云场景实践研究第12期:有货
更多云场景实践研究案例,点击这里:【云场景实践研究合集】联合不是简单的加法,而是无限的生态,谁会是下一个独角兽
随着整体业务的高速发展、流量的爆发式增长,有货对系统进行了大面积的重构。首先,数据中心从传统的单一IDC演化成为“公有云+IDC”混合模式,同时应用系统也从原来的单体全站应用演变到以微服务为核心的架构模式,并且从多级缓存、服务的降级等多维度、全方面地提升了系统的可用性。 有货借助阿里云的能力降低了整体的硬件、运维成本,并且将系统前台应用相关计算、缓存节点全部迁移到阿里云上,能够帮助系统更加有效地应对诸如双11这样的场景下的流量峰值冲击。
“对于互联网的业务而言,企业必须做到快速响应业务需求,同时互联网业务需求是灵活多变的,传统IDC模式很难保证在短时间内上线一款新的应用。对于像阿里云这样的公有云来说,其具有的弹性伸缩能力,能应对频繁业务活动;同时像双十一之类的对于流量突发增长活动,公有云可以采取峰值应对,弥补传统IDC的不足。”
——李健
有货CTO
采用的阿里云产品
- 阿里云云服务器 ECS
- 阿里云云解析 DNS
- 阿里云DDoS高防IP
- 阿里云负载均衡 SLB
为什么使用阿里云
需要在前端使用阿里云CDN来加速图片、JS等静态资源,提升用户的体验。
互联网业务需求是灵活多变的,传统IDC模式很难保证在短时间内上线一款新的应用,需要阿里云这样的公有云来采取峰值应对,弥补传统IDC的不足。
传统运维方式低效,需要借助公有云的能力帮助简化运维流程。
使用阿里云这样的公共云可以降低整体的硬件、运维成本。
关于 有货
有货旨打造中国潮流生态圈,其核心业务包括有货App、YOHO、Mars应用。有货也积极举办线下活动,例如举办潮流嘉年华等活动。YOHO!将在2016年5月在艾尚开3000平方米的旗舰店,将集理发、拍照、咖啡、读书等为一体。该店将采用完全的电子货架,也是全球唯一一个完全的电子货架模式。
有货上云之前的痛点与思考
对于有货为什么选择混合云架构这个问题可以拆成两个问题,一是为什么使用公共云?另一个问题就是为什么不完全使用公共云,为什么还保留原来的IDC?
有货之所以采用这种混合云的架构的设计主要是基于以下几个痛点考虑的:
业务痛点:对于互联网的业务而言,企业必须做到快速响应业务需求,同时互联网业务需求是灵活多变的,传统IDC模式很难保证在短时间内上线一款新的应用。对于公共云来说,其具有的弹性伸缩能力,能应对频繁业务活动;同时像双十一之类的对于流量突发增长活动,公共云可以采取峰值应对,弥补传统IDC的不足;
运维痛点:对于传统的IDC,要完成一次具体的扩容,必须要从服务器的采购申请,再到服务器的上架,再去安装操作系统,再去部署应用等等一系列操作,十分复杂。同时在扩容过程中,不仅流程过去繁琐,还有可能遇到一系列的问题,比如因为服务器环境差异导致系统故障等问题。这些问题不仅增加了运维过程中的难度,还使得整个系统的可用性大大降低;
成本控制:一方面使用公共云可以降低整体的硬件、运维成本;另一方面从传统的IDC迁移到公共云上的迁移成本,包括迁移过程中对系统进行改造和迁移时间的成本。所以基于两者考虑,最后选择了混合云的模式;
安全控制:从安全角度出发,采用混合云模式:将前台应用相关计算、缓存节点全部迁移到阿里云上。核心组数据依然保留在IDC中,保障核心数据的安全。
为什么选择阿里云?
有货基于混合云的系统架构
1) 整体架构设计

有货基于“IDC+阿里云”的系统架构
如图所示的是有货抽象化的混合云系统架构的整个层次结构。中间是整个服务注册中心,主要分为六层。客户端采用多种高可用策略,在客户端完成降级、缓存、Http DNS等操作;客户端下侧的入口层主要涉及智能DNS、高防DDOS、SLB、Nginx等;从入口层再往下是网关层,在网关层内完成安全、流控、降级等操作;核心业务服务层完成所有的核心业务逻辑,包括服务注册、服务发现、服务调用等等;从服务层再往下就是缓存层,在缓存层内一是对热点数据进行加速,同时也需要考虑缓存数据的更新时效等问题;最下面一层是数据层,主要的数据存储在MySQL中,同时进行数据双活操作,保证数据的一致性。图中六层结构的左侧是垂直运维平台,平台在每一层都有相关的运维监控工作,右边是基于大数据平台的数据分析系统。
2) 客户端
在客户端:
通过使用HttpDNS,解决LocalDNS的潜在问题。在移动端采取Http直连的模式,防止DNS劫持问题,通过HttpDNS Server获取后端服务的IP列表,避免LocalDNS缓存问题,避免域名解析慢或者解析失败,能快速应对故障处理。同时在高可用方面,混合云的模式下,如果其中一个数据中心出现问题时,可以通过HttpDNS快速进行流量切换;
在前端使用阿里云的CDN加速图片、JS等静态资源,极大的提升了用户体验;
App客户端通过Cache-Control HTTP头来定义自己的缓存策略,通过预加载和客户端缓存,实现离线化,大幅度提升性能;
服务降级,客户端根据降级策略可在特定条件下对非关键业务进行降级,以保证核心关键业务的高可用;
对网络质量监测,根据用户在2G/3G/4G/Wi-Fi等不同网络环境下设置不同的超时参数,以及网络服务的并发数量。同时根据不同的网络质量设计不同的产品体验;
业务异常监测,在客户端监测用户使用过程中的异常情况、快照信息,实时上报异常数据,实时定位分析问题;
如果App出现大面积故障,可快速切换至Web App模式,保障了系统的高可用。
3) 入口层
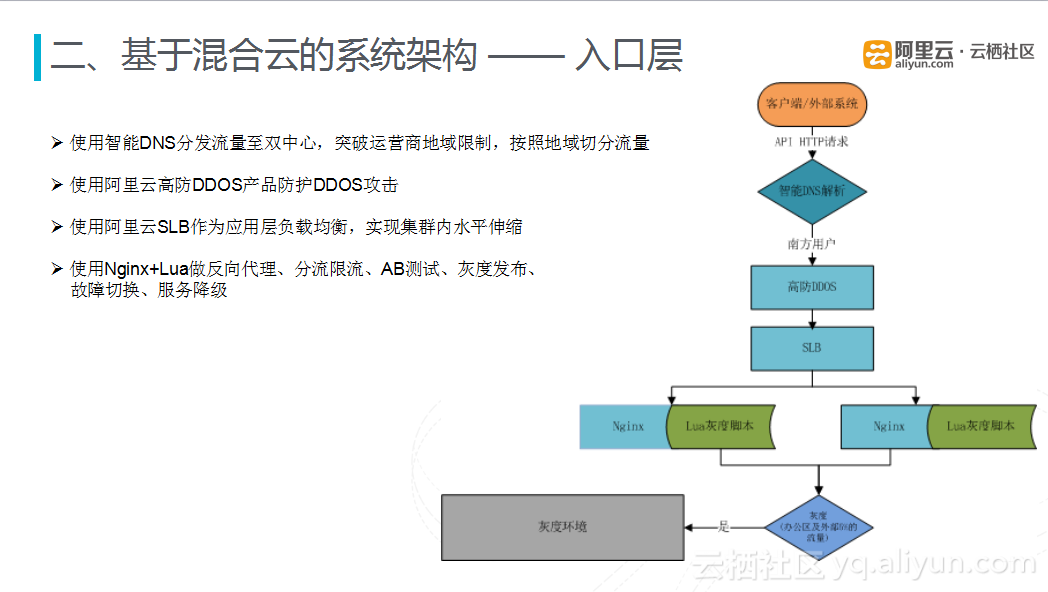
入口层使用智能DNS分发流量至混合云的双数据中心,将应用做成无状态模式,在两个应用中心做对等的部署,突破运营商地域限制,按照地域切分流量,比如将南方的数据流量切入到阿里云上,将北方的流量切换到自建的IDC中。安全方面,使用阿里云高防DDOS产品防护DDoS攻击。使用阿里云SLB作为应用层负载均衡,实现集群内水平伸缩,同时结合阿里云的ECS,很好地应对流量高峰时、高峰过后的复杂情况。此外,接口层还使用自建Nginx+Lua做反向代理、分流限流、AB测试、灰度发布、故障切换、服务降级等处理措施。
3) 网关层
入口层之下的网关层内也做了很多措施来保障系统高可用性。安全控制方面,在网关层统一完成客户端请求的身份认证,统一完成数据的加密解密;分流与限流方面,将流量按业务切分,路由至后端不同业务线的服务中心,以实现后端服务的实时动态水平扩展。当流量超过预定阀值,系统出现瓶颈的时候自动限制流量进入后端服务,以防止雪崩效应。服务降级方面,在系统出现瓶颈是,自动降级非关键业务,以保证核心业务的正常运转。熔断机制方面,根据后端服务的健康状况,自动熔断对服务的调用,以防止雪崩效应。异步化方面,网关异步化调用后端服务,避免长期占用请求线程,快速响应处理结果,快速释放线程资源。在网关层,一级缓存用于加速热点数据;二级缓存用户容灾。请求进入网络层后首先调用一级缓存,如果一级缓存命中,直接将结果返回给客户端;如果没有命中,网关层会调用后端服务,从服务中返回数据,在这个过程中如果服务出现故障无法访问时,网关会访问二级缓存,因为二级缓存是用于容灾处理,所以二级缓存的时间非常长,数据保存24小时。
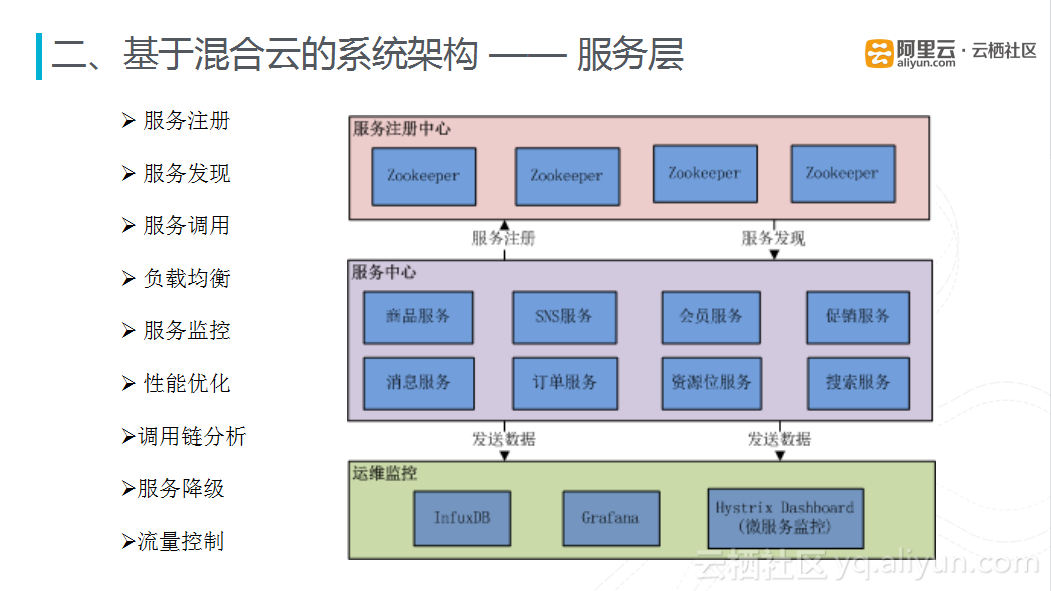
4) 服务层
5) 缓存层
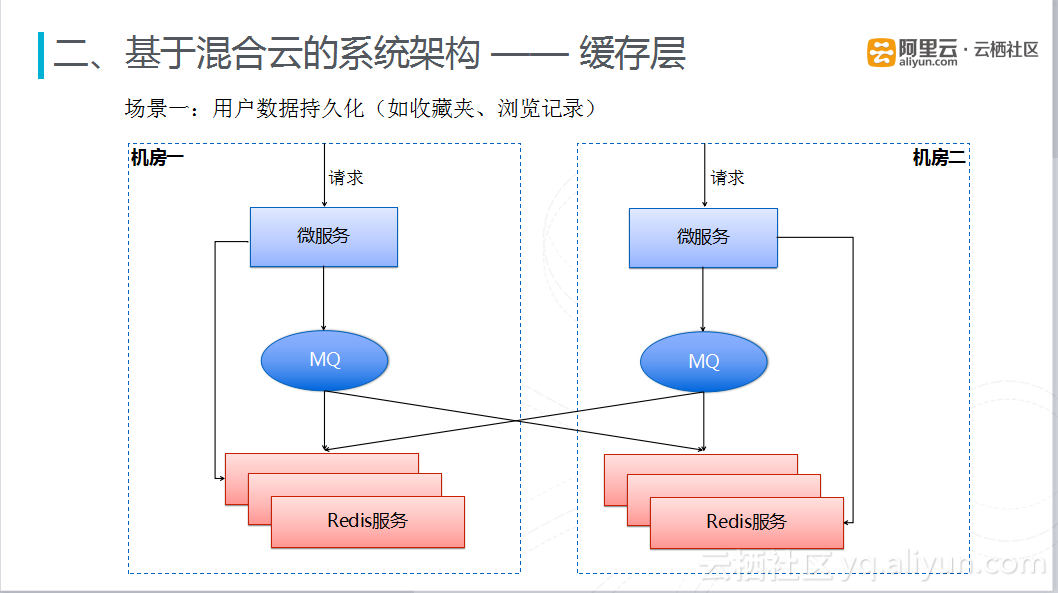
在不同的场景下,采用不同的缓存策略。在用户数据(收藏夹、浏览记录)持久化场景中,采用混合云双数据中心完全对等的部署方式、做双写双活。每个数据中心微服务将数据写入缓存时,均是将数据发送到当前数据中心的MQ中,读取数据是直接从当前数据中心的Redis集群读取。Redis集群同时订阅两个数据中心的MQ的数据,确保两个数据中心部署的Redis集群完全对等,同时Redis集群中的数据也是全量数据,当一个数据中心出现问题时,可以将流量切换到另一个数据中心。
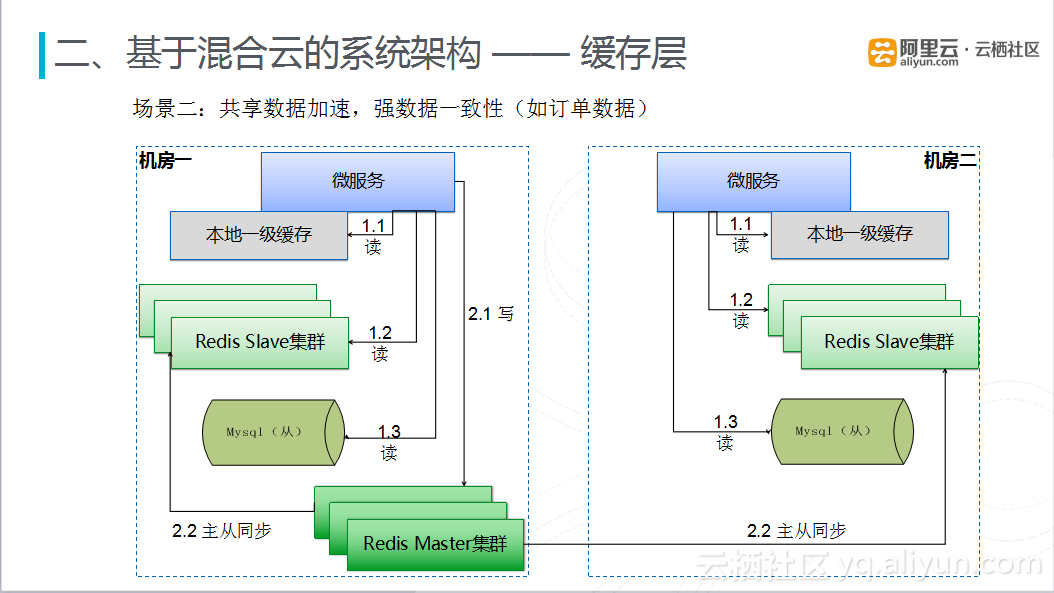
在共享数据加速,保持数据(如订单数据)一致性的场景下,采用单主多从的缓存模式,在两个数据中心更新缓存时,是先写到一个Redis Master集群中,然后从一个Redis Master集群同步到两个数据中心的Redis Slave集群中,整个请求的逻辑就是:请求进入其中一个机房的微服务中,微服务首先会读取微服务本地的一级缓存,如果没有命中,再去本数据中心的Redis Slave集群进行查询,如果还是没有命中,再回源到本数据中心的数据库中进行查询,将读取后的数据写入到Redis Master集群,同时更新本地的一级缓存和Redis Slave集群,当然Redis Master集群也会将数据同步更新到另一个数据中心的Redis Slave集群中。这种单写多读的缓存模式实现数据加速以及保证数据一致性的要求。目前这种跨机房的主从同步延时并不明显,延迟在一两毫秒左右。
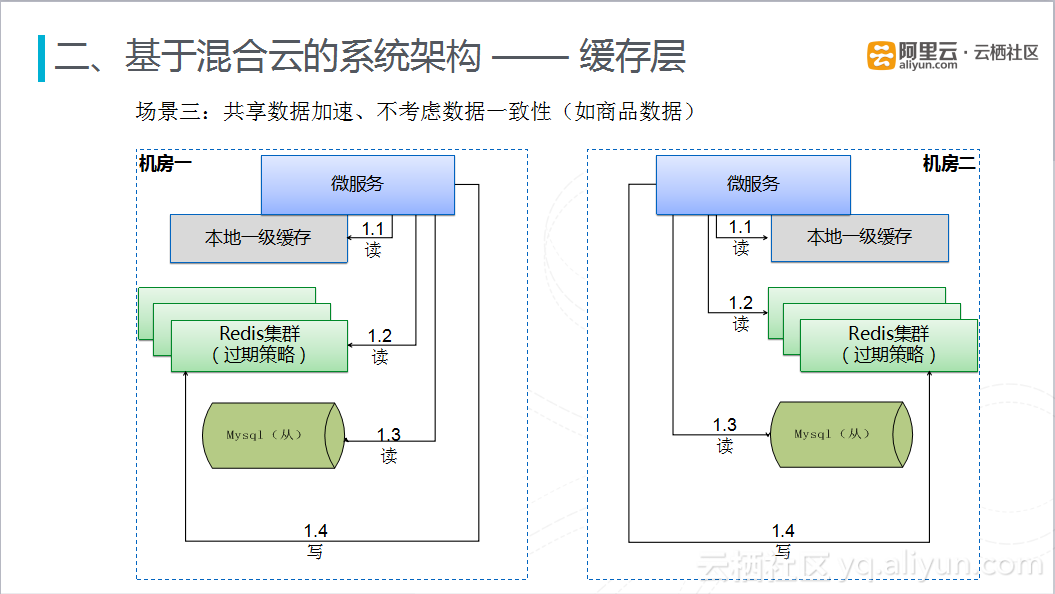
在共享数据加速但不考虑数据(商品)一致性的场景下,也是采用多活的理念,即在两个数据中心部署完全对等的缓存集群。在上图的机房一中,当有数据请求时,首先从本地一级缓存进行查询,如果没有命中,再去查本地的Redis集群,依旧没有命中时,回源到本地的数据库进行查询,同时将查询到的数据更新到本数据中心的Redis集群。虽然两个数据中心的缓存集群部署一致,但是在Redis集群中存的数据可能不一致。
6) 数据层
数据层作为六层架构中的最底层,主要的应用还是基于MySQL的主从模式。下面提到的特点是在非核心业务上的一些尝试,并没有大面积应用:
同城双活,即由业务层来控制数据的实时性和最终一致性,而不是通过数据同步来保证实时性和一致性。
业务层双写,数据异步分发至两个数据中心,任意机房写入的数据通过异步消息的方式分发到另一个机房,以此来保证两个机房数据的最终一致性。
业务层通过二级查询保证数据的实时一致性,由于业务层双写只能保证数据的最终一致性,无法保证实时一致性,因此,针对具有实时一致性要求的业务场景,我们通过业务层的二级查询来保证。
重复写入应对单机房故障,当任意机房出现故障时,如果写入的数据还没有分发至另一个机房,则由业务层在可用机房重复写入数据,通过算法来生成相同的ID。
通过failover库为高可用提供双重保险,针对流水型业务数据,在数据库故障时,需要进行主从切换,此时通过业务层将所有数据的读写切换至failover库,主库恢复以后再将流量切回主库。
垂直拆分与水平拆分结合使用。
有货系统架构的服务化设计
有货的架构设计之所以需要服务化,是因为在做服务化之前系统高度耦合,牵一发而动全身,直接影响到系统可用性;同时业务相互影响,系统很难维护;系统逻辑过于耦合,很难进行水平扩展;也无法通过流控、降级等手段保障系统的可用性;此外由于系统的高度耦合,极易产生雪崩效应。因此基于上述原因,服务化改造势在必行。
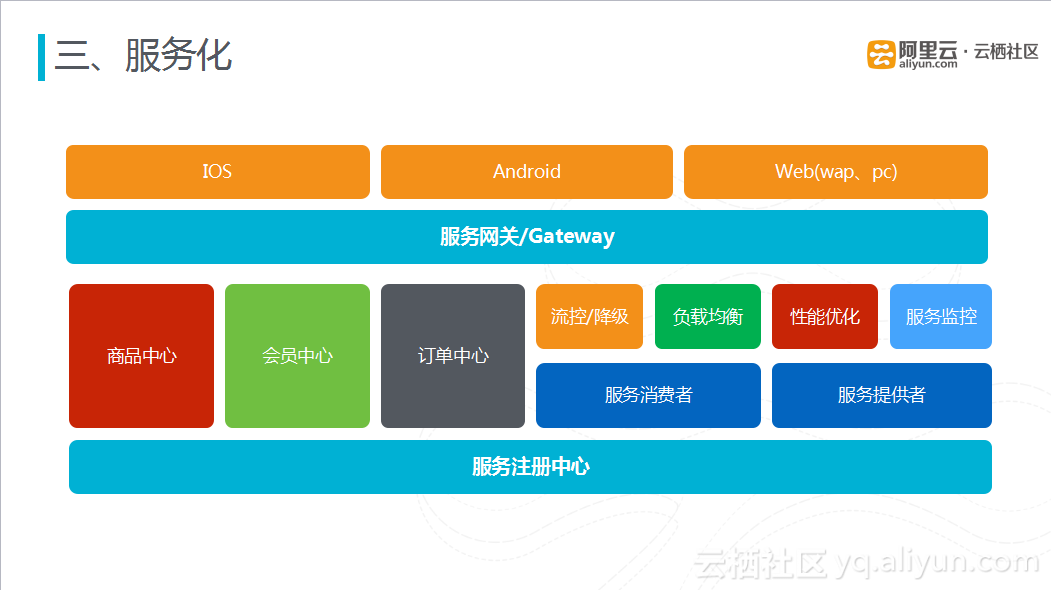
上图是有货服务化系统的架构,最上面一层是客户端,客户端下面就是服务网关层,再往下就是具体的业务服务中心,目前对电商而言三大核心就是商品、会员、订单中心。围绕服务中心的是一些服务治理策略,如流控/降级、负载均衡等。系统的最低层是服务注册中心。
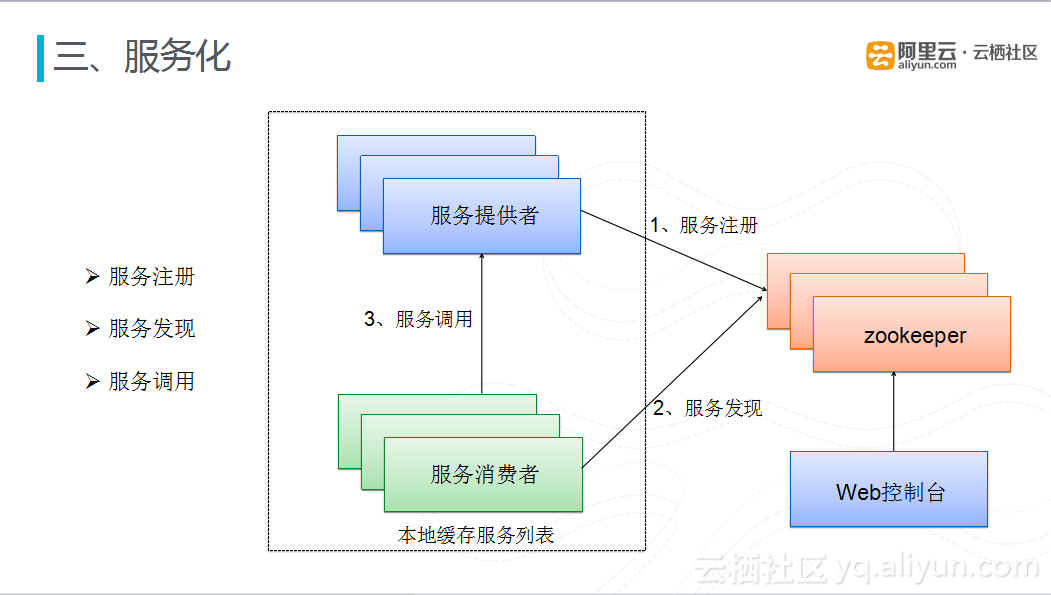
对于服务化而言,最核心的就是服务的发现、注册、调用。目前有货采用的是Spring+Register+Zookeeper搭建的最简单的服务框架,通过Zookeeper完成的服务注册和发现,通过Register完成服务的调用。
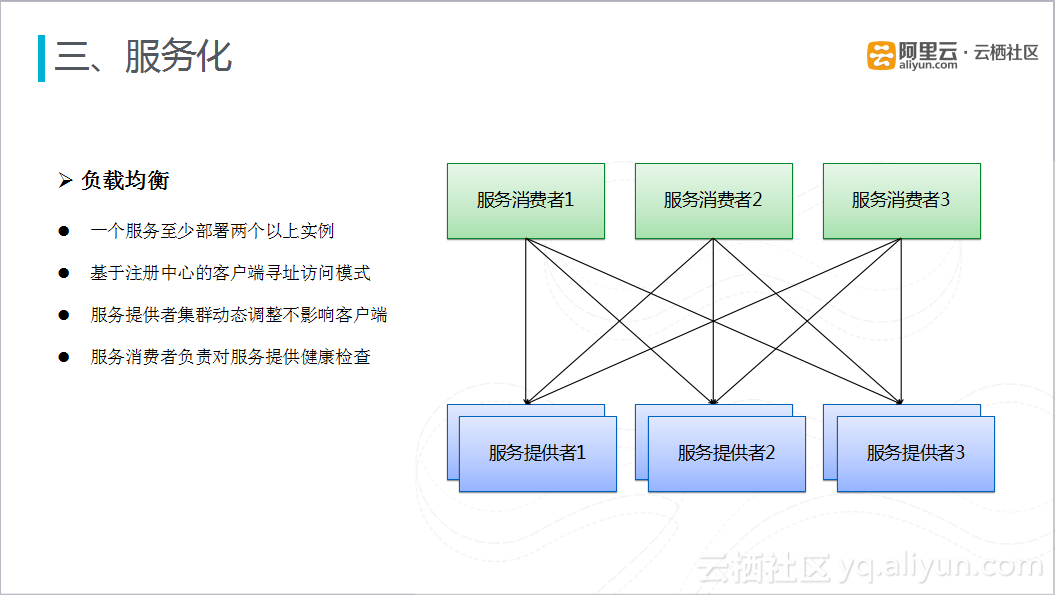
服务化还有一个很重要的要求就是服务化负载均衡,一般是有两种方案:集中式的LoadBalance,在服务消费者和提供者之间通过阿里云的SLB或者F5搭建独立的LoadBalance,通过集中式的负载均衡设备完成对服务调用的负载均衡;在进程内做负载均衡,即软负载的方式,将负载均衡策略渗入到服务框架里面,服务消费者作为负载均衡的客户端,请求只需要从服务注册中心获取最新的服务列表,利用服务框架自身携带的负载均衡策略,完成负载均衡的调用。
在服务降级方面,通过使用开源的Hystrix配置服务超时时间,当服务调用超时时,直接返回或执行Fallback逻辑。另外基于Hystrix提供的熔断器组件,可以自动运行或手动调用对当前服务进行暂停后再重新调用服务。流量控制方面,通过计数器服务限定单位时间内当前服务的最大调用次数(比如600次/分钟),如果超过则拒绝,以保证系统的可用性;同时为每个服务提供一个小的线程池,如果线程池已满,调用将被立即拒绝,默认不采用排队,加速失败判定时间。
服务化中,对于服务的监控、性能优化以及调用链的分析也尤为重要。通过Hystrix提供的服务化监控工具实时观察在线服务的运行状态,有了监控之后可以进行相应的性能优化。对于调用链分析,当请求从网关层进入时,追加一个Trace ID,Trace ID会在整个调用过程中保留,最后通过分析Trace ID将整个请求的调用链串联起来。
自动化运维平台
目前采用的混合云双数据中心模式,如果依旧采用传统的手工部署应用,做文件拷贝、同步等工作,很容易出现版本不一致、文件更新异常等问题。因此在混合云模式下构建自动化运维平台需要考虑以下核心问题:
首先在运维平台上要能完成对双云的一键式的自动化部署发布,以及部署失败后的一键快速回滚;
在运维平台中需要完成对流量的管理控制,可以完成对整个应用系统的容量规划;
最核心的部分是运维平台实现监控和报警,包括对业务层级监控、应用系统的监控、以及系统层级的IO、磁盘、网络的监控。
在运维平台中,需要做到应对故障快速恢复的预案,分析系统可能出现的故障点,在出现故障时,通过自动化的脚本对故障进行恢复。
关于有货的更多实践详情:有货:六层混合云架构打造中国最潮生态圈
原文发布日期:2016-03-31
云栖社区场景研究小组成员:贾子甲,仲浩。
云场景实践研究第12期:有货相关推荐
- 云场景实践研究第85期:墨迹天气
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 墨迹运营团队每天最关心的是用户正在如何使用墨迹,在他们操作中透露了哪些个性化需求.这些数 ...
- 云场景实践研究第52期:畅游
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 畅游在手游和端游方面做了很长时间,在游戏运维方面也积累了十几年的经验.而畅游对于混合云来 ...
- 云场景实践研究第55期:京颐集团
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 京颐集团的趣医网从2014年的5月建立之初就开始了上云之路,上云的初期,管理层还担心上云 ...
- 云场景实践研究第7期:驴妈妈旅游网
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 在驴妈妈旅游网成立初期,整体系统最初采用的是ALL IN ONE架构,服务器和数据库数量 ...
- 云场景实践研究第71期:云集微店
更多云场景实践研究案例,点击这里: [云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 11.11全球精品狂欢节的首日,云集微店用日PV过两亿.每秒钟最大并发6万.日销售额超 ...
- 云场景实践研究第74期:科沃斯
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 科沃斯机器人德国的市场占有率达到了34%,是德国所有扫地机器人的NO.1的产品.本文分享 ...
- 云场景实践研究第34期:加和科技
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 ReachMax成立之初,主创推出的PDB可退还模式在业内还是一个很新的服务模式.为了精 ...
- 云场景实践研究第27期:袋鼠云
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 随着网站论坛粉丝数高涨,原有系统架构和服务器性能已无法满足热情高涨的粉丝需求.同时,网站 ...
- 云场景实践研究第37期:悦跑圈
更多云场景实践研究案例,点击这里:[云场景实践研究合集]联合不是简单的加法,而是无限的生态,谁会是下一个独角兽 作为一款基于社交型的跑步应用,悦跑圈选择阿里云文件存储服务,实现高可用.高可靠.线性的横 ...
最新文章
- 安装hadoop下的sqoop1.99.3及配置问题全解决
- invalid dts/pts combination
- Java实例---计算器实例
- 【人脸识别】人脸识别必读论文
- luogu P5304 [GXOI/GZOI2019]旅行者
- Linux连接状态为syn_recv,linux 服务器 syn*** 大量SYN_RECV状态处理
- Django echarts初试随笔
- 2021计算机一级新增知识点,2021年计算机一级知识点.doc
- 苹果6s最大屏幕尺寸_iPhone 6s:经典的小屏旗舰,百元价位也能做苹果党
- 一些网络爱好者常用的网络工具
- 2022.02.17学习总结(最小生成树)
- 微信小程序开发———音乐播放器
- Linux设备模型(2)——Kobject
- 网易免费企业邮支持POP3/SMTP服务器
- 最小生成树-Kruskal和Prim-JAVA代码
- 【20210827】【系统设计】“秒杀系统”架构设计分析
- 阿里二面: 说一下从url输入到返回请求的过程
- Window11 alt+tab键失效
- 赵小楼《天道》《遥远的救世主》深度解析(83)形式主义的典范,辩证逻辑的障碍
- 前端毕业设计 天气预报