快排的优化(简直神乎其神了!!!)
本文转载于:http://www.blogjava.net/killme2008/archive/2010/09/08/quicksort_optimized.html
quicksort可以说是应用最广泛的排序算法之一,它的基本思想是分治法,选择一个pivot(中轴点),将小于pivot放在左边,将大于pivot放在右边,针对左右两个子序列重复此过程,直到序列为空或者只有一个元素。这篇blog主要目的是关注quicksort可能的改进方法,并对这些改进方法做评测。其目的是为了理解Arrays.sort(int [ ]a)的实现。实现本身有paper介绍。
quicksort一个教科书式的简单实现,采用左端点做pivot(《算法导论》上伪代码是以右端点做pivot):
// 0个或1个元素,返回
if (p >= r)
return ;
// 选择左端点为pivot
int x = a[p];
int j = p;
for ( int i = p + 1 ; i <= r; i ++ ) {
// 小于pivot的放到左边
if (a[i] < x) {
swap(a, ++ j, i);
}
}
// 交换左端点和pivot位置
swap(a, p, j);
// 递归子序列
qsort1(a, p, j - 1 );
qsort1(a, j + 1 , r);
}
其中的swap用于交换数组元素:
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
quicksort的最佳情况下的时间复杂度O(n logn),最坏情况下的时间复杂度是O(n^2),退化到插入排序的最坏情况,平均情况下的平均复杂度接近于最佳情况也就是O(nlog n),这也是基于比较的排序算法的比较次数下限。
为了对排序算法的性能改进有个直观的对比,我们建立一个测试基准,分别测试随机数组的排序、升序数组的排序、降序数组的排序以及重复元素的数组排序。首先使用java.util.Arrays.sort建立一个评测基准,注意这里的时间单位是秒,这些绝对时间没有意义,我们关注的是相对值,因此这里我不会列出详细的评测程序:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| Arrays.sort | 136.293 | 0.548 | 0.524 | 26.822 |
qsort1对于输入做了假设,假设输入是随机的数组,如果排序已经排序的数组,qsort1马上退化到O(n^2)的复杂度,这是由于选定的pivot每次都会跟剩余的所有元素做比较。它跟Arrays.sort的比较:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| Arrays.sort | 136.293 | 0.548 | 0.524 | 26.822 |
| qsort1 | 134.475 | 48.498 | 141.968 | 45.244 |
果然,在排序已经排序的数组的时候,qsort的性能跟Arrays.sort的差距太大了。那么我们能做的第一个优化是什么?答案是将pivot的选择随机化,不再是固定选择左端点,而是利用随机数产生器选择一个有效的位置作为pivot,这就是qsort2:
// 0个或1个元素,返回
if (p >= r)
return ;
// 随机选择pivot
int i = p + rand.nextInt(r - p + 1 );
// 交换pivot和左端点
swap(a, p, i);
// 划分算法不变
int x = a[p];
int j = p;
for (i = p + 1 ; i <= r; i ++ ) {
// 小于pivot的放到左边
if (a[i] < x) {
swap(a, ++ j, i);
}
}
// 交换左端点和pivot位置
swap(a, p, j);
// 递归子序列
qsort2(a, p, j - 1 );
qsort2(a, j + 1 , r);
}
再次进行测试,查看qsort1和qsort2的对比:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| qsort1 | 134.475 | 48.498 | 141.968 | 45.244 |
| qsort2 | 227.87 | 19.009 | 18.597 | 74.639 |
从随机数组的排序来看,qsort2比之qsort1还有所下降,这主要是随机数产生器带来的消耗,但是在已经排序数组的排序上面,qsort2有很大进步,在有大量随机重复元素的数组排序上,qsort2却有所下降,主要消耗也是来自随机数产生器的影响。
更进一步的优化是在划分算法上,现在的划分算法只使用了一个索引i,i从左向右扫描,遇到比pivot小的,就跟从p+1开始的位置(由j索引进行递增标志)进行交换,最终的划分点落在了j,然后将pivot调换到j上,再递归排序左右两边子序列。一个更高效的划分过程是使用两个索引i和j,分别从左右两端进行扫描,i扫描到大于等于pivot的元素就停止,j扫描到小于等于pivot的元素也停止,交换两个元素,持续这个过程直到两个索引相遇,此时的pivot的位置就落在了j,然后交换pivot和j的位置,后续的工作没有不同,示意图


改进后的qsort3代码如下:
if (p >= r)
return ;
// 随机选
int i = p + rand.nextInt(r - p + 1 );
swap(a, p, i);
// 左索引i指向左端点
i = p;
// 右索引j初始指向右端点
int j = r + 1 ;
int x = a[p];
while ( true ) {
// 查找比x大于等于的位置
do {
i ++ ;
} while (i <= r && a[i] < x);
// 查找比x小于等于的位置
do {
j -- ;
} while (a[j] > x);
if (j < i)
break ;
// 交换a[i]和a[j]
swap(a, i, j);
}
swap(a, p, j);
qsort3(a, p, j - 1 );
qsort3(a, j + 1 , r);
}
这里要用do……while是因为i索引的初始位置是pivot值存储的左端点,而j所在初始位置是右端点之外,因此都需要先移动一个位置才是合法的。查看下qsort2和qsort3的基准测试对比:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| qsort2 | 227.87 | 19.009 | 18.597 | 74.639 |
| qsort3 | 229.44 | 18.696 | 18.507 | 43.428 |
可以看到qsort3的改进主要体现在了大量重复元素的数组的排序上,这是因为qsort3在遇到跟pivot相等的元素的时候,还是进行停止并交换,而非跳过;假设遇到相等的元素你不停止,那么这些相等的元素在下次划分的时候需要再次进行比较,比较次数退化到最差情况的O(n^2),而通过在遇到相等元素的时候停止并交换,尽管增加了交换的次数,但是却避免了所有元素相同情况下最差情况的发生。
改进到这里,回头看看我们做了什么,首先是使用随机挑选pivot替代固定选择,其次是改进了划分算法,从两端进行扫描替代单向查找,并仔细处理元素相同的情况。
插入排序的时间复杂度是O(N^2),但是在已经排序好的数组上面,插入排序的最佳情况是O(n),插入排序在小数组的排序上是非常高效的,这给我们一个提示,在快速排序递归的子序列,如果序列规模足够小,可以使用插入排序替代快速排序,因此可以在快排之前判断数组大小,如果小于一个阀值就使用插入排序,这就是qsort4:
if (p >= r)
return ;
// 在数组大小小于7的情况下使用快速排序
if (r - p + 1 < 7 ) {
for ( int i = p; i <= r; i ++ ) {
for ( int j = i; j > p && a[j - 1 ] > a[j]; j -- ) {
swap(a, j, j - 1 );
}
}
return ;
}
int i = p + rand.nextInt(r - p + 1 );
swap(a, p, i);
i = p;
int j = r + 1 ;
int x = a[p];
while ( true ) {
do {
i ++ ;
} while (i <= r && a[i] < x);
do {
j -- ;
} while (a[j] > x);
if (j < i)
break ;
swap(a, i, j);
}
swap(a, p, j);
qsort4(a, p, j - 1 );
qsort4(a, j + 1 , r);
}
如果数组大小小于7就使用插入排序,7这个数字完全是经验值。查看qsort3和qsort4的测试比较:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| qsort3 | 229.44 | 18.696 | 18.507 | 43.428 |
| qsort4 | 173.201 | 7.436 | 7.477 | 32.195 |
qsort4改进的效果非常明显,所有基准测试的结果都取得了明显的进步。qsort4还有一种变形,现在是在每个递归的子序列上进行插入排序,也可以换一种形式,当小于某个特定阀值的时候直接返回不进行任何排序,在递归返回之后,对整个数组进行一次插入排序,这个时候整个数组是由一个一个没有排序的子序列按照顺序组成的,因此插入排序可以很快地将整个数组排序,这个变形的qsort5跟qsort4没有本质上的不同:
if (p >= r)
return ;
// 递归子序列,并且数组大小小于7,直接返回
if (p != 0 && r!=(a.length-1) && r - p + 1 < 7 )
return ;
// 随机选
int i = p + rand.nextInt(r - p + 1 );
swap(a, p, i);
i = p;
int j = r + 1 ;
int x = a[p];
while ( true ) {
do {
i ++ ;
} while (i <= r && a[i] < x);
do {
j -- ;
} while (a[j] > x);
if (j < i)
break ;
swap(a, i, j);
}
swap(a, p, j);
qsort5(a, p, j - 1 );
qsort5(a, j + 1 , r);
// 最后对整个数组进行插入排序
if (p == 0 && r==a.length-1) {
for (i = 0 ; i <= r; i ++ ) {
for (j = i; j > 0 && a[j - 1 ] > a[j]; j -- ) {
swap(a, j, j - 1 );
}
}
return ;
}
}
基准测试的结果也证明了qsort4和qsort5是一样的:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| qsort4 | 173.201 | 7.436 | 7.477 | 32.195 |
| qsort5 | 175.031 | 7.324 | 7.453 | 32.322 |
现在,最大的开销还是随机数产生器选择pivot带来的开销,我们用随机数产生器来选择pivot,是希望pivot能尽量将数组划分得均匀一些,可以选择一个替代方案来替代随机数产生器来选择pivot,比如三数取中,通过对序列的first、middle和last做比较,选择三个数的中间大小的那一个做pivot,从概率上可以将比较次数下降到12/7 ln(n)。
median-of-three对小数组来说有很大的概率选择到一个比较好的pivot,但是对于大数组来说就不足以保证能够选择出一个好的pivot,因此还有个办法是所谓median-of-nine,这个怎么做呢?它是先从数组中分三次取样,每次取三个数,三个样品各取出中数,然后从这三个中数当中再取出一个中数作为pivot,也就是median-of-medians。取样也不是乱来,分别是在左端点、中点和右端点取样。什么时候采用median-of-nine去选择pivot,这里也有个数组大小的阀值,这个值也完全是经验值,设定在40,大小大于40的数组使用median-of-nine选择pivot,大小在7到40之间的数组使用median-of-three选择中数,大小等于7的数组直接选择中数,大小小于7的数组则直接使用插入排序,这就是改进后的qsort6,已经非常接近于Arrays.sort的实现:
if (p >= r)
return ;
// 在数组大小小于7的情况下使用快速排序
if (r - p + 1 < 7 ) {
for ( int i = p; i <= r; i ++ ) {
for ( int j = i; j > p && a[j - 1 ] > a[j]; j -- ) {
swap(a, j, j - 1 );
}
}
return ;
}
// 计算数组长度
int len = r - p + 1 ;
// 求出中点,大小等于7的数组直接选择中数
int m = p + (len >> 1 );
// 大小大于7
if (len > 7 ) {
int l = p;
int n = p + len - 1 ;
if (len > 40 ) { // 大数组,采用median-of-nine选择
int s = len / 8 ;
l = med3(a, l, l + s, l + 2 * s); // 取样左端点3个数并得出中数
m = med3(a, m - s, m, m + s); // 取样中点3个数并得出中数
n = med3(a, n - 2 * s, n - s, n); // 取样右端点3个数并得出中数
}
m = med3(a, l, m, n); // 取中数中的中数 ,median-of-three
}
// 交换pivot到左端点,后面的操作与qsort4相同
swap(a, p, m);
m = p;
int j = r + 1 ;
int x = a[p];
while ( true ) {
do {
m ++ ;
} while (m <= r && a[m] < x);
do {
j -- ;
} while (a[j] > x);
if (j < m)
break ;
swap(a, m, j);
}
swap(a, p, j);
qsort6(a, p, j - 1 );
qsort6(a, j + 1 , r);
}
其中的med3函数用于取三个数的中数:
return x[a] < x[b] ? (x[b] < x[c] ? b : x[a] < x[c] ? c : a)
: x[b] > x[c] ? b : x[a] > x[c] ? c : a;
}
运行基准测试跟qsort4进行比较:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| qsort4 | 173.201 | 7.436 | 7.477 | 32.195 |
| qsort6 | 143.264 | 0.54 | 0.836 | 27.311 |
观察到qsort6的改进也非常明显,消除了随机产生器带来的开销,取中数的时间复杂度在O(1)。此时qsort6跟Arrays.sort的差距已经非常小了。Array.sort所做的最后一个改进是针对划分算法,采用了所谓"split-end"的划分算法,这主要是为了针对equals的元素,降低equals元素参与递归的开销。我们原来的划分算法是分为两个区域加上一个pivot:

跟pivot equals的元素分散在左右两个子序列里,继续参与递归调用。当数组里的相同元素很多的时候,这个开销是不可忽视的,因此一个方案是将这些相同的元素集中存放到中间这个地方,不参与后续的递归处理,这就是"fat partition",此时是将数组划分为3个区域:小于pivot,等于pivot以及大于pivot:

但是Arrays.sort采用的却不是"fat partition",这是因为fat partition的实现比较复杂并且低效,Arrays.sort是将与pivot相同的元素划分到两端,也就是将数组分为了4个区域:
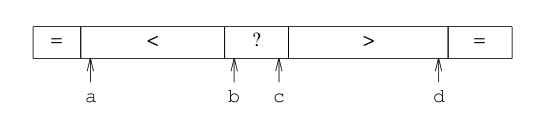

这就是split-end名称的由来,这个算法的实现可以跟qsort3的改进结合起来,同样是进行两端扫描,但是遇到equals的元素不是进行互换,而是各自交换到两端。当扫描结束,还要将两端这些跟pivot equals的元素交换到中间位置,不相同的元素交换到两端,左边仍然是比pivot小的,右边是比pivot大的,分别进行递归的快速排序处理,这样改进后的算法我们成为qsort7:
if (p >= r)
return ;
// 在数组大小小于7的情况下使用快速排序
if (r - p + 1 < 7 ) {
for ( int i = p; i <= r; i ++ ) {
for ( int j = i; j > p && x[j - 1 ] > x[j]; j -- ) {
swap(x, j, j - 1 );
}
}
return ;
}
// 选择中数,与qsort6相同。
int len = r - p + 1 ;
int m = p + (len >> 1 );
if (len > 7 ) {
int l = p;
int n = p + len - 1 ;
if (len > 40 ) {
int s = len / 8 ;
l = med3(x, l, l + s, l + 2 * s);
m = med3(x, m - s, m, m + s);
n = med3(x, n - 2 * s, n - s, n);
}
m = med3(x, l, m, n);
}
int v = x[m];
// a,b进行左端扫描,c,d进行右端扫描
int a = p, b = a, c = p + len - 1 , d = c;
while ( true ) {
// 尝试找到大于pivot的元素
while (b <= c && x[b] <= v) {
// 与pivot相同的交换到左端
if (x[b] == v)
swap(x, a ++ , b);
b ++ ;
}
// 尝试找到小于pivot的元素
while (c >= b && x[c] >= v) {
// 与pivot相同的交换到右端
if (x[c] == v)
swap(x, c, d -- );
c -- ;
}
if (b > c)
break ;
// 交换找到的元素
swap(x, b ++ , c -- );
}
// 将相同的元素交换到中间
int s, n = p + len;
s = Math.min(a - p, b - a);
vecswap(x, p, b - s, s);
s = Math.min(d - c, n - d - 1 );
vecswap(x, b, n - s, s);
// 递归调用子序列
if ((s = b - a) > 1 )
qsort7(x, p, s + p - 1 );
if ((s = d - c) > 1 )
qsort7(x, n - s, n - 1 );
}
其中用到了vecswap方法用于批量交换一批数据,将a位置(包括a)之后n个元素与b位置(包括b)之后n个元素进行交换:
private static void vecswap( int x[], int a, int b, int n) {
for ( int i = 0 ; i < n; i ++ , a ++ , b ++ )
swap(x, a, b);
}
主要是用于划分后将两端与pivot相同的元素交换到中间来。qsort7的实现跟Arrays.sort的实现是一样的,看看split-end划分带来的改进跟qsort6的对比:
| 算法 | 随机数组 | 升序数组 | 降序数组 | 重复数组 |
| qsort6 | 143.264 | 0.54 | 0.836 | 27.311 |
| qsort6 | 140.468 | 0.491 | 0.506 | 26.639 |
这个结果跟Arrays.sort保持一致。
最后给几张7个快排程序的在4种测试中的对比图

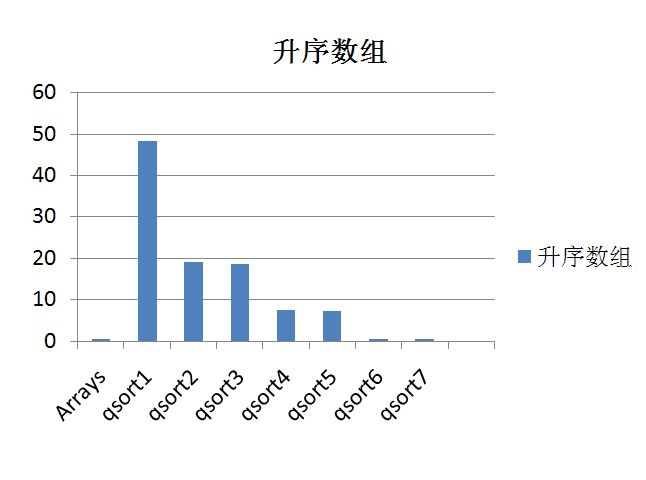
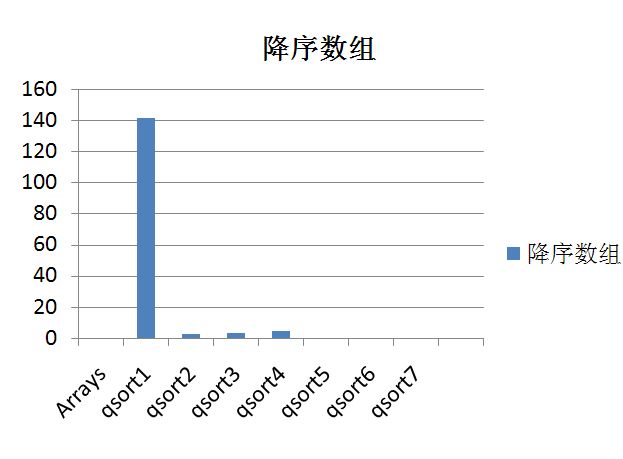
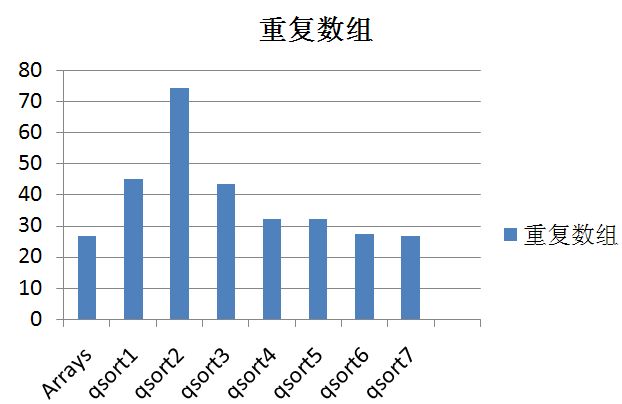
还可以做的优化:
1、内联swap和vecswap函数,循环中的swap调用可以展开。
2、改进插入排序,这是《编程珠玑》里提到的,减少取值次数。
int t = x[i];
int j = i;
for (; j > p && x[j - 1 ] > t; j -- ) {
x[j] = x[j - 1 ];
}
x[j] = t;
}
3、递归可以展开为循环,最后一个递归调用是尾递归调用,很容易展开为循环,左子序列的递归调用就没那么容易展开了。
4、尝试更多取样算法来提高选择好的pivot的概率。
5、并行处理子序列
快排的优化(简直神乎其神了!!!)相关推荐
- 基于单链表快排的优化算法
快排大法好,不说日常数据处理的巨大优势,面试时能手写快排更是装X一大利器. 不过传统的快排有一大缺陷:当出现大量相同值或数据已经有序时,由于对相同值的重复递归,排序效率会急剧降低乃至O(N^2). 为 ...
- 快速排序、快排的优化 及Java实现
一.快速排序的思想 选取一个比较的基准,将待排序数据分为独立的两个部分,左侧都是小于或等于基准,右侧都是大于或等于基准,然后分别对左侧部分和右侧部分重复前面的过程,也就是左侧部分又选择一个基准,又分为 ...
- 排序算法--快排的优化
排序算法–快排的优化 下面是我写的一种快排: #include <iostream> #include <stdlib.h>using namespace std;void P ...
- 深入了解快排 以及 优化
快排 文章目录 快排 一.挖坑法 1.1 性能 二.Hoare法: 三.三数取中法 四. 随机选择 五.直接插入排序优化 六.非递归快排
- 快速排序的三种方式以及快排的优化
一.快速排序的基本思想 关于快速排序,它的基本思想就是选取一个基准,一趟排序确定两个区间,一个区间全部比基准值小,另一个区间全部比基准值大,接着再选取一个基准值来进行排序,以此类推,最后得到一个有序的 ...
- 快排的优化策略(3种快排4种优化)
转自:http://blog.csdn.net/hacker00011000/article/details/52176100 1.快速排序的基本思想: 快速排序使用分治的思想,通过一趟排序将待排序列 ...
- 快排及其优化(C语言)
快排的普通写法(递归) 时间复杂度(平均情况):nlog2(n) int PartSort(int*arr,int first,int end) //分步排序函数 {int tmp=arr[first ...
- 八大排序算法之快速排序(下篇)(快排的优化+非递归快排的实现)
目录 一.前言 1.快速排序的实现: 快速排序的单趟排序(排升序)(快慢指针法实现): 2.未经优化的快排的缺陷 二.快速排序的优化 1.三数取中优化 优化思路: 2. 小区间插入排序优化 小区间插 ...
- 经典排序之快排及其优化
基础快排: int __partition(int arr[], int l, int r) {int v = arr[l];int j = l ;for (int i = l + 1; i < ...
最新文章
- Win2D 官方文章系列翻译 - 避免内存泄漏
- windows php exec()不生效问题
- 轻量级消息队列RedisQueue
- 第三十二期:MySQL常见的图形化工具
- vs2010 mysql linq to sql 系列_LINQ to SQL 系列 如何使用LINQ to SQL插入、修改、删除数据...
- IBM将发布以固态硬盘为基础的全企业系统
- 知乎热榜:如何看待华为天才少年年薪201万?
- linux如何手动释放内存吗,Linux如何手动清理内存中cache信息
- WinAppDriver UI自动化测试环境搭建
- 大厂面试为什么总考算法
- matlab坐标轴为指数,matlab画图设置中,如何把坐标改称指数坐标以及修改范围?...
- android P adb shell dumpsys battery 使用
- 制定小目标的软件APP哪款好
- 一起来学Kotlin:概念:7. Kotlin 函数介绍:扩展函数,中缀函数,运算符函数,带有varrag输入的函数
- 【华为OD机试 2023】 最多获得的短信条数/云短信平台优惠活动(C++ Java JavaScript Python)
- 关联规则 置信度定义
- 现实总比相像中好些——西单图书大厦活动侧记
- 一篇文章理解外汇知识
- Android点击文字编辑进行缩放、移动和改变字体、颜色的实现
- 秋招迟迟没消息?免笔试直通网易游戏的offer在这里!