【图普科技】边界框的数据增强:对目标检测图像变换的再思考(一)
【本文由图普科技编译】
当谈到深度学习任务的表现时,毋庸置疑,数据越多越好。然而,我们拥有的数据可能是有限的。数据增强是通过人为扩充数据集来解决数据短缺问题的一种方法。实际上,该技术已被证明非常成功,因而也成为深度学习系统的主要内容之一。
数据增强为什么有用?
理解数据增强工作原理的一种非常直接的方法是将其视为人为扩充数据集的一种方式。正如深度学习的其他应用一样,数据越多越好。
另一种理解数据增强的方法是将其视为我们数据集的附加噪声,尤其是在在线数据增强,或是随机增强将用于训练循环的每个数据样本时。

左:原始图像,右:增强的图像。
由于应用了随机数据增强技术,神经网络每次看到的相同图像时都会发现在某方面存在一定差异。这种差异可以看作是添加到我们的数据样本中的噪声,这些噪声将迫使神经网络学习广义特征,而不是过度拟合数据集。
GitHub Repo
本文中的所有内容和使用的数据增强库都可以在以下Github Repo中找到。
https://github.com/Paperspace/DataAugmentationForObjectDetection
文档
可以通过在浏览器中打开 docs/build/html/index.html或在此链接中找到此项目的文档。
本系列包括4个部分。
• 第1部分:基本设计和水平翻转
• 第2部分:缩放和平移
• 第3部分:旋转和裁剪
• 第4部分:所有技术整合
目标检测的边界框
目前,许多深度学习库如torchvision,keras和github上的专用库为分类训练任务提供了数据增强支持。但是,目前仍然缺少对目标检测任务的数据增强支持。例如,进行分类任务时,水平翻转以增强图像将类似于上面的图像。
然而,对目标检测任务执行相同的增强技术还需要更新边界框,如下图。

水平翻转时边界框的变化
这种数据增强方式,或者说是用于目标检测的主要数据增强技术,需要我们更新边界框,这些我们将在这篇文章中介绍。具体来说,以下是我们将要介绍的增强技术的确切列表。
- 水平翻转(如上图所示)
- 缩放和平移

- 旋转

- 裁剪

- 调整神经网络输入的尺寸
技术实现过程
我们将基于Numpy和OpenCV建立我们的小型数据增强库。
我们将增强方法定义为类,可以调用类的实例来执行增强。我们将定义一种统一的方法来定义这些类,以便您也可以编写自己的数据增强方法。
我们还将定义一种数据增强方法,将以上的数据增强方法结合起来,以便应用于同一序列之中。
对于每种数据增强,我们将定义它的两个变体,一个是随机的,一个是确定性的。对于随机的变体,增强是随机发生的,而在确定性的变体中,增强的参数(如要旋转的角度)等是固定的。
数据增强示例:水平翻转
本文将概述实现数据增强的一般方法。我们还将介绍一些效用函数,这些函数将帮助我们将检测和其他一些过程可视化。那么,让我们开始吧。
标注存储格式
针对每个图像,我们将边界框标注存储在具有N行和5列的numpy数组中。在这里,N表示图像中目标的数量,而五列分别代表:
- 左上角的x坐标
- 左上角的y坐标
- 右下角的x坐标
- 右下角的y坐标
- 目标的类
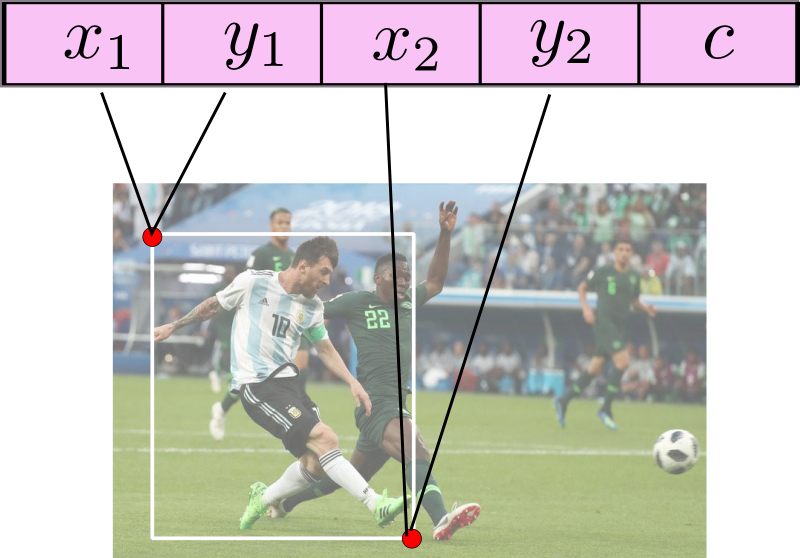
存储边界框标注的格式
有很多数据集和标注工具可以将标注存储为其他格式存储,因此,如何将数据标注的存储格式转换为上述格式,我在这里就不详述了。
同时,出于示范目的,我们将使用梅西与尼日利亚队比赛时进球的图像,如上所示。
文件组织
我们将代码保存在2个文件中,data_aug.py 和 bbox_util.py。第一个文件包含实现增强的代码,而第二个文件则包含辅助函数的代码。
这两个文件都将存储于 data_aug 文件夹中
我们假定你必须在训练循环中必须使用这些数据增强。我会介绍如何提取你所需的图像,并确保标注的格式正确。
但是,为了更简单明了,我们一次只会使用一张图像。您可以轻松地在训练循环时内部变换此代码,或者使用数据提取函数来扩展功能。
复制github repo文件夹中包含训练代码的文件,或者需要进行增强的文件。
git clone https://github.com/Paperspace/DataAugmentationForObjectDetection
随机水平翻转
首先,我们必须导入所有必要的东西,并确保添加了路径,即使我们是从包含文件的文件夹外部调用的函数。将以下代码添加到文件 data_aug.py 中
import random
import numpy as np
import cv2
import matplotlib.pyplot as plt
import sys
import oslib_path = os.path.join(os.path.realpath("."), "data_aug")
sys.path.append(lib_path)此处的数据增强是通过随机水平翻转方法来实现的,以一定的概率p来水平翻转图像。
我们首先使用类的 __ init __ 方法。init方法包含增强参数。对于水平翻转增强方法,参数指的是每个图像被翻转的概率。对于像旋转这样的其他增强方法,参数可以是目标旋转的角度等。
class RandomHorizontalFlip(object):"""Randomly horizontally flips the Image with the probability *p*Parameters----------p: floatThe probability with which the image is flippedReturns-------numpy.ndaarayFlipped image in the numpy format of shape `HxWxC`numpy.ndarrayTranformed bounding box co-ordinates of the format `n x 4` where n is number of bounding boxes and 4 represents `x1,y1,x2,y2` of the box"""def __init__(self, p=0.5):self.p = p
函数的docstring以Numpy 的docstring格式编写。这对于使用Sphinx生成文档很有用。
每个函数的 __ init __ 方法用于定义增强方法的所有参数。但是,增强方法的实际逻辑是在 __ call __ 函数中定义。
当从类实例调用时,call函数有两个参数,img和bboxes。其中img是包含像素值的OpenCV numpy数组,bboxes 是包含边界框标注的numpy数组。
__ call __ 函数也返回相同的参数,这有助于我们将一系列增强方法链接在一起以应用于序列中。
def __call__(self, img, bboxes):img_center = np.array(img.shape[:2])[::-1]/2img_center = np.hstack((img_center, img_center))if random.random() < self.p:img = img[:,::-1,:]bboxes[:,[0,2]] += 2*(img_center[[0,2]] - bboxes[:,[0,2]])box_w = abs(bboxes[:,0] - bboxes[:,2])bboxes[:,0] -= box_wbboxes[:,2] += box_wreturn img, bboxes让我们一点一点地剖析这部分内容。
在水平翻转中,我们围绕穿过其中心的垂直线旋转图像。
然后可以将每个角的新坐标描述为穿过图像中心的垂直线中对应角的镜像。从数学的角度来讲,穿过中心的垂直线将是原始角和新的、变换过的角的连接线的垂直平分线。
要更好地了解这一过程,请观察以下图像。变换图像的右半部分的像素和原始图像的左半部分的像素是彼此关于中心线的镜像。

上述内容是通过以下代码完成的。
img_center = np.array(img.shape[:2])[::-1]/2
img_center = np.hstack((img_center, img_center))
if random.random() < self.p:img = img[:,::-1,:]bboxes[:,[0,2]] += 2*(img_center[[0,2]] - bboxes[:,[0,2]])注意,img = img[:,::-1,:] 这一行基本上采用包含图像的数组并反转第一维中的元素,或者说是存储像素值x坐标的维数。
但是,必须注意左上角的镜像是更新后边界框的右上角。实际上,结果坐标是边界框的右上角和左下角坐标。但是,我们需要的是原始图像的左上角和右下角格式。

我们的代码的副作用
以下代码负责实现这种转换。
box_w = abs(bboxes[:,0] - bboxes[:,2])
bboxes[:,0] -= box_w
bboxes[:,2] += box_w我们最终返回图像和包含边界框的数组。
确定性的水平翻转
上面的代码以概率p 随机地实现了图像变换。但是,如果我们想构建一个确定性的图像变换,我们只需简单地将传递给参数 p 的值设置为1。或者我们可以另外定义一个类,该类根本不包含参数 p ,并根据下面代码实现 __ call __ 函数。
def __call__(self, img, bboxes):img_center = np.array(img.shape[:2])[::-1]/2img_center = np.hstack((img_center, img_center))img = img[:,::-1,:]bboxes[:,[0,2]] += 2*(img_center[[0,2]] - bboxes[:,[0,2]])box_w = abs(bboxes[:,0] - bboxes[:,2])bboxes[:,0] -= box_wbboxes[:,2] += box_wreturn img, bboxes
实际操作表现
现在,让我们假定您必须使用水平翻转方法来实现图像变换。我们将在一张图片上使用它,但您可以在任何数量的图像上使用它。首先,我们创建一个文件 test.py 。我们首先导入所有需要的东西:
from data_aug.data_aug import *
import cv2
import pickle as pkl
import numpy as np
import matplotlib.pyplot as plt
然后,我们导入图像并加载标注:
img = cv2.imread("messi.jpg")[:,:,::-1] #OpenCV uses BGR channels
bboxes = pkl.load(open("messi_ann.pkl", "rb"))#print(bboxes) #visual inspection为了看看我们的增强方法是否真的有效,我们定义了一个辅助函数 draw_rect ,它接收 img 和 bboxes 并返回一个numpy图像数组,在该图像上绘制有边界框。
让我们创建一个文件 bbox_utils.py 并导入需要的东西。
import cv2
import numpy as np
现在,我们定义函数 draw_rect
def draw_rect(im, cords, color = None):"""Draw the rectangle on the imageParameters----------im : numpy.ndarraynumpy image cords: numpy.ndarrayNumpy array containing bounding boxes of shape `N X 4` where N is the number of bounding boxes and the bounding boxes are represented in theformat `x1 y1 x2 y2`Returns-------numpy.ndarraynumpy image with bounding boxes drawn on it"""im = im.copy()cords = cords.reshape(-1,4)if not color:color = [255,255,255]for cord in cords:pt1, pt2 = (cord[0], cord[1]) , (cord[2], cord[3])pt1 = int(pt1[0]), int(pt1[1])pt2 = int(pt2[0]), int(pt2[1])im = cv2.rectangle(im.copy(), pt1, pt2, color, int(max(im.shape[:2])/200))
return im完成后,让我们回到 test.py 文件,并绘制原始边界框。
plt.imshow(draw_rect(img, bboxes))
结果如下所示:
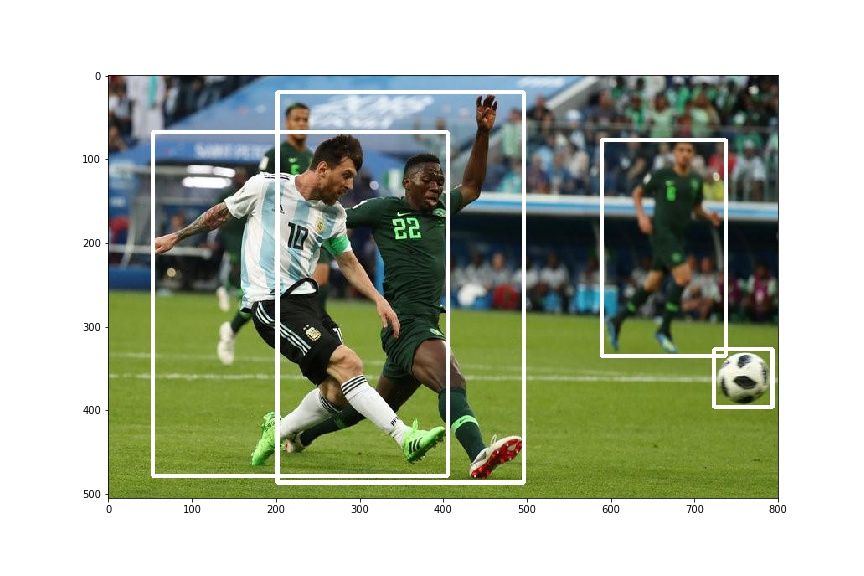
让我们看看我们变换的效果。
hor_flip = RandomHorizontalFlip(1)
img, bboxes = hor_flip(img, bboxes)
plt.imshow(draw_rect(img, bboxes))你应该得到以下类似图像:
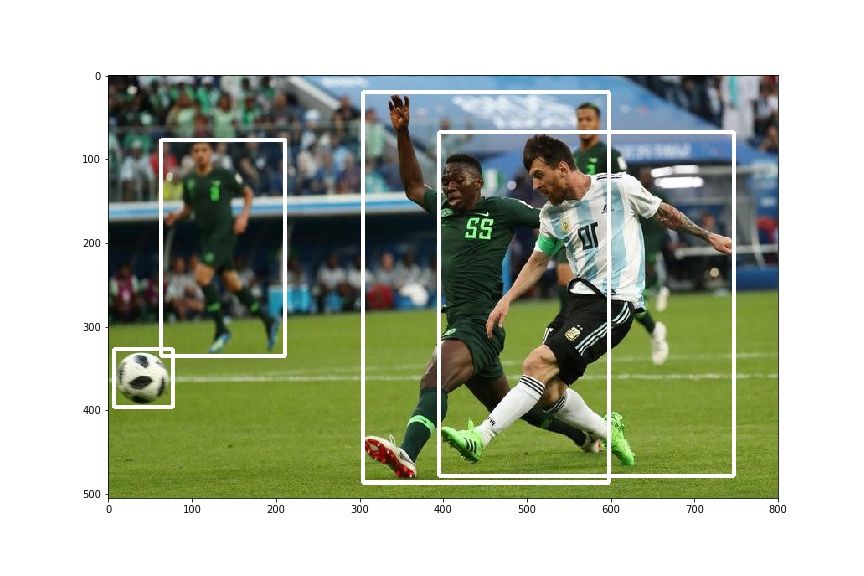
总结
- 边界框标注应存储在大小为N x 5的numpy数组中,其中N是目标的数量,每个框由具有5个属性的行表示; 左上角的坐标,右下角的坐标和目标的类。
- 每种数据增强方法都定义为一个类,其中
__ init __方法用于定义增强参数,而__ call __方法描述增强方法的实际逻辑。它需要两个参数,图像img和边界框标注bboxes并返回转换后的值。
这是本文的内容。在下一篇文章中,我们将讨论缩放和平移增强方法。考虑到这些方法有更多参数(缩放和平移因子),它们的变换不仅更加复杂,同时还带来了一些我们在水平翻转变换中无需处理的挑战,例如在增强之后如果边界框的部分在图像之外,那么是否需保留该边界框呢?
【图普科技】边界框的数据增强:对目标检测图像变换的再思考(一)相关推荐
- 【图普科技】边界框的数据增强(二) ——缩放和平移
本文由[图普科技]编译. 这是我们根据目标检测任务调整图像增强技术系列文章的第二部分.在这一部分中,我们将介绍如何实现缩放和平移的数据增强技术, 以及图像增强后,如果出现边界框在图像区域之外的情况该如 ...
- 图普科技工程师:Mask R-CNN的理论创新会带来怎样的可能性?
melmcgowan 上周,雷锋网 AI 科技评论报道了 Facebook 实验室出炉的新论文<Mask R-CNN>,第一作者何恺明带领团队提出了一种名为「Mask R-CNN」的目标实 ...
- 如何基于深度学习实现商品识别技术|图普科技
目前实时客流检测.商品识别.货架识别等人工智能技术可以帮助越来越多的零售门店实现智慧零售数字化转型.随着人工智能技术的发展,图普科技在深度学习在实现商品识别的应用上越发成熟,从技术层面来说,具体包含以 ...
- 刷新世界纪录,图普科技夺MegaFace百万级人脸识别冠军
近期,图普科技在国际权威海量人脸识别数据库MegaFace中,以99.087%的最新成绩在百万级别人脸识别测试中拔得头筹,参加这项测试的还有来自Google.微软中国.百度.腾讯等公司的AI团队. 数 ...
- 国内主流小视频平台的审核机制与智能审核应用|图普科技
近年来随着我国移动短视频在各大平台的上线,相关管理部门对短视频市场的监管力度随着加大,陆续出台了关于移动短视频平台的内容管控的规范细则,包括但不限于:所有移动短视频平台的生产内容需经过内容审核合格后播 ...
- 图普科技:国内最早将人工智能深度学习技术应用于互联网内容审核的企业之一 | 百万人学AI评选
2020 无疑是特殊的一年,而 AI 在开年的这场"战疫"中表现出了惊人的力量.站在"新十年"的起点上,CSDN[百万人学AI]评选活动正式启动.本届评选活动在 ...
- 门店客流量如何统计?门店客流分析的重要性|图普科技智慧零售
客流量指的就是单位时间内进入店铺.超市某个场所的人数,是能够显示出这个场所的热门程度的重要数据指标,经营者可以依据此调整自己经营策略,以实现店铺的的经营效益最大化. 客流量统计对于零售行业来说是非常重 ...
- 「镁客·请讲」图普科技李明强:“鉴别违规内容”标签不会带来副作用,是实力受认可的证明...
李明强表示,2017年的计算机视觉市场是走向务实的,而2018年的市场将进入洗牌期. 经过去年的融资热潮,计算机视觉成为了AI行业的年度热词之一.同时,我们可以看到,在一些细分领域,有些企业已经做到了 ...
- 图普科技AI智能赋能审核|数字出版内容审核发展趋势的显现
长期以来,内容风险管控都是传媒行业实现可持续发展的必要条件.在大数据.云计算.人工智能.5G蓬勃发展的时代,相对于传统图书出版行业,数字出版作品的内容把关面临诸多挑战. 富媒体:Rich Media的 ...
最新文章
- 轻松理解正向代理与反向代理
- 浙大pat1009题解
- 数据结构——树、森林和二叉树之间的转换
- [Python unittest] 3-Organizing test code
- 如何将bing搜索页面以HTML Mashup的方式嵌入到SAP C4C页面
- .NET Conf 2021 回顾
- 和付费网盘说再见,自己起个网盘不香吗?| Java 开源项目
- html页面的ajax请求,【提问】ajax请求返回整个html页面
- 费波纳奇数c语言,费波纳切数列用C语言怎么编程
- 2018-2-13-win10-uwp-如何让WebView标识win10手机
- [转载]Coursera课程批量下载(保持资源原目录结构)
- UCOSII实时操作系统启动原理和理解
- 在centos官网下载系统镜像完整教程
- 对现有计算机应用的建议,对计算机课程的建议
- w ndoWs10开机时间长,详细教你解决win10开机慢
- Node.js全局对象
- 十分钟搞定SSD1963液晶屏驱动
- java 山洞过火车 java,我的世界稀有PE种子:罕见双层末地门!
- 南航大二学生两年手搓火箭成功发射,全靠业余时间上网自学,稚晖君点赞
- 关于BAPI_CONTRACT_CREATEFROMDATA涉及使用价格