使用TextRank算法进行文本摘要提取(python代码)
文本摘要是自然语言处理(NLP)的一种应用,随着人工智能的发展文本提取必将对我们的生活产生巨大的影响。随着网络的发展我们处在一个信息爆炸的时代,通读每天更新的海量文章/文档/书籍会占用我们大量的时间,所以用一种算法帮我们提取一篇文章的关键信息是非常高效的。谢天谢地,这项技术已经出现了。你有没有遇到过inshorts的手机应用?这是一款创新的新闻应用程序,可以将新闻文章转换成60字的摘要。这正是我们在这篇文章中要学习的——自动文本摘要提取。
自动文本摘要早在20世纪50年代就引起了人们的注意。汉斯•彼得•鲁恩(Hans Peter Luhn)在20世纪50年代末发表了一篇研究论文,题为《文学文摘的自动创作》(the automatic creation of literature abstracts)。该论文利用词频和短语频等特征,从文本中提取重要句子进行总结。
另一项重要的研究是Harold P Edmundson在20世纪60年代末所做的,该研究利用线索词的出现、出现在文章标题中的词以及句子的位置等方法,提取出有意义的句子进行文本总结。从那时起,许多重要和令人兴奋的研究已经发表,以解决自动文本摘要的挑战。
下面来看TextRank算法进行网球类文章的摘要提取实例
一、TextRank算法流程
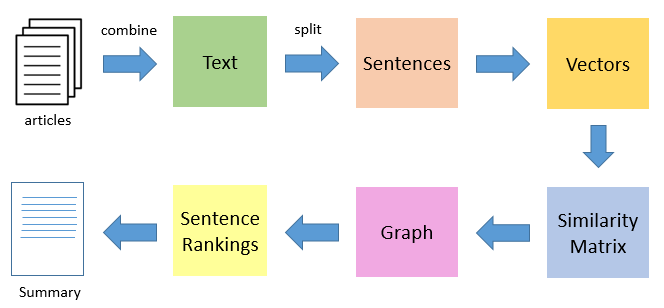
我们选取网球类文章来进行我们的文本摘要提取实战,我们将以多篇文章作为输入,并生成单个项目符号摘要。本文不讨论多域文本摘要,但您可以在文章末尾尝试它。
数据集地址:https://s3-ap-south-1.amazonaws.com/av-blog-media/wp-content/uploads/2018/10/tennis_articles_v4.csv
三、python代码
1、导入库
import numpy as np
import pandas as pd
import nltk
nltk.download('punkt') # one time execution
import re
2、读取并查看数据
df = pd.read_csv("tennis_articles_v4.csv")
df.head()
3、将文本分成句子
from nltk.tokenize import sent_tokenize
sentences = []
for s in df['article_text']:sentences.append(sent_tokenize(s))sentences = [y for x in sentences for y in x] # flatten list
4、下载GloVe词嵌入
GloVe词嵌入是词的向量表示。这些词的嵌入将被用来为我们的句子创建向量。我们也可以使用单词包或TF-IDF方法为句子创建特征,但是这些方法忽略了单词的顺序(特征的数量通常相当大)。我们将使用预先培训的维基百科2014 + Gigaword5 GloVe矢量,这些单词嵌入的大小是822 MB。
!wget http://nlp.stanford.edu/data/glove.6B.zip
!unzip glove*.zip
5、提取单词嵌入或单词向量
# Extract word vectors
word_embeddings = {}
f = open('glove.6B.100d.txt', encoding='utf-8')
for line in f:values = line.split()word = values[0]coefs = np.asarray(values[1:], dtype='float32')word_embeddings[word] = coefs
f.close()
6、文本处理
对文本数据做一些基本的文本清理以尽可能避免文本数据的噪音对摘要提取的影响。
# remove punctuations, numbers and special characters
clean_sentences = pd.Series(sentences).str.replace("[^a-zA-Z]", " ")# make alphabets lowercase
clean_sentences = [s.lower() for s in clean_sentences]
nltk.download('stopwords')
from nltk.corpus import stopwords
stop_words = stopwords.words('english')
# function to remove stopwords
def remove_stopwords(sen):sen_new = " ".join([i for i in sen if i not in stop_words])return sen_new
# remove stopwords from the sentences
clean_sentences = [remove_stopwords(r.split()) for r in clean_sentences]
7、句子的向量表示
# Extract word vectors
word_embeddings = {}
f = open('glove.6B.100d.txt', encoding='utf-8')
for line in f:values = line.split()word = values[0]coefs = np.asarray(values[1:], dtype='float32')word_embeddings[word] = coefs
f.close()
sentence_vectors = []
for i in clean_sentences:if len(i) != 0:v = sum([word_embeddings.get(w, np.zeros((100,))) for w in i.split()])/(len(i.split())+0.001)else:v = np.zeros((100,))sentence_vectors.append(v)
8、创建相似矩阵
为了找出句子之间的相似点,我们将使用余弦相似法来解决这个问题。让我们为这个任务创建一个空的相似性矩阵,并用句子的余弦相似性填充它。
# similarity matrix
sim_mat = np.zeros([len(sentences), len(sentences)])
from sklearn.metrics.pairwise import cosine_similarity
for i in range(len(sentences)):for j in range(len(sentences)):if i != j:sim_mat[i][j] = cosine_similarity(sentence_vectors[i].reshape(1,100), sentence_vectors[j].reshape(1,100))[0,0]
9、实验TextRank算法
在这里我们将相似矩阵sim_mat转换为图形。图中的节点表示句子,边表示句子之间的相似度得分。在这个图中,我们将使用PageRank算法得到句子的排名。
import networkx as nx
nx_graph = nx.from_numpy_array(sim_mat)
scores = nx.pagerank(nx_graph)#Summary Extraction
ranked_sentences = sorted(((scores[i],s) for i,s in enumerate(sentences)), reverse=True)
# Extract top 10 sentences as the summary
for i in range(10):print(ranked_sentences[i][1])
输出结果
When I'm on the courts or when I'm on the court playing, I'm a competitor and I want to beat every single person
whether they're in the locker room or across the net.So I'm not the one to strike up a conversation about the
weather and know that in the next few minutes I have to go and try to win a tennis match.Major players feel that a big event in late November combined with one in January before the Australian Open will
mean too much tennis and too little rest.Speaking at the Swiss Indoors tournament where he will play in Sundays final against Romanian qualifier Marius
Copil, the world number three said that given the impossibly short time frame to make a decision, he opted out of
any commitment."I felt like the best weeks that I had to get to know players when I was playing were the Fed Cup weeks or the
Olympic weeks, not necessarily during the tournaments.Currently in ninth place, Nishikori with a win could move to within 125 points of the cut for the eight-man event
in London next month.He used his first break point to close out the first set before going up 3-0 in the second and wrapping up the
win on his first match point.
The Spaniard broke Anderson twice in the second but didn't get another chance on the South African's serve in the
final set."We also had the impression that at this stage it might be better to play matches than to train.The competition is set to feature 18 countries in the November 18-24 finals in Madrid next year, and will replace
the classic home-and-away ties played four times per year for decades.Federer said earlier this month in Shanghai in that his chances of playing the Davis Cup were all but non-existent.
具体代码和数据参看github:https://github.com/prateekjoshi565/textrank_text_summarization
结语:
更多机器学习算法的学习欢迎关注我们。对机器学习感兴趣的同学欢迎大家转发&转载本公众号文章,让更多学习机器学习的伙伴加入公众号《python练手项目实战》,在实战中成长。

使用TextRank算法进行文本摘要提取(python代码)相关推荐
- 基于TextRank算法的文本摘要(附Python代码)
基于TextRank算法的文本摘要(附Python代码): https://www.jiqizhixin.com/articles/2018-12-28-18
- 中文文本摘要提取 (文本摘要提取 有代码)基于python
任务简介 文本摘要旨在将文本或文本集合转换为包含关键信息的简短摘要.文本摘要按照输入类型可分为单文档摘要和多文档摘要.单文档摘要从给定的一个文档中生成摘要,多文档摘要从给定的一组主题相关的文档中生成摘 ...
- 独家 | 基于TextRank算法的文本摘要(附Python代码)
作者:Prateek Joshi 翻译:王威力 校对:丁楠雅 本文约3300字,建议阅读10分钟. 本文介绍TextRank算法及其在多篇单领域文本数据中抽取句子组成摘要中的应用. TextRank ...
- nlp中文文本摘要提取,快速提取文本主要意思
文本摘要提取 之前写过一版 文本摘要提取,但那版并不完美.有所缺陷(但也获得几十次收藏). 中文文本摘要提取 (文本摘要提取 有代码)基于python 今天写改进版的文本摘要提取. 文本摘要旨在将文本 ...
- 使用TextRank算法为文本生成关键字和摘要
使用TextRank算法为文本生成关键字和摘要 发表于1年前(2014-12-01 21:31) 阅读(10282) | 评论(27) 155人收藏此文章, 我要收藏 赞15 摘要 TextRan ...
- 文本摘要提取_了解自动文本摘要-1:提取方法
文本摘要提取 Text summarization is commonly used by several websites and applications to create news feed ...
- 实现自动文本摘要(python,java)
参考资料:http://www.ruanyifeng.com/blog/2013/03/automatic_summarization.html http://joshbohde.com/blog/d ...
- 【负荷预测】基于灰色预测算法的负荷预测(Python代码实现)
目录 1 概述 2 流程图 3 入门算例 4 基于灰色预测算法的负荷预测(Python代码实现) 1 概述 "由于数据列的离散性,信息时区内将出现空集(不包含信息的定时区),因此只能按近似 ...
- 联邦学习算法介绍-FedAvg详细案例-Python代码获取
联邦学习算法介绍-FedAvg详细案例-Python代码获取 一.联邦学习系统框架 二.联邦平均算法(FedAvg) 三.联邦随梯度下降算法 (FedSGD) 四.差分隐私随联邦梯度下降算法 (DP- ...
最新文章
- 彻底弄懂C语言数组名
- PaddlePaddle飞浆开启人工智能新时代
- 数据结构与算法--将数组排成最小的数
- 苹果ppt_你的PPT太low了,学学苹果吧
- Spring MVC国际化(i18n)和本地化(L10n)示例
- layui select下拉框选项不显示
- python列表元组字典集合实验心得_python心得 元组,字典,集合
- 学习:网络接口RJ45
- 油藏弹性存储量计算公式_低渗透油藏压裂井弹性产能和采收率计算方法
- CCF推荐会议(人工智能与模式识别)
- CSS画五星红旗,我请AutoCAD帮忙
- JavaScript基础知识总结 18:dom基本操作
- 初中八年级计算机课程计划,初中信息技术教学计划
- mac终端Login Incorrect问题
- 食品安全管理知识演讲PPT模板
- 【nlp学习】中文命名实体识别(待补充)
- DeepLink的实现原理
- 大专生出身?java技术栈xmind
- 图像识别过程(概念)
- Word 自带公式转为mathtype格式