AdaBoost AdaRank
1. AdaBoost
http://my.oschina.net/supersonic/blog/379438
实习了三个多月,把ML的算法都忘得差不多了,最近写论文用到了AdaBoost和AdaRank,这里重新复习总结了下,主要参考了:http://blog.csdn.net/haidao2009/article/details/7514787 。
AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器。(很多博客里说的三个臭皮匠赛过诸葛亮)
算法本身是改变数据分布实现的,它根据每次训练集之中的每个样本的分类是否正确,以及上次的总体分类的准确率,来确定每个样本的权值。将修改权值的新数据送给下层分类器进行训练,然后将每次训练得到的分类器融合起来,作为最后的决策分类器。完整的adaboost算法如下:

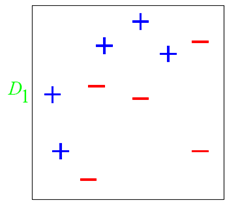
图中,“+”和“-”分别表示两种类别,在这个过程中,我们使用水平或者垂直的直线作为分类器,来进行分类。
第一步:

根据分类的正确率,得到一个新的样本分布D2,一个子分类器h1 其中划圈的样本表示被分错的。在右边的途中,比较大的“+”表示对该样本做了加权。
 得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式
得到 误差为分错了的三个点的值之和,所以ɛ1=(0.1+0.1+0.1)=0.3,而ɑ1 根据表达式第二步:
 根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
根据分类的正确率,得到一个新的样本分布D3,一个子分类器h2
第三步:
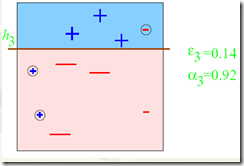
第四步:
 因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
因此可以得到整合的结果,从结果中看,及时简单的分类器,组合起来也能获得很好的分类效果,在例子中所有的。
关于若分类器:
- 不同的弱学习算法得到不同学习器的参数估计、非参数估计。
- 使用相同的若学习算法,但用不同的参数,eg:K-Means的k,神经网络不同的隐含层。
- 相同输入对象的不同表示,不同的表示可以凸显事务的不同特征。
一些思考:
到这里,也许你已经对adaboost算法有了大致的理解。但是也许你会有个问题,为什么每次迭代都要把分错的点的权值变大呢?这样有什么好处呢?不这样不行吗? 这就是我当时的想法,为什么呢?我看了好几篇介绍adaboost 的博客,都没有解答我的疑惑,也许大牛认为太简单了,不值一提,或者他们并没有意识到这个问题而一笔带过了。然后我仔细一想,也许提高错误点可以让后面的分类器权值更高。然后看了adaboost算法,和我最初的想法很接近,但不全是。 注意到算法最后的表到式为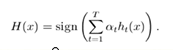 ,这里面的a 表示的权值,是由
,这里面的a 表示的权值,是由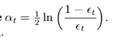 得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
得到的。而a是关于误差的表达式,到这里就可以得到比较清晰的答案了,所有的一切都指向了误差。提高错误点的权值,当下一次分类器再次分错了这些点之后,会提高整体的错误率,这样就导致 a 变的很小,最终导致这个分类器在整个混合分类器的权值变低。也就是说,这个算法让优秀的分类器占整体的权值更高,而挫的分类器权值更低。这个就很符合常理了。到此,我认为对adaboost已经有了一个透彻的理解了。
总结:
我们可以总结下adaboost算法的一些实际可以使用的场景:
AdaBoost AdaRank相关推荐
- 04 集成学习 - Boosting - AdaBoost算法构建
03 集成学习 - Boosting - AdaBoost算法原理 十.AdaBoost算法构建 上一章最后说明了每个基模型的权值α是如何求得的,于是我就可以对模型进行更新操作了. 构建过程一 1.假 ...
- 基于Adaboost算法的人脸检测分类器!
↑↑↑关注后"星标"Datawhale 每日干货 & 每月组队学习,不错过 Datawhale干货 作者:陈锴,Datawhale优秀学习者,中山大学数学系 人脸检测属于计 ...
- 最常用的决策树算法!Random Forest、Adaboost、GBDT 算法
点击上方"Datawhale",选择"星标"公众号 第一时间获取价值内容 本文主要介绍基于集成学习的决策树,其主要通过不同学习框架生产基学习器,并综合所有基学习 ...
- 集成学习-Adaboost
Author: 鲁力; Email: jieyuhuayang@foxmail.com Datawhale Adaboost 算法简介 集成学习(ensemble learning)通过构建并结合多个 ...
- gbdt 算法比随机森林容易_机器学习(七)——Adaboost和梯度提升树GBDT
1.Adaboost算法原理,优缺点: 理论上任何学习器都可以用于Adaboost.但一般来说,使用最广泛的Adaboost弱学习器是决策树和神经网络.对于决策树,Adaboost分类用了CART分类 ...
- GBDT 和 AdaBoost区别?
GBDT 和 AdaBoost区别? Adaboost算法是一种提升方法,将多个弱分类器,组合成强分类器. AdaBoost,是英文"Adaptive Boosting"(自适应增 ...
- Boosting、Adaboost、AdaBoost模型的优缺点、提升树、梯度提升树GBDT
Boosting.Adaboost.AdaBoost模型的优缺点.提升树.梯度提升树GBDT 目录 Boosting.Adaboost.AdaBoost模型的优缺点.提升树.梯度提升树GBDT Boo ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
- 集成学习——Adaboost分类
https://www.toutiao.com/a6674839167580504587/ 上一期分享了集成学习之Bagging分类的方法,这一期分享它的另外一种方法,Adaboost分类方. Ada ...
最新文章
- [vijos1234]口袋的天空最小生成树
- Visual Studio 2010 and .NET 4 RTM中文版发布
- Geoserver怎样发布图层组(shapefile文件)
- (转)创业需要知道的13句话
- WebLogic 12c 修改节点 Managed Server 和 AdminServer 内存方法
- 发布一个自己开发的网站
- 一种常见的关于率指标的错误分析思路
- C语言 memcpy_s 函数 - C语言零基础入门教程
- 帆软报表重要Activator之DesignerInitActivator之一
- docker添加新的环境变量_docker使用教程[三]Dockfile小试牛刀
- 项目清理和删除svn信息(转)
- 关于基础类数据结构的设计想法
- delphi 2010 mysql_Delphi2010 DBExpress+MySQL 程序的打包
- 修改Python解释器和包路径
- 具体案例 快速原型模型_【复习资料】软件工程之快速原型模型
- Hyper-v 虚拟机固定Ip、连接外网
- Thymeleaf从后端取数据到js中 js中字符串转数字的函数应用
- 漫话:什么是DevOps?
- 文献综述在哪儿能找到?
- Python数据结构栈,后进先出