统计学中各种检验以及python实现
1. T检验
T检验是假设检验的一种,又叫student t检验(Student’s t test),主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。
T检验用于检验两个总体的均值差异是否显著。
计算公式:
t统计量: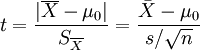
自由度:v=n - 1
适用条件:
(1) 已知一个总体均数;
(2) 可得到一个样本均数及该样本标准误;
(3) 样本来自正态或近似正态总体。
t检验的分类
t检验分为单总体t检验和双总体t检验
单总体t检验
检验一个样本平均数与一个已知的总体平均数差异是否显著。
适用条件:
1.总体服从正态分布
2.样本量小于30(当样本量大于30时,用Z统计量)
统计量:
t=x¯−μS/n−−√∼t(n−1)t=x¯−μS/n∼t(n−1)
x¯x¯——样本均值
μμ——总体均值
SS——样本标准差
nn——样本容量
例1就是单样本t检验的例子。
双总体t检验
检验两个样本各自所代表的总体的均值差异是否显著,包括独立样本t检验和配对样本t检验
独立样本t检验
检验两个独立样本所代表的总体均值差异是否显著。
适用条件:
1.两样本均来自于正态总体
2.两样本相互独立
3.满足方差齐性(两总体方差相等)
统计量:
t=x¯−y¯Sw1m+1n−−−−−−√∼t(m+n−2)t=x¯−y¯Sw1m+1n∼t(m+n−2)
其中
Sw=1m+n+1[(m−1)S21+(n−1)S22]Sw=1m+n+1[(m−1)S12+(n−1)S22]
x¯x¯——第一个样本均值
y¯y¯——第二个样本均值
mm——第一个样本容量
nn——第二个样本容量
S21S12——第一个样本方差
S22S22——第二个样本方差
配对样本t检验
检验两个配对样本所代表的总体均值差异是否显著。
配对样本主要包含以下两种情形:
1.同源配对,也就是同质的对象分别接受两种不同的处理。例如:为了验证某种记忆方法对改善儿童对词汇的记忆是否有效,先随机抽取40名学生,再随机分为两组。一组使用该训练方法,一组不使用,三个月后对这两组的学生进行词汇测验,得到数据。问该训练方法是否对提高词汇记忆量有效?
2.自身配对
2.1某组同质对象接受两种不同的处理。例如:某公司推广了一种新的促销方式,实施前和实施后分别统计了员工的业务量,得到数据。试问这种促销方式是否有效?
适用条件:
每对数据的差值必须服从正态分布
统计量:
t=xd¯Sd/n−−√t=xd¯Sd/n
两配对样本对应元素做差后形成的新样本
xd¯xd¯——新样本均值
SdSd——新样本标准差
nn——新样本容量
python实现
使用scipy直接做假设检验
Scipy提供了两个方法解决双样本同方差的Student t-test问题:
1. scipy.stats.ttest_ind
2. scipy.stats.ttest_ind_from_stats
第一个方法要求输入原始样本数据,第二个方法直接输入样本的描述统计量(均值,标准差,样本数)即可。那么这里我们直接使用第二方法。
import numpy as np from scipy import stats mean1 = 30.97 mean2 = 21.79 std1 = 26.7 std2 = 12.1 nobs1 = 10 nobs2 = 10 modified_std1 = np.sqrt(np.float32(nobs1)/np.float32(nobs1-1)) * std1 modified_std2 = np.sqrt(np.float32(nobs2)/np.float32(nobs2-1)) * std2 (statistic, pvalue) = stats.ttest_ind_from_stats(mean1=mean1, std1=modified_std1, nobs1=10, mean2=mean2, std2=modified_std2, nobs2=10) print "t statistic is: ", statistic print "pvalue is: ", pvalue
t statistic is: 0.939488657335
pvalue is: 0.359917216785假设我们显著性水平α=0.05α=0.05,pvalue显著的大于0.05,所以我们不能拒绝原假设,也就是认为两种作物的产量没有显著差异。
配对样本的结果证明看
α小于0.05,说明有显著相关
Ttest_1sampResult(statistic=array([ 4.51858295]), pvalue=array([ 8.49191658e-05]))
from scipy import stats import numpy as np
生成50行x2列的数据
np.random.seed(7654567) # 保证每次运行都会得到相同结果
# 均值为5,方差为10
rvs = stats.norm.rvs(loc=5, scale=10, size=(50,2))- 1
- 2
- 3
检验两列数的均值与1和2的差异是否显著
stats.ttest_1samp(rvs, [1, 2])- 1
返回结果:
Ttest_1sampResult(statistic=array([ 2.0801775 , 2.44893711]), pvalue=array([ 0.04276084, 0.01795186]))
分别显示两列数的t统计量和p值。由p值分别为0.042和0.018,当p值小于0.05时,认为差异显著,即第一列数的均值不等于1,第二列数的均值不等于2。
不拒绝原假设——均值等于5
stats.ttest_1samp(rvs, 5.0)- 1
Ttest_1sampResult(statistic=array([-0.68014479, -0.04323899]), pvalue=array([ 0.49961383, 0.96568674]))
拒绝原假设——均值不等于5
stats.ttest_1samp(rvs, 0.0)- 1
Ttest_1sampResult(statistic=array([ 2.77025808, 4.11038784]), pvalue=array([ 0.00789095, 0.00014999]))
第一列数均值等于5,第二列数均值不等于0
stats.ttest_1samp(rvs,[5.0,0.0])- 1
Ttest_1sampResult(statistic=array([-0.68014479, 4.11038784]), pvalue=array([ 4.99613833e-01, 1.49986458e-04]))
第一行数均值等于5,第二行数均值不等于0
#axis=0按列运算,axis=1按行运算
stats.ttest_1samp(rvs.T,[5.0,0.0],axis=1) - 1
- 2
Ttest_1sampResult(statistic=array([-0.68014479, 4.11038784]), pvalue=array([ 4.99613833e-01, 1.49986458e-04]))
将两列数据均值分别与5.0和0.0比较,得到4个t统计量和p值
stats.ttest_1samp(rvs,[[5.0],[0.0]])- 1
Ttest_1sampResult(statistic=array([[-0.68014479, -0.04323899],
[ 2.77025808, 4.11038784]]), pvalue=array([[ 4.99613833e-01, 9.65686743e-01],
[ 7.89094663e-03, 1.49986458e-04]]))
两独立样本t检验-ttest_ind
ttest_ind官方文档
生成数据
np.random.seed(12345678)
#loc:平均值 scale:方差
rvs1 = stats.norm.rvs(loc=5,scale=10,size=500)
rvs2 = stats.norm.rvs(loc=5,scale=10,size=500)- 1
- 2
- 3
- 4
当两总体方差相等时,即具有“方差齐性”,可以直接检验
不拒绝原假设——两总体均值相等
stats.ttest_ind(rvs1,rvs2)- 1
Ttest_indResult(statistic=0.26833823296238857, pvalue=0.78849443369565098)
当不确定两总体方差是否相等时,应先利用levene检验,检验两总体是否具有方差齐性。
stats.levene(rvs1, rvs2)- 1
LeveneResult(statistic=1.0117186648494396, pvalue=0.31473525853990908)
p值远大于0.05,认为两总体具有方差齐性。
如果两总体不具有方差齐性,需要将equal_val参数设定为“False”。
需注意的情况:
如果两总体具有方差齐性,错将equal_var设为False,p值变大
stats.ttest_ind(rvs1,rvs2, equal_var = False)- 1
Ttest_indResult(statistic=0.26833823296238857, pvalue=0.78849452749501059)
两总体方差不等时,若没有将equal_var参数设定为False,则函数会默认equal_var为True,这样会低估p值
rvs3 = stats.norm.rvs(loc=5, scale=20, size=500)
stats.ttest_ind(rvs1, rvs3, equal_var = False)- 1
- 2
正确的p值
Ttest_indResult(statistic=-0.46580283298287956, pvalue=0.64149646246568737)
stats.ttest_ind(rvs1, rvs3)- 1
被低估的p值
Ttest_indResult(statistic=-0.46580283298287956, pvalue=0.64145827413435608)
当两样本数量不等时,equal_val的变化会导致t统计量变化
rvs1:来自总体——均值5,方差10,样本数500
rvs2:来自总体——均值5,方差20,样本数100
两总体不具有方差齐性,应设定equal_var=False
rvs4 = stats.norm.rvs(loc=5, scale=20, size=100)
stats.ttest_ind(rvs1, rvs4)- 1
- 2
错误的t统计量
Ttest_indResult(statistic=-0.99882539442782847, pvalue=0.31828327091038783)
stats.ttest_ind(rvs1, rvs4, equal_var = False)- 1
正确的t统计量
Ttest_indResult(statistic=-0.69712570584654354, pvalue=0.48716927725401871)
不同均值,不同方差,不同样本量的t检验
错误的检验:未将equal_var设定为False
rvs5 = stats.norm.rvs(loc=8, scale=20, size=100)
stats.ttest_ind(rvs1, rvs5)- 1
- 2
Ttest_indResult(statistic=-1.4679669854490669, pvalue=0.14263895620529113)
正确的检验:
stats.ttest_ind(rvs1, rvs5, equal_var = False)- 1
Ttest_indResult(statistic=-0.94365973617133081, pvalue=0.34744170334794089)
配对样本t检验
ttest_rel官方文档
np.random.seed(12345678)- 1
不拒绝原假设,认为rvs1 与 rvs2 所代表的总体均值相等
rvs1 = stats.norm.rvs(loc=5,scale=10,size=500)
rvs2 = (stats.norm.rvs(loc=5,scale=10,size=500) + stats.norm.rvs(scale=0.2,size=500))
stats.ttest_rel(rvs1,rvs2)- 1
- 2
- 3
Ttest_relResult(statistic=0.24101764965300979, pvalue=0.80964043445811551)
拒绝原假设,认为rvs1 与 rvs3所代表的总体均值不相等
rvs3 = (stats.norm.rvs(loc=8,scale=10,size=500) + stats.norm.rvs(scale=0.2,size=500))
stats.ttest_rel(rvs1,rvs3)- 1
- 2
Ttest_relResult(statistic=-3.9995108708727924, pvalue=7.3082402191661285e-05)
2.卡方检验
什么是卡方检验
卡方检验是一种用途很广的计数资料的假设检验方法。它属于非参数检验的范畴,主要是比较两个及两个以上样本率( 构成比)以及两个分类变量的关联性分析。其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
它在分类资料统计推断中的应用,包括:两个率或两个构成比比较的卡方检验;多个率或多个构成比比较的卡方检验以及分类资料的相关分析等。
例子1:四格卡方检验
以下为一个典型的四格卡方检验,我们想知道喝牛奶对感冒发病率有没有影响:
| 感冒人数 | 未感冒人数 | 合计 | 感冒率 | |
| 喝牛奶组 | 43 | 96 | 139 | 30.94% |
| 不喝牛奶组 | 28 | 84 | 112 | 25.00% |
| 合计 | 71 | 180 | 251 | 28.29% |
通过简单的统计我们得出喝牛奶组和不喝牛奶组的感冒率为30.94%和25.00%,两者的差别可能是抽样误差导致,也有可能是牛奶对感冒率真的有影响。
为了确定真实原因,我们先假设喝牛奶对感冒发病率是没有影响的,即喝牛奶喝感冒时独立无关的,所以我们可以得出感冒的发病率实际是(43+28)/(43+28+96+84)= 28.29%
所以,理论的四格表应该如下表所示:
| 感冒人数 | 未感冒人数 | 合计 | |
| 喝牛奶组 | =139*0.2829 | =139*(1-0.2829) | 139 |
| 不喝牛奶组 | =112*0.2829 | =112*(1-0.2829) | 112 |
即下表:
| 感冒人数 | 未感冒人数 | 合计 | |
| 喝牛奶组 | 39.3231 | 99.6769 | 139 |
| 不喝牛奶组 | 31.6848 | 80.3152 | 112 |
| 合计 | 71 | 180 | 251 |
如果喝牛奶喝感冒真的是独立无关的,那么四格表里的理论值和实际值差别应该会很小。
卡方检验
卡方检验的计算公式为:

其中,A为实际值,T为理论值。
x2用于衡量实际值与理论值的差异程度(也就是卡方检验的核心思想),包含了以下两个信息:
1. 实际值与理论值偏差的绝对大小(由于平方的存在,差异是被放大的)
2. 差异程度与理论值的相对大小
例1卡方检验
根据卡方检验公式我们可以得出例1的卡方值为:
卡方 = (43 - 39.3231)平方 / 39.3231 + (28 - 31.6848)平方 / 31.6848 + (96 - 99.6769)平方 / 99.6769 + (84 - 80.3152)平方 / 80.3152 = 1.077
卡方分布的临界值:
上一步我们得到了卡方的值,但是如何通过卡方的值来判断喝牛奶和感冒是否真的是独立无关的?也就是说,怎么知道无关性假设是否可靠?
答案是,通过查询卡方分布的临界值表。
这里需要用到一个自由度的概念,自由度等于V = (行数 - 1) * (列数 - 1),对四格表,自由度V = 1。
对V = 1,喝牛奶和感冒95%概率不相关的卡方分布的临界概率是:3.84。即如果卡方大于3.84,则认为喝牛奶和感冒有95%的概率不相关。
显然1.077<3.84,没有达到卡方分布的临界值,所以喝牛奶和感冒独立不相关的假设不成立。

上面通过一个小例子让大家对卡方检验有一个简单的认识,下面是卡方检验的标准做法:
例子2. 四格卡方检验的标准做法
我们想知道不吃晚饭对体重下降有没有影响:
| 体重下降 | 体重未下降 | 合计 | 体重下降率 | |
| 吃晚饭组 | 123 | 467 | 590 | 20.85% |
| 不吃晚饭组 | 45 | 106 | 151 | 29.80% |
| 合计 | 168 | 573 | 741 | 22.67% |
1. 建立假设检验:
H0:r1=r2,不吃晚饭对体重下降没有影响,即吃不吃晚饭的体重下降率相等;
H1:r1≠r2,不吃晚饭对体重下降有显著影响,即吃不吃晚饭的体重下降率不相等。α=0.05
2. 计算理论值
| 体重下降 | 体重未下降 | 合计 | |
| 吃晚饭组 | 133.765 | 456.234 | 590 |
| 不吃晚饭组 | 34.2348 | 116.765 | 151 |
| 合计 | 168 | 573 | 741 |
3. 计算卡方值
根据公式
计算出卡方值为5.498
4. 查卡方表求P值
在查表之前应知本题自由度。按卡方检验的自由度v=(行数-1)(列数-1),则该题的自由度v=(2-1)(2-1)=1,查卡方界值表,找到3.84,而本题卡方=5.498即卡方>3.84,P<0.05,差异有显著统计学意义,按α=0.05水准,拒绝H0,可以认为两组的体重下降率有明显差别。
通过实例计算,对卡方的基本公式有如下理解:若各理论数与相应实际数相差越小,卡方值越小;如两者相同,则卡方值必为零。
python实现卡方分布
某科学家预言抛一个色子,各面向上的几率都相同。为了验证自己理论的正确性,该科学家抛了600次硬币,结果为一点102次,二点102次,三点96次,四点105次,五点95次,六点100次。显然这个结果和理论预期并不完全一样,那么,科学家的理论有错吗?我们就用Python来验证一下。
from scipy import stats
obs = [102, 102, 96, 105, 95, 100]
exp = [100, 100, 100, 100, 100, 100]
stats.chisquare(obs, f_exp = exp)输出
(0.73999999999999999, 0.98070147251964801)
从结果来看,p 值为0.98,可以认为观测到的值和预期值是相近即“合适”的。科学家的理论没有错,观测值和理论值的不同是由偶然误差造成的。(一般 p 值大于0.95即可)
python中通过sklearn来选择卡方检验最好的特征
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.datasets import load_iris
#导入IRIS数据集
iris = load_iris()
iris.data#查看数据
array([[ 5.1, 3.5, 1.4, 0.2],
[ 4.9, 3. , 1.4, 0.2],
[ 4.7, 3.2, 1.3, 0.2],
[ 4.6, 3.1, 1.5, 0.2],
[ 5. , 3.6, 1.4, 0.2],
[ 5.4, 3.9, 1.7, 0.4],
[ 4.6, 3.4, 1.4, 0.3],
model1 = SelectKBest(chi2, k=2)#选择k个最佳特征
model1.fit_transform(iris.data, iris.target)#iris.data是特征数据,iris.target是标签数据,该函数可以选择出k个特征
model1.scores_ #得分
model1.pvalues_ #p-values
3.F检验
统计学中各种检验以及python实现相关推荐
- 统计学中的变异及其Python实现
统计学中的变异及其Python实现 在统计学中,变异是指对数据的分散程度的度量,常用的统计量称为标准差和方差.另外,变异系数是一种用来比较不同变量或不同尺度下变异度量的方法,更加直观和具有可比性.本文 ...
- python t检验_讲讲统计学中T检验的种类
这一篇给大家介绍一下T检验的种类以及具体的Python实现代码.T检验是比较两个均值差异的,不同种类T检验的差别其实在于均值的计算差异. 1.单样本T检验 单样本T检验是用来检验一组样本的均值A与一个 ...
- 医学统计学中差异性检验的检验方法选择
初步选择: 深入选择:
- python卡方检验kf_data_统计学中的各种检验-scipy.stats和statsmodels.stats的使用
这里会罗列一些统计学中的检验方法,当然顺序以笔者遇到的为准. 1.方差分析 1.1 概述 对于均值的检验,一般分为以下几种情况: 某样本均值与常数的比较 两个样本均值的比较 两个以上样本均值的比较 对 ...
- 【Python】假设检验中单个样本t检验的Python实现过程
Python有一个很好的统计推断包.那就是scipy里面的stats.ttest_1samp实现了单样本t检验. 假设检验 假设检验(Hypothesis Testing)是数理统计学中根据一定假设条 ...
- python 绘制分布直方图_统计学中常见的4种抽样分布及其分布曲线(Python绘制)...
现代统计学奠基人之一.英国统计学家费希尔(Fisher)曾把抽样分布.参书估计和假设检验看作统计推断的三大中心内容. 统计学中,需要研究统计量的性质,并评价一个统计推断的优良性,而这些取决于其抽样分布 ...
- python 计量经济 35岁 工作_Python在计量经济与统计学中的应用
Python for Econometrics and Statistics (Python在计量经济与统计学中的应用) [点击链接进入主页].这套笔记将重点介绍Python在计量经济学与统计分析中的 ...
- t检验自由度的意义_统计学中自由度的理解和应用
数理统计研究问题的方式,不是对所研究对象的全体(称为总体)进行观察,而是抽取其中的部分(称为样本)进行观察获得数据(抽样),并通过这些数据对总体进行推断.数理统计方法具有"部分推断整体&qu ...
- python相关性分析_python实践统计学中的三大相关性系数,并绘制相关性分析的热力图...
本文首发地址: https://yishuihancheng.blog.csdn.net/article/details/83547648 欢迎关注我的博客[Together_CZ],我是沂水寒城! ...
最新文章
- RNAseq-GO、biomaRt转换ID
- freemarker模板文件中文本域(textarea)的高度自适应实现
- ctrl+Enter 自动加上 .com 而不是 .com.cn
- Jackson 读写 JSON
- 美团容器平台架构及容器技术实践
- crontab 日志_liunx 中定时清理过期日志文件
- OpenCV学习笔记04:在Visual Studio上使用OpenCV4.5.5
- PyCharm 入手第一记
- 彩虹自助下单平台对接爱代挂插件程序
- java程序员 英文简历_Java程序员英文简历范文
- C++随机生成中文姓名
- 温习Java和基础汇总
- python模拟微信登录公众号_Python3微信公众平台requests模拟登陆
- Unity 5如何设置物体透明
- TOOD: Task-aligned One-stage Object Detection
- 计算机图表制作教程,PPT怎么制作动态图表 PPT动态图表制作教程-电脑教程
- WannaCry勒索病毒分析 **下**
- 微信小程序中显示换行、空格
- zepoto.js的使用
- module github.com/jinzhu/gorm/dialects/mysql: git ls-remote -q origin in E:\go_gin\pkg\mod\cache\vcs