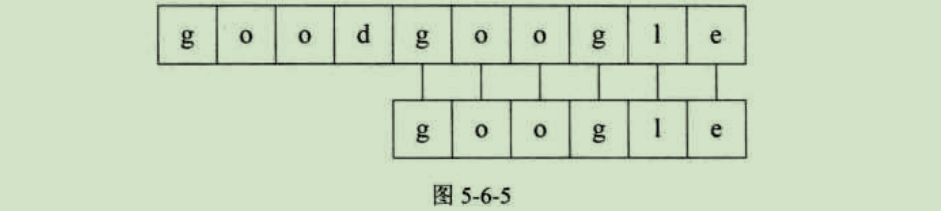
简单的说,就是对主串的每一个字符作为子串开头,与要匹配的字符串进行匹配。对主串做大循环,每个字符开头做T的长度的小循环,直到匹配成功或全部遍历完成为止。
前面我们已经用串的其他操作实现了模式匹配的算法Index。现在考虑不用串的其他操作,而是只用基本的数组来实现同样的算法。注意我们假设主串S和要匹配的子串T的长度存在S[0]与T[0]中。实现代码如下: 

分析一下,最好的情况是什么?那就是一开始就匹配成功,比如"googlegood"中去找"google",时间复杂度为O(1)。稍差一些,如果像刚才例子中第二、三、四位一样,每次都是首字符就不匹配,那么对T串的循环就不必进行了,比如"abcdefgoogle"中去找"google"。那么时间复杂度为O(n+m),其中n为主串长度,m为要匹配的子串长度。根据等概率原则,平均是(n+m)/2次查找,时间复杂度为O(n+m)。
那么最坏的情况又是什么?就是每次不成功的匹配都发生在串T的最后一个字符。举一个很极端的例子。主串为S="000000000000000000000000000000001",而要匹配的子串为T="0000000001",前者是有49个"0"和1个"1"的主串,后者是9个"0"和1个"1"的子串。在匹配时,每次都得将T中字符循环到最后一位才发现:哦,原来它们是不匹配的。这样等于T串需要在S串的前40个位置都需要判断10次,并得出不匹配的结论,如图5-6-6所示。 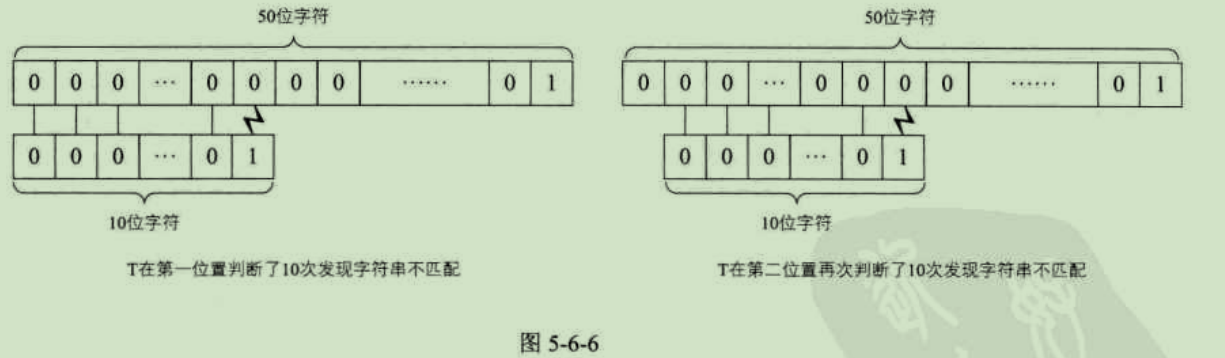
直到最后第41个位置,因为全部匹配相等,所以不需要再继续进行下去,如图5-6-7所示。如果最终没有可匹配的子串,比如是T="0000000002",到了第41位置判断不匹配后同样不需要继续比对下去。因此最坏情况的时间复杂度为O((n-m+1)*m)。 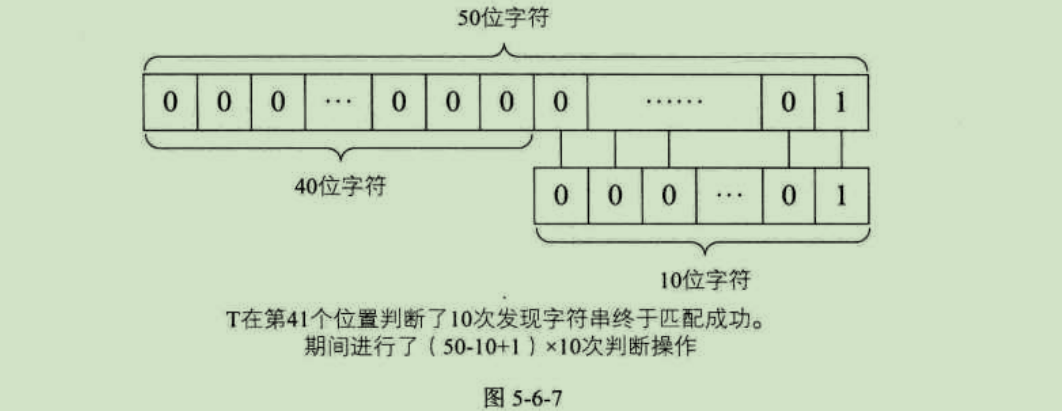
不要以为我这只是危言耸听,在实际运用中,对于计算机来说,处理的都是二进位的0和1的串,一个字符的ASCII吗也可以看成是8位的二进位01串,当然,汉字等所有的字符也都可以看成是多个0和1串。再比如像计算机图形也可以理解为是由许许多多个0和1的串组成。所以在计算机的运算当中,模式匹配操作可说是随处可见,而刚才的这个算法,就显得太低效了。
5.7 KMP模式匹配算法
你们可以忍受朴素模式匹配算法的低效吗?也许不可以、也许无所谓。但在很多年前我们的科学家们,觉得像这种有多个0和1重复字符的字符串,却需要挨个遍历的算法是非常糟糕的事情。于是有三位前辈,D.E.Knuth、J.H.Morris和V.R.Pratt(其中Knuth和Pratt共同研究,Morris独立研究)发表一个模式匹配算法,可以大大避免重复遍历的情况,我们把它称之为克努特-莫里斯-普拉特算法,简称KMP算法。
5.7.1 KMP模式匹配算法原理
为了能讲清楚KMP算法,我们不直接讲代码,那样很容易造成理解困难,还是从这个算法的研究角度来理解为什么它比朴素算法要好。
如果主串S="abcdefgab",其实还可以更长一些,我们就省略掉只保留前9位,我们要匹配的T="abcdex",那么如果用前面的朴素算法的话,前5个字母,两个串完全相等,直到第6个字母,"f"与"x"不等,如图5-7-1的(1)所示。 
接下来,按照朴素模式匹配算法,应该是如图5-7-1的流程(2)(3)(4)(5)(6)。即主串中当i=2,3,4,5,6时,首字符与子串T的首字符均不等。
似乎这也是理所当然,原来的算法就是这样设计的。可仔细观察发现。对于要匹配的子串T来说,"abcdex"首字母"a"与后面的串"bcdex"中任意一个字符都不相等。也就是说,既然"a"不与自己后面的子串中任何一字符相等,那么对于图5-7-1的(1)来说,前五位字符分别相等,意味着子串T的首字符"a"不可能与S串的第2位到第5位的字符相等。在图5-7-1中,(2)(3)(4)(5)的判断都是多余。
注意这里是理解KMP算法的关键。如果我们知道T串中首字符"a"与T中后面的字符均不相等(注意这是前提,如何判断后面再讲)。而T串的第二位的"b"与S串中第二位的"b"在图5-7-1的(1)中已经判断是相等的,那么也就意味着,T串中首字符"a"与S串中的第二位"b"是不需要判断也知道它们是不可能相等了,这样图5-7-1的(2)这一步判断是可以省略的,如图5-7-2所示。 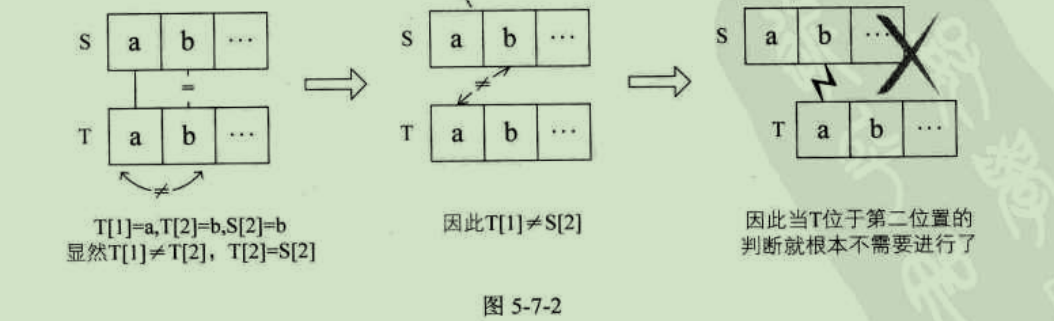
同样道理,在我们知道T串中首字符"a"与T中后面的字符均不相等的前提下,T串的"a"与S串后面的字符均不相等的前提下,T串的"a"与S串后面的"c","d","e"也都可以在(1)之后就可以确定是不相等的,所以这个算法当中(2)(3)(4)(5)没有必要,只保留(1)(6)即可,如图5-7-3所示。

之所以保留(6)中的判断是因为在(1)中T[6]!=S[6],尽管我们已经知道T[1]!=T[6],但也不能断定T[1]一定不等于S[6],因此需要保留(6)这一步。
有人就会问,如果T串后面也含有首字符"a"的字符怎么办呢?
我们来看下面一个例子,假设S="abcabcabc",T="abcabx"。对于开始的判断,前5个字符完全相等,第6个字符不等,如图5-7-4的(1)。此时,根据刚才的经验,T的首字符"a"与T的第二位字符"b",第三位字符"c"均不等,所以不需要做判断,图5-7-4的朴素算法步骤(2)(3)都是多余。 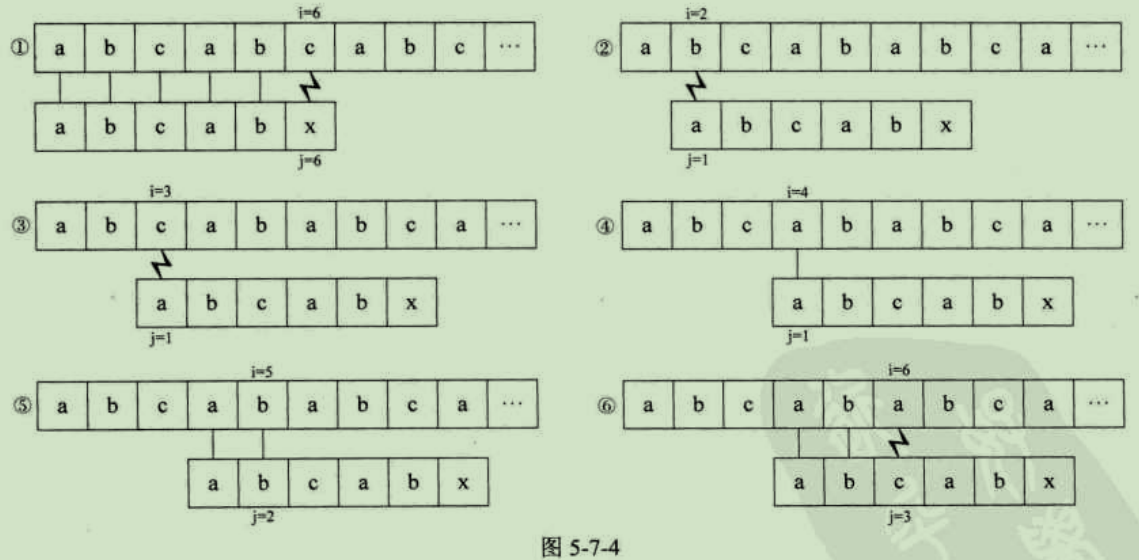
因为T的首位"a"与T第四位的"a"相等,第二位的"b"与第五位的"b"相等。而在(1)时。第四位的"a"与第五位的"b"已经与主串S中的相应位置比较过了,是相等的,因此可以断定,T的首字符"a"、第二位的字符"b"与S的第四位字符和第五位字符也不需要比较了,肯定也是相等的--之前比较过了,还判断什么,所以(4)(5)这两个比较得出字符相等的步骤也可以省略。
也就是说,对于在子串中有与首字符相等的字符,也是可以省略一部分不必要的判断步骤。如图5-7-5所示,省略掉右图的T串前两位"a"与"b"同S串中的4、5位置字符匹配操作。 
对比这两个例子,我们会发现在(1)时,我们的i值,也就是主串当前位置的下标是6,(2)(3)(4)(5),i值是2,3,4,5,到了(6),i值才又回到了6。即我们在朴素的模式匹配算法中,主串的i值是不断地回溯来完成的。而我们的分析发现,这种回溯其实是可以不需要的--正所谓好马不吃回头草,我们的KMP模式匹配算法就是为了让这没必要的回溯不发生。
既然i值不回溯,也就是不可以变小,那么要考虑的变化就是j值了。通过观察也可发现,我们屡屡提到了T串的首字符与自身后面字符的比较,发现如果有相等字符,j值的变化就会不相同。也就是说,这个j值的变化与主串其实没什么关系,关键就取决于T串的结构中是否有重复的问题。
比如图5-7-3中,由于T="abcdex",当中没有任何重复的字符,所以j就由6变成了1.而图5-7-4中,由于T="abcabx",前缀的"ab"与最后"x"之前串的后缀"ab"是相等的。因此j就由6变成了3.因此,我们可以得出规律,j值的多少取决于当前字符之间的串的前后缀的相似度。
我们把T串各个位置的j值的变化定义为一个数组next,那么next的长度就是T串的长度。于是我们可以得到下面的函数定义: 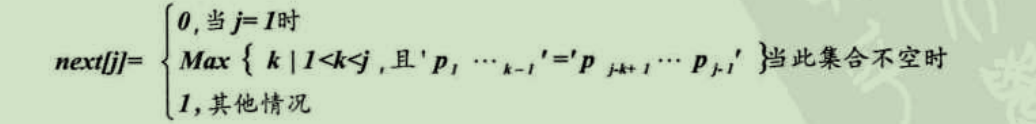
5.7.2 next数组推导
具体如何推导出一个串的next数组值呢,我们来看一些例子。
- T="abcdex"(如表5-7-1所示)

- 1)当j=1时,next[1]=0;
- 2)当j=2时,j由1到j-1就只有字符"a",属于其他情况next[2]=1;
- 3)当j=3时,j由1到j-1串是"ab",显然"a"与"b"不相等,属其他情况,next[3]=1;
- 4)以后同理,所以最终此T串的next[j]为011111。
- T="abcabx"(如图5-7-2所示)

- 1)当j=1时,next[1]=0;
- 2)当j=2时,同上例说明,next[2]=1;
- 3)当j=3时,同上,next[3]=1;
- 4)当j=4时,同上,next[4]=1;
- 5)当j=5时,此时j由1到j-1的串是"abca",前缀字符"a"与后缀字符"a"相等,因此可推算出k值为2(由'p1...p(k-1)'='p(j-k+1)...p(j-1)',得到p1=p4),因此next[5]=2;
- 6)当j=6时,j由1到j-1的串是"abcab",由于前缀字符"ab"与后缀"ab"相等,所以next[6]=3。
我们可以根据经验得到如果前后缀一个字符相等,k值是2,两个字符k值是3,n个字符相等k值就是n+1。
- T="ababaaaba"(如表5-7-3所示)

- 1)当j=1时,next[1]=0;
- 2)当j=2时,同上next[2]=1;
- 3)当j=3时,同上next[3]=1;
- 4)当j=4时,j由1到j-1的串是"aba",前缀字符"a"与后缀字符"a"相等,next[4]=2;
- 5)当j=5时,j由1到j-1的串是"abab",由于前缀字符"ab"与后缀"ab"相等,所以next[5]=3;
- 6)当j=6时,j由1到j-1的串的"ababa",由于前缀字符"aba"与后缀"aba"相等,所以next[6]=4;
- 7)当j=7时,j由1到j-1的串是"ababaa",由于前缀字符"ab"与后缀"aa"并不相等,只有"a"相等,所以next[7]=2;
- 8)当j=8时,j由1到j-1的串是"ababaaa",只有"a"相等,所以next[8]=2;
- 9)当j=9时,j由1到j-1的串是"ababaaab",由于前缀字符"ab"与后缀"ab"相等,所以next[9]=3。
- T="aaaaaaaab"(如表5-7-4所示)

- 1)当j=1时,next[1]=0;
- 2)当j=2时,同上next[2]=1;
- 3)当j=3时,j由1到j-1的串是"aa",前缀字符"a"与后缀字符"a"相等,next[3]=2;
- 4)当j=4时,j由1到j-1的串是"aaa",由于前缀字符"aa"与后缀"aa"相等,所以next[4]=3;
- 5)......
- 6)当j=9时,j由1到j-1的串是"aaaaaaaa",由于前缀字符"aaaaaaa"与后缀"aaaaaaa"相等,所以next[9]=8。
5.7.3 KMP模式匹配算法实现
说了这么多,我们可以来看看代码了。 
这段代码的目的就是为了计算出当前要匹配的串T的next数组。 

加粗的为相对于朴素匹配算法增加的代码,改动不算大,关键就是去掉了i值回溯的部分。对于get_next函数来说,若T的长度为m,因只涉及到简单的单循环,其时间复杂度为O(m),而由于i值的不回溯,使得index_KMP算法效率得到了提高,while循环的时间复杂度为O(n)。因此,整个算法的时间复杂度为O(n+m)。相较于朴素模式匹配算法的O((n-m+1)*m)来说,是要好一些。
这里也需要强调,KMP算法仅当模式与主串之间存在许多"部分匹配"的情况下才体现出它的优势,否则两者差异并不明显。
5.7.4 KMP模式匹配算法改进
后来有人发现,KMP还是有缺陷的。比如,如果我们的主串S="aaaabcde",子串T="aaaaax",其next数组值分别为012345,在开始时,当i=5、j=5时,我们发现"b"与"a"不相等,如图5-7-6的(1),因此j=next[5]=4,如图中的(2),此时"b"与第4位置的"a"依然不等,j=next[4]=3,如图中的(3),后依次是(4)(5),直到j=next[1]=0时,根据算法,此时i++,j++,得到i=6,j=1,如图中的(6)。
我们发现,当中的(2)(3)(4)(5)步骤,其实是多余的判断。由于T串的第二、三、四、五位置的字符都与首位的"a"相等,那么可以用首位next[1]的值去取代与它相等的字符后续next[j]的值,这是个很好的办法。因此我们对求next函数进行了改良。
假设取代的数组为nextval,增加了加粗部分,代码如下: 

实际匹配算法,只需要将"get_next(T,next)";改为"get_nextval(T,next);"即可,这里不再重复。
5.7.5 nextval数组值推导
改良后,我们之前的例子nextval值就与next值不完全相同了。比如:
- T="ababaaaba"(如表5-7-5所示)

先算出next数组的值分别是001234223,然后再分别判断。
- 1)当j=1时。nextval[1]=0;
- 2)当j=2时,因第二位字符"b"的next值是1,而第一位就是"a",他们不相等,所以nextval[2]=next[2]=1,维持原值。
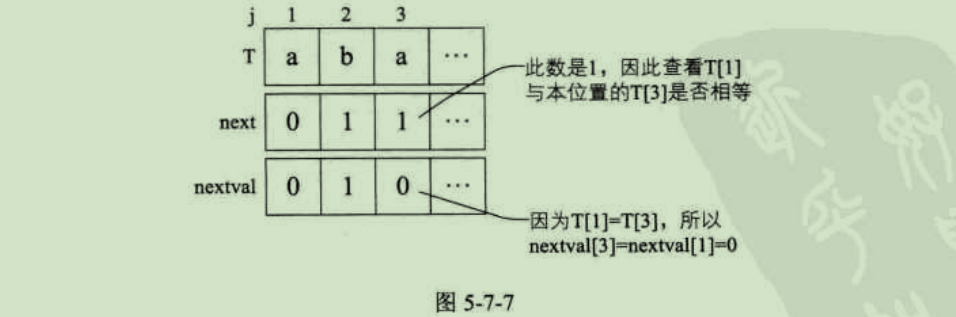
- 3)当j=3时,因为第三位字符"a"的next值为1,所以与第一位的"a"比较得知它们相等,所以nextval[3]=nextval[1]=0;如图5-7-7所示。
4)当j=4时,第四位的字符"b",next值为2,所以与第二位的"b"相比较得到结果是相等,因此nextval[4]=nextval[2]=1;如图5-7-8所示。 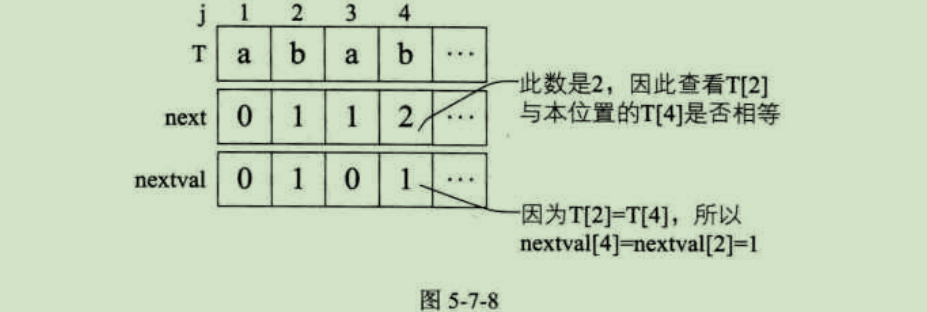
- 5)当j=5时,next值为3,第五个字符"a"与第三个字符"a"相等,因此nextval[5]=nextval[3]=0;
- 6)当j=6时,next值为4,第六个字符"a"与第四个字符"b"不相等,因此nextval[6]=4;
- 7)当j=7时,next值为2,第七个字符"a"与第二个字符"b"不相等,因此nextval[7]=2;
- 8)当j=8时,next值为2,第八个字符"b"与第二个字符"b"相等,因此nextval[8]=nextval[2]=1;
- 9)当j=9时,next值为3,第九个字符"a"与第三个字符"a"相等,因此nextval[9]=nextval[3]=1。
- T="aaaaaaaab"(如表5-7-6)

先算出next数组的值分别为012345678,然后再分别判断。
- 1)当j=1时,nextval[1]=0;
- 2)当j=2时,next值为1,第二个字符与第一个字符相等,所以nextval[2]=nextval[1]=0;
- 3)同样的道理,其后都为0....;
- 4)当j=9时,next值为8,第九个字符"b"与第八个字符"a"不相等,所以nextval[9]=9。
总结改进过的KMP算法,它是在计算出next值的同时,如果a位字符与它next值指向的b位字符相等,则该a位的nextval就指向b位的nextval值,如果不等,则该a位的nextval值就是它自己a位的next的值。
5.8 总结回顾
这一章节我们重点讲了"串"这样的数据结构,串(string)是由零个或多个字符组成的有限序列,又名字符串。本质上,它是一种线性表的扩展,但相对于线性表关注一个个元素来说,我们对串这种结构更多的是关注它子串的应用问题,如查找、替换等操作。现在的高级语言都有针对串的函数可以调用。我们在使用这些函数的时候,同时也应该要理解它当中的原理,以便于在碰到复杂的问题时,可以更加灵活的使用,比如KMP模式匹配算法的学习,就是更有效地去理解index函数当中的实现细节。多用心一点,说不定有一天,可以有以你的名字命令的算法流传于后世。
转载于:https://my.oschina.net/u/2484728/blog/1830740
大话数据结构读书笔记系列(五)串相关推荐
- 大话数据结构读书笔记系列(七)图
2019独角兽企业重金招聘Python工程师标准>>> 7.1 开场白 旅游几乎是每个年轻人的爱好,但没有钱或没时间也是困惑年轻人不能圆梦的直接原因.如果可以用最少的资金和最少的时间 ...
- 大话数据结构读书笔记系列(三)线性表
2019独角兽企业重金招聘Python工程师标准>>> 3.1 开场白 各位同学,大家好.今天我们要开始学习数据结构中最常用和最简单的一种结构,在介绍它之前先讲个例子. 我经常下午去 ...
- 大话数据结构读书笔记艾提拉总结 查找算法 和排序算法比较好 第1章数据结构绪论 1 第2章算法 17 第3章线性表 41 第4章栈与队列 87 第5章串 123 第6章树 149 第7章图 21
大话数据结构读书笔记艾提拉总结 查找算法 和排序算法比较好 第1章数据结构绪论 1 第2章算法 17 第3章线性表 41 第4章栈与队列 87 第5章串 123 第6章树 149 第7章图 211 第 ...
- 《ASP.NET Core In Action》读书笔记系列五 ASP.NET Core 解决方案结构解析1
<ASP.NET Core In Action>读书笔记系列五 ASP.NET Core 解决方案结构解析1 参考文章: (1)<ASP.NET Core In Action> ...
- [大话数据结构-读书笔记] 栈
栈 1 栈的定义 1.1 栈的定义 在我们软件应用中,栈这种后进先出数据结构的应用是非常普遍的.比如Word. Photoshop 等文档或图像编辑软件中, 都有撤销 (undo)的操作,也是用栈这种 ...
- C#刨根究底:《你必须知道的.NET》读书笔记系列
一.此书到底何方神圣? <你必须知道的.NET>来自于微软MVP-王涛(网名:AnyTao,博客园大牛之一,其博客地址为:http://anytao.cnblogs.com/)的最新技术心 ...
- 读书笔记系列1——MySQL必知必会
读书笔记系列1--MySQL必知必会 文章目录 读书笔记系列1--MySQL必知必会 MySQL官方文档:https://dev.mysql.com/doc/ 第一章 数据库基础 *2021.11.2 ...
- 数据结构学习笔记(五):重识字符串(String)
目录 1 字符串与数组的关系 1.1 字符串与数组的联系 1.2 字符串与数组的区别 2 实现字符串的链式存储(Java) 3 子串查找的简单实现 1 字符串与数组的关系 1.1 字符串与数组的联系 ...
- 密码学读书笔记系列(三):《商用密码应用与安全性评估》
密码学读书笔记系列(三):<商用密码应用与安全性评估> 思考/前言 第1章 密码基础知识 1.1 密码应用概述 1.2 密码应用安全性评估(密评)的基本原理 1.3 密码技术发展 1.4 ...
最新文章
- 【Pyhon 3】: 170104:优品课堂: GUI -tkinter
- jQuery中的.bind()、.live()和.delegate()之间区别分析
- C#判断奇偶数的函数
- souce insight中文出现乱码
- 004-cpu的区分
- vue3+typescript引入外部文件
- 自旋锁/互斥锁/读写锁/递归锁的区别与联系
- AntDesignUI - V3.0 技术手册(资源篇)
- php代码并发控制,php并发控制
- 小学在班里排第几名家长才比较放心?
- 多个安卓设备投屏到电脑_无线投屏器投屏不需要网络
- 张宇真题全解(纯题目)
- php发送邮件pop3,php 发送邮件与pop3邮件登录代码
- ae 的动画导出为html,Bodymovin v5.5.3 – AE导出Web动画插件+使用教程
- word2016版本解决脚注分栏情况
- 《加州消费者隐私法案》(CCPA)解读一:美国最严隐私法CCPA适用范围有哪些?
- Web 3D集成开发环境【nunuStudio中文版】
- openfeign接口启动报错: is not assignable to interface feign.hystrix.FallbackFactory
- js 为label标签和div标签赋值
- 知乎上对 国内机器视觉行业的发展的 讨论-经典