流式处理 术语解释 Exactly-once与Effectively-once
分布式事件流处理已逐渐成为大数据领域的热点话题。该领域主要的流处理引擎(SPE)包括 Apache Storm、Apache Flink、Heron、Apache Kafka(Kafka Streams)以及 Apache Spark(Spark Streaming)等。处理语义是围绕 SPE 最受关注,讨论最多的话题之一,其中“严格一次(Exactly-once)”是很多引擎追求的目标之一,很多 SPE 均宣称可提供“严格一次”的处理语义。
然而“严格一次”具体指什么,需要具备哪些能力,当 SPE 宣称可支持时这实际上意味着什么,对于这些问题还有很多误解和歧义。使用“严格一次”来描述处理语义,这本身也容易造成误导。本文将探讨各大主要 SPE 在“严格一次”处理语义方面的差异,以及为什么“严格一次”更适合称之为“实际一次(Effectively-once)”。同时本文还将探讨在实现所谓“严格一次”的语义过程中,各类常用技术之间需要进行的取舍。
背景
流处理通常也被称之为事件处理,简单来说是指持续不断地处理一系列无穷无尽地数据或事件地过程。流处理或事件处理应用程序大致可以看作一种有向图(Directed graph),大部分情况(但也并非总是如此)下也可以看作有向非循环图(Directed acyclic graph,DAG)。在这种图中,每个边缘(Edge)可代表一个数据或事件流,每个顶点(Vertex)代表使用应用程序定义的逻辑处理来自相邻边缘的数据或事件的运算符(Operator)。有两种特殊类型的顶点,通常称之为 Source 和 Sink,Source 会消耗外部数据 / 事件并将其注入应用程序,而 Sink 通常负责收集应用程序生成的结果。图 1 展示了这样的一个流应用程序范例。
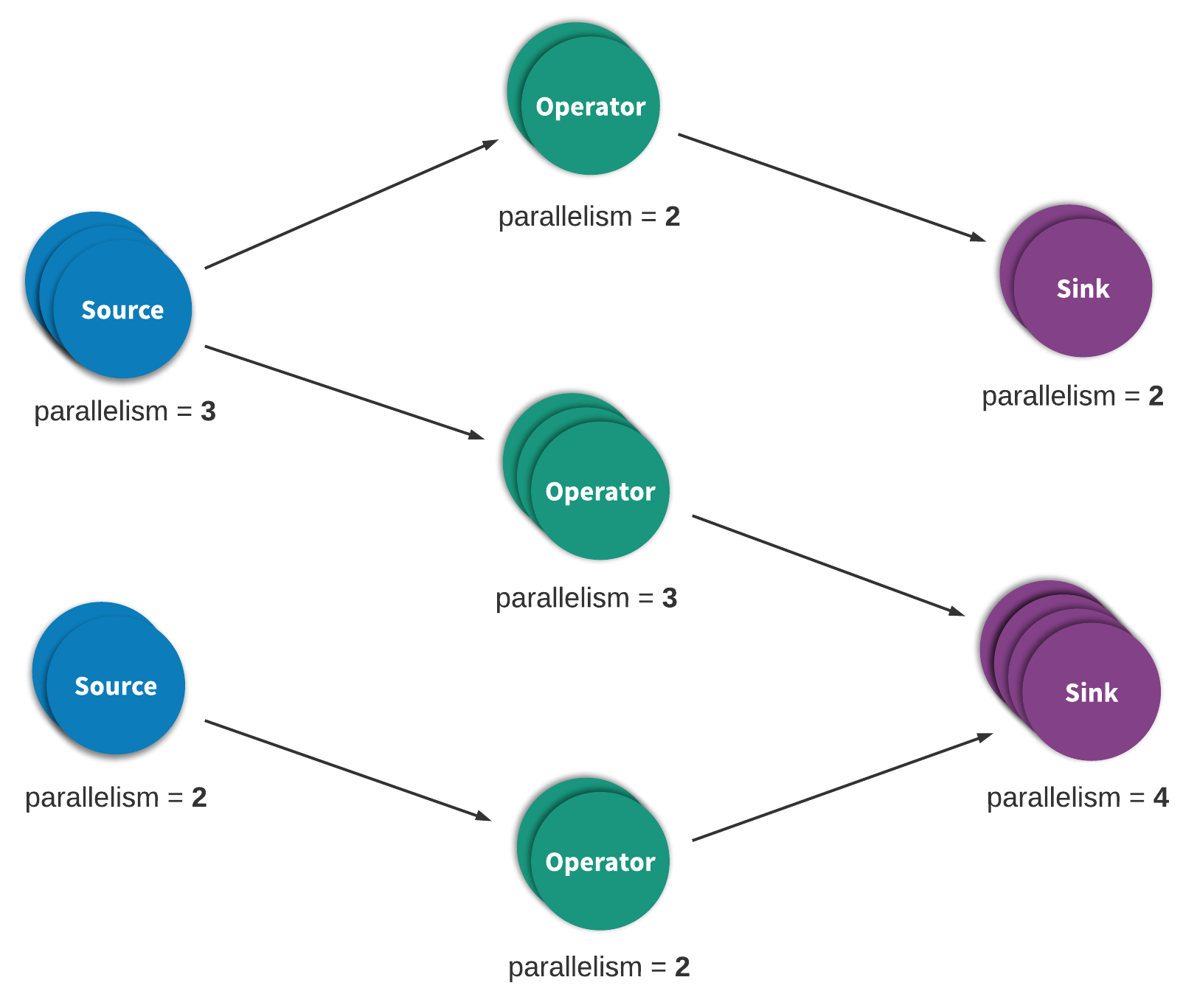
图 1:一个典型的 Heron 处理拓扑
执行流 / 事件处理应用程序的 SPE 通常可供用户指定可靠性模式或处理语义,这代表了在跨越整个应用程序图处理数据时所能提供的保证。这些保证是有一定意义的,因为我们始终可以假设由于网络、计算机等原因遇到失败进而导致数据丢失的概率。在描述 SPE 能为应用程序提供的数据处理语义时,通常会使用三种模式 / 标签:最多一次(At-most-once)、最少一次(At-least-once),以及严格一次(Exactly-once)。
这些不同处理语义可粗略理解如下:
最多一次
这其实是一种“尽力而为”的方法。数据或事件可以保证被应用程序中的所有运算符最多处理一次。这意味着如果在流应用程序最终成功处理之前就已丢失,则不会额外试图重试或重新传输事件。图 2 列举了一个范例。

图 2:最多一次处理语义
最少一次
数据或事件可保证被应用程序图中的所有运算符最少处理一次。这通常意味着如果在流应用程序最终成功处理之前就已丢失,那么事件将从来源重播(Replayed)或重新传输。然而因为可以重新传输,有时候一个事件可能被多次处理,因此这种方式被称之为“最少一次”。图 3 展示了一个范例。在本例中,第一个运算符最初处理事件时失败了,随后重试并成功,随后再次重试并再次成功,然而再次重试实际上是不必要的。
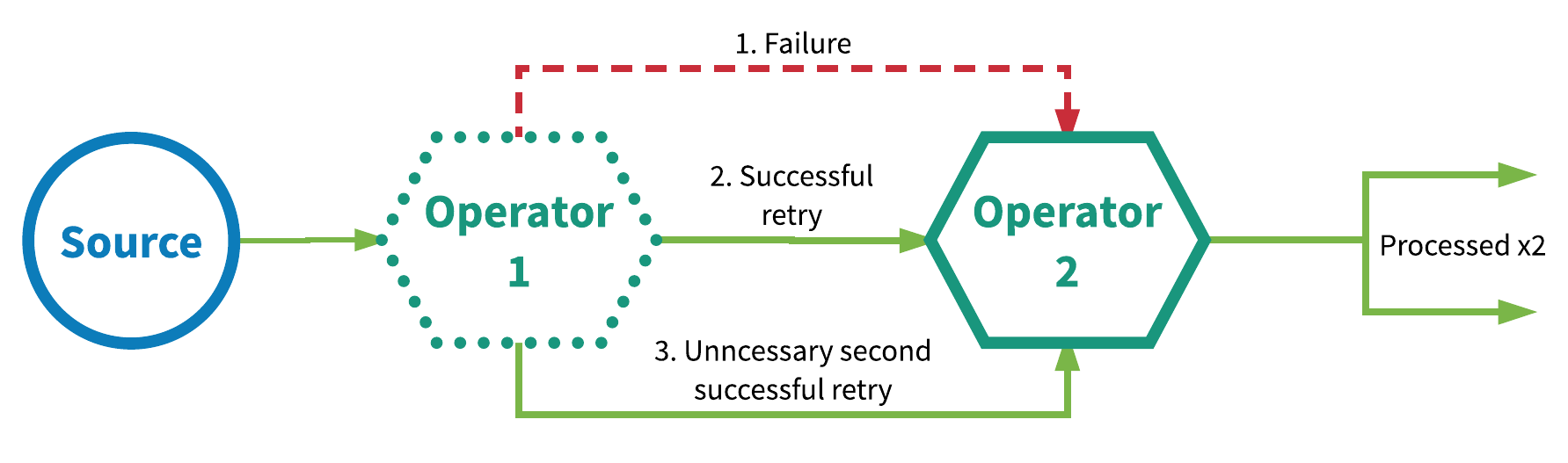
图 3:最少一次处理语义
严格一次
事件可保证被流应用程序中的所有运算符“严格一次”处理,哪怕遇到各种失败。
为了实现“严格一次”处理语义,通常主要会使用下列两种机制:
- 分布式快照 / 状态检查点
- 最少一次事件交付,外加消息去重
通过分布式快照 / 状态检查点方法实现的“严格一次”是由 Chandy-Lamport 分布式快照算法[1]启发而来的。在这种机制中,会定期为流应用程序中每个运算符的所有状态创建检查点,一旦系统中任何位置出现失败,每个运算符的所有状态会回滚至最新的全局一致检查点。回滚过程中所有处理工作会暂停。随后源也会重置为与最新检查点相符的偏移量。整个流应用程序基本上会被“倒带”到最新一致状态,并从该状态开始重新处理。图 4 展示了这种机制的一些基本概念。
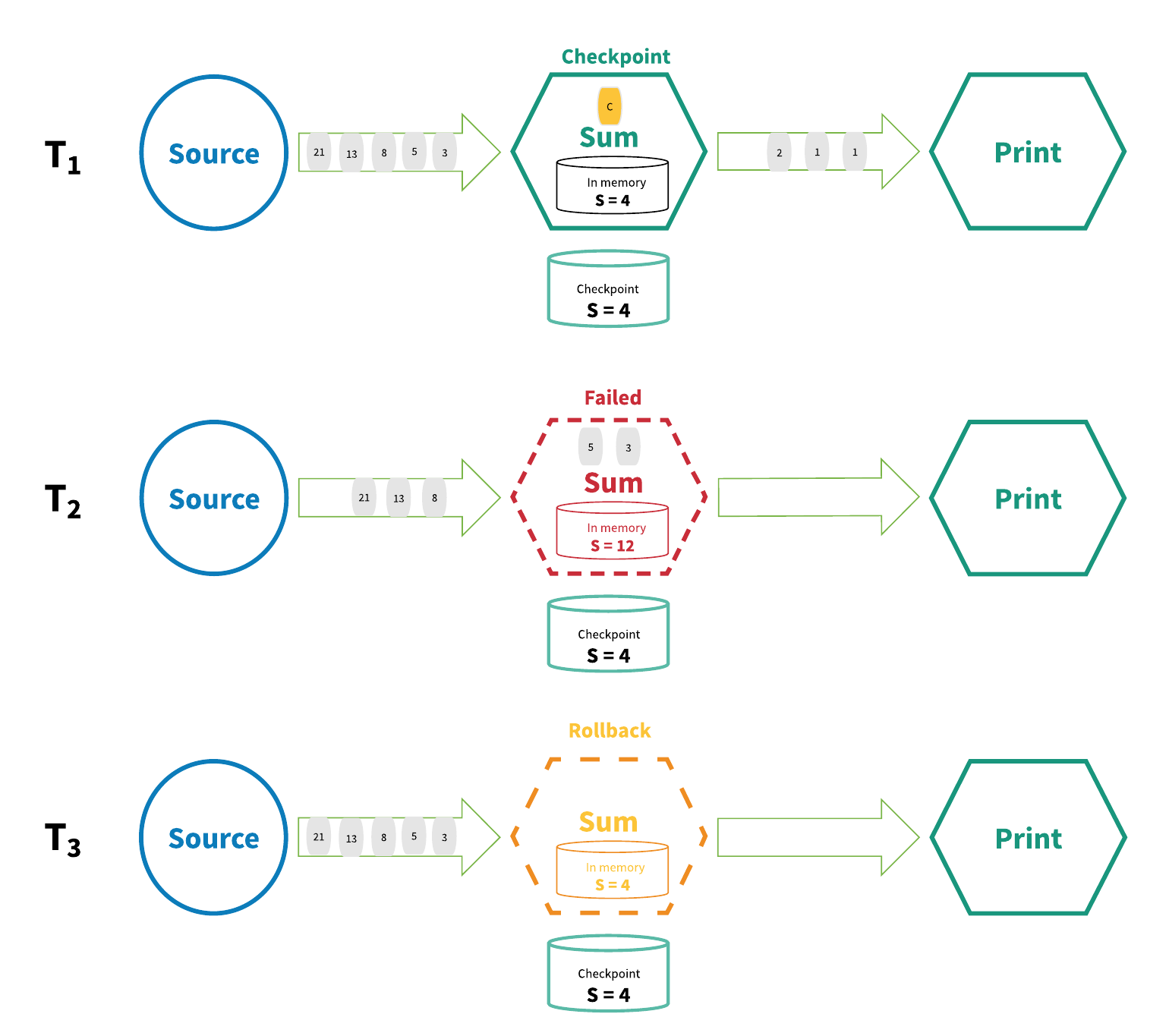
图 4:分布式快照
在图 4 中,流应用程序在 T1 时正在正常运行,并创建了状态检查点。然而在 T2 时,运算符在处理传入的数据时失败了。此时 S = 4 这个状态值已经被保存到持久存储中,而 S = 12 状态值正位于运算符的内存中。为了调和这种矛盾,在 T3 时处理图将状态回退至 S = 4,并“重播”了流中直至最新状态前每个连续的状态,并处理了每个数据。最终结果是有些数据被处理了多次,但这也没问题,因为无论回滚多少次,结果状态都是相同的。
实现“严格一致”的另一种方法是在实现至少一次事件交付的同时在每个运算符一端进行事件去重。使用这种方法的 SPE 会重播失败的事件并再次尝试处理,并从每个运算符中移除重复的事件,随后才将结果事件发送给用户在运算符中定义的逻辑。这种机制要求为每个运算符保存事务日志,借此才能追踪哪些事件已经处理过了。为此 SPE 通常会使用诸如 Google 的 MillWheel[2]以及Apache Kafka Streams等机制。图 5 展示了这种机制的概况。
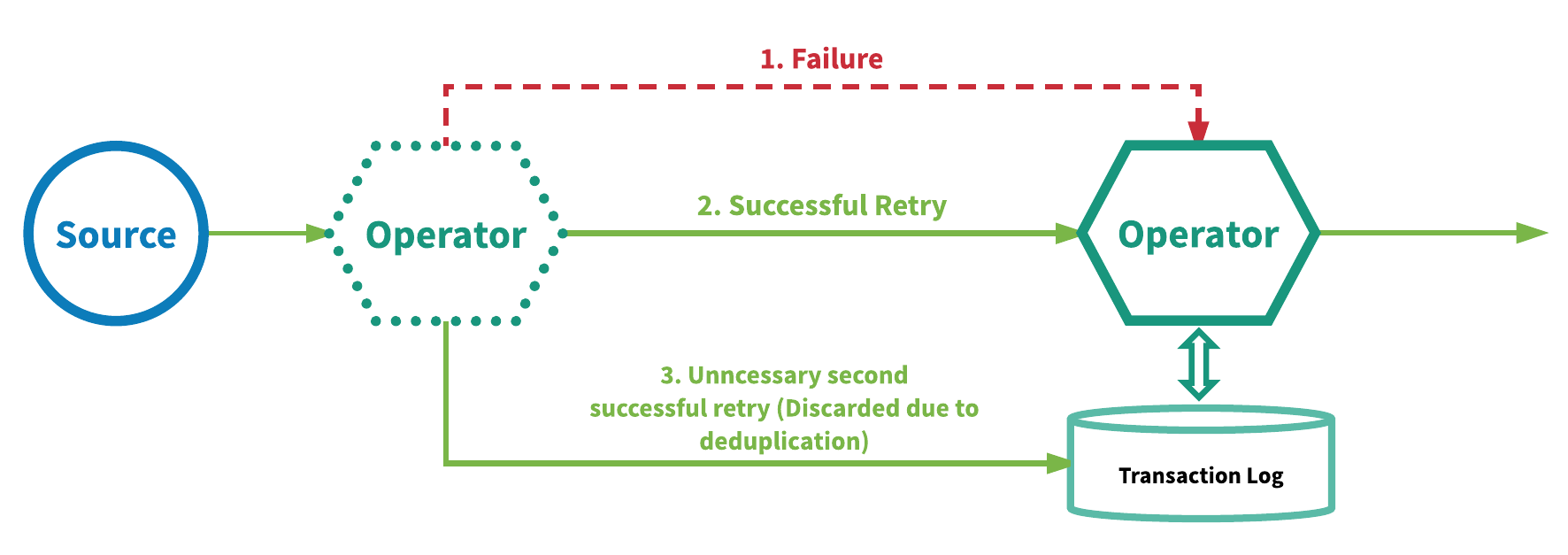
图 5:至少一次交付外加去重
严格一次真的就一次吗?
接着重新考虑一下“严格一次”处理语义实际上能为最终用户提供怎样的保证。“严格一次”这样的标签对于到底什么只执行一次其实起到了一定的误导效果。
有些人可能认为“严格一次”描述了一种保证:在事件处理过程中,流中的每个事件只被处理一次。实际上任何 SPE 都不能完全保证真的只处理一次。面对各种可能的失败,根本不可能保证每个运算符中包含的,由用户定义的逻辑针对每个事件只执行一次,因为用户代码的不完整执行(Partial execution)这种可能性始终会出现。
假设这样一个场景:有个流处理运算符需要执行 Map 操作输出传入事件的 ID,随后返回无改变的事件。例如这个操作可能使用了如下的虚构代码:
复制代码
|
|
|
|
|
|
|
|
|
|
|
每个事件有自己的 GUID(全局唯一 ID)。如果用户逻辑的严格一次执行可以得到保证,那么事件 ID 将只输出一次。然而这一点永远无法保证,因为用户定义的逻辑执行过程中可能随时随地发生失败。SPE 无法自行判断用户定义的处理逻辑到底执行到哪一步了。因此任何用户定义的逻辑都无法保证只执行一次。这也意味着用户定义逻辑中实现的外部操作,例如数据库写入也无法严格保证只执行一次。此类操作依然需要通过幂等的方式实现。
那么当 SPE 宣称提供“严格一次”的处理语义保证时,它们指的到底是什么?如果用户逻辑无法严格保证只执行一次,那么到底是什么东西只执行了一次?当 SPE 宣称“严格一次”处理语义时,它们真正的含义在于可以保证在对 SPE 管理的状态进行更新时,可以只向后端的持久存储提交一次。
上文提到的两种机制均使用持久的后端存储作为事实来源(Source of truth),用于保存每个操作符的状态,并自动提交状态更新。对于机制 1(分布式快照 / 状态检查点),这个持久的后端存储可用于保存流应用程序中全局一致的状态检查点(每个运算符的状态检查点);对于机制 2(至少一次事件交付,外加去重),这个持久的后端存储可用于保存每个运算符的状态,以及为了追踪哪些事件已经被成功处理过而为每个运算符生成的事务日志。
状态的提交或对事实来源的持久后端进行的更新可描述为事件(Occurring)的严格一次。然而在计算状态的更新 / 改动,例如所处理的事件正在针对事件执行各种用户定义的逻辑时,如果失败则可能进行多次,这一点正如上文所述。换句话说,事件的处理可能会进行多次,但处理的最终结果只会在持久的后端状态存储中体现一次。因此 Streamlio 认为“实际一次(Effectively-once)”可以更精确地描述这样地处理语义。
分布式快照,与至少一次事件交付外加去重机制的对比
从语义的角度来看,分布式快照,以及至少一次事件交付外加去重,这两种机制可以提供相同的保证。然而由于两种机制在实现方面的差异,可能会对性能产生巨大的影响。
基于机制 1(分布式快照 / 状态检查点)的 SPE 在性能方面的开销可能是最低的,因为基本上,SPE 只需要在通过流应用程序照常处理事件的过程之外发送少量特殊事件,而状态检查点操作可以在后台以异步的方式进行。但是对于大型流应用程序,失败的概率将会更高,这会导致 SPE 需要暂停应用程序并回滚所有操作符的状态,这会对性能产生较大影响。流应用程序规模越大,遇到失败的频率就会越高,因此性能方面受到的影响也会越大。然而需要再次提醒的是,这种机制是非侵入式的,只会对资源的使用造成最少量的影响。
机制 2(至少一次事件交付外加去重)可能需要更多资源,尤其是存储资源。在这种机制中,SPE 需要能追踪已经被运算符的每个实例成功处理的每个元组(Tuple),借此才能执行去重并实现自身在每个事件中的去重。这可能需要追踪非常大量的数据,尤其是当流应用程序规模非常大,或运行了很多应用程序的时候。每个运算符中的每个事件执行去重操作,这本身也会产生巨大的性能开销。然而对于这种机制,流应用程序的性能不太可能受到应用程序规模的影响。对于机制 1,如果任何运算符遇到任何失败,均需要全局暂停并状态回滚;对于机制 2,失败只能影响到局部。如果某个运算符遇到失败,只需要从上游来源重播 / 重新传输尚未成功处理的事件,对性能的影响可隔离在流应用程序中实际发生失败的地方,只会对流应用程序中其他运算符的性能产生最少量的影响。从性能的角度来看,两种机制各有利弊,具体情况可参阅下文表格。
分布式快照 / 状态检查点
| 利 | 弊 |
|---|---|
| 性能和资源开销小 | 从失败中恢复时的性能影响大 |
| 随着拓扑规模逐渐增大,对性能的潜在影响将增高 |
至少一次交付外加去重
| 利 | 弊 |
|---|---|
| 失败对性能的影响更为局部 | 可能需要存储与基础架构提供更多支持 |
| 失败的影响未必随着拓扑规模一起增加 | 每个运算符处理每个事件均会产生性能开销 |
虽然从理论上看,分布式快照,和至少一次事件交付外加去重,这两种机制之间存在差异,但两者均可理解为至少一次处理外加幂等。对于这两种机制,如果遇到失败事件将会重播 / 重新传输(为了实现至少一次),而在状态回滚或事件去重时,如果从内部更新所管理的状态,运算符实际上将具备幂等的特性。
结论
希望本文可以帮助大家意识到“严格一次”这个术语极具误导性。提供“严格一次”的处理语义实际上意味着在对流处理引擎所管理的运算符的状态进行各种更新后,结果将仅体现一次。“严格一次”完全无法保证事件的处理(例如执行各类用户定义的逻辑)只需要进行一次。因此 Streamlio 更愿意使用“最终一次”这个属于来描述这种保证,因为没必要确保处理工作只进行一次,只要保证由 SPE 管理的状态的最终结果只体现一次就够了。分布式快照和消息去重,这两种主流机制就是为了实现严格 / 实际一次的处理语义。在消息处理和状态更新方面,这两种机制均可提供相同的语义保证,但在性能方面可能有所差异。本文并不是为了探讨哪种机制更胜一筹,因为每种机制都各有利弊。
流式处理 术语解释 Exactly-once与Effectively-once相关推荐
- 完美解释:wenet-流式与非流式语音识别统一模型
Unified Streaming and Non-streaming Two-pass End-to-end Model for Speech Recognition[1] ,本文以该篇论文为主线, ...
- 大数据凉了?No,流式计算浪潮才刚刚开始!
AI 前线导读:本文重点讨论了大数据系统发展的历史轨迹,行文轻松活泼,内容通俗易懂,是一篇茶余饭后用来作为大数据谈资的不严肃说明文.本文翻译自<Streaming System>最后一章& ...
- 编程范式:函数式编程防御式编程响应式编程契约式编程流式编程
不长的编码生涯,看到无数概念和词汇:面向对象编程.过程式编程.指令式编程.函数式编程.防御式编程.流式编程.响应式编程.契约式编程.进攻式编程.声明式编程--有种生无可恋的感觉. 本文试图加以汇总和整 ...
- 物流仓储行业专业术语解释
一.五大管理系统 OMS 订单管理系统(Order Management System)是对客户下达的订单进行管理及跟踪,同时把处理后的订单指令通过EDI接口传送至仓储管理系统(WMS)或车辆调度系统 ...
- Flink系列之Flink流式计算引擎基础理论
声明: 文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除.感谢.转载请注明出处,感谢. By luoye ...
- 网络存储设备磁带机术语解释
1.存储容量 存储容量是指在数据未被压缩前磁带机所能存储的最大数据量.这个数值取决于两个因素,一是单盒磁带的存储容量,二是磁带机所能容纳的磁带数目.由于磁带机采用多种不同的备份技术所以存储 ...
- 小白学习Flink系列--第二篇-01(流式数据概念)
导读 要想彻底理解Flink,就要了解流数据的前世今生,流数据的语义.特点,以及如何处理,以下文章就能很好的解释流数据的概念和模型,对了解Flink有很大的帮助 前言 今天流式数据处理在大数据领域是一 ...
- java 数据库 流式查询_关于mybatis:强大MyBatis-三种流式查询方法
基本概念 流式查问指的是查问胜利后不是返回一个汇合而是返回一个迭代器,利用每次从迭代器取一条查问后果.流式查问的益处是可能升高内存应用. [腾讯云]云产品限时秒杀,爆款1核2G云服务器,首年99元 如 ...
- 基于流式的md5计算-多线程下载工具Lwget介绍
在数据传输的时候,我们希望实现以下目标: 1. 使用多线程传输,加速下载速度 2. 数据在传输过程中,进行流式md5计算,避免在传输完毕之后校验大文件 3. 支持断点续传 4. 支持http协议和ft ...
最新文章
- 用人工智能打击人工智能
- stream流【java8 二】
- C++for循环中i++与++i的区别
- pycharm在创建py文件时如何自动注释
- Swift的控制转移语句--continue语句
- Rust基础概念之函数
- 模型压缩_模型压缩:
- mysql 联合索引底层结构_MySQL联合索引底层数据结构
- php数组和字符串转换
- VS2010 SP1安装卡在VS10Sp1-KB983509处的解决(转)
- ENSP之STP协议基本配置教程
- react ssr php,从零开始搭建React同构应用(三):配置SSR
- vue2 数据回显取消编辑不修改原数据
- 程序语言的自我意识与仿他意识
- TF_REPEATED_DATA ignoring data with redundant timestamp for frame left_wheel at time
- 2022全新抖音取图表情包小程序+创作者入驻+流量主
- 安卓studio 添加后台bgm音乐的几种方法
- 华为机试真题 Java 实现【数字涂色】
- iOS资源帖-优秀博客、iOS开发技术文、学习网站
- lc用U盘更新固件_U盘故障修复实践