数据结构之线性表的查找
目录
查找的基本概念
线性表的查找
顺序查找(线性查找)
折半查找(二分或对分查找)
折半查找的性能分析——判定树
分块查找(索引顺序查找)
分块查找性能分析
三种方法比较
查找的基本概念
查找表是由同一类型的数据元素(或记录)构成的集合。由于“集合”中的数据元素之间存在着松散的关系(即无严格的前驱与后继关系),因此查找表是一种应用灵便的结构。
其中“灵便”是指:我们可以根据需要,将这些数据元素存成线性表或树表等。
- 什么是查找?
查找就是根据某个给定的值,在查找表中查找一个其关键字等于给定值的数据元素(或记录)。
- 关键字(用来标识一个数据元素(或记录)的某个数据项的值)
关键字又分为主关键字和次关键字。
- 主关键字:可唯一地标识一个记录的关键字。(如查找张三的语文成绩,那么在成绩表中可以查找到一个唯一确定的值)
- 次关键字:用以识别若干记录的关键字。(如查找语文成绩为91分的人,那么就有可能在成绩表中查找到许多个语文成绩为91分的学生。)
- 如何确定查找是否成功?
若在查找表中存在一个与给定值相等的数据元素(或记录),则为“查找成功”。查找结果给出整个记录的信息,或指示该记录在查找表中的位置;反之,“查找不成功”,查找结果给出“空记录”或“空指针”。
- 查找的目的
- 查询某个“特定”数据元素是否在查找表中。
- 检索某个“特定”数据元素的各种属性。(如查找成绩表中张三的各科成绩)
- 在查找表中插入一个数据元素。
- 在查找表中删除某个数据元素。
- 查找表的分类
- 静态查找表:仅作“查询”(检索)操作的查找表。
- 动态查找表:在“查询”完之后,还要作“插入”或“删除”操作的查找表。
- 怎样评价查找算法?
查找算法的评价指标:平均查找长度(ASL),即关键字的平均比较次数。
ASL=Average Search Length
ASL=
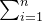
(关键字比较次数的期望值)
n:表中记录的个数
pi:查找第i个记录的概率(通常认为pi= 1/n)
ci:找到第i个记录所需要的比较次数
线性表的查找
顺序查找(线性查找)
应用范围:顺序表或线性链表表示的静态查找表;表内元素之间无序
例如:表ST中有12为元素,其中下标为0的位置不存放元素。 ST.length=11
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 5 | 9 | 56 | 32 | 74 | 11 | 45 | 30 | 75 | 46 | 25 | 88 |
在查找此表时,有两种方法:第一种,从前往后找;第二种,从后往前找。
在顺序表ST中查找值为11的数据元素,查到了,返回6;若在表中查找10,未找到,返回0。
改进:把待查关键字key存入表头(即设立“哨兵”),可以免去查找过程中每一步都要检测是否查找完毕,加快速度。当ST.length较大时,此改进能使进行一次查找所需的平均时间几乎减少一半。
/*数据元素类型定义*/
typedef struct {KeyType key; //关键字域…… ; //其他域
}ElemType;typedef struct { //顺序表结构类型定义ElemType *R; //表基址int length; //表长
}SSTable; //Sequential Search Table
SSTable ST; //定义顺序表ST/*算法(设有哨兵)*/
int Search(SSTable ST,KeyType key)
{ST.R[0].key=key;int i;for(i=ST.length;ST.R[i].key!=key;i--);return i;
}顺序查找的比较次数与key位置有关:
查找第i个元素,需要比较n+1-i次;查找失败,需要比较n+1次。
- 时间复杂度:O(n)
查找成功时的平均查找长度:设表中各个记录查找效率相等,ASL=(n+1)/2。
- 空间复杂度:需要一个辅助空间——O(1)
顺序查找的优缺点:
优点:算法简单,逻辑次序无要求,且适用于不同的存储结构。
缺点:ASL太长,时间效率太低。
折半查找(二分或对分查找)
折半查找将每次待查记录所在的区间缩小一半。进行折半查找的要求是顺序表中的记录之间是有序的。(如:递增序列或递减序列)
查找过程:(查找32)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 5 | 9 | 13 | 32 | 39 | 40 | 45 | 50 | 75 | 79 | 82 | 88 |
| | |
low mid high
mid=(low+high)/2; 当key(32)<mid上的值,high移动到mid的前一位:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 5 | 9 | 13 | 32 | 39 | 40 | 45 | 50 | 75 | 79 | 82 | 88 |
| | |
low high mid
再进行mid=(low+high)/2,mid移动到下标为3的位置:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 5 | 9 | 13 | 32 | 39 | 40 | 45 | 50 | 75 | 79 | 82 | 88 |
| | |
low mid high
此时比较关键字与mid位置上的值,发现key>mid,则low的位置移动到mid的后一位,即low=mid+1:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 5 | 9 | 13 | 32 | 39 | 40 | 45 | 50 | 75 | 79 | 82 | 88 |
| | |
mid low high
再进行mid=(low+high)/2,mid的值为4:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 5 | 9 | 13 | 32 | 39 | 40 | 45 | 50 | 75 | 79 | 82 | 88 |
| |
low high
|
mid
此时比较关键字与mid位置上的值,发现他俩相等,即找到。
若查找的是30:此时的mid为4,low为4,high为5, 此时的mid位置上的值与关键字的值仍不相等,并且比mid位置上的值小,则high=mid-1:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 5 | 9 | 13 | 32 | 39 | 40 | 45 | 50 | 75 | 79 | 82 | 88 |
| |
high low
|
mid
此时,high<low,查找结束。
/*非递归算法*/
int Search(SSTable ST,KeyType key){int low,high,mid; low=1;high=ST.length; //设置区间初值while(low<=high){mid=(low+high)/2; //计算mid的值if(ST,R[mid].key==key) return mid; //找到待查找的元素else if(key<ST.R[mid].key) //缩小查找区间high=mid+1; //继续在前半区查找else low=mid+1; //继续在后半区查找}retur 0; //顺序表中未找到待查找的元素
}/*递归算法*/
int search(SSTable ST,KeyType key,int low,int high)
{if(low>high) return 0; //查找不到时返回0 mid=(low+high)/2;else if(ST.R[mid].key==key) return mid;else if(ST.R[mid].key>key)search(ST,key,low,mid-1); //递归,在前半区进行查找else search(ST,key,mid+1,low); //递归,在后半区进行查找} 折半查找的性能分析——判定树
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 5 | 9 | 13 | 32 | 39 | 40 | 45 | 50 | 75 | 79 | 82 |
3 4 2 3 4 1 3 4 2 3 4
上面一行数字为查找各位置元素需比较次数。
若查找的是6号位置的元素,则该元素只需要比较1次便可找到,对应在二叉判定树的第一层;
3、9号位置的元素需要比较二次才能找到,对应在二叉判定树的第二层……
上面的表格对应的二叉判定树为:
![]()
树中结点内的数字代表表中记录的位置。
查找成功:
- 比较次数=路径上的结点数(从根结点开始)=结点的层数
- 比较次数<=树的深度:(
)+1
查找不成功时:比较次数<=()+1
上图二叉判定树对应的查找成功时的平均查找长度:
ASL=(1*1+2*2+3*4+4*4)/11=3
平均查找长度ASL(成功时):
设表长为n,n=-1,(h表示判定树为深度=h的满二叉树),h=
,且表中每个记录的查找概率相等,都为1/n,则:
ASL约等于 (n>50)
折半查找的优缺点:
优点:效率比顺序查找高。
缺点:只适用与有序表,并且是顺序存储结构,对于线性链表无效。若想对表中的元素进行插入或者删除时,需要移动大量的元素。
分块查找(索引顺序查找)
分块查找是在查找时,先确定需要查找的元素所在哪一块,然后进入到那一块区域中进行查找,这样查找也大大缩小了需要查找的范围。
分块查找,又叫索引顺序表的查找。
应用分块查找时,需要满足:
- 将表分为几块,表中的内容既可以是有序的,也可以是无序的,但是要求分块有序(块与块的排序是有序的):例如,将一个表分为1,2两块,则第2块中的所有记录的关键字的值均大于第1块中的最大关键字的值。
- 建立“索引表”(每个结点含有最大关键字域和指向本块第一个结点的指针,且按关键字有序)。
![]()
查找过程:先确定待查记录所在块(顺序或者折半查找),再在块内查找(顺序查找;若块内记录也是有序的,也可用折半查找)。
分块查找性能分析:
分块查找的ASL是由两部分构成:
- 对索引表查找的ASL
- 对块内查找的ASL
索引表是有序的,它的平均查找长度按照二分法来算。
ASL=,n是指线性表中的元素个数,s是指每块内部的元素个数,n/s即块的数目。s/2是在块内的平均查找长度。
<= ASL <= (n+1)/2 ,分块查找的ASL比二分查找的要大,比顺序查找的要小,且更接近与二分查找的ASL。
分块查找的优缺点:
优点:插入和删除比较容易,无需将元素进行大量的移动。
缺点:要增加一个索引表的存储空间并对初始索引表进行排序运算。
适用情况:适用于线性表既要快速查找又经常动态变化。
三种方法比较
| 顺序查找 | 折半查找 | 分块查找 | |
| ASL | 最大 | 最小 | 中等 |
| 表结构 | 有序表、无序表 | 有序表 | 分块有序 |
| 存储结构 | 顺序表、线性链表 | 顺序表 | 顺序表、线性链表 |
欢迎大家的指正。
数据结构之线性表的查找相关推荐
- 【数据结构和算法笔记】线性表的查找(平均查找长度,二分法,判定树)
查找: 给定一个值k,在含有n个元素的表中找出关键字等于k的元素,若找到,则查找成功,否则,查找失败 查找前首先确定(1)存放数据的数据结构是什么(2)元素是否有序 动态查找表:查找的同时做修改操作( ...
- 数据结构-线性表的查找
文章目录 查找(一) 9.1 查找基本概念 9.2 线性表的查找 9.2.1 顺序查找 9.2.2 折半查找 9.2.3 索引存储结构 参考资料 本篇文章用于记录,不适合参考. 查找(一) 9.1 查 ...
- 用标准C语言初始化线性表,C语言数据结构-顺序线性表的实现-初始化、销毁、长度、查找、前驱、后继、插入、删除、显示操作...
1.数据结构-顺序线性表的实现-C语言 #define MAXSIZE 100 //结构体定义 typedef struct { int *elem; //基地址 int length; //结构体当 ...
- 数据结构——线性表的查找
查找 查找的概念 线性表的查找 顺序查找(线性查找) 折半查找(二分或对分查找) 分块查找 查找的概念 主关键字:可唯一地标识一个记录的关键字就是主关键字 次关键字:用以识别若干记录的关键字就是次关键 ...
- 数据结构与算法--线性表的查找
一.查找的基本概念 1) 查找表: 查找表是由同一类型的数据元素(或记录)构成的集合 2) 由于集合中的数据元素之间存在着松散的关系,因此查找表是一种应用灵便的结构 3) 查找: 根据 ...
- 【Java数据结构】线性表
线性表 线性表是最基本.最简单.也是最常用的一种数据结构. 线性表中数据元素之间的关系是一对一的关系,即除了第一个和最后一个数据元素之外,其它数据元素都是首尾相接的(注意,这句话只适用大部分线性表,而 ...
- step3 . day2 数据结构之线性表链表
今天继续学习数据结构的线性表部分,从基础的顺序表到链表,类比写了一些调用函数,完成了表的增删改查排序等问题. 尤其是链表的排序,费了很大的心思终于捋顺写出来了,小有成就感,而且代码一次通过率越来越高, ...
- 数据结构之线性表(附代码)
数据结构 之 线性表(附代码) 线性表思维导图: 线性表定义(逻辑结构): 一.顺序表 1.顺序表思维导图: 2.顺序表的逻辑结构: 3.顺序表基本操作的功能实现: 1.线性表的静态定义: 2.线性表 ...
- 用Java描述数据结构之线性表的链式存储(链表),模拟LinkedList实现
上一篇介绍了顺序表:用Java描述数据结构之线性表的顺序存储(顺序表),ArrayList及其方法的介绍 上一篇博客中说明了什么是线性表--线性表就是一个个数据元素逻辑上以一对一的相邻关系(但是在物理 ...
最新文章
- python 面板数据分析_科学网—Python中的结构化数据分析利器-Pandas简介 - 郑俊娟的博文...
- 来!一起捋一捋机器学习分类算法
- 谭浩强C程序设计第四版答案
- java链表寻找中间节点
- js返回上一页实用的
- mysql 2进制 安装_mysql二进制安装
- 【JavaScript】js数组与字符串的相互转换
- Android 中 Activity 的生命周期
- SAP Spartacus lazy load module 里包含了被其他 Component 静态引用的组件该怎么办
- java 对线程进行事务控制_Java 多线程事务回滚 ——多线程插入数据库时事务控制...
- Maven 无法下载Oracle 驱动解决
- ext2 无损升级 ext3、ext4
- 基于内外环PD控制的四旋翼飞行器控制系统simulink仿真
- 轻型机械臂模块关节机械设计方案
- python里使用正则表达式搜索单词
- spring 代码执行 (CVE-2018-1273)
- 第7章 网站前台-吐槽与问答
- spark sql uv_使用Spark Streaming SQL进行PV/UV统计-阿里云开发者社区
- 学海灯塔新增学习笔记上传功能
- 【SQL Server系列】_01数据库系统概述