如何丧心病狂的使用python爬虫读小说

写在前边
其实一直想入门python很久了,慕课网啊,菜鸟教程啊python的基础的知识被我翻了很多遍了,但是一直没有什么实践。刚好,这两天被别人一直安利一本小说《我可能修的是假仙》,还在连载中的,我等屌丝,打钱是不可能打钱的,只好先去网上找一下资源了,基本笔趣阁啊,什么的提供很多在线的资源给我们。好吧,就看这个就行了,可是看也看得不爽啊,,浏览器上下部分都被什么 美女荷官在线发牌,一夜不射提升半小时之类你懂的画面遮盖了,还经常误触,如果是在电脑上看,我们可以用ADBLOCK之类的广告插件屏蔽,可是手机浏览器貌似没有插件啊,那怎么办呢?我可是程序员啊,程序员怎么能向这种问题低头呢?
解决方案
我们把在线网页上的章节名和章节内容都保存下来,造一个离线的版本不就没这个问题了么?
那怎么保存呢,这就需要我们的主角出场了,铛铛铛,python scrapy爬虫框架
关于scrapy
向大家推荐 一个好玩的有趣的牛逼的网站**scrapy中文教程**
这个作者写的很有趣,摘录一下:
本scrapy文档,主要是给诸君介绍一下神马是scrapy,scrapy能干神马,提提大伙的学习热情!scrapy是一个网页爬虫框架,神马叫做爬虫,如果没听说过,那就:内事不知问度娘,外事不决问谷歌,百度或谷歌一下吧!……(这里的省略号代表scrapy很牛逼,基本神马都能爬,包括你喜欢的苍老师……这里就不翻译了)
爬虫代码
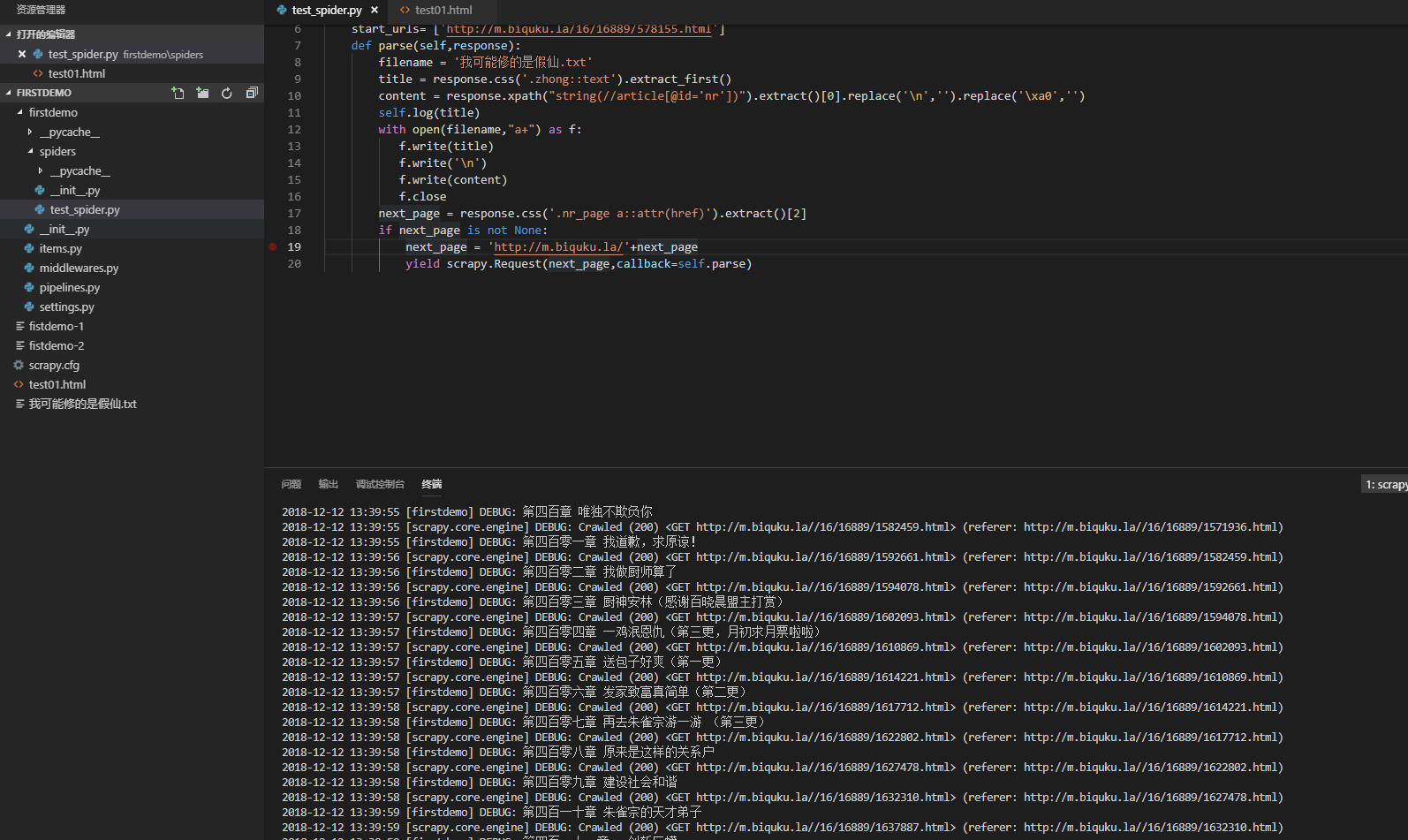
import scrapyclass firstdemo(scrapy.Spider):# 爬虫名称name = 'firstdemo'# 第一页start_urls= ['http://m.biquku.la/16/16889/578155.html']def parse(self,response):filename = '我可能修的是假仙.txt'# 章节名title = response.css('.zhong::text').extract_first()# 章节内容content = response.xpath("string(//article[@id='nr'])").extract()[0].replace('\n','').replace('\xa0','')self.log(title)with open(filename,"a+",encoding='utf-8') as f:f.write(title)# 添加章节目录f.write('\n')# 添加换行(\n)是为了让txt阅读器识别章节目录f.write(content)f.write('\n')f.closenext_page = response.css('.nr_page a::attr(href)').extract()[2]if next_page is not None:next_page = 'http://m.biquku.la'+next_pageyield scrapy.Request(next_page,callback=self.parse)else:self.log('已到最终章节')
没想到吧,代码就这么多,具体的教程可以参见向大家推荐的那个网站。最后我们执行scrapy crawl firstdemo就开始爬取了。
最后
最后?哪里有什么最后?都下载下来了,还不抓紧去看一下我们的战斗成果?
当然还是要提醒诸位,学习为主,不要玩物丧志。
如何丧心病狂的使用python爬虫读小说相关推荐
- python爬虫17K小说网资料
python爬虫17K小说网资料 爬虫作业要求:抓取小说网站为例,必须抓取一系列小说(不是一部小说)的篇名.作者.出版单位(或首发网站).出版时间(或网上发布时间).内容简介.小说封面图画.价格.读者 ...
- python爬虫之小说网站--下载小说(正则表达式)
python爬虫之小说网站--下载小说(正则表达式) 思路: 1.找到要下载的小说首页,打开网页源代码进行分析(例:https://www.kanunu8.com/files/old/2011/244 ...
- 苦逼的Python爬虫抓小说实战
人生苦短,我用python.原来以为用Python抓本小说是小case,但做下来却发现不是所想的那样. 故事从某个人喜欢一本小说开始,头条新闻的大热,居然夹杂了许多小说,某人(真的是亲人!)喜欢某本小 ...
- python爬虫下载小说_用PYTHON爬虫简单爬取网络小说
用PYTHON爬虫简单爬取网络小说. 这里是17K小说网上,随便找了一本小说,名字是<千万大奖>. 里面主要是三个函数: 1.get_download_url() 用于获取该小说的所有章节 ...
- python爬虫下载小说_python 爬取小说并下载的示例
代码 import requests import time from tqdm import tqdm from bs4 import BeautifulSoup """ ...
- Python爬虫中文小说网点查找小说并且保存到txt(含中文乱码处理方法)
从某些网站看小说的时候经常出现垃圾广告,一气之下写个爬虫,把小说链接抓取下来保存到txt,用requests_html全部搞定,代码简单,容易上手. 中间遇到最大的问题就是编码问题,第一抓取下来的小说 ...
- python爬虫-实现小说<战争与和平>中人物出场顺序显示所有人名
目录 开发工具 爬虫分析 爬虫代码 运行效果 总结 开发工具 python版本: python-3.8.1-amd64 python开发工具: JetBrains PyCharm 2018.3.6 x ...
- python爬虫-多线程小说批量下载
# 增加了:1.使面向对象化 2.加入了异常判断,防止程序因报错中断 3.检查txt文件是否存在,如存在,跳过并下载下一个文件 # 增加了:多线程,可同时download多个文件 2018.1.11i ...
- 利用python爬虫下载小说
回想当初自学Python很大一部分原因是想要自己爬数据,今天终于学会了怎么下载小说.于是搞了一波<球状闪电>. 需要用到两个库:requests 和 BeautifulSoup,用 pip ...
最新文章
- spfa 判断负环 (转载)
- mysql(mariadb)常用命令(持续更新ing)
- Realtek24口RTL8382L+RTL8218B+RTL8231方案简介
- 评分怎么读_英国留学本科中途被退学怎么申请硕士补救
- linux之vim怎么跳到指定的一行
- 手写分页 个人感觉还能优化,甚至抽象出来,需要高手讲解
- 十年数据分析经验,总结出这三类分析工具最好用
- ofo 回应假装老外秒退押金;董明珠雷军十亿赌约到期;高通苹果摩擦再升级 | 极客头条...
- 【优化算法】改进型的LMS算法-NLMS算法【含Matlab源码 631期】
- 单片机C语言程序设计实训 100例—基于 8051+Proteus仿真
- 【学习笔记】matlab进行数字信号处理(一)生成信号及信号的时域频域分析
- mysql for centos下载_CentOS下载mysql哪个版本
- go中使用protobuf
- NLP-文本摘要:“文本摘要”综述(Text Summarization)
- Android听筒模式和免提模式的切换
- 30岁人生进度条_你的人生进度条,只剩下最后的1%
- python画美图_用python做个街拍美图手册
- 蚁群算法原理详解和matlab代码
- 计算机测控技术论文,计算机测控技术论文(2)
- 解决Redis K和v 乱码情况 插入整个对象