RabbitMQ吐血总结(2)---高级特性总结
为什么80%的码农都做不了架构师?>>> 
经历上一篇的基础API总结,其实RabbitMQ的基础使用,就不成问题了。但是要想稍微拔高,还是要经历这一篇的洗礼。一直以来,我面试别人的时候,大多数面试者的简历中,都会写上熟练使用RabbitMQ,然而,我问出一个只要是消息中间件就老生常谈的话题的时候,几乎清一色的,都没有很好的说出来。这个问题就是:请介绍下,RabbitMQ如何保证消息的可靠性的。通过这一篇文章的总结,我想让自己达到对这个问题的细节覆盖全面的程度,至少一个架构师过来问我,我能有条理有逻辑的说明白,不会东一句西一句。作为RabbitMQ,这种我们日常生产中使用频率相当高的消息中间件,我认为,对他的掌控,要更好,才能说明我们对技术的追求,而不只是CURD。
一、mandatory与immediate参数
这两个参数,是保证消息可靠性的第一扇门,我们先来看看上篇文章中,消息发送的api源码:
/*** 发布一个消息到服务端。** @param mandatory 后面文章介绍* @param immediate 后面文章介绍*/
void basicPublish(String exchange,String routingKey,boolean mandatory,boolean immediate,BasicProperties props,byte[] body) throws IOException;
这两个参数,上一篇里面注释的,这一章我们来解开
1、mandatory
- true:交换机无法根据自身的烈性和路由键找到一个符合条件的队列,那么RabbitMQ就会调用Basic.Return命令将消息返回给生产者
- false:如何出现true的情况,消息直接被丢弃
我们看看如何获取到madatory为true的时候,消息没有被正确路由,返回给生产者的消息:
channel.basicPublish("exchangeName", "routingKey",true, MessageProperties.PERSISTENT_TEXT_PLAIN, "test".getBytes());
channel.addReturnListener(new ReturnListener() {@Overridepublic void handleReturn(int replyCode, String replyText,String exchange, String routingKey,AMQP.BasicProperties properties, byte[] body) throws IOException {String msg = new String(body);System.out.println("返回的结果是:" + msg);}
});
2、immediate
- true:如果交换机路由到队列上并不存在任何消费者,那么消息将不会存入队列中,该消息通过Basic.Return返回给生产者
- false:出现上述情况,消息一样会发送给消息队列
mandatory主要保护的是:交换机是否能正确匹配到消息队列,immediate主要保护的是消息队列是否有消费者。通过这两个参数,可以保证消息在整个从发送到接收过程中,全称掌控。
RabbitMQ3.0之后去掉了immediate参数的支持,官方说法是会影响性能,增加代码复杂性,建议使用TTL(消息最大生存时间)和DLX(死信队列)来代替
二、备份交换机
这东西主要应对mandatory参数不想去设置,并且,这个参数设置了,会增大代码的侵入性,那我们又如何保障消息没有匹配的队列这种情况不丢失呢,就使用这个。下面是一段使用备份交换机的代码:
Map<String, Object> arguments = new HashMap<>();
// alternate-exchange这个参数就是设置具体的备份交换机是谁
arguments.put("alternate-exchange", "myAe");
channel.exchangeDeclare("nomalExchange", "direct", true, false, arguments);
channel.exchangeDeclare("myAe","fanout",true,false,null);
channel.queueDeclare("nomalQueue",true,false,false,null);
channel.queueBind("nomalQueue","nomalExchange","normalKey");
channel.queueDeclare("unroutedQueue",true,false,false,null);
channel.queueBind("unroutedQueue","myAe","");
这段代码的主要示意图如下:
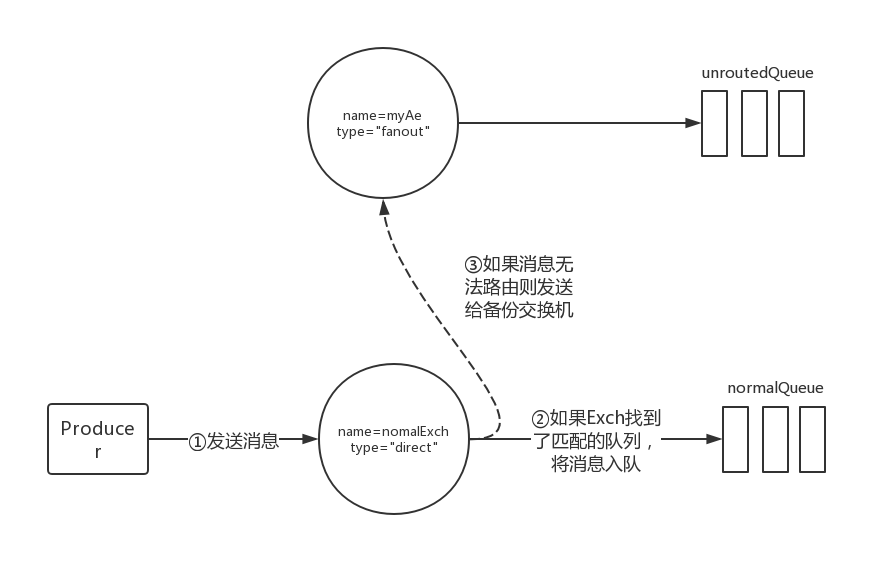
有以下几点:
- 发送到备份交换机上面的路由键和原始的路由键一致
- 如果设置的备份交换机不存在,客户端和RabbitMQ服务端都不会有异常,此时消息丢失
- 如果备份交换机没有绑定队列,客户端和RabbitMQ服务端都不会有异常,此时消息丢失
- 如果备份交换机没有任何匹配的队列,客户端和RabbitMQ服务端都不会有任何异常,此时消息丢失
- mandatory与备份交换机一起使用,那么mandatory无效
三、过期时间(TTL)
过期时间分为消息的过期时间和队列的过期时间
1、消息过期时间
消息过期时间设置,有两种方式:
- 第一种是通过设置队列属性的方式,队列中的所有消息都有相同的过期时间
- 第二种是通过设置消息本身的属性,没调消息的过期时间不同
如果两个一起使用的话,会取较小的那个值。并且如果消息到了过期时间之后还没有消费者进行消费的话,就会变成死信。下面我们首先来看看如何通过队列属性的方式设置过期时间:
Map<String, Object> arguments = new HashMap<>();
// x-message-ttl通过这个参数进行设置
arguments.put("x-message-ttl",6000);
channel.queueDeclare("queueName",true,false,false,arguments);
画外音:当然还可以通过Policy与HTTPAPI的方式进行设置,但是我感觉这两种偏运维,这里主要想写写开发视角,我就不多写这两种设置方式了
不设置这个参数,表示队列里面的消息不会过期,设置成0,除非消息马上被消费者消费,否则将会被丢弃,这个设置0的特性可以部分代替immediate这个参数。下面我们来看看直接设置消息的TTL:
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
builder.deliveryMode(2);// 持久化消息
builder.expiration("60000");//设置TTL=60000ms
AMQP.BasicProperties properties = builder.build();
channel.basicPublish("exchangeName", "routingKey", properties, "123".getBytes());
两种过期效果,对消息删除的契机不太一样:
- 第一种:一旦过期就会从队列中删除消息
- 第二种:在投递到消费者之前进行判定,然后删除
2、队列的TTL
队列过期表示,这个队列上面没有任何的消费者,且队列没有被重新声明过,并且在过期时间段内未调用过Basic.Get命令。RabbitMQ会确保再过期时间到达后将队列删除,但不能保证动作有多么的及时,再RabbitMQ重启之后,过期时间将会被重新计算,下面是设置队列的过期时间:
Map<String, Object> arguments = new HashMap<>();
// x-expires通过这个参数进行设置
arguments.put("x-expires",6000);
channel.queueDeclare("queueName",true,false,false,arguments);
四、死信队列与延迟队列
一个消息,变成死信的时候,就会被发送到一个交换机里面,这个交换机就是DLX(死信交换机),绑定到DLX的队列就是死信队列。消息变成死信有如下几个情况:
- 消息被拒绝(Basic.Reject/Basic.Nack),并设置了requeue参数为false
- 消息过期
- 队列长度达到了最大
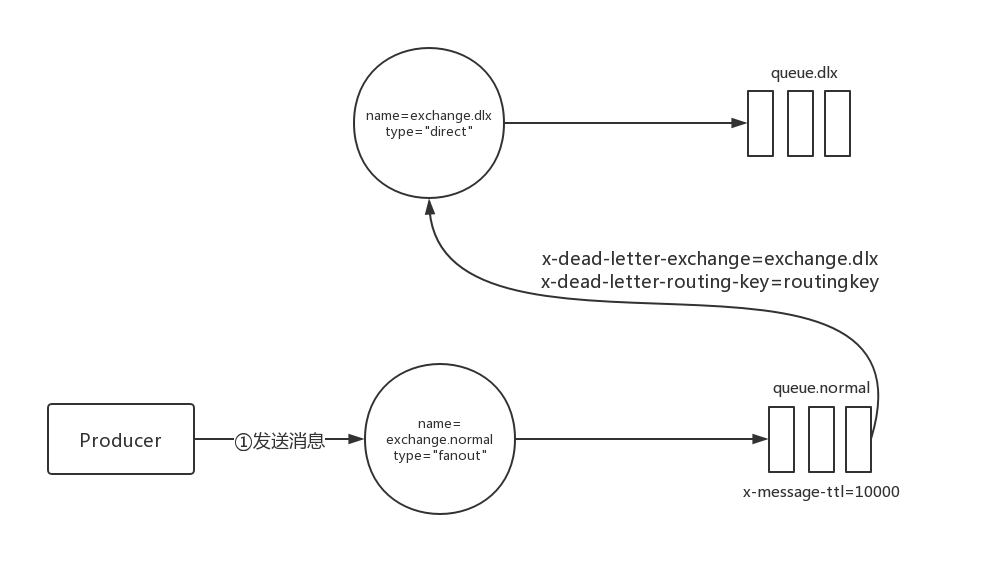
其实DLX和一般交换机没区别,就是将一个普通的队列设置一下DLX的属性,然后这个队列里面编程死信的消息就会被发送到这个交换机上面。这个特性,我们可以为DLX绑定一个队列,然后配合TTL等于0,来弥补3.0中去除掉的immediate参数的功能。下面是一段简单设置DLX的代码:
channel.exchangeDeclare("exchange.dlx", "direct",true, false, false, null);
channel.exchangeDeclare("exchange.normal", "fanout",true, false, false, null);
Map<String, Object> argument = new HashMap<>();
// 设置DLX
argument.put("x-dead-letter-exchange", "exchange.dlx");
// 设置DLK,就是消息变成死信之后的路由键
argument.put("x-dead-letter-routing-key", "routingkey");
// 设置队列的过期时间
argument.put("x-message-ttl", 10000);channel.queueDeclare("queue.normal", false, false, false, argument);
channel.queueBind("queue.normal", "exchange.normal", "");
channel.queueDeclare("queue.dlx", true, false, false, null);
channel.queueBind("queue.dlx", "exchange.dlx", "routingkey");
channel.basicPublish("exchange.normal", "rk",MessageProperties.PERSISTENT_TEXT_PLAIN, "dlx".getBytes());
核心的属性:
- x-dead-letter-exchange:为一个队列配置DLX
- x-dead-letter-routing-key:为DLX指定一个路由键,没有指定的话将使用远消息的路由键
下面是这个死信队列的一个简单的图例:
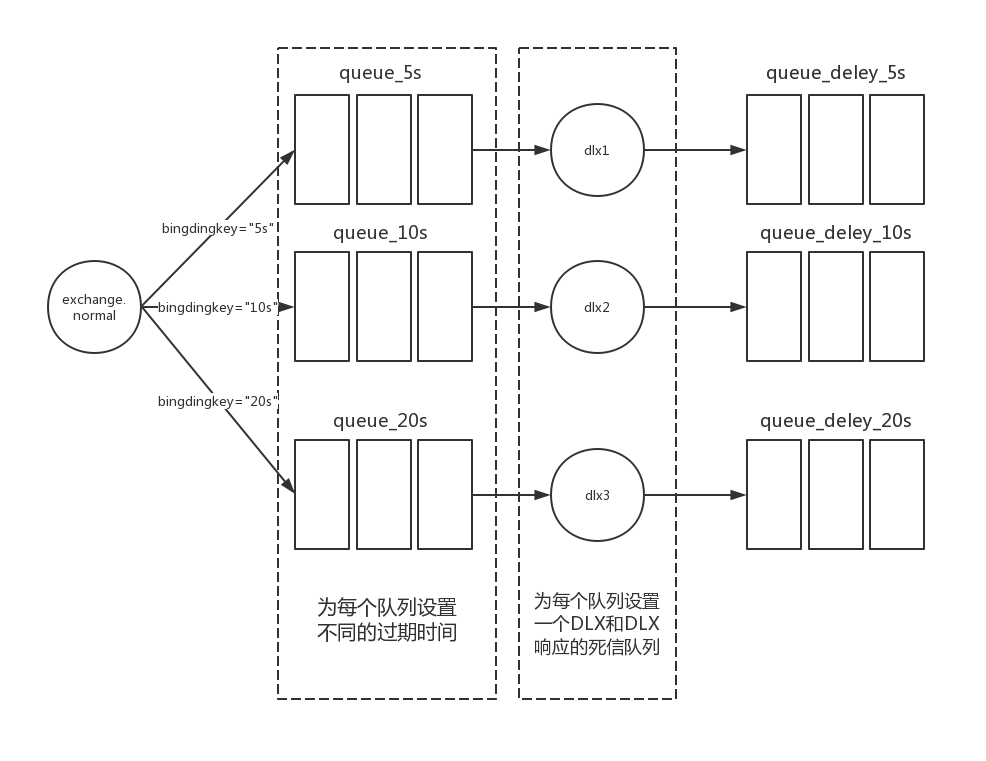
接下来就可以引出延迟队列这个概念了,通过上面的TTL与DLX的详细解说,其实我们完全可以用这两个来实现延迟队列的功能。无非就是将消费者直接去消费死信队列里面的消息,而不是直接消费普通队列的消息。这样普通队列,我们可以设置消息的TTL,然后,到了指定的过期时间,就会直接发送到DLX绑定的队列里面,这样,我们消费者就能消费到了。这样就丁算是过了TTL毫秒,延迟收到消息。我们完全可以通过bindingKey来动态的指定不同的队列,每个队列设置不同的TTL,每个队列设置不同的DLX,然后每个DLX又是不同的死信队列,这样,延迟消息就可以运行了。这里代码不写了,都是重复性的代码。给出延迟队列的图例:
四、生产者确认
这一部分对于学习整个RabbitMQ的高可用、消息可靠性具有至关重要的作用。在介绍生产者确认之前,我们来看看,至今为止,我们接触到的相关RabbitMQ实体,有哪几种持久化,与这几种持久化对应的效果:
- 交换机持久化:false情况重启,交换机的元数据丢失,消息不会丢失,只不过无法往这个交换机发送消息了
- 队列持久化:false情况,重启之后队列元数据与消息都会丢失,消息最终存储是在队列里面的
- 消息持久化:发送时候通过发送属性声明,不持久化消息有可能会丢失
其实我们使用默认的属性封装的常量,已经封装了消息,我们来看看源码:
public class MessageProperties {....../** Content-type "text/plain", deliveryMode 2 (persistent), priority zero */public static final BasicProperties PERSISTENT_TEXT_PLAIN =new BasicProperties("text/plain",null,null,2,// deliveryMode0, null, null, null,null, null, null, null,null, null);
}
但是,即使是上面提到的实体,我们都进行了持久化,我们还是会有无法保证消息不会丢失的场景,下面说两个:
- 如果消息被消费的时候设置了autoAck为true,之后消费者没来得及处理就宕机了,消息在服务端也被删除了。这种可以使用autoAck为false来解决
- 如果消息设置成了持久化,但是消息刚刚发送到RabbitMQ服务端,到持久化这个过程还是有一段时间间隔的,这段时间服务端宕机,那么消息也会丢失
为了解决一些异常宕机或者其他情况导致的消息不可靠的场景,可以使用以下两种技术来解决:
- 镜像(我们在后面原理章节会介绍)
- 生产者确认机制
生产者确认又可以细分成两种:
- 事务机制
- 发送方确认机制
下面我们一个个来说
1、事务机制
首先说说,这种事务机制,其实会榨干RabbitMQ的全乎性能,完全不推荐使用,不过作为一种机制,还是要细说。与具体的事务操作类似,整个发送的事务,也是三步走:
- channel.txSelect
- 发送消息
- channel.txCommit
- 回滚:channel.txRollback
下面就是正常事务发送消息的时序图:
下面是回滚的事务时序图:
下面是极简的一段代码:
try {channel.txSelect();channel.basicPublish("exchange.normal", "rk",MessageProperties.PERSISTENT_TEXT_PLAIN, "dlx".getBytes());channel.txCommit();
} catch (IOException e) {e.printStackTrace();channel.txRollback();
}2、发送方确认机制
首先我们来看第一种确认机制的代码:
channel.confirmSelect();
channel.basicPublish("exchange.normal", "rk",MessageProperties.PERSISTENT_TEXT_PLAIN, "dlx".getBytes());
try {if(!channel.waitForConfirms()){System.out.println("failed");}
} catch (InterruptedException e) {e.printStackTrace();
}这种方式其实并不能增加吞吐量,因为是同一个线程进行同步确认的当然,我们可以使用一个容器,并且批量进行确认,增加吞吐量。下面是模板:
channel.confirmSelect();
int msgcount = 0;
while (true) {channel.basicPublish("exchange.normal", "rk",MessageProperties.PERSISTENT_TEXT_PLAIN, "dlx".getBytes());// 将发出去的消息存储在一个容器里面if(++msgcount>34) {msgcount = 0;try {if (channel.waitForConfirms()) {// 将缓存清空continue;}// 将缓存中的消息重发} catch (InterruptedException e) {e.printStackTrace();// 将缓存中的消息重发}}
}当然,最佳的方式,是通过异步的方式,注册监听器,来处理这种生产者确认的方式。我们来看看具体的代码模板
channel.confirmSelect();
TreeSet<Long> confirmSet = new TreeSet<>();
channel.addConfirmListener(new ConfirmListener() {@Overridepublic void handleAck(long deliveryTag, boolean multiple) throws IOException {System.out.println("nack,seqNo"+deliveryTag+", nultiple:"+multiple);if(multiple){confirmSet.headSet(deliveryTag-1).clear();}else{confirmSet.remove(deliveryTag);}}@Overridepublic void handleNack(long deliveryTag, boolean multiple) throws IOException {if(multiple){confirmSet.headSet(deliveryTag-1).clear();}else{confirmSet.remove(deliveryTag);}// 这里要重新发送消息}
});while(true){long nextSeq = channel.getNextPublishSeqNo();channel.basicPublish("exchange.normal", "rk",MessageProperties.PERSISTENT_TEXT_PLAIN, "dlx".getBytes());confirmSet.add(nextSeq);
}五、消息分发
这一部分,主要说几个概念,也是对消息的消费很有帮助的点
1、Qos是啥
在消费者这一边可以通过一个方法,来设置Qos:
/*** 设置所谓的“服务质量”** 这个设置主要能够限制在服务端发给消费者消息的时候,最大能保持多少未确认的消息,* 在一个信道上面。因此,Qos就提供了一种基于消费者数据流控制的手段。* @param prefetchSize 服务端发送给消费者最大消息大小 (使用八进制表示),0表示不控制* @param prefetchCount 最大服务端发送给消费者的未确认消息数,0表示不控制* @param global true表示这个设置要应用到此Connection上的各个消费者上面*/
void basicQos(int prefetchSize, int prefetchCount, boolean global) throws IOException;void basicQos(int prefetchCount, boolean global) throws IOException;void basicQos(int prefetchCount) throws IOException;针对性的,我们来说说global这个参数:
- false:(默认值)一个信道上面的所有消费者,每个最大保持的未确认消息数都是prefetchCount
- true:当前通信链路(Connection)上所有消费者,都需要遵从prefetchCount的限定值
针对global为true的时候要协调多个消费者,这种情况下非常消耗性能,RabbitMQ针对性的修改了global的定义:
- false:信道上新的消费者需要遵从prefetchCount限定值
- true:信道上的所有消费者都需要遵从prefetchCount限定值
可见,主要是把限制范围缩小了,从Connection级别到channel级别。
2、弃用QueueingConsumer
我们先来看一段QueueingConsumer代码:
QueueingConsumer consumer = new QueueingConsumer(channel);
// channel.basicQos(4);
channel.basicConsumer("QueueName",false,"consumer_zzh",consumer);
while(true){QueueingConsumer.Delivery delivery = consumer.nextDelivery();String message = new String(delivery.getBody());// 对消息做业务逻辑处理channel.basicAck(dlivery.getEnvelope().getDeliveryTag(),false);
}如果环境不是特别的“傲娇”,其实上面代码也没问题,但是要是一下子来了非常大量的消息要消费,这个QueueingConsumer就是造成内存溢出情况,因为他内部使用了一个LinkedBlockingQueue,每次都是循环逐条的进行处理,这样,消息肯定会堆积,内存占用一下子就上去了。当然我们可以使用Qos来控制这一点。但是,这东西还会存在下面的缺陷:
- QueueingConsumer会拖累同一个Connection下的所有信道,使其性能降低
- 同步递归调用QueueingConsumer会产生死锁
- RabbitMQ自动连接恢复机制,不知道QueueingConsumer
- QueueingConsumer不是事件驱动
所以为了避免这么多问题,尽量都要使用DefaultConsumer的方式进行消费
六、总结
最后这部分,我们收拢一下这一章中的一些点。首先我们来看看消息中间件中消息可靠性的三个级别:
- 最多一次:消息可能会丢失,但绝不重复
- 最少一次:消息绝不会丢失,但可能会重复
- 刚好一次:每条消息肯定会被传输一次,且仅一次
RabbitMQ支持其中的最多一次和最少一次。我们来看看最少一次投递的时候,要考虑消息可靠性,要考虑以下几个方面:
- 消息生产者需要开启事物机制或者是生产者确认机制,以确保消息可以可靠性的传输到RabbitMQ中
- 消息生产者需要配合使用mandatory参数或者备份交换机来确保消息能够从交换机中路由到队列里面去,进而保证消息不会被丢弃
- 消息与队列都需要进行持久化,以确保RabbitMQ服务器遇到异常情况时不造成消息丢失
- 消费者在消费消息的同时需要将autoAck设置为false,然后通过手动确认的方式去确认已经正确消费的消息,以避免消费者这边造成消息丢失
最多一次,我们只要生产者随意发送,消费者随意消费,不过这样很难确保消息的可靠性,不会丢失。另外在我们的业务代码中,要确保消费者的幂等性,以防止消息的重复发送。
至此RabbitMQ的基础与高级的使用方式,已经讲解完了,下面一章节,我们进入RabbitMQ原理级别的总结。由于是erlang写的,我本人也看不懂erlang,主要就是对核心的几个原理进行记录一下罢了,根本没有源码讲解,所以也请放松,不难,就看你努力不努力了。
转载于:https://my.oschina.net/UBW/blog/3045353
RabbitMQ吐血总结(2)---高级特性总结相关推荐
- RabbitMQ 基本概念与高级特性
文章目录 1. 什么是消息队列 1.1 消息队列概述 1.2 使用消息队列的优势 1.3 使用消息队列的劣势 1.4 常见的消息队列产品对比 2. RabbitMQ 基本概念 2.1 RabbitMQ ...
- RabbitMQ学习笔记:高级特性TTL(过期时间)
TTL,Time To Live的简称,即消息过期时间,可以对消息和队列设置TTL. 目前有两种方式可以设置消息的TTL.第一种是通过队列的属性设置,队列中的所有消息都有相同的过期时间.第二种方法是对 ...
- RabbitMQ 高级特性(吐血猝死整理篇)
文章目录 RabbitMQ 高级特性 消息可靠性投递(可靠性发送) 事务机制 代码实现 发送方确认机制 为什么比事务性能好 示例代码 测试一下QPS 持久化存储 TTL 队列 死信队列(DLX) 延迟 ...
- RabbitMQ(二):RabbitMQ高级特性
RabbitMQ(二):RabbitMQ高级特性 RabbitMQ是目前非常热门的一款消息中间件,不管是互联网大厂还是中小企业都在大量使用.作为一名合格的开发者,有必要了解一下相关知识,RabbitM ...
- 3 RabbitMQ高级特性 3
主要为大家讲解RabbitMQ的高级特性和实际场景应用, 包括消息如何保障 100% 的投递成功 ? 幂等性概念详解,在海量订单产生的业务高峰期,如何避免消息的重复消费问题? Confirm确认消息. ...
- RabbitMQ高级特性
文章目录 1. 简述 2. 特性示例: 2.1 消息可靠性投递 2.2 Consumer Ack 2.3 消费端限流 2.4 TTL 2.5 死信队列 2.6 延迟队列 1. 简述 在rabbitMQ ...
- 服务异步通讯(rabbitmq的高级特性)
服务异步通讯(rabbitmq的高级特性) MQ的一些常见问题 消息可靠性问题:如何确保发送的消息至少被消费一次. 延迟消息问题:如何实现消息的延迟问题. 消息堆积问题:如何解决数百万消息堆积,无法及 ...
- SpringBoot高级特性
SpringBoot高级特性 SpringBoot缓存 基本环境搭建 导入数据库文件,创建出 department 和 employee 数据表 创建 JavaBean 封装数据 整合 Mybatis ...
- RabbitMQ学习笔记(高级篇)
RabbitMQ学习笔记(高级篇) 文章目录 RabbitMQ学习笔记(高级篇) RabbitMQ的高级特性 消息的可靠投递 生产者确认 -- confirm确认模式 生产者确认 -- return确 ...
最新文章
- linux删除指定创建时间文件(文件夹)脚本
- Python:利用原生函数count或正则表达式compile、findall、finditer实现匹配统计(包括模糊匹配的贪婪匹配、懒惰匹配)
- 简述python的安装过程_python3+ selenium3开发环境搭建-手把手教你安装python(详细)...
- PHP uniqid()函数可用于生成不重复的唯一标识符,该函数基于微秒级当前时间戳。在高并发或者间隔时长极短(如循环代码)的情况下,会出现大量重复数据。即使使用了第二个参数,也会重复,最好的方案是结
- findwindowex子窗口类型有哪几种_游戏场景该怎么画?来参考一下不同的类型吧
- 高斯数据库-GaussDB
- CDN技术详解之系统架构
- 【openv450-samples】像素点聚类EM 图像聚类目标检测
- 网站收录有很多为什么没排名?解决办法
- 微信上传临时素材|微信公众号发送图片
- 秦纪三 二世皇帝下二年(癸已、前208)——摘要
- 【C语言随笔2】GCC编译环境下Socket编程简单实践
- 产品生命周期管理(PLM)的内涵
- Effective TCP/IP Programming读书笔记
- 【Java入门】--键盘输入月份,控制台返回对应英文月份。
- 程序员去大公司面试,阿里P8面试官都说太详细了,社招面试心得
- 从零开始搭建自己的网站二十一:网站IP/PV统计功能设计
- 如果用SEO来优化好论坛,提高排名
- python的积木式编程
- 基于国家统计局城乡规划数据的地名提取(1)