Cowboy 2.6 User Guide 中英文对照版【翻译】
The modern Web
Cowboy is a server for the modern Web. This chapter explains what it means and details all the standards involved.
Cowboy是现代Web的服务器。本章将解释其含义,并详细介绍所有涉及的标准。
Cowboy supports all the standards listed in this document.
Cowboy支持本文档中列出的所有标准。
HTTP/2
HTTP/2 is the most efficient protocol for consuming Web services. It enables clients to keep a connection open for long periods of time; to send requests concurrently; to reduce the size of requests through HTTP headers compression; and more. The protocol is binary, greatly reducing the resources needed to parse it.
HTTP / 2是使用Web服务的最有效协议。它使客户端可以长时间保持连接打开;同时发送请求;通过HTTP标头压缩来减少请求的大小;和更多。该协议是二进制的,大大减少了解析它所需的资源
HTTP/2 also enables the server to push messages to the client. This can be used for various purposes, including the sending of related resources before the client requests them, in an effort to reduce latency. This can also be used to enable bidirectional communication.
Cowboy provides transparent support for HTTP/2. Clients that know it can use it; others fall back to HTTP/1.1 automatically.
HTTP / 2还使服务器能够将消息推送到客户端。这可以用于各种目的,包括在客户端请求资源之前发送相关资源,以减少延迟。这也可用于启用双向通信。
HTTP/2 is compatible with the HTTP/1.1 semantics.
HTTP/2 is defined by RFC 7540 and RFC 7541.
HTTP / 2与HTTP / 1.1语义兼容。
HTTP / 2由RFC 7540和RFC 7541定义。
HTTP/1.1
HTTP/1.1 is the previous version of the HTTP protocol. The protocol itself is text-based and suffers from numerous issues and limitations. In particular it is not possible to execute requests concurrently (though pipelining is sometimes possible), and it's also sometimes difficult to detect that a client disconnected.
HTTP / 1.1是HTTP协议的先前版本。该协议本身是基于文本的,并且存在许多问题和限制。特别是不可能同时执行请求(尽管有时可以进行流水线操作),并且有时也很难检测到客户端已断开连接。
HTTP/1.1 does provide very good semantics for interacting with Web services. It defines the standard methods, headers and status codes used by HTTP/1.1 and HTTP/2 clients and servers.
HTTP / 1.1确实为与Web服务交互提供了非常好的语义。它定义了HTTP / 1.1和HTTP / 2客户端和服务器使用的标准方法,标头和状态代码。
HTTP/1.1 also defines compatibility with an older version of the protocol, HTTP/1.0, which was never really standardized across implementations.
HTTP / 1.1还定义了与旧版本协议HTTP / 1.0的兼容性,该协议从未在所有实现中真正标准化。
The core of HTTP/1.1 is defined by RFC 7230, RFC 7231, RFC 7232, RFC 7233, RFC 7234 and RFC 7235. Numerous RFCs and other specifications exist defining additional HTTP methods, status codes, headers or semantics.
HTTP / 1.1的核心由RFC 7230,RFC 7231,RFC 7232,RFC 7233,RFC 7234和RFC 7235定义。存在许多RFC和其他规范,用于定义其他HTTP方法,状态代码,标头或语义。
Websocket
Websocket is a protocol built on top of HTTP/1.1 that provides a two-ways communication channel between the client and the server. Communication is asynchronous and can occur concurrently.
Websocket是建立在HTTP / 1.1之上的协议,该协议在客户端和服务器之间提供双向通信通道。通信是异步的,可以同时发生
It consists of a Javascript object allowing setting up a Websocket connection to the server, and a binary based protocol for sending data to the server or the client.
它由允许建立与服务器的Websocket连接的Javascript对象和用于将数据发送到服务器或客户端的基于二进制的协议组成。
Websocket connections can transfer either UTF-8 encoded text data or binary data. The protocol also includes support for implementing a ping/pong mechanism, allowing the server and the client to have more confidence that the connection is still alive.
Websocket连接可以传输UTF-8编码的文本数据或二进制数据。该协议还包括对实现ping / pong机制的支持,从而使服务器和客户端可以更有信心地确定连接仍然有效。
A Websocket connection can be used to transfer any kind of data, small or big, text or binary. Because of this Websocket is sometimes used for communication between systems.
Websocket连接可用于传输任何类型的数据,无论大小,文本或二进制。因此,Websocket有时用于系统之间的通信。
Websocket messages have no semantics on their own. Websocket is closer to TCP in that aspect, and requires you to design and implement your own protocol on top of it; or adapt an existing protocol to Websocket.
Websocket消息本身没有语义。 Websocket在这方面更接近于TCP,并且要求您在它之上设计和实现自己的协议。或使现有协议适应Websocket。
Cowboy provides an interface known as Websocket handlers that gives complete control over a Websocket connection.
Cowboy提供了一个称为Websocket处理程序的接口,该接口可以完全控制Websocket连接。
The Websocket protocol is defined by RFC 6455.
Websocket协议由RFC 6455定义。
Long-lived requests 长期存在的请求
Cowboy provides an interface that can be used to support long-polling or to stream large amounts of data reliably, including using Server-Sent Events.
Cowboy提供的接口可用于支持长轮询或可靠地流式传输大量数据,包括使用服务器发送事件。
Long-polling is a mechanism in which the client performs a request which may not be immediately answered by the server. It allows clients to request resources that may not currently exist, but are expected to be created soon, and which will be returned as soon as they are.
长轮询是一种机制,其中客户端执行请求,服务器可能不会立即对其进行答复。它允许客户端请求当前可能不存在但预期将很快创建的资源,并将立即返回这些资源。
Long-polling is essentially a hack, but it is widely used to overcome limitations on older clients and servers.
长轮询本质上是一种hack,但是它被广泛用于克服对旧客户端和服务器的限制。
Server-Sent Events is a small protocol defined as a media type, text/event-stream, along with a new HTTP header, Last-Event-ID. It is defined in the EventSource W3C specification.
服务器发送事件是一种小型协议,定义为媒体类型,文本/事件流以及新的HTTP标头Last-Event-ID。它在EventSource W3C规范中定义。
Cowboy provides an interface known as loop handlers that facilitates the implementation of long-polling or stream mechanisms. It works regardless of the underlying protocol.
Cowboy提供了一个称为循环处理程序的接口,该接口有助于实现长轮询或流机制。无论底层协议如何,它都可以工作。
REST
REST, or REpresentational State Transfer, is a style of architecture for loosely connected distributed systems. It can easily be implemented on top of HTTP.
REST is essentially a set of constraints to be followed. Many of these constraints are purely architectural and solved by simply using HTTP. Some constraints must be explicitly followed by the developer.
REST或表示性状态转移是一种用于松散连接的分布式系统的体系结构样式。它可以轻松地在HTTP之上实现。 REST本质上是要遵循的一组约束。这些约束中的许多都是纯粹的体系结构,只需使用HTTP即可解决。开发人员必须明确遵循一些约束。
Cowboy provides an interface known as REST handlers that simplifies the implementation of a REST API on top of the HTTP protocol.
Cowboy提供了一个称为REST处理程序的接口,该接口简化了基于HTTP协议的REST API的实现。
Erlang and the Web
Erlang is the ideal platform for writing Web applications. Its features are a perfect match for the requirements of modern Web applications.
Erlang是编写Web应用程序的理想平台。它的功能非常适合现代Web应用程序的需求。
The Web is concurrent
When you access a website there is little concurrency involved. A few connections are opened and requests are sent through these connections. Then the web page is displayed on your screen. Your browser will only open up to 4 or 8 connections to the server, depending on your settings. This isn't much.
当您访问网站时,涉及的并发很少。将打开一些连接,并通过这些连接发送请求。然后,网页显示在屏幕上。您的浏览器最多只能打开4到8个与服务器的连接,具体取决于您的设置。这个不多。
But think about it. You are not the only one accessing the server at the same time. There can be hundreds, if not thousands, if not millions of connections to the same server at the same time.
但是考虑一下。您不是同时访问服务器的唯一人。同一时间可能有数百个(如果不是数千个)甚至数百万个连接到同一服务器。
Even today a lot of systems used in production haven't solved the C10K problem (ten thousand concurrent connections). And the ones who did are trying hard to get to the next step, C100K, and are pretty far from it.
即使在今天,生产中使用的许多系统仍未解决C10K问题(一万个并发连接)。那些确实在努力迈出下一步的人C100K,与之相距甚远。
Erlang meanwhile has no problem handling millions of connections. At the time of writing there are application servers written in Erlang that can handle more than two million connections on a single server in a real production application, with spare memory and CPU!
The Web is concurrent, and Erlang is a language designed for concurrency, so it is a perfect match.
同时,Erlang处理数百万个连接没有问题。在撰写本文时,有一些用Erlang编写的应用程序服务器,它们可以在实际生产应用程序中的单个服务器上处理超过200万个连接,并具有备用内存和CPU!
Web是并发的,而Erlang是为并发设计的语言,因此是完美的选择。
Of course, various platforms need to scale beyond a few million connections. This is where Erlang's built-in distribution mechanisms come in. If one server isn't enough, add more! Erlang allows you to use the same code for talking to local processes or to processes in other parts of your cluster, which means you can scale very quickly if the need arises.
当然,各种平台都需要扩展到几百万个连接。这就是Erlang内置的分发机制的所在。如果一台服务器不够用,请添加更多服务器! Erlang允许您使用相同的代码与本地进程或集群中其他部分的进程进行通信,这意味着您可以在需要时快速扩展。
The Web has large userbases, and the Erlang platform was designed to work in a distributed setting, so it is a perfect match.
Web具有庞大的用户群,Erlang平台旨在在分布式环境中工作,因此非常适合。
Or is it? Surely you can find solutions to handle that many concurrent connections with your favorite language... But all these solutions will break down in the next few years. Why? Firstly because servers don't get any more powerful, they instead get a lot more cores and memory. This is only useful if your application can use them properly, and Erlang is light-years away from anything else in that area. Secondly, today your computer and your phone are online, tomorrow your watch, goggles, bike, car, fridge and tons of other devices will also connect to various applications on the Internet.
还是?当然,您可以找到使用您喜欢的语言来处理许多并发连接的解决方案...但是所有这些解决方案在未来几年内都会崩溃。为什么?首先,由于服务器功能不再强大,因此它们拥有更多的内核和内存。只有在您的应用程序可以正确使用它们的情况下,这才有用。其次,今天您的计算机和电话在线,明天您的手表,护目镜,自行车,汽车,冰箱和大量其他设备也将连接到Internet上的各种应用程序。
Only Erlang is prepared to deal with what's coming.
只有Erlang愿意处理即将发生的事情。
The Web is soft real time
What does soft real time mean, you ask? It means we want the operations done as quickly as possible, and in the case of web applications, it means we want the data propagated fast.
您问软实时是什么意思?这意味着我们希望尽快完成操作,对于Web应用程序,这意味着我们希望数据能够快速传播。
In comparison, hard real time has a similar meaning, but also has a hard time constraint, for example an operation needs to be done in under N milliseconds otherwise the system fails entirely.
相比之下,硬实时具有类似的含义,但也具有硬时间限制,例如,操作需要在N毫秒内完成,否则系统将完全失败。
Users aren't that needy yet, they just want to get access to their content in a reasonable delay, and they want the actions they make to register at most a few seconds after they submitted them, otherwise they'll start worrying about whether it successfully went through.
用户并不需要,他们只是希望在合理的延迟时间内访问其内容,并且希望他们提交的操作最多在提交后几秒钟即可注册,否则他们将开始担心它是否成功地通过了。
The Web is soft real time because taking longer to perform an operation would be seen as bad quality of service。
Web是软实时的,因为花费更长的时间执行操作将被视为不良的服务质量。
Erlang is a soft real time system. It will always run processes fairly, a little at a time, switching to another process after a while and preventing a single process to steal resources from all others. This means that Erlang can guarantee stable low latency of operations.
Erlang是一个软实时系统。它将始终公平地运行一次进程,一段时间后切换到另一个进程,并防止单个进程从所有其他进程中窃取资源。这意味着Erlang可以保证稳定的低操作延迟。
Erlang provides the guarantees that the soft real time Web requires.
Erlang提供了软实时Web所需的保证。
The Web is asynchronous Web是异步的
Long ago, the Web was synchronous because HTTP was synchronous. You fired a request, and then waited for a response. Not anymore. It all began when XmlHttpRequest started being used. It allowed the client to perform asynchronous calls to the server.
很久以前,Web是同步的,因为HTTP是同步的。您触发了一个请求,然后等待响应。不再。这一切始于XmlHttpRequest开始使用。它允许客户端执行对服务器的异步调用。
Then Websocket appeared and allowed both the server and the client to send data to the other endpoint completely asynchronously. The data is contained within frames and no response is necessary.
然后出现了Websocket,并允许服务器和客户端将数据完全异步地发送到另一个端点。数据包含在帧内,不需要响应。
Erlang processes work the same. They send each other data contained within messages and then continue running without needing a response. They tend to spend most of their time inactive, waiting for a new message, and the Erlang VM happily activate them when one is received.
Erlang进程的工作原理相同。它们彼此发送包含在消息中的数据,然后继续运行而无需响应。他们倾向于将大部分时间都闲置起来,等待一条新消息,而Erlang VM在收到消息时会很高兴地激活它们。
It is therefore quite easy to imagine Erlang being good at receiving Websocket frames, which may come in at unpredictable times, pass the data to the responsible processes which are always ready waiting for new messages, and perform the operations required by only activating the required parts of the system.
因此,很容易想象Erlang擅长接收Websocket帧,这些帧可能在不可预知的时间出现,将数据传递给负责的进程,这些进程始终准备等待新消息,并仅通过激活所需的部分来执行所需的操作系统的。
The more recent Web technologies, like Websocket of course, but also HTTP/2.0, are all fully asynchronous protocols. The concept of requests and responses is retained of course, but anything could be sent in between, by both the client or the browser, and the responses could also be received in a completely different order.
当然,最新的Web技术(例如Websocket)以及HTTP / 2.0都是完全异步的协议。当然,请求和响应的概念仍然保留,但是客户端和浏览器之间都可以发送任何内容,并且响应也可以完全不同的顺序接收。
Erlang is by nature asynchronous and really good at it thanks to the great engineering that has been done in the VM over the years. It's only natural that it's so good at dealing with the asynchronous Web.
由于多年来在VM中完成的出色工程设计,Erlang本质上是异步的并且非常擅长于此。很好地处理异步Web是很自然的。
The Web is omnipresent 网络无所不在
The Web has taken a very important part of our lives. We're connected at all times, when we're on our phone, using our computer, passing time using a tablet while in the bathroom... And this isn't going to slow down, every single device at home or on us will be connected.
网络已经成为我们生活中非常重要的一部分。无论何时,无论是使用手机,使用计算机还是在浴室中使用平板电脑打发时间,我们始终保持连接状态……而且这不会降低速度,无论是在家中还是我们身上的每一个设备将被连接。
All these devices are always connected. And with the number of alternatives to give you access to the content you seek, users tend to not stick around when problems arise. Users today want their applications to be always available and if it's having too many issues they just move on.
所有这些设备始终处于连接状态。有了许多使您能够访问所需内容的替代方法,出现问题时,用户往往不会呆在身边。今天的用户希望他们的应用程序始终可用,如果有太多问题,他们将继续前进。
Despite this, when developers choose a product to use for building web applications, their only concern seems to be "Is it fast?", and they look around for synthetic benchmarks showing which one is the fastest at sending "Hello world" with only a handful concurrent connections. Web benchmarks haven't been representative of reality in a long time, and are drifting further away as time goes on.
尽管如此,当开发人员选择用于构建Web应用程序的产品时,他们唯一关心的似乎是“速度快吗?”,并且他们四处寻找综合基准,以显示哪一个是发送“ Hello world”最快的基准。少数并发连接。 Web基准已经很长时间没有代表现实了,并且随着时间的流逝越来越远。
What developers should really ask themselves is "Can I service all my users with no interruption?" and they'd find that they have two choices. They can either hope for the best, or they can use Erlang.
开发人员真正应该问自己的是:“我可以不间断地为所有用户提供服务吗?”他们发现他们有两个选择。他们可以希望最好,也可以使用Erlang。
Erlang is built for fault tolerance. When writing code in any other language, you have to check all the return values and act accordingly to avoid any unforeseen issues. If you're lucky, you won't miss anything important. When writing Erlang code, you can just check the success condition and ignore all errors. If an error happens, the Erlang process crashes and is then restarted by a special process called a supervisor.
Erlang专为容错而设计。用任何其他语言编写代码时,您必须检查所有返回值并采取相应措施以避免任何无法预料的问题。如果幸运的话,您将不会错过任何重要的事情。编写Erlang代码时,您只需检查成功条件并忽略所有错误。如果发生错误,则Erlang进程将崩溃,然后由称为管理程序的特殊进程重新启动。
Erlang developers thus have no need to fear unhandled errors, and can focus on handling only the errors that should give some feedback to the user and let the system take care of the rest. This also has the advantage of allowing them to write a lot less code, and let them sleep at night.
因此,Erlang开发人员无需担心未处理的错误,而可以专注于仅处理应向用户提供一些反馈并让系统负责其余工作的错误。这还具有允许他们编写少得多的代码并让他们在晚上睡觉的优点。
Erlang's fault tolerance oriented design is the first piece of what makes it the best choice for the omnipresent, always available Web.
Erlang面向容错的设计是使其成为无所不在且始终可用的Web的最佳选择的第一步。
The second piece is Erlang's built-in distribution. Distribution is a key part of building a fault tolerant system, because it allows you to handle bigger failures, like a whole server going down, or even a data center entirely.
第二部分是Erlang的内置发行版。分发是构建容错系统的关键部分,因为它使您可以处理更大的故障,例如整个服务器宕机,甚至整个数据中心。
Fault tolerance and distribution are important today, and will be vital in the future of the Web. Erlang is ready.
容错性和分发在今天非常重要,并且在Web的未来中至关重要。 Erlang准备好了。
Learn Erlang
If you are new to Erlang, you may want to grab a book or two to get started. Those are my recommendations as the author of Cowboy.
如果您不熟悉Erlang,则可能要先读一本书或两本书。这些是我作为《牛仔》作者的推荐。
The Erlanger Playbook
The Erlanger Playbook is an ebook I am currently writing, which covers a number of different topics from code to documentation to testing Erlang applications. It also has an Erlang section where it covers directly the building blocks and patterns, rather than details like the syntax.
Erlanger Playbook是我目前正在写的一本电子书,涵盖了从代码到文档再到测试Erlang应用程序的许多不同主题。它还有一个Erlang部分,其中直接覆盖了构建块和模式,而不是语法之类的细节。
You can most likely read it as a complete beginner, but you will need a companion book to make the most of it. Buy it from the Nine Nines website.
您很可能会作为一个完整的初学者来阅读它,但是您将需要一本随书以充分利用它。从九尼兹网站上购买。
Programming Erlang
This book is from one of the creator of Erlang, Joe Armstrong. It provides a very good explanation of what Erlang is and why it is so. It serves as a very good introduction to the language and platform.
这本书来自Erlang的创建者之一Joe Armstrong。它很好地解释了什么是Erlang以及为什么如此。它是对语言和平台的很好的介绍。
The book is Programming Erlang, and it also features a chapter on Cowboy.
这本书是《编程Erlang》,其中还包括有关牛仔的一章。
Learn You Some Erlang for Great Good!
LYSE is a much more complete book covering many aspects of Erlang, while also providing stories and humor. Be warned: it's pretty verbose. It comes with a free online version and a more refined paper and ebook version.
LYSE是一本比较完整的书,涵盖了Erlang的许多方面,同时还提供了故事和幽默。请注意:这很冗长。它带有免费的在线版本以及更精致的纸张和电子书版本。
Introduction
Cowboy is a small, fast and modern HTTP server for Erlang/OTP.
Cowboy是适用于Erlang / OTP的小型,快速,现代化的HTTP服务器。
Cowboy aims to provide a complete modern Web stack. This includes HTTP/1.1, HTTP/2, Websocket, Server-Sent Events and Webmachine-based REST.
Cowboy旨在提供完整的现代Web堆栈。这包括HTTP / 1.1,HTTP / 2,Websocket,服务器发送的事件和基于Webmachine的REST。
Cowboy comes with functions for introspection and tracing, enabling developers to know precisely what is happening at any time. Its modular design also easily enable developers to add instrumentation.
Cowboy带有自省和跟踪功能,使开发人员可以准确地随时知道发生了什么。其模块化设计还使开发人员可以轻松添加仪表。
Cowboy is a high quality project. It has a small code base, is very efficient (both in latency and memory use) and can easily be embedded in another application.
牛仔是一个高质量的项目。它具有小的代码库,非常高效(在延迟和内存使用方面),并且可以轻松地嵌入到另一个应用程序中。
Cowboy is clean Erlang code. It includes hundreds of tests and its code is fully compliant with the Dialyzer. It is also well documented and features a Function Reference, a User Guide and numerous Tutorials.
牛仔是干净的Erlang代码。它包含数百个测试,其代码完全符合Dialyzer。它也有详细的文档记录,并具有功能参考,用户指南和大量教程。
Prerequisites 先决条件
Beginner Erlang knowledge is recommended for reading this guide.
建议阅读初学者的Erlang知识来阅读本指南。
Knowledge of the HTTP protocol is recommended but not required, as it will be detailed throughout the guide.
建议(但不是必需)了解HTTP协议,因为它将在本指南中进行详细介绍。
Supported platforms 支持平台
Cowboy is tested and supported on Linux, FreeBSD, Windows and OSX.
Cowboy已在Linux,FreeBSD,Windows和OSX上经过测试和支持。
Cowboy has been reported to work on other platforms, but we make no guarantee that the experience will be safe and smooth. You are advised to perform the necessary testing and security audits prior to deploying on other platforms.
据报道,Cowboy可以在其他平台上工作,但是我们不能保证该体验将是安全,流畅的。建议您在部署到其他平台上之前执行必要的测试和安全审核。
Cowboy is developed for Erlang/OTP 19.0 and newer.
Cowboy是为Erlang / OTP 19.0及更高版本开发的。
License
Cowboy uses the ISC License.
Cowboy使用ISC许可证。
Copyright (c) 2011-2017, Loïc Hoguin <essen@ninenines.eu>Permission to use, copy, modify, and/or distribute this software for any
purpose with or without fee is hereby granted, provided that the above
copyright notice and this permission notice appear in all copies.THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.Versioning 版本控制
Cowboy uses Semantic Versioning 2.0.0.
Cowboy使用语义版本控制2.0.0。
Conventions 约定
In the HTTP protocol, the method name is case sensitive. All standard method names are uppercase.
在HTTP协议中,方法名称区分大小写。所有标准方法名称均为大写。
Header names are case insensitive. When using HTTP/1.1, Cowboy converts all the request header names to lowercase. HTTP/2 requires clients to send them as lowercase. Any other header name is expected to be provided lowercased, including when querying information about the request or when sending responses.
标头名称不区分大小写。使用HTTP / 1.1时,Cowboy将所有请求标头名称转换为小写。 HTTP / 2要求客户端以小写形式发送它们。期望将任何其他标头名都小写,包括查询有关请求的信息或发送响应时。
The same applies to any other case insensitive value.
其他任何不区分大小写的值也是如此。
Getting started
Erlang is more than a language, it is also an operating system for your applications. Erlang developers rarely write standalone modules, they write libraries or applications, and then bundle those into what is called a release. A release contains the Erlang VM plus all applications required to run the node, so it can be pushed to production directly.
Erlang不仅仅是一种语言,它还是您的应用程序的操作系统。 Erlang开发人员很少编写独立模块,而是编写库或应用程序,然后将它们捆绑到所谓的发行版中。一个发行版包含Erlang VM以及运行该节点所需的所有应用程序,因此可以将其直接推送到生产环境。
This chapter walks you through all the steps of setting up Cowboy, writing your first application and generating your first release. At the end of this chapter you should know everything you need to push your first Cowboy application to production.
本章将引导您完成设置Cowboy,编写第一个应用程序以及生成第一个发行版的所有步骤。在本章的最后,您应该了解将第一个Cowboy应用程序推向生产所需的一切。
Prerequisites 先决条件
We are going to use the Erlang.mk build system. If you are using Windows, please check the Installation instructions to get your environment setup before you continue.
我们将使用Erlang.mk构建系统。如果您使用的是Windows,请先查看安装说明以进行环境设置,然后再继续。
Bootstrap 引导程序
First, let's create the directory for our application.
首先,让我们为应用程序创建目录。
$ mkdir hello_erlang $ cd hello_erlang
Then we need to download Erlang.mk. Either use the following command or download it manually.
然后,我们需要下载Erlang.mk。使用以下命令或手动下载。
$ wget https://erlang.mk/erlang.mk
We can now bootstrap our application. Since we are going to generate a release, we will also bootstrap it at the same time.
现在我们可以引导我们的应用程序了。由于我们将生成一个发行版,因此我们还将同时对其进行引导。
$ make -f erlang.mk bootstrap bootstrap-rel
This creates a Makefile, a base application, and the release files necessary for creating the release. We can already build and start this release.
这将创建一个Makefile,一个基本应用程序以及创建发行版所需的发行版文件。我们已经可以构建并启动此版本。
$ make run
...
(hello_erlang@127.0.0.1)1>
Entering the command i(). will show the running processes, including one called hello_erlang_sup. This is the supervisor for our application.
输入命令i()。将显示正在运行的进程,包括一个名为hello_erlang_sup的进程。这是我们应用程序的主管
The release currently does nothing. In the rest of this chapter we will add Cowboy as a dependency and write a simple "Hello world!" handler.
该版本当前不执行任何操作。在本章的其余部分,我们将添加Cowboy作为依赖项,并编写一个简单的“ Hello world!”。处理程序。
Cowboy setup 牛仔设置
We will modify the Makefile to tell the build system it needs to fetch and compile Cowboy:
我们将修改Makefile来告诉构建系统需要获取和编译Cowboy:
PROJECT = hello_erlangDEPS = cowboy
dep_cowboy_commit = 2.6.3DEP_PLUGINS = cowboyinclude erlang.mk
The DEP_PLUGINS line tells the build system to load the plugins Cowboy provides. These include predefined templates that we will use soon.
DEP_PLUGINS行告诉构建系统加载Cowboy提供的插件。其中包括我们将很快使用的预定义模板。
If you do make run now, Cowboy will be included in the release and started automatically. This is not enough however, as Cowboy doesn't do anything by default. We still need to tell Cowboy to listen for connections.
如果您立即进行运行,则Cowboy将包含在发行版中并自动启动。但是,这还不够,因为牛仔默认情况下不执行任何操作。我们仍然需要告诉Cowboy收听连接。
Listening for connections 倾听连接
First we define the routes that Cowboy will use to map requests to handler modules, and then we start the listener. This is best done at application startup.
首先,我们定义Cowboy用来将请求映射到处理程序模块的路由,然后启动侦听器。最好在应用程序启动时完成。
Open the src/hello_erlang_app.erl file and add the necessary code to the start/2 function to make it look like this:
打开src / hello_erlang_app.erl文件,并将必要的代码添加到start / 2函数中,使其看起来像这样:
start(_Type, _Args) ->Dispatch = cowboy_router:compile([{'_', [{"/", hello_handler, []}]}]),{ok, _} = cowboy:start_clear(my_http_listener,[{port, 8080}],#{env => #{dispatch => Dispatch}}),hello_erlang_sup:start_link().
Routes are explained in details in the Routing chapter. For this tutorial we map the path / to the handler module hello_handler. This module doesn't exist yet.
在“路由”一章中详细说明了路由。在本教程中,我们将路径/映射到处理程序模块hello_handler。该模块尚不存在。
Build and start the release, then open http://localhost:8080 in your browser. You will get a 500 error because the module is missing. Any other URL, like http://localhost:8080/test, will result in a 404 error.
生成并启动发行版,然后在浏览器中打开http:// localhost:8080。因为缺少模块,您将收到500错误。任何其他URL(例如http:// localhost:8080 / test)将导致404错误
Handling requests 处理请求
Cowboy features different kinds of handlers, including REST and Websocket handlers. For this tutorial we will use a plain HTTP handler.
Cowboy具有各种处理程序,包括REST和Websocket处理程序。在本教程中,我们将使用普通的HTTP处理程序。
Generate a handler from a template:
从模板生成处理程序:
$ make new t=cowboy.http n=hello_handler
Then, open the src/hello_handler.erl file and modify the init/2 function like this to send a reply.
然后,打开src / hello_handler.erl文件,并像这样修改init / 2函数以发送回复。
init(Req0, State) ->Req = cowboy_req:reply(200,#{<<"content-type">> => <<"text/plain">>},<<"Hello Erlang!">>,Req0),{ok, Req, State}.
What the above code does is send a 200 OK reply, with the Content-type header set to text/plain and the response body set to Hello Erlang!.
上面的代码所做的是发送200 OK答复,其中Content-type标头设置为text / plain,响应主体设置为Hello Erlang!。
If you run the release and open http://localhost:8080 in your browser, you should get a nice Hello Erlang! displayed!
如果您运行发行版并在浏览器中打开http:// localhost:8080,您将得到一个不错的Hello Erlang!显示!
Flow diagram 流程图
Cowboy is a lightweight HTTP server with support for HTTP/1.1, HTTP/2 and Websocket.
Cowboy是一种轻量级的HTTP服务器,支持HTTP / 1.1,HTTP / 2和Websocket。
It is built on top of Ranch. Please see the Ranch guide for more information about how the network connections are handled.
它建立在牧场之上。请参阅牧场指南,以获取有关如何处理网络连接的更多信息。
Overview 总览
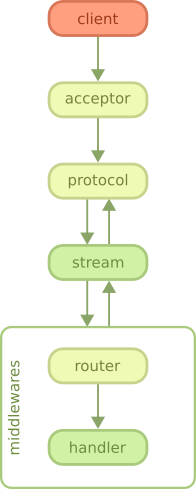
As you can see on the diagram, the client begins by connecting to the server. This step is handled by a Ranch acceptor, which is a process dedicated to accepting new connections.
如您在该图上看到的,客户端从连接到服务器开始。此步骤由Ranch接受器处理,这是一个专用于接受新连接的过程。
After Ranch accepts a new connection, whether it is an HTTP/1.1 or HTTP/2 connection, Cowboy starts receiving requests and handling them.
在Ranch接受新的连接(无论是HTTP / 1.1还是HTTP / 2连接)之后,Cowboy开始接收请求并进行处理。
In HTTP/1.1 all requests come sequentially. In HTTP/2 the requests may arrive and be processed concurrently.
在HTTP / 1.1中,所有请求都按顺序发出。在HTTP / 2中,请求可以到达并被同时处理。
When a request comes in, Cowboy creates a stream, which is a set of request/response and all the events associated with them. The protocol code in Cowboy defers the handling of these streams to stream handler modules. When you configure Cowboy you may define one or more module that will receive all events associated with a stream, including the request, response, bodies, Erlang messages and more.
当请求进入时,Cowboy创建一个流,该流是一组请求/响应以及与它们相关联的所有事件。 Cowboy中的协议代码将这些流的处理推迟到流处理程序模块。配置Cowboy时,您可以定义一个或多个模块,该模块将接收与流相关的所有事件,包括请求,响应,主体,Erlang消息等。
By default Cowboy comes configured with a stream handler called cowboy_stream_h. This stream handler will create a new process for every request coming in, and then communicate with this process to read the body or send a response back. The request process executes middlewares which, by default, including the router and then the execution of handlers. Like stream handlers, middlewares may also be customized.
默认情况下,Cowboy配置有名为cowboy_stream_h的流处理程序。此流处理程序将为每个传入的请求创建一个新进程,然后与该进程进行通信以读取正文或将响应发送回去。请求过程执行中间件,默认情况下,中间件包括路由器,然后是处理程序的执行。像流处理程序一样,中间件也可以自定义。
A response may be sent at almost any point in this diagram. If the response must be sent before the stream is initialized (because an error occurred early, for example) then stream handlers receive a special event indicating this error.
几乎可以在该图中的任何一点发送响应。如果必须在初始化流之前发送响应(例如,由于错误较早发生),则流处理程序将收到一个特殊事件,指示此错误。
Protocol-specific headers
Cowboy takes care of protocol-specific headers and prevents you from sending them manually. For HTTP/1.1 this includes the transfer-encoding and connection headers. For HTTP/2 this includes the colon headers like :status.
Cowboy处理协议特定的标头,并阻止您手动发送它们。对于HTTP / 1.1,这包括传输编码和连接头。对于HTTP / 2,这包括冒号标题,例如:status。
Cowboy will also remove protocol-specific headers from requests before passing them to stream handlers. Cowboy tries to hide the implementation details of all protocols as well as possible.
Cowboy还将在将请求传递给流处理程序之前从请求中删除特定于协议的标头。 Cowboy尝试尽可能隐藏所有协议的实现细节。
Number of processes per connection
By default, Cowboy will use one process per connection, plus one process per set of request/response (called a stream, internally).
默认情况下,Cowboy每个连接将使用一个进程,而每组请求/响应(内部称为流)将使用一个进程。
The reason it creates a new process for every request is due to the requirements of HTTP/2 where requests are executed concurrently and independently from the connection. The frames from the different requests end up interleaved on the single TCP connection.
它为每个请求创建一个新进程的原因是由于HTTP / 2的要求,在该要求下,请求是同时并独立于连接执行的。来自不同请求的帧最终在单个TCP连接上交错。
The request processes are never reused. There is therefore no need to perform any cleanup after the response has been sent. The process will terminate and Erlang/OTP will reclaim all memory at once.
请求过程永远不会重用。因此,在发送响应之后,无需执行任何清除操作。该过程将终止,Erlang / OTP将立即回收所有内存。
Cowboy ultimately does not require more than one process per connection. It is possible to interact with the connection directly from a stream handler, a low level interface to Cowboy. They are executed from within the connection process, and can handle the incoming requests and send responses. This is however not recommended in normal circumstances, as a stream handler taking too long to execute could have a negative impact on concurrent requests or the state of the connection itself.
最终,Cowboy每次连接不需要多个进程。可以直接从流处理程序(Cowboy的低级接口)与连接进行交互。它们在连接过程中执行,并且可以处理传入的请求并发送响应。但是,在正常情况下不建议这样做,因为执行时间太长的流处理程序可能会对并发请求或连接本身的状态产生负面影响
Date header
Because querying for the current date and time can be expensive, Cowboy generates one Date header value every second, shares it to all other processes, which then simply copy it in the response. This allows compliance with HTTP/1.1 with no actual performance loss.
由于查询当前日期和时间可能很昂贵,因此Cowboy每秒生成一个Date标头值,并将其共享给所有其他进程,然后将其简单地复制到响应中。这允许符合HTTP / 1.1,而不会造成实际性能损失。
Binaries
Cowboy makes extensive use of binaries.
牛仔大量使用二进制文件。
Binaries are more efficient than lists for representing strings because they take less memory space. Processing performance can vary depending on the operation. Binaries are known for generally getting a great boost if the code is compiled natively. Please see the HiPE documentation for more details.
二进制比列表表示字符串更有效,因为它们占用更少的内存空间。处理性能可能因操作而异。如果代码是本地编译的,则二进制通常会大大提高性能。请参阅HiPE文档以获取更多详细信息。
Binaries may end up being shared between processes. This can lead to some large memory usage when one process keeps the binary data around forever without freeing it. If you see some weird memory usage in your application, this might be the cause.
二进制可能最终会在进程之间共享。当一个进程永久保留二进制数据而不释放它时,这可能会导致大量内存使用。如果您在应用程序中看到一些奇怪的内存使用情况,则可能是原因。
Listeners
A listener is a set of processes that listens on a port for new connections. Incoming connections get handled by Cowboy. Depending on the connection handshake, one or another protocol may be used.
侦听器是一组在端口上侦听新连接的进程。传入连接由牛仔处理。根据连接握手,可以使用一个或另一个协议。
This chapter is specific to Cowboy. Please refer to the Ranch User Guide for more information about listeners.
本章专门针对牛仔。请参阅《牧场用户指南》以获取有关侦听器的更多信息。
Cowboy provides two types of listeners: one listening for clear TCP connections, and one listening for secure TLS connections. Both of them support the HTTP/1.1 and HTTP/2 protocols.
Cowboy提供了两种类型的侦听器:一种侦听清晰的TCP连接,一种侦听安全的TLS连接。它们都支持HTTP / 1.1和HTTP / 2协议。
Clear TCP listener
The clear TCP listener will accept connections on the given port. A typical HTTP server would listen on port 80. Port 80 requires special permissions on most platforms however so a common alternative is port 8080.
清除TCP侦听器将接受给定端口上的连接。典型的HTTP服务器将在端口80上侦听。端口80在大多数平台上都需要特殊权限,因此,常见的替代方法是端口8080。
The following snippet starts listening for connections on port 8080:
以下代码段开始侦听端口8080上的连接:
start(_Type, _Args) ->Dispatch = cowboy_router:compile([{'_', [{"/", hello_handler, []}]}]),{ok, _} = cowboy:start_clear(my_http_listener,[{port, 8080}],#{env => #{dispatch => Dispatch}}),hello_erlang_sup:start_link().
The Getting Started chapter uses a clear TCP listener.
《入门》一章使用清晰的TCP侦听器。
Clients connecting to Cowboy on the clear listener port are expected to use either HTTP/1.1 or HTTP/2.
通过清晰的侦听器端口连接到Cowboy的客户端应使用HTTP / 1.1或HTTP / 2。
Cowboy supports both methods of initiating a clear HTTP/2 connection: through the Upgrade mechanism (RFC 7540 3.2) or by sending the preface directly (RFC 7540 3.4).
Cowboy支持两种启动清晰HTTP / 2连接的方法:通过升级机制(RFC 7540 3.2)或直接发送前言(RFC 7540 3.4)。
Compatibility with HTTP/1.0 is provided by Cowboy's HTTP/1.1 implementation.
Cowboy的HTTP / 1.1实现提供与HTTP / 1.0的兼容性。
Secure TLS listener
安全的TLS侦听器
The secure TLS listener will accept connections on the given port. A typical HTTPS server would listen on port 443. Port 443 requires special permissions on most platforms however so a common alternative is port 8443.
安全的TLS侦听器将接受给定端口上的连接。典型的HTTPS服务器将在端口443上侦听。端口443在大多数平台上都需要特殊权限,因此,常见的替代方法是端口8443。
The function provided by Cowboy will ensure that the TLS options given are following the HTTP/2 RFC with regards to security. For example some TLS extensions or ciphers may be disabled. This also applies to HTTP/1.1 connections on this listener. If this is not desirable, Ranch can be used directly to setup a custom listener.
Cowboy提供的功能将确保给出的TLS选项在安全性方面遵循HTTP / 2 RFC。例如,某些TLS扩展名或密码可能被禁用。这也适用于此侦听器上的HTTP / 1.1连接。如果不希望这样做,可以直接使用Ranch设置自定义侦听器。
start(_Type, _Args) ->Dispatch = cowboy_router:compile([{'_', [{"/", hello_handler, []}]}]),{ok, _} = cowboy:start_tls(my_http_listener,[{port, 8443},{certfile, "/path/to/certfile"},{keyfile, "/path/to/keyfile"}],#{env => #{dispatch => Dispatch}}),hello_erlang_sup:start_link().
Clients connecting to Cowboy on the secure listener are expected to use the ALPN TLS extension to indicate what protocols they understand. Cowboy always prefers HTTP/2 over HTTP/1.1 when both are supported. When neither are supported by the client, or when the ALPN extension was missing, Cowboy expects HTTP/1.1 to be used.
希望在安全侦听器上连接到Cowboy的客户端使用ALPN TLS扩展来指示他们理解的协议。当牛仔和牛仔同时受支持时,它们总是比HTTP / 1.1更喜欢HTTP / 2。如果客户端都不支持,或者缺少ALPN扩展,则Cowboy希望使用HTTP / 1.1。
Cowboy also advertises HTTP/2 support through the older NPN TLS extension for compatibility. Note however that this support will likely not be enabled by default when Cowboy 2.0 gets released.
Cowboy还通过较早的NPN TLS扩展来宣传HTTP / 2支持,以实现兼容性。但是请注意,当Cowboy 2.0发布时,默认情况下可能不会启用此支持。
Compatibility with HTTP/1.0 is provided by Cowboy's HTTP/1.1 implementation.
Cowboy的HTTP / 1.1实现提供与HTTP / 1.0的兼容性。
Protocol configuration
The HTTP/1.1 and HTTP/2 protocols share the same semantics; only their framing differs. The first is a text protocol and the second a binary protocol.
HTTP / 1.1和HTTP / 2协议具有相同的语义。只有它们的框架不同。第一个是文本协议,第二个是二进制协议。
Cowboy doesn't separate the configuration for HTTP/1.1 and HTTP/2. Everything goes into the same map. Many options are shared.
Cowboy不会将HTTP / 1.1和HTTP / 2的配置分开。一切都进入同一张地图。许多选项是共享的。
Routing 路由
Cowboy does nothing by default.
To make Cowboy useful, you need to map URIs to Erlang modules that will handle the requests. This is called routing.
牛仔默认情况下不执行任何操作。
为了使Cowboy有用,您需要将URI映射到将处理请求的Erlang模块。这称为路由。
When Cowboy receives a request, it tries to match the requested host and path to the configured routes. When there's a match, the route's associated handler is executed.
Routes need to be compiled before they can be used by Cowboy. The result of the compilation is the dispatch rules.
当Cowboy收到请求时,它将尝试将请求的主机和路径与配置的路由进行匹配。匹配时,将执行路由的关联处理程序。必须先编译路线,然后牛仔才能使用它们。编译的结果就是调度规则。
Syntax 语法
The general structure for the routes is defined as follow.
路线的一般结构定义如下。
Routes = [Host1, Host2, ... HostN].
Each host contains matching rules for the host along with optional constraints, and a list of routes for the path component.
每个主机都包含与主机匹配的规则以及可选的约束,以及路径组件的路由列表。
Host1 = {HostMatch, PathsList}.
Host2 = {HostMatch, Constraints, PathsList}.
The list of routes for the path component is defined similar to the list of hosts.
路径组件的路由列表的定义类似于主机列表。
PathsList = [Path1, Path2, ... PathN].
Finally, each path contains matching rules for the path along with optional constraints, and gives us the handler module to be used along with its initial state.
最后,每个路径都包含该路径的匹配规则以及可选约束,并为我们提供了要使用的处理程序模块及其初始状态。
Path1 = {PathMatch, Handler, InitialState}.
Path2 = {PathMatch, Constraints, Handler, InitialState}.
Continue reading to learn more about the match syntax and the optional constraints.
继续阅读以了解有关匹配语法和可选约束的更多信息。
Match syntax 匹配语法
The match syntax is used to associate host names and paths with their respective handlers.
match语法用于将主机名和路径与其各自的处理程序相关联。
The match syntax is the same for host and path with a few subtleties. Indeed, the segments separator is different, and the host is matched starting from the last segment going to the first. All examples will feature both host and path match rules and explain the differences when encountered
匹配语法对于主机和路径是相同的,只是有些微妙。实际上,段分隔符是不同的,并且从最后一个段到第一个段匹配主机。所有示例都将包含主机匹配规则和路径匹配规则,并说明遇到的差异。
Excluding special values that we will explain at the end of this section, the simplest match value is a host or a path. It can be given as either a string() or a binary().
除了特殊的值(我们将在本节末尾说明)之外,最简单的匹配值是主机或路径。它可以以string()或binary()的形式给出。
PathMatch1 = "/".
PathMatch2 = "/path/to/resource".HostMatch1 = "cowboy.example.org".
As you can see, all paths defined this way must start with a slash character. Note that these two paths are identical as far as routing is concerned.
如您所见,以这种方式定义的所有路径都必须以斜杠字符开头。请注意,就路由而言,这两个路径是相同的。
PathMatch2 = "/path/to/resource".
PathMatch3 = "/path/to/resource/".
Hosts with and without a trailing dot are equivalent for routing. Similarly, hosts with and without a leading dot are also equivalent.
带有和不带有尾点的主机等效于路由。同样,带和不带前导点的主机也等效。
HostMatch1 = "cowboy.example.org".
HostMatch2 = "cowboy.example.org.".
HostMatch3 = ".cowboy.example.org".
It is possible to extract segments of the host and path and to store the values in the Reqobject for later use. We call these kind of values bindings.
可以提取主机和路径的段,并将值存储在Req对象中以备后用。我们称这类为值绑定。
The syntax for bindings is very simple. A segment that begins with the : character means that what follows until the end of the segment is the name of the binding in which the segment value will be stored.
绑定的语法非常简单。以:字符开头的段表示直到段末尾的内容是将在其中存储段值的绑定的名称。
If these two end up matching when routing, you will end up with two bindings defined, subdomain and name, each containing the segment value where they were defined. For example, the URL http://test.example.org/hats/wild_cowboy_legendary/prices will result in having the value test bound to the name subdomain and the value wild_cowboy_legendary bound to the name name. They can later be retrieved using cowboy_req:binding/{2,3}. The binding name must be given as an atom.
如果这两个在路由时最终匹配,则最终将定义两个绑定,subdomain和name,每个绑定都包含定义它们的段值。例如,URL http://test.example.org/hats/wild_cowboy_legendary/prices将导致值test绑定到名称子域,而值wild_cowboy_legendary绑定到名称name。以后可以使用cowboy_req:binding / {2,3}来检索它们。绑定名称必须作为原子给出。
There is a special binding name you can use to mimic the underscore variable in Erlang. Any match against the _ binding will succeed but the data will be discarded. This is especially useful for matching against many domain names in one go.
您可以使用一个特殊的绑定名称来模仿Erlang中的下划线变量。与_绑定的任何匹配都将成功,但数据将被丢弃。这对于一次性匹配多个域名特别有用。
HostMatch = "ninenines.:_".
Similarly, it is possible to have optional segments. Anything between brackets is optional.
同样,可以有可选段。括号之间的任何内容都是可选的。
PathMatch = "/hats/[page/:number]".
HostMatch = "[www.]ninenines.eu".
You can also have imbricated optional segments.
您还可以使用固定的细分受众群。
PathMatch = "/hats/[page/[:number]]".
While Cowboy does not reject multiple brackets in a route, the behavior may be undefined if the route is under-specified. For example, this route requires constraints to determine what is a chapter and what is a page, since they are both optional:
虽然Cowboy不会拒绝路线中的多个括号,但如果路线指定不充分,则行为可能不确定。例如,此路由需要约束来确定什么是章节和什么是页面,因为它们都是可选的:
PathMatch = "/book/[:chapter]/[:page]".
You can retrieve the rest of the host or path using [...]. In the case of hosts it will match anything before, in the case of paths anything after the previously matched segments. It is a special case of optional segments, in that it can have zero, one or many segments. You can then find the segments using cowboy_req:host_info/1 and cowboy_req:path_info/1respectively. They will be represented as a list of segments.
您可以使用[...]检索主机或路径的其余部分。对于主机,它将匹配之前的任何内容,对于路径,将匹配之前匹配的段之后的任何内容。这是可选段的一种特殊情况,因为它可以有零个,一个或多个段。然后,您可以分别使用cowboy_req:host_info / 1和cowboy_req:path_info / 1查找分段。它们将被表示为段列表。
PathMatch = "/hats/[...]".
HostMatch = "[...]ninenines.eu".
If a binding appears twice in the routing rules, then the match will succeed only if they share the same value. This copies the Erlang pattern matching behavior.
如果绑定在路由规则中出现两次,则仅当它们共享相同的值时,匹配才会成功。这将复制Erlang模式匹配行为。
PathMatch = "/hats/:name/:name".
This is also true when an optional segment is present. In this case the two values must be identical only if the segment is available.
当存在可选段时,也是如此。在这种情况下,仅当段可用时,两个值必须相同。
PathMatch = "/hats/:name/[:name]".
If a binding is defined in both the host and path, then they must also share the same value.
如果在主机和路径中都定义了绑定,则它们也必须共享相同的值。
PathMatch = "/:user/[...]".
HostMatch = ":user.github.com".
Finally, there are two special match values that can be used. The first is the atom '_' which will match any host or path.
最后,可以使用两个特殊的匹配值。第一个是原子“ _”,它将匹配任何主机或路径。
PathMatch = '_'.
HostMatch = '_'.
The second is the special host match "*" which will match the wildcard path, generally used alongside the OPTIONS method.
第二个是特殊的主机匹配“ *”,它将匹配通配符路径,通常与OPTIONS方法一起使用。
HostMatch = "*".
Constraints 约束条件
After the matching has completed, the resulting bindings can be tested against a set of constraints. Constraints are only tested when the binding is defined. They run in the order you defined them. The match will succeed only if they all succeed. If the match fails, then Cowboy tries the next route in the list.
匹配完成后,可以针对一组约束对生成的绑定进行测试。仅在定义绑定时才测试约束。它们按照您定义它们的顺序运行。只有他们全部成功,比赛才会成功。如果匹配失败,则Cowboy尝试列表中的下一条路线。
The format used for constraints is the same as match functions in cowboy_req: they are provided as a list of fields which may have one or more constraints. While the router accepts the same format, it will skip fields with no constraints and will also ignore default values, if any.
用于约束的格式与cowboy_req中的match函数相同:它们作为可能具有一个或多个约束的字段列表提供。当路由器接受相同格式时,它将跳过没有限制的字段,并且还将忽略默认值(如果有)。
Read more about constraints.
阅读有关约束的更多信息。
Compilation 汇编
The routes must be compiled before Cowboy can use them. The compilation step normalizes the routes to simplify the code and speed up the execution, but the routes are still looked up one by one in the end. Faster compilation strategies could be to compile the routes directly to Erlang code, but would require heavier dependencies.
必须先编译路线,然后Cowboy才能使用它们。编译步骤将路由标准化,以简化代码并加快执行速度,但最终仍会逐一查找路由。更快的编译策略可能是直接将路由编译到Erlang代码,但将需要更大的依赖性。
To compile routes, just call the appropriate function:
要编译路由,只需调用适当的函数:
Dispatch = cowboy_router:compile([%% {HostMatch, list({PathMatch, Handler, InitialState})}{'_', [{'_', my_handler, #{}}]}
]),
%% Name, NbAcceptors, TransOpts, ProtoOpts
cowboy:start_clear(my_http_listener,[{port, 8080}],#{env => #{dispatch => Dispatch}}
).
Live update 实时更新
You can use the cowboy:set_env/3 function for updating the dispatch list used by routing. This will apply to all new connections accepted by the listener:
您可以使用cowboy:set_env / 3函数来更新路由使用的调度列表。这将适用于侦听器接受的所有新连接:
Dispatch = cowboy_router:compile(Routes),
cowboy:set_env(my_http_listener, dispatch, Dispatch).
Note that you need to compile the routes again before updating.
请注意,您需要在更新之前再次编译路由。
Constraints 约束条件
Constraints are validation and conversion functions applied to user input.
约束是应用于用户输入的验证和转换功能。
They are used in various places in Cowboy, including the router and the cowboy_req match functions.
它们在Cowboy中的各个地方都有使用,包括路由器和cowboy_req匹配功能。
Syntax 语法
Constraints are provided as a list of fields. For each field in the list, specific constraints can be applied, as well as a default value if the field is missing.
约束作为字段列表提供。对于列表中的每个字段,可以应用特定的约束,如果缺少该字段,则可以应用默认值。
A field can take the form of an atom field, a tuple with constraints {field, Constraints}or a tuple with constraints and a default value {field, Constraints, Default}. The fieldform indicates the field is mandatory.
字段可以采用原子字段,具有约束{field,Constraints}的元组或具有约束和默认值{field,Constraints,Default}的元组的形式。字段形式表示该字段是必填字段。
Note that when used with the router, only the second form makes sense, as it does not use the default and the field is always defined.
请注意,与路由器一起使用时,只有第二种形式才有意义,因为它不使用默认格式,并且始终定义该字段。
Constraints for each field are provided as an ordered list of atoms or funs to apply. Built-in constraints are provided as atoms, while custom constraints are provided as funs.
提供每个字段的约束,作为要应用的原子或函数的有序列表。内置约束作为原子提供,而自定义约束作为函数提供。
When multiple constraints are provided, they are applied in the order given. If the value has been modified by a constraint then the next one receives the new value.
提供多个约束时,将按给定的顺序应用它们。如果该值已被约束修改,则下一个约束将接收新值。
For example, the following constraints will first validate and convert the field my_value to an integer, and then check that the integer is positive:
例如,以下约束将首先验证并将my_value字段转换为整数,然后检查该整数是否为正:
PositiveFun = fun(_, V) when V > 0 ->{ok, V};(_, _) ->{error, not_positive}
end,
{my_value, [int, PositiveFun]}.
We ignore the first fun argument in this snippet. We shouldn't. We will simply learn what it is later in this chapter.
我们忽略了此片段中的第一个有趣的论点。我们不应该我们将在本章后面简单地学习它。
When there's only one constraint, it can be provided directly without wrapping it into a list:
当只有一个约束时,可以直接提供它而不必将其包装到列表中
{my_value, int}
Built-in constraints 内置约束
Built-in constraints are specified as an atom:
内置约束被指定为一个原子:
| Constraint | Description |
|---|---|
| int | Converts binary value to integer. |
| nonempty | Ensures the binary value is non-empty. |
Custom constraints 自定义约束
Custom constraints are specified as a fun. This fun takes two arguments. The first argument indicates the operation to be performed, and the second is the value. What the value is and what must be returned depends on the operation.
自定义约束被指定为一种乐趣。这种乐趣有两个论点。第一个参数表示要执行的操作,第二个参数是值。值是什么,必须返回什么取决于操作。
Cowboy currently defines three operations. The operation used for validating and converting user input is the forward operation.
牛仔当前定义了三个操作。用于验证和转换用户输入的操作是前向操作
int(forward, Value) ->try{ok, binary_to_integer(Value)}catch _:_ ->{error, not_an_integer}end;
The value must be returned even if it is not converted by the constraint.
即使未通过约束转换该值,也必须返回。
The reverse operation does the opposite: it takes a converted value and changes it back to what the user input would have been.
反向操作则相反:它将转换后的值更改回用户输入的状态。
int(reverse, Value) ->try{ok, integer_to_binary(Value)}catch _:_ ->{error, not_an_integer}end;
Finally, the format_error operation takes an error returned by any other operation and returns a formatted human-readable error message.
最终,format_error操作接受任何其他操作返回的错误,并返回格式化的人类可读错误消息。
int(format_error, {not_an_integer, Value}) ->io_lib:format("The value ~p is not an integer.", [Value]).
Notice that for this case you get both the error and the value that was given to the constraint that produced this error.
请注意,在这种情况下,您会同时获得错误和为产生此错误的约束赋予的值。
Cowboy will not catch exceptions coming from constraint functions. They should be written to not emit any exceptions.
Cowboy不会捕获来自约束函数的异常。应该将它们写为不会发出任何异常。
Handlers
Handlers are Erlang modules that handle HTTP requests.
处理程序是处理HTTP请求的Erlang模块。
Plain HTTP handlers 纯HTTP处理程序
The most basic handler in Cowboy implements the mandatory init/2 callback, manipulates the request, optionally sends a response and then returns.
Cowboy中最基本的处理程序实现强制性的init / 2回调,处理请求,可选地发送响应然后返回。
This callback receives the Req object and the initial state defined in the router configuration.
此回调接收Req对象和路由器配置中定义的初始状态。
A handler that does nothing would look like this:
不执行任何操作的处理程序如下所示:
init(Req, State) ->{ok, Req, State}.
Despite sending no reply, a 204 No Content response will be sent to the client, as Cowboy makes sure that a response is sent for every request.
尽管没有发送任何答复,但由于Cowboy确保为每个请求都发送了响应,因此会向客户端发送204 No Content响应。
We need to use the Req object to reply.
我们需要使用Req对象进行回复。
init(Req0, State) ->Req = cowboy_req:reply(200, #{<<"content-type">> => <<"text/plain">>}, <<"Hello World!">>, Req0),{ok, Req, State}.
Cowboy will immediately send a response when cowboy:reply/4 is called.
调用cowboy:reply / 4时,Cowboy将立即发送响应。
We then return a 3-tuple. ok means that the handler ran successfully. We also give the modified Req back to Cowboy.
然后,我们返回一个三元组。正常表示处理程序成功运行。我们还将修改后的Req还给了Cowboy。
The last value of the tuple is a state that will be used in every subsequent callbacks to this handler. Plain HTTP handlers only have one additional callback, the optional and rarely used terminate/3.
元组的最后一个值是将在此处理程序的每个后续回调中使用的状态。普通的HTTP处理程序只有一个附加的回调,即可选的和很少使用的terminate/3。
Other handlers 其他处理者
The init/2 callback can also be used to inform Cowboy that this is a different kind of handler and that Cowboy should switch to it. To do this you simply need to return the module name of the handler type you want to switch to.
init / 2回调还可以用于通知Cowboy这是另一种处理程序,并且Cowboy应该切换到该处理程序。为此,您只需要返回要切换到的处理程序类型的模块名称即可。
Cowboy comes with three handler types you can switch to: cowboy_rest, cowboy_websocketand cowboy_loop. In addition to those you can define your own handler types.
Cowboy具有三种可以切换的处理程序类型:cowboy_rest,cowboy_websocket和cowboy_loop。除了这些之外,您还可以定义自己的处理程序类型。
Switching is simple. Instead of returning ok, you simply return the name of the handler type you want to use. The following snippet switches to a Websocket handler:
切换很简单。无需返回ok,您只需返回要使用的处理程序类型的名称。以下代码片段切换到Websocket处理程序:
init(Req, State) ->{cowboy_websocket, Req, State}.
Cleaning up
All handler types provide the optional terminate/3 callback.
所有处理程序类型都提供可选的终止/ 3回调。
terminate(_Reason, _Req, _State) ->ok.
This callback is strictly reserved for any required cleanup. You cannot send a response from this function. There is no other return value.
严格保留此回调用于进行任何必需的清理。您不能通过此功能发送响应。没有其他返回值。
This callback is optional because it is rarely necessary. Cleanup should be done in separate processes directly (by monitoring the handler process to detect when it exits).
此回调是可选的,因为它很少需要。清除应直接在单独的进程中完成(通过监视处理程序进程以检测其退出时间)。
Cowboy does not reuse processes for different requests. The process will terminate soon after this call returns.
Cowboy不会针对不同的请求重用流程。该调用返回后,该过程将立即终止。
Loop handlers
Loop handlers are a special kind of HTTP handlers used when the response can not be sent right away. The handler enters instead a receive loop waiting for the right message before it can send a response.
循环处理程序是一种特殊的HTTP处理程序,它在无法立即发送响应时使用。处理程序将进入接收循环,等待正确的消息,然后才能发送响应。
Loop handlers are used for requests where a response might not be immediately available, but where you would like to keep the connection open for a while in case the response arrives. The most known example of such practice is known as long polling.
循环处理程序用于请求,在这些请求中可能无法立即获得响应,但是希望在响应到达时保持连接一段时间。这种做法最著名的例子就是长轮询。
Loop handlers can also be used for requests where a response is partially available and you need to stream the response body while the connection is open. The most known example of such practice is server-sent events, but it also applies to any response that takes a long time to send.
循环处理程序还可用于部分响应可用的请求,并且您需要在连接打开时流式传输响应主体。这种做法的最著名示例是服务器发送的事件,但它也适用于发送时间很长的任何响应。
While the same can be accomplished using plain HTTP handlers, it is recommended to use loop handlers because they are well-tested and allow using built-in features like hibernation and timeouts.
尽管可以使用普通的HTTP处理程序完成相同的操作,但是建议您使用循环处理程序,因为它们经过了充分的测试,并允许使用诸如休眠和超时之类的内置功能。
Loop handlers essentially wait for one or more Erlang messages and feed these messages to the info/3 callback. It also features the init/2 and terminate/3 callbacks which work the same as for plain HTTP handlers.
循环处理程序本质上等待一个或多个Erlang消息,并将这些消息提供给info / 3回调。它还具有init / 2和terminate/ 3回调,其作用与普通HTTP处理程序相同。
Initialization 初始化
The init/2 function must return a cowboy_loop tuple to enable loop handler behavior. This tuple may optionally contain the atom hibernate to make the process enter hibernation until a message is received.
init / 2函数必须返回cowboy_loop元组以启用循环处理程序行为。该元组可以选择包含原子休眠,以使进程进入休眠状态,直到接收到消息为止。
This snippet enables the loop handler:
该代码段启用了循环处理程序:
init(Req, State) ->{cowboy_loop, Req, State}.
This also makes the process hibernate:
这也使进程休眠:
init(Req, State) ->{cowboy_loop, Req, State, hibernate}.
Receive loop
Once initialized, Cowboy will wait for messages to arrive in the process' mailbox. When a message arrives, Cowboy calls the info/3 function with the message, the Req object and the handler's state.
初始化后,Cowboy将等待消息到达进程的邮箱。消息到达时,Cowboy会使用消息,Req对象和处理程序的状态来调用info / 3函数。
The following snippet sends a reply when it receives a reply message from another process, or waits for another message otherwise.
以下代码段在收到来自另一个进程的答复消息时发送答复,否则将等待其他消息
info({reply, Body}, Req, State) ->cowboy_req:reply(200, #{}, Body, Req),{stop, Req, State};
info(_Msg, Req, State) ->{ok, Req, State, hibernate}.
Do note that the reply tuple here may be any message and is simply an example.
请注意,这里的回复元组可以是任何消息,仅是示例。
This callback may perform any necessary operation including sending all or parts of a reply, and will subsequently return a tuple indicating if more messages are to be expected.
该回调可以执行任何必要的操作,包括发送全部或部分答复,并且随后将返回一个元组,指示是否需要更多消息。
The callback may also choose to do nothing at all and just skip the message received.
回调也可以选择不执行任何操作,而只是跳过收到的消息。
If a reply is sent, then the stop tuple should be returned. This will instruct Cowboy to end the request.
如果发送了回复,则应该返回停止元组。这将指示Cowboy结束请求。
Otherwise an ok tuple should be returned.
否则应返回一个ok元组。
Streaming loop 流循环
Another common case well suited for loop handlers is streaming data received in the form of Erlang messages. This can be done by initiating a chunked reply in the init/2 callback and then using cowboy_req:chunk/2 every time a message is received.
非常适合循环处理程序的另一种常见情况是流式传输以Erlang消息形式接收的数据。这可以通过在init / 2回调中启动分块答复,然后在每次收到消息时使用cowboy_req:chunk / 2来完成。
The following snippet does exactly that. As you can see a chunk is sent every time an eventmessage is received, and the loop is stopped by sending an eof message.
以下代码段正是这样做的。如您所见,每次接收到事件消息时都会发送一个块,并且通过发送eof消息来停止循环。
init(Req, State) ->Req2 = cowboy_req:stream_reply(200, Req),{cowboy_loop, Req2, State}.info(eof, Req, State) ->{stop, Req, State};
info({event, Data}, Req, State) ->cowboy_req:stream_body(Data, nofin, Req),{ok, Req, State};
info(_Msg, Req, State) ->{ok, Req, State}.
Cleaning up
Please refer to the Handlers chapter for general instructions about cleaning up.
请参阅“处理程序”一章以获取有关清理的一般说明。
Hibernate 冬眠
To save memory, you may hibernate the process in between messages received. This is done by returning the atom hibernate as part of the loop tuple callbacks normally return. Just add the atom at the end and Cowboy will hibernate accordingly.
为了节省内存,您可以在接收到的消息之间使进程休眠。通过返回原子休眠作为循环元组回调通常返回的一部分来完成此操作。只需在最后添加原子,Cowboy就会相应地休眠。
Static files
Cowboy comes with a ready to use handler for serving static files. It is provided as a convenience for serving files during development.
Cowboy随附了一个随时可用的处理程序,用于处理静态文件。提供它是为了方便在开发过程中提供文件。
For systems in production, consider using one of the many Content Distribution Network (CDN) available on the market, as they are the best solution for serving files.
对于生产中的系统,请考虑使用市场上许多内容分发网络(CDN)中的一种,因为它们是提供文件的最佳解决方案。
The static handler can serve either one file or all files from a given directory. The etag generation and mime types can be configured.
静态处理程序可以提供给定目录中的一个文件或所有文件。可以配置etag生成和mime类型。
Serve one file 服务一个文件
You can use the static handler to serve one specific file from an application's private directory. This is particularly useful to serve an index.html file when the client requests the /path, for example. The path configured is relative to the given application's private directory.
您可以使用静态处理程序从应用程序的专用目录中提供一个特定的文件。例如,当客户端请求/path时,这对于提供index.html文件特别有用。配置的路径是相对于给定应用程序的私有目录的。
The following rule will serve the file static/index.html from the application my_app's priv directory whenever the path / is accessed:
每当访问路径/时,以下规则将从应用程序my_app的priv目录中提供文件static / index.html:
{"/", cowboy_static, {priv_file, my_app, "static/index.html"}}
You can also specify the absolute path to a file, or the path to the file relative to the current directory:
您还可以指定文件的绝对路径,或相对于当前目录的文件路径:
{"/", cowboy_static, {file, "/var/www/index.html"}}
Serve all files from a directory 提供目录中的所有文件
You can also use the static handler to serve all files that can be found in the configured directory. The handler will use the path_info information to resolve the file location, which means that your route must end with a [...] pattern for it to work. All files are served, including the ones that may be found in subfolders.
您还可以使用静态处理程序来提供可在已配置目录中找到的所有文件。处理程序将使用path_info信息来解析文件位置,这意味着您的路由必须以[...]模式结束才能起作用。将提供所有文件,包括子文件夹中可能包含的文件。
You can specify the directory relative to the application's private directory (e.g. my_app/priv).
您可以指定相对于应用程序私有目录的目录(例如my_app / priv)。
The following rule will serve any file found in the my_app application's private directory in the my_app/priv/static/assets folder whenever the requested path begins with /assets/:
每当请求的路径以 /assets/ 开头时,以下规则将为my_app/priv/static/assets文件夹中my_app应用程序的私有目录中找到的任何文件提供服务:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets"}}
You can also specify the absolute path to the directory or set it relative to the current directory:
您还可以指定目录的绝对路径或相对于当前目录进行设置:
{"/assets/[...]", cowboy_static, {dir, "/var/www/assets"}}
Customize the mimetype detection 自定义模仿类型检测
By default, Cowboy will attempt to recognize the mimetype of your static files by looking at the extension.
默认情况下,Cowboy将通过查看扩展名来尝试识别您的静态文件的模仿类型。
You can override the function that figures out the mimetype of the static files. It can be useful when Cowboy is missing a mimetype you need to handle, or when you want to reduce the list to make lookups faster. You can also give a hard-coded mimetype that will be used unconditionally.
您可以覆盖找出静态文件模仿类型的函数。当Cowboy缺少您需要处理的模仿类型时,或者当您希望减少列表以加快查找速度时,此功能很有用。您还可以提供将无条件使用的硬编码模仿类型。
Cowboy comes with two functions built-in. The default function only handles common file types used when building Web applications. The other function is an extensive list of hundreds of mimetypes that should cover almost any need you may have. You can of course create your own function.
Cowboy内置了两个功能。默认功能仅处理在构建Web应用程序时使用的常见文件类型。另一个功能是包含数百种模仿类型的广泛列表,应能满足您几乎所有的需求。您当然可以创建自己的功能。
To use the default function, you should not have to configure anything, as it is the default. If you insist, though, the following will do the job:
要使用默认功能,您不必配置任何内容,因为它是默认功能。但是,如果您坚持要执行以下操作:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",[{mimetypes, cow_mimetypes, web}]}}
As you can see, there is an optional field that may contain a list of less used options, like mimetypes or etag. All option types have this optional field.
如您所见,有一个可选字段,其中可能包含一些使用较少的选项,例如mimetypes或etag。所有选项类型都有此可选字段。
To use the function that will detect almost any mimetype, the following configuration will do:
要使用将检测几乎所有模仿类型的功能,请执行以下配置:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",[{mimetypes, cow_mimetypes, all}]}}
You probably noticed the pattern by now. The configuration expects a module and a function name, so you can use any of your own functions instead:
您现在可能已经注意到了这种模式。该配置需要一个模块和一个函数名,因此您可以使用任何自己的函数:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",[{mimetypes, Module, Function}]}}
The function that performs the mimetype detection receives a single argument that is the path to the file on disk. It is recommended to return the mimetype in tuple form, although a binary string is also allowed (but will require extra processing). If the function can't figure out the mimetype, then it should return {<<"application">>, <<"octet-stream">>, []}.
执行模仿类型检测的函数将接收单个参数,该参数是磁盘上文件的路径。尽管也允许使用二进制字符串(但需要额外的处理),但是建议以元组形式返回mimetype。如果该函数无法计算出模仿类型,则应返回{<<"application">>, <<"octet-stream">>, []}。
When the static handler fails to find the extension, it will send the file as application/octet-stream. A browser receiving such file will attempt to download it directly to disk.
当静态处理程序无法找到扩展名时,它将作为application / octet-stream发送文件。收到此类文件的浏览器将尝试直接将其下载到磁盘。
Finally, the mimetype can be hard-coded for all files. This is especially useful in combination with the file and priv_file options as it avoids needless computation:
最后,可以对所有文件的mimetype进行硬编码。这与file和priv_file选项结合使用特别有用,因为它避免了不必要的计算:
{"/", cowboy_static, {priv_file, my_app, "static/index.html",[{mimetypes, {<<"text">>, <<"html">>, []}}]}}
Generate an etag 产生一个etag
By default, the static handler will generate an etag header value based on the size and modified time. This solution can not be applied to all systems though. It would perform rather poorly over a cluster of nodes, for example, as the file metadata will vary from server to server, giving a different etag on each server.
默认情况下,静态处理程序将根据大小和修改的时间生成etag标头值。但是,此解决方案不能应用于所有系统。例如,由于文件元数据会因服务器而异,因此在节点群集上的性能会相当差,从而给每个服务器提供不同的etag。
You can however change the way the etag is calculated:
但是,您可以更改etag的计算方式:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",[{etag, Module, Function}]}}
This function will receive three arguments: the path to the file on disk, the size of the file and the last modification time. In a distributed setup, you would typically use the file path to retrieve an etag value that is identical across all your servers.
该函数将接收三个参数:磁盘上文件的路径,文件的大小和最后修改时间。在分布式设置中,通常将使用文件路径来检索所有服务器上相同的etag值。
You can also completely disable etag handling:
您还可以完全禁用etag处理:
{"/assets/[...]", cowboy_static, {priv_dir, my_app, "static/assets",[{etag, false}]}}
The Req object
The Req object is a variable used for obtaining information about a request, read its body or send a response.
Req对象是一个变量,用于获取有关请求的信息,读取其主体或发送响应。
It is not really an object in the object-oriented sense. It is a simple map that can be directly accessed or used when calling functions from the cowboy_req module.
从面向对象的意义上说,它并不是真正的对象。这是一个简单的映射,当从cowboy_req模块调用函数时可以直接访问或使用。
The Req object is the subject of a few different chapters. In this chapter we will learn about the Req object and look at how to retrieve information about the request.
Req对象是几个不同章节的主题。在本章中,我们将学习Req对象,并研究如何检索有关请求的信息。
Direct access 直接访问
The Req map contains a number of fields which are documented and can be accessed directly. They are the fields that have a direct mapping to HTTP: the request method; the HTTP version used; the effective URI components scheme, host, port, path and qs; the request headers; the connection peer address and port; and the TLS certificate certwhen applicable.
Req映射包含许多已记录并可以直接访问的字段。它们是直接映射到HTTP的字段:request方法;使用的HTTP版本;有效的URI组件方案,主机,端口,路径和qs;请求头;连接对等地址和端口;和TLS证书cert(如果适用)。
Note that the version field can be used to determine whether a connection is using HTTP/2.
请注意,版本字段可用于确定连接是否正在使用HTTP / 2。
To access a field, you can simply match in the function head. The following example sends a simple "Hello world!" response when the method is GET, and a 405 error otherwise.
要访问一个字段,您只需在功能头中进行匹配即可。下面的示例发送一个简单的“ Hello world!”。方法为GET时响应,否则为405错误。
init(Req0=#{method := <<"GET">>}, State) ->Req = cowboy_req:reply(200, #{<<"content-type">> => <<"text/plain">>}, <<"Hello world!">>, Req0),{ok, Req, State};
init(Req0, State) ->Req = cowboy_req:reply(405, #{<<"allow">> => <<"GET">>}, Req0),{ok, Req, State}.
Any other field is internal and should not be accessed. They may change in future releases, including maintenance releases, without notice.
任何其他字段都是内部的,不应访问。它们可能会在将来的版本(包括维护版本)中更改,恕不另行通知。
Modifying the Req object, while allowed, is not recommended unless strictly necessary. If adding new fields, make sure to namespace the field names so that no conflict can occur with future Cowboy updates or third party projects.
除非绝对必要,否则不建议在允许的情况下修改Req对象。如果添加新字段,请确保为字段名称命名空间,以免与以后的Cowboy更新或第三方项目发生冲突
Introduction to the cowboy_req interface Cowboy_req接口介绍
Functions in the cowboy_req module provide access to the request information but also various operations that are common when dealing with HTTP requests.
cowboy_req模块中的函数提供对请求信息的访问,还提供了处理HTTP请求时常见的各种操作。
All the functions that begin with a verb indicate an action. Other functions simply return the corresponding value (sometimes that value does need to be built, but the cost of the operation is equivalent to retrieving a value).
以动词开头的所有功能都表示一个动作。其他函数仅返回相应的值(有时确实需要构建该值,但是操作成本等同于检索一个值)。
Some of the cowboy_req functions return an updated Req object. They are the read, reply, set and delete functions. While ignoring the returned Req will not cause incorrect behavior for some of them, it is highly recommended to always keep and use the last returned Req object. The manual for cowboy_req details these functions and what modifications are done to the Req object.
一些cowboy_req函数返回更新的Req对象。它们是读取,回复,设置和删除功能。尽管忽略返回的Req不会对其中的某些行为造成不正确的行为,但强烈建议始终保留并使用最后返回的Req对象。 cowboy_req的手册详细介绍了这些功能以及对Req对象的哪些修改。
Some of the calls to cowboy_req have side effects. This is the case of the read and reply functions. Cowboy reads the request body or replies immediately when the function is called.
对cowboy_req的某些调用具有副作用。读取和回复功能就是这种情况。 Cowboy会在调用函数时读取请求正文或立即回复。
All functions will crash if something goes wrong. There is usually no need to catch these errors, Cowboy will send the appropriate 4xx or 5xx response depending on where the crash occurred.
如果出现问题,所有功能将崩溃。通常不需要捕获这些错误,Cowboy将根据崩溃发生的位置发送相应的4xx或5xx响应。
Request method
The request method can be retrieved directly:
可以直接检索请求方法:
#{method := Method} = Req.
Or using a function:
或使用函数
Method = cowboy_req:method(Req).
The method is a case sensitive binary string. Standard methods include GET, HEAD, OPTIONS, PATCH, POST, PUT or DELETE.
该方法是区分大小写的二进制字符串。标准方法包括GET,HEAD,OPTIONS,PATCH,POST,PUT或DELETE。
HTTP version HTTP版本
The HTTP version is informational. It does not indicate that the client implements the protocol well or fully.
HTTP版本仅供参考。它并不表示客户端正确或完整地实现了协议。
There is typically no need to change behavior based on the HTTP version: Cowboy already does it for you.
通常无需基于HTTP版本更改行为:Cowboy已经为您完成了此操作。
It can be useful in some cases, though. For example, one may want to redirect HTTP/1.1 clients to use Websocket, while HTTP/2 clients keep using HTTP/2.
不过,在某些情况下它可能会很有用。例如,一个人可能想重定向HTTP / 1.1客户端以使用Websocket,而HTTP / 2客户端继续使用HTTP / 2。
The HTTP version can be retrieved directly:
可以直接获取HTTP版本:
#{version := Version} = Req.
Or using a function:
或使用函数
Version = cowboy_req:version(Req).
Cowboy defines the 'HTTP/1.0', 'HTTP/1.1' and 'HTTP/2' versions. Custom protocols can define their own values as atoms.
Cowboy定义了“ HTTP / 1.0”,“ HTTP / 1.1”和“ HTTP / 2”版本。自定义协议可以将自己的值定义为原子。
Effective request URI 有效请求URI
The scheme, host, port, path and query string components of the effective request URI can all be retrieved directly:
有效请求URI的方案,主机,端口,路径和查询字符串组件都可以直接检索:
#{scheme := Scheme,host := Host,port := Port,path := Path,qs := Qs
} = Req.
Or using the related functions:
或使用相关函数:
Scheme = cowboy_req:scheme(Req),
Host = cowboy_req:host(Req),
Port = cowboy_req:port(Req),
Path = cowboy_req:path(Req).
Qs = cowboy_req:qs(Req).
The scheme and host are lowercased case insensitive binary strings. The port is an integer representing the port number. The path and query string are case sensitive binary strings.
方案和主机是小写的不区分大小写的二进制字符串。端口是代表端口号的整数。路径和查询字符串是区分大小写的二进制字符串。
Cowboy defines only the <<"http">> and <<"https">> schemes. They are chosen so that the scheme will only be <<"https">> for requests on secure HTTP/1.1 or HTTP/2 connections.
Cowboy仅定义<<“ http” >>和<<“ https” >>方案。选择它们是为了使该方案仅对安全HTTP / 1.1或HTTP / 2连接上的请求为<<“ https” >>。
The effective request URI itself can be reconstructed with the cowboy_req:uri/1,2 function. By default, an absolute URI is returned:
有效请求URI本身可以使用cowboy_req:uri/1,2函数来重构。默认情况下,返回绝对URI:
%%scheme://host[:port]/path[?qs]
URI = cowboy_req:uri(Req).
Options are available to either disable or replace some or all of the components. Various URIs or URI formats can be generated this way, including the origin form:
可以使用选项禁用或替换某些或所有组件。可以通过这种方式生成各种URI或URI格式,包括原始格式:
%% /path[?qs]
URI = cowboy_req:uri(Req, #{host => undefined}).
The protocol relative form:
协议的相对形式:
%% //host[:port]/path[?qs]
URI = cowboy_req:uri(Req, #{scheme => undefined}).
The absolute URI without a query string:
不含查询字符串的绝对URI:
URI = cowboy_req:uri(Req, #{qs => undefined}).
A different host:
其他主机:
URI = cowboy_req:uri(Req, #{host => <<"example.org">>}).
And any other combination.
和任何其他组合。
Bindings 绑定
Bindings are the host and path components that you chose to extract when defining the routes of your application. They are only available after the routing.
绑定是您在定义应用程序的路由时选择提取的主机和路径组件。它们仅在路由之后可用。
Cowboy provides functions to retrieve one or all bindings.
Cowboy提供了检索一个或所有绑定的功能。
To retrieve a single value:
要检索单个值:
Value = cowboy_req:binding(userid, Req).
When attempting to retrieve a value that was not bound, undefined will be returned. A different default value can be provided:
尝试检索未绑定的值时,将返回undefined。可以提供其他默认值:
Value = cowboy_req:binding(userid, Req, 42).
To retrieve everything that was bound:
要检索绑定的所有内容:
Bindings = cowboy_req:bindings(Req).
They are returned as a map, with keys being atoms.
它们作为映射返回,键为原子。
The Cowboy router also allows you to capture many host or path segments at once using the ... qualifier.
Cowboy路由器还允许您使用...限定符一次捕获许多主机或路径段。
To retrieve the segments captured from the host name:
要检索从主机名捕获的段:
HostInfo = cowboy_req:host_info(Req).
And the path segments:
和路径段:
PathInfo = cowboy_req:path_info(Req).
Cowboy will return undefined if ... was not used in the route.
如果未在路线中使用...,牛仔将返回未定义。
Query parameters 查询参数
Cowboy provides two functions to access query parameters. You can use the first to get the entire list of parameters.
Cowboy提供了两种访问查询参数的功能。您可以使用第一个获取完整的参数列表。
QsVals = cowboy_req:parse_qs(Req),
{_, Lang} = lists:keyfind(<<"lang">>, 1, QsVals).
Cowboy will only parse the query string, and not do any transformation. This function may therefore return duplicates, or parameter names without an associated value. The order of the list returned is undefined.
Cowboy将仅解析查询字符串,而不进行任何转换。因此,此函数可能会返回重复项或没有关联值的参数名称。返回列表的顺序是不确定的。
When a query string is key=1&key=2, the list returned will contain two parameters of name key.
当查询字符串为key = 1&key = 2时,返回的列表将包含名称key的两个参数。
The same is true when trying to use the PHP-style suffix []. When a query string is key[]=1&key[]=2, the list returned will contain two parameters of name key[].
尝试使用PHP样式后缀[]时,也是如此。当查询字符串为key[]=1&key[]=2时,返回的列表将包含名称key []的两个参数。
When a query string is simply key, Cowboy will return the list [{<<"key">>, true}], using true to indicate that the parameter key was defined, but with no value.
当查询字符串只是键时,Cowboy将返回列表[{<<“ key” >>,true}],并使用true表示已定义参数键,但没有值。
The second function Cowboy provides allows you to match out only the parameters you are interested in, and at the same time do any post processing you require using constraints. This function returns a map.
Cowboy提供的第二个功能允许您仅匹配您感兴趣的参数,并且同时使用约束进行所需的任何后期处理。此函数返回一个map。
#{id := ID, lang := Lang} = cowboy_req:match_qs([id, lang], Req).
Constraints can be applied automatically. The following snippet will crash when the idparameter is not an integer, or when the lang parameter is empty. At the same time, the value for id will be converted to an integer term:
约束可以自动应用。当id参数不是整数或lang参数为空时,以下代码段将崩溃。同时,id的值将转换为整数项:
QsMap = cowboy_req:match_qs([{id, int}, {lang, nonempty}], Req).
A default value may also be provided. The default will be used if the lang key is not found. It will not be used if the key is found but has an empty value.
也可以提供默认值。如果找不到lang键,将使用默认值。如果找到了密钥但其值为空,将不使用它。
#{lang := Lang} = cowboy_req:match_qs([{lang, [], <<"en-US">>}], Req).
If no default is provided and the value is missing, the query string is deemed invalid and the process will crash.
如果没有提供默认值并且缺少该值,则该查询字符串被视为无效,并且该过程将崩溃
When the query string is key=1&key=2, the value for key will be the list [1, 2]. Parameter names do not need to include the PHP-style suffix. Constraints may be used to ensure that only one value was passed through.
当查询字符串为key=1&key=2时,key的值将为列表[1, 2]。参数名称不需要包含PHP样式的后缀。可以使用约束来确保仅传递一个值。
Headers 标头
Header values can be retrieved either as a binary string or parsed into a more meaningful representation.
标头值可以作为二进制字符串检索,也可以解析为更有意义的表示形式。
The get the raw value:
得到原始值:
HeaderVal = cowboy_req:header(<<"content-type">>, Req).
Cowboy expects all header names to be provided as lowercase binary strings. This is true for both requests and responses, regardless of the underlying protocol.
Cowboy希望所有标头名称均以小写二进制字符串形式提供。无论底层协议是什么,对于请求和响应都是如此。
When the header is missing from the request, undefined will be returned. A different default can be provided:
当请求中缺少标题时,将返回undefined。可以提供其他默认值:
HeaderVal = cowboy_req:header(<<"content-type">>, Req, <<"text/plain">>).
All headers can be retrieved at once, either directly:
可以一次直接检索所有标头:
#{headers := AllHeaders} = Req.
Or using a function:
或使用函数:
AllHeaders = cowboy_req:headers(Req).
Cowboy provides equivalent functions to parse individual headers. There is no function to parse all headers at once.
Cowboy提供了等效的功能来解析各个标头。没有一次解析所有标头的功能。
To parse a specific header:
要解析特定的标头:
ParsedVal = cowboy_req:parse_header(<<"content-type">>, Req).
An exception will be thrown if it doesn't know how to parse the given header, or if the value is invalid. The list of known headers and default values can be found in the manual.
如果不知道如何解析给定的标头,或者该值无效,则将引发异常。已知标题和默认值的列表可在手册中找到。
When the header is missing, undefined is returned. You can change the default value. Note that it should be the parsed value directly:
缺少标题时,将返回undefined。您可以更改默认值。请注意,它应该是直接解析的值:
ParsedVal = cowboy_req:parse_header(<<"content-type">>, Req,{<<"text">>, <<"plain">>, []}).
Peer 同行
The peer address and port number for the connection can be retrieved either directly or using a function.
连接的对等地址和端口号可以直接获取,也可以使用函数获取。
To retrieve the peer directly:
要直接检索对等方:
#{peer := {IP, Port}} = Req.
And using a function:
并使用一个函数:
{IP, Port} = cowboy_req:peer(Req).
Note that the peer corresponds to the remote end of the connection to the server, which may or may not be the client itself. It may also be a proxy or a gateway.
请注意,对等点对应于与服务器的连接的远程端,该端可以是客户端本身,也可以不是客户端本身。它也可以是代理或网关。
Reading the request body 读取请求正文
The request body can be read using the Req object.
可以使用Req对象读取请求正文。
Cowboy will not attempt to read the body until requested. You need to call the body reading functions in order to retrieve it.
除非提出要求,否则牛仔不会尝试读取body 。您需要调用正文读取功能才能检索它。
Cowboy will not cache the body, it is therefore only possible to read it once.
牛仔不会缓存body,因此只能读取一次。
You are not required to read it, however. If a body is present and was not read, Cowboy will either cancel or skip its download, depending on the protocol.
但是,您不需要阅读它。如果存在body但没有读取body,则根据协议,Cowboy将取消或跳过其下载。
Cowboy provides functions for reading the body raw, and read and parse form urlencoded or multipart bodies. The latter is covered in its own chapter.
Cowboy提供了一些函数,用于读取原始的body ,以及读取和解析经过Urlencoded或多部分的body 。后者在其自己的章节中介绍。
Request body presence 请求body 存在
Not all requests come with a body. You can check for the presence of a request body with this function:
并非所有请求都带有主体。您可以使用此功能检查请求正文的存在:
cowboy_req:has_body(Req).
It returns true if there is a body; false otherwise.
如果存在主体,则返回true;否则,返回true。否则为假。
In practice, this function is rarely used. When the method is POST, PUT or PATCH, the request body is often required by the application, which should just attempt to read it directly.
实际上,此功能很少使用。当方法是POST,PUT或PATCH时,应用程序通常需要请求正文,而应用程序应尝试直接读取它。
Request body length 请求boady的长度
You can obtain the length of the body:
您可以获取身体的长度:
Length = cowboy_req:body_length(Req).
Note that the length may not be known in advance. In that case undefined will be returned. This can happen with HTTP/1.1's chunked transfer-encoding, or HTTP/2 when no content-length was provided.
请注意,长度可能事先未知。在这种情况下,将返回undefined。这可能发生在HTTP/1.1的分块传输编码或HTTP/2(未提供内容长度)的情况下。
Cowboy will update the body length in the Req object once the body has been read completely. A length will always be returned when attempting to call this function after reading the body completely.
完整读取body 后,Cowboy将更新Req对象中的body 长度。完全阅读正文后,尝试调用此函数时,总是会返回一个长度。
Reading the body 阅读body
You can read the entire body with one function call:
您可以通过一个函数调用来读取整个正文:
{ok, Data, Req} = cowboy_req:read_body(Req0).
Cowboy returns an ok tuple when the body has been read fully.
充分阅读body 后,Cowboy会返回一个ok元组。
By default, Cowboy will attempt to read up to 8MB of data, for up to 15 seconds. The call will return once Cowboy has read at least 8MB of data, or at the end of the 15 seconds period.
默认情况下,Cowboy将尝试读取最多8MB的数据,最多持续15秒。一旦Cowboy读取了至少8MB的数据,或在15秒周期结束时,呼叫将返回。
These values can be customized. For example, to read only up to 1MB for up to 5 seconds:
这些值可以定制。例如,要读取最多1MB的内容最多5秒钟,请执行以下操作:
{ok, Data, Req} = cowboy_req:read_body(Req0,#{length => 1000000, period => 5000}).
You may also disable the length limit:
您还可以禁用长度限制:
{ok, Data, Req} = cowboy_req:read_body(Req0, #{length => infinity}).
This makes the function wait 15 seconds and return with whatever arrived during that period. This is not recommended for public facing applications.
这会使函数等待15秒,然后返回在此期间到达的所有内容。不建议将其用于面向公众的应用程序。
These two options can effectively be used to control the rate of transmission of the request body.
这两个选项可以有效地用于控制请求主体的传输速率。
Streaming the body 流body
When the body is too large, the first call will return a more tuple instead of ok. You can call the function again to read more of the body, reading it one chunk at a time.
当主体太大时,第一个调用将返回一个更多的元组,而不是确定。您可以再次调用该函数以读取更多内容,一次读取一个内容。
read_body_to_console(Req0) ->case cowboy_req:read_body(Req0) of{ok, Data, Req} ->io:format("~s", [Data]),Req;{more, Data, Req} ->io:format("~s", [Data]),read_body_to_console(Req)end.
The length and period options can also be used. They need to be passed for every call.
长度和周期选项也可以使用。每个呼叫都需要传递它们。
Reading a form urlencoded body 读取表单urlencoded body
Cowboy provides a convenient function for reading and parsing bodies sent as application/x-www-form-urlencoded.
Cowboy提供了一种方便的功能,用于读取和解析作为application / x-www-form-urlencoded发送的正文。
{ok, KeyValues, Req} = cowboy_req:read_urlencoded_body(Req0).
This function returns a list of key/values, exactly like the function cowboy_req:parse_qs/1.
该函数返回键/值的列表,与功能 cowboy_req:parse_qs / 1完全相同。
The defaults for this function are different. Cowboy will read for up to 64KB and up to 5 seconds. They can be modified:
此功能的默认设置不同。 Cowboy最多读取64KB,最多5秒。可以修改它们:
{ok, KeyValues, Req} = cowboy_req:read_urlencoded_body(Req0,#{length => 4096, period => 3000}).
Sending a response
The response must be sent using the Req object.
必须使用Req对象发送响应。
Cowboy provides two different ways of sending responses: either directly or by streaming the body. Response headers and body may be set in advance. The response is sent as soon as one of the reply or stream reply function is called.
牛仔提供了两种不同的发送响应的方式:直接发送或通过流式发送body。响应头和body可以预先设置。一旦调用答复或流答复功能之一,就发送响应。
Cowboy also provides a simplified interface for sending files. It can also send only specific parts of a file.
Cowboy还提供了用于发送文件的简化界面。它也只能发送文件的特定部分。
While only one response is allowed for every request, HTTP/2 introduced a mechanism that allows the server to push additional resources related to the response. This chapter also describes how this feature works in Cowboy.
虽然每个请求只允许一个响应,但是HTTP/2引入了一种机制,该机制允许服务器推送与该响应相关的其他资源。本章还介绍了此功能在Cowboy中的工作方式。
Reply 应答
Cowboy provides three functions for sending the entire reply, depending on whether you need to set headers and body. In all cases, Cowboy will add any headers required by the protocol (for example the date header will always be sent).
根据是否需要设置标题和正文,Cowboy提供了三个用于发送整个答复的功能。在所有情况下,Cowboy都会添加协议所需的任何标头(例如,将始终发送日期标头)。
When you need to set only the status code, use cowboy_req:reply/2:
当您只需要设置状态码时,请使用cowboy_req:reply / 2:
Req = cowboy_req:reply(200, Req0).
When you need to set response headers at the same time, use cowboy_req:reply/3:
当您需要同时设置响应头时,请使用cowboy_req:reply / 3:
Req = cowboy_req:reply(303, #{<<"location">> => <<"https://ninenines.eu">>
}, Req0).
Note that the header name must always be a lowercase binary.
请注意,标头名称必须始终为小写二进制。
When you also need to set the response body, use cowboy_req:reply/4:
当您还需要设置响应正文时,请使用cowboy_req:reply / 4:
Req = cowboy_req:reply(200, #{<<"content-type">> => <<"text/plain">>
}, "Hello world!", Req0).
You should always set the content-type header when the response has a body. There is however no need to set the content-length header; Cowboy does it automatically.
响应包含正文时,应始终设置content-type标头。但是,无需设置content-length标头。Cowboy 会自动执行。
The response body and the header values must be either a binary or an iolist. An iolist is a list containing binaries, characters, strings or other iolists. This allows you to build a response from different parts without having to do any concatenation:
响应主体和标头值必须是二进制或iolist。 iolist是包含二进制文件,字符,字符串或其他iolist的列表。这使您可以从不同部分构建响应,而不必进行任何串联
Title = "Hello world!",
Body = <<"Hats off!">>,
Req = cowboy_req:reply(200, #{<<"content-type">> => <<"text/html">>
}, ["<html><head><title>", Title, "</title></head>","<body><p>", Body, "</p></body></html>"], Req0).
This method of building responses is more efficient than concatenating. Behind the scenes, each element of the list is simply a pointer, and those pointers are used directly when writing to the socket.
这种建立响应的方法比连接更有效。在幕后,列表的每个元素都只是一个指针,并且这些指针在写入套接字时直接使用
Stream reply 流回复
Cowboy provides two functions for initiating a response, and an additional function for streaming the response body. Cowboy will add any required headers to the response.
Cowboy提供了两个用于启动响应的功能,以及一个用于流式传输响应正文的附加功能。 Cowboy会将所有必需的标题添加到响应中。
When you need to set only the status code, use cowboy_req:stream_reply/2:
当您只需要设置状态码时,请使用cowboy_req:stream_reply / 2:
Req = cowboy_req:stream_reply(200, Req0),cowboy_req:stream_body("Hello...", nofin, Req),
cowboy_req:stream_body("chunked...", nofin, Req),
cowboy_req:stream_body("world!!", fin, Req).
The second argument to cowboy_req:stream_body/3 indicates whether this data terminates the body. Use fin for the final flag, and nofin otherwise.
cowboy_req:stream_body/3的第二个参数指示此数据是否终止主体。使用fin作为最终标志,否则使用nofin
This snippet does not set a content-type header. This is not recommended. All responses with a body should have a content-type. The header can be set beforehand, or using the cowboy_req:stream_reply/3:
此代码段未设置内容类型标头。不建议这样做。具有主体的所有响应都应具有内容类型。标头可以预先设置,也可以使用cowboy_req:stream_reply/3设置:
Req = cowboy_req:stream_reply(200, #{<<"content-type">> => <<"text/html">>
}, Req0),cowboy_req:stream_body("<html><head>Hello world!</head>", nofin, Req),
cowboy_req:stream_body("<body><p>Hats off!</p></body></html>", fin, Req).
HTTP provides a few different ways to stream response bodies. Cowboy will select the most appropriate one based on the HTTP version and the request and response headers.
HTTP提供了几种不同的方式来响应正文。 Cowboy将根据HTTP版本以及请求和响应标头选择最合适的一个。
While not required by any means, it is recommended that you set the content-length header in the response if you know it in advance. This will ensure that the best response method is selected and help clients understand when the response is fully received.
尽管绝对不需要,但建议您在响应中设置content-length标头(如果事先知道的话)。这将确保选择最佳的响应方法,并帮助客户理解何时完全收到响应。
Cowboy also provides a function to send response trailers. Response trailers are semantically equivalent to the headers you send in the response, only they are sent at the end. This is especially useful to attach information to the response that could not be generated until the response body was fully generated.
Cowboy还提供了发送响应预告片的功能。响应预告片在语义上等效于您在响应中发送的标头,只有它们是在末尾发送的。这对于将信息附加到响应,直到完全生成响应主体才可以生成。
Trailer fields must be listed in the trailer header. Any field not listed might be dropped by the client or an intermediary.
尾部字段必须在尾部标题中列出。客户或中介可能会丢弃任何未列出的字段。
Req = cowboy_req:stream_reply(200, #{<<"content-type">> => <<"text/html">>,<<"trailer">> => <<"expires, content-md5">>
}, Req0),cowboy_req:stream_body("<html><head>Hello world!</head>", nofin, Req),
cowboy_req:stream_body("<body><p>Hats off!</p></body></html>", nofin, Req),cowboy_req:stream_trailers(#{<<"expires">> => <<"Sun, 10 Dec 2017 19:13:47 GMT">>,<<"content-md5">> => <<"c6081d20ff41a42ce17048ed1c0345e2">>
}, Req).
The stream ends with trailers. It is no longer possible to send data after sending trailers. You cannot send trailers after setting the fin flag when streaming the body.
流以拖车结尾。发送预告片后不再可以发送数据。流主体时,在设置fin标志后,您将无法发送预告片。
Preset response headers 预设响应头
Cowboy provides functions to set response headers without immediately sending them. They are stored in the Req object and sent as part of the response when a reply function is called.
Cowboy提供了设置响应头的功能,而无需立即发送它们。它们存储在Req对象中,并在调用回复函数时作为响应的一部分发送。
To set response headers:
设置响应头:
Req = cowboy_req:set_resp_header(<<"allow">>, "GET", Req0).
Header names must be a lowercase binary.
标头名称必须是小写的二进制。
Do not use this function for setting cookies. Refer to the Cookies chapter for more information.
请勿使用此功能设置Cookie。有关更多信息,请参考Cookies章节。
To check if a response header has already been set:
要检查是否已设置响应头:
cowboy_req:has_resp_header(<<"allow">>, Req).
It returns true if the header was set, false otherwise.
如果设置了标头,则返回true,否则返回false。
To delete a response header that was set previously:
要删除先前设置的响应头:
Req = cowboy_req:delete_resp_header(<<"allow">>, Req0).
Overriding headers 覆盖头
As Cowboy provides different ways of setting response headers and body, clashes may occur, so it's important to understand what happens when a header is set twice.
由于Cowboy提供了设置响应标题和正文的不同方法,因此可能会发生冲突,因此了解两次设置标题会发生什么很重要。
Headers come from five different origins:
- Protocol-specific headers (for example HTTP/1.1's connection header)
- Other required headers (for example the date header)
- Preset headers
- Headers given to the reply function
- Set-cookie headers
标头来自五个不同的来源:
- 协议特定的标头(例如HTTP / 1.1的连接标头)
- 其他必需的标头(例如日期标头)
- 预设标头提供给回复功能的标头
- Set-cookie标头
Cowboy does not allow overriding protocol-specific headers.
Cowboy不允许覆盖特定于协议的标头。
Set-cookie headers will always be appended at the end of the list of headers before sending the response.
在发送响应之前,Set-cookie标题将始终附加在标题列表的末尾。
Headers given to the reply function will always override preset headers and required headers. If a header is found in two or three of these, then the one in the reply function is picked and the others are dropped.
赋予回复功能的标题将始终覆盖预设标题和必需的标题。如果在其中的两个或三个中找到一个标头,则将选择回复功能中的一个标头,然后删除其他标头。
Similarly, preset headers will always override required headers.
同样,预设标题将始终覆盖所需的标题。
To illustrate, look at the following snippet. Cowboy by default sends the server header with the value "Cowboy". We can override it:
为了说明,请看下面的代码片段。缺省情况下,Cowboy发送带有值“ Cowboy”的服务器头。我们可以覆盖它
Req = cowboy_req:reply(200, #{<<"server">> => <<"yaws">>
}, Req0).
Preset response body 预设响应体
Cowboy provides functions to set the response body without immediately sending it. It is stored in the Req object and sent when the reply function is called.
Cowboy提供了用于设置响应主体的功能,而无需立即发送它。它存储在Req对象中,并在调用Reply函数时发送。
To set the response body:
设置响应主体:
Req = cowboy_req:set_resp_body("Hello world!", Req0).
To check if a response body has already been set:
要检查是否已设置响应正文:
cowboy_req:has_resp_body(Req).
It returns true if the body was set and is non-empty, false otherwise.
如果主体已设置且为非空,则返回true,否则返回false。
The preset response body is only sent if the reply function used is cowboy_req:reply/2 or cowboy_req:reply/3.
仅当使用的回复功能为cowboy_req:reply / 2或cowboy_req:reply / 3时,才发送预设响应正文。
Sending files 发送文件
Cowboy provides a shortcut for sending files. When using cowboy_req:reply/4, or when presetting the response header, you can give a sendfile tuple to Cowboy:
Cowboy提供了发送文件的快捷方式。使用cowboy_req:reply / 4或预设响应标头时,可以为Cowboy提供sendfile元组:
{sendfile, Offset, Length, Filename}
Depending on the values for Offset or Length, the entire file may be sent, or just a part of it.
根据“偏移”或“长度”的值,可以发送整个文件,也可以仅发送一部分。
The length is required even for sending the entire file. Cowboy sends it in the content-length header.
即使发送整个文件也需要该长度。 Cowboy在content-length标头中发送它
To send a file while replying:
要在回复时发送文件:
Req = cowboy_req:reply(200, #{<<"content-type">> => "image/png"
}, {sendfile, 0, 12345, "path/to/logo.png"}, Req0).
Informational responses 信息回应
Cowboy allows you to send informational responses.
Cowboy允许您发送信息响应。
Informational responses are responses that have a status code between 100 and 199. Any number can be sent before the proper response. Sending an informational response does not change the behavior of the proper response, and clients are expected to ignore any informational response they do not understand.
信息响应是状态码在100到199之间的响应。可以在正确响应之前发送任何数字。发送信息响应不会改变适当响应的行为,并且希望客户端忽略他们不理解的任何信息响应。
The following snippet sends a 103 informational response with some headers that are expected to be in the final response.
以下代码段发送103信息响应,其中包含一些预期在最终响应中的标头。
Req = cowboy_req:inform(103, #{<<"link">> => <<"</style.css>; rel=preload; as=style, </script.js>; rel=preload; as=script">>
}, Req0).
Push 推
The HTTP/2 protocol introduced the ability to push resources related to the one sent in the response. Cowboy provides two functions for that purpose: cowboy_req:push/3,4.
HTTP / 2协议引入了推送与响应中发送的资源相关的资源的功能。为此,Cowboy提供了两个功能:cowboy_req:push/3,4。
Push is only available for HTTP/2. Cowboy will automatically ignore push requests if the protocol doesn't support it.
推送仅适用于HTTP / 2。如果协议不支持,Cowboy 将自动忽略推送请求。
The push function must be called before any of the reply functions. Doing otherwise will result in a crash.
必须在任何回复函数之前调用push函数。否则会导致崩溃。
To push a resource, you need to provide the same information as a client performing a request would. This includes the HTTP method, the URI and any necessary request headers.
要推送资源,您需要提供与执行请求的客户端相同的信息。这包括HTTP方法,URI和任何必要的请求标头。
Cowboy by default only requires you to give the path to the resource and the request headers. The rest of the URI is taken from the current request (excluding the query string, set to empty) and the method is GET by default.
默认情况下,Cowboy仅要求您提供资源路径和请求标头。 URI的其余部分取自当前请求(不包括查询字符串,设置为空),默认情况下该方法为GET
The following snippet pushes a CSS file that is linked to in the response:
以下代码段将推送一个链接到响应中的CSS文件:
cowboy_req:push("/static/style.css", #{<<"accept">> => <<"text/css">>
}, Req0),
Req = cowboy_req:reply(200, #{<<"content-type">> => <<"text/html">>
}, ["<html><head><title>My web page</title>","<link rel='stylesheet' type='text/css' href='/static/style.css'>","<body><p>Welcome to Erlang!</p></body></html>"], Req0).
To override the method, scheme, host, port or query string, simply pass in a fourth argument. The following snippet uses a different host name:
要覆盖方法,方案,主机,端口或查询字符串,只需传入第四个参数即可。以下代码段使用其他主机名:
cowboy_req:push("/static/style.css", #{<<"accept">> => <<"text/css">>
}, #{host => <<"cdn.example.org">>}, Req),
Pushed resources don't have to be files. As long as the push request is cacheable, safe and does not include a body, the resource can be pushed.
推送的资源不必是文件。只要推送请求是可缓存的,安全的并且不包含主体,就可以推送资源。
Under the hood, Cowboy handles pushed requests the same as normal requests: a different process is created which will ultimately send a response to the client.
在后台,Cowboy处理推送的请求的方式与正常请求相同:创建了一个不同的过程,该过程最终将向客户端发送响应。
Using cookies 使用cookie
Cookies are a mechanism allowing applications to maintain state on top of the stateless HTTP protocol.
Cookies是一种机制,允许应用程序在无状态HTTP协议之上维护状态。
Cookies are a name/value store where the names and values are stored in plain text. They expire either after a delay or when the browser closes. They can be configured on a specific domain name or path, and restricted to secure resources (sent or downloaded over HTTPS), or restricted to the server (disallowing access from client-side scripts).
Cookies是一个名称/值存储,其中的名称和值以纯文本格式存储。它们会在延迟或浏览器关闭后过期。可以在特定的域名或路径上配置它们,并限制为安全资源(通过HTTPS发送或下载),或限制为服务器(禁止从客户端脚本访问)。
Cookie names are de facto case sensitive.
Cookie名称实际上区分大小写。
Cookies are stored client-side and sent with every subsequent request that matches the domain and path for which they were stored, until they expire. This can create a non-negligible cost.
Cookies是在客户端存储的,并随与存储它们的域和路径匹配的每个后续请求一起发送,直到它们过期。这会产生不可忽略的成本。
Cookies should not be considered secure. They are stored on the user's computer in plain text, and can be read by any program. They can also be read by proxies when using clear connections. Always validate the value before using it, and never store any sensitive information inside it.
Cookies不应被认为是安全的。它们以纯文本格式存储在用户的计算机上,并且可以由任何程序读取。使用明晰的连接时,代理也可以读取它们。在使用值之前,请始终对其进行验证,并且切勿在其中存储任何敏感信息。
Cookies set by the server are only available in requests following the client reception of the response containing them.
服务器设置的cookie仅在客户端接收到包含它们的响应之后的请求中可用。
Cookies may be sent repeatedly. This is often useful to update the expiration time and avoid losing a cookie.
Cookies可能会重复发送。这通常对于更新到期时间并避免丢失cookie很有用。
Setting cookies 设置饼干
By default cookies are defined for the duration of the session:
默认情况下,在会话期间定义cookie:
SessionID = generate_session_id(),
Req = cowboy_req:set_resp_cookie(<<"sessionid">>, SessionID, Req0).
They can also be set for a duration in seconds:
也可以将它们设置为几秒钟的持续时间:
SessionID = generate_session_id(),
Req = cowboy_req:set_resp_cookie(<<"sessionid">>, SessionID, Req0,#{max_age => 3600}).
To delete cookies, set max_age to 0:
要删除cookie,请将max_age设置为0:
SessionID = generate_session_id(),
Req = cowboy_req:set_resp_cookie(<<"sessionid">>, SessionID, Req0,#{max_age => 0}).
To restrict cookies to a specific domain and path, the options of the same name can be used:
要将Cookie限制为特定的域和路径,可以使用相同名称的选项:
Req = cowboy_req:set_resp_cookie(<<"inaccount">>, <<"1">>, Req0,#{domain => "my.example.org", path => "/account"}).
Cookies will be sent with requests to this domain and all its subdomains, and to resources on this path or deeper in the path hierarchy.
Cookies将与请求一起发送到该域及其所有子域,并发送到此路径或路径层次结构中更深层的资源。
To restrict cookies to secure channels (typically resources available over HTTPS):
要将Cookie限制为安全通道(通常是通过HTTPS可用的资源)
SessionID = generate_session_id(),
Req = cowboy_req:set_resp_cookie(<<"sessionid">>, SessionID, Req0,#{secure => true}).
To prevent client-side scripts from accessing a cookie:
为防止客户端脚本访问Cookie,请执行以下操作:
SessionID = generate_session_id(),
Req = cowboy_req:set_resp_cookie(<<"sessionid">>, SessionID, Req0,#{http_only => true}).
Cookies may also be set client-side, for example using Javascript.
Cookie也可以在客户端设置,例如使用Javascript。
Reading cookies 阅读饼干
The client only ever sends back the cookie name and value. All other options that can be set are never sent back.
客户端只会发送回cookie名称和值。可以设置的所有其他选项永远不会发回。
Cowboy provides two functions for reading cookies. Both involve parsing the cookie header(s) and so should not be called repeatedly.
Cowboy提供了两种读取Cookie的功能。两者都涉及解析cookie头,因此不应重复调用。
You can get all cookies as a key/value list:
您可以将所有cookie作为键/值列表获取:
Cookies = cowboy_req:parse_cookies(Req),
{_, Lang} = lists:keyfind(<<"lang">>, 1, Cookies).
Or you can perform a match against cookies and retrieve only the ones you need, while at the same time doing any required post processing using constraints. This function returns a map:
或者,您可以对cookie进行匹配并仅检索所需的cookie,同时使用约束条件进行任何所需的后处理。此函数返回一个映射:
#{id := ID, lang := Lang} = cowboy_req:match_cookies([id, lang], Req).
You can use constraints to validate the values while matching them. The following snippet will crash if the id cookie is not an integer number or if the lang cookie is empty. Additionally the id cookie value will be converted to an integer term:
您可以使用约束来验证值,同时匹配它们。如果id cookie不是整数或lang cookie为空,则以下代码段将崩溃。另外,id cookie值将转换为整数项:
CookiesMap = cowboy_req:match_cookies([{id, int}, {lang, nonempty}], Req).
Note that if two cookies share the same name, then the map value will be a list of the two cookie values.
请注意,如果两个cookie共享相同的名称,则映射值将是两个cookie值的列表。
A default value can be provided. The default will be used if the lang cookie is not found. It will not be used if the cookie is found but has an empty value:
可以提供默认值。如果找不到lang cookie,将使用默认值。如果找到cookie,但其值为空,将不使用它:
#{lang := Lang} = cowboy_req:match_cookies([{lang, [], <<"en-US">>}], Req).
If no default is provided and the value is missing, an exception is thrown.
如果没有提供默认值,并且缺少该值,则会引发异常。
Multipart requests 多部分请求
Multipart originates from MIME, an Internet standard that extends the format of emails.
Multipart源自MIME,MIME是扩展电子邮件格式的Internet标准。
A multipart message is a list of parts. A part contains headers and a body. The body of the parts may be of any media type, and contain text or binary data. It is possible for parts to contain a multipart media type.
多部分消息是部分列表。零件包含标题和主体。部件的主体可以是任何媒体类型,并包含文本或二进制数据。零件可能包含多部分媒体类型。
In the context of HTTP, multipart is most often used with the multipart/form-data media type. It is what browsers use to upload files through HTML forms.
在HTTP上下文中,multipart最常与multipart / form-data媒体类型一起使用。这是浏览器用来通过HTML表单上传文件的工具。
The multipart/byteranges is also common. It is the media type used to send arbitrary bytes from a resource, enabling clients to resume downloads.
multipart / byteranges也很常见。它是用于从资源发送任意字节的媒体类型,使客户端能够继续下载。
Form-data 表单数据
In the normal case, when a form is submitted, the browser will use the application/x-www-form-urlencoded content-type. This type is just a list of keys and values and is therefore not fit for uploading files.
在正常情况下,提交表单后,浏览器将使用application / x-www-form-urlencoded内容类型。此类型只是键和值的列表,因此不适合上传文件。
That's where the multipart/form-data content-type comes in. When the form is configured to use this content-type, the browser will create a multipart message where each part corresponds to a field on the form. For files, it also adds some metadata in the part headers, like the file name.
这就是要输入multipart / form-data内容类型的地方。将表单配置为使用此内容类型时,浏览器将创建一个多部分消息,其中每个部分都对应于表单上的字段。对于文件,它还会在零件标题中添加一些元数据,例如文件名。
A form with a text input, a file input and a select choice box will result in a multipart message with three parts, one for each field.
具有文本输入,文件输入和选择选择框的表单将导致包含三部分的多部分消息,每个字段一个。
The browser does its best to determine the media type of the files it sends this way, but you should not rely on it for determining the contents of the file. Proper investigation of the contents is recommended.
浏览器会尽力确定以这种方式发送的文件的媒体类型,但您不应依靠它来确定文件的内容。建议对内容进行正确的调查。
Checking for multipart messages 检查多部分消息
The content-type header indicates the presence of a multipart message:
内容类型标头指示存在多部分消息:
{<<"multipart">>, <<"form-data">>, _}= cowboy_req:parse_header(<<"content-type">>, Req).
Reading a multipart message
Cowboy provides two sets of functions for reading request bodies as multipart messages.
Cowboy提供了两组函数,用于将请求正文作为多部分消息读取。
The cowboy_req:read_part/1,2 functions return the next part's headers, if any.
cowboy_req:read_part / 1,2函数返回下一部分的标题(如果有)。
The cowboy_req:read_part_body/1,2 functions return the current part's body. For large bodies you may need to call the function multiple times.
cowboy_req:read_part_body / 1,2函数返回当前零件的主体。对于大型物体,您可能需要多次调用该函数。
To read a multipart message you need to iterate over all its parts:
要阅读多部分消息,您需要遍历所有部分:
multipart(Req0) ->case cowboy_req:read_part(Req0) of{ok, _Headers, Req1} ->{ok, _Body, Req} = cowboy_req:read_part_body(Req1),multipart(Req);{done, Req} ->Reqend.
When part bodies are too large, Cowboy will return a more tuple, and allow you to loop until the part body has been fully read.
当零件体太大时,Cowboy将返回一个更多的元组,并允许您循环直到零件体被完全读取。
The function cow_multipart:form_data/1 can be used to quickly obtain information about a part from a multipart/form-data message. The function returns a data or a file tuple depending on whether this is a normal field or a file being uploaded.
函数cow_multipart:form_data/1 1可用于从multipart/form-data消息中快速获取有关零件的信息。该函数根据是正常字段还是要上传的文件返回数据或文件元组。
The following snippet will use this function and use different strategies depending on whether the part is a file:
以下代码段将使用此功能,并根据零件是否为文件使用不同的策略:
multipart(Req0) ->case cowboy_req:read_part(Req0) of{ok, Headers, Req1} ->Req = case cow_multipart:form_data(Headers) of{data, _FieldName} ->{ok, _Body, Req2} = cowboy_req:read_part_body(Req1),Req2;{file, _FieldName, _Filename, _CType} ->stream_file(Req1)end,multipart(Req);{done, Req} ->Reqend.stream_file(Req0) ->case cowboy_req:read_part_body(Req0) of{ok, _LastBodyChunk, Req} ->Req;{more, _BodyChunk, Req} ->stream_file(Req)end.
Both the part header and body reading functions can take options that will be given to the request body reading functions. By default, cowboy_req:read_part/1 reads up to 64KB for up to 5 seconds. cowboy_req:read_part_body/1 has the same defaults as cowboy_req:read_body/1.
零件标题和正文读取功能都可以采用将提供给请求正文读取功能的选项。默认情况下,cowboy_req:read_part/11读取最多64KB的内容最多5秒钟。 cowboy_req:read_part_body/1的默认设置与cowboy_req:read_body/1相同。
To change the defaults for part headers:
要更改零件标题的默认设置:
cowboy_req:read_part(Req, #{length => 128000}).
And for part bodies:
对于零件主体:
cowboy_req:read_part_body(Req, #{length => 1000000, period => 7000}).
Skipping unwanted parts 跳过不需要的零件
Part bodies do not have to be read. Cowboy will automatically skip it when you request the next part's body.
零件主体不必读取。当您请求下一部分的身体时,Cowboy会自动跳过它。
The following snippet reads all part headers and skips all bodies:
以下代码段读取所有零件标题,并跳过所有主体:
multipart(Req0) ->case cowboy_req:read_part(Req0) of{ok, _Headers, Req} ->multipart(Req);{done, Req} ->Reqend.
Similarly, if you start reading the body and it ends up being too big, you can simply continue with the next part. Cowboy will automatically skip what remains.
同样,如果您开始阅读正文,但结果太大,则可以继续下一部分。Cowboy 会自动跳过剩下的东西。
While Cowboy can skip part bodies automatically, the read rate is not configurable. Depending on your application you may want to skip manually, in particular if you observe poor performance while skipping.
虽然Cowboy可以自动跳过零件,但是读取速率是不可配置的。根据您的应用程序,您可能需要手动跳过,特别是如果您在跳过时发现性能不佳时。
You do not have to read all parts either. You can stop reading as soon as you find the data you need.
您也不必阅读所有部分。找到所需数据后,您可以立即停止阅读。
REST principles REST原则
This chapter will attempt to define the concepts behind REST and explain what makes a service RESTful.
本章将尝试定义REST背后的概念,并说明使服务成为RESTful的原因
REST is often confused with performing a distinct operation depending on the HTTP method, while using more than the GET and POST methods. That's highly misguided at best.
REST通常与根据HTTP方法执行不同的操作相混淆,而使用的不仅仅是GET和POST方法。充其量是极度误导的。
We will first attempt to define REST and will look at what it means in the context of HTTP and the Web. For a more in-depth explanation of REST, you can read Roy T. Fielding's dissertation as it does a great job explaining where it comes from and what it achieves.
我们将首先尝试定义REST,并查看它在HTTP和Web上下文中的含义。有关REST的更深入说明,您可以阅读Roy T. Fielding的论文,因为它在解释它的来源和实现方面做得很好。
REST architecture REST架构
REST is a client-server architecture. The client and the server both have a different set of concerns. The server stores and/or manipulates information and makes it available to the user in an efficient manner. The client takes that information and displays it to the user and/or uses it to perform subsequent requests for information. This separation of concerns allows both the client and the server to evolve independently as it only requires that the interface stays the same.
REST是一种客户端-服务器体系结构。客户端和服务器都有不同的关注点。服务器存储和/或操纵信息,并以有效的方式使信息可供用户使用。客户端获取该信息并将其显示给用户和/或使用它执行后续的信息请求。关注点的分离允许客户端和服务器独立发展,因为它只需要接口保持不变即可。
REST is stateless. That means the communication between the client and the server always contains all the information needed to perform the request. There is no session state in the server, it is kept entirely on the client's side. If access to a resource requires authentication, then the client needs to authenticate itself with every request.
REST是无状态的。这意味着客户端和服务器之间的通信始终包含执行请求所需的所有信息。服务器中没有会话状态,它完全保留在客户端。如果对资源的访问需要身份验证,则客户端需要对每个请求进行身份验证。
REST is cacheable. The client, the server and any intermediary components can all cache resources in order to improve performance.
REST是可缓存的。客户端,服务器和任何中间组件都可以缓存资源以提高性能。
REST provides a uniform interface between components. This simplifies the architecture, as all components follow the same rules to speak to one another. It also makes it easier to understand the interactions between the different components of the system. A number of constraints are required to achieve this. They are covered in the rest of the chapter.
REST在组件之间提供了统一的接口。由于所有组件都遵循相同的规则进行相互交谈,因此简化了架构。它还使理解系统的不同组件之间的交互变得更加容易。要达到此目的,需要许多约束。本章的其余部分将介绍它们。
REST is a layered system. Individual components cannot see beyond the immediate layer with which they are interacting. This means that a client connecting to an intermediate component, like a proxy, has no knowledge of what lies beyond. This allows components to be independent and thus easily replaceable or extendable.
REST是一个分层系统。各个组件无法看到与它们交互的直接层。这意味着连接到中间组件(如代理)的客户端不了解范围之外的内容。这允许组件是独立的,因此易于更换或扩展。
REST optionally provides code on demand. Code may be downloaded to extend client functionality. This is optional however because the client may not be able to download or run this code, and so a REST component cannot rely on it being executed.
REST可选地按需提供代码。可以下载代码以扩展客户端功能。但是,这是可选的,因为客户端可能无法下载或运行此代码,因此REST组件不能依赖于其执行。
Resources and resource identifiers 资源和资源标识符
A resource is an abstract concept. In a REST system, any information that can be named may be a resource. This includes documents, images, a collection of resources and any other information. Any information that can be the target of an hypertext link can be a resource.
资源是一个抽象的概念。在REST系统中,可以命名的任何信息都可以是资源。这包括文档,图像,资源集合和任何其他信息。可以作为超文本链接目标的任何信息都可以是资源。
A resource is a conceptual mapping to a set of entities. The set of entities evolves over time; a resource doesn't. For example, a resource can map to "users who have logged in this past month" and another to "all users". At some point in time they may map to the same set of entities, because all users logged in this past month. But they are still different resources. Similarly, if nobody logged in recently, then the first resource may map to the empty set. This resource exists regardless of the information it maps to.
资源是到一组实体的概念映射。实体集会随着时间而演变;资源没有。例如,一个资源可以映射到“过去一个月登录的用户”,另一个可以映射到“所有用户”。在某个时间点,他们可能会映射到同一组实体,因为所有用户都在上个月登录。但是它们仍然是不同的资源。同样,如果最近没有人登录,则第一个资源可能会映射到空集。此资源存在,无论它映射到什么信息。
Resources are identified by uniform resource identifiers, also known as URIs. Sometimes internationalized resource identifiers, or IRIs, may also be used, but these can be directly translated into a URI.
资源由统一资源标识符(也称为URI)标识。有时也可以使用国际化的资源标识符或IRI,但是这些标识符可以直接转换为URI。
In practice we will identify two kinds of resources. Individual resources map to a set of one element, for example "user Joe". Collection of resources map to a set of 0 to N elements, for example "all users".
在实践中,我们将识别两种资源。各个资源映射到一组一个元素,例如“用户Joe”。资源集合映射到一组0到N个元素,例如“所有用户”
Resource representations 资源表示
The representation of a resource is a sequence of bytes associated with metadata.
资源的表示形式是与元数据关联的字节序列。
The metadata comes as a list of key-value pairs, where the name corresponds to a standard that defines the value's structure and semantics. With HTTP, the metadata comes in the form of request or response headers. The headers' structure and semantics are well defined in the HTTP standard. Metadata includes representation metadata, resource metadata and control data.
元数据以键-值对的列表的形式出现,其中名称对应于定义值的结构和语义的标准。使用HTTP,元数据以请求或响应头的形式出现。标头的结构和语义在HTTP标准中定义良好。元数据包括表示元数据,资源元数据和控制数据。
The representation metadata gives information about the representation, such as its media type, the date of last modification, or even a checksum.
表示形式元数据提供有关表示形式的信息,例如其媒体类型,上次修改日期甚至校验和。
Resource metadata could be link to related resources or information about additional representations of the resource.
资源元数据可以链接到相关资源或有关资源其他表示的信息。
Control data allows parameterizing the request or response. For example, we may only want the representation returned if it is more recent than the one we have in cache. Similarly, we may want to instruct the client about how it should cache the representation. This isn't restricted to caching. We may, for example, want to store a new representation of a resource only if it wasn't modified since we first retrieved it.
控制数据允许参数化请求或响应。例如,我们可能只希望返回的表示形式比我们在缓存中的表示形式更新。同样,我们可能要指导客户端如何缓存表示。这不限于缓存。例如,我们可能只想存储一个新的资源表示形式,因为自从我们第一次检索它以来就没有对其进行过修改。
The data format of a representation is also known as the media type. Some media types are intended for direct rendering to the user, while others are intended for automated processing. The media type is a key component of the REST architecture.
表示形式的数据格式也称为媒体类型。某些媒体类型旨在直接呈现给用户,而其他媒体类型旨在进行自动处理。媒体类型是REST体系结构的关键组成部分。
Self-descriptive messages 自我描述信息
Messages must be self-descriptive. That means that the data format of a representation must always come with its media type (and similarly requesting a resource involves choosing the media type of the representation returned). If you are sending HTML, then you must say it is HTML by sending the media type with the representation. In HTTP this is done using the content-type header.
消息必须具有自我描述性。这意味着表示的数据格式必须始终带有其媒体类型(并且类似地,请求资源涉及选择返回的表示的媒体类型)。如果要发送HTML,则必须通过发送带有表示形式的媒体类型来说它是HTML。在HTTP中,这是使用content-type标头完成的。
The media type is often an IANA registered media type, like text/html or image/png, but does not need to be. Exactly two things are important for respecting this constraint: that the media type is well specified, and that the sender and recipient agree about what the media type refers to.
媒体类型通常是IANA注册的媒体类型,例如text / html或image / png,但不是必须的。对于遵守此约束而言,确实有两点很重要:正确指定了媒体类型,并且发送者和接收者就媒体类型所指的内容达成了一致。
This means that you can create your own media types, like application/x-mine, and that as long as you write the specifications for it and that both endpoints agree about it then the constraint is respected.
这意味着您可以创建自己的媒体类型,例如application/x-mine,并且只要您为其编写规范并且两个端点都同意它,那么就可以遵守该约束。
Hypermedia as the engine of application state 超媒体作为应用程序状态的引擎
The last constraint is generally where services that claim to be RESTful fail. Interactions with a server must be entirely driven by hypermedia. The client does not need any prior knowledge of the service in order to use it, other than an entry point and of course basic understanding of the media type of the representations, at the very least enough to find and identify hyperlinks and link relations.
最后一个约束通常是声称为RESTful的服务失败的地方。与服务器的交互必须完全由超媒体驱动。客户端不需要任何先验知识即可使用该服务,除了进入点,当然还有对表示形式媒体类型的基本理解,至少足以找到和识别超链接和链接关系。
To give a simple example, if your service only works with the application/json media type then this constraint cannot be respected (as there are no concept of links in JSON) and thus your service isn't RESTful. This is the case for the majority of self-proclaimed REST services.
举一个简单的例子,如果您的服务仅适用于application/json媒体类型,则无法遵守此约束(因为JSON中没有链接的概念),因此您的服务不是RESTful的。大多数自称REST服务的情况就是如此。
On the other hand if you create a JSON based media type that has a concept of links and link relations, then your service might be RESTful.
另一方面,如果您创建具有链接和链接关系概念的基于JSON的媒体类型,则您的服务可能是RESTful的。
Respecting this constraint means that the entirety of the service becomes self-discoverable, not only the resources in it, but also the operations you can perform on it. This makes clients very thin as there is no need to implement anything specific to the service to operate on it.
遵守此约束意味着不仅服务中的资源,而且您可以对其执行的操作都可以自我发现整个服务。这使客户端非常瘦,因为无需对其实施任何特定于服务的操作。
REST handlers
REST is implemented in Cowboy as a sub protocol. The request is handled as a state machine with many optional callbacks describing the resource and modifying the machine's behavior.
REST在Cowboy中作为子协议实现。该请求作为状态机处理,具有许多可选的回调,这些回调描述资源并修改机器的行为。
The REST handler is the recommended way to handle HTTP requests.
推荐使用REST处理程序来处理HTTP请求。
Initialization 初始化
First, the init/2 callback is called. This callback is common to all handlers. To use REST for the current request, this function must return a cowboy_rest tuple.
首先,调用init/2回调。该回调对于所有处理程序都是通用的。要将REST用于当前请求,此函数必须返回cowboy_rest元组。
init(Req, State) ->{cowboy_rest, Req, State}.
Cowboy will then switch to the REST protocol and start executing the state machine.
Cowboy随后将切换到REST协议并开始执行状态机。
After reaching the end of the flowchart, the terminate/3 callback will be called if it is defined.
到达流程图的末尾后,如果已定义则terminate/3回调将被调用。
Methods 方法
The REST component has code for handling the following HTTP methods: HEAD, GET, POST, PATCH, PUT, DELETE and OPTIONS.
REST组件具有用于处理以下HTTP方法的代码:HEAD,GET,POST,PATCH,PUT,DELETE和OPTIONS。
Other methods can be accepted, however they have no specific callback defined for them at this time.
可以接受其他方法,但是目前没有为它们定义特定的回调。
Callbacks 回调
All callbacks are optional. Some may become mandatory depending on what other defined callbacks return. The various flowcharts in the next chapter should be a useful to determine which callbacks you need.
所有回调都是可选的。根据其他定义的回调返回的内容,有些可能成为强制性的。下一章中的各种流程图将有助于确定所需的回调。
All callbacks take two arguments, the Req object and the State, and return a three-element tuple of the form {Value, Req, State}.
所有回调都接受两个参数,即Req对象和State,并返回{Value,Req,State}形式的三元素元组。
Nearly all callbacks can also return {stop, Req, State} to stop execution of the request, and {{switch_handler, Module}, Req, State} or {{switch_handler, Module, Opts}, Req, State} to switch to a different handler type. The exceptions are expires generate_etag, last_modified and variances.
几乎所有的回调函数也可以返回{stop,Req,State}停止执行请求,并返回{{switch_handler,Module},Req,State}或{{switch_handler,Module,Opts},Req,State}切换到不同的处理程序类型。例外是expires generate_etag,last_modified和variances。
The following table summarizes the callbacks and their default values. If the callback isn't defined, then the default value will be used. Please look at the flowcharts to find out the result of each return value.
下表总结了回调及其默认值。如果未定义回调,则将使用默认值。请查看流程图以找出每个返回值的结果
In the following table, "skip" means the callback is entirely skipped if it is undefined, moving directly to the next step. Similarly, "none" means there is no default value for this callback.
在下表中,“skip”表示未定义的回调将被完全跳过,直接进入下一步。同样,“none”表示此回调没有默认值。
| Callback name | Default value |
|---|---|
| allowed_methods |
[<<"GET">>, <<"HEAD">>, <<"OPTIONS">>]
|
| allow_missing_post |
true
|
| charsets_provided | skip |
| content_types_accepted | none |
| content_types_provided |
[{{ <<"text">>, <<"html">>, '*'}, to_html}]
|
| delete_completed |
true
|
| delete_resource |
false
|
| expires |
undefined
|
| forbidden |
false
|
| generate_etag |
undefined
|
| is_authorized |
true
|
| is_conflict |
false
|
| known_methods |
[<<"GET">>, <<"HEAD">>, <<"POST">>, <<"PUT">>, <<"PATCH">>, <<"DELETE">>, <<"OPTIONS">>]
|
| languages_provided | skip |
| last_modified |
undefined
|
| malformed_request |
false
|
| moved_permanently |
false
|
| moved_temporarily |
false
|
| multiple_choices |
false
|
| options |
ok
|
| previously_existed |
false
|
| rate_limited |
false
|
| resource_exists |
true
|
| service_available |
true
|
| uri_too_long |
false
|
| valid_content_headers |
true
|
| valid_entity_length |
true
|
| variances |
[]
|
As you can see, Cowboy tries to move on with the request whenever possible by using well thought out default values.
如您所见,Cowboy尝试通过使用经过深思熟虑的默认值来继续处理请求。
In addition to these, there can be any number of user-defined callbacks that are specified through content_types_accepted/2 and content_types_provided/2. They can take any name, however it is recommended to use a separate prefix for the callbacks of each function. For example, from_html and to_html indicate in the first case that we're accepting a resource given as HTML, and in the second case that we send one as HTML.
除此之外,还可以通过content_types_accepted/2和content_types_provided/2指定任意数量的用户定义的回调。它们可以采用任何名称,但是建议对每个函数的回调使用单独的前缀。例如,from_html 和to_html在第一种情况下表示我们接受以HTML形式给出的资源,在第二种情况下,我们以HTML形式发送资源。
Meta data 元数据
Cowboy will set informative values to the Req object at various points of the execution. You can retrieve them by matching the Req object directly. The values are defined in the following table:
Cowboy将在执行的各个时间点为Req对象设置信息量。您可以通过直接匹配Req对象来检索它们。下表中定义了这些值:
| Key | Details |
|---|---|
| media_type | The content-type negotiated for the response entity. 为响应实体协商的内容类型。 |
| language | The language negotiated for the response entity. 为响应实体协商的语言。 |
| charset | The charset negotiated for the response entity. 字符集协商响应实体。 |
They can be used to send a proper body with the response to a request that used a method other than HEAD or GET.
它们可以用于发送适当的正文,以及对使用HEAD或GET以外的方法的请求的响应。
Response headers 响应头
Cowboy will set response headers automatically over the execution of the REST code. They are listed in the following table.
Cowboy将在REST代码执行期间自动设置响应头。下表中列出了它们。
| Header name | Details |
|---|---|
| content-language | Language used in the response body 响应主体中使用的语言 |
| content-type | Media type and charset of the response body 响应主体的媒体类型和字符集 |
| etag | Etag of the resource 资源的标签 |
| expires | Expiration date of the resource 资源的到期日期 |
| last-modified | Last modification date for the resource 资源的最后修改日期 |
| location | Relative or absolute URI to the requested resource 所请求资源的相对或绝对URI |
| vary | List of headers that may change the representation of the resource 可能更改资源表示的标头列表 |
REST flowcharts REST流程图
This chapter will explain the REST handler state machine through a number of different diagrams.
本章将通过许多不同的图来说明REST处理程序状态机。
There are four main paths that requests may follow. One for the method OPTIONS; one for the methods GET and HEAD; one for the methods PUT, POST and PATCH; and one for the method DELETE.
请求可能遵循四个主要路径。一种方法选项;一种用于方法GET和HEAD;一种用于方法PUT,POST和PATCH;一种是方法DELETE。
All paths start with the "Start" diagram, and all paths excluding the OPTIONS path go through the "Content negotiation" diagram and optionally the "Conditional requests" diagram if the resource exists.
所有路径均以“开始”图开头,除OPTIONS路径之外的所有路径均通过“内容协商”图,如果资源存在,则通过“条件请求”图。
The red squares refer to another diagram. The light green squares indicate a response. Other squares may be either a callback or a question answered by Cowboy itself. Green arrows tend to indicate the default behavior if the callback is undefined. The star next to values indicate that the value is descriptive rather than exact.
红色方块表示另一张图。浅绿色方块表示响应。其他方块可能是回调,也可能是Cowboy本身回答的问题。如果未定义回调,则绿色箭头倾向于指示默认行为。值旁边的星号表示该值是描述性的而不是精确的。
Start
All requests start from here.
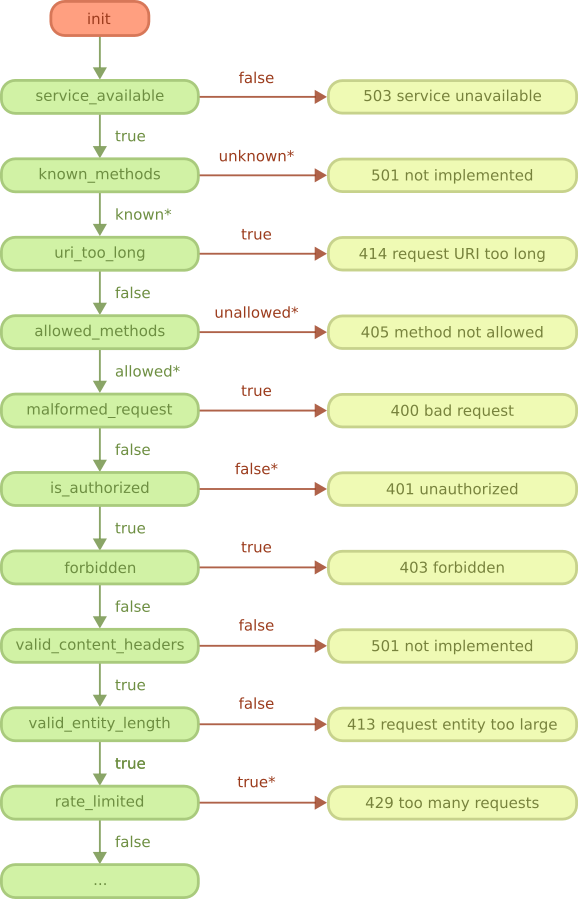
A series of callbacks are called in succession to perform a general checkup of the service, the request line and request headers.
依次调用一系列回调以对服务,请求行和请求标头执行常规检查。
The request body, if any, is not expected to have been received for any of these steps. It is only processed at the end of the "PUT, POST and PATCH methods" diagram, when all conditions have been met.
这些步骤中的任何一个都不会收到请求正文(如果有的话)。当满足所有条件时,仅在“ PUT,POST和PATCH方法”图的末尾对其进行处理。
The known_methods and allowed_methods callbacks return a list of methods. Cowboy then checks if the request method is in the list, and stops otherwise.
known_methods和allowed_methods回调返回方法列表。 Cowboy然后检查请求方法是否在列表中,否则停止。
The is_authorized callback may be used to check that access to the resource is authorized. Authentication may also be performed as needed. When authorization is denied, the return value from the callback must include a challenge applicable to the requested resource, which will be sent back to the client in the www-authenticate header.
is_authorized回调可用于检查对资源的访问是否已授权。认证也可以根据需要执行。拒绝授权后,回调的返回值必须包含适用于所请求资源的质询,该质询将通过www-authenticate标头发送回客户端。
This diagram is immediately followed by either the "OPTIONS method" diagram when the request method is OPTIONS, or the "Content negotiation" diagram otherwise.
当请求方法为OPTIONS时,此图后紧接着是“ OPTIONS方法”图,否则,紧随其后。
OPTIONS method
This diagram only applies to OPTIONS requests.
此图仅适用于OPTIONS请求。
The options callback may be used to add information about the resource, such as media types or languages provided; allowed methods; any extra information. A response body may also be set, although clients should not be expected to read it.
options回调可用于添加有关资源的信息,例如提供的媒体类型或语言;允许的方法;任何其他信息。也可以设置响应主体,尽管不应期望客户阅读它。
If the options callback is not defined, Cowboy will send a response containing the list of allowed methods by default.
如果未定义options回调,则Cowboy将默认发送包含允许方法列表的响应。
Content negotiation 内容协商
This diagram applies to all request methods other than OPTIONS. It is executed right after the "Start" diagram is completed.
该图适用于OPTIONS以外的所有请求方法。在“启动”图完成后立即执行。
The purpose of these steps is to determine an appropriate representation to be sent back to the client.
这些步骤的目的是确定要发送回客户端的适当表示形式。
The request may contain any of the accept header; the accept-language header; or the accept-charset header. When present, Cowboy will parse the headers and then call the corresponding callback to obtain the list of provided content-type, language or charset for this resource. It then automatically select the best match based on the request.
该请求可以包含任何accept标头;接受语言标题;或accept-charset标头。如果存在,则Cowboy将解析标头,然后调用相应的回调以获取为此资源提供的内容类型,语言或字符集的列表。然后,它将根据请求自动选择最佳匹配。
If a callback is not defined, Cowboy will select the content-type, language or charset that the client prefers.
如果未定义回调,则Cowboy将选择客户端喜欢的内容类型,语言或字符集。
The content_types_provided also returns the name of a callback for every content-type it accepts. This callback will only be called at the end of the "GET and HEAD methods" diagram, when all conditions have been met.
content_types_provided 还针对其接受的每种内容类型返回回调的名称。当满足所有条件时,仅在“ GET和HEAD方法”图的末尾调用此回调。
The selected content-type, language and charset are saved as meta values in the Req object. You should use the appropriate representation if you set a response body manually (alongside an error code, for example).
所选的内容类型,语言和字符集将作为元值保存在Req对象中。如果手动设置响应正文(例如,错误代码),则应使用适当的表示形式。
This diagram is immediately followed by the "GET and HEAD methods" diagram, the "PUT, POST and PATCH methods" diagram, or the "DELETE method" diagram, depending on the method.
在此图之后,紧随其后的是“ GET和HEAD方法”图,“ PUT,POST和PATCH方法”图或“ DELETE方法”图,具体取决于方法。
GET and HEAD methods
This diagram only applies to GET and HEAD requests.
此图仅适用于GET和HEAD请求。
For a description of the cond step, please see the "Conditional requests" diagram.
有关条件步骤的说明,请参见“条件要求”图。
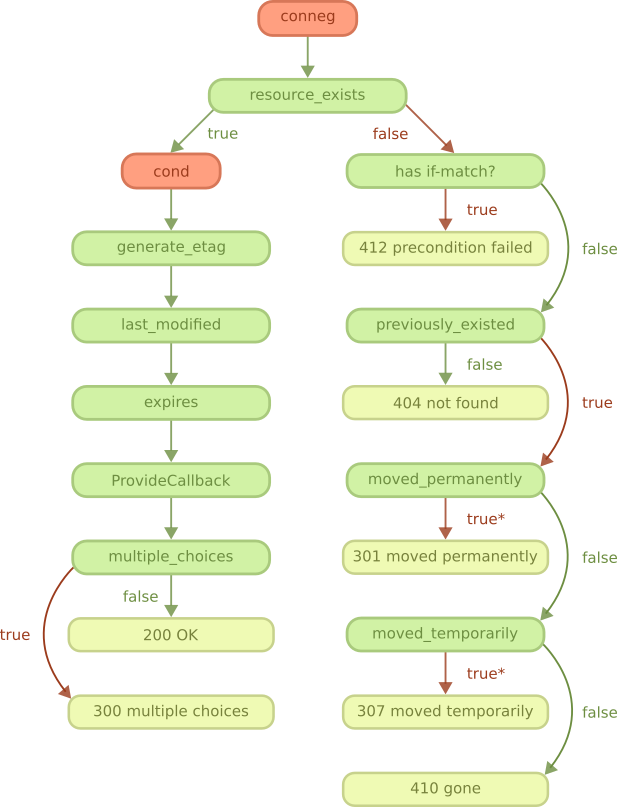
When the resource exists, and the conditional steps succeed, the resource can be retrieved.
当资源存在并且条件步骤成功时,可以检索资源。
Cowboy prepares the response by first retrieving metadata about the representation, then by calling the ProvideResource callback. This is the callback you defined for each content-types you returned from content_types_provided. This callback returns the body that will be sent back to the client, or a fun if the body must be streamed.
Cowboy通过首先获取有关表示形式的元数据,然后通过调用ProvideResource回调来准备响应。这是您为从content_types_provided返回的每种内容类型定义的回调。此回调返回将被发送回客户端的主体,如果必须对该主体进行流传输则很有趣。
When the resource does not exist, Cowboy will figure out whether the resource existed previously, and if so whether it was moved elsewhere in order to redirect the client to the new URI.
当资源不存在时,Cowboy将确定该资源先前是否存在,如果存在,则是否将其移动到其他位置以将客户端重定向到新的URI。
The moved_permanently and moved_temporarily callbacks must return the new location of the resource if it was in fact moved.
如果实际上已移动资源,则moved_permanently和moved_temporarily回调必须返回该资源的新位置。
PUT, POST and PATCH methods
This diagram only applies to PUT, POST and PATCH requests.
此图仅适用于PUT,POST和PATCH请求。
For a description of the cond step, please see the "Conditional requests" diagram.
有关条件步骤的说明,请参见“条件要求”图。
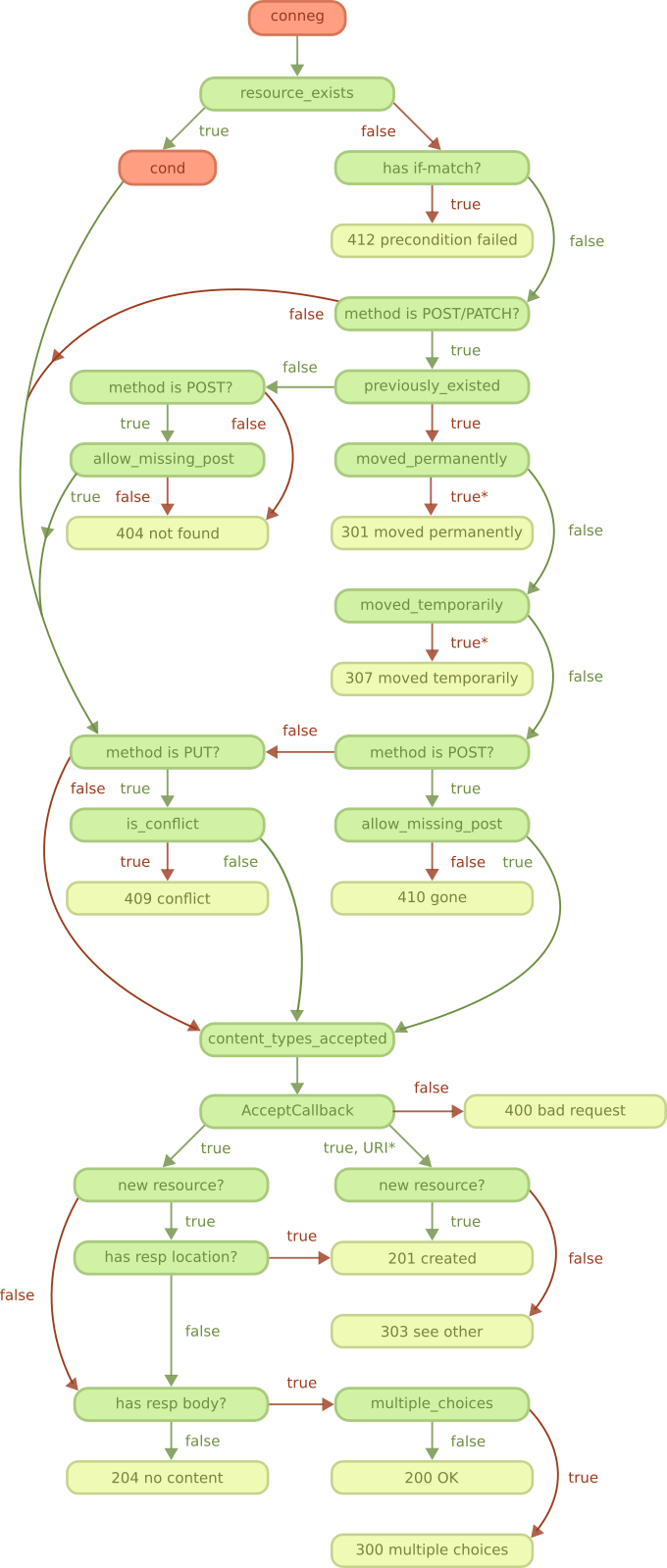
When the resource exists, first the conditional steps are executed. When that succeeds, and the method is PUT, Cowboy will call the is_conflict callback. This function can be used to prevent potential race conditions, by locking the resource for example.
资源存在时,首先执行条件步骤。成功后,方法为PUT,Cowboy将调用is_conflict回调。例如,可以通过锁定资源来防止潜在的竞争情况。
Then all three methods reach the content_types_accepted step that we will describe in a few paragraphs.
然后,这三种方法都达到了我们将在几段中描述的content_types_accepted步骤。
When the resource does not exist, and the method is PUT, Cowboy will check for conflicts and then move on to the content_types_accepted step. For other methods, Cowboy will figure out whether the resource existed previously, and if so whether it was moved elsewhere. If the resource is truly non-existent, the method is POST and the call for allow_missing_post returns true, then Cowboy will move on to the content_types_accepted step. Otherwise the request processing ends there.
当资源不存在且方法为PUT时,Cowboy将检查冲突,然后继续执行content_types_accepted步骤。对于其他方法,Cowboy将确定该资源先前是否存在,如果存在,是否将其移动到其他位置。如果资源确实不存在,则方法为POST,并且对allow_missing_post的调用返回true,则Cowboy将继续执行content_types_accepted步骤。否则,请求处理到此结束。
The moved_permanently and moved_temporarily callbacks must return the new location of the resource if it was in fact moved.
如果实际上已移动资源,则moved_permanently和moved_temporarily回调必须返回该资源的新位置。
The content_types_accepted returns a list of content-types it accepts, but also the name of a callback for each of them. Cowboy will select the appropriate callback for processing the request body and call it.
content_types_accepted返回其接受的内容类型的列表,还返回每种类型的回调的名称。 Cowboy将选择适当的回调来处理请求正文并进行调用。
This callback may return one of three different return values.
此回调可以返回三个不同的返回值之一。
If an error occurred while processing the request body, it must return false and Cowboy will send an appropriate error response.
如果在处理请求正文时发生错误,则它必须返回false,并且Cowboy将发送适当的错误响应
If the method is POST, then you may return true with an URI of where the resource has been created. This is especially useful for writing handlers for collections.
如果该方法是POST,则您可能会返回true 以及创建资源所在位置的URI。这对于编写集合处理程序特别有用。
Otherwise, return true to indicate success. Cowboy will select the appropriate response to be sent depending on whether a resource has been created, rather than modified, and on the availability of a location header or a body in the response.
否则,返回true表示成功。 Cowboy将根据是否已创建而不是修改资源以及响应中位置标头或正文的可用性来选择要发送的适当响应。
DELETE method
This diagram only applies to DELETE requests.
该图仅适用于DELETE请求。
For a description of the cond step, please see the "Conditional requests" diagram.
有关条件步骤的说明,请参见“条件要求”图。
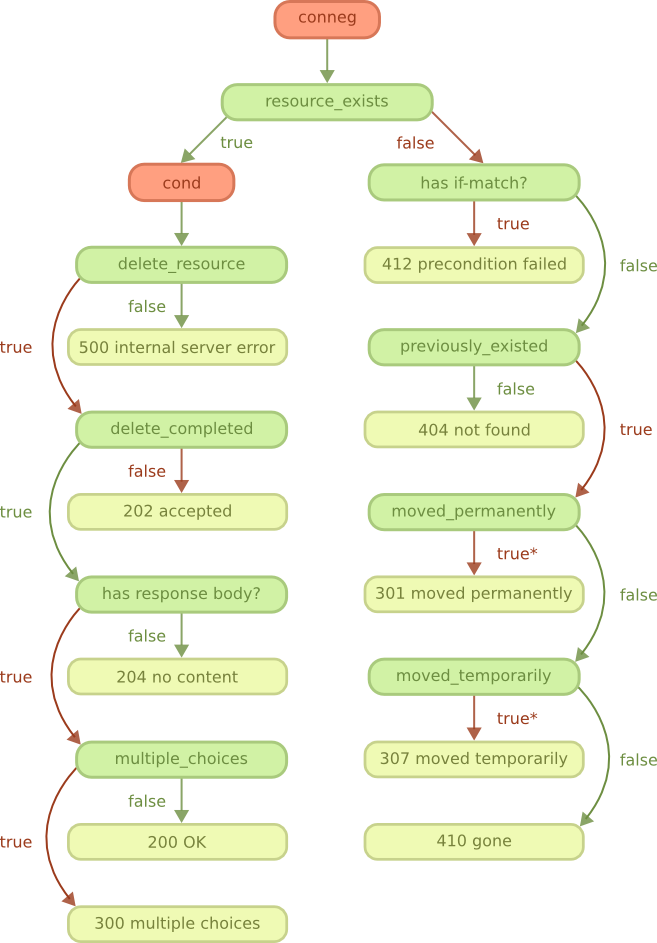
When the resource exists, and the conditional steps succeed, the resource can be deleted.
当资源存在并且条件步骤成功时,可以删除资源。
Deleting the resource is a two steps process. First the callback delete_resource is executed. Use this callback to delete the resource.
删除资源是一个两步过程。首先执行回调delete_resource。使用此回调删除资源。
Because the resource may be cached, you must also delete all cached representations of this resource in the system. This operation may take a while though, so you may return before it finished.
因为可能会缓存资源,所以您还必须在系统中删除该资源的所有缓存表示。不过,此操作可能需要一段时间,因此您可能在操作完成之前返回。
Cowboy will then call the delete_completed callback. If you know that the resource has been completely deleted from your system, including from caches, then you can return true. If any doubts persist, return false. Cowboy will assume true by default.
然后Cowboy将调用delete_completed回调。如果您知道该资源已从系统(包括从缓存)中完全删除,则可以返回true。如果仍有任何疑问,请返回false。Cowboy 将默认为true。
To finish, Cowboy checks if you set a response body, and depending on that, sends the appropriate response.
最后,Cowboy检查您是否设置了响应正文,并根据该正文发送适当的响应。
When the resource does not exist, Cowboy will figure out whether the resource existed previously, and if so whether it was moved elsewhere in order to redirect the client to the new URI.
当资源不存在时,Cowboy将确定该资源先前是否存在,如果存在,则是否将其移动到其他位置以将客户端重定向到新的URI。
The moved_permanently and moved_temporarily callbacks must return the new location of the resource if it was in fact moved.
如果实际上已移动资源,则moved_permanently和moved_temporarily回调必须返回该资源的新位置。
Conditional requests 有条件的请求
This diagram applies to all request methods other than OPTIONS. It is executed right after the resource_exists callback, when the resource exists.
该图适用于OPTIONS以外的所有请求方法。资源存在时,将在resource_exists回调之后立即执行。
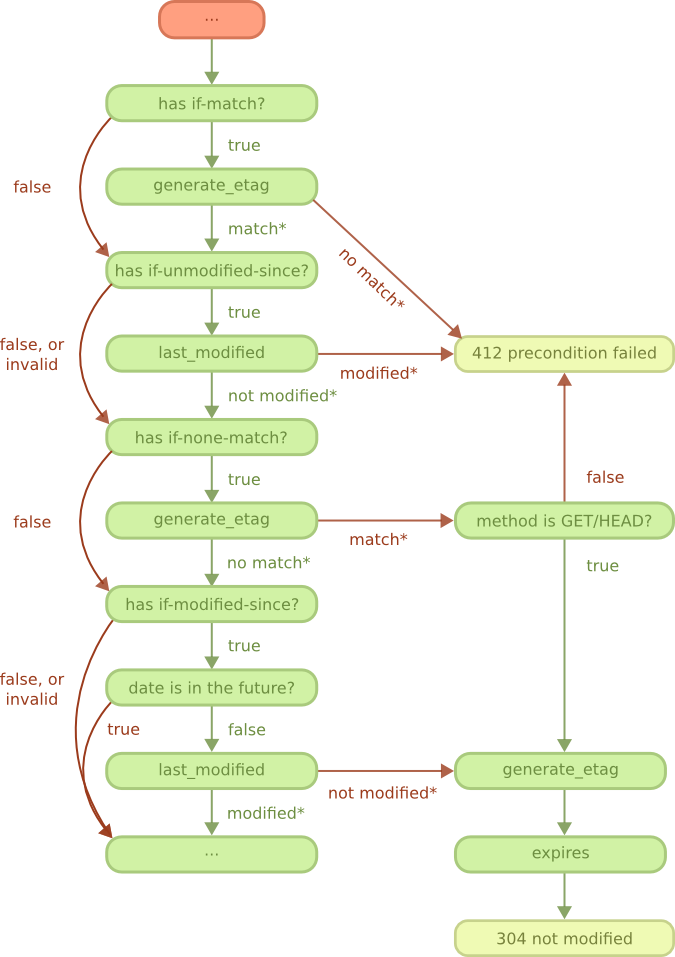
A request becomes conditional when it includes either of the if-match header; the if-unmodified-since header; the if-none-match header; or the if-modified-since header.
当请求包含if-match头中的任何一个时,它就成为条件请求。 if-unmodified-since标头; if-none-match标头;或if-modified-since标头。
If the condition fails, the request ends immediately without any retrieval or modification of the resource.
如果条件失败,则请求将立即结束,而无需任何资源的检索或修改。
The generate_etag and last_modified are called as needed. Cowboy will only call them once and then cache the results for subsequent use.
根据需要调用generate_etag和last_modified。 Cowboy只会调用一次,然后将结果缓存以备后用。
Designing a resource handler 设计资源处理程序
This chapter aims to provide you with a list of questions you must answer in order to write a good resource handler. It is meant to be usable as a step by step guide.
本章旨在为您提供必须编写的问题列表,以便编写一个好的资源处理程序。它旨在用作逐步指南。
The service 服务
Can the service become unavailable, and when it does, can we detect it? For example, database connectivity problems may be detected early. We may also have planned outages of all or parts of the system. Implement the service_available callback.
服务可以不可用吗?当它可用时,我们可以检测到它吗?例如,数据库连接问题可能会及早发现。我们可能还计划了整个系统或部分系统的中断。实现service_available回调。
What HTTP methods does the service implement? Do we need more than the standard OPTIONS, HEAD, GET, PUT, POST, PATCH and DELETE? Are we not using one of those at all? Implement the known_methods callback.
服务实现哪些HTTP方法?除了标准的OPTIONS,HEAD,GET,PUT,POST,PATCH和DELETE,我们还需要更多吗?我们根本不使用其中之一吗?实施known_methods回调。
Type of resource handler 资源处理程序的类型
Am I writing a handler for a collection of resources, or for a single resource?
我是为资源集合还是单个资源编写处理程序?
The semantics for each of these are quite different. You should not mix collection and single resource in the same handler.
这些语言的语义完全不同。您不应在同一处理程序中混合使用集合资源和单个资源。
Collection handler 收集处理程序
Skip this section if you are not doing a collection.
如果您不进行收集,请跳过本节。
Is the collection hardcoded or dynamic? For example, if you use the route /users for the collection of users then the collection is hardcoded; if you use /forums/:category for the collection of threads then it isn't. When the collection is hardcoded you can safely assume the resource always exists.
集合是硬编码还是动态的?例如,如果将路由/users用于用户集合,则该集合是硬编码的。如果您使用/forums/:category来收集线程,则不会。对集合进行硬编码后,您可以放心地假设资源始终存在。
What methods should I implement?
我应该采用什么方法?
OPTIONS is used to get some information about the collection. It is recommended to allow it even if you do not implement it, as Cowboy has a default implementation built-in.
OPTIONS用于获取有关集合的一些信息。即使没有实现,也建议允许它,因为Cowboy内置了默认实现。
HEAD and GET are used to retrieve the collection. If you allow GET, also allow HEAD as there's no extra work required to make it work.
HEAD和GET用于检索集合。如果允许GET,则还允许HEAD,因为不需要额外的工作即可使其工作。
POST is used to create a new resource inside the collection. Creating a resource by using POST on the collection is useful when resources may be created before knowing their URI, usually because parts of it are generated dynamically. A common case is some kind of auto incremented integer identifier.
POST用于在集合内部创建新资源。当可以在知道资源的URI之前创建资源时,通过在集合上使用POST创建资源很有用,通常是因为其中的一部分是动态生成的。一种常见情况是某种自动递增的整数标识符。
The next methods are more rarely allowed.
接下来的方法很少被允许。
PUT is used to create a new collection (when the collection isn't hardcoded), or replace the entire collection.
PUT用于创建新集合(当未对集合进行硬编码时),或替换整个集合。
DELETE is used to delete the entire collection.
DELETE用于删除整个集合。
PATCH is used to modify the collection using instructions given in the request body. A PATCH operation is atomic. The PATCH operation may be used for such things as reordering; adding, modifying or deleting parts of the collection.
PATCH用于使用请求正文中给出的指令来修改集合。 PATCH操作是原子的。 PATCH操作可用于诸如重新排序之类的事情;添加,修改或删除集合的一部分。
Single resource handler 单一资源处理程序
Skip this section if you are doing a collection.
如果要进行收集,请跳过本节。
What methods should I implement?
我应该采用什么方法?
OPTIONS is used to get some information about the resource. It is recommended to allow it even if you do not implement it, as Cowboy has a default implementation built-in.
OPTIONS用于获取有关资源的一些信息。即使没有实现,也建议允许它,因为Cowboy内置了默认实现。
HEAD and GET are used to retrieve the resource. If you allow GET, also allow HEAD as there's no extra work required to make it work.
HEAD和GET用于检索资源。如果允许GET,则还允许HEAD,因为不需要额外的工作即可使其工作。
POST is used to update the resource.
POST用于更新资源。
PUT is used to create a new resource (when it doesn't already exist) or replace the resource.
PUT用于创建新资源(如果尚不存在)或替换该资源。
DELETE is used to delete the resource.
DELETE用于删除资源。
PATCH is used to modify the resource using instructions given in the request body. A PATCH operation is atomic. The PATCH operation may be used for adding, removing or modifying specific values in the resource.
PATCH用于使用请求正文中给出的指令来修改资源。 PATCH操作是原子的。 PATCH操作可用于添加,删除或修改资源中的特定值。
The resource 资源
Following the above discussion, implement the allowed_methods callback.
经过以上讨论,实现了allowed_methods回调。
Does the resource always exist? If it may not, implement the resource_exists callback.
资源是否一直存在?如果不能,请实现resource_exists回调。
Do I need to authenticate the client before they can access the resource? What authentication mechanisms should I provide? This may include form-based, token-based (in the URL or a cookie), HTTP basic, HTTP digest, SSL certificate or any other form of authentication. Implement the is_authorized callback.
在客户端可以访问资源之前,我需要对其进行身份验证吗?我应该提供什么认证机制?这可能包括基于表单,基于令牌(在URL或cookie中),HTTP基本,HTTP摘要,SSL证书或任何其他形式的身份验证。实现is_authorized回调。
Do I need fine-grained access control? How do I determine that they are authorized access? Handle that in your is_authorized callback.
我是否需要细粒度的访问控制?我如何确定它们已被授权访问?在您的is_authorized回调中处理该问题。
Can access to a resource be forbidden regardless of access being authorized? A simple example of that is censorship of a resource. Implement the forbidden callback.
是否可以禁止访问资源,而不管访问是否被授权?一个简单的例子就是对资源的审查。实现禁止的回调。
Can access be rate-limited for authenticated users? Use the rate_limited callback.
通过身份验证的用户可以限制访问速度吗?使用rate_limited回调。
Are there any constraints on the length of the resource URI? For example, the URI may be used as a key in storage and may have a limit in length. Implement uri_too_long.
资源URI的长度是否有限制?例如,URI可以用作存储中的密钥,并且可以具有长度限制。实现uri_too_long。
Representations 表示
What media types do I provide? If text based, what charsets are provided? What languages do I provide?
我提供哪些媒体类型?如果基于文本,提供哪些字符集?我提供什么语言?
Implement the mandatory content_types_provided. Prefix the callbacks with to_ for clarity. For example, to_html or to_text. For resources that don't implement methods GET or HEAD, you must still accept at least one media type, but you can leave the callback as undefined since it will never be called.
实现强制性的ontent_types_provided。为了清晰起见,在回调中使用to_前缀。例如,to_htmll或tto_text。对于没有实现GET或HEAD方法的资源,您仍然必须至少接受一种媒体类型,但是您可以将回调保留为undefined,因为它将永远不会被调用。
Implement the languages_provided or charsets_provided callbacks if applicable.
如果适用,请实现languages_provided或charsets_provided回调。
Is there any other header that may make the representation of the resource vary? Implement the variances callback.
是否有其他标头可能会使资源的表示形式有所不同?实现方差回调。
Depending on your choices for caching content, you may want to implement one or more of the generate_etag, last_modified and expires callbacks.
根据您对缓存内容的选择,您可能需要实现generate_etag,last_modified和expires回调中的一个或多个。
Do I want the user or user agent to actively choose a representation available? Send a list of available representations in the response body and implement the multiple_choicescallback.
我是否希望用户或用户代理主动选择可用的表示形式?在响应正文中发送可用表示形式的列表,并实现multiple_choices回调。
Redirections 重定向
Do I need to keep track of what resources were deleted? For example, you may have a mechanism where moving a resource leaves a redirect link to its new location. Implement the previously_existed callback.
我是否需要跟踪删除了哪些资源?例如,您可能具有一种机制,在该机制下,移动资源将重定向链接保留到其新位置。实现以前存在的回调。
Was the resource moved, and is the move temporary? If it is explicitly temporary, for example due to maintenance, implement the moved_temporarily callback. Otherwise, implement the moved_permanently callback.
资源是否已转移,并且该转移是临时的?如果它是临时的(例如由于维护),请实施moved_temporarily回调。否则,请实现moved_permanently回调。
The request 请求
Do you need to read the query string? Individual headers? Implement malformed_requestand do all the parsing and validation in this function. Note that the body should not be read at this point.
您需要阅读查询字符串吗?个人标题?实现malformed_request并在此函数中进行所有解析和验证。请注意,此时不应阅读正文。
May there be a request body? Will I know its size? What's the maximum size of the request body I'm willing to accept? Implement valid_entity_length.
可以有一个请求机构吗?我能知道它的大小吗?我愿意接受的请求正文的最大大小是多少?实现valid_entity_length。
Finally, take a look at the sections corresponding to the methods you are implementing.
最后,看看与您要实现的方法相对应的部分。
OPTIONS method 选项方法
Cowboy by default will send back a list of allowed methods. Do I need to add more information to the response? Implement the options method.
默认情况下,Cowboy将发回允许的方法列表。我需要在响应中添加更多信息吗?实现选项方法。
GET and HEAD methods
If you implement the methods GET and/or HEAD, you must implement one ProvideResource callback for each content-type returned by the content_types_providedcallback.
如果您实现GET和/或HEAD方法,则必须为content_types_provided回调返回的每种内容类型实现一个ProvideResource回调。
PUT, POST and PATCH methods
If you implement the methods PUT, POST and/or PATCH, you must implement the content_types_accepted callback, and one AcceptCallback callback for each content-type it returns. Prefix the AcceptCallback callback names with from_ for clarity. For example, from_html or from_json.
如果实现方法PUT,POST和/或PATCH,则必须实现content_types_accepted回调,并为其返回的每种内容类型实现一个AcceptCallback回调。为了清晰起见,在AcceptCallback回调名称前使用from_前缀。例如,from_html或from_json。
Do we want to allow the POST method to create individual resources directly through their URI (like PUT)? Implement the allow_missing_post callback. It is recommended to explicitly use PUT in these cases instead.
我们是否要允许POST方法直接通过其URI(例如PUT)创建单个资源?实现allow_missing_post回调。建议在这些情况下显式使用PUT。
May there be conflicts when using PUT to create or replace a resource? Do we want to make sure that two updates around the same time are not cancelling one another? Implement the is_conflict callback.
使用PUT创建或替换资源时可能会有冲突吗?我们是否要确保大约同时进行的两次更新不会互相取消?实现is_conflict回调。
DELETE methods
If you implement the method DELETE, you must implement the delete_resource callback.
如果实现方法DELETE,则必须实现delete_resource回调。
When delete_resource returns, is the resource completely removed from the server, including from any caching service? If not, and/or if the deletion is asynchronous and we have no way of knowing it has been completed yet, implement the delete_completedcallback.
当delete_resource返回时,资源是否已从服务器(包括所有缓存服务)中完全删除?如果不是,并且/或者如果删除是异步的,并且我们还无法得知删除已完成,请实现delete_completed回调。
The Websocket protocol Websocket协议
This chapter explains what Websocket is and why it is a vital component of soft realtime Web applications.
本章说明什么是Websocket以及为什么Websocket是软实时Web应用程序的重要组成部分。
Description 描述
Websocket is an extension to HTTP that emulates plain TCP connections between the client, typically a Web browser, and the server. It uses the HTTP Upgrade mechanism to establish the connection.
Websocket是HTTP的扩展,它模拟了客户端(通常是Web浏览器)与服务器之间的纯TCP连接。它使用HTTP升级机制来建立连接。
Websocket connections are fully asynchronous, unlike HTTP/1.1 (synchronous) and HTTP/2 (asynchronous, but the server can only initiate streams in response to requests). With Websocket, the client and the server can both send frames at any time without any restriction. It is closer to TCP than any of the HTTP protocols.
与HTTP / 1.1(同步)和HTTP / 2(异步)不同,Websocket连接是完全异步的,但是服务器只能响应请求而启动流。借助Websocket,客户端和服务器都可以随时发送帧,而没有任何限制。它比任何HTTP协议都更接近TCP。
Websocket is an IETF standard. Cowboy supports the standard and all drafts that were previously implemented by browsers, excluding the initial flawed draft sometimes known as "version 0".
Websocket是IETF标准。 Cowboy支持该标准以及以前由浏览器实现的所有草稿,但不包括有时被称为“版本0”的原始缺陷草稿。
Websocket vs HTTP/2
For a few years Websocket was the only way to have a bidirectional asynchronous connection with the server. This changed when HTTP/2 was introduced. While HTTP/2 requires the client to first perform a request before the server can push data, this is only a minor restriction as the client can do so just as it connects.
几年来,Websocket是与服务器建立双向异步连接的唯一方法。引入HTTP / 2时,这种情况发生了变化。尽管HTTP / 2要求客户端在服务器可以推送数据之前先执行请求,但这只是一个小限制,因为客户端可以在连接时这样做。
Websocket was designed as a kind-of-TCP channel to a server. It only defines the framing and connection management and lets the developer implement a protocol on top of it. For example you could implement IRC over Websocket and use a Javascript IRC client to speak to the server.
Websocket被设计为服务器的一种TCP通道。它仅定义了框架和连接管理,并允许开发人员在其之上实施协议。例如,您可以在Websocket上实现IRC并使用Java IRC客户端与服务器对话。
HTTP/2 on the other hand is just an improvement over the HTTP/1.1 connection and request/response mechanism. It has the same semantics as HTTP/1.1.
另一方面,HTTP / 2只是对HTTP / 1.1连接和请求/响应机制的改进。它具有与HTTP / 1.1相同的语义。
If all you need is to access an HTTP API, then HTTP/2 should be your first choice. On the other hand, if what you need is a different protocol, then you can use Websocket to implement it.
如果您只需要访问HTTP API,那么HTTP / 2应该是您的首选。另一方面,如果您需要的是其他协议,则可以使用Websocket来实现它。
Implementation 实现
Cowboy implements Websocket as a protocol upgrade. Once the upgrade is performed from the init/2 callback, Cowboy switches to Websocket. Please consult the next chapter for more information on initiating and handling Websocket connections.
Cowboy将Websocket实施为协议升级。从init/2回调执行升级后,Cowboy将切换到Websocket。请参阅下一章以获取有关启动和处理Websocket连接的更多信息。
The implementation of Websocket in Cowboy is validated using the Autobahn test suite, which is an extensive suite of tests covering all aspects of the protocol. Cowboy passes the suite with 100% success, including all optional tests.
使用Autobahn测试套件验证了Cowboy中Websocket的实现,该套件是涵盖协议各个方面的广泛测试套件。 Cowboy通过套件成功100%,包括所有可选测试。
Cowboy's Websocket implementation also includes the permessage-deflate and x-webkit-deflate-frame compression extensions.
Cowboy的Websocket实现还包括permessage-deflate和x-webkit-deflate-frame压缩扩展。
Cowboy will automatically use compression when the compress option is returned from the init/2 function.
当init/2函数返回compress选项时,Cowboy将自动使用压缩。
Websocket handlers Websocket处理程序
Websocket handlers provide an interface for upgrading HTTP/1.1 connections to Websocket and sending or receiving frames on the Websocket connection.
Websocket处理程序提供了一个接口,用于将HTTP / 1.1连接升级到Websocket并在Websocket连接上发送或接收帧。
As Websocket connections are established through the HTTP/1.1 upgrade mechanism, Websocket handlers need to be able to first receive the HTTP request for the upgrade, before switching to Websocket and taking over the connection. They can then receive or send Websocket frames, handle incoming Erlang messages or close the connection.
由于Websocket连接是通过HTTP / 1.1升级机制建立的,因此Websocket处理程序需要能够在切换到Websocket并接管连接之前首先接收HTTP升级请求。然后,他们可以接收或发送Websocket框架,处理传入的Erlang消息或关闭连接。
Upgrade 升级
The init/2 callback is called when the request is received. To establish a Websocket connection, you must switch to the cowboy_websocket module:
收到请求时,将调用init/2回调。要建立Websocket连接,必须切换到cowboy_websocket模块:
init(Req, State) ->{cowboy_websocket, Req, State}.
Cowboy will perform the Websocket handshake immediately. Note that the handshake will fail if the client did not request an upgrade to Websocket.
Cowboy将立即执行Websocket握手。请注意,如果客户端未请求升级到Websocket,则握手将失败。
The Req object becomes unavailable after this function returns. Any information required for proper execution of the Websocket handler must be saved in the state.
此函数返回后,Req对象将不可用。正确执行Websocket处理程序所需的任何信息都必须保存在状态中。
Subprotocol 子协议
The client may provide a list of Websocket subprotocols it supports in the sec-websocket-protocol header. The server must select one of them and send it back to the client or the handshake will fail.
客户端可以在sec-websocket-protocol标头中提供其支持的Websocket子协议列表。服务器必须选择其中之一并将其发送回客户端,否则握手将失败。
For example, a client could understand both STOMP and MQTT over Websocket, and provide the header:
例如,客户端可以通过Websocket理解STOMP和MQTT,并提供标头:
sec-websocket-protocol: v12.stomp, mqtt
If the server only understands MQTT it can return:
如果服务器仅了解MQTT,则可以返回:
sec-websocket-protocol: mqtt
This selection must be done in init/2. An example usage could be:
此选择必须在init/2中完成。用法示例可能是:
init(Req0, State) ->case cowboy_req:parse_header(<<"sec-websocket-protocol">>, Req0) ofundefined ->{cowboy_websocket, Req0, State};Subprotocols ->case lists:keymember(<<"mqtt">>, 1, Subprotocols) oftrue ->Req = cowboy_req:set_resp_header(<<"sec-websocket-protocol">>,<<"mqtt">>, Req0),{cowboy_websocket, Req, State};false ->Req = cowboy_req:reply(400, Req0),{ok, Req, State}endend.
Post-upgrade initialization 升级后初始化
Cowboy has separate processes for handling the connection and requests. Because Websocket takes over the connection, the Websocket protocol handling occurs in a different process than the request handling.
Cowboy具有用于处理连接和请求的单独流程。因为Websocket接管了连接,所以Websocket协议处理的过程与请求处理的过程不同。
This is reflected in the different callbacks Websocket handlers have. The init/2 callback is called from the temporary request process and the websocket_ callbacks from the connection process.
这反映在Websocket处理程序具有的不同回调中。从临时请求过程中调用init/2回调,从连接过程中调用websocket_回调。
This means that some initialization cannot be done from init/2. Anything that would require the current pid, or be tied to the current pid, will not work as intended. The optional websocket_init/1 can be used instead:
这意味着无法从init/2进行某些初始化。任何需要当前pid或绑定到当前pid的东西都将无法按预期工作。可以使用可选的websocket_init/1:
websocket_init(State) ->erlang:start_timer(1000, self(), <<"Hello!">>),{ok, State}.
All Websocket callbacks share the same return values. This means that we can send frames to the client right after the upgrade:
所有Websocket回调共享相同的返回值。这意味着我们可以在升级后立即将帧发送到客户端:
websocket_init(State) ->{reply, {text, <<"Hello!">>}, State}.
Receiving frames 接收框
Cowboy will call websocket_handle/2 whenever a text, binary, ping or pong frame arrives from the client.
每当客户端收到文本,二进制,ping或pong帧时,Cowboy都会调用websocket_handle/2。
The handler can handle or ignore the frames. It can also send frames back to the client or stop the connection.
处理程序可以处理或忽略帧。它还可以将帧发送回客户端或停止连接。
The following snippet echoes back any text frame received and ignores all others:
以下代码段回显收到的所有文本框,并忽略所有其他文本框:
websocket_handle(Frame = {text, _}, State) ->{reply, Frame, State};
websocket_handle(_Frame, State) ->{ok, State}.
Note that ping and pong frames require no action from the handler as Cowboy will automatically reply to ping frames. They are provided for informative purposes only.
请注意,ping和pong帧不需要处理程序采取任何操作,因为Cowboy会自动回复ping帧。它们仅供参考
Receiving Erlang messages 接收Erlang消息
Cowboy will call websocket_info/2 whenever an Erlang message arrives.
每当有Erlang消息到达时,Cowboy都会调用websocket_info/2。
The handler can handle or ignore the messages. It can also send frames to the client or stop the connection.
处理程序可以处理或忽略消息。它还可以将帧发送到客户端或停止连接。
The following snippet forwards log messages to the client and ignores all others:
以下代码段将日志消息转发到客户端,并忽略所有其他消息:
websocket_info({log, Text}, State) ->{reply, {text, Text}, State};
websocket_info(_Info, State) ->{ok, State}.
Sending frames 发送帧
All websocket_ callbacks share return values. They may send zero, one or many frames to the client.
所有websocket_回调共享返回值。它们可以向客户端发送零,一或多个帧。
To send nothing, just return an ok tuple:
要不发送任何内容,只需返回一个确定的元组:
websocket_info(_Info, State) ->{ok, State}.
To send one frame, return a reply tuple with the frame to send:
要发送一帧,请返回带有该帧的回复元组:
websocket_info(_Info, State) ->{reply, {text, <<"Hello!">>}, State}.
You can send frames of any type: text, binary, ping, pong or close frames.
您可以发送任何类型的帧:文本,二进制,ping,pong或封闭帧。
To send many frames at once, return a reply tuple with the list of frames to send:
要一次发送许多帧,请返回一个包含要发送帧列表的回复元组:
websocket_info(_Info, State) ->{reply, [{text, "Hello"},{text, <<"world!">>},{binary, <<0:8000>>}], State}.
They are sent in the given order.
它们以给定的顺序发送。
Keeping the connection alive 保持连接畅通
Cowboy will automatically respond to ping frames sent by the client. They are still forwarded to the handler for informative purposes, but no further action is required.
Cowboy将自动响应客户端发送的ping帧。它们仍然出于信息目的而转发给处理程序,但是不需要采取进一步的措施。
Cowboy does not send ping frames itself. The handler can do it if required. A better solution in most cases is to let the client handle pings. Doing it from the handler would imply having an additional timer per connection and this can be a considerable cost for servers that need to handle large numbers of connections.
牛仔本身不会发送ping帧。如果需要,处理程序可以执行此操作。在大多数情况下,更好的解决方案是让客户端处理ping。从处理程序执行此操作将意味着每个连接都有一个额外的计时器,对于需要处理大量连接的服务器而言,这可能是一笔可观的成本。
Cowboy can be configured to close idle connections automatically. It is highly recommended to configure a timeout here, to avoid having processes linger longer than needed.
可以将Cowboy配置为自动关闭空闲连接。强烈建议在此处配置超时,以免进程停留的时间超过所需的时间。
The init/2 callback can set the timeout to be used for the connection. For example, this would make Cowboy close connections idle for more than 30 seconds:
init/22回调可以设置要用于连接的超时。例如,这将使Cowboy关闭连接空闲30秒以上:
init(Req, State) ->{cowboy_websocket, Req, State, #{idle_timeout => 30000}}.
This value cannot be changed once it is set. It defaults to 60000.
设置该值后将无法更改。默认值为60000。
Limiting frame sizes 限制帧的大小
Cowboy accepts frames of any size by default. You should limit the size depending on what your handler may handle. You can do this via the init/2 callback:
Cowboy 默认接受任何大小的帧。您应该根据处理程序可能处理的大小来限制大小。您可以通过init/2回调来实现:
init(Req, State) ->{cowboy_websocket, Req, State, #{max_frame_size => 8000000}}.
The lack of limit is historical. A future version of Cowboy will have a more reasonable default.
缺乏限制是历史的。 Cowboy的未来版本将具有更合理的默认设置。
Saving memory 节省内存
The Websocket connection process can be set to hibernate after the callback returns.
回调返回后,可以将Websocket连接过程设置为休眠状态。
Simply add an hibernate field to the ok or reply tuples:
只需向OK添加一个休眠字段或回复元组即可
websocket_init(State) ->{ok, State, hibernate}.websocket_handle(_Frame, State) ->{ok, State, hibernate}.websocket_info(_Info, State) ->{reply, {text, <<"Hello!">>}, State, hibernate}.
It is highly recommended to write your handlers with hibernate enabled, as this allows to greatly reduce the memory usage. Do note however that an increase in the CPU usage or latency can be observed instead, in particular for the more busy connections.
强烈建议编写启用了休眠的处理程序,因为这样可以大大减少内存使用量。但是请注意,相反,可以观察到CPU使用率或等待时间的增加,尤其是对于较忙的连接。
Closing the connection 断开连接
The connection can be closed at any time, either by telling Cowboy to stop it or by sending a close frame.
可以通过告诉Cowboy停止连接或发送关闭帧来随时关闭连接。
To tell Cowboy to close the connection, use a stop tuple:
要告诉Cowboy关闭连接,请使用停止元组:
websocket_info(_Info, State) ->{stop, State}.
Sending a close frame will immediately initiate the closing of the Websocket connection. Note that when sending a list of frames that include a close frame, any frame found after the close frame will not be sent.
发送关闭帧将立即启动Websocket连接的关闭。请注意,当发送包含关闭帧的帧列表时,在关闭帧之后找到的任何帧都不会发送
The following example sends a close frame with a reason message:
以下示例发送带有原因消息的关闭帧:
websocket_info(_Info, State) ->{reply, {close, 1000, <<"some-reason">>}, State}.
Streams 流
A stream is the set of messages that form an HTTP request/response pair.
流是形成HTTP请求/响应对的一组消息。
The term stream comes from HTTP/2. In Cowboy, it is also used when talking about HTTP/1.1 or HTTP/1.0. It should not be confused with streaming the request or response body.
术语流来自HTTP / 2。在Cowboy中,在谈论HTTP / 1.1或HTTP / 1.0时也使用它。不应将其与流式传输请求或响应正文相混淆
All versions of HTTP allow clients to initiate streams. HTTP/2 is the only one also allowing servers, through its server push feature. Both client and server-initiated streams go through the same process in Cowboy.
所有版本的HTTP都允许客户端启动流。 HTTP / 2是唯一通过服务器推送功能还允许服务器的服务器。客户端和服务器启动的流在Cowboy中都经过相同的过程。
Stream handlers 流处理程序
Stream handlers must implement five different callbacks. Four of them are directly related; one is special.
流处理程序必须实现五个不同的回调。其中有四个直接相关。一个很特别。
All callbacks receives the stream ID as first argument.
所有回调都将流ID接收为第一个参数。
Most of them can return a list of commands to be executed by Cowboy. When callbacks are chained, it is possible to intercept and modify these commands. This can be useful for modifying responses for example.
他们中的大多数人都可以返回由Cowboy执行的命令列表。当回调链接在一起时,可以截取和修改这些命令。例如,这对于修改响应很有用。
The init/3 callback is invoked when a new request comes in. It receives the Req object and the protocol options for this listener.
收到新请求时,将调用init/3回调。它接收此监听器的Req对象和协议选项。
The data/4 callback is invoked when data from the request body is received. It receives both this data and a flag indicating whether more is to be expected.
当接收到来自请求主体的数据时,将调用data/4回调。它既接收到该数据,又接收到指示是否期望更多数据的标志。
The info/3 callback is invoked when an Erlang message is received for this stream. They will typically be messages sent by the request process.
当收到此流的Erlang消息时,将调用info/3回调。它们通常是请求过程发送的消息。
Finally the terminate/3 callback is invoked with the terminate reason for the stream. The return value is ignored. Note that as with all terminate callbacks in Erlang, there is no strong guarantee that it will be called.
最后,使用流的终止原因调用terminate/3回调。返回值将被忽略。请注意,与Erlang中的所有终止回调一样,不能完全保证将被调用。
The special callback early_error/5 is called when an error occurs before the request headers were fully received and Cowboy is sending a response. It receives the partial Req object, the error reason, the protocol options and the response Cowboy will send. This response must be returned, possibly modified.
在完全接收到请求标头且Cowboy正在发送响应之前发生错误时,将调用特殊回调early_error/5。它接收部分Req对象,错误原因,协议选项以及Cowboy将发送的响应。必须返回此响应,并可能对其进行修改。
Built-in handlers 内置处理程序
Cowboy comes with two handlers.
牛仔有两个处理程序。
cowboy_stream_h is the default stream handler. It is the core of much of the functionality of Cowboy. All chains of stream handlers should call it last.
cowboy_stream_h是默认的流处理程序。它是Cowboy大部分功能的核心。所有流处理程序链都应最后调用它。
cowboy_compress_h will automatically compress responses when possible. It is not enabled by default. It is a good example for writing your own handlers that will modify responses.
cowboy_compress_h将在可能的情况下自动压缩响应。默认情况下未启用。这是编写自己的将修改响应的处理程序的好例子。
Middlewares 中间件
Cowboy delegates the request processing to middleware components. By default, two middlewares are defined, for the routing and handling of the request, as is detailed in most of this guide.
Cowboy将请求处理委托给中间件组件。默认情况下,为该请求的路由和处理定义了两个中间件,如本指南的大部分内容所述。
Middlewares give you complete control over how requests are to be processed. You can add your own middlewares to the mix or completely change the chain of middlewares as needed.
中间件使您可以完全控制请求的处理方式。您可以添加自己的中间件,也可以根据需要完全更改中间件链。
Cowboy will execute all middlewares in the given order, unless one of them decides to stop processing.
Cowboy将按照给定的顺序执行所有中间件,除非其中之一决定停止处理。
Usage 用法
Middlewares only need to implement a single callback: execute/2. It is defined in the cowboy_middleware behavior.
中间件只需要实现一个回调:execute/2。它在cowboy_middleware行为中定义。
This callback has two arguments. The first is the Req object. The second is the environment.
该回调有两个参数。第一个是Req对象。第二是环境。
Middlewares can return one of three different values:
{ok, Req, Env}to continue the request processing{suspend, Module, Function, Args}to hibernate{stop, Req}to stop processing and move on to the next request
中间件可以返回三个不同值之一:
{ok, Req, Env}继续请求处理{suspend, Module, Function, Args}休眠{stop, Req}停止处理并继续下一个请求
Of note is that when hibernating, processing will resume on the given MFA, discarding all previous stacktrace. Make sure you keep the Req and Env in the arguments of this MFA for later use.
值得注意的是,在休眠状态下,处理将在给定的MFA上恢复,并丢弃所有先前的堆栈跟踪。确保在此MFA的参数中保留Req和Env供以后使用
If an error happens during middleware processing, Cowboy will not try to send an error back to the socket, the process will just crash. It is up to the middleware to make sure that a reply is sent if something goes wrong.
如果在中间件处理期间发生错误,Cowboy将不会尝试将错误发送回套接字,该过程只会崩溃。如果发生问题,由中间件决定是否发送回复。
Configuration 构造
The middleware environment is defined as the env protocol option. In the previous chapters we saw it briefly when we needed to pass the routing information. It is a list of tuples with the first element being an atom and the second any Erlang term.
中间件环境定义为env协议选项。在前面的章节中,我们在需要传递路由信息时简要地介绍了它。它是一个元组列表,第一个元素是原子,第二个元素是Erlang项。
Two values in the environment are reserved:
listenercontains the name of the listenerresultcontains the result of the processing
环境中保留了两个值:
listener包含侦听器的名称result包含处理结果
The listener value is always defined. The result value can be set by any middleware. If set to anything other than ok, Cowboy will not process any subsequent requests on this connection.
侦听器值始终是定义的。结果值可以由任何中间件设置。如果设置为ok以外的任何其他选项,Cowboy将不会处理此连接上的任何后续请求。
The middlewares that come with Cowboy may define or require other environment values to perform.
Cowboy随附的中间件可能会定义或要求其他环境值来执行。
You can update the environment by calling the cowboy:set_env/3 convenience function, adding or replacing a value in the environment.
您可以通过调用cowboy:set_env/3便捷功能,在环境中添加或替换值来更新环境
Routing middleware 路由中间件
The routing middleware requires the dispatch value. If routing succeeds, it will put the handler name and options in the handler and handler_opts values of the environment, respectively.
路由中间件需要调度值。如果路由成功,它将把处理程序名称和选项分别放在环境的handler和handler_opts值中。
Handler middleware 处理程序中间件
The handler middleware requires the handler and handler_opts values. It puts the result of the request handling into result.
处理程序中间件需要handler和handler_opts值。它将请求处理的结果放入结果。
本文翻译自:https://ninenines.eu/docs/en/cowboy/2.6/guide/
Cowboy 2.6 User Guide 中英文对照版【翻译】相关推荐
- VS Code:史上最全的VS Code快捷键+分门别类(中英文对照版)
VS Code:史上最全的VS Code快捷键+分门别类(中英文对照版) 目录 基础编辑 Basic editing 导航 Navigation 搜索和替换 Search and replace 多光 ...
- 深度学习论文阅读目标检测篇(四)中英文对照版:YOLOv1《 You Only Look Once: Unified, Real-Time Object Detection》
深度学习论文阅读目标检测篇(四)中英文对照版:YOLOv1< You Only Look Once: Unified, Real-Time Object Detection> Abstra ...
- AlexNet论文翻译(中英文对照版)-ImageNet Classification with Deep Convolutional Neural Networks
图像分类经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为中英文对照版,纯中文版请稳步:[AlexNet纯中文版] ImageNet Classification with De ...
- 图像分类经典卷积神经网络—ResNet论文翻译(中英文对照版)—Deep Residual Learning for Image Recognition(深度残差学习的图像识别)
图像分类经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为中英文对照版,纯中文版请稳步:[ResNet纯中文版] Deep Residual Learning for Image ...
- 宇宙最强,meltdown论文中英文对照版(三)
本文由郭健郭大侠翻译,将分为三次连载完成,这是第三部分.郭大侠是蜗窝科技(http://www.wowotech.net/)的创始人,倡导"慢下来,享受技术"的健康理念,侠之大者, ...
- 布斯(Steve Jobs)在斯坦福大学的演讲稿,中英文对照版
2005年6月14日,苹果CEO史蒂夫·乔布斯(Steve Jobs)在他的母校斯坦福大学的毕业典礼发表了著名的演讲,关于这段演讲,你会看到N多人的推荐(比如同样喜欢在大学演讲的李开复先生).此前曾经 ...
- RFC2326 - Real Time Streaming Protocol (RTSP) 完整中英文对照版
RFC2326 - Real Time Streaming Protocol (RTSP) 完整中英文对照版 E-mail:bryanj@163.com 译者: Bryan.Wong(王晶,宁夏固原) ...
- 目标检测经典论文——Fast R-CNN论文翻译(中英文对照版):Fast R-CNN(Ross Girshick, Microsoft Research(微软研究院))
目标检测经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为纯中文版,中英文对照版请稳步:[Fast R-CNN纯中文版] Fast R-CNN Ross Girshick Mic ...
- 图像分类经典卷积神经网络—GoogLeNet论文翻译(中英文对照版)—Going Deeper with Convolutions(走向更深的卷积神经网络)
图像分类经典论文翻译汇总:[翻译汇总] 翻译pdf文件下载:[下载地址] 此版为中英文对照版,纯中文版请稳步:[GoogLeNet纯中文版] Going Deeper with Convolution ...
最新文章
- gz键盘增强小工具_这些不起眼的Mac小工具,能让你的Macbook效率倍增!
- php 如何缓存数据字典,使用PHP脚本如何导出MySQL数据字典
- 通过C#发送自定义的html格式邮件
- javafx中的tree_JavaFX中的塔防(5)
- [渝粤教育] 武汉大学 数字图像处理 参考 资料
- 如何在Pandas中使用Excel文件
- 判断是否为ajax请求
- JUnit-4.11使用报java.lang.NoClassDefFoundError: org/hamcrest/SelfDescribing错误
- sql server 部署_将程序包部署到SQL Server集成服务目录(SSISDB)
- 简明 MongoDB 入门教程 1
- Python基础语法-03-私有化
- 理解 __doPostBack--1
- 【web前端开发】vs code插件推荐
- arm实验使用keil自带的MDK仿真教程
- Android移动应用开发入门
- 为什么说软件测试很重要?
- 一个老程序员的忠告:千万不要一辈子靠技术生存
- java实现接口必须实现所有方法吗_我们是否必须在实现Java接口的类中实现所有方法?...
- centos linux 查看ip,centos如何查看ip
- 光能手写板 android,一种液晶光能手写板的制作方法