时间序列的自回归模型—从线性代数的角度来看
时间序列的自回归模型—从线性代数的角度来看
Fibonacci 序列
在开始讲解时间序列的自回归模型(AutoRegression Model)之前,我们需要先介绍一下线性代数的基础知识。为了介绍线性代数的基础知识,我们可以先看一个简单的例子。考虑整数序列 Fibonacci 序列,它的通项公式是一个递归函数,每项的取值是由前两项所生成的,其具体的公式就是

其初始值是 
0,1,1,2,3,5,8,13,21,34,55,89,144,…
但是,计算 Fibonacci 的通项公式则比计算等差数列和等比数列的通项公式复杂的多,因为这里需要使用线性代数的技巧才能解决这个问题。
求解 Fibonacci 序列的通项公式 --- 矩阵对角化
根据 Fibonacci 数列的递归公式,基于矩阵乘法的定义,Fibonacci 序列可以写成如下形式:


这就意味着我们需要计算出矩阵 A 的幂。在线性代数里面,为了计算矩阵的 n 次方,除了通过矩阵乘法的公式直接计算之外,还有一个经典的技巧,那就是将矩阵对角化。详细来说,如果 



其中 





另外,如果想知道一个矩阵 A 的特征值和特征向量,则需要计算以下多项式的根,i.e. 计算关于 

其中 I 是一个单位矩阵(identity matrix)。
按照以上的思路,如果令

可以计算出 A 的两个特征值分别是 


因此直接计算可以得到

通过上面的计算方法,为了计算 Fibonacci 数列的通项公式,我们可以先把它转换成一个矩阵求幂的问题,于是我们就能矩阵对角化的方法把 Fibonacci 数列的通项公式求出来。
时间序列的弱平稳性
要讲解自回归模型,就必须提到时间序列的弱平稳性。一个时间序列 
对于所有的
都是恒定的;
对于所有的
与
的协方差对于所有的
另外,时间序列的自相关方程(AutoCorrelation Function)指的是对于 

如果时间序列

时间序列的自回归模型(AutoRegression Model)
AR(1) 模型
AR(1) 模型指的是时间序列 



这个时间序列
,并且
满足 iid 条件。其中
表示 Gauss 正态分布,它的均值是0,方差是
。
是弱平稳的,i.e. 必须满足
。
如果选择初始条件 

从 AR(1) 以上的定义出发,我们可以得到:
.
.
.
Proof of 1. 从 AR(1) 的模型出发,可以得到

从而,
Proof of 2. 从 AR(1) 的模型出发,可以得到


从而,
Proof of 3. 令 


从而,

AR(1) 模型与一维动力系统
特别的,如果假设 


下面我们要计算 



Method 1.
通过 

令 

另外,如果 

Method 2.
将原函数转换成 Lipschitz 函数的形式,i.e. 如果



因为 


反之,如果


因此,在 
AR(p) 模型
按照之前类似的定义,可以把 AR(1) 模型扩充到 AR(p) 模型,也就是说:
1. AR(1) 模型形如:

2. AR(2) 模型形如:

3. AR(p) 模型形如:

AR(p) 模型的稳定性 --- 基于线性代数
对于 AR(2) 模型,可以假定 

写成矩阵的形式形如:

求解其特征多项式则是基于 




对于更加一般的 AR(p) 模型,也就是考虑 p 阶差分方程

可以用同样的方法将其转换成矩阵的形式,那就是:

计算

当每个特征值都在单位圆盘内部的时候,i.e. 

存在稳定性的解。
时间序列的搜索
在之前的时间序列相似度算法中,时间戳都是一一对应的,但是在实际的场景中,时间戳有可能出现一定的偏移,但是两条时间序列却又是十分相似的。例如正弦函数 


基于动态规划的相似度计算方法
DTW 的经典算法
基于动态规划的相似度计算的典型代表就是 DTW(Dynamical Time Warping )和 Frechet 距离。在这里将会主要介绍 DTW 算法。详细来说,DTW 算法是为了计算语音信号处理中,由于两个人说话的时长不一样,但是却是类似的一段话,欧几里德算法不完全能够解决这类问题。在这种情况下,DTW 算法就被发展出来。DTW 算法是为了计算两条时间序列的最佳匹配点,假设我们有两条时间序列 Q 和 C,长度都是 n,并且 









现在我们需要找到一条路径使得

这条路径就是动态规划的解,它满足一个动态规划方程:对于 


其初始状态是 



- 如果
时,则
表示最后的距离;
- 如果
时,则
- 如果
时,则
表示最后的距离。
Remark.
DTW 算法不满足三角不等式。例如:

DTW 的加速算法
某些时候,我们可以添加一个窗口长度的限制,换言之,如果要比较 


初始条件和之前一样。

这里的 


相似时间序列的搜索
相似的时间序列的搜索问题一般是这样的:
Question 1. 给定一条时间序列 


Question 2. 给定一条时间序列 
DTW 算法的下界 LB_Kim
对于两条时间序列 Q 和 C 而言,可以分别提取它们的四个特征,那就是最大值,最小值,第一个元素的值,最后一个元素的值。这样可以计算出 LB_Kim


可以证明 
DTW 算法的下界 LB_Yi
有学者在 LB_Kim 的基础上提出了一种下界的计算方法,那就是 LB_Yi,有兴趣的读者可以参见:efficient retrieval of similar time sequences under time warping, 1998.
DTW 算法的下界 LB_Keogh
但是,如果是基于 DTW 的距离计算方法,每次都要计算两条时间序列的 DTW 距离,时间复杂度是
(1)首先定义时间序列 Q 的上下界。i.e. 


(2)定义公式:


其中,LBKeogh 满足性质:
对于任意两条长度为 n 的时间序列 Q 和 C,对于任意的窗口 

所以,可以把搜索的算法进行加速:
Lower Bounding Sequential Scan(Q)best_so_far = infinity for all sequences in databaseLB_dist = lower_bound_distance(C_{i},Q)if LB_dist < best_so_fartrue_dist = DTW(C_{i},Q)if true_dist < best_so_farbest_so_far = true_distindex_of_best_match = iendifendifendfor
在论文 Exact Indexing of Dynamic Time Warping 里面,作者还尝试将 Piecewise Constant Approximation 与 LB_Keogh 结合起来,提出了 LB_PAA 的下界。它满足条件 
总结
本文初步介绍了 DTW 算法以及它的下界算法,包括 LB_Kim, LB_Keogh 等,以及时间序列数据库的搜索算法。
如何理解时间序列?— 从RIEMANN积分和LEBESGUE积分谈起
Riemann 积分和 Lebesgue 积分是数学中两个非常重要的概念。本文将会从 Riemann 积分和 Lebesgue 积分的定义出发,介绍它们各自的性质和联系。
积分
Riemann 积分
Riemann 积分虽然被称为 Riemann 积分,但是在 Riemann 之前就有学者对这类积分进行了详细的研究。早在阿基米德时代,阿基米德为了计算曲线 
下面来看一下 Riemann 积分的详细定义。

考虑定义在闭区间 [a,b] 上的函数
取一个有限的点列 





当我们说该函数 

对于任意 



通常来说,用符号来表示就是:
用几幅图来描述 Riemann 积分的思想就是:



Lebesgue 积分
Riemann 积分是为了计算曲线与 X 轴所围成的面积,而 Lebesgue 积分也是做同样的事情,但是计算面积的方法略有不同。要想直观的解释两种积分的原理,可以参见下图:
 Riemann 积分(上)与 Lebesgue 积分(下)
Riemann 积分(上)与 Lebesgue 积分(下)
Riemann 积分是把一条曲线的底部分成等长的区间,测量每一个区间上的曲线高度,所以总面积就是这些区间与高度所围成的面积和。
Lebesgue 积分是把曲线化成等高线图,每两根相邻等高线的差值是一样的。每根等高线之内含有它所圈着的长度,因此总面积就是这些等高线内的面积之和。
用再形象一点的语言来描述就是:吃一块汉堡有多种方式
- Riemann 积分:从一个角落开始一口一口吃,每口都包含所有的配料;
- Lebesgue 积分:从最上层开始吃,按照“面包-配菜-肉-蛋-面包”的节奏,一层一层来吃。
再看一幅图的表示就是:Riemann 积分是按照蓝色的数字顺序相加的,Lebesgue 积分是按照红色的数字来顺序相加的。

基于这些基本的思想,就可以给出 Lebesgue 积分的定义:
简单函数指的是对指示函数的有限线性组合,i.e. 

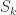


如果 

这里的 
而对于可测函数时,可以把可测函数 



Riemann 积分与Lebesgue 积分的关系
定义了两种积分之后,也许有人会问它们之间是否存在矛盾?其实,它们之间是不矛盾的,因为有学者证明了这样的定理:
如果有界函数

左侧是表示 Riemann 积分,右侧表示 Lebesgue 积分。
用形象化一点的语言描述就是:无论从角落一口一口地吃汉堡,还是从顶至下一层一层吃,所吃的汉堡都是同一个。
但是 Lebesgue 积分比 Riemann 积分有着更大的优势,例如 Dirichlet 函数,
- 当
是有理数时,
;
- 当
.
Dirichlet 函数是定义在实数轴的函数,并且值域是 
时间序列
提到时间序列,也就是把以上所讨论的连续函数换成离散函数而已,把定义域从一个闭区间 
时间序列的表示 — 基于 Riemann 积分
现在我们可以按照 Riemann 积分的计算方法来表示一个时间序列的特征,于是就有学者把时间序列按照横轴切分成很多段,每一段使用某个简单函数(线性函数等)来表示,于是就有了以下的方法:
- 分段线性逼近(Piecewise Linear Approximation)
- 分段聚合逼近(Piecewise Aggregate Approximation)
- 分段常数逼近(Piecewise Constant Approximation)
说到这几种算法,其实最本质的思想就是进行数据降维的工作,用少数的数据来进行原始时间序列的表示(Representation)。用数学化的语言来描述时间序列的数据降维(Data Reduction)就是:把原始的时间序列 


分段聚合逼近(Piecewise Aggregate Approximation)— 类似 Riemann 积分
在这种算法中,分段聚合逼近(Piecewise Aggregate Approximation)是一种非常经典的算法。假设原始的时间序列是 

其中

在这里 

至于分段线性逼近(Piecewise Linear Approximation)和分段常数逼近(Piecewise Constant Approximation),只需要在 
符号特征(Symbolic Approximation)— 类似用简单函数来计算 Lebesgue 积分
在推荐系统的特征工程里面,特征通常来说可以做归一化,二值化,离散化等操作。例如,用户的年龄特征,一般不会直接使用具体的年月日,而是划分为某个区间段,例如 0~6(婴幼儿时期),7~12(小学),13~17(中学),18~22(大学)等阶段。
其实在得到分段特征之后,分段特征在某种程度上来说依旧是某些连续值,能否把连续值划分为一些离散的值呢?于是就有学者使用一些符号来表示时间序列的关键特征,也就是所谓的符号表示法(Symbolic Representation)。下面来介绍经典的 SAX Representation。
如果我们希望使用 



SAX 方法的流程如下:
- 正规化(normalization):把原始的时间序列映射到一个新的时间序列,新的时间序列满足均值为零,方差为一的条件。
- 分段表示(PAA):
。
- 符号表示(SAX):如果
,那么
;如果
,那么
,在这里
;如果
,那么
。
于是,我们就可以用

时间序列的表示 — 基于 Lebesgue 积分
要想考虑一个时间序列的值分布情况,其实就类似于 Lebesgue 积分的计算方法,考虑它们的分布情况,然后使用某些函数去逼近时间序列。要考虑时间序列的值分布情况,可以考虑熵的概念。
熵(Entropy)
通常来说,要想描述一种确定性与不确定性,熵(entropy)是一种不错的指标。对于离散空间而言,一个系统的熵(entropy)可以这样来表示:

如果一个系统的熵(entropy)越大,说明这个系统就越混乱;如果一个系统的熵越小,那么说明这个系统就更加确定。
提到时间序列的熵特征,一般来说有几个经典的熵指标,其中有一个就是 binned entropy。
分桶熵(Binned Entropy)
从熵的定义出发,可以考虑把时间序列的值进行分桶的操作,例如,可以把 [min, max] 这个区间等分为十个小区间,那么时间序列的取值就会分散在这十个桶中。根据这个等距分桶的情况,就可以计算出这个概率分布的熵(entropy)。i.e. Binned Entropy 就可以定义为:

其中 
如果一个时间序列的 Binned Entropy 较大,说明这一段时间序列的取值是较为均匀的分布在 [min, max] 之间的;如果一个时间序列的 Binned Entropy 较小,说明这一段时间序列的取值是集中在某一段上的。
总结
在本篇文章中,笔者从 Riemann 积分和 Lebesgue 积分出发,介绍了它们的基本概念,性质和联系。然后从两种积分出发,探讨了时间序列的分段特征,时间序列的熵特征。在未来的 Blog 中,笔者将会介绍时间序列的更多相关内容。
时间序列的相似性
在文本挖掘中,可以通过 Word2Vec 生成的向量以及向量的内积,或者根据语义和词性来判断两个词语是否是近义词。在时间序列的挖掘中,同样可以找到一些方法来描述两条时间序列是否相似。
在介绍时间序列的距离之前,笔者感觉需要回顾一下数学中度量空间和内积空间的定义。
度量空间
在数学里面,集合 



,并且
当且仅当
;
,也就是满足对称性;
,也就是三角不等式。
满足这三个条件的距离函数称为度量,具有某种度量的集合则叫做度量空间。
Remark.
在本文下面的时间序列距离的各种定义中,这些距离不一定满足三角不等式。例如动态时间算法(DTW)就不满足三角不等式。
内积空间
一个内积空间是域 




1. 对于任意的 

2. 共轭双线性形式指的是:




3. 非负性:

4. 非退化:从 

基于欧几里德距离的相似度计算
假设两条时间序列曲线为 





基于相关性的相似度计算方法
Pearson 系数(Pearson Coefficient)

其中,


Pearson 系数的性质如下:
- 如果两条时间序列
,则
表是它们是完全一致的,如果两条时间序列
,则
表示它们之间是负相关的。
.
可以基于 Pearson 系数来制定两条时间序列之间的距离:


其中
The First Order Temporal Correlation Coefficient
这个相关性系数与 Pearson 系数类似,但是略有不同,其定义为:


表示两条时间序列持有类似的趋势, 它们会同时上涨或者下跌,并且涨幅或者跌幅也是类似的。
表示两条时间序列的上涨和下跌趋势恰好相反。
表示两条时间序列在单调性方面没有相关性。

基于 CORT,同样可以定义时间序列的距离,用公式描述如下:

其中,


是一个递减函数。
基于自相关系数的距离(Autocorrelation-based distance)
假设时间序列是 

其中 



于是,通过给定一个正整数 


对于 



其中的 

(1)

(2)


除了自相关系数(Autocorrelation Coefficients)之外,也可以考虑偏自相关系数(Partial Autocorrelation Coefficients),使用 PACFs 来取代 ACFs。这样,使用同样的定义方式就可以得到 

基于周期性的相似度计算方法
这里会介绍基于周期图表(Periodogram-based)的距离计算方法。其大体思想就是通过 Fourier 变换得到一组参数,然后通过这组参数来反映原始的两个时间序列时间的距离。用数学公式来描述就是:


其中 



(1)用原始的特征来表示距离:

(2)用正则化之后的特征来描述就是:

其中 




(3)用取对数之后的特征表示:

基于模型的相似度计算
Piccolo 距离
基于模型的相似度判断本质上是用一个模型和相应的一组参数去拟合某条时间序列,然后得到最优的一组参数,计算两个时间序列所得到的最优参数的欧几里德距离即可。




分别表示 




其中 








Maharaj 距离
按照之前的描述,可以增加一个矩阵来修改 Piccolo 距离:

其中 







基于 Cepstral 的距离
考虑时间序列 








所以,LPC 的距离定义是:

总结
在本文中,介绍了时间序列之间距离的计算方法,包括基于 
时间序列的表示与信息提取
提到时间序列,大家能够想到的就是一串按时间排序的数据,但是在这串数字背后有着它特殊的含义,那么如何进行时间序列的表示(Representation),如何进行时间序列的信息提取(Information Extraction)就成为了时间序列研究的关键问题。
就笔者的个人经验而言,其实时间序列的一些想法和文本挖掘是非常类似的。通常来说句子都是由各种各样的词语组成的,并且一般情况下都是“主谓宾”的句子结构。于是就有人希望把词语用一个数学上的向量描述出来,那么最经典的做法就是使用 one – hot 的编码格式。i.e. 也就是对字典里面的每一个词语进行编码,一个词语对应着一个唯一的数字,例如 0,1,2 这种形式。one hot 的编码格式是这行向量的长度是词典中词语的个数,只有一个值是1,其余的取值是0,也就是 (0,…,0,1,0,…,0) 这种样子。但是在一般情况下,词语的个数都是非常多的,如何使用一个维度较小的向量来表示一个词语就成为了一个关键的问题。几年前,GOOGLE 公司开源了 Word2vec 开源框架,把每一个词语用一串向量来进行描述,向量的长度可以自行调整,大约是100~1000 不等,就把原始的 one-hot 编码转换为了一个低维空间的向量。在这种情况下,机器学习的很多经典算法,包括分类,回归,聚类等都可以在文本上得到巨大的使用。Word2vec 是采用神经网络的思想来提取每个词语与周边词语的关系,从而把每个词语用一个低维向量来表示。在这里,时间序列的特征提取方法与 word2vec 略有不同,后面会一一展示这些技巧。
时间序列的统计特征
提到时间序列的统计特征,一般都能够想到最大值(max),最小值(min),均值(mean),中位数(median),方差(variance),标准差(standard variance)等指标,不过一般的统计书上还会介绍两个指标,那就是偏度(skewness)和峰度(kuriosis)。如果使用时间序列 




其中 
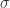
时间序列的熵特征
为什么要研究时间序列的熵呢?请看下面两个时间序列:
时间序列(1):(1,2,1,2,1,2,1,2,1,2,…)
时间序列(2):(1,1,2,1,2,2,2,2,1,1,…)
在时间序列(1)中,1 和 2 是交替出现的,而在时间序列(2)中,1 和 2 是随机出现的。在这种情况下,时间序列(1)则更加确定,时间序列(2)则更加随机。并且在这种情况下,两个时间序列的统计特征,例如均值,方差,中位数等等则是几乎一致的,说明用之前的统计特征并不足以精准的区分这两种时间序列。
通常来说,要想描述一种确定性与不确定性,熵(entropy)是一种不错的指标。对于离散空间而言,一个系统的熵(entropy)可以这样来表示:

如果一个系统的熵(entropy)越大,说明这个系统就越混乱;如果一个系统的熵越小,那么说明这个系统就更加确定。
提到时间序列的熵特征,一般来说有几个经典的例子,那就是 binned entropy,approximate entropy,sample entropy。下面来一一介绍时间序列中这几个经典的熵。
Binned Entropy
从熵的定义出发,可以考虑把时间序列 
其中 


如果一个时间序列的 Binned Entropy 较大,说明这一段时间序列的取值是较为均匀的分布在
Approximate Entropy
回到本节的问题,如何判断一个时间序列是否具备某种趋势还是随机出现呢?这就需要介绍 Approximate Entropy 的概念了,Approximate Entropy 的思想就是把一维空间的时间序列提升到高维空间中,通过高维空间的向量之间的距离或者相似度的判断,来推导出一维空间的时间序列是否存在某种趋势或者确定性。那么,我们现在可以假设时间序列 



Step 1. 固定两个参数,正整数



Step 2. 通过新的向量 


在这里,距离 
Step 3. 考虑函数

Step 4. Approximate Entropy 可以定义为:

Remark.
- 正整数
会基于具体的时间序列具体调整;
- 如果某条时间序列具有很多重复的片段(repetitive pattern)或者自相似性(self-similarity pattern),那么它的 Approximate Entropy 就会相对小;反之,如果某条时间序列几乎是随机出现的,那么它的 Approximate Entropy 就会相对较大。
Sample Entropy
除了 Approximate Entropy,还有另外一个熵的指标可以衡量时间序列,那就是 Sample Entropy,通过自然对数的计算来表示时间序列是否具备某种自相似性。
按照以上 Approximate Entropy 的定义,可以基于 



其中,



Remark.
- Sample Entropy 总是非负数;
- Sample Entropy 越小表示该时间序列具有越强的自相似性(self similarity)。
- 通常来说,在 Sample Entropy 的参数选择中,可以选择
.
时间序列的分段特征
即使时间序列有一定的自相似性(self-similarity),能否说明这两条时间序列就完全相似呢?其实答案是否定的,例如:两个长度都是 1000 的时间序列,
时间序列(1): [1,2] * 500
时间序列(2): [1,2,3,4,5,6,7,8,9,10] * 100
其中,时间序列(1)是 1 和 2 循环的,时间序列(2)是 1~10 这样循环的,它们从图像上看完全是不一样的曲线,并且它们的 Approximate Entropy 和 Sample Entropy 都是非常小的。那么问题来了,有没有办法提炼出信息,从而表示它们的不同点呢?答案是肯定的。
首先,我们可以回顾一下 Riemann 积分和 Lebesgue 积分的定义和不同之处。按照下面两幅图所示,Riemann 积分是为了算曲线下面所围成的面积,因此把横轴划分成一个又一个的小区间,按照长方形累加的算法来计算面积。而 Lebesgue 积分的算法恰好相反,它是把纵轴切分成一个又一个的小区间,然后也是按照长方形累加的算法来计算面积。
之前的 Binned Entropy 方案是根据值域来进行切分的,好比 Lebesgue 积分的计算方法。现在我们可以按照 Riemann 积分的计算方法来表示一个时间序列的特征,于是就有学者把时间序列按照横轴切分成很多段,每一段使用某个简单函数(线性函数等)来表示,于是就有了以下的方法:
- 分段线性逼近(Piecewise Linear Approximation)
- 分段聚合逼近(Piecewise Aggregate Approximation)
- 分段常数逼近(Piecewise Constant Approximation)
说到这几种算法,其实最本质的思想就是进行数据降维的工作,用少数的数据来进行原始时间序列的表示(Representation)。用数学化的语言来描述时间序列的数据降维(Data Reduction)就是:把原始的时间序列
分段聚合逼近(Piecewise Aggregate Approximation)— 类似 Riemann 积分
在这种算法中,分段聚合逼近(Piecewise Aggregate Approximation)是一种非常经典的算法。假设原始的时间序列是
其中
在这里
至于分段线性逼近(Piecewise Linear Approximation)和分段常数逼近(Piecewise Constant Approximation),只需要在
符号逼近(Symbolic Approximation)— 类似 Riemann 积分
在推荐系统的特征工程里面,特征通常来说可以做归一化,二值化,离散化等操作。例如,用户的年龄特征,一般不会直接使用具体的年月日,而是划分为某个区间段,例如 0~6(婴幼儿时期),7~12(小学),13~17(中学),18~22(大学)等阶段。
其实在得到分段特征之后,分段特征在某种程度上来说依旧是某些连续值,能否把连续值划分为一些离散的值呢?于是就有学者使用一些符号来表示时间序列的关键特征,也就是所谓的符号表示法(Symbolic Representation)。下面来介绍经典的 SAX Representation。
如果我们希望使用
SAX 方法的流程如下:
Step 1. 正规化(normalization):也就是该时间序列被映射到均值为零,方差为一的区间内。
Step 2. 分段表示(PAA):
Step 3. 符号表示(SAX):如果
于是,我们就可以用
、
总结
在本篇文章中,我们介绍了时间序列的一些表示方法(Representation),其中包括时间序列统计特征,时间序列的熵特征,时间序列的分段特征。在下一篇文章中,我们将会介绍时间序列的相似度计算方法。
HOW TO CONVERT A TIME SERIES TO A SUPERVISED LEARNING PROBLEM IN PYTHON
https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/
Machine learning methods like deep learning can be used for time series forecasting.
Before machine learning can be used, time series forecasting problems must be re-framed as supervised learning problems. From a sequence to pairs of input and output sequences.
In this tutorial, you will discover how to transform univariate and multivariate time series forecasting problems into supervised learning problems for use with machine learning algorithms.
After completing this tutorial, you will know:
- How to develop a function to transform a time series dataset into a supervised learning dataset.
- How to transform univariate time series data for machine learning.
- How to transform multivariate time series data for machine learning.
Let’s get started.

Time Series vs Supervised Learning
Before we get started, let’s take a moment to better understand the form of time series and supervised learning data.
A time series is a sequence of numbers that are ordered by a time index. This can be thought of as a list or column of ordered values.
For example:
|
1
2
3
4
5
6
7
8
9
10
|
0
1
2
3
4
5
6
7
8
9
|
A supervised learning problem is comprised of input patterns (X) and output patterns (y), such that an algorithm can learn how to predict the output patterns from the input patterns.
For example:
|
1
2
3
4
5
6
7
8
9
|
X, y
1 2
2, 3
3, 4
4, 5
5, 6
6, 7
7, 8
8, 9
|
For more on this topic, see the post:
- Time Series Forecasting as Supervised Learning
Pandas shift() Function
A key function to help transform time series data into a supervised learning problem is the Pandas shift() function.
Given a DataFrame, the shift() function can be used to create copies of columns that are pushed forward (rows of NaN values added to the front) or pulled back (rows of NaN values added to the end).
This is the behavior required to create columns of lag observations as well as columns of forecast observations for a time series dataset in a supervised learning format.
Let’s look at some examples of the shift function in action.
We can define a mock time series dataset as a sequence of 10 numbers, in this case a single column in a DataFrame as follows:
|
1
2
3
4
|
from pandas import DataFrame
df = DataFrame()
df[‘t’] = [x for x in range(10)]
print(df)
|
Running the example prints the time series data with the row indices for each observation.
|
1
2
3
4
5
6
7
8
9
10
11
|
t
0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
|
We can shift all the observations down by one time step by inserting one new row at the top. Because the new row has no data, we can use NaN to represent “no data”.
The shift function can do this for us and we can insert this shifted column next to our original series.
|
1
2
3
4
5
|
from pandas import DataFrame
df = DataFrame()
df[‘t’] = [x for x in range(10)]
df[‘t-1’] = df[‘t’].shift(1)
print(df)
|
Running the example gives us two columns in the dataset. The first with the original observations and a new shifted column.
We can see that shifting the series forward one time step gives us a primitive supervised learning problem, although with X and y in the wrong order. Ignore the column of row labels. The first row would have to be discarded because of the NaN value. The second row shows the input value of 0.0 in the second column (input or X) and the value of 1 in the first column (output or y).
|
1
2
3
4
5
6
7
8
9
10
11
|
t t-1
0 0 NaN
1 1 0.0
2 2 1.0
3 3 2.0
4 4 3.0
5 5 4.0
6 6 5.0
7 7 6.0
8 8 7.0
9 9 8.0
|
We can see that if we can repeat this process with shifts of 2, 3, and more, how we could create long input sequences (X) that can be used to forecast an output value (y).
The shift operator can also accept a negative integer value. This has the effect of pulling the observations up by inserting new rows at the end. Below is an example:
|
1
2
3
4
5
|
from pandas import DataFrame
df = DataFrame()
df[‘t’] = [x for x in range(10)]
df[‘t+1’] = df[‘t’].shift(–1)
print(df)
|
Running the example shows a new column with a NaN value as the last value.
We can see that the forecast column can be taken as an input (X) and the second as an output value (y). That is the input value of 0 can be used to forecast the output value of 1.
|
1
2
3
4
5
6
7
8
9
10
11
|
t t+1
0 0 1.0
1 1 2.0
2 2 3.0
3 3 4.0
4 4 5.0
5 5 6.0
6 6 7.0
7 7 8.0
8 8 9.0
9 9 NaN
|
Technically, in time series forecasting terminology the current time (t) and future times (t+1, t+n) are forecast times and past observations (t-1, t-n) are used to make forecasts.
We can see how positive and negative shifts can be used to create a new DataFrame from a time series with sequences of input and output patterns for a supervised learning problem.
This permits not only classical X -> y prediction, but also X -> Y where both input and output can be sequences.
Further, the shift function also works on so-called multivariate time series problems. That is where instead of having one set of observations for a time series, we have multiple (e.g. temperature and pressure). All variates in the time series can be shifted forward or backward to create multivariate input and output sequences. We will explore this more later in the tutorial.
The series_to_supervised() Function
We can use the shift() function in Pandas to automatically create new framings of time series problems given the desired length of input and output sequences.
This would be a useful tool as it would allow us to explore different framings of a time series problem with machine learning algorithms to see which might result in better performing models.
In this section, we will define a new Python function named series_to_supervised() that takes a univariate or multivariate time series and frames it as a supervised learning dataset.
The function takes four arguments:
- data: Sequence of observations as a list or 2D NumPy array. Required.
- n_in: Number of lag observations as input (X). Values may be between [1..len(data)] Optional. Defaults to 1.
- n_out: Number of observations as output (y). Values may be between [0..len(data)-1]. Optional. Defaults to 1.
- dropnan: Boolean whether or not to drop rows with NaN values. Optional. Defaults to True.
The function returns a single value:
- return: Pandas DataFrame of series framed for supervised learning.
The new dataset is constructed as a DataFrame, with each column suitably named both by variable number and time step. This allows you to design a variety of different time step sequence type forecasting problems from a given univariate or multivariate time series.
Once the DataFrame is returned, you can decide how to split the rows of the returned DataFrame into X and y components for supervised learning any way you wish.
The function is defined with default parameters so that if you call it with just your data, it will construct a DataFrame with t-1 as X and t as y.
The function is confirmed to be compatible with Python 2 and Python 3.
The complete function is listed below, including function comments.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
from pandas import DataFrame
from pandas import concat
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
“”“
Frame a time series as a supervised learning dataset.
Arguments:
data: Sequence of observations as a list or NumPy array.
n_in: Number of lag observations as input (X).
n_out: Number of observations as output (y).
dropnan: Boolean whether or not to drop rows with NaN values.
Returns:
Pandas DataFrame of series framed for supervised learning.
““”
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, … t-1)
for i in range(n_in, 0, –1):
cols.append(df.shift(i))
names += [(‘var%d(t-%d)’ % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, … t+n)
for i in range(0, n_out):
cols.append(df.shift(–i))
if i == 0:
names += [(‘var%d(t)’ % (j+1)) for j in range(n_vars)]
else:
names += [(‘var%d(t+%d)’ % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
|
Can you see obvious ways to make the function more robust or more readable?
Please let me know in the comments below.
Now that we have the whole function, we can explore how it may be used.
One-Step Univariate Forecasting
It is standard practice in time series forecasting to use lagged observations (e.g. t-1) as input variables to forecast the current time step (t).
This is called one-step forecasting.
The example below demonstrates a one lag time step (t-1) to predict the current time step (t).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
from pandas import DataFrame
from pandas import concat
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
“”“
Frame a time series as a supervised learning dataset.
Arguments:
data: Sequence of observations as a list or NumPy array.
n_in: Number of lag observations as input (X).
n_out: Number of observations as output (y).
dropnan: Boolean whether or not to drop rows with NaN values.
Returns:
Pandas DataFrame of series framed for supervised learning.
““”
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, … t-1)
for i in range(n_in, 0, –1):
cols.append(df.shift(i))
names += [(‘var%d(t-%d)’ % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, … t+n)
for i in range(0, n_out):
cols.append(df.shift(–i))
if i == 0:
names += [(‘var%d(t)’ % (j+1)) for j in range(n_vars)]
else:
names += [(‘var%d(t+%d)’ % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
values = [x for x in range(10)]
data = series_to_supervised(values)
print(data)
|
Running the example prints the output of the reframed time series.
|
1
2
3
4
5
6
7
8
9
10
|
var1(t-1) var1(t)
1 0.0 1
2 1.0 2
3 2.0 3
4 3.0 4
5 4.0 5
6 5.0 6
7 6.0 7
8 7.0 8
9 8.0 9
|
We can see that the observations are named “var1” and that the input observation is suitably named (t-1) and the output time step is named (t).
We can also see that rows with NaN values have been automatically removed from the DataFrame.
We can repeat this example with an arbitrary number length input sequence, such as 3. This can be done by specifying the length of the input sequence as an argument; for example:
|
1
|
data = series_to_supervised(values, 3)
|
The complete example is listed below.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
from pandas import DataFrame
from pandas import concat
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
“”“
Frame a time series as a supervised learning dataset.
Arguments:
data: Sequence of observations as a list or NumPy array.
n_in: Number of lag observations as input (X).
n_out: Number of observations as output (y).
dropnan: Boolean whether or not to drop rows with NaN values.
Returns:
Pandas DataFrame of series framed for supervised learning.
““”
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, … t-1)
for i in range(n_in, 0, –1):
cols.append(df.shift(i))
names += [(‘var%d(t-%d)’ % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, … t+n)
for i in range(0, n_out):
cols.append(df.shift(–i))
if i == 0:
names += [(‘var%d(t)’ % (j+1)) for j in range(n_vars)]
else:
names += [(‘var%d(t+%d)’ % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
values = [x for x in range(10)]
data = series_to_supervised(values, 3)
print(data)
|
Again, running the example prints the reframed series. We can see that the input sequence is in the correct left-to-right order with the output variable to be predicted on the far right.
|
1
2
3
4
5
6
7
8
|
var1(t-3) var1(t-2) var1(t-1) var1(t)
3 0.0 1.0 2.0 3
4 1.0 2.0 3.0 4
5 2.0 3.0 4.0 5
6 3.0 4.0 5.0 6
7 4.0 5.0 6.0 7
8 5.0 6.0 7.0 8
9 6.0 7.0 8.0 9
|
Multi-Step or Sequence Forecasting
A different type of forecasting problem is using past observations to forecast a sequence of future observations.
This may be called sequence forecasting or multi-step forecasting.
We can frame a time series for sequence forecasting by specifying another argument. For example, we could frame a forecast problem with an input sequence of 2 past observations to forecast 2 future observations as follows:
|
1
|
data = series_to_supervised(values, 2, 2)
|
The complete example is listed below:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
from pandas import DataFrame
from pandas import concat
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
“”“
Frame a time series as a supervised learning dataset.
Arguments:
data: Sequence of observations as a list or NumPy array.
n_in: Number of lag observations as input (X).
n_out: Number of observations as output (y).
dropnan: Boolean whether or not to drop rows with NaN values.
Returns:
Pandas DataFrame of series framed for supervised learning.
““”
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, … t-1)
for i in range(n_in, 0, –1):
cols.append(df.shift(i))
names += [(‘var%d(t-%d)’ % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, … t+n)
for i in range(0, n_out):
cols.append(df.shift(–i))
if i == 0:
names += [(‘var%d(t)’ % (j+1)) for j in range(n_vars)]
else:
names += [(‘var%d(t+%d)’ % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
values = [x for x in range(10)]
data = series_to_supervised(values, 2, 2)
print(data)
|
Running the example shows the differentiation of input (t-n) and output (t+n) variables with the current observation (t) considered an output.
|
1
2
3
4
5
6
7
8
|
var1(t-2) var1(t-1) var1(t) var1(t+1)
2 0.0 1.0 2 3.0
3 1.0 2.0 3 4.0
4 2.0 3.0 4 5.0
5 3.0 4.0 5 6.0
6 4.0 5.0 6 7.0
7 5.0 6.0 7 8.0
8 6.0 7.0 8 9.0
|
Multivariate Forecasting
Another important type of time series is called multivariate time series.
This is where we may have observations of multiple different measures and an interest in forecasting one or more of them.
For example, we may have two sets of time series observations obs1 and obs2 and we wish to forecast one or both of these.
We can call series_to_supervised() in exactly the same way.
For example:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
from pandas import DataFrame
from pandas import concat
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
“”“
Frame a time series as a supervised learning dataset.
Arguments:
data: Sequence of observations as a list or NumPy array.
n_in: Number of lag observations as input (X).
n_out: Number of observations as output (y).
dropnan: Boolean whether or not to drop rows with NaN values.
Returns:
Pandas DataFrame of series framed for supervised learning.
““”
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, … t-1)
for i in range(n_in, 0, –1):
cols.append(df.shift(i))
names += [(‘var%d(t-%d)’ % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, … t+n)
for i in range(0, n_out):
cols.append(df.shift(–i))
if i == 0:
names += [(‘var%d(t)’ % (j+1)) for j in range(n_vars)]
else:
names += [(‘var%d(t+%d)’ % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
raw = DataFrame()
raw[‘ob1’] = [x for x in range(10)]
raw[‘ob2’] = [x for x in range(50, 60)]
values = raw.values
data = series_to_supervised(values)
print(data)
|
Running the example prints the new framing of the data, showing an input pattern with one time step for both variables and an output pattern of one time step for both variables.
Again, depending on the specifics of the problem, the division of columns into X and Y components can be chosen arbitrarily, such as if the current observation of var1 was also provided as input and only var2was to be predicted.
|
1
2
3
4
5
6
7
8
9
10
|
var1(t-1) var2(t-1) var1(t) var2(t)
1 0.0 50.0 1 51
2 1.0 51.0 2 52
3 2.0 52.0 3 53
4 3.0 53.0 4 54
5 4.0 54.0 5 55
6 5.0 55.0 6 56
7 6.0 56.0 7 57
8 7.0 57.0 8 58
9 8.0 58.0 9 59
|
You can see how this may be easily used for sequence forecasting with multivariate time series by specifying the length of the input and output sequences as above.
For example, below is an example of a reframing with 1 time step as input and 2 time steps as forecast sequence.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
from pandas import DataFrame
from pandas import concat
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
“”“
Frame a time series as a supervised learning dataset.
Arguments:
data: Sequence of observations as a list or NumPy array.
n_in: Number of lag observations as input (X).
n_out: Number of observations as output (y).
dropnan: Boolean whether or not to drop rows with NaN values.
Returns:
Pandas DataFrame of series framed for supervised learning.
““”
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, … t-1)
for i in range(n_in, 0, –1):
cols.append(df.shift(i))
names += [(‘var%d(t-%d)’ % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, … t+n)
for i in range(0, n_out):
cols.append(df.shift(–i))
if i == 0:
names += [(‘var%d(t)’ % (j+1)) for j in range(n_vars)]
else:
names += [(‘var%d(t+%d)’ % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
raw = DataFrame()
raw[‘ob1’] = [x for x in range(10)]
raw[‘ob2’] = [x for x in range(50, 60)]
values = raw.values
data = series_to_supervised(values, 1, 2)
print(data)
|
Running the example shows the large reframed DataFrame.
|
1
2
3
4
5
6
7
8
9
|
var1(t-1) var2(t-1) var1(t) var2(t) var1(t+1) var2(t+1)
1 0.0 50.0 1 51 2.0 52.0
2 1.0 51.0 2 52 3.0 53.0
3 2.0 52.0 3 53 4.0 54.0
4 3.0 53.0 4 54 5.0 55.0
5 4.0 54.0 5 55 6.0 56.0
6 5.0 55.0 6 56 7.0 57.0
7 6.0 56.0 7 57 8.0 58.0
8 7.0 57.0 8 58 9.0 59.0
|
Experiment with your own dataset and try multiple different framings to see what works best.
Summary
In this tutorial, you discovered how to reframe time series datasets as supervised learning problems with Python.
Specifically, you learned:
- About the Pandas shift() function and how it can be used to automatically define supervised learning datasets from time series data.
- How to reframe a univariate time series into one-step and multi-step supervised learning problems.
- How to reframe multivariate time series into one-step and multi-step supervised learning problems.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
MUEEN KEOGH算法
论文:Exact Discovery of Time Series Motifs
Speeded up Brute Force Motif Discovery:
Github:https://github.com/saifuddin778/mkalgo
但是感觉有一行比较奇怪,应该是 



Generalization to multiple reference points:
https://github.com/nicholasg3/motif-mining/tree/95bbb05ac5d0f9e90134a67a789ea7e607f22cea
注意:
for j = 1 to m-offset 而不是 for j = 1 to R


Time Series Clustering with Dynamic Time Warping (DTW)
https://github.com/goodmattg/wikipedia_kaggle
zr9558's Blog
- HOME
- CONTACT
- NATIONAL UNIVERSITY OF SINGAPORE
- MATH MODULES
- LEVEL 1
- MA 1100 FUNDAMENTAL CONCEPTS OF MATHEMATICS
- MA 1101R LINEAR ALGEBRA I
- MA 1102R CALCULUS
- MA 1104 MULTI-VARIABLE CALCULUS
- MA 1505 MATHEMATICS I
- KEY POINTS OF MA 1505 MATHEMATICS I
- PREDICTION OF FINAL EXAM
- TUTORIALS
- MA 1506 MATHEMATICS II
- TUTORIALS
- MA 1507 ADVANCED CALCULUS
- MA 1521 CALCULUS FOR COMPUTING
- LEVEL 2
- MA 2101 LINEAR ALGEBRA II
- MA 2108 MATHEMATICAL ANALYSIS I
- MA 2213 NUMERICAL ANALYSIS I
- MA 2214 COMBINATORIAL ANALYSIS
- LEVEL 3
- QF 3101 INVESTMENT INSTRUMENTS: THEORY AND COMPUTATION
- MA 3227 NUMERICAL ANALYSIS II
- MA 3501 MATHEMATICAL METHODS IN ENGINEERING
- LEVEL 4 AND GRADUATE LEVEL
- QF 4201 FINANCIAL MODELING
- MA 4230 MATRIX COMPUTATION
- MA 4247 COMPLEX ANALYSIS II
- MA 5203 GRADUATE ALGEBRA I
- MA 5205 GRADUATE ANALYSIS I
- MA 5213 PARTIAL DIFFERENTIAL EQUATIONS
- MA 5238 FOURIER ANALYSIS
- LEVEL 1
- PHD QE PAPERS
- ALGEBRA
- ANALYSIS
- REAL AND COMPLEX DYNAMICS
- MATH MODULES
- NANJING UNIVERSITY
- NJUBBS
- 飞哥传说
- 数学系本科课程
- 离散数学
- 高等代数
- 数学分析
- TENCENT
- MACHINE LEARNING
- RECOMMENDER SYSTEMS
- TIME SERIES
| M | T | W | T | F | S | S |
|---|---|---|---|---|---|---|
| « May | ||||||
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 | |||||
Search for:
TOP POSTS & PAGES
- 用Latex写中英文简历,CV
- 分类模型的正负样本
- Follow the Regularized Leader (FTRL) 算法
- Forward-Backward Splitting (FOBOS) 算法简介
- 时间序列的搜索
- MA 2108 Mathematical Analysis I
- 异常点检测算法(一)
- 特征工程简介
- 时间序列的相似性
- 时间序列模型之灰度模型
CATEGORIES
- Classical and Modern Fourier Analysis
- Complex Analysis
- Computer Science
- 灌篮高手
- DeepMind
- Discrete Mathematics
- 职场纵横
- 量子计算
- 袁腾飞
- GaofeiZhang
- Graduate Summer School 2008
- How To Enjoy Your Life and Your Job
- MA 1505 Mathematics I
- MA 1506 Mathematics II
- Mathematical Analysis
- Mathematics
- One Dimensional Dynamical System
- Opencv
- PHD的生涯
- Singapore
- SQL基础教程
- Statistics
- Time Series
- Uncategorized
- 南京大学bbs小百合
- 变形金刚
- 吃货系列
- 安全业务领域
- 心理学
- 扑克AI
- 报刊杂志摘选
- 推荐系统
- 数学界的八卦
- 数学科普
- 数据挖掘与机器学习
- 文本挖掘
- 时间序列
- 智能运维
- 暗黑破坏神3
- 每天的时间。。。。
- 三国演义
- 互联网的生涯
BLOG STATS
- 148,523 hits
META
- Register
- Log in
- Entries RSS
- Comments RSS
- WordPress.com
BLOGROLL
- Dimensions
- watchme007's Blog
- xiangsun
ARCHIVES
- May 2018
- April 2018
- March 2018
- January 2018
- November 2017
- September 2017
- August 2017
- May 2017
- April 2017
- March 2017
- February 2017
- January 2017
- December 2016
- November 2016
- October 2016
- September 2016
- August 2016
- June 2016
- May 2016
- April 2016
- March 2016
- February 2016
- January 2016
- November 2015
- October 2015
- September 2015
- April 2015
- January 2015
- December 2014
- November 2014
- October 2014
- September 2014
- August 2014
- July 2014
- June 2014
- May 2014
- April 2014
- February 2014
- January 2014
- December 2013
- November 2013
- October 2013
- September 2012
- August 2012
- May 2012
- April 2012
- March 2012
- February 2012
- January 2012
- December 2011
- November 2011
- October 2011
- May 2011
- April 2011
- March 2011
FOLLOW BLOG VIA EMAIL
Enter your email address to follow this blog and receive notifications of new posts by email.
Join 50 other followers
时间序列的自回归模型—从线性代数的角度来看相关推荐
- 线性代数的本质及其在AI中的应用
线性代数是 AI 专家必须掌握的知识,这已不再是个秘密.如果不掌握应用数学这个领域,你永远就只能是「门外汉」.当然,学习线性代数道阻且长.数学,尤其是线性代数常与枯燥.复杂和毫无意义的事物联系起来.不 ...
- c语言中x的n次方怎么表示_线性代数的本质及其在AI中的应用
线性代数是 AI 专家必须掌握的知识,这已不再是个秘密.如果不掌握应用数学这个领域,你永远就只能是「门外汉」.当然,学习线性代数道阻且长.数学,尤其是线性代数常与枯燥.复杂和毫无意义的事物联系起来.不 ...
- c语言中x的n次方怎么表示_线性代数的本质及其在人工智能中的应用
线性代数是 AI 专家必须掌握的知识,这已不再是个秘密.如果不掌握应用数学这个领域,你永远就只能是「门外汉」.当然,学习线性代数道阻且长.数学,尤其是线性代数常与枯燥.复杂和毫无意义的事物联系起来.不 ...
- MIT 18.06 +线性代数的几何意义+3Blue1Brown 笔记
第一节 线性映射与线性变换 线性函数:初等f(x)=kxf ( x ) = k xf(x)=kx,满足可加性与比例行,几何意义为一条直线:高等线性函数:扩展初等线性函数,f(x1,x2,⋯,xn)=k ...
- 【线性代数的本质|笔记】从线性变换的角度看向量的点积和叉积
点积与叉积 引入点积的标准方法 定义:对于给定的两个同维度的向量求解点积,就是将向量相对应的维度的分量相乘再相加. 几何意义:两个向量w和v的点积,可以看成是向量w在v方向的投影和v长度的乘积:或者是 ...
- 对线性代数的思考和理解
前言 刚刚看完了"可汗学院公开课-线性代数的本质",对线性代数的理解上了不止一个台阶.虽然大学的时候上过这门必修课,以及本科毕业之后特意读了黄色书皮的<线性代数及其应用> ...
- 十分钟理解线性代数的本质_数学对于编程来说到底有多重要?来看看编程大佬眼里的线性代数!...
本文提出了一种观点:从应用的角度,我们可以把线性代数视为一门特定领域的程序语言.我们一起来看看!文章有点偏理论讨论,可能比较枯燥,对于一名程序员,你如果看下去,你将会有不一样的收获! 线性代数是什么? ...
- 线性代数的本质(干货!)
原文链接:https://www.cnblogs.com/TenosDoIt/p/3214096.html 从大学开始接触矩阵论和线性代数,记了很多公式,但是总感觉徘徊在线性代数的门外没有进去,感觉并 ...
- 【直观详解】线性代数的本质
转载自:https://charlesliuyx.github.io/2017/10/06/%E3%80%90%E7%9B%B4%E8%A7%82%E8%AF%A6%E8%A7%A3%E3%80%91 ...
最新文章
- P4722 【模板】最大流
- python声明编码作用_Python源代码中的编码声明字符串的作用
- 【Linux】一步一步学Linux——dig命令(160)
- 云上更安全?亚马逊云科技宣布将持续加大在中国区域安全合规领域投入
- 【服务端渲染】之 Vue SSR
- ICCV2021 人脸深伪分析挑战赛 重磅来袭
- mysql日志模式默认是raw还是_深入学习MySQL 02 日志系统:bin log,redo log,undo log
- B - 好数 51Nod - 1717
- mysql的常见命令与语法规范
- 微软开启imap服务器,连接到 IMAP 或 SMTP 服务器
- 正态性检验中的统计量D值和统计量W值如何计算?
- 如何彻底关闭Windows更新
- 一张纸的厚度为0.08mm,对折多少次能达到或超过珠穆朗玛峰的高度(8848.13米)
- java时区ZoneId集
- 一名大二废柴今后目标
- dell t640 添加硬盘_Dell PowerEdge T640服务器安装教程
- 使用aria2搭建离线下载服务器
- Elasticsearch Ingest-Attachment
- python爬取微博评论超100页_python爬取新浪微博评论-Go语言中文社区
- Greenplum查看表/库大小、进程、表膨胀处理(sql语句)