scrapy初始第二波——爬取知乎首页的问题和回答并写入mysql中
1.前言
这几天在爬取了美女网站,小说网站之余,想着用scrapy做点逼格高点的爬虫,就想到我们的目前声誉较高的社区——知乎,今天就来爬取知乎的问题及回答,本来知乎是不需要登录就可以爬取,但是首页上推荐的内容就不是你关注的,所以我们需要在登录知乎的前提下(挺重要的技术),爬取我们首页的问题和各个问题的回答
转载请注明
2.知乎登录
知乎登录我之前写过一个关于它登录的文章:知乎登录文章--点击,可以通过这个文章实操一下,在这里就不详说了,这里直接贴出scrapy的知乎登录代码
class ZhihuSpider(scrapy.Spider):name = 'zhihu'allowed_domains = ['www.zhihu.com']start_urls = ['http://www.zhihu.com/']headers = {"HOST": "www.zhihu.com","Referer": "https://www.zhizhu.com",'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.91 Safari/537.36"}def start_requests(self):return [scrapy.Request('https://www.zhihu.com/#signin', headers=self.headers, callback=self.login)]def login(self, response):response_text = response.textmatch_obj = re.match('.*name="_xsrf" value="(.*?)"', response_text, re.DOTALL)xsrf = ''if match_obj:xsrf = (match_obj.group(1))if xsrf:post_url = "https://www.zhihu.com/login/phone_num"post_data = {"_xsrf": xsrf,"phone_num": "你的手机号码","password": "你的知乎登录密码","captcha": ""}import timet = str(int(time.time() * 1000))captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)yield scrapy.Request(captcha_url, headers=self.headers, meta={"post_data": post_data},callback=self.login_after_captcha)def login_after_captcha(self, response):with open("captcha.jpg", "wb") as f:f.write(response.body)f.close()from PIL import Imagetry:im = Image.open('captcha.jpg')im.show()im.close()except:passcaptcha = input("输入验证码\n>")post_data = response.meta.get("post_data", {})post_url = "https://www.zhihu.com/login/phone_num"post_data["captcha"] = captchareturn [scrapy.FormRequest(url=post_url,formdata=post_data,headers=self.headers,callback=self.check_login)]def check_login(self,response):text_json = json.loads(response.text)print(text_json)if "msg" in text_json and text_json["msg"] == "登录成功":for url in self.start_urls:yield scrapy.Request(url, dont_filter=True, headers=self.headers)3.知乎scrapy项目
首先创建scrapy项目 在cmd上cd进入项目目录 输入:scrapy genspider zhihu www.zhihu.com
这样就创建知乎scrapy基础模板:
class ZhihuSpider(scrapy.Spider):name = 'zhihu'allowed_domains = ['www.zhihu.com']start_urls = ['http://www.zhihu.com/']def parse(self, response):pass
4.获取知乎首页所有问题的url
点击一个知乎问题 url为:https://www.zhihu.com/question/50731621/answer/123225450
这是老版的问题url,
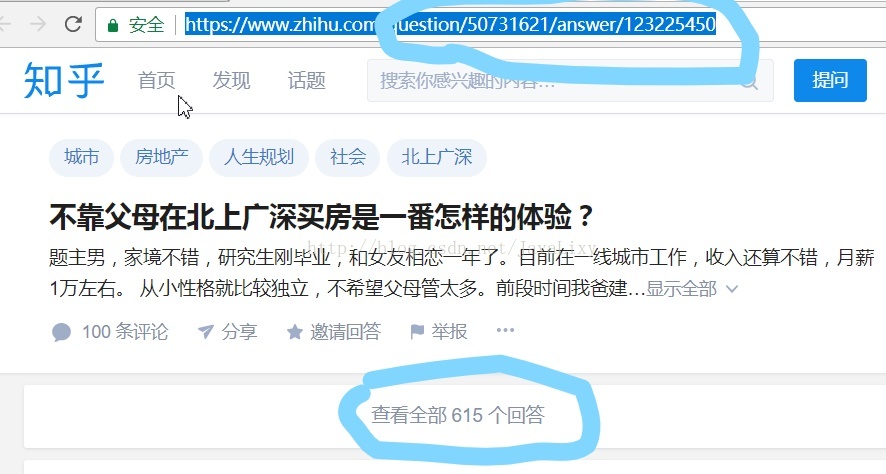
你会发现,回答并没有展开,这在我们后面的回答提取上会有困难,这时在浏览器中输入https://www.zhihu.com/question/50731621/answer/123225450即去掉后缀
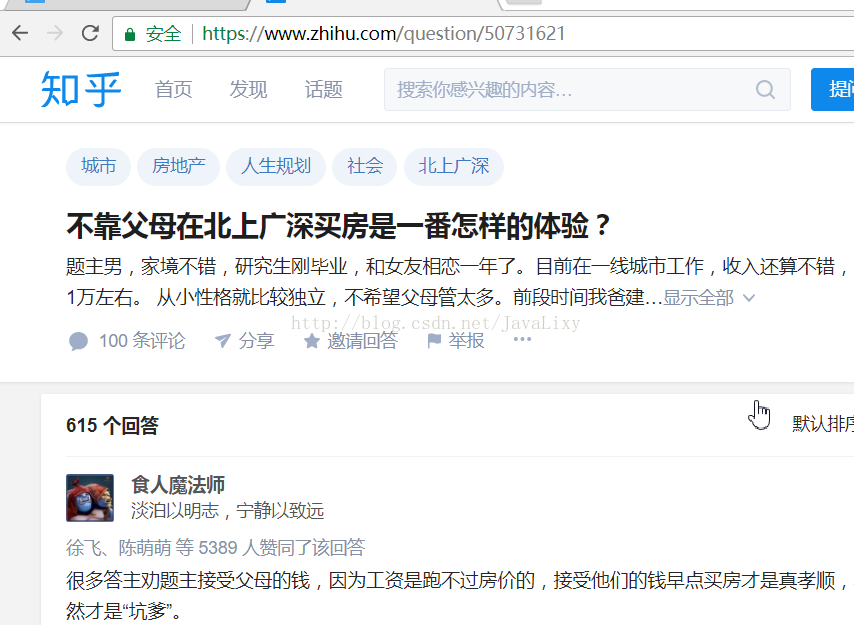
你会发现回答展开了,所以我们的爬取的问题url为https://www.zhihu.com/question/*******格式的,
代码如下:
def parse(self, response):all_urls = response.css("a::attr(href)").extract()all_urls = [parse.urljoin(response.url, url) for url in all_urls]for url in all_urls:# print(url)match_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", url)if match_obj:request_url = match_obj.group(1)yield scrapy.Request(request_url,headers = self.headers,callback=self.parse_question)else:# 如果不是question页面则直接进一步跟踪yield scrapy.Request(url, headers=self.headers, callback=self.parse)上述代码通过正则表达式取出知乎问题url(新版的,答案展开的)
这里讲callback回调给我们的parse_question即处理问题的函数
5.处理问题函数parse_question的创建
在这个函数中我们要获取问题的详细信息,包括问题的id,title,content,url等,这里我们用到scrapy.loader中的itemloader来加载我们的item,这个itemloader可以直接添加我们的css,xpath,十分方便,但是它默认加载的item格式为list,需要对它重载方法取出str,方便我们载入数据库
这里首先在ArticleSpider.items中重载ItemLoader,并创建ZhihuQuestionItem和
ZhihuAnswerItem(后面会用到)
import re
import scrapy
from scrapy.loader.processors import TakeFirst,MapCompose,Join
from scrapy.loader import ItemLoaderdef get_nums(value):#将数字的数据提取出来并转换成int类型match_re = re.match(".*?(\d+).*", value)if match_re:nums = int(match_re.group(1))else:nums = 0return numsclass FirstItemLoader(ItemLoader):#自定义itemloader,继承scrapy的ItemLoader类default_output_processor = TakeFirst()class ZhihuQuestionItem(scrapy.Item):# 知乎的问题itemzhihu_id = scrapy.Field()topics = scrapy.Field(input_processor=Join(","))url = scrapy.Field()title = scrapy.Field()content = scrapy.Field()answer_num = scrapy.Field(input_processor=MapCompose(get_nums))comments_num = scrapy.Field()watch_user_num = scrapy.Field()click_num = scrapy.Field()crawl_time = scrapy.Field()
class ZhihuAnswerItem(scrapy.Item):#知乎的问题回答itemzhihu_id = scrapy.Field()url = scrapy.Field()question_id = scrapy.Field()author_id = scrapy.Field()content = scrapy.Field()parise_num = scrapy.Field()下面创建处理问题的函数from ArticleSpider.items import ZhihuQuestionItem
from ArticleSpider.items import FirstItemLoader
start_answer_url = "https://www.zhihu.com/api/v4/questions/{0}/answers?include=data%5B*%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cupvoted_followees%3Bdata%5B*%5D.mark_infos%5B*%5D.url%3Bdata%5B*%5D.author.follower_count%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={1}&limit={2}&sort_by=default"def parse_question(self,response):#获取文章idmatch_obj = re.match("(.*zhihu.com/question/(\d+))(/|$).*", response.url)if match_obj:question_id = int(match_obj.group(2))#创建item_loader ,需要传入我们的ZhihuQuestionItemitem_loader = FirstItemLoader(item=ZhihuQuestionItem(), response=response)item_loader.add_css("title", "h1.QuestionHeader-title::text")item_loader.add_css("content", ".QuestionHeader-detail")item_loader.add_value("url", response.url)item_loader.add_value("zhihu_id", question_id)item_loader.add_css("answer_num", ".List-headerText span::text")item_loader.add_css("topics", ".QuestionHeader-topics .Popover div::text")question_item = item_loader.load_item()#print(question_item)yield scrapy.Request(self.start_answer_url.format(question_id,0,20),headers=self.headers,callback=self.parse_answer)yield question_item上述有个start_answer_url 是知乎请求回答数据的url,可以通过分析网页提交的url得知,传入的参数(question_id,0,20)即初始数据为 0-20,这个函数回调给parse_answer,并将取到的question_item交给pipeline处理
6.处理回答函数parse_answer的创建
这里首先要搞清楚知乎传给我们的数据为什么格式,都有哪些数据,通过在旧版本的知乎链接https://www.zhihu.com/question/50731621/answer/123225450 中按f12
点击查看全部答案 ,可以见到它传回的response
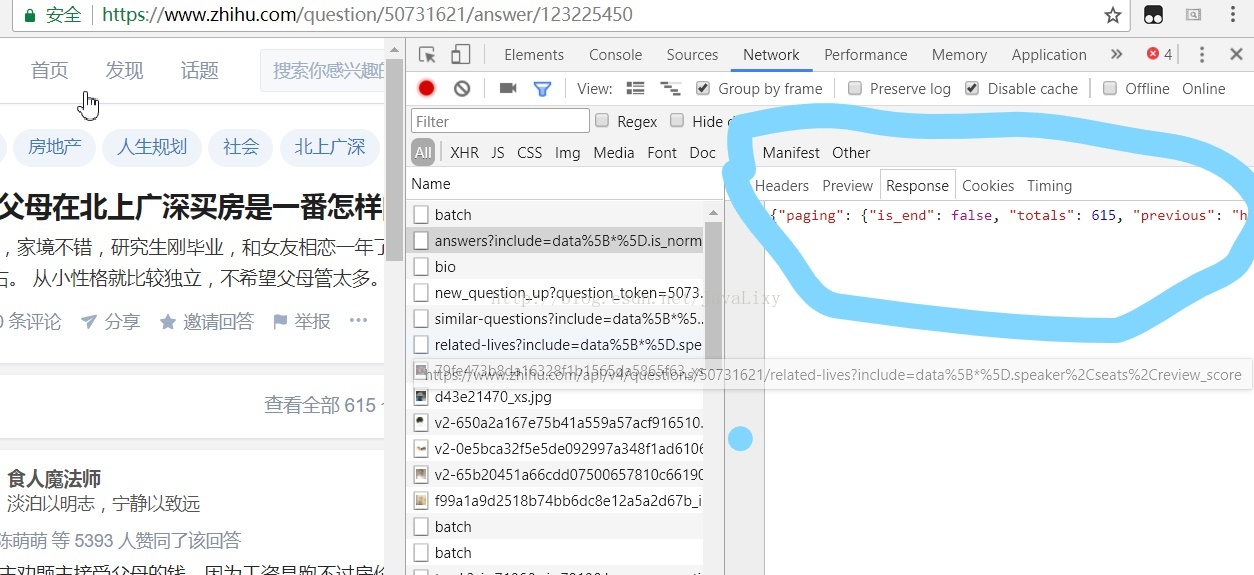
可以看到传回的数据为json格式,在这里还可以看到headers
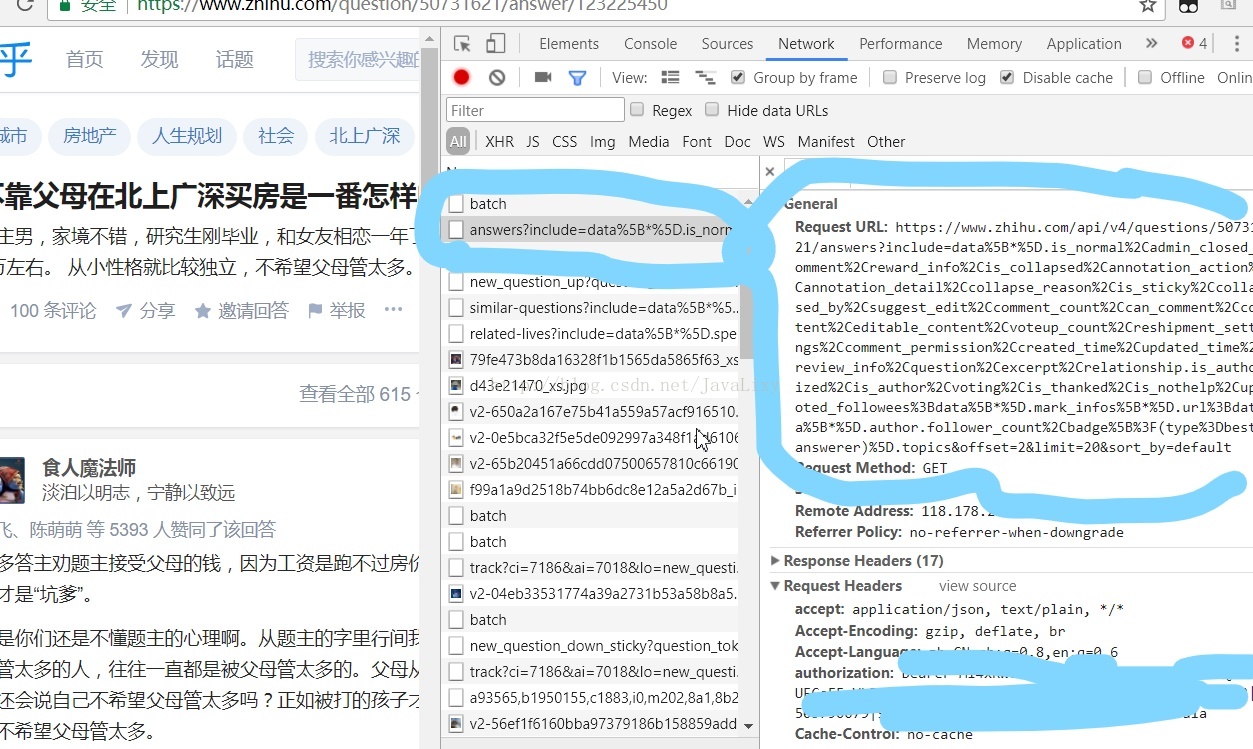
这里的url就是之前我们说的start_answer_url,接下来贴出代码
def parse_answer(self,response):#返回数据为json格式ans_json = json.loads(response.text)is_end = ans_json["paging"]["is_end"]totals_answer = ans_json["paging"]["totals"]next_url = ans_json["paging"]["next"]#提取answer的具体字段for answer in ans_json["data"]:answer_item = ZhihuAnswerItem()answer_item["zhihu_id"] = answer["id"]answer_item["url"] = answer["url"]answer_item["question_id"] = answer["question"]["id"]answer_item["author_id"] = answer["author"]["id"] if "id" in answer["author"] else Noneanswer_item["content"] = answer["content"] if "content" in answer else Noneanswer_item["parise_num"] = answer["voteup_count"]answer_item["comments_num"] = answer["comment_count"]answer_item["create_time"] = answer["created_time"]answer_item["update_time"] = answer["updated_time"]answer_item["crawl_time"] = datetime.datetime.now()print(answer_item)yield answer_item#提取下一个更多answerif not is_end:yield scrapy.Request(next_url,headers=self.headers,callback=self.parse_answer)既然是json数据,当然要用json来加载了,加载出来的item就是str类型,十分方便写入数据库7.在pipelines中将数据写入数据库
首先在setting文件中写入数据库连接信息,还有运行的pipelines(取消注释后加入
MysqlTwistedPipline,后面会说到,是载入mysql的类)
ITEM_PIPELINES = {'ArticleSpider.pipelines.MysqlTwistedPipline': 300,}
MYSQL_HOST = "127.0.0.1"
MYSQL_DBNAME = "article_spider"
MYSQL_USER = "root"
MYSQL_PASSWORD = "root"这里通过twisted的adbapi模块来加载mysqldb,可以将数据库的写入变成异步的(更快)
import MySQLdb
import MySQLdb.cursors
from twisted.enterprise import adbapi
#异步操作数据库
class MysqlTwistedPipline(object):def __init__(self, dbpool):#把dbpool接收到对象中来,数据连接池self.dbpool = dbpool
#写入setting文件,@classmethoddef from_settings(cls, settings):dbparms = dict(host = settings["MYSQL_HOST"],db = settings["MYSQL_DBNAME"],user = settings["MYSQL_USER"],passwd = settings["MYSQL_PASSWORD"],charset='utf8',cursorclass=MySQLdb.cursors.DictCursor,use_unicode=True,)#用mysqldb模块,传入连接数据,首先将参数变成dict,传入时加**为可变长度变量dbpool = adbapi.ConnectionPool("MySQLdb", **dbparms)return cls(dbpool)def process_item(self, item, spider):#使用twisted将mysql插入变成异步执行query = self.dbpool.runInteraction(self.do_insert, item)query.addErrback(self.handle_error) #处理异常def handle_error(self, failure):#处理异步插入的异常print (failure)def do_insert(self, cursor, item):#执行具体的插入#根据不同的item 构建不同的sql语句并插入到mysql中#知乎问题插入mysqlif item.__class__.__name__ == "ZhihuQuestionItem":insert_sql = """insert into zhihu_question(zhihu_id, topics, url, title, content, answer_num)VALUES (%s, %s, %s, %s, %s, %s) """cursor.execute(insert_sql, (item["zhihu_id"], item["topics"],item["url"],item["title"], item["content"],item["answer_num"]))#知乎回答插入if item.__class__.__name__ == "ZhihuAnswerItem":insert_sql = """insert into zhihu_answer(zhihu_id, question_id, url, parise_num, content, author_id)VALUES (%s, %s, %s, %s, %s, %s)"""cursor.execute(insert_sql, (item["zhihu_id"], item["question_id"], item["url"], item["parise_num"], item["content"], item["author_id"]))注意:这里的mysqldb在python3中为mysqlclient
8.在navicat中创建数据库和表
首先创建数据库 article_spider
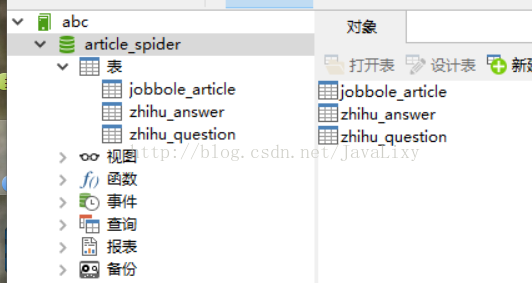
接下来创建问题表
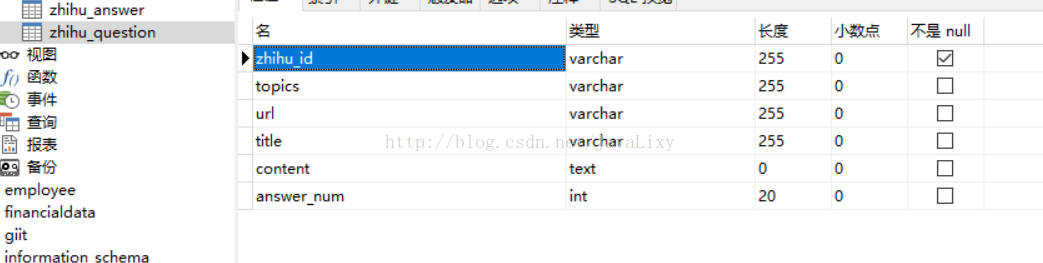
接下来创建回答表
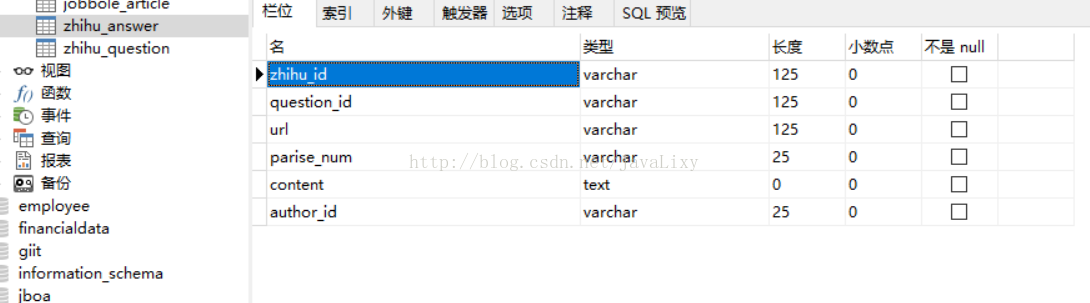
这样就大功告成啦
9.运行
创建main.py,写入
from scrapy.cmdline import executeimport sys
import osprint(os.path.abspath(__file__))
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy","crawl","zhihu"])这样运行main.py就能运行
运行结果: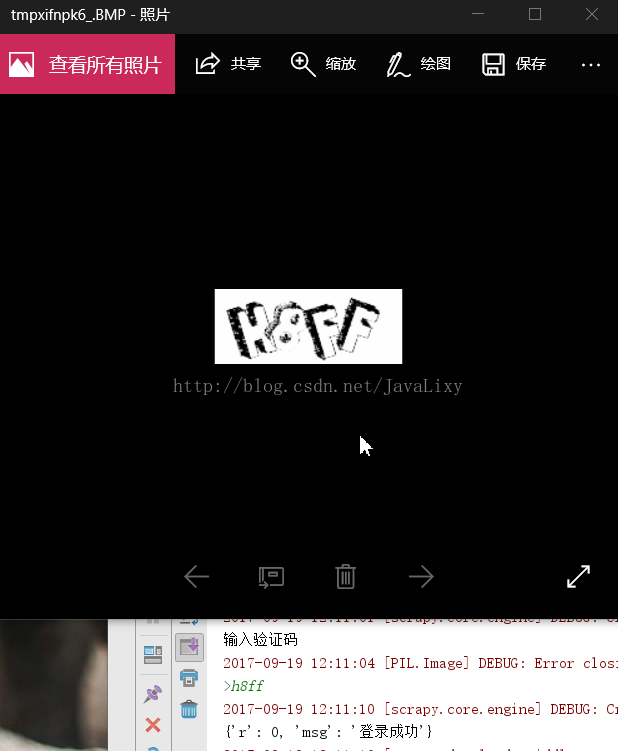


10.后续
这次只是简单的实现知乎的爬取,因为知乎的反爬机制比较成熟,所以常常爬到十几条数据它就会弹出验证码,这样我们的爬虫就无法爬取网站信息,这在后面我会使用自动输入验证码的方法,目前代码比较简陋希望各位亲别介意
此外这次代码量有点大,如果照上面的步骤不能实现的,可以到我的github上下载完整的代码:https://github.com/oldbig-carry/jobbole_spider 这个与之前伯乐在线的代码集合在一起了,可以的话,给个star哦
转载于:https://my.oschina.net/u/1987703/blog/1617546
scrapy初始第二波——爬取知乎首页的问题和回答并写入mysql中相关推荐
- Scrapy实战:爬取知乎用户信息
思路:从一个用户(本例为"张佳玮")出发,来爬取其粉丝,进而爬取其粉丝的粉丝- 先来观察网页结构: 审查元素: 可以看到用户"关注的人"等信息在网页中用json ...
- 爬取知网博硕士文献及中国专利存到mysql数据库中的代码及其注意事项
今天因为需要做了一个爬取知网博硕士论文及中国专利的爬虫,在制作的过程中遇到了不少坑,在网上查资料时都是很老的资源,在现在知网的反爬虫下不起作用,所以我来写这篇文章来供大家参考.(这篇文章主要介绍通过改 ...
- python抽取指定url页面的title_Python使用scrapy爬虫,爬取今日头条首页推荐新闻
爬取今日头条https://www.toutiao.com/首页推荐的新闻,打开网址得到如下界面 查看源代码你会发现 全是js代码,说明今日头条的内容是通过js动态生成的. 用火狐浏览器F12查看得知 ...
- scrapy初始第一波——爬取伯乐在线所有文章
1 前言 要说到爬虫界的明星,当属我们的python,而这得益于我们的爬虫明星框架--scrapy,这就让我们不得不学习它,这几天刚好用它做一些小demo,就将其总结一下,希望能对大家的学习爬虫 ...
- python爬取知乎问题_python爬取知乎首页问题
我的代码如下:importurllib.requestimporthttp.cookiejarurl_a="https://www.zhihu.com/"url_a="h ...
- 平常人可以漂亮到什么程度?教你爬取知乎大神们的回答一探究竟!
大家好,今天才哥带大家看看知乎这个高达14.3万关注,2.6亿浏览,回答数超过1.27万的问题<平常人可以漂亮到什么程度?>. 最近呢,可能是因为写了几篇关于爬虫获取美女照片的文章的缘故? ...
- python爬取丁香园首页疫情json数据,尝试存入mysql数据库
新手练python爬虫 # -*- coding:utf-8 -*- """ 作者:孙敏 日期:2022年01月01日 """ import ...
- python xpath爬取新闻标题_爬取知乎热榜标题和连接 (python,requests,xpath)
用python爬取知乎的热榜,获取标题和链接. 环境和方法:ubantu16.04.python3.requests.xpath 1.用浏览器打开知乎,并登录 2.获取cookie和User-Agen ...
- 以爬取知乎为例,进行python 多进程爬虫性能分析
以爬取知乎为例,进行python 多进程爬虫性能分析 如果对多进程multiproessing模块不熟悉,请先浏览 python 使用multiprocessing模块进行多进程爬虫 问题背景: 爬取 ...
最新文章
- 【linux】Valgrind工具集详解(十四):Cachegrind(缓存和分支预测分析器)
- JavaScript实时更新中国标准时间
- 《Zabbix安装部署-1》-Centos7
- vue前端上传文件夹的插件_基于vue-simple-uploader封装文件分片上传、秒传及断点续传的全局上传插件...
- 花小猪,真正的对手是谁?
- Linux中find命令详解
- JAVA中如何取map的值_如何在java中取map中的键值 的两种方法
- 高光谱遥感数据集下载及简介
- jquery 判断checkbox是否为空的三种方法
- 【原】Storm调度器
- 角度传感器原理和应用
- 过采样之SMOTE算法
- Delphi 字体修改一例 (转)
- android 方法映射,高通Android平台驱动层 MSM8916 键值映射方法
- C#服务端的微信小游戏——多人在线角色扮演(六)
- php开发中常用字符串函数总结
- 种子计数法对种子公司的好处
- ArcGIS for IOS 添加多个覆盖物,并设置点击覆盖物触发委托
- 无为无欲、与世无争,也就没有烦恼......
- 价格为3000元的计算机的机型,2000-3000元左右的笔记本电脑推荐,性价比超高