文本分析——分词技术
---恢复内容开始---
![]()
1.分词:
基于规则的分词方法
- 1)正向最大匹配法(由左到右的方向)
- 2)逆向最大匹配法(由右到左的方向)
- 3)最少切分(使每一句中切出的词数最小)
- 4)双向最大匹配法(进行由左到右、由右到左两次扫描)
基于统计的分词方法中的互信息的运用:反应了字与字之间的紧密程度
![]()
深度学习下:双向LSTM+ CRF
![]()
基于机器学习的方法介绍:HMM & CRF
HMM介绍:
![]()
图:隐马尔可夫模型图解
图中的箭头表示了变量间的依赖关系。在任一时刻,观测变量的取值仅依赖于状态变量,即xi由yi决定,与其他状态变量及观测变量的取值无关。同时,i时刻的状态yi仅依赖于i-1时刻的状态yi-1,与其余n-2个状态无关。这就是所谓的“马尔可夫链”,即:系统下一时刻的状态仅由当前状态决定,不依赖于以往的任何状态。
隐马尔可夫的求解
一般的,一个HMM可以记作一个五元组u=(S, K, A, B, π), 其中S是状态集合,K是输出符号也就是观察集合,A是状态转移概率,B是符号发射概率,π是初始状态的概率分布。HMM主要解决三个基本问题:
- 观测估计问题,给定一个观察序列O=O1,O2,O3,... ,Ot和模型u=(A,B,π),计算观察序列的概率;
- 状态序列问题,给定一个观察序列O=O1,O2,O3... Ot和模型μ=(A, B, π),计算最优的状态序列Q=q1,q2,q3...qt;
- 参数估计问题,给定一个观察序列O=O1,O2,O3... Ot,如何调节模型μ=(A,B, π)的参数,使得P(O|μ)最大。
隐马尔可夫的估计问题可以通过前向/后向的动态规划算法来求解;序列问题可以通过viterbi算法求解;参数估计问题可以通过EM算法求解。通过海量的语料数据,可以方便快速地学习出HMM图模型。
HMM分词方法:
隐马尔可夫的三大问题分别对应了分词中的几个步骤。
- 参数估计问题即是分词的学习阶段,通过海量的语料数据来学习归纳出分词模型的各个参数。
- 状态序列问题是分词的执行阶段,通过观察变量(即待分词句子的序列)来预测出最优的状态序列(分词结构)。
我们设定状态值集合S =(B, M, E, S),分别代表每个状态代表的是该字在词语中的位置,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词;观察值集合K =(所有的汉字);则中文分词的问题就是通过观察序列来预测出最优的状态序列。
比如观察序列为:
O = 小红就职于达观数据
预测的状态序列为:
Q = BEBESBMME
根据这个状态序列我们可以进行切词:
BE/BE/S/BMME/
所以切词结果如下:
小红/就职/于/达观数据/
因为HMM分词算法是基于字的状态(BEMS)来进行分词的,因此很适合用于新词发现,某一个新词只要标记为如“BMME”,就算它没有在历史词典中出现过,HMM分词算法也能将它识别出来。
基于条件随机场的分词算法
条件随机场(Conditional Random Field,简称CRF)是一种判别式无向图模型,它是随机场的一种,常用于标注或分析序列语料,如自然语言文字或是生物序列。
跟隐马尔可夫模型通过联合分布进行建模不同,条件随机场试图对多个变量在给定观测值后的条件概率进行建模。
具体来说,若令x = {x1, x2, …, xn}为观测序列,y = {y1, y2, …, yn}为与之对应的标记序列,则条件随机场的目标是构建条件概率模型P(y | x)。令图G = 表示结点与标记变量y中元素一一对应的无向图,yv表示与结点v对应的标记变量,n(v)表示结点v的邻接结点,如果图G的每个变量yv都满足马尔可夫性,即:
则(y, x)构成一个条件随机场。也就是说, 条件概率只与x和y的邻接结点有关,与其他的y结点没有关系。
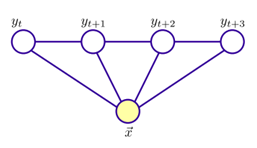
图3:条件随机场模型图解
理论上来说,图G可具有任意结构,只要能表示标记变量之间的条件独立性关系即可。但在现实应用中,尤其是对标记序列建模时,最常用的仍然是上图所示的链式结构,即“链式条件随机场”。
(2) 条件随机场的求解方法
条件随机场使用势函数和图结构上的团来定义条件概率P(y | x)。给定观测序列x,链式条件随机场主要包含两种关于标记变量的团,即单个标记变量{yi}以及相邻的标记变量{yi-1,yi}。在条件随机场中,通过选用合适的势函数,并引入特征函数,可以得到条件概率的定义:
其中:
其中tk(yi - 1, yi, x, i)是定义在观测序列的两个相邻标记位置上的转移特征函数,用于刻画相邻标记变量之间的相关关系以及观测序列对它们的影响,
sj(yi, x, i)是定义在观测序列的标记位置i上的状态特征函数,用于刻画观测序列对标记变量的影响,λk和 为参数,Z为规范化因子。
可以将tk(yi - 1, yi, x, i)和sl(yi, x, i)两个特征函数统一为:fk(yi-1, yi, x, i),则有:
其中:
已知训练数据集,由此可知经验概率分布 ,可以通过极大化训练数据的对数似然函数来求模型参数。加入惩罚项后,训练数据的对数似然函数为:
其中的σ是可以调节的惩罚权重。对似然函数L(w)中的w求偏导,令:
可以依次求出wi。
(3) 条件随机场分词方法
条件随机场和隐马尔可夫一样,也是使用BMES四个状态位来进行分词。以如下句子为例:
中 国 是 泱 泱 大 国
B B B B B B B
M M M M M M M
E E E E E E E
S S S S S S S
条件随机场解码就是在以上由标记组成的数组中搜索一条最优的路径。
我们要把每一个字(即观察变量)对应的每一个状态BMES(即标记变量)的概率都求出来。例如对于观察变量“国”,当前标记变量为E,前一个观察变量为“中”,前一个标记变量为B,则:
t(B, E, ‘国’) 对应到条件随机场里相邻标记变量{yi-1, yi}的势函数:
s(E, ‘国’) 对应到条件随机场里单个标记变量{yi}对应的势函数sl(yi, x, i):
t(B, E, ‘国’), s(E, ‘国’)相应的权值λ、k, 都是由条件随机场用大量的标注语料训练出来。因此分词的标记识别就是求对于各个观察变量,它们的标记变量(BMES)状态序列的概率最大值,即求:
的概率组合最大值。这个解法与隐马尔可夫类似,都是可以用viterbi算法求解。
(4) 条件随机场分词的优缺点
条件随机场分词是一种精度很高的分词方法,它比隐马尔可夫的精度要高,是因为隐马尔可夫假设观察变量xi只与当前状态yi有关,而与其它状态yi-1,yi+1无关;而条件随机场假设了当前观察变量xi与上下文相关,如 ,就是考虑到上一个字标记状态为B时,当前标记状态为E并且输出“国”字的概率。因此通过上下文的分析,条件随机场分词会提升到更高的精度。但因为复杂度比较高,条件随机场一般训练代价都比较大。
---恢复内容结束---
转载于:https://www.cnblogs.com/the-wolf-sky/p/10481860.html
文本分析——分词技术相关推荐
- 文本分析——分词并去停用词返回嵌套列表并保存到本地
文章目录 文本分析分词并去停用词返回嵌套列表 读取文件并进行分词去停用词操作 保存结果到本地 从本地读取结果 文本分析分词并去停用词返回嵌套列表 此代码块用于分词并去停用词(从csv文件转成了txt分 ...
- 互动媒体技术——对十二个“一”的文艺创作作业进行文本分析、统计和可视化
小组成员: 1.1191170412 陈颖 2.1191170413 黄洁 概要 一.文艺创作作业的相关介绍 二.文本分析方法介绍 三.snowNLP库介绍 四.gensim库介绍 五.处理代码展示 ...
- 词干抽取java实现_LinkedIn文本分析平台:主题挖掘的四大技术步骤
LinkedIn前不久发布两篇文章分享了自主研发的 文本分析平台及主题挖掘 文本 在机器学习和自然语言处理等领域,主题挖掘是寻找是主题模型,主题模型是用来在一系列文档中发现抽象主题的一种统计模型.如果 ...
- 【自然语言处理与文本分析】中文分词的基本原理,如何进行词性标注 使用HMM算法提高准确率
分词(中文) 本次内容 分词: N-Gram vs.中文分词 分词的难点 法则式分词 统计式分词 词性标注: 词性标注简介 词性标注的难点 词性的种类及意义 保留某些词性的词 分词: N-Gram v ...
- 文本分析--jieba中文分词
分词技术可以分为英文分词和中文分词: 对于英文分词而言,由于英文单词之间以空格来分隔,所以在进行英文分词的过程中,只需要针对空格进行划分就可以了. 对于中文分词而言,中文单词之 ...
- NLP之TEA:基于SnowNLP实现自然语言处理之对输入文本进行情感分析(分词→词性标注→拼音简繁转换→情感分析→测试)
NLP之TEA:基于SnowNLP实现自然语言处理之对输入文本进行情感分析(分词→词性标注→拼音&简繁转换→情感分析→测试) 目录 NLP分词 NLP词性标注 NLP情感分析-TEA NLP常 ...
- laravel 分词搜索匹配度_SEO除了“中文分词”还有“文本分析”- 搜狗蜘蛛池博客...
原出处:蜘蛛池博客 原文链接:SEO除了"中文分词"还有"文本分析" - 蜘蛛池博客 对于刚入职的SEO人员,日常工作中,我们很少谈论"中文分词&qu ...
- ik分词和jieba分词哪个好_Python 中文 文本分析 实战:jieba分词+自定义词典补充+停用词词库补充+词频统计...
最近项目需要,实现文本的词频分析,折腾了几天才完成任务,有点成就感,最后整理总结一下这部分的内容,希望更多同僚受益. 一.使用前准备 环境:Python3.6 安装结巴:pip install ji ...
- IRIS 2021 技术文档 First Look 30 -- 使用 InterSystems 产品进行文本分析
本技术概览( First Look )介绍了 InterSystems IRIS® 数据平台 支持使用 Natural Language Processing(NLP,自然语言处理 )文本分析的能力, ...
最新文章
- I.MX6 android 源码下载
- 关于appstore多语言版本,不可不看!
- python发邮件给女朋友代码_python实现邮件发送完整代码(带附件发送方式)
- 51单片机如何用c语言位定义,嵌入式编程(一):51单片机如何将函数 定义到指定程序地址...
- P2661 信息传递 二分图的最小环
- 韩国小哥哥用Pytorch实现谷歌最强NLP预训练模型BERT | 代码
- Zookeeper的Leader选举
- SpringBoot使用thymefeal出现No mapping for GET /xxx的解决办法
- python行数据转列数据_python – 如何转换数据框,以便列值是行值
- java无法使用_在cmd中无法使用java命令的解决方法
- 解决:Assign object to a variable before exporting as module default
- 4G全网通模块 安卓 高通骁龙MSM8909核心板 开发板
- 【C++】重定义,重载,重写
- python常见容器操作:字符串的增删改查循环、列表的增删改查循环、元组的查循环、字典的的增删改查循环等常规操作
- 机器学习西瓜书-代价曲线
- IPFS DHT专题:去中心化搜索的架构演进
- 分布式动态路由的实现
- python openpyxl 新建 excel xlsx
- b站选择HTML5播放器,b站用什么播放器看片好?选择硬解还是软解?看本地视频首选哪一个?...
- Exchange 2016就地存档