Python爬虫入门教程 9-100 河北阳光理政投诉板块 1
1.河北阳光理政投诉板块-写在前面
之前几篇文章都是在写图片相关的爬虫,今天写个留言板爬出,为另一套数据分析案例的教程做做准备,作为一个河北人,遵纪守法,有事投诉是必备的技能,那么咱看看我们大河北人都因为什么投诉过呢?
今天要爬取的网站地址 http://yglz.tousu.hebnews.cn/l-1001-5-,一遍爬取一遍嘀咕,别因为爬这个网站在去喝茶,再次声明,学习目的,切勿把人家网站爬瘫痪了。

2.河北阳光理政投诉板块-开始撸代码
今天再次尝试使用一个新的模块 lxml ,它可以配合xpath快速解析HTML文档,官网网站 https://lxml.de/index.html
利用pip安装lxml,如果安装失败,可以在搜索引擎多搜搜,内容很多,100%有解决方案。
pip install lxml
废话不多说,直接通过requests模块获取百度首页,然后用lxml进行解析
import requests
from lxml import etree # 从lxml中导入etreeresponse = requests.get("http://www.baidu.com")
html = response.content.decode("utf-8")
tree=etree.HTML(html) # 解析htmlprint(tree)
当你打印的内容为下图所示,你就接近成功了!

下面就是 配合xpath 语法获取网页元素了,关于xpath 这个你也可以自行去学习,非常简单,搜索一下全都是资料,咱就不讲了。
通过xpath我们进行下一步的操作,代码注释可以多看一下。
tree=etree.HTML(html) # 解析html
hrefs = tree.xpath('//a') #通过xpath获取所有的a元素
# 注意网页中有很多的a标签,所以获取到的是一个数组,那么我们需要用循环进行操作
for href in hrefs:print(href)打印结果如下
<Element a at 0x1cf64252408>
<Element a at 0x1cf642523c8>
<Element a at 0x1cf64252288>
<Element a at 0x1cf64252308>
<Element a at 0x1cf64285708>
<Element a at 0x1cf642aa108>
<Element a at 0x1cf642aa0c8>
<Element a at 0x1cf642aa148>
<Element a at 0x1cf642aa048>
<Element a at 0x1cf64285848>
<Element a at 0x1cf642aa188>在使用xpath配合lxml中,记住只要输出上述内容,就代表获取到东西了,当然这个不一定是你需要的,不过代码至少是没有错误的。
继续编写代码
# 注意网页中有很多的a标签,所以获取到的是一个数组,那么我们需要用循环进行操作
for href in hrefs:print(href)print(href.get("href")) # 获取html元素属性print(href.text) # 获取a标签内部文字
输出结果
<Element a at 0x1c7b76c2408>
http://news.baidu.com
新闻
<Element a at 0x1c7b76c23c8>
http://www.hao123.com
hao123
<Element a at 0x1c7b76c2288>
http://map.baidu.com
地图
<Element a at 0x1c7b76c2308>
http://v.baidu.com
视频
<Element a at 0x1c7b76f5708>
http://tieba.baidu.com
贴吧现在你已经看到,我们已经获取到了百度首页的所有a标签,并且获取到了a标签的href属性和a标签的文字。有这些内容,你就能很容易的去获取我们的目标网站了。
3.河北阳光理政投诉板块-爬取投诉数据
找到我们的目标网页,结果发现,出事情了,页面竟然是用aspx动态生成的,技术你就不需要研究了,总之,碰到了一个比较小的问题。
首先,点击下一页的时候,页面是局部刷新的

刷新的同时,捕获了一下发送的请求,是post方式,这个需要留意一下,最要紧的是下面第2张图片和第3张图片。
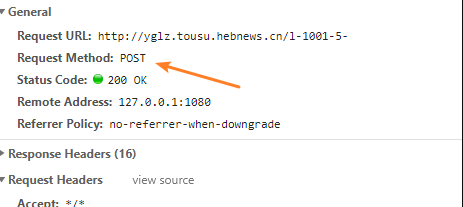
这张图片中的viewstate
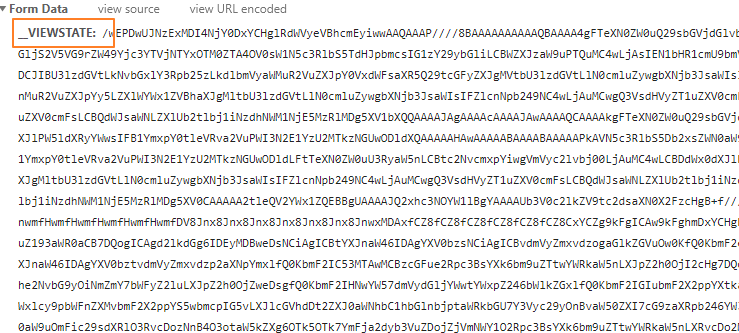
这张图片也有一些奇怪的参数
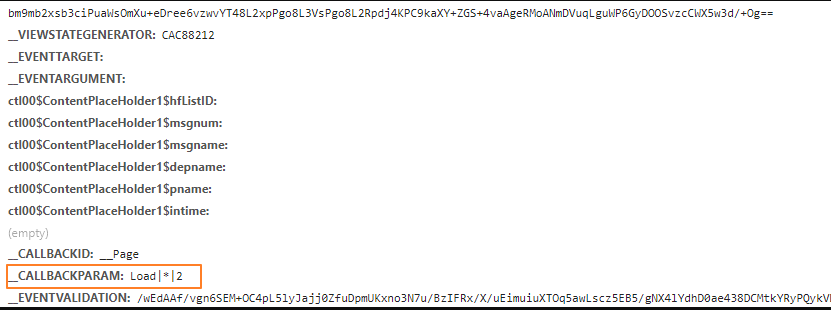
这些参数都是典型的动态网页参数。
解决这个问题,还要从源头抓起!

打开我们要爬取的首页http://yglz.tousu.hebnews.cn/l-1001-5- 第1点需要确定,post的地址经过分析就是这个页面。
所以这段代码是必备的了,注意下面的post
response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-")
html = response.content.decode("utf-8")右键查看源码之后,发现源码中有一些比较重要的隐藏域 里面获取就是我们要的必备信息

没错,这些内容,我们想办法获取到就可以了
基本步骤
- 获取源码
- lxml通过xpath解析隐藏域,取值
import requests
from lxml import etree # 从lxml中导入etree
try:response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-")html = response.content.decode("utf-8")
except Exception as e:print(e)tree=etree.HTML(html) # 解析html
hids = tree.xpath('//input[@type="hidden"]') # 获取隐藏域# 声明一个字典,用来存储后面的数据
common_param = {}
# 循环取值
for ipt in hids:common_param.update({ipt.get("name"):ipt.get("value")}) # 这个地方可以分开写,应该会很清楚,我就不写了,总之,就是把上面获取到的隐藏域的name属性和value属性都获取到了
上面的代码写完之后,其实已经完成了,非常核心的内容了,后面就是继续爬取了
我们按照post要的参数补充完整其他的参数即可
import requests
from lxml import etree # 从lxml中导入etreetry:response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-")html = response.content.decode("utf-8")
except Exception as e:print(e)tree=etree.HTML(html) # 解析htmlhids = tree.xpath('//input[@type="hidden"]')
common_param = {}
for ipt in hids:common_param.update({ipt.get("name"):ipt.get("value")})##############################################################
for i in range(1,691):common_param.update({"__CALLBACKPARAM":f"Load|*|{i}", # 注意这个地方,由于我直接看到了总共有690页数据,所以直接写死了循环次数"__CALLBACKID": "__Page","__EVENTTARGET":"","__EVENTARGUMENT":""})到这一步,就可以抓取真实的数据了,我在下面的代码中最关键的一些地方加上注释,希望你能看懂
for i in range(1,691):common_param.update({"__CALLBACKPARAM":f"Load|*|{i}","__CALLBACKID": "__Page","__EVENTTARGET":"","__EVENTARGUMENT":""})response = requests.post("http://yglz.tousu.hebnews.cn/l-1001-5-",data=common_param,headers=headers)html = response.content.decode("utf-8")print("*"*200)tree = etree.HTML(html) # 解析htmldivs = tree.xpath('//div[@class="listcon"]') # 解析列表区域divfor div in divs: # 循环这个区域try:# 注意下面是通过div去进行的xpath查找,同时加上try方式报错shouli = div.xpath('span[1]/p/a/text()')[0] # 受理单位type = div.xpath('span[2]/p/text()')[0].replace("\n","") # 投诉类型content = div.xpath('span[3]/p/a/text()')[0] # 投诉内容datetime = div.xpath('span[4]/p/text()')[0].replace("\n","") # 时间status = div.xpath('span[6]/p/text()')[0].replace("\n","") # 时间one_data = {"shouli":shouli,"type":type,"content":content,"datetime":datetime,"status":status,}print(one_data) # 打印数据,方便存储到mongodb里面except Exception as e:print("内部数据报错")print(div)continue代码完成,非常爽

最后抓取到了 13765 条数据,官方在我抓取的时候是13790,差了25条数据,没有大的影响~
数据我都存储在了 mongodb里面,关于这个如何使用,请去看我以前的代码吧~~~~

她专科学历
27岁从零开始学习c,c++,python编程语言,
29岁编写百例教程,
30岁掌握10种编程语言,
用亲身经历告诉你,编程入门,就找梦想橡皮擦
欢迎关注她的公众号,非本科程序员
这些数据,放着以后做数据分析用了。
Python爬虫入门教程 9-100 河北阳光理政投诉板块 1相关推荐
- Python爬虫入门教程 9-100 河北阳光理政投诉板块
1.河北阳光理政投诉板块-写在前面 之前几篇文章都是在写图片相关的爬虫,今天写个留言板爬出,为另一套数据分析案例的教程做做准备,作为一个河北人,遵纪守法,有事投诉是必备的技能,那么咱看看我们大河北人都 ...
- Python爬虫入门教程:河北阳光理政投诉板块
河北阳光理政投诉板块-写在前面 之前几篇文章都是在写图片相关的爬虫,今天写个留言板爬出,为另一套数据分析案例的教程做做准备,作为一个河北人,遵纪守法,有事投诉是必备的技能,那么咱看看我们大河北人都因为 ...
- Python爬虫入门教程导航帖
转载:梦想橡皮擦 https://blog.csdn.net/hihell/article/details/86106916 **Python爬虫入门教程导航,目标100篇** 本系列博客争取把爬虫入 ...
- python爬虫入门教程(三):淘女郎爬虫 ( 接口解析 | 图片下载 )
2019/10/28更新 网站已改版,代码已失效(其实早就失效了,但我懒得改...)此博文仅供做思路上的参考 代码使用python2编写,因已失效,就未改写成python3 爬虫入门系列教程: pyt ...
- Python爬虫入门教程:博客园首页推荐博客排行的秘密
1. 前言 虽然博客园注册已经有五年多了,但是最近才正式开始在这里写博客.(进了博客园才知道这里面个个都是人才,说话又好听,超喜欢这里...)但是由于写的内容都是软件测试相关,热度一直不是很高.看到首 ...
- Python 爬虫入门教程——社团授课型
Python爬虫入门教程 基础知识 什么是HTML.CSS.JavaScript 网页往往采用html+css+js开发,html是一门标记语言 如下: <!- 将下面这句话放入html文件中, ...
- python教程是用什么博客写的-Python爬虫入门教程:博客园首页推荐博客排行的秘密...
1. 前言 虽然博客园注册已经有五年多了,但是最近才正式开始在这里写博客.(进了博客园才知道这里面个个都是人才,说话又好听,超喜欢这里...)但是由于写的内容都是软件测试相关,热度一直不是很高.看到首 ...
- python爬虫入门教程--优雅的HTTP库requests(二)
requests 实现了 HTTP 协议中绝大部分功能,它提供的功能包括 Keep-Alive.连接池.Cookie持久化.内容自动解压.HTTP代理.SSL认证等很多特性,下面这篇文章主要给大家介绍 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
最新文章
- 新闻发布项目——业务逻辑层(newsTbService)
- 人工智能时代,开发者是逆袭还是走向末日?
- 在VmWare Workstation 6.5上安装Esx 3.5 U3之二
- HDU 3932 模拟退火
- 制造业ai中台_如何建立自己的制造者工作台
- android 检查 write_external_storage,android – 如何知道何时需要WRITE_EXTERNAL_STORAGE
- 2018年php还是python好_2018年PHP还值得学习吗?
- MySQL命令行导入导出sql文件
- 吴恩达深度学习——深层神经网络
- Sklearn fit , transform ,fit_transform
- 怎样启动Windows系统呢
- PS更改显示的尺寸单位
- 在蚂蚁金服工作是一种什么体验
- 程序员常用的一些快捷键(持续更新)
- C# 更换微信小程序码中间的logo图层
- Android冒险之旅-14-RecycleView(线性,网格,瀑布流)
- 【原创纯手打】如何使用Vue写微信朋友圈中的留言回复功能(附源码)
- ACM-ICPC 2018 南京赛区网络预赛 AC Challenge (状态压缩DP)
- TransFuse论文
- 炒菜机器人的弊端_饭店用智能炒菜机器人的好处