使用基于ggplot2的包ggalluvial绘制桑基图(冲积图)
1. 使用基于ggplot2的包ggalluvial绘制桑基图(冲积图)
参考:https://corybrunson.github.io/ggalluvial/articles/ggalluvial.html
ggalluvial 是ggplot2的拓展,用于在 tidyverse 框架中产生冲积图(或桑基图)。该包的设计和功能受 alluvial 包的启发,并从许多用户的反馈中受益。本简介包括如下内容:
定义在命名方案和文件中使用的冲积地块的基本组成部分(轴axis、冲积层alluvium、地层stratum、矿脉lode、水流flow),
描述ggalluvial可以识别的冲积数据结构,
说明了新的数据和几何函数,还有
展示了该主题的一些流行变体以及如何制作它们。
与大多数冲积图和相关图不同,由ggalluvial 生成的图是由数据集和统计转换唯一确定的。这篇博客文章将详细介绍二者的区别。
还有许多其他资源可以在R中可视化分类数据,包括几种更基本的绘图类型,当数据的结构不符合冲积图的要求时,它们可能更准确地向观众传递比例信息。特别地,可以查看Michael Friendly的vcd和vcdExtra软件包(PDF)来了解各种基于统计的分类数据可视化技术,Hadley Wickham的**productplots软件包**以及Haley Jeppson和Heike Hofmann的后继者ggmosaic软件包可用于产品或者马赛克图,以及Nicholas Hamilton的ggtern软件包用于三元坐标。其他相关的程序包如下所述。
1.1 冲积图(Alluvial plots)
此处是一个典型的冲积图:
![]()
下一节将详细说明该图像的元素如何对底层数据集的信息进行编码。现在,我们用这张图片作为一个参考点来定义一个典型冲积图的以下元素:
- **轴(axis )**是一个维度(变量),数据沿着它在固定的水平位置垂直分组。上面的图像使用了三个分类轴:Class、Sex和Age。
- 每个轴上的分组被描绘成不透明的块,称为地层(strata)。例如,
Class轴包含4个层次:1、2、3和Crew。 - 被称为**冲积(alluvia)**的水平(x-)样条横跨地块的宽度。在这个图中,每个冲积层对应于每个轴变量的固定值,由其在轴上的垂直位置表示,以及由其填充颜色表示的
Survived变量的固定值。 - 在相邻轴线之间的冲积层片段是水流(flow)。
- 冲积层在**矿脉处(lodes)**与地层相交。上述图中没有显示矿脉,但可以推断为填充的矩形,这些矩形在图的每一端延伸流过地层的流动,或连接中心地层两侧的流动。
正如下一节的示例所演示的那样,将这些元素中的哪些合并到冲积图中取决于底层数据的结构方式以及创建者希望该图传达什么信息。
1.2 冲积图数据(Alluvial data)
ggalluvial可以识别两种形式的“冲积数据alluvial data", 在以下几个小节中详细处理,但基本上对应于分类重复测量数据的“宽”和“长”格式。另外表格形式(tablular或者array)是多种分类维度数据存储的流行方式,例如Titanic和UCBAdmissions数据集。为了符合数据整洁原则和ggplot2转化,ggalluvial接受tabular输入; base::data.frame()可以将array转化为可接受的data frame。
补充:
- Titanic数据集:数据集为1912年泰坦尼克号沉船事件中一些船员的个人信息以及存活状况。包括乘客编号、所在船舱等级、姓名、性别、兄弟姐妹数量、父母和子女数量、票号、票价、座位号和乘客登船码头等。参考:https://www.heywhale.com/mw/dataset/58a940107159a710d916aefb
- UCBAdmissions数据集:伯克利研究生院性别歧视数据。原数据六个院系中,一个严重「歧视」男生,三个轻微「歧视」男生。另外还有两个院系轻微「歧视」女生,某种程度上削弱了数据的戏剧性。参考:https://zhuanlan.zhihu.com/p/30446806
1.2.1 Alluvia (wide) format
宽(wide)的格式反映了冲积图的视觉安排,但“不扭曲”: 每一行对应一组观测,每个变量取特定值,每个变量有自己的列。另外的1列表示每行的数量,例如队列中观测单位的数量,可用于控制**地层(strata) 高度。基本上,宽格式由每冲积层一行(one row per alluvium)**组成。这是base::as.data.frame()转换频率表的格式,例如三维UCBAdmissions数据集:
head(as.data.frame(UCBAdmissions), n = 12)
## Admit Gender Dept Freq
## 1 Admitted Male A 512
## 2 Rejected Male A 313
## 3 Admitted Female A 89
## 4 Rejected Female A 19
## 5 Admitted Male B 353
## 6 Rejected Male B 207
## 7 Admitted Female B 17
## 8 Rejected Female B 8
## 9 Admitted Male C 120
## 10 Rejected Male C 205
## 11 Admitted Female C 202
## 12 Rejected Female C 391
is_alluvia_form(as.data.frame(UCBAdmissions), axes = 1:3, silent = TRUE)
## [1] TRUE
这种形式来自ggalluvial的第一版本,其是根据alluvial的使用建立的。用户可以定义任意数量的轴数目, stat_alluvium() and stat_stratum() 能够以一致的方式来识别:
stat_alluvium(): 计算冲积层与地层的交点。stat_stratum(): 计算每个轴中地层的中心和高度。
ggplot(as.data.frame(UCBAdmissions),aes(y = Freq, axis1 = Gender, axis2 = Dept)) +geom_alluvium(aes(fill = Admit), width = 1/12) +geom_stratum(width = 1/12, fill = "black", color = "grey") +geom_label(stat = "stratum", aes(label = after_stat(stratum))) +scale_x_discrete(limits = c("Gender", "Dept"), expand = c(.05, .05)) +scale_fill_brewer(type = "qual", palette = "Set1") +ggtitle("UC Berkeley admissions and rejections, by sex and department")
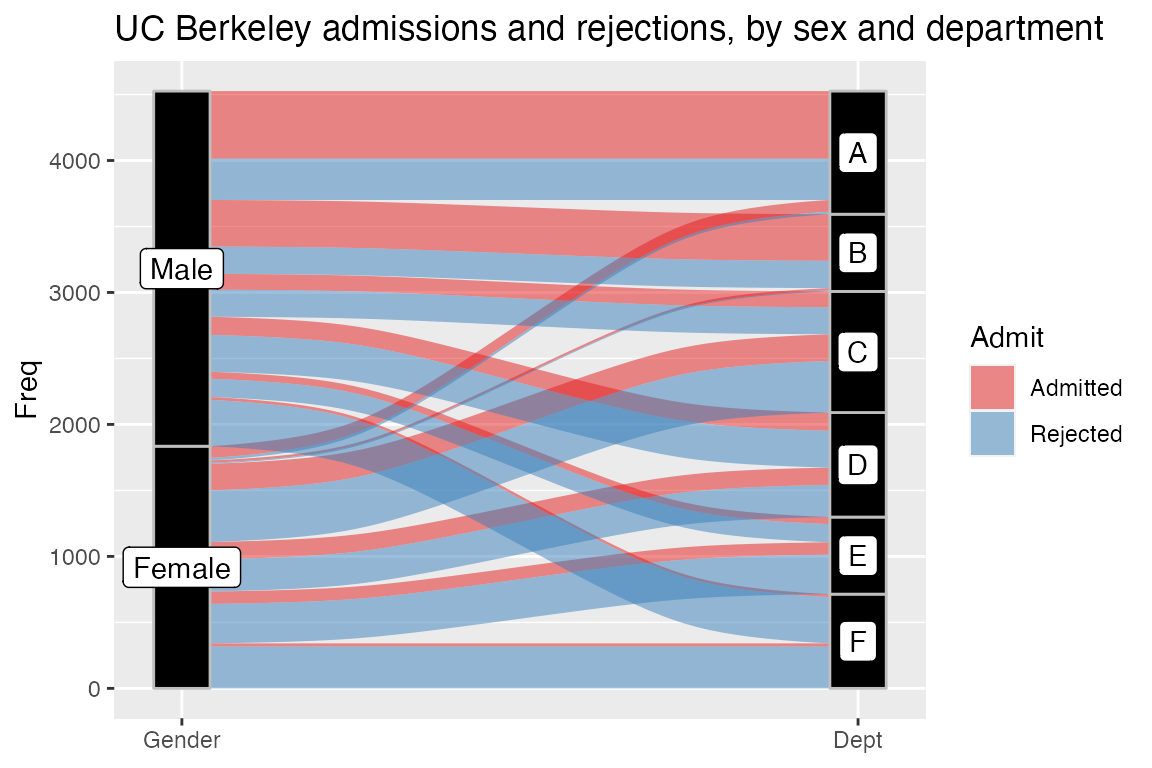
这些图的一个重要特征是垂直轴的意义: 地层之间没有插入空隙,因此图片的总高度反映了观测的累积量。由ggalluvial 形成的图片(在某种程度上)符合ggplot2的“图形语法”原则,这阻止了用户生成“自由浮动”的可视化,比如这里展示的桑基图。ggalluvial参数和现有的ggplot2功能也可以生成并行集合的图片,这里使用HairEyeColor数据集https://corybrunson.github.io/ggalluvial/articles/ggalluvial.html#fn5:
ggplot(as.data.frame(HairEyeColor),aes(y = Freq,axis1 = Hair, axis2 = Eye, axis3 = Sex)) +geom_alluvium(aes(fill = Eye),width = 1/8, knot.pos = 0, reverse = FALSE) +scale_fill_manual(values = c(Brown = "#70493D", Hazel = "#E2AC76",Green = "#3F752B", Blue = "#81B0E4")) +guides(fill = FALSE) +geom_stratum(alpha = .25, width = 1/8, reverse = FALSE) +geom_text(stat = "stratum", aes(label = after_stat(stratum)),reverse = FALSE) +scale_x_continuous(breaks = 1:3, labels = c("Hair", "Eye", "Sex")) +coord_flip() +ggtitle("Eye colors of 592 subjects, by sex and hair color")
## Warning: `guides(<scale> = FALSE)` is deprecated. Please use `guides(<scale> =
## "none")` instead.
## Warning in to_lodes_form(data = data, axes = axis_ind, discern =
## params$discern): Some strata appear at multiple axes.## Warning in to_lodes_form(data = data, axes = axis_ind, discern =
## params$discern): Some strata appear at multiple axes.## Warning in to_lodes_form(data = data, axes = axis_ind, discern =
## params$discern): Some strata appear at multiple axes.
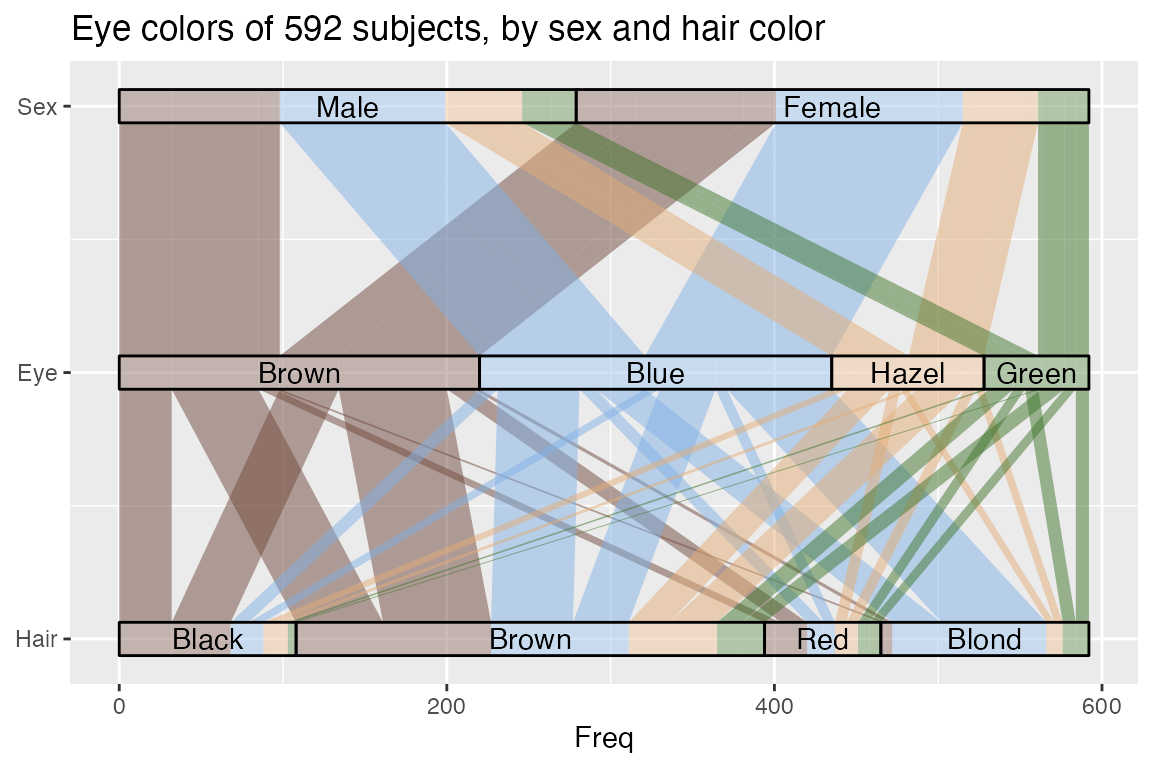
(警告是因为“头发Hair"和"眼睛Eye"轴都含有”Brown“值)
这种形式很功能对于很多应用时有用的,将在未来的版本中保留。它们还涉及一些明显偏离ggplot2规范的情况。
axis[0-9]*的位置美学是非标准的:它们不是一组显式参数,而是基于正则表达式模式的一系列参数;至少需要一个,但不是特定的一个。stat_alluvium()忽略group美学的任何参数;相反,statAlluvium$compute_panel()使用group来链接对应于同一冲积层的内部转换数据集的行。stat_stratum()(由geom_text()调用)产生的stratum变量在执行统计转换之前不可用,必须使用after_stat()恢复。- 必须手动纠正水平轴(使用
scale_x_discrete()或scale_x_continuous()),以反映标识轴的隐式分类变量。
此外,对于每个冲积层来说,fill等格式美学是必要的;例如,它们不能根据每个轴的值从一个轴改变到另一个轴。这意味着,尽管它们可以再现平行集的分支树结构,但这种格式和功能不能自然地产生带有配色方案的冲积图,比如这里的那些(“控制颜色”),它们在每个轴上都被“重置”。
1.2.2 Lodes (long) format
被ggalluvial识别的长格式每个lode包含一行(one row per lode),可以理解为将dplyr格式的数据集的轴列“gathering”(在dplyr的意义上)或将microsoftexcel格式的数据集的轴列“pivoting”(在microsoftexcel的意义上)到一个键-值对的列中,将轴编码为键,地层编码为值。这种格式需要一个额外的索引列,将对应于一个共同队列的行连接起来,即单个冲积层的矿脉:
UCB_lodes <- to_lodes_form(as.data.frame(UCBAdmissions),axes = 1:3,id = "Cohort")
head(UCB_lodes, n = 12)
## Freq Cohort x stratum
## 1 512 1 Admit Admitted
## 2 313 2 Admit Rejected
## 3 89 3 Admit Admitted
## 4 19 4 Admit Rejected
## 5 353 5 Admit Admitted
## 6 207 6 Admit Rejected
## 7 17 7 Admit Admitted
## 8 8 8 Admit Rejected
## 9 120 9 Admit Admitted
## 10 205 10 Admit Rejected
## 11 202 11 Admit Admitted
## 12 391 12 Admit Rejected
is_lodes_form(UCB_lodes, key = x, value = stratum, id = Cohort, silent = TRUE)
## [1] TRUE
在宽(alluvia)和长(lodes)格式之间转换数据的函数包括几个有助于保存辅助信息的参数。参见help("alluvial-data")获取示例。
相同的属性和geom可以使用不同的位置美学来接收这种格式的数据,同样也适用于ggalluvial:
x:“键”变量,表示行对应的轴,将沿水平轴排列;stratum,由轴变量x所表示的“值”;而且alluvium,将单个冲积层的各行连接起来的索引方案。
高度可以从轴到轴变化,允许用户生成像这里(https://imgur.com/gallery/gI5p7)展示的凹凸图在这些情况下,地层所包含的信息并不比冲积层多,而且常常没有绘制出来。为了方便起见,stat_alluvium()和stat_flow()将接受x和alluvium的参数,即使没有给出参数stratum。例如,我们可以按地区对Refugees数据集中的国家进行分组,以便比较不同规模的难民数量:
data(Refugees, package = "alluvial")
country_regions <- c(Afghanistan = "Middle East",Burundi = "Central Africa",`Congo DRC` = "Central Africa",Iraq = "Middle East",Myanmar = "Southeast Asia",Palestine = "Middle East",Somalia = "Horn of Africa",Sudan = "Central Africa",Syria = "Middle East",Vietnam = "Southeast Asia"
)
Refugees$region <- country_regions[Refugees$country]
ggplot(data = Refugees,aes(x = year, y = refugees, alluvium = country)) +geom_alluvium(aes(fill = country, colour = country),alpha = .75, decreasing = FALSE) +scale_x_continuous(breaks = seq(2003, 2013, 2)) +theme_bw() +theme(axis.text.x = element_text(angle = -30, hjust = 0)) +scale_fill_brewer(type = "qual", palette = "Set3") +scale_color_brewer(type = "qual", palette = "Set3") +facet_wrap(~ region, scales = "fixed") +ggtitle("refugee volume by country and region of origin")
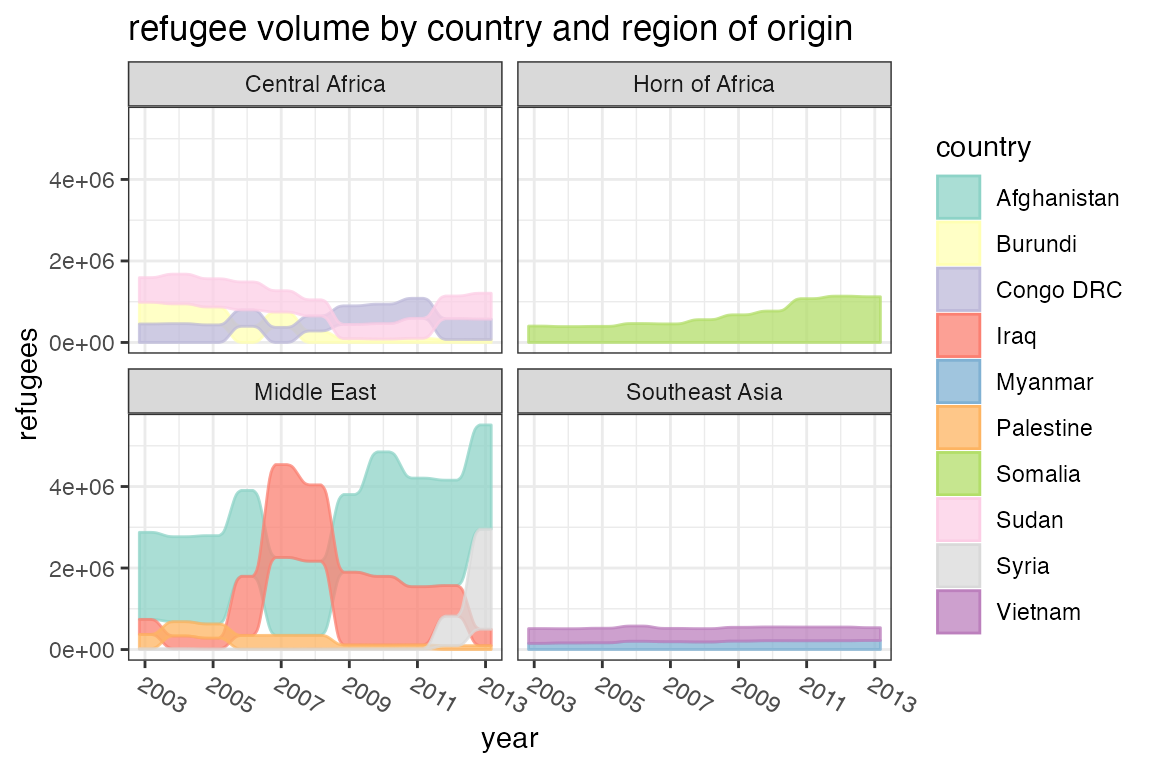
该格式允许我们沿着同一冲积层从轴到轴的变化分配图片属性,这对重复测量数据集很有用。这需要为每个流生成单独的图形对象,就像在geom_flow()中实现的那样。下面的图片使用了一组学生在几个学期的课程的学术课程的变化。由于geom_flow()默认调用stat_flow()(见下一个例子),我们用stat_alluvium()覆盖它,以便跟踪所有学期的每个学生:
data(majors)
majors$curriculum <- as.factor(majors$curriculum)
ggplot(majors,aes(x = semester, stratum = curriculum, alluvium = student,fill = curriculum, label = curriculum)) +scale_fill_brewer(type = "qual", palette = "Set2") +geom_flow(stat = "alluvium", lode.guidance = "frontback",color = "darkgray") +geom_stratum() +theme(legend.position = "bottom") +ggtitle("student curricula across several semesters")
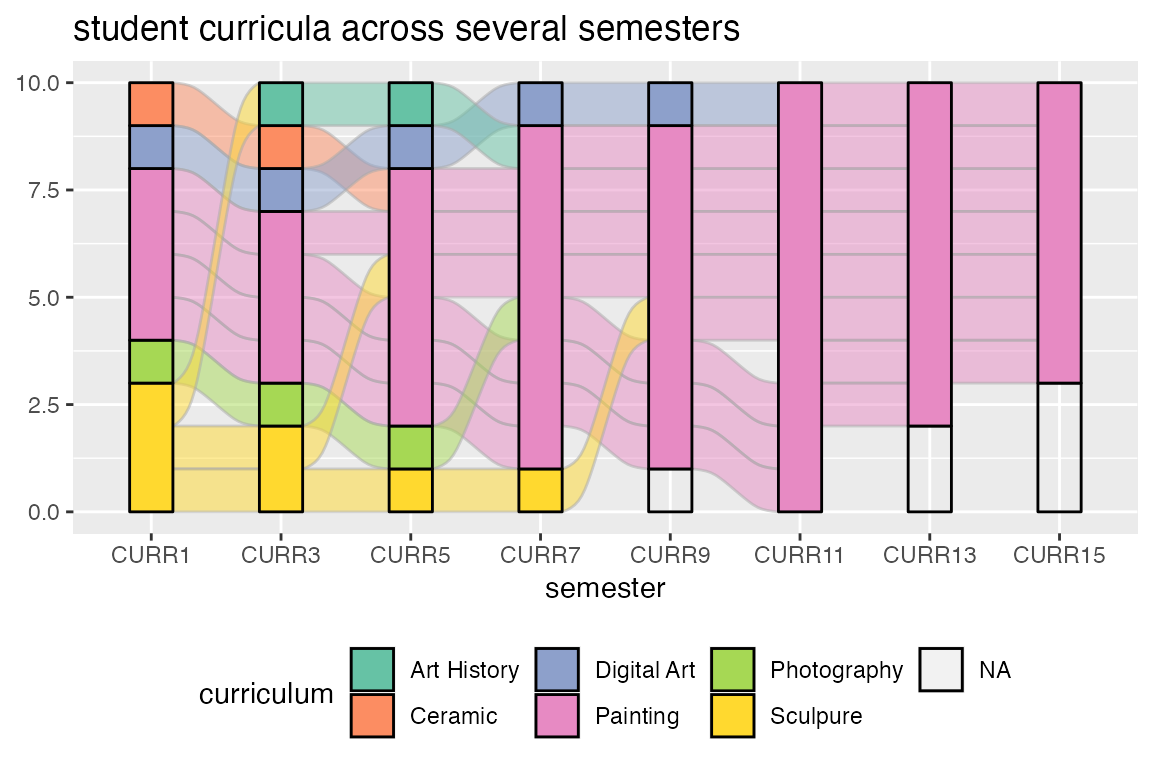
地层高度y未指定,因此每一行给定单位高度。这个例子展示了ggalluvial 处理丢失数据的一种方法。另一种方法是设置参数na.rm=TRUE。丢失的数据处理(具体来说,地层的顺序)也取决于stratum变量是字符变量还是因子/数字变量。
最后,lode格式为我们提供了聚合相邻轴之间的流的选项,当相邻轴之间的转换是最重要的时候,这可能是合适的。我们可以通过兰德美国生命小组(RAND American Life Panel)进行的流感疫苗接种调查数据来证明这一选择。数据,包括三个调查中每个问题的一个问题,已被汇总的回应档案(response profile):每个“subject”(对应到alluvium)实际上代表了一个队列的受试者,他们以相同的方式回答所有三个问题,每个队列的大小(映射到y)被记录在“频率freq”中。
data(vaccinations)
vaccinations <- transform(vaccinations,response = factor(response, rev(levels(response))))
ggplot(vaccinations,aes(x = survey, stratum = response, alluvium = subject,y = freq,fill = response, label = response)) +scale_x_discrete(expand = c(.1, .1)) +geom_flow() +geom_stratum(alpha = .5) +geom_text(stat = "stratum", size = 3) +theme(legend.position = "none") +ggtitle("vaccination survey responses at three points in time")
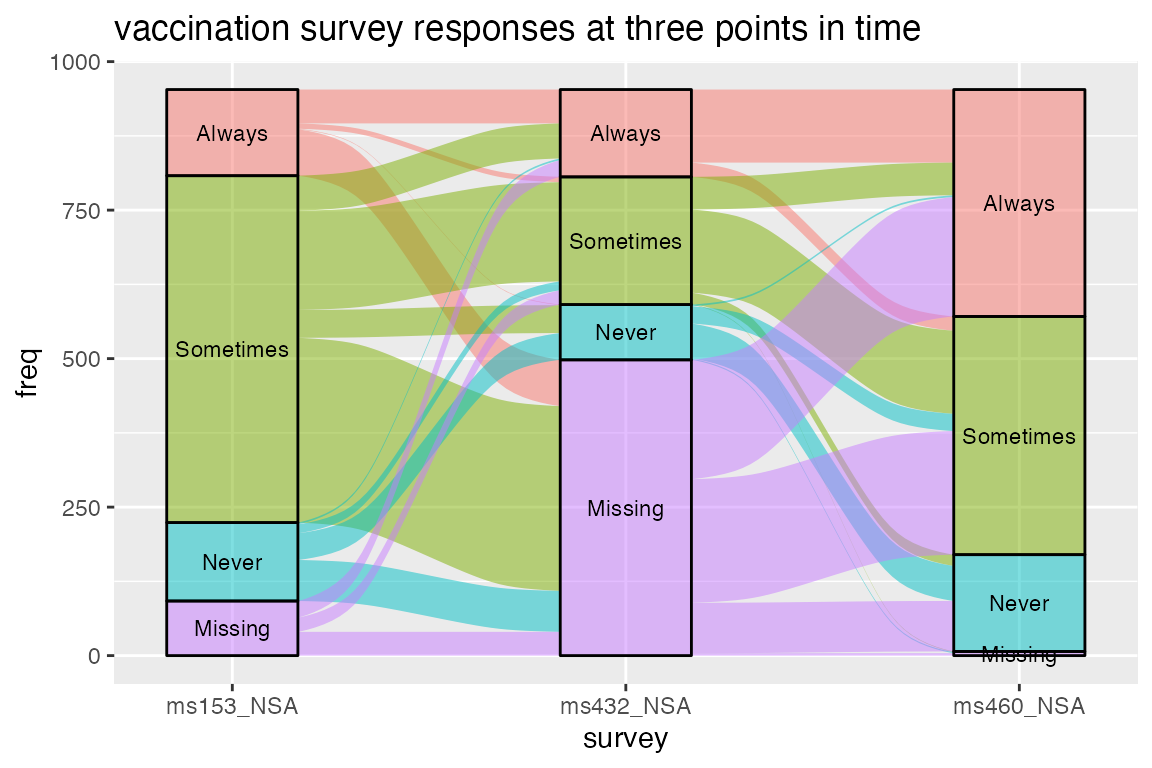
这个图忽略了轴与轴之间的流动之间的连续性。这种“无记忆”地块产生了一个不那么混乱的图,其中最多有一个流从一个轴上的每个地层流向下一个轴上的每个地层,但代价是能够在整个图片上跟踪每个队列。
使用基于ggplot2的包ggalluvial绘制桑基图(冲积图)相关推荐
- python 桑基图_3行代码基于python的matplotlib绘制桑基图
背景 桑基图作为1种表达数据流动方向的可视化方式,在商业数据分析,地理可视化,生物医学领域有着广泛应用.比如:在基因组学领域,有研究利用桑基图来表示生物分子之间的调控关系. 目前多数桑基图软件包(如p ...
- riverplot绘制桑基图
桑基图是一种方便说明信息.资源流动和图形,图形中的分.合正如漂流的分叉与汇合,如可用于比较不同簇间关系,可以用来表示各个节点之间转换. Sankey plots are a type of diagr ...
- Pyecharts一文速学-绘制桑基图详解+Python代码
目录 前言 一.桑基图 二.Pyecharts绘制 1.数据处理 2.桑基图参数 1.class Sankey() 2.class SankeyLevelsOpts() 三.add()方法参数 1.s ...
- Python绘制桑基图
很多时候,我们需要一种必须可视化数据如何在实体之间流动的情况.例如,以居民如何从一个国家迁移到另一个国家为例.这里演示了有多少居民从英格兰迁移到北爱尔兰.苏格兰和威尔士. 桑基图简介 从这个 桑基图 ...
- 【Python 实战基础】如何绘制桑基图分析人口流动和年龄数据
目录 一.实战场景 二.主要知识点 文件读写 基础语法 字符串处理 文件生成 数据构建 三.菜鸟实战 1.创建 python 文件 2.运行结果 一.实战场景 实战场景:如何绘制桑基图分析人口流动和年 ...
- Python绘制桑基图Sankey,Pyecharts不显示html页面,桑基图只显示标题,原因总结
Python绘制桑基图Sankey,Pyecharts不显示html页面,桑基图只显示标题,原因总结 说说使用上的三点注意: 1.nodes中的"name"不要重新命名,否则会不识 ...
- R包ggalluvial绘制冲击图(alluvial diagram)
ggalluvial是一个基于ggplot2的扩展包,冲击图(alluvial diagram)是流程图(flow diagram)的一种,最初开发用于代表网络结构的时间变化. R代码 ...
- python怎么画函数图_可视化|Python绘制桑基图
桑基图(Sankey diagram),即桑基能量分流图,也叫桑基能量平衡图.它是一种特定类型的流程图,图中延伸的分支的宽度对应数据流量的大小,通常应用于电商.材料成分.金融等数据的可视化分析.因18 ...
- 太酷了,手把手教你用 Python 绘制桑基图
桑基图,它的核心是对不同点之间,通过线来连接.线的粗细代表流量的大小.很多工具都能实现桑基 图,比如:Excel.tableau,我们今天要用 Pyecharts 来绘制. 因为没有用户行为路径相关的 ...
最新文章
- 使用 ZwUnmapViewOfSection 卸载并替换内存镜像
- 《移山之道》第十一章:两人合作 读书笔记 PB16110698 第六周(~4.15)
- DNS-实验6_queryperf和dnstop的简单使用
- linux常用命令之权限
- 用FFmpeg从视频截取任意一帧图片的解决办法~
- 华为双11发 20 亿奖金!?
- sql 在某表中加入一列count所有数据_执行COUNT(1)、COUNT(*) 与 COUNT(列名) 到底有什么区别?...
- C# 连接 Exchange 发送邮件
- 漫画:什么是A*寻路算法?
- 分布式任务定时框架elasticjob详解
- oracle8i odac for c,ODAC for delphi
- EI会议列表--IEEE主办的会议
- 【QT】对话框dialog
- Amoeba:开源的分布式数据库Porxy解决方案
- 打开计算机文档左边,打开.chm的文件后,看不到左边的目录,该怎样解决?
- python增加一列数据_使用Python向DataFrame中指定位置添加一列或多列的方法
- codeforce 417D Cunning Gena (状压DP)
- Oracle 变量绑定与变量窥视合集系列五
- 手机安装linux发行版,为亲朋好友挑选一款合适的Linux发行版
- toAppendStream doesn‘t support consuming update and delete changes which is produced by node XXX